【数据结构1-2】二叉树
树形结构不仅能表示数据间的指向关系,还能表示出数据的层次关系,而有很明显的递归性质。因此,我们可以利用树的性质解决更多种类的问题。

但是在平常的使用中,我们并不需要使用这么复杂的结构,只需要建立一个包含int right和int left的结构体即可,left和right用于指示该节点的左儿子和右儿子。
一、【P4913】二叉树深度(递归/层次遍历)
本题的重点在于二叉树的存储和二叉树的层次遍历。
1. 二叉树存储:考虑一个二叉树的每个节点都有两个子节点,所以我们可以考虑用一个结构体来存储。其中,left和right分别代表节点的左节点编号和右节点编号。
struct node {int left, right;
};
node tree[MAXN];2. 二叉树层次遍历:我们可以从根节点出发,先递归遍历该节点的左节点,再递归遍历该节点的右节点。对于每个父亲节点,先比较左右子树的高度,然后选取较高的子树,将其深度加1,每次遍历更新子树的高度。当遍历到叶子节点后返回0(叶子节点的左右子树高度均为0)。
int maxDepth(int id)
{if (id == 0) return 0;return 1 + max(maxDepth(Tree[id].left), maxDepth(Tree[id].right));
}AC代码:
#include <iostream>
#include <string>
#include <algorithm>
#include <cmath>using namespace std;struct node
{int left;int right;
}Tree[1000005];int maxDepth(int id)
{if (id == 0) return 0;return 1 + max(maxDepth(Tree[id].left), maxDepth(Tree[id].right));
}int main()
{int n; cin >> n;for (int i = 1; i <= n; i++){int a, b; cin >> a >> b;Tree[i].left = a;Tree[i].right = b;}cout << maxDepth(1);}二、【P1827】美国血统(前中后序遍历)
前序遍历、中序遍历和后序遍历是三种利用深度优先搜索遍历二叉树的方式。它们是在对节点访问的顺序有一点不同,其它完全相同。
需要注意的是下图中伪代码并未给出base case,即递归返回的条件。

AC代码:
先序遍历的特点是优先遍历根节点,所以整棵树的根应该会在inorder字符串的最开始出现;中序遍历的特点是优先遍历左子树,然后遍历根节点,所以我们可以根据中序遍历序列判断左右子树中包含哪些点。
以本题为例:
中序(inorder)遍历:ABEDFCHG;先序(preorder)遍历:CBADEFGH。
- 首先可以根据preorder判断C为根节点,然后依据inorder判断ABEDF为左子树中的节点,HG为右子树中的节点。
- 回到preorder序列,第二个节点是B,所以左子树的根节点为B,依据inorder序列可知A构成次级左子树,DEF构成次级右子树。
- 回到preorder序列,第三个节点是A,刚好是以B为根的子树的左子树的根;第四个节点是D,所以以B为根的子树的右子树的根为D。
- 以此类推,可以还原整棵树的情况。
#include <iostream>
#include <string>
#include <algorithm>
#include <cmath>
#include <vector>
#include <map>
#include <stack>
#include <set>using namespace std;struct TreeNode //建树
{char val;TreeNode* left;TreeNode* right;TreeNode() :val(0), left(nullptr), right(nullptr) {}TreeNode(char x) : val(x), left(nullptr), right(nullptr) {}TreeNode(char x, TreeNode* left, TreeNode* right) : val(x), left(left), right(right) {}
};//对preorder中的[s0,e0]部分操作,s1用于跟踪preorder序列中某个父亲节点
TreeNode* buildTree(string& preorder, map<char, int>& mp, int s0, int e0, int s1)
{if (s0 > e0) return nullptr;char mid = preorder[s1];int index = mp[mid]; //找到当前父亲节点在中序遍历inorder中的位置int left_length = index - s0; //左子树大小TreeNode* node = new TreeNode(mid);node->left = buildTree(preorder, mp, s0, index - 1, s1 + 1);node->right = buildTree(preorder, mp, index + 1, e0, s1 + 1 + left_length);return node;
}void PostOrder(TreeNode* tree)
{if (!tree) return;PostOrder(tree->left);PostOrder(tree->right);cout << tree->val;
}int main()
{string preorder, inorder;cin >> inorder >> preorder;map<char, int> mp;//使用map存储,便于搜索for (int i = 0; i < inorder.length(); i++)mp[inorder[i]] = i;TreeNode* res = buildTree(preorder, mp, 0, inorder.length() - 1, 0);PostOrder(res);
}由于需要通过preorder序列的节点,查询该点在inorder序列的位置,所以将inorder序列用map存储,实现O(1)量级的查询。
使用buildTree函数递归还原整棵树,然后使用postorder函数对树进行后序遍历,得到答案。
三、【P1229】遍历问题(前中后序遍历)
思路:给定inorder能确定树的具体结构,是因为可以确定子树是左子树还是右子树;而只给定preorder和postorder,则不能确定,这就是会出现不同树结构的原因。
只有前和后,那么主要问题就是没有办法处理只有一个子树的情况,因为这种情况下不知道子树究竟是这个节点的左子树还是右子树,也就是说其实这道题要判断遍历中存在着多少个只有一棵子树的情况。对于前,如果一个结点的下个结点等于后中对应结点的前一个结点的话,那么这个结点就是根节点且其只有一个子树。sum初始化为1,出现一个只有一棵子树的情况,就把sum*2(每次会出现两种不同的情况,分别是出现左子树和出现右子树)。
AC代码:
#include <iostream>
#include <string>
#include <algorithm>
#include <cmath>
#include <vector>
#include <map>
#include <cstring>
#include <queue>using namespace std;
const int INF = 0x7fffffff;int main()
{string preorder, postorder;cin >> preorder >> postorder;int sum = 1;for (int i = 0; i <= preorder.length() - 2; i++){for (int j = 0; j <= postorder.length() - 1; j++){if (preorder[i] == postorder[j] && preorder[i + 1] == postorder[j - 1]){sum *= 2;}}}cout << sum << endl;
}四、【P1030】求先序序列(前中后序遍历)
首先,一点基本常识,给你一个后序遍历,那么最后一个就是根(如ABCD,则根为D),因为题目求先序,意味着要不断找根。
那么我们来看这道题方法:(示例)
中序ACGDBHZKX,后序CDGAHXKZB,首先可找到主根B;
那么我们找到中序遍历中的B,由这种遍历的性质,可将中序遍历分为ACGD和HZKX两棵子树,那么对应可找到后序遍历CDGA和HXKZ(从头找即可);从而问题就变成求:
- 中序遍历ACGD,后序遍历CDGA的树;
- 中序遍历HZKX,后序遍历HXKZ的树;
接着递归,按照原先方法,找到
1.子根A,再分为两棵子树;
2.子根Z,再分为两棵子树。
就按这样一直做下去(先输出根,再递归)。
模板概括为:
- step1:找到根并输出
- step2:将中序,后序各分为左右两棵子树;
- step3:递归,重复step1,2;
AC代码:
#include <iostream>
#include <string>
#include <algorithm>
#include <cmath>
#include <vector>
#include <map>
#include <cstring>
#include <queue>using namespace std;
const int INF = 0x7fffffff;string inorder, postorder;void preorder(string in,string after)
{if (in.size() > 0){char ch = after[after.size() - 1];cout << ch;int k = in.find(ch);preorder(in.substr(0, k), after.substr(0, k)); //左子树preorder(in.substr(k + 1), after.substr(k, in.size() - k - 1));//从k开始,截取这么多个数}
}int main()
{cin >> inorder >> postorder;preorder(inorder, postorder);
}将2,3,4三题进行比较,2的解题思路具有普适性,但是建树的过程相对复杂;4的解题思路较为清晰,但是缺点在于只能输出序列,并不能得到完整的树。
五、【P5076】简化二叉树(二叉搜索树)
参考:https://www.cnblogs.com/do-while-true/p/13566274.html
但值得强调的是,二叉搜索树是一种低级的平衡二叉树,因为在最差情况下,可以会呈现链状结构,导致时间复杂度为O(n),而不是所需的O(logN)。因此,只需要了解即可,重点需要掌握的是平衡二叉树。
splay搜索树的几种操作:
(1)插入:x 是当前节点的下标,v 是要插入的值。要在树上插入一个 v 的值,就要找到一个合适 v 的位置,如果本身树的节点内有代表 v 的值的节点,就把该节点的计数器加 11 ,否则一直向下寻找,直到找到叶子节点,这个时候就可以从这个叶子节点连出一个儿子,代表 v 的节点。具体向下寻找该走左儿子还是右儿子是根据二叉搜索树的性质来的。
void add(int x,int v)
{tree[x].siz++;//如果查到这个节点,说明这个节点的子树里面肯定是有v的,所以siz++if(tree[x].val==v){//如果恰好有重复的数,就把cnt++,退出即可,因为我们要满足第四条性质tree[x].cnt++;return ;}if(tree[x].val>v){//如果v<tree[x].val,说明v实在x的左子树里if(tree[x].ls!=0)add(tree[x].ls,v);//如果x有左子树,就去x的左子树else{//如果不是,v就是x的左子树的权值cont++;//cont是目前BST一共有几个节点tree[cont].val=v;tree[cont].siz=tree[cont].cnt=1;tree[x].ls=cont;}}else{//右子树同理if(tree[x].rs!=0)add(tree[x].rs,v);else{cont++;tree[cont].val=v;tree[cont].siz=tree[cont].cnt=1;tree[x].rs=cont;}}
}(2)找前驱:x 是当前的节点的下标,val 是要找前驱的值,ans 是目前找到的比 val 小的数的最大值。找前驱的方法也是不断的在树上向下爬找具体节点,具体爬的方法可以参考代码注释部分。
int queryfr(int x, int val, int ans) {if (tree[x].val>=val){//如果当前值大于val,就说明查的数大了,所以要往左子树找if (tree[x].ls==0)//如果没有左子树就直接返回找到的ansreturn ans;else//如果不是的话,去查左子树return queryfr(tree[x].ls,val,ans);}else{//如果当前值小于val,就说明我们找比val小的了if (tree[x].rs==0)//如果没有右孩子,就返回tree[x].val,因为走到这一步时,我们后找到的一定比先找到的大(参考第二条性质)return (tree[x].val<val) ? tree[x].val : ans//如果有右孩子,,我们还要找这个节点的右子树,因为万一右子树有比当前节点还大并且小于要找的val的话,ans需要更新if (tree[x].cnt!=0)//如果当前节数的个数不为0,ans就可以更新为tree[x].valreturn queryfr(tree[x].rs,val,tree[x].val);else//反之ans不需要更新return queryfr(tree[x].rs,val,ans);}
}(3)找后继:与找前驱同理,只不过需要反过来。
int queryne(int x, int val, int ans) {if (tree[x].val<=val){if (tree[x].rs==0)return ans;elsereturn queryne(tree[x].rs,val,ans);}else{if (tree[x].ls==0)return (tree[x].val>val)? tree[x].val : ans;if (tree[x].cnt!=0)return queryne(tree[x].ls,val,tree[x].val);elsereturn queryne(tree[x].ls,val,ans);}
}(4)按值找排名:这里我们就要用到 siz 了,排名就是比这个值要小的数的个数再 +1,所以我们按值找排名,就可以看做找比这个值小的数的个数,最后加上 1 即可。
int queryval(int x,int val)
{if(x==0) return 0;//没有排名 if(val==tree[x].val) return tree[tree[x].ls].siz;//如果当前节点值=val,则我们加上现在比val小的数的个数,也就是它左子树的大小 if(val<tree[x].val) return queryval(tree[x].ls,val);//如果当前节点值比val大了,我们就去它的左子树找val,因为左子树的节点值一定是小的 return queryval(tree[x].rs,val)+tree[tree[x].ls].siz+tree[x].cnt;//如果当前节点值比val小了,我们就去它的右子树找val,同时加上左子树的大小和这个节点的值出现次数 //因为这个节点的值小于val,这个节点的左子树的各个节点的值一定也小于val
}
//注:这里最终返回的是排名-1,也就是比val小的数的个数,在输出的时候记得+1(5)按排名找值:排名为 n 的数在BST上是第 n 靠左的数。或者说排名为 n 的数的节点在BST中,它的左子树的 siz 与它的各个祖先的左子树的 siz 相加恰好 =n (这里相加是要减去重复部分)。
int queryrk(int x,int rk)
{if(x==0) return INF; if(tree[tree[x].ls].siz>=rk)//如果左子树大小>=rk了,就说明答案在左子树里 return queryrk(tree[x].ls,rk);//查左子树 if(tree[tree[x].ls].siz+tree[x].cnt>=rk)//如果左子树大小加上当前的数的多少恰好>=k,说明我们找到答案了 return tree[x].val;//直接返回权值 return queryrk(tree[x].rs,rk-tree[tree[x].ls].siz-tree[x].cnt);//否则就查右子树,同时减去当前节点的次数与左子树的大小
}AC代码:
#include <iostream>
#include <string>
#include <algorithm>
#include <cmath>
#include <vector>
#include <map>
#include <stack>
#include <set>using namespace std;
const int INF = 0x7fffffff;struct node
{int val; //节点值int left, right; //左右子树int cnt; //计数器int siz; //子树大小
}tree[100005];
int cont = 0;//记录节点数量//初始化
void init()
{for (int i = 0; i < 100005; i++){tree[i].val = 0;tree[i].left = 0;tree[i].right = 0;tree[i].cnt = 0;tree[i].siz = 0;}
}//添加新点
void add(int x, int value) //当前节点为x,需要插入value
{tree[x].siz++; //肯定在x子树上,规模加一if (tree[x].val == value) //如果value刚好等于节点值,计数器加一即可{tree[x].cnt++;return;}if (tree[x].val > value) //如果x的值大于value,value只能放在x的左子树上{if (tree[x].left != 0)//如果左子树上有节点,递归查找add(tree[x].left, value);else//如果左子树上没有点,直接添加{cont++;tree[cont].val = value;tree[cont].siz = tree[cont].cnt = 1;tree[x].left = cont;}}else if (tree[x].val < value)//如果x的值小于value,value要放到x的右子树上{if (tree[x].right != 0)//如果右子树上有节点,递归查找add(tree[x].right, value);else//如果右子树上没有点,直接添加{cont++;tree[cont].val = value;tree[cont].siz = tree[cont].cnt = 1;tree[x].right = cont;}}
}//查找前驱
int query_front(int x, int value, int ans) //x 是当前的节点的下标,val 是要找前驱的值,ans 是目前找到的比val小的数的最大值。
{if (cont == 0) return -INF;if (tree[x].val >= value)//当前节点val大于所查value,到左子树查找{if (tree[x].left == 0) //左子树不存在,那么前驱为ansreturn ans;elsereturn query_front(tree[x].left, value, ans); //否则遍历左子树}else{if (tree[x].right == 0)//若无右孩子,说明当前点满足条件return (tree[x].val < value) ? tree[x].val : ans;else{if (tree[x].cnt != 0) //如果当前节点的个数不为0,ans就可以更新为tree[x].valreturn query_front(tree[x].right, value, tree[x].val);elsereturn query_front(tree[x].right, value, ans);}}
}//查找后继
int query_next(int x, int value, int ans)
{if (cont == 0) return INF;if (tree[x].val <= value){if (tree[x].right == 0)return ans;elsereturn query_next(tree[x].right, value, ans);}else{if (tree[x].left == 0)return (tree[x].val > value) ? tree[x].val : ans;else{if (tree[x].cnt != 0)return query_next(tree[x].left, value, tree[x].val);elsereturn query_next(tree[x].left, value, ans);}}
}//按值找排名
int val_to_rank(int x, int value)
{if (x == 0) return 0;if (value == tree[x].val)return tree[tree[x].left].siz;//比它小的数if (value < tree[x].val)return val_to_rank(tree[x].left, value);if (value > tree[x].val)return val_to_rank(tree[x].right, value) + tree[tree[x].left].siz + tree[x].cnt;//左子树上的所有点加上根上的点都小于value
}//按排名找值
int rank_to_val(int x, int rank)
{if (x == 0)return INF;if (tree[tree[x].left].siz >= rank) //如果小于x.val的数多于rank,那么该值一定在左子树上,递归查找return rank_to_val(tree[x].left, rank);if (tree[tree[x].left].siz + tree[x].cnt >= rank) //如果左子树上的点数+根上的节点数大于rank,且左子树上的点数小于rank,那么点x的值为所需值return tree[x].val;return rank_to_val(tree[x].right, rank - tree[tree[x].left].siz - tree[x].cnt); //否则在右子树上,要先将左子树+根上的点数减去
}int main()
{int q; cin >> q;init();for (int i = 1; i <= q; i++){int op, v;cin >> op >> v;if (op == 1)cout << val_to_rank(1, v) + 1 << endl;else if (op == 2)cout << rank_to_val(1, v) << endl;else if (op == 3)cout << query_front(1, v, -INF) << endl;else if (op == 4)cout << query_next(1, v, INF) << endl;else{if (cont == 0){cont++;tree[cont].cnt = tree[cont].siz = 1;tree[cont].val = v;}elseadd(1, v);}}
}六、【P1364】医院设置(BFS广搜)
广度优先搜索(breadth-first search, BFS)不同与深度优先搜索,它是一层层进行遍历的,因此需要用先入先出的队列而非先入后出的栈进行遍历。由于是按层次进行遍历,广度优先搜索时按照“广”的方向进行遍历的,也常常用来处理最短路径等问题。
在本题中,由于每个点都可以是原点(树根),因此采用树结构存储是行不通的,因为指针只能单方向指向。这里采用邻接矩阵的方式来存储树。
AC代码:
本题中只考虑每个点到根节点的距离,因此采用DFS和BFS均可。
由于BFS操作起来更直观,因此本题用普通图的形式存储树,枚举每个节点为根节点的情况,进行n遍BFS,然后每遍都进行答案的比较更新。
#include <iostream>
#include <string>
#include <algorithm>
#include <cmath>
#include <vector>
#include <map>
#include <cstring>
#include <queue>using namespace std;
const int INF = 0x7fffffff;bool graph[105][105] = { 0 };
bool visit[105] = { 0 };
int value[105] = { 0 };struct node
{int num;int step; //用于存储某点到根节点的距离
};
int n;int BFS(int x) //以x为根对树进行BFS遍历
{memset(visit, 0, sizeof(visit)); queue<node> q;visit[x] = 1;node gen; gen.num = x, gen.step = 0;q.push(gen); //将树根节点入队int sum = 0;while (!q.empty()){node now = q.front();q.pop();for (int i = 1; i <= n; i++) //依次取出队列中的点,并找到与该点距离为1且未被访问过的点{if (graph[now.num][i] && !visit[i]){node next;next.num = i, next.step = now.step + 1; //更新选中点到根的距离visit[i] = 1;q.push(next);sum += value[i] * next.step; //该点的权重乘以与根的距离}}}return sum;
}int main()
{cin >> n;for (int i = 1; i <= n; i++){int w, u, v;cin >> w >> u >> v;value[i] = w;if (u != 0)graph[i][u] = graph[u][i] = 1;if (v != 0)graph[i][v] = graph[v][i] = 1;}int MinDis = INF;for (int i = 1; i <= n; i++){int tmp = BFS(i);if (tmp < MinDis)MinDis = tmp;}cout << MinDis << endl;
}
由于bfs每遍都是O(V+E)的,而这里特殊之处在于本身是个树,所以是n个节点和n-1条边
所以总复杂度近似为
.
七、【P3884】二叉树问题(Floyd算法)
树其实一种特殊的图。
即没有环路,一定联通,而且有且有只有一个节点没有入度的图。
- 树上任意两点间的距离可以直接通过最短路算法获得。
- 树的深度就是距离根节点最远的那个点的距离。
- 树的宽度是节点最多的一层,同一层的节点距离根节点的距离都是相同的,所以也可以直接枚举获得。
AC代码:
Floyd:使用邻接矩阵存储树,先将邻接矩阵的对角线位置初始化为0(某点到自己的距离为0),其他位置初始化为INT_MAX/4(不相连的节点理论上距离为无限大,但是在计算是要考虑可能发生的溢出情况,所以除以4)
三层嵌套循环,列举每两个点 i 和 j 之间的距离,并且要考虑有中继点 k 存在的情况下,两点间的距离。(由于树是无环图,所以只需要一个中继点即可覆盖所有情况)
#include <iostream>
#include <string>
#include <algorithm>
#include <cmath>
#include <vector>
#include <map>
#include <cstring>
#include <queue>using namespace std;
const int INF = 0x7fffffff / 4; //若直接为INT_MAX,则使用floyed时会发生溢出int a[105][105] = { 0 };
int b[10005] = { 0 };void init()
{for (int i = 0; i < 105; i++){for (int j = 0; j < 105; j++){if (i != j)a[i][j] = INF;}}
}int main()
{init();int n; cin >> n;for (int i = 1; i <= n - 1; i++){int u, v; cin >> u >> v;a[u][v] = 1;a[v][u] = 2;}for (int k = 1; k <= n; k++){for (int i = 1; i <= n; i++){for (int j = 1; j <= n; j++){a[i][j] = min(a[i][j], a[i][k] + a[k][j]);}}}int maxdepth = 0;for (int i = 1; i <= n; i++){if (maxdepth < a[1][i])maxdepth = a[1][i];b[a[1][i]]++;}int maxd = 0;for (int i = 1; i <= maxdepth; i++){maxd = max(maxd, b[i]);}int u, v;cin >> u >> v;cout << maxdepth + 1 << endl;cout << maxd << endl;cout << a[u][v] << endl;
}相关文章:
【数据结构1-2】二叉树
树形结构不仅能表示数据间的指向关系,还能表示出数据的层次关系,而有很明显的递归性质。因此,我们可以利用树的性质解决更多种类的问题。 但是在平常的使用中,我们并不需要使用这么复杂的结构,只需要建立一个包含int r…...
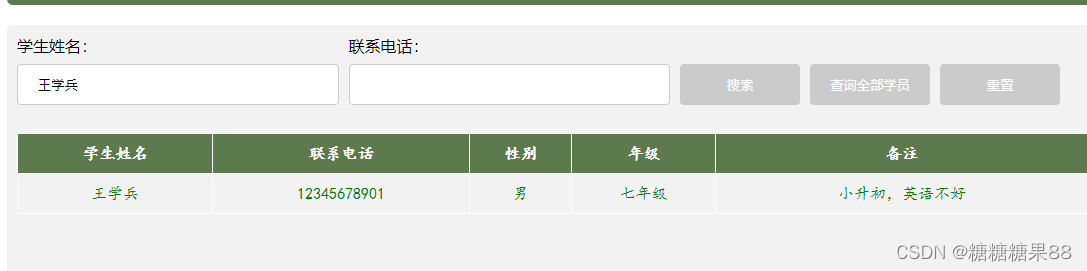
ajax点击搜索返回所需数据
html 中body设置(css设置跟进自身需求) <p idsearch_head>学生信息查询表</p> <div id"div_1"> <div class"search_div"> <div class"search_div_item"> …...

Redis6基础知识梳理~
初识NOSQL: NOSQL是为了解决性能问题而产生的技术,在最初,我们都是使用单体服务器架构,如下所示: 随着用户访问量大幅度提升,同时产生了大量的用户数据,单体服务器架构面对着巨大的压力 NOSQL解…...

在Python中如何使用集合进行元素操作
目录 1. 创建集合 2. 添加或删除元素 3. 集合运算 4. 其他集合操作 总结 在Python中,集合(set)是一种基本的数据结构,用于存储无序且唯一的元素。这意味着集合中的每个元素都是独一无二的,且集合不保持任何元素的…...
2024年阿里云幻兽帕鲁Palworld游戏服务器优惠价格表
自建幻兽帕鲁服务器租用价格表,2024阿里云推出专属幻兽帕鲁Palworld游戏优惠服务器,配置分为4核16G和4核32G服务器,4核16G配置32.25元/1个月、10M带宽66.30元/1个月、4核32G配置113.24元/1个月,4核32G配置3个月339.72元。ECS云服务…...
)
Atlassian Confluence Data Center and Server 权限提升漏洞复现(CVE-2023-22515)
0x01 产品简介 Atlassian Confluence是一款由Atlassian开发的企业团队协作和知识管理软件,提供了一个集中化的平台,用于创建、组织和共享团队的文档、知识库、项目计划和协作内容。是面向大型企业和组织的高可用性、可扩展性和高性能版本。 0x02 漏洞概述 Atlassian Confl…...
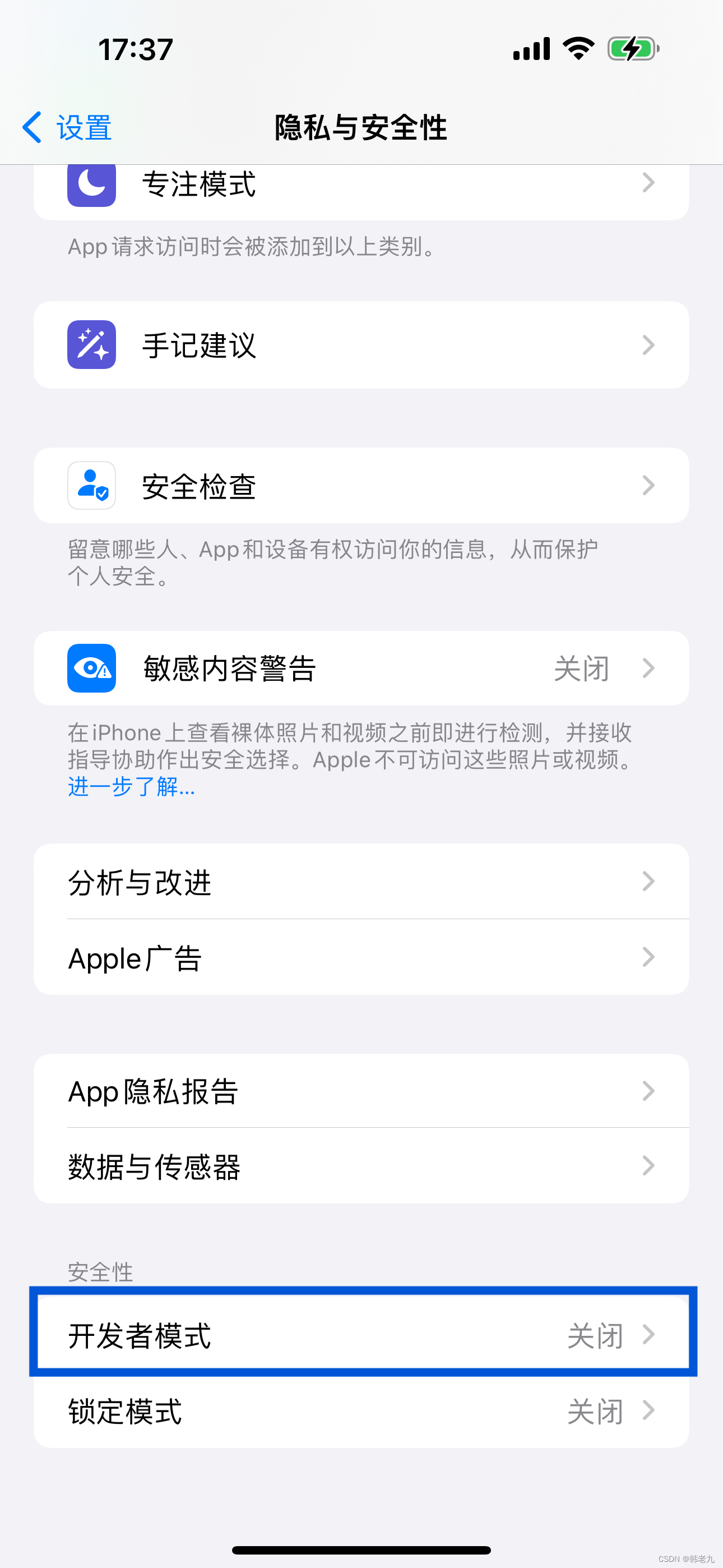
打开 IOS开发者模式
前言 需要 1、辅助设备:苹果电脑; 2、辅助应用:Xcode; 3、准备工作:苹果手机 使用数据线连接 苹果电脑; 当前系统版本 IOS 17.3 通过Xcode激活 两指同时点击 Xcode 显示选择,Open Develop…...

【C语言刷题系列】交换两个变量的三种方式
文章目录 1.使用临时变量(推荐) 2.相加和相减的方式(值较大时可能丢失数据) 3.按位异或运算 本文所属专栏C语言刷题_倔强的石头106的博客-CSDN博客 两个变量值的交换是编程中最常见的问题之一,以下将介绍三种变量的…...
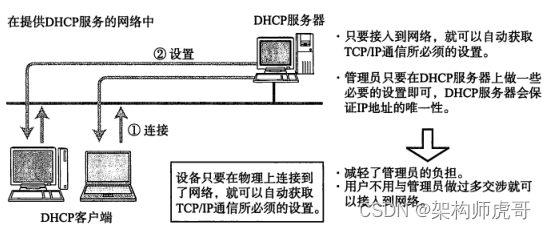
架构师之路(十五)计算机网络(网络层协议)
前置知识(了解):计算机基础。 作为架构师,我们所设计的系统很少为单机系统,因此有必要了解计算机和计算机之间是怎么联系的。局域网的集群和混合云的网络有啥区别。系统交互的时候网络会存在什么瓶颈。 ARP协议 地址解…...
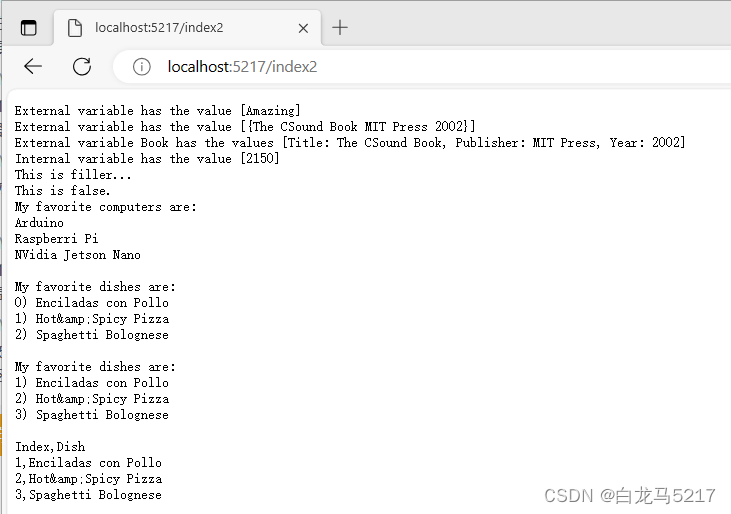
【JSON2WEB】03 go的模板包html/template的使用
Go text/template 是 Go 语言标准库中的一个模板引擎,用于生成文本输出。它使用类似于 HTML 的模板语言,可以将数据和模板结合起来,生成最终的文本输出。 Go html/template包实现了数据驱动的模板,用于生成可防止代码注入的安全的…...
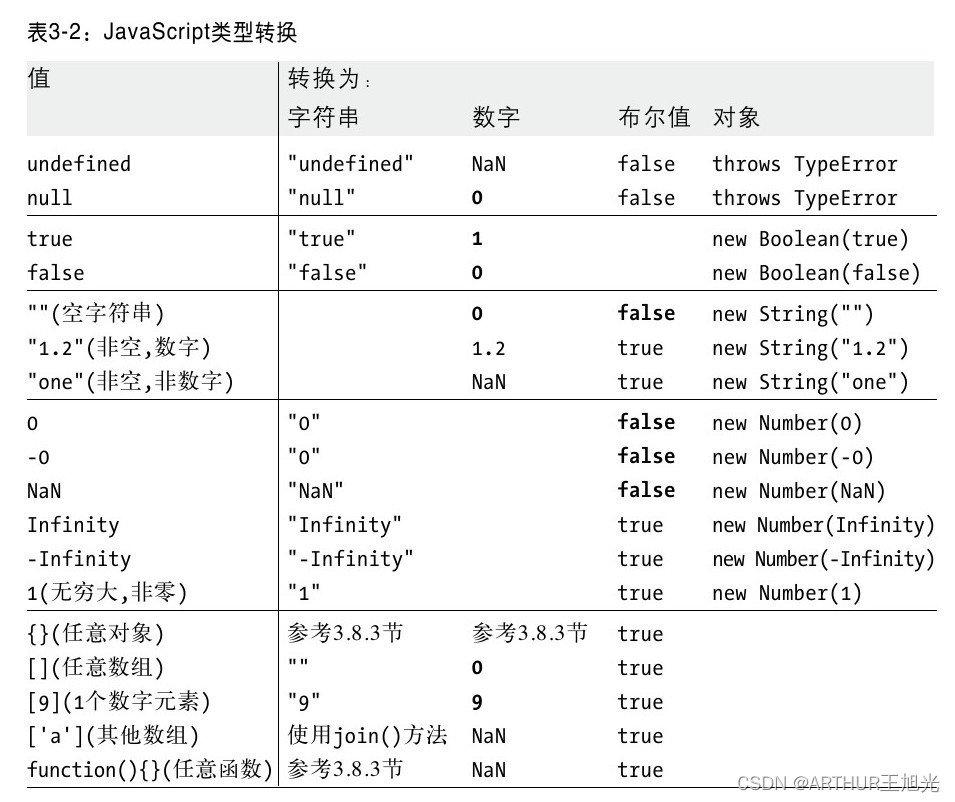
3 JS类型 值和变量
计算机对value进行操作。 value有不同的类型。每种语言都有其自身的类型集合。编程语言的类型集是该编程语言的基本特性。 value需要保存一个变量中。 变量的工作机制是变成语言的另一个基本特性。 3.1概述和定义 JS类型分为: 原始类型和对象类型。 原始类型&am…...

【Android】实现简易购物车功能(附源码)
先上结果: 代码: 首先引入图片加载: implementation com.github.bumptech.glide:glide:4.15.1配置权限清单: <!-- 网络权限 --><uses-permission android:name"android.permission.INTERNET"/><uses…...

使用Excel计算--任务完成总工作日时间段
(Owed by: 春夜喜雨 http://blog.csdn.net/chunyexiyu) 引言 计算任务完成时间周期,和计算金钱一样,是一个比较细致严谨的工作。 通常,我们可能以为,完成周期形如: 任务完成周期 任务结束时间 - 任务开始时间 但是…...

.NET高级面试指南专题一【委托和事件】
在C#中,委托(Delegate)和事件(Event)是两个重要的概念,它们通常用于实现事件驱动编程和回调机制。 委托定义: 委托是一个类,它定义了方法的类型,使得可以将方法当作另一个…...
基于springboot+vue的在线教育系统(前后端分离)
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战 主要内容:毕业设计(Javaweb项目|小程序等)、简历模板、学习资料、面试题库、技术咨询 文末联系获取 项目背景…...

54-函数的3种定义,函数的4种调用:函数模式调用,方法模式调用,构造函数模式调用,apply call bind调用
一.函数的3种定义 1.函数的声明定义:具有声明提升 <script>//函数声明定义function fn(){}</script> 2.函数的表达式定义 <script>//匿名式表达式var fn = function(){}//命名式表达式var fn1 = function a(){}</script> 3.构造函数定义 var 变量…...

[C#]winform部署yolov5实例分割模型onnx
【官方框架地址】 https://github.com/ultralytics/yolov5 【算法介绍】 YOLOv5实例分割是目标检测算法的一个变种,主要用于识别和分割图像中的多个物体。它是在YOLOv5的基础上,通过添加一个实例分割模块来实现的。 在实例分割中,算法不仅…...

C++核心编程:类和对象 笔记
4.类和对象 C面向对象的三大特性为:封装,继承,多态C认为万事万物都皆为对象,对象上有其属性和行为 例如: 人可以作为对象,属性有姓名、年龄、身高、体重...,行为有走、跑、跳、说话...车可以作为对象,属性有轮胎、方向盘、车灯…...
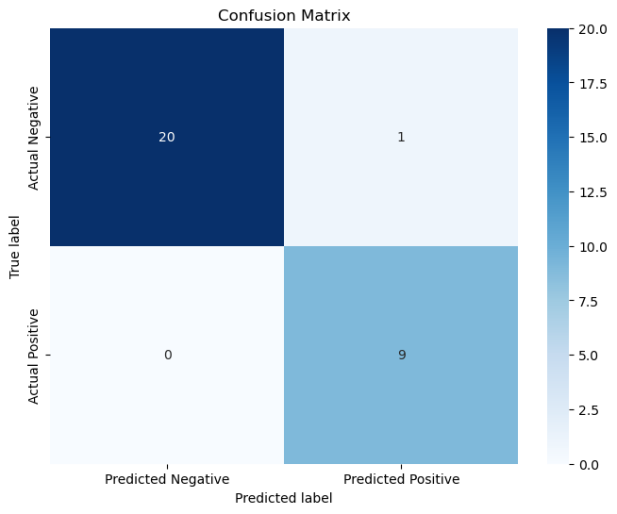
机器学习实验3——支持向量机分类鸢尾花
文章目录 🧡🧡实验内容🧡🧡🧡🧡数据预处理🧡🧡代码认识数据相关性分析径向可视化各个特征之间的关系图 🧡🧡支持向量机SVM求解🧡🧡直觉…...
:移除孤立的记录)
R语言【taxlist】——clean():移除孤立的记录
Package taxlist version 0.2.4 Description 对于 taxlist 类对象的操作可能会产生独立的条目。clean() 方法就是用来删除这样的条目,并恢复 taxlist 对象的一致性。 Usage clean(object, ...)## S4 method for signature taxlist clean(object, times 2, ...) A…...

Flutter GetX实战:从Provider迁移到GetX,我的开发效率提升了多少?
Flutter GetX实战:从Provider迁移到GetX的效率革命 当Flutter开发团队面临状态管理方案的选择时,往往会陷入一种甜蜜的烦恼——官方推荐的Provider虽然稳定可靠,但第三方库GetX却以"全家桶"式的解决方案不断吸引开发者的目光。作为…...

qmcdump:专业解决QQ音乐加密音频格式兼容性问题
qmcdump:专业解决QQ音乐加密音频格式兼容性问题 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 在数字音乐时…...

SyntaxUI:基于原子设计与Web组件的现代UI库开发实践
1. 项目概述:一个为开发者而生的现代UI组件库 如果你是一名前端开发者,或者正在构建一个需要用户界面的应用,那么你肯定经历过这样的场景:为了一个按钮的样式、一个表格的交互,或者一个模态框的动画,反复在…...

终极显卡调校指南:如何用NVIDIA Profile Inspector释放游戏性能
终极显卡调校指南:如何用NVIDIA Profile Inspector释放游戏性能 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector是一款专为NVIDIA显卡用户设计的免费优化工具&…...

期权交易基础框架:模块化设计与Python实现指南
1. 项目概述:一个为期权交易者打造的“乐高积木”底座如果你在量化交易或者期权策略开发领域摸爬滚打过一段时间,大概率会遇到一个共同的痛点:策略想法很多,但把它们变成可回测、可实盘、可管理的代码,却要耗费大量的“…...

Apache Burr:用状态机模式构建Python流式应用
1. 项目概述:一个用于构建流式应用的Python框架最近在折腾一些实时数据处理和模型推理的项目,从简单的日志分析到复杂的在线推荐,总感觉现有的工具链要么太重,要么太散。想要一个既能处理流式数据,又能轻松集成机器学习…...

LLM应用快速演示框架:从架构解析到智能体开发的实战指南
1. 项目概述:一个面向开发者的LLM应用快速演示框架最近在GitHub上闲逛,发现了一个名为wronai/llm-demo的项目,点进去一看,瞬间觉得眼前一亮。这可不是又一个简单的“Hello World”式的大语言模型调用示例,而是一个结构…...

开源AI图像生成工具Dream-Creator:本地部署与Stable Diffusion实战指南
1. 项目概述:一个开源的AI图像生成与创作工具 最近在GitHub上闲逛,发现了一个挺有意思的项目叫“Dream-Creator”。光看名字,你可能会联想到一些AI绘画或者创意生成工具。没错,这确实是一个围绕AI图像生成的开源项目。作为一个在…...

Git安全增强实战:使用Ante实现策略即代码的版本控制防护
1. 项目概述:一个为开发者打造的“代码保险箱”如果你和我一样,在职业生涯中经历过几次“代码灾难”——比如不小心git push -f覆盖了同事的提交,或者手滑rm -rf删除了一个正在开发中的功能分支——那你一定会对“代码安全”这四个字有切肤之…...

基于Nginx-Lua镜像构建高性能可编程网关的实践指南
1. 项目概述:一个为现代Web架构而生的Nginx镜像如果你和我一样,长期在容器化环境中部署和管理Web服务,那么你一定对Nginx的灵活性和Lua脚本的强大能力印象深刻。但将这两者结合,并打包成一个稳定、安全、功能齐全的Docker镜像&…...