【大数据】详解 Flink 中的 WaterMark
详解 Flink 中的 WaterMark
- 1.基础概念
- 1.1 流处理
- 1.2 乱序
- 1.3 窗口及其生命周期
- 1.4 Keyed vs Non-Keyed
- 1.5 Flink 中的时间
- 2.Watermark
- 2.1 案例一
- 2.2 案例二
- 2.3 如何设置最大乱序时间
- 2.4 延迟数据重定向
- 3.在 DDL 中的定义
- 3.1 事件时间
- 3.2 处理时间
1.基础概念
1.1 流处理
流处理,最本质的是在处理数据的时候,接受一条处理一条数据。
批处理,则是累积数据到一定程度在处理。这是他们本质的区别。
在设计上 Flink 认为数据是流式的,批处理只是流处理的特例。同时对数据分为有界数据和无界数据。
- 有界数据对应批处理,API 对应
DateSet。 - 无界数据对应流处理,API 对应
DataStream。
1.2 乱序
什么是乱序呢?
可以理解为数据到达的顺序和其实际产生时间的排序不一致。导致这的原因有很多,比如延迟,消息积压,重试等等。
我们知道,流处理从事件产生,到流经 source,再到 operator,中间是有一个过程和时间的。虽然大部分情况下,流到 operator 的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络、背压等原因,导致乱序的产生(out-of-order 或者说 late element)。
✅ 某数据源中的某些数据由于某种原因(如:网络原因,外部存储自身原因)会有 5 秒的延时,也就是在实际时间的第 1 秒产生的数据有可能在第 5 秒中产生的数据之后到来(比如到 Window 处理节点)。例如,有 1 ~ 10 个事件,乱序到达的序列是:2, 3, 4, 5, 1, 6, 3, 8, 9, 10, 7。
1.3 窗口及其生命周期
对于 Flink,如果来一条消息计算一条,这样是可以的,但是这样计算是非常频繁而且消耗资源,如果想做一些统计这是不可能的。所以对于 Spark 和 Flink 都产生了窗口计算。
比如,因为我们想看到过去一分钟或过去半小时的访问数据,这时候我们就需要窗口。
- Window:Window 是处理无界流的关键,Window 将流拆分为一个个有限大小的
buckets,可以在每一个buckets中进行计算。 - 当 Window 是时间窗口的时候,每个 Window 都会有一个开始时间(
start_time)和结束时间(end_time)(左闭右开),这个时间是系统时间。
简而言之,只要属于此窗口的第一个元素到达,就会创建一个窗口,当时间(事件或处理时间)超过其结束时间戳加上用户指定的允许延迟时,窗口将被完全删除。
窗口有如下组件:
Window Assigner:用来决定某个元素被分配到哪个或哪些窗口中去。Trigger:触发器。决定了一个窗口何时能够被计算或清除。触发策略可能类似于 “当窗口中的元素数量大于 4” 时,或 “当水位线通过窗口结束时”。Evictor:驱逐器。Evictor 提供了在使用 WindowFunction 之前或者之后从窗口中删除元素的能力。
窗口还拥有函数,比如 ProcessWindowFunction,ReduceFunction,AggregateFunction 或 FoldFunction。该函数将包含要应用于窗口内容的计算,而触发器指定窗口被认为准备好应用该函数的条件。
1.4 Keyed vs Non-Keyed
在定义窗口之前,要指定的第一件事是流是否需要 Keyed,使用 keyBy(...) 将无界流分成逻辑的 keyed stream。如果未调用 keyBy(...),则表示流不是 keyed stream。
- 对于 Keyed 流,可以将传入事件的任何属性用作 key。拥有
keyed stream将允许窗口计算由多个任务并行执行,因为每个逻辑 Keyed 流可以独立于其余任务进行处理。相同 Key 的所有元素将被发送到同一个任务。 - 在 Non-Keyed 流的情况下,原始流将不会被分成多个逻辑流,并且所有窗口逻辑将由单个任务执行,即并行性为 1。
1.5 Flink 中的时间
Flink 在流处理程序支持不同的时间概念。分别为是 事件时间(Event Time)、处理时间(Processing Time)、提取时间(Ingestion Time)。
从时间序列角度来说,发生的先后顺序是:事件时间 ▶ 提取时间 ▶ 处理时间。
Event Time是事件在现实世界中发生的时间,它通常由事件中的时间戳描述。Ingestion Time是数据进入 Apache Flink 流处理系统的时间,也就是 Flink 读取数据源时间。Processing Time是数据流入到具体某个算子 (消息被计算处理) 时候相应的系统时间。也就是 Flink 程序处理该事件时当前系统时间。
2.Watermark
Watermark 是 Apache Flink 为了处理 EventTime 窗口计算提出的一种机制,本质上也是一种时间戳。Watermark 是用于处理乱序事件或延迟数据的,这通常用 Watermark 机制结合 Window 来实现(Watermarks 用来触发 Window 窗口计算)。
2.1 案例一
public class BoundedOutOfOrdernessGenerator implements AssignerWithPeriodicWatermarks<MyEvent> {private final long maxOutOfOrderness = 3000; // 3.0 secondsprivate long currentMaxTimestamp;@Overridepublic long extractTimestamp(MyEvent element, long previousElementTimestamp) {long timestamp = element.getCreationTime();currentMaxTimestamp = Math.max(timestamp, currentMaxTimestamp);return timestamp;}@Overridepublic Watermark getCurrentWatermark() {// return the watermark as current highest timestamp minus the out-of-orderness bound// 生成 watermarkreturn new Watermark(currentMaxTimestamp - maxOutOfOrderness);}
}

上图中是一个 10s 大小的窗口,10000~ 20000 为一个窗口。当 EventTime 为 23000 的数据到来,生成的 WaterMark 的时间戳为 20000,大于等于 window_end_time,会触发窗口计算。
2.2 案例二
public class TimeLagWatermarkGenerator implements AssignerWithPeriodicWatermarks<MyEvent> {private final long maxTimeLag = 3000; // 3 seconds@Overridepublic long extractTimestamp(MyEvent element, long previousElementTimestamp) {return element.getCreationTime();}@Overridepublic Watermark getCurrentWatermark() {// return the watermark as current time minus the maximum time lagreturn new Watermark(System.currentTimeMillis() - maxTimeLag);}
}

只是简单的用当前系统时间减去最大延迟时间生成 Watermark ,当 WaterMark 为 20000 时,大于等于窗口的结束时间,会触发 10000 ~ 20000 窗口计算。再当 EventTime 为 19500 的数据到来,它本应该是属于窗口 10000 ~ 20000 窗口的,但这个窗口已经触发计算了,所以此数据会被丢弃。
2.3 如何设置最大乱序时间
虽说水位线表明着早于它的事件不应该再出现,接收到水位线以前的的消息是不可避免的,这就是所谓的 迟到事件。实际上迟到事件是乱序事件的特例,和一般乱序事件不同的是它们的乱序程度超出了水位线的预计,导致窗口在它们到达之前已经关闭。
迟到事件出现时窗口已经关闭并产出了计算结果,因此处理的方法有 3 种:
- 重新激活已经关闭的窗口并重新计算以修正结果。将迟到事件收集起来另外处理。将迟到事件视为错误消息并丢弃。Flink 默认的处理方式是直接丢弃,其他两种方式分别使用
Side Output和Allowed Lateness。 - Side Output 机制 可以将迟到事件单独放入一个数据流分支,这会作为 Window 计算结果的副产品,以便用户获取并对其进行特殊处理。
- Allowed Lateness 机制 允许用户设置一个允许的最大迟到时长。Flink 会在窗口关闭后一直保存窗口的状态直至超过允许迟到时长,这期间迟到的事件不会被丢弃,而是默认会触发窗口重新计算。因为保存窗口状态需要额外内存,并且如果窗口计算使用了
ProcessWindowFunction API还可能使得每个迟到事件触发一次窗口的全量计算,代价比较大,所以允许迟到时长不宜设得太长,迟到事件也不宜过多,否则应该考虑降低水位线提高的速度或者调整算法。
这里总结机制为:
- 窗口 Window 的作用是为了周期性的获取数据。
- WaterMark 的作用是防止数据出现乱序(经常),事件时间内获取不到指定的全部数据,而做的一种保险方法。
allowLateNess是将窗口关闭时间再延迟一段时间。sideOutPut是最后兜底操作,所有过期延迟数据,指定窗口已经彻底关闭了,就会把数据放到侧输出流。
public class TumblingEventWindowExample {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);env.setParallelism(1);
// env.getConfig().setAutoWatermarkInterval(100);DataStream<String> socketStream = env.socketTextStream("localhost", 9999);DataStream<Tuple2<String, Long>> resultStream = socketStream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<String>(Time.seconds(3)) {@Overridepublic long extractTimestamp(String element) {long eventTime = Long.parseLong(element.split(" ")[0]);System.out.println(eventTime);return eventTime;}}).map(new MapFunction<String, Tuple2<String, Long>>() {@Overridepublic Tuple2<String, Long> map(String value) throws Exception {return Tuple2.of(value.split(" ")[1], 1L);}}).keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(10))).allowedLateness(Time.seconds(2)) // 允许延迟处理2秒.reduce(new ReduceFunction<Tuple2<String, Long>>() {@Overridepublic Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception {return new Tuple2<>(value1.f0, value1.f1 + value2.f1);}});resultStream.print();env.execute();}
}

当 watermark 为 21000 时,触发了 [10000, 20000) 窗口计算,由于设置了 allowedLateness(Time.seconds(2)),即允许两秒延迟处理,watermark < window_end_time + lateTime 公式得到满足,因此随后 10000 和 12000 进入窗口时,依然能触发窗口计算;随后 watermark 增加到 22000,watermark < window_end_time + lateTime 不再满足,因此 11000 再次进入窗口时,窗口不再进行计算。
2.4 延迟数据重定向
流的返回值必须是 SingleOutputStreamOperator,其是 DataStream 的子类。通过 getSideOutput 方法获取延迟数据。可以将延迟数据重定向到其他流或者进行输出。
public class TumblingEventWindowExample {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);env.setParallelism(1);DataStream<String> socketStream = env.socketTextStream("localhost", 9999);//保存被丢弃的数据OutputTag<Tuple2<String, Long>> outputTag = new OutputTag<Tuple2<String, Long>>("late-data"){};//注意,由于getSideOutput方法是SingleOutputStreamOperator子类中的特有方法,所以这里的类型,不能使用它的父类dataStream。SingleOutputStreamOperator<Tuple2<String, Long>> resultStream = socketStream// Time.seconds(3)有序的情况修改为0.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<String>(Time.seconds(3)) {@Overridepublic long extractTimestamp(String element) {long eventTime = Long.parseLong(element.split(" ")[0]);System.out.println(eventTime);return eventTime;}}).map(new MapFunction<String, Tuple2<String, Long>>() {@Overridepublic Tuple2<String, Long> map(String value) throws Exception {return Tuple2.of(value.split(" ")[1], 1L);}}).keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(10))).sideOutputLateData(outputTag) // 收集延迟大于2s的数据.allowedLateness(Time.seconds(2)) //允许2s延迟.reduce(new ReduceFunction<Tuple2<String, Long>>() {@Overridepublic Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception {return new Tuple2<>(value1.f0, value1.f1 + value2.f1);}});resultStream.print();//把迟到的数据暂时打印到控制台,实际中可以保存到其他存储介质中DataStream<Tuple2<String, Long>> sideOutput = resultStream.getSideOutput(outputTag);sideOutput.print();env.execute();}
}
3.在 DDL 中的定义
3.1 事件时间
事件时间属性是通过 CREATE TABLE DDL 语句中的 WATERMARK 语句定义的。水印语句在现有事件时间字段上定义 水印生成表达式,将事件时间字段标记为事件时间属性。
Flink SQL 支持在 TIMESTAMP 和 TIMESTAMP_LTZ 列上定义事件时间属性。如果源中的时间戳数据以 年-月-日-时-分-秒 表示,通常是不含时区信息的字符串值,例如 2020-04-15 20:13:40.564,建议将事件-时间属性定义为 TIMESTAMP 列。
CREATE TABLE user_actions (user_name STRING,data STRING,user_action_time TIMESTAMP(3),-- Declare the user_action_time column as an event-time attribute-- and use a 5-seconds-delayed watermark strategy.WATERMARK FOR user_action_time AS user_action_time - INTERVAL '5' SECOND
) WITH (...
);SELECT TUMBLE_START(user_action_time, INTERVAL '10' MINUTE), COUNT(DISTINCT user_name)
FROM user_actions
GROUP BY TUMBLE(user_action_time, INTERVAL '10' MINUTE);
如果数据源中的时间戳数据以纪元时间表示,通常是一个长值,例如 1618989564564,建议将事件时间属性定义为 TIMESTAMP_LTZ 列。
CREATE TABLE user_actions (user_name STRING,data STRING,ts BIGINT,time_ltz AS TO_TIMESTAMP_LTZ(ts, 3),-- Declare the time_ltz column as an event-time attribute-- and use a 5-seconds-delayed watermark strategy.WATERMARK FOR time_ltz AS time_ltz - INTERVAL '5' SECOND
) WITH (...
);SELECT TUMBLE_START(time_ltz, INTERVAL '10' MINUTE), COUNT(DISTINCT user_name)
FROM user_actions
GROUP BY TUMBLE(time_ltz, INTERVAL '10' MINUTE);
3.2 处理时间
处理时间能让表格程序根据本地机器的时间产生结果。这是最简单的时间概念,但会产生非确定性结果。处理时间不需要提取时间戳或生成水印。
在 CREATE TABLE DDL 语句中,使用系统 PROCTIME() 函数将处理时间属性定义为计算列。函数返回类型为 TIMESTAMP_LTZ。
CREATE TABLE user_actions (user_name STRING,data STRING,-- Declare an additional field as a processing-time attribute.user_action_time AS PROCTIME()
) WITH (...
);SELECT TUMBLE_START(user_action_time, INTERVAL '10' MINUTE), COUNT(DISTINCT user_name)
FROM user_actions
GROUP BY TUMBLE(user_action_time, INTERVAL '10' MINUTE);
相关文章:
【大数据】详解 Flink 中的 WaterMark
详解 Flink 中的 WaterMark 1.基础概念1.1 流处理1.2 乱序1.3 窗口及其生命周期1.4 Keyed vs Non-Keyed1.5 Flink 中的时间 2.Watermark2.1 案例一2.2 案例二2.3 如何设置最大乱序时间2.4 延迟数据重定向 3.在 DDL 中的定义3.1 事件时间3.2 处理时间 1.基础概念 1.1 流处理 流…...
【数据结构1-2】二叉树
树形结构不仅能表示数据间的指向关系,还能表示出数据的层次关系,而有很明显的递归性质。因此,我们可以利用树的性质解决更多种类的问题。 但是在平常的使用中,我们并不需要使用这么复杂的结构,只需要建立一个包含int r…...
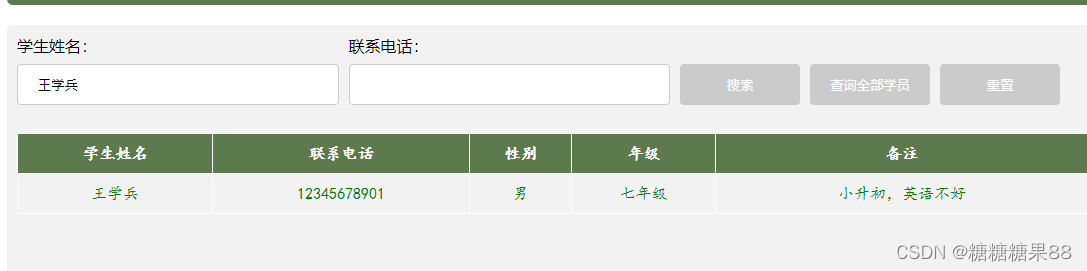
ajax点击搜索返回所需数据
html 中body设置(css设置跟进自身需求) <p idsearch_head>学生信息查询表</p> <div id"div_1"> <div class"search_div"> <div class"search_div_item"> …...

Redis6基础知识梳理~
初识NOSQL: NOSQL是为了解决性能问题而产生的技术,在最初,我们都是使用单体服务器架构,如下所示: 随着用户访问量大幅度提升,同时产生了大量的用户数据,单体服务器架构面对着巨大的压力 NOSQL解…...

在Python中如何使用集合进行元素操作
目录 1. 创建集合 2. 添加或删除元素 3. 集合运算 4. 其他集合操作 总结 在Python中,集合(set)是一种基本的数据结构,用于存储无序且唯一的元素。这意味着集合中的每个元素都是独一无二的,且集合不保持任何元素的…...
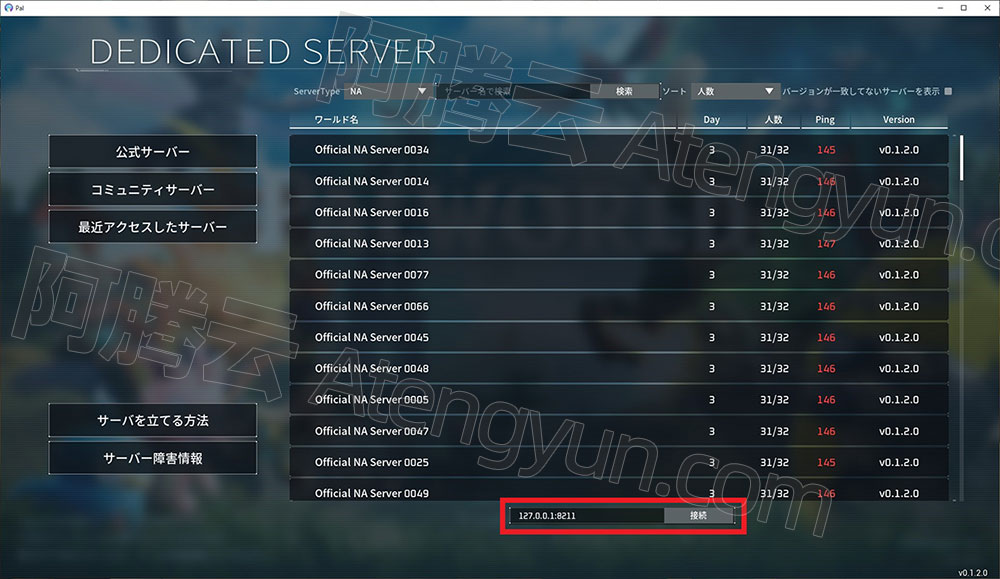
2024年阿里云幻兽帕鲁Palworld游戏服务器优惠价格表
自建幻兽帕鲁服务器租用价格表,2024阿里云推出专属幻兽帕鲁Palworld游戏优惠服务器,配置分为4核16G和4核32G服务器,4核16G配置32.25元/1个月、10M带宽66.30元/1个月、4核32G配置113.24元/1个月,4核32G配置3个月339.72元。ECS云服务…...
)
Atlassian Confluence Data Center and Server 权限提升漏洞复现(CVE-2023-22515)
0x01 产品简介 Atlassian Confluence是一款由Atlassian开发的企业团队协作和知识管理软件,提供了一个集中化的平台,用于创建、组织和共享团队的文档、知识库、项目计划和协作内容。是面向大型企业和组织的高可用性、可扩展性和高性能版本。 0x02 漏洞概述 Atlassian Confl…...
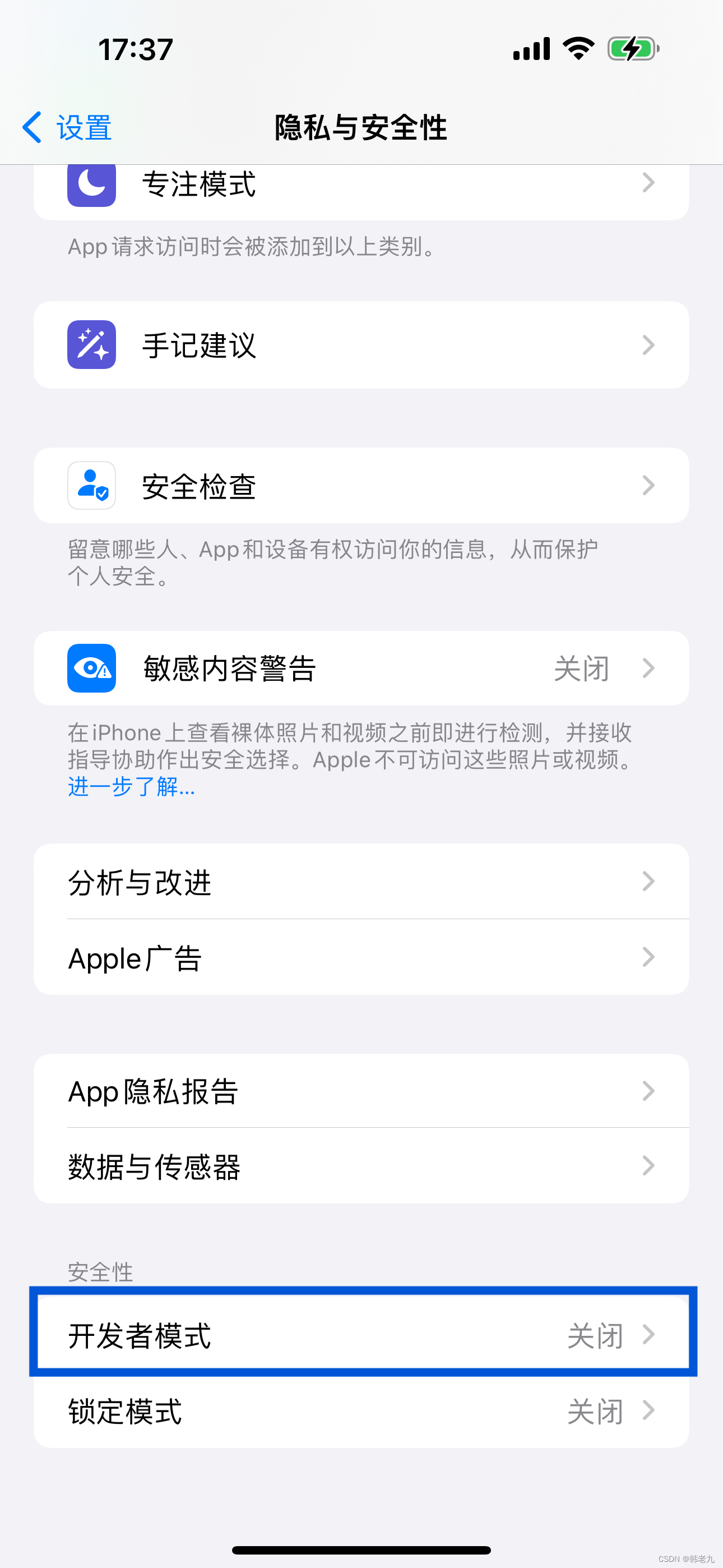
打开 IOS开发者模式
前言 需要 1、辅助设备:苹果电脑; 2、辅助应用:Xcode; 3、准备工作:苹果手机 使用数据线连接 苹果电脑; 当前系统版本 IOS 17.3 通过Xcode激活 两指同时点击 Xcode 显示选择,Open Develop…...

【C语言刷题系列】交换两个变量的三种方式
文章目录 1.使用临时变量(推荐) 2.相加和相减的方式(值较大时可能丢失数据) 3.按位异或运算 本文所属专栏C语言刷题_倔强的石头106的博客-CSDN博客 两个变量值的交换是编程中最常见的问题之一,以下将介绍三种变量的…...
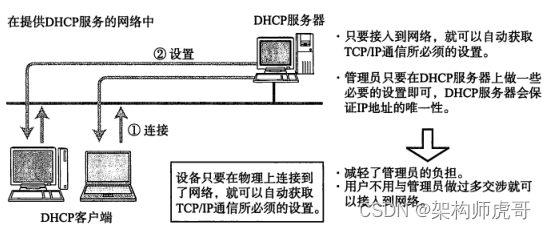
架构师之路(十五)计算机网络(网络层协议)
前置知识(了解):计算机基础。 作为架构师,我们所设计的系统很少为单机系统,因此有必要了解计算机和计算机之间是怎么联系的。局域网的集群和混合云的网络有啥区别。系统交互的时候网络会存在什么瓶颈。 ARP协议 地址解…...
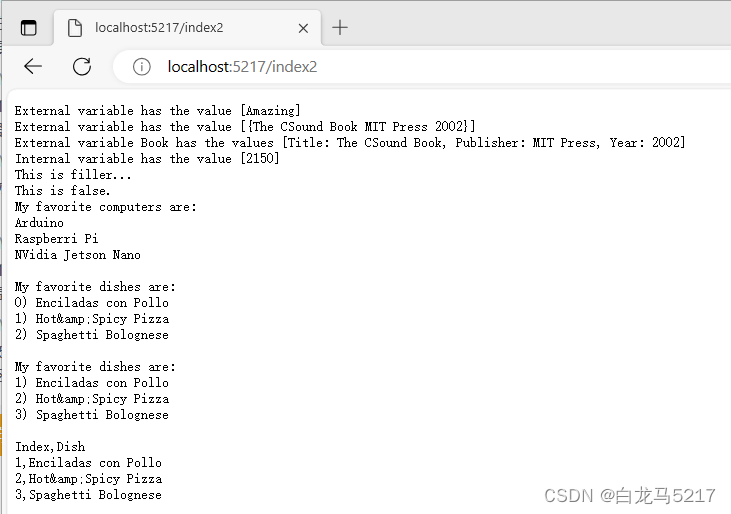
【JSON2WEB】03 go的模板包html/template的使用
Go text/template 是 Go 语言标准库中的一个模板引擎,用于生成文本输出。它使用类似于 HTML 的模板语言,可以将数据和模板结合起来,生成最终的文本输出。 Go html/template包实现了数据驱动的模板,用于生成可防止代码注入的安全的…...
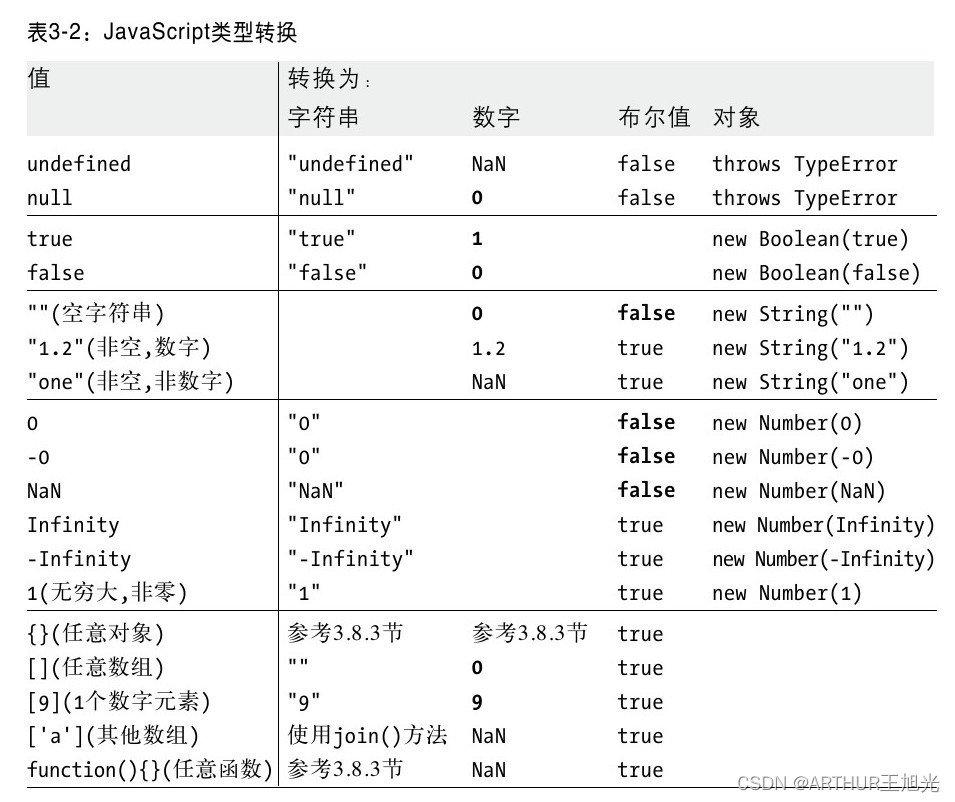
3 JS类型 值和变量
计算机对value进行操作。 value有不同的类型。每种语言都有其自身的类型集合。编程语言的类型集是该编程语言的基本特性。 value需要保存一个变量中。 变量的工作机制是变成语言的另一个基本特性。 3.1概述和定义 JS类型分为: 原始类型和对象类型。 原始类型&am…...

【Android】实现简易购物车功能(附源码)
先上结果: 代码: 首先引入图片加载: implementation com.github.bumptech.glide:glide:4.15.1配置权限清单: <!-- 网络权限 --><uses-permission android:name"android.permission.INTERNET"/><uses…...

使用Excel计算--任务完成总工作日时间段
(Owed by: 春夜喜雨 http://blog.csdn.net/chunyexiyu) 引言 计算任务完成时间周期,和计算金钱一样,是一个比较细致严谨的工作。 通常,我们可能以为,完成周期形如: 任务完成周期 任务结束时间 - 任务开始时间 但是…...

.NET高级面试指南专题一【委托和事件】
在C#中,委托(Delegate)和事件(Event)是两个重要的概念,它们通常用于实现事件驱动编程和回调机制。 委托定义: 委托是一个类,它定义了方法的类型,使得可以将方法当作另一个…...
基于springboot+vue的在线教育系统(前后端分离)
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战 主要内容:毕业设计(Javaweb项目|小程序等)、简历模板、学习资料、面试题库、技术咨询 文末联系获取 项目背景…...

54-函数的3种定义,函数的4种调用:函数模式调用,方法模式调用,构造函数模式调用,apply call bind调用
一.函数的3种定义 1.函数的声明定义:具有声明提升 <script>//函数声明定义function fn(){}</script> 2.函数的表达式定义 <script>//匿名式表达式var fn = function(){}//命名式表达式var fn1 = function a(){}</script> 3.构造函数定义 var 变量…...

[C#]winform部署yolov5实例分割模型onnx
【官方框架地址】 https://github.com/ultralytics/yolov5 【算法介绍】 YOLOv5实例分割是目标检测算法的一个变种,主要用于识别和分割图像中的多个物体。它是在YOLOv5的基础上,通过添加一个实例分割模块来实现的。 在实例分割中,算法不仅…...

C++核心编程:类和对象 笔记
4.类和对象 C面向对象的三大特性为:封装,继承,多态C认为万事万物都皆为对象,对象上有其属性和行为 例如: 人可以作为对象,属性有姓名、年龄、身高、体重...,行为有走、跑、跳、说话...车可以作为对象,属性有轮胎、方向盘、车灯…...
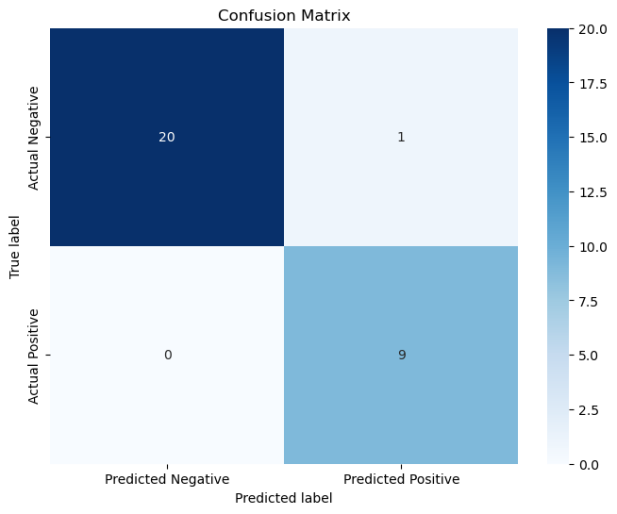
机器学习实验3——支持向量机分类鸢尾花
文章目录 🧡🧡实验内容🧡🧡🧡🧡数据预处理🧡🧡代码认识数据相关性分析径向可视化各个特征之间的关系图 🧡🧡支持向量机SVM求解🧡🧡直觉…...

终极指南:如何使用Autoclick实现Mac自动点击900次/秒
终极指南:如何使用Autoclick实现Mac自动点击900次/秒 【免费下载链接】Autoclick A simple Mac app that simulates mouse clicks 项目地址: https://gitcode.com/gh_mirrors/au/Autoclick 你是否厌倦了重复性的鼠标点击工作?无论是游戏中的重复操…...

基于AI智能体的渗透测试框架:从自动化到智能协同的范式转变
1. 项目概述:一个面向渗透测试的智能体框架最近在整理自己的工具链时,发现了一个挺有意思的项目,叫GH05TCREW/pentestagent。乍一看这个名字,你可能会觉得这又是一个“缝合怪”式的自动化渗透工具,把Nmap、SQLmap之类的…...

荣品RV1126 SDK编译避坑指南:从环境配置到分区调整,手把手解决常见编译错误
RV1126 SDK编译实战:从环境搭建到分区优化的全流程解决方案 1. 开发环境配置与初始化 RV1126开发环境的搭建是整个开发流程的第一步,也是后续所有工作的基础。一个稳定、高效的开发环境能够显著提升开发效率,减少不必要的错误。 首先需要确保…...

LVGL在无显存TFT屏上的驱动适配:双缓冲与DMA优化实践
1. 项目概述:当TFT屏幕遇上LVGL最近在做一个嵌入式GUI项目,核心任务是把LVGL这个轻量级图形库,适配到一块分辨率不算高但接口比较“个性”的TFT屏幕上。这活儿听起来像是把标准插头插到非标插座上,得自己动手改改线序。LVGL这几年…...

【2026最新】鸿蒙NEXT ArkUI实战:培训班管理系统UI界面开发全攻略
鸿蒙UI开发总是踩坑?ArkUI组件用法记不住?本文用15分钟带你彻底搞懂ArkUI核心组件、布局系统、自定义组件和交互动画,附完整培训班管理系统实战代码和踩坑记录,让你的鸿蒙App界面从此丝滑流畅!一、培训班管理界面设计1…...

基于Kubernetes Lease构建分布式部署锁:解决CI/CD环境下的资源竞争
1. 项目概述:从“clawfight”看一场被遗忘的社区技术博弈看到“2019-02-18/clawfight”这个标题,很多人的第一反应可能是困惑。它不像一个标准的软件项目名,没有清晰的版本号,也没有指明具体的技术栈。但恰恰是这种看似随意的命名…...
架构与实现)
基于RAG与向量数据库的智能信息管理系统(IIMS)架构与实现
1. 项目概述:当AI成为你的“第二大脑”最近在折腾一个挺有意思的项目,叫“IIMS-By-AI”。乍一看这个标题,可能有点摸不着头脑,但拆解一下就能明白它的野心:IntelligentInformationManagementSystem, By AI。…...

AXI Crossbar设计解析:从总线互联原理到SoC集成实战
1. 项目概述:AXI Crossbar,不仅仅是“总线交叉开关”在复杂的数字系统设计,尤其是SoC(片上系统)和FPGA应用中,我们常常面临一个核心问题:多个主设备(Master,如CPU、DMA控…...

RL78/G13单片机实现流水呼吸灯:软件PWM与状态机编程实践
1. 项目概述与核心思路最近在整理手头的瑞萨RL78/G13开发板,想着做点有意思的小项目来熟悉一下这款MCU的GPIO操作和定时器资源。呼吸灯和流水灯算是嵌入式开发的“Hello World”了,但把两者结合起来,做成一个“流水呼吸灯”,既有动…...

Harness 中的请求标识染色:端到端追踪
1. 标题选项(核心关键词:Harness、请求标识染色、端到端追踪、可观测性、CI/CD) 「Harness 可观测性实战:请求标识染色实现全链路端到端追踪」 「从0到1搞定Harness请求染色:让微服务调用链路+变更链路无所遁形」 「告别排查黑洞:Harness请求标识染色的端到端追踪落地指南…...