第3章-python深度学习——(波斯美女)
第3章 神经网络入门
本章的目的是让你开始用神经网络来解决实际问题。你将进一步巩固在第 2 章第一个示例中学到的知识,还会将学到的知识应用于三个新问题,这三个问题涵盖神经网络最常见的三种使用场景:二分类问题、多分类问题和标量回归问题。
本章将进一步介绍神经网络的核心组件,即层、网络、目标函数和优化器;还会简要介绍Keras,它是贯穿本书的 Python 深度学习库。你还将建立深度学习工作站,安装好 TensorFlow和Keras,并支持GPU。
最后,我们将用三个介绍性示例深入讲解如何使用神经网络解决实际问题,这三个示例分别是:
学完本章,你将能够使用神经网络解决简单的机器问题,比如对向量数据的分类问题和回归问题。然后,你就可以从第 4 章开始建立对机器学习更加具有原则性、理论性的理解。
3.1 神经网络剖析
前面几章介绍过,训练神经网络主要围绕以下四个方面。
你可以将这四者的关系可视化,如图 3-1 所示:多个层链接在一起组成了网络,将输入数据映射为预测值。然后损失函数将这些预测值与目标进行比较,得到损失值,用于衡量网络预测值与预期结果的匹配程度。优化器使用这个损失值来更新网络的权重。

我们来进一步研究层、网络、损失函数和优化器。
3.1.1 层:深度学习的基础组件
我们在第 2 章中介绍过,神经网络的基本数据结构是层。层是一个数据处理模块,将一个或多个输入张量转换为一个或多个输出张量。有些层是无状态的,但大多数的层是有状态的,即层的权重。权重是利用随机梯度下降学到的一个或多个张量,其中包含网络的知识。
不同的张量格式与不同的数据处理类型需要用到不同的层。
例如,
(1)简单的向量数据保存在形状为 (samples, features) 的 2D 张量中,通常用密集连接层[densely connected layer,也叫全连接层(fully connected layer)或密集层(dense layer),对应于 Keras 的 Dense 类]来处理。
(2)序列数据保存在形状为 (samples, timesteps, features) 的 3D 张量中,通常用循环层(recurrent layer,比如 Keras 的 LSTM 层)来处理。
(3)图像数据保存在 4D 张量中,通常用二维卷积层(Keras 的 Conv2D)来处理。
你可以将层看作深度学习的乐高积木,Keras 等框架则将这种比喻具体化。在 Keras 中,构建深度学习模型就是将相互兼容的多个层拼接在一起,以建立有用的数据变换流程。这里层兼容性(layer compatibility)具体指的是每一层只接受特定形状的输入张量,并返回特定形状的输出张量。看看下面这个例子。
from keras import layers
layer = layers.Dense(32, input_shape=(784,))我们创建了一个层,只接受第一个维度大小为 784 的 2D 张量(第 0 轴是批量维度,其大小没有指定,因此可以任意取值)作为输入。这个层将返回一个张量,第一个维度的大小变成了 32。
因此,这个层后面只能连接一个接受 32 维向量作为输入的层。使用 Keras 时,你无须担心兼容性,因为向模型中添加的层都会自动匹配输入层的形状,例如下面这段代码。
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(32, input_shape=(784,)))
model.add(layers.Dense(32))其中第二层没有输入形状(input_shape)的参数,相反,它可以自动推导出输入形状等于上一层的输出形状。
3.1.2 模型:层构成的网络
深度学习模型是层构成的有向无环图。最常见的例子就是层的线性堆叠,将单一输入映射为单一输出。但随着深入学习,你会接触到更多类型的网络拓扑结构。
一些常见的网络拓扑结构如下。
网络的拓扑结构定义了一个假设空间(hypothesis space)。你可能还记得第 1 章里机器学习的定义:“在预先定义好的可能性空间中,利用反馈信号的指引来寻找输入数据的有用表示。”
选定了网络拓扑结构,意味着将可能性空间(假设空间)限定为一系列特定的张量运算,将输入数据映射为输出数据。然后,你需要为这些张量运算的权重张量找到一组合适的值。
选择正确的网络架构更像是一门艺术而不是科学。虽然有一些最佳实践和原则,但只有动手实践才能让你成为合格的神经网络架构师。后面几章将教你构建神经网络的详细原则,也会帮你建立直觉,明白对于特定问题哪些架构有用、哪些架构无用。
3.1.3 损失函数与优化器:配置学习过程的关键
一旦确定了网络架构,你还需要选择以下两个参数。
损失函数(目标函数)——在训练过程中需要将其最小化。它能够衡量当前任务是否已成功完成。
优化器——决定如何基于损失函数对网络进行更新。它执行的是随机梯度下降(SGD)的某个变体。
具有多个输出的神经网络可能具有多个损失函数(每个输出对应一个损失函数)。但是,梯度下降过程必须基于单个标量损失值。因此,对于具有多个损失函数的网络,需要将所有损失函数取平均,变为一个标量值。
选择正确的目标函数对解决问题是非常重要的。网络的目的是使损失尽可能最小化,因此,如果目标函数与成功完成当前任务不完全相关,那么网络最终得到的结果可能会不符合你的预期。想象一下,利用 SGD 训练一个愚蠢而又无所不能的人工智能,给它一个蹩脚的目标函数:“将所有活着的人的平均幸福感最大化”。为了简化自己的工作,这个人工智能可能会选择杀死绝大多数人类,只留几个人并专注于这几个人的幸福——因为平均幸福感并不受人数的影响。这可能并不是你想要的结果!请记住,你构建的所有神经网络在降低损失函数时和上述的人工智能一样无情。因此,一定要明智地选择目标函数,否则你将会遇到意想不到的副作用。
幸运的是,对于分类、回归、序列预测等常见问题,你可以遵循一些简单的指导原则来选择正确的损失函数。
例如,对于二分类问题,你可以使用二元交叉熵(binary crossentropy)损失函数;
对于多分类问题,可以用分类交叉熵(categorical crossentropy)损失函数;
对于回归问题,可以用均方误差(mean-squared error)损失函数;
对于序列学习问题,可以用联结主义时序分类(CTC,connectionist temporal classification)损失函数,等等。
只有在面对真正全新的研究问题时,你才需要自主开发目标函数。在后面几章里,我们将详细说明对于各种常见任务应选择哪种损失函数。
3.2 Keras 简介
本书的代码示例全都使用 Keras 实现。Keras 是一个 Python 深度学习框架,可以方便地定义和训练几乎所有类型的深度学习模型。Keras 最开始是为研究人员开发的,其目的在于快速实验。
Keras 具有以下重要特性。
Keras 基于宽松的 MIT 许可证发布,这意味着可以在商业项目中免费使用它。它与所有版本的 Python 都兼容(截至 2017 年年中,从 Python 2.7 到 Python 3.6 都兼容)。
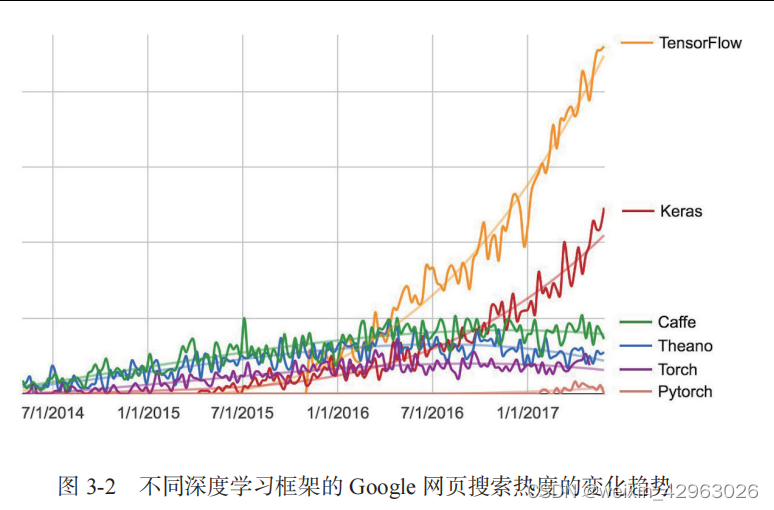
Keras 已有 200 000 多个用户,既包括创业公司和大公司的学术研究人员和工程师,也包括研究生和业余爱好者。Google、Netflix、Uber、CERN、Yelp、Square 以及上百家创业公司都在用 Keras 解决各种各样的问题。Keras 还是机器学习竞赛网站 Kaggle 上的热门框架,最新的深度学习竞赛中,几乎所有的优胜者用的都是 Keras 模型,如图 3-2 所示。
3.2.1 Keras、TensorFlow、Theano 和 CNTK
Keras 是一个模型级(model-level)的库,为开发深度学习模型提供了高层次的构建模块。它不处理张量操作、求微分等低层次的运算。相反,它依赖于一个专门的、高度优化的张量库来完成这些运算,这个张量库就是 Keras 的后端引擎(backend engine)。Keras 没有选择单个张量库并将 Keras 实现与这个库绑定,而是以模块化的方式处理这个问题(见图 3-3)。因此,几个不同的后端引擎都可以无缝嵌入到 Keras 中。目前,Keras 有三个后端实现:TensorFlow 后端、Theano 后端和微软认知工具包(CNTK,Microsoft cognitive toolkit)后端。未来 Keras 可能会扩展到支持更多的深度学习引擎。

TensorFlow、CNTK 和 Theano 是当今深度学习的几个主要平台。Theano 由蒙特利尔大学的MILA 实验室开发,TensorFlow 由 Google 开发,CNTK 由微软开发。你用 Keras 写的每一段代码都可以在这三个后端上运行,无须任何修改。也就是说,你在开发过程中可以在两个后端之间无缝切换,这通常是很有用的。例如,对于特定任务,某个后端的速度更快,那么我们就可以无缝切换过去。我们推荐使用 TensorFlow 后端作为大部分深度学习任务的默认后端,因为它的应用最广泛,可扩展,而且可用于生产环境。
通过 TensorFlow(或 Theano、CNTK),Keras 可以在 CPU 和 GPU 上无缝运行。在 CPU 上运行时,TensorFlow 本身封装了一个低层次的张量运算库,叫作 Eigen;在 GPU 上运行时,TensorFlow封装了一个高度优化的深度学习运算库,叫作 NVIDIA CUDA 深度神经网络库(cuDNN)。
3.2.2 使用 Keras 开发:概述
你已经见过一个 Keras 模型的示例,就是 MNIST 的例子。典型的 Keras 工作流程就和那个例子类似。
(1) 定义训练数据:输入张量和目标张量。
(2) 定义层组成的网络(或模型),将输入映射到目标。
(3) 配置学习过程:选择损失函数、优化器和需要监控的指标。
(4) 调用模型的 fit 方法在训练数据上进行迭代。
定义模型有两种方法:一种是使用 Sequential 类(仅用于层的线性堆叠,这是目前最常见的网络架构),另一种是函数式 API(functional API,用于层组成的有向无环图,让你可以构建任意形式的架构)。
前面讲过,这是一个利用 Sequential 类定义的两层模型(注意,我们向第一层传入了输入数据的预期形状)。
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(32, activation='relu', input_shape=(784,)))
model.add(layers.Dense(10, activation='softmax'))下面是用函数式 API 定义的相同模型。
input_tensor = layers.Input(shape=(784,))
x = layers.Dense(32, activation='relu')(input_tensor)
output_tensor = layers.Dense(10, activation='softmax')(x)
model = models.Model(inputs=input_tensor, outputs=output_tensor)利用函数式 API,你可以操纵模型处理的数据张量,并将层应用于这个张量,就好像这些层是函数一样。
注意 第 7 章有关于函数式 API 的详细指南。在那之前,我们的代码示例中只会用到 Sequential 类。
一旦定义好了模型架构,使用 Sequential 模型还是函数式 API 就不重要了。接下来的步骤都是相同的。
配置学习过程是在编译这一步,你需要指定模型使用的优化器和损失函数,以及训练过程中想要监控的指标。下面是单一损失函数的例子,这也是目前最常见的。
from keras import optimizers
model.compile(optimizer=optimizers.RMSprop(lr=0.001),loss='mse',metrics=['accuracy'])最后,学习过程就是通过 fit() 方法将输入数据的 Numpy 数组(和对应的目标数据)传入模型,这一做法与 Scikit-Learn 及其他机器学习库类似。
model.fit(input_tensor, target_tensor, batch_size=128, epochs=10)在接下来的几章里,你将会在这些问题上培养可靠的直觉:哪种类型的网络架构适合解决哪种类型的问题?如何选择正确的学习配置?如何调节模型使其给出你想要的结果?我们将在3.4~3.6 节讲解三个基本示例,分别是二分类问题、多分类问题和回归问题。
3.3 建立深度学习工作站
在开始开发深度学习应用之前,你需要建立自己的深度学习工作站。虽然并非绝对必要,但强烈推荐你在现代 NVIDIA GPU 上运行深度学习实验。某些应用,特别是卷积神经网络的图像处理和循环神经网络的序列处理,在 CPU 上的速度非常之慢,即使是高速多核 CPU 也是如此。即使是可以在 CPU 上运行的深度学习应用,使用现代 GPU 通常也可以将速度提高 5 倍或 10 倍。如果你不想在计算机上安装 GPU,也可以考虑在 AWS EC2 GPU 实例或 Google 云平台上运行深度学习实验。但请注意,时间一长,云端 GPU 实例可能会变得非常昂贵。
无论在本地还是在云端运行,最好都使用 UNIX 工作站。虽然从技术上来说可以在 Windows上使用 Keras(Keras 的三个后端都支持 Windows),但我们不建议这么做。在附录 A 的安装说明中,我们以安装了 Ubuntu 的计算机为例。如果你是 Windows 用户,最简单的解决方案就是安装 Ubuntu双系统。这看起来可能有点麻烦,但从长远来看,使用 Ubuntu 将会为你省去大量时间和麻烦。
注意,使用 Keras 需要安装 TensorFlow、CNTK 或 Theano(如果你希望能够在三个后端之间来回切换,那么可以安装三个)。本书将重点介绍 TensorFlow,并简要介绍一下 Theano,不会涉及 CNTK。
3.3.1 Jupyter 笔记本:运行深度学习实验的首选方法
Jupyter 笔记本是运行深度学习实验的好方法,特别适合运行本书中的许多代码示例。它广泛用于数据科学和机器学习领域。笔记本(notebook)是 Jupyter Notebook 应用生成的文件,可以在浏览器中编辑。它可以执行 Python 代码,还具有丰富的文本编辑功能,可以对代码进行注释。笔记本还可以将冗长的实验代码拆分为可独立执行的短代码,这使得开发具有交互性,而且如果后面的代码出现问题,你也不必重新运行前面的所有代码。
我们推荐使用 Jupyter 笔记本来上手 Keras,虽然这并不是必需的。你也可以运行独立的Python 脚本,或者在 IDE(比如 PyCharm)中运行代码。本书所有代码示例都以开源笔记本的形式提供,你可以在本书网站上下载:https://www.manning.com/books/deep-learning-with-python。
3.3.2 运行 Keras:两种选择
想要在实践中使用 Keras,我们推荐以下两种方式。
使用官方的 EC2 深度学习 Amazon 系统映像(AMI),并在 EC2 上以 Jupyter 笔记本的方式运行 Keras 实验。如果你的本地计算机上没有 GPU,你可以选择这种方式。附录 B 给出了详细指南。
在本地 UNIX 工作站上从头安装。然后你可以运行本地 Jupyter 笔记本或常规的 Python 代码库。如果你已经拥有了高端的 NVIDIA GPU,可以选择这种方式。附录 A 给出了基于 Ubuntu 的详细安装指南。
我们来详细看一下这两种方式的优缺点。
3.3.3 在云端运行深度学习任务:优点和缺点
如果你还没有可用于深度学习的 GPU(即最新的高端 NVIDIA GPU),那么在云端运行深度学习实验是一种简单又低成本的方法,让你无须额外购买硬件就可以上手。如果你使用Jupyter 笔记本,那么在云端运行的体验与在本地运行完全相同。截至 2017 年年中,最容易上手深度学习的云产品肯定是 AWS EC2。附录 B 给出了在 EC2 GPU 实例上运行 Jupyter 笔记本的详细指南。
但如果你是深度学习的重度用户,从长期来看这种方案是难以持续的,甚至几个星期都不行。EC2 实例的价格很高:附录 B 推荐的实例(p2.xlarge 实例,计算能力一般)在 2017 年年中的价格是每小时 0.90 美元。与此相对的是,一款可靠的消费级 GPU 价格在 1000~1500 美元——这个价格一直相当稳定,而这种 GPU 的性能则在不断提高。如果你准备认真从事深度学习,那么应该建立具有一块或多块 GPU 的本地工作站。
简而言之,EC2 是很好的上手方法。你完全可以在 EC2 GPU 实例上运行本书的代码示例。但如果你想成为深度学习的高手,那就自己买 GPU。
3.3.4 深度学习的最佳 GPU
如果你准备买一块 GPU,应该选择哪一款呢?首先要注意,一定要买 NVIDIA GPU。NVIDIA 是目前唯一一家在深度学习方面大规模投资的图形计算公司,现代深度学习框架只能在 NVIDIA 显卡上运行。截至 2017 年年中,最容易上手深度学习的云产品肯定是 AWS EC2。附录 B 给出了在 EC2 GPU 实例上运行 Jupyter 笔记本的详细指南。
从这一节开始,我们将认为你的计算机已经安装好 Keras 及其依赖,最好支持 GPU。在继续阅读之前请确认已经完成此步骤。阅读附录中的详细指南,还可以在网上搜索进一步的帮助。安装 Keras 及常见的深度学习依赖的教程有很多。
下面我们将深入讲解 Keras 示例。
3.4 电影评论分类:二分类问题
二分类问题可能是应用最广泛的机器学习问题。在这个例子中,你将学习根据电影评论的文字内容将其划分为正面或负面。
3.4.1 IMDB 数据集
本节使用 IMDB 数据集,它包含来自互联网电影数据库(IMDB)的 50 000 条严重两极分化的评论。数据集被分为用于训练的 25 000 条评论与用于测试的 25 000 条评论,训练集和测试集都包含 50% 的正面评论和 50% 的负面评论。
为什么要将训练集和测试集分开?因为你不应该将训练机器学习模型的同一批数据再用于测试模型!模型在训练数据上的表现很好,并不意味着它在前所未见的数据上也会表现得很好,而且你真正关心的是模型在新数据上的性能(因为你已经知道了训练数据对应的标签,显然不再需要模型来进行预测)。例如,你的模型最终可能只是记住了训练样本和目标值之间的映射关系,但这对在前所未见的数据上进行预测毫无用处。下一章将会更详细地讨论这一点。
与 MNIST 数据集一样,IMDB 数据集也内置于 Keras 库。它已经过预处理:评论(单词序列)已经被转换为整数序列,其中每个整数代表字典中的某个单词。
下列代码将会加载 IMDB 数据集(第一次运行时会下载大约 80MB 的数据)。
代码清单 3-1 加载 IMDB 数据集
from keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)参数 num_words=10000 的意思是仅保留训练数据中前 10 000 个最常出现的单词。低频单词将被舍弃。这样得到的向量数据不会太大,便于处理。
train_data 和 test_data 这两个变量都是评论组成的列表,每条评论又是单词索引组成的列表(表示一系列单词)。train_labels 和 test_labels 都是 0 和 1 组成的列表,其中 0代表负面(negative),1 代表正面(positive)。
>>> train_data[0]
[1, 14, 22, 16, ... 178, 32]
>>> train_labels[0]
1由于限定为前 10 000 个最常见的单词,单词索引都不会超过 10 000。
>>> max([max(sequence) for sequence in train_data])
9999下面这段代码很有意思,你可以将某条评论迅速解码为英文单词。
# word_index 是一个将单词映射为整数索引的字典
word_index = imdb.get_word_index()
# 键值颠倒,将整数索引映射为单词
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
decoded_review = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]])print('train_labels[0]=', train_labels[0])
# 打印训练数据形状
print('train_data.shape', train_data.shape)train_labels[0]= 1
train_data.shape (25000,)print('train_data[0]:', train_data[0])train_data[0]: [1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]print('word_index.get(''this''):', word_index.get('this'))
print('len(word_index):', len(word_index))
print('word_index[''this'']:', word_index['this'])
print('word_index[''film'']:', word_index['film'])
print('word_index[''fawn'']:', word_index['fawn'])print('reverse_word_index[''11'']:', reverse_word_index[11])word_index.get(this): 11
len(word_index): 88584
word_index[this]: 11
word_index[film]: 19
word_index[fawn]: 34701
reverse_word_index[11]: this3.4.2 准备数据
你不能将整数序列直接输入神经网络。你需要将列表转换为张量。转换方法有以下两种。
填充列表,使其具有相同的长度,再将列表转换成形状为 (samples, word_indices)的整数张量,然后网络第一层使用能处理这种整数张量的层(即 Embedding 层,本书后面会详细介绍)。
对列表进行 one-hot 编码,将其转换为 0 和 1 组成的向量。举个例子,序列 [3, 5] 将会被转换为 10 000 维向量,只有索引为 3 和 5 的元素是 1,其余元素都是 0。然后网络第一层可以用 Dense 层,它能够处理浮点数向量数据。
下面我们采用后一种方法将数据向量化。为了加深理解,你可以手动实现这一方法,如下所示。
#代码清单 3-2 将整数序列编码为二进制矩阵# 定义vectorize_sequences函数
def vectorize_sequences(sequences, dimension=10000):results = np.zeros((len(sequences), dimension))# enumeratefor i, sequence in enumerate(sequences):results[i, sequence] = 1. # 将 results[i] 的指定索引设为 1# print(i, sequence)# print(results)return resultsx_train0 = vectorize_sequences(train_data[0:3])
print(x_train0)[[0. 1. 1. ... 0. 0. 0.][0. 1. 1. ... 0. 0. 0.][0. 1. 1. ... 0. 0. 0.]]x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)# 将训练数据向量化
x_train = vectorize_sequences(train_data)
# 将测试数据向量化
x_test = vectorize_sequences(test_data)
print('x_train:', x_train)
print('x_test:', x_test)x_train: [[0. 1. 1. ... 0. 0. 0.][0. 1. 1. ... 0. 0. 0.][0. 1. 1. ... 0. 0. 0.]...[0. 1. 1. ... 0. 0. 0.][0. 1. 1. ... 0. 0. 0.][0. 1. 1. ... 0. 0. 0.]]
x_test: [[0. 1. 1. ... 0. 0. 0.][0. 1. 1. ... 0. 0. 0.][0. 1. 1. ... 0. 0. 0.]...[0. 1. 1. ... 0. 0. 0.][0. 1. 1. ... 0. 0. 0.][0. 1. 1. ... 0. 0. 0.]]y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
print('y_train:', y_train)
print('y_test:', y_test)
print('y_train.shape', y_train.shape)y_train: [1. 0. 0. ... 0. 1. 0.]
y_test: [0. 1. 1. ... 0. 0. 0.]
y_train.shape (25000,)# enumerate的测试
seasons = ['Spring', 'Summer', 'Fall', 'Winter']
print('seasons:', seasons)
print('list(enumerate(seasons)):', list(enumerate(seasons)))
print("list(enumerate(seasons, start=1)):", list(enumerate(seasons, start=1)))seasons: ['Spring', 'Summer', 'Fall', 'Winter']
list(enumerate(seasons)): [(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
list(enumerate(seasons, start=1)): [(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
3.4.3 构建网络
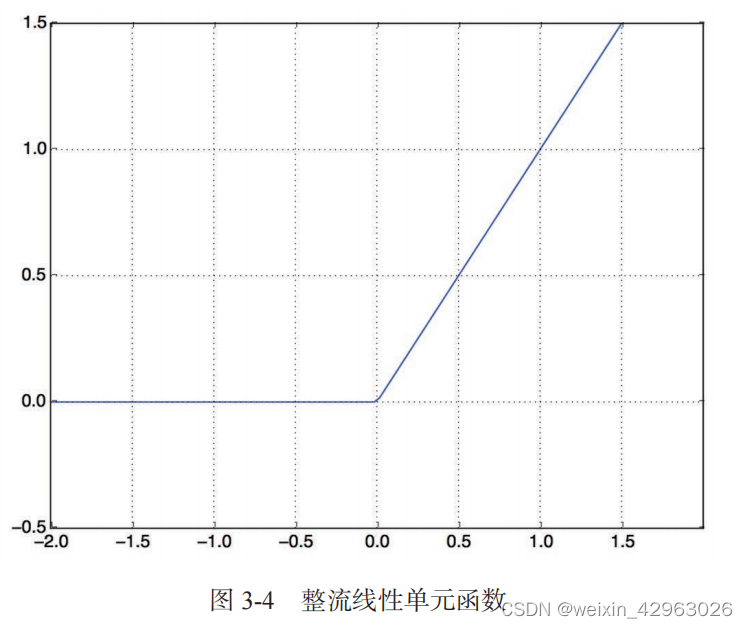
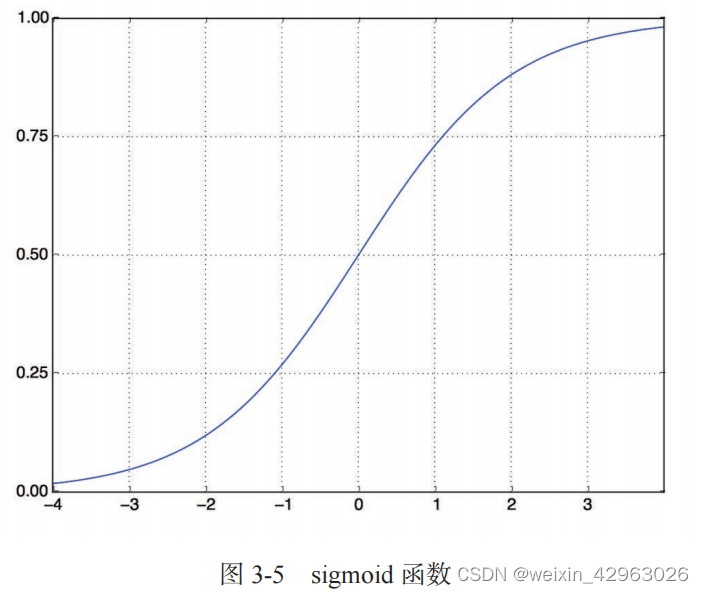
输入数据是向量,而标签是标量(1 和 0),这是你会遇到的最简单的情况。有一类网络在这种问题上表现很好,就是带有 relu 激活的全连接层(Dense)的简单堆叠,比如

from keras import models
from keras import layersmodel = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))代码清单 3-4 编译模型
# 选择损失函数和优化器
model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['accuracy'])上述代码将优化器、损失函数和指标作为字符串传入,这是因为 rmsprop、binary_ crossentropy 和 accuracy 都是 Keras 内置的一部分。
有时你可能希望配置自定义优化器的参数,或者传入自定义的损失函数或指标函数。前者可通过向 optimizer 参数传入一个优化器类实例来实现,如代码清单 3-5 所示;后者可通过向 loss 和 metrics 参数传入函数对象来实现,如代码清单 3-6 所示。
代码清单 3-5 配置优化器
model.compile(optimizer=optimizers.RMSprop(lr=0.001),loss='binary_cross-entropy',metrics=['accuracy'])model.compile(optimizer=optimizers.RMSprop(lr=0.001),loss=losses.binary_crossentropy,metrics=[metrics.binary_accuracy])3.4.4 验证你的方法
# 代码清单 3-7 留出验证集
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]# 代码清单 3-8 训练模型
model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['acc'])# 使用 512 个样本组成的小批量,将模型训练 20 个轮次(即对 x_train 和 y_train 两
# 个张量中的所有样本进行 20 次迭代)
# 在 CPU 上运行,每轮的时间不到 2 秒,训练过程将在 20 秒内结束。
# 每轮结束时会有短暂的停顿,因为模型要计算在验证集的 10 000 个样本上的损失和精度。history = model.fit(partial_x_train,partial_y_train,epochs=20,batch_size=512,validation_data=(x_val, y_val))# 调用 model.fit() 返回了一个 History 对象
# 这个对象有一个成员 history,它是一个字典,包含训练过程中的所有数据
# 字典中包含 4 个条目,对应训练过程和验证过程中监控的指标history_dict = history.history
print(history_dict.keys())dict_keys(['loss', 'acc', 'val_loss', 'val_acc'])loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']print("history_dict:", history_dict)
print("loss_values:", loss_values)
print('val_loss_values:', val_loss_values)history_dict: {'loss': [0.5311576724052429, 0.3295612335205078, 0.24616199731826782, 0.20007984340190887, 0.16878725588321686, 0.14065328240394592, 0.12178117036819458, 0.10707651078701019, 0.08816918730735779, 0.08290471136569977, 0.0661439448595047, 0.05832947418093681, 0.04871470853686333, 0.041972383856773376, 0.03593316674232483, 0.03029720112681389, 0.02458023838698864, 0.020768452435731888, 0.020750146359205246, 0.012916498817503452], 'acc': [0.7743333578109741, 0.8935999870300293, 0.9193999767303467, 0.9332000017166138, 0.9430000185966492, 0.9547333121299744, 0.9611999988555908, 0.9675999879837036, 0.9740666747093201, 0.9751999974250793, 0.9829333424568176, 0.9851999878883362, 0.9885333180427551, 0.9905333518981934, 0.9923999905586243, 0.9939333200454712, 0.9965333342552185, 0.9972666501998901, 0.9962666630744934, 0.9993333220481873], 'val_loss': [0.3976058065891266, 0.3222864866256714, 0.29301297664642334, 0.28684449195861816, 0.27952781319618225, 0.29999497532844543, 0.2950637638568878, 0.3080497980117798, 0.3298104405403137, 0.3424592912197113, 0.36206743121147156, 0.38678547739982605, 0.3946729898452759, 0.42827942967414856, 0.43978291749954224, 0.4857790470123291, 0.485530823469162, 0.5184621810913086, 0.5329005122184753, 0.5609933137893677], 'val_acc': [0.8687000274658203, 0.878600001335144, 0.8820000290870667, 0.8851000070571899, 0.8870000243186951, 0.8798999786376953, 0.8855999708175659, 0.8835999965667725, 0.8826000094413757, 0.8754000067710876, 0.8733000159263611, 0.8718000054359436, 0.8756999969482422, 0.8697999715805054, 0.8726000189781189, 0.8718000054359436, 0.8708999752998352, 0.8723999857902527, 0.8716999888420105, 0.8705000281333923]}loss_values: [0.5311576724052429, 0.3295612335205078, 0.24616199731826782, 0.20007984340190887, 0.16878725588321686, 0.14065328240394592, 0.12178117036819458, 0.10707651078701019, 0.08816918730735779, 0.08290471136569977, 0.0661439448595047, 0.05832947418093681, 0.04871470853686333, 0.041972383856773376, 0.03593316674232483, 0.03029720112681389, 0.02458023838698864, 0.020768452435731888, 0.020750146359205246, 0.012916498817503452]val_loss_values: [0.3976058065891266, 0.3222864866256714, 0.29301297664642334, 0.28684449195861816, 0.27952781319618225, 0.29999497532844543, 0.2950637638568878, 0.3080497980117798, 0.3298104405403137, 0.3424592912197113, 0.36206743121147156, 0.38678547739982605, 0.3946729898452759, 0.42827942967414856, 0.43978291749954224, 0.4857790470123291, 0.485530823469162, 0.5184621810913086, 0.5329005122184753, 0.5609933137893677]print('代码清单 3-9 绘制训练损失和验证损失___结果')
import matplotlib.pyplothistory_dict = history.history
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']epochs = range(1, len(loss_values) + 1)# 'bo' 表示蓝色圆点 # 'b' 表示蓝色实线
plt.plot(epochs, loss_values, 'bo', label='Training loss')
plt.plot(epochs, val_loss_values, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
import matplotlib.pyplotmatplotlib.pyplot.clf()
acc = history_dict['acc']
val_acc = history_dict['val_acc']
matplotlib.pyplot.plot(epochs, acc, 'bo', label='Training acc')
matplotlib.pyplot.plot(epochs, val_acc, 'b', label='Validation acc')
matplotlib.pyplot.title('Training and validation accuracy')
matplotlib.pyplot.xlabel('Epochs')
matplotlib.pyplot.ylabel('Accuracy')
matplotlib.pyplot.legend()
matplotlib.pyplot.show()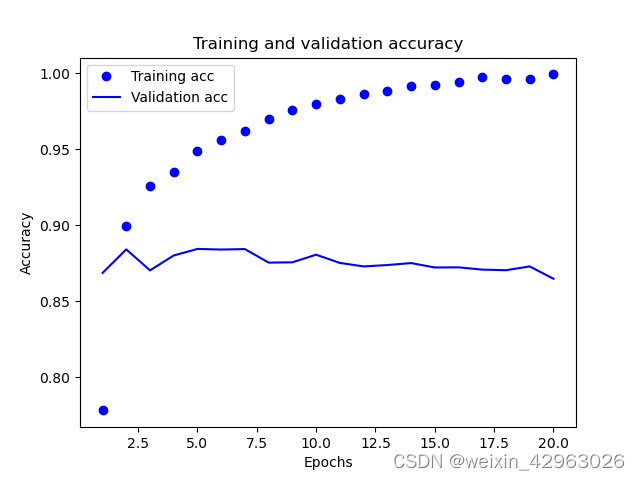
from keras.datasets import imdb
from keras import models
from keras import layers
from keras import optimizers
import numpy as np(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)# word_index 是一个将单词映射为整数索引的字典
word_index = imdb.get_word_index()# 键值颠倒,将整数索引映射为单词
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])# 反向字典
decoded_review = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]])# 定义vectorize_sequences函数
def vectorize_sequences(sequences, dimension=10000):results = np.zeros((len(sequences), dimension))for i, sequence in enumerate(sequences):results[i, sequence] = 1.return resultsx_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')model = models.Sequential()
model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['accuracy'])
# 模型定义
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]partial_y_train = y_train[10000:]# 编译模型
model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['accuracy'])# 仅作四次训练
model.fit(x_train, y_train, epochs=4, batch_size=512)
results = model.evaluate(x_test, y_test)print('results', results)
print('model.predict(x_test):',model.predict(x_test))
49/49 [==============================] - 1s 7ms/step - loss: 0.4647 - accuracy: 0.8133
Epoch 2/4
49/49 [==============================] - 0s 6ms/step - loss: 0.2754 - accuracy: 0.9021
Epoch 3/4
49/49 [==============================] - 0s 6ms/step - loss: 0.2135 - accuracy: 0.9230
Epoch 4/4
49/49 [==============================] - 0s 5ms/step - loss: 0.1821 - accuracy: 0.9348
782/782 [==============================] - 1s 830us/step - loss: 0.3018 - accuracy: 0.8806
results [0.3018262982368469, 0.8806399703025818]3.4.5 使用训练好的网络在新数据上生成预测结果
print('model.predict(x_test):',model.predict(x_test))model.predict(x_test): [[0.23568308][0.9997094 ][0.9133028 ]...[0.08991385][0.07172912][0.647347 ]]3.4.6 进一步的实验
# 模型定义
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))49/49 [==============================] - 1s 6ms/step - loss: 0.4853 - accuracy: 0.8112
Epoch 2/4
49/49 [==============================] - 0s 6ms/step - loss: 0.2759 - accuracy: 0.9028
Epoch 3/4
49/49 [==============================] - 0s 6ms/step - loss: 0.2136 - accuracy: 0.9216
Epoch 4/4
49/49 [==============================] - 0s 5ms/step - loss: 0.1766 - accuracy: 0.9360
782/782 [==============================] - 1s 825us/step - loss: 0.2884 - accuracy: 0.8860
results [0.2884432375431061, 0.8860399723052979]# 模型定义
model.add(layers.Dense(32, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
# model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))results [0.3072710633277893, 0.877560019493103]尝试使用 mse 损失函数代替 binary_crossentropy。
尝试使用 tanh 激活(这种激活在神经网络早期非常流行)代替 relu。
3.4.7 小结
3.5 新闻分类:多分类问题
上一节中,我们介绍了如何用密集连接的神经网络将向量输入划分为两个互斥的类别。但如果类别不止两个,要怎么做?
3.5.1 路透社数据集
# 路透社数据集,有 8982 个训练样本和 2246 个测试样本
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=10000)print('len(train_data):', len(train_data))
print('len(test_data):', len(test_data))len(train_data): 8982
len(test_data): 2246print('train_data[10]', train_data[10])train_data[10] [1, 245, 273, 207, 156, 53, 74, 160, 26, 14, 46, 296, 26, 39, 74, 2979, 3554, 14, 46, 4689, 4329, 86, 61, 3499, 4795, 14, 61, 451, 4329, 17, 12]相关文章:
第3章-python深度学习——(波斯美女)
第3章 神经网络入门 本章包括以下内容: 神经网络的核心组件 Keras 简介 建立深度学习工作站 使用神经网络解决基本的分类问题与回归问题 本章的目的是让你开始用神经网络来解决实际问题。你将进一步巩固在第 2 章第一个示例中学到的知识,还会将学到的…...
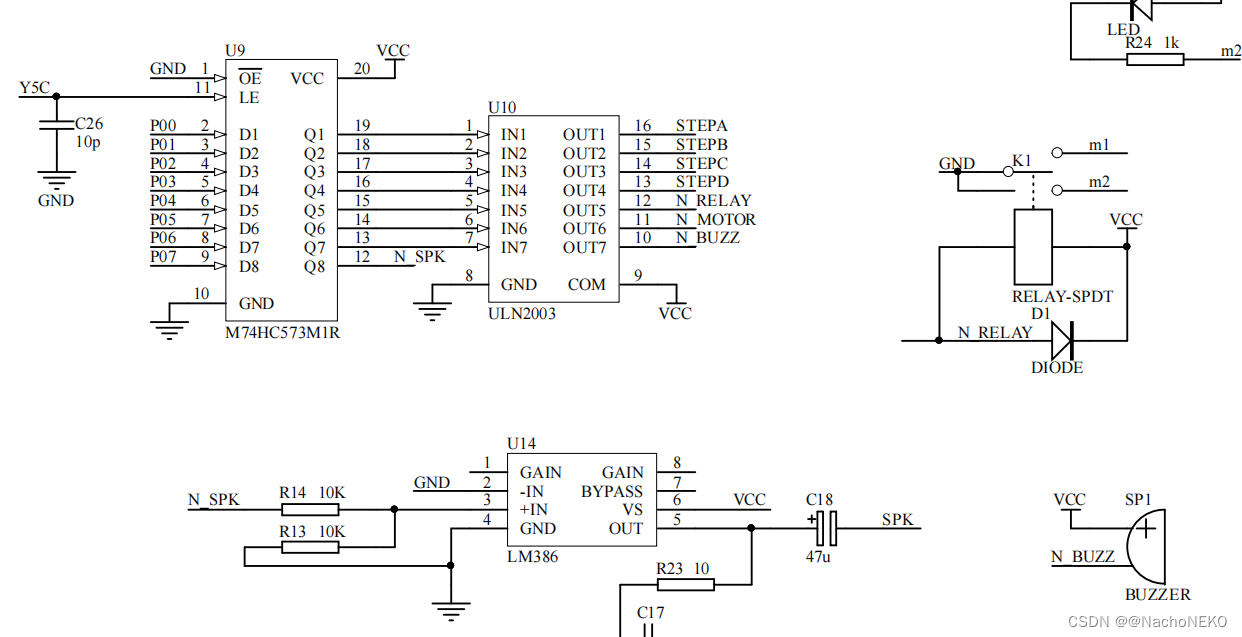
蓝桥杯备战——4.继电器/蜂鸣器
1.分析原理图 最好自己先去查查138以及ULN2003的使用方法,我这里直接讲思路。 由上图我们可以看到如果138输入ABC101,则输出Y50,此时若WR通过跳线帽接地则Y5C1 ,于是573(U9)处于输出跟随输入P0状态,此时若P061,则573输出Q71&am…...

Redis高级特性之地理空间索引
Redis的地理空间索引是一种功能强大的工具,用于存储和查询地理空间数据。这个特性主要通过Redis的地理空间数据类型 - GeoSet(地理集合)来实现。在这篇文章中,我们将探索Redis地理空间数据类型的使用和应用。 1. Redis GeoSet 简…...

R语言【taxlist】——as():将 taxlist 对象强制转换为 list 对象
Package taxlist version 0.2.4 Description 可以应用 S4 对象到 list 对象的强制转换来探索它们的内容,避免由它们的验证引起的错误。 Usage S4_to_list(x) Argument 参数【x】:一个 taxlist 类对象或任意 S4 类。 Details 将 taxlist 对象强制转换…...

使用POI生成word文档的table表格
文章目录 使用POI生成word文档的table表格1. 引入maven依赖2. 生成table的两种方式介绍2.1 生成一行一列的table2.2 生成固定行列的table2.3 table合并列2.4 创建多个table存在的问题 使用POI生成word文档的table表格 1. 引入maven依赖 <dependency><groupId>org.…...

C# 继承、多态性、抽象和接口详解:从入门到精通
C# 继承 在 C# 中,可以将字段和方法从一个类继承到另一个类。我们将“继承概念”分为两类: 派生类(子类) - 从另一个类继承的类基类(父类) - 被继承的类 要从一个类继承,使用 : 符号。 在以…...
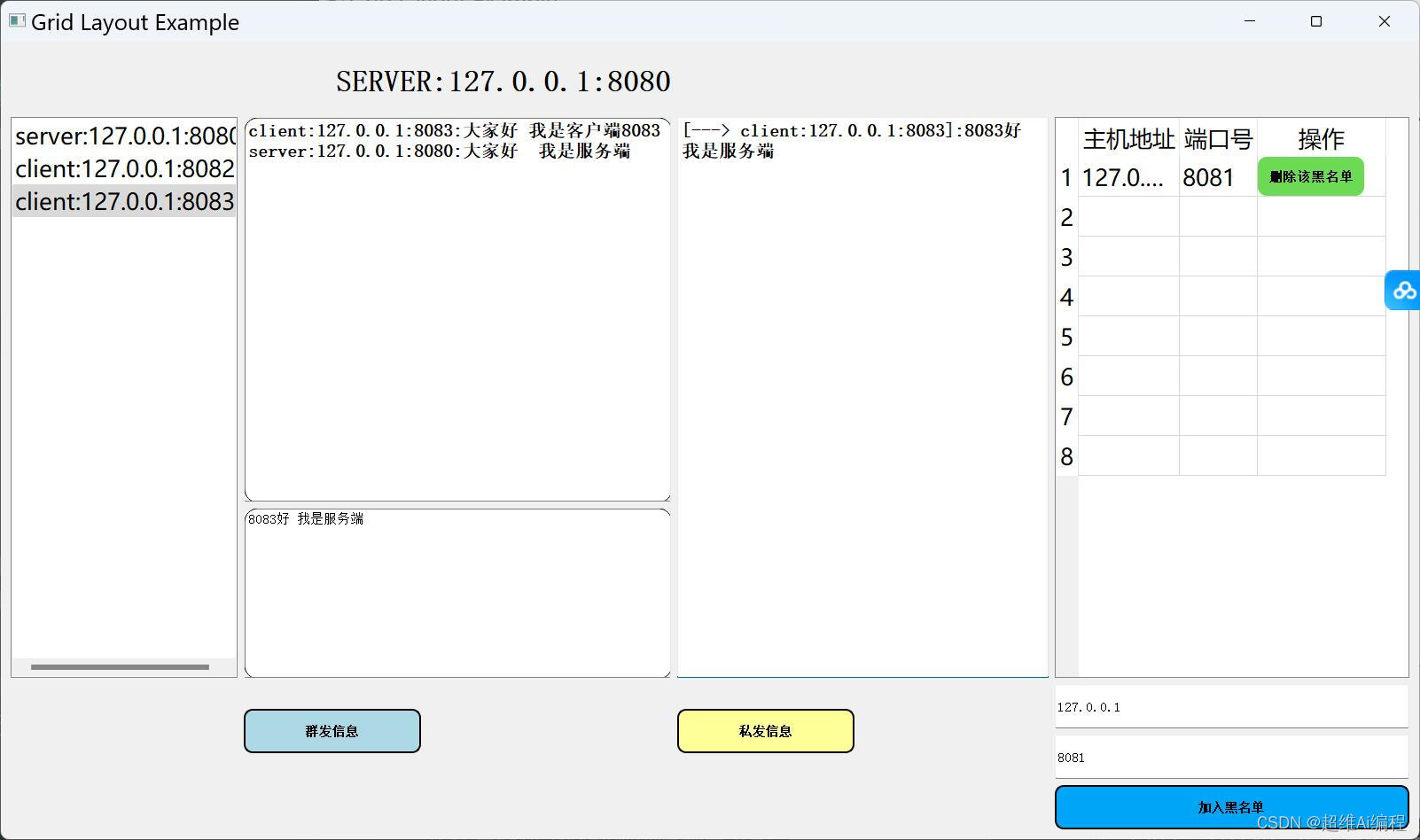
python在线聊天室(带聊天保存)
python Socket在线聊天室(带聊天保存) 需求功能 1.聊天信息保存功能(服务端会把信息保存到一个txt里面) 2.使用pyqt5框架作为一个可视化界面 3.具备一个服务端和多个客户端的功能 4.具备离线加入黑名单(离线踢出) 5.具备在线加入黑名单(在线加入黑名单被踢出) 6.具备群聊功能…...

jenkins+gitlab实现Android自动打包填坑之旅
一.背景 1.首先你需要知道你想要实现的Android自动打包的Android项目的一些环境配置及需要使用的一些开发版本。 声明:本文 Android项目基于:1.jdk11 2.SDK无要求 3.gradle无要求(同Manven一样为项目自动化构建开源工具) 注&am…...

洛谷B3625迷宫寻路
迷宫寻路 题目描述 机器猫被困在一个矩形迷宫里。 迷宫可以视为一个 n m n\times m nm 矩阵,每个位置要么是空地,要么是墙。机器猫只能从一个空地走到其上、下、左、右的空地。 机器猫初始时位于 ( 1 , 1 ) (1, 1) (1,1) 的位置,问能否…...
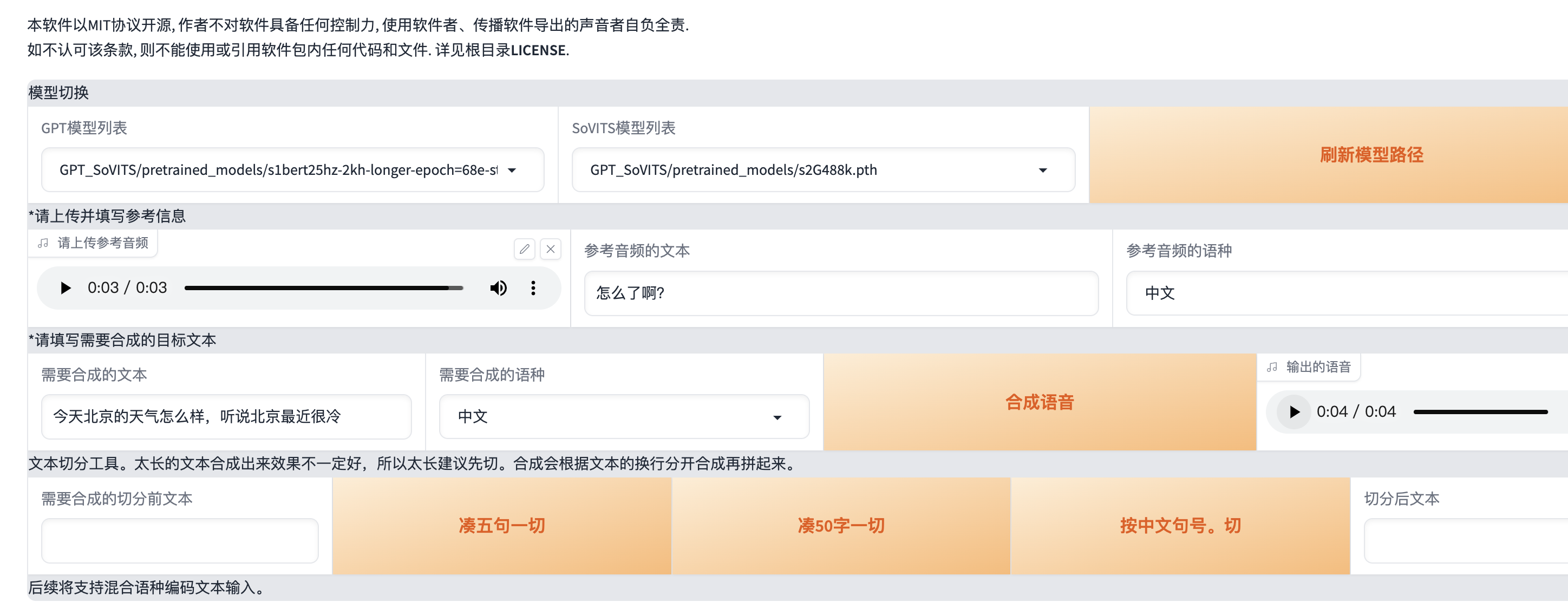
GPT-SoVITS 测试
开箱直用版(使用 AutoDL) step1 打开地址 https://www.codewithgpu.com/i/RVC-Boss/GPT-SoVITS/GPT-SoVITS-Official 选择 AutoDL创建实例,选择 3080ti 机器 step2 创建好实例之后,进入命令行,输入命令 echo {}>…...
人工智能:更多有用的 Python 库
目录 前言 推荐 JupyterLab 入门 复杂的矩阵运算 其它人工智能和机器学习的 Python 库 前言 在这篇文章中,我们将了解更多的矩阵操作,同时再介绍几个人工智能 Python 库。 推荐 前些天发现了一个巨牛的人工智能学习网站,通俗易懂&#x…...

Linux BIO如何下发到HDD?
在Linux操作系统中,当创建一个Block I/O请求(BIO)时,它会被封装成适合硬件交互的数据结构,并通过内核存储子系统传递到对应的硬件控制器上,如SAS(Serial Attached SCSI)HBAÿ…...

《动手学深度学习(PyTorch版)》笔记4.6
注:书中对代码的讲解并不详细,本文对很多细节做了详细注释。另外,书上的源代码是在Jupyter Notebook上运行的,较为分散,本文将代码集中起来,并加以完善,全部用vscode在python 3.9.18下测试通过。…...

Hadoop-MapReduce-源码跟读-客户端篇
一、源码下载 下面是hadoop官方源码下载地址,我下载的是hadoop-3.2.4,那就一起来看下吧 Index of /dist/hadoop/core 二、从WordCount进入源码 用idea将源码加载进来后,找到org.apache.hadoop.examples.WordCount类(快捷方法&…...
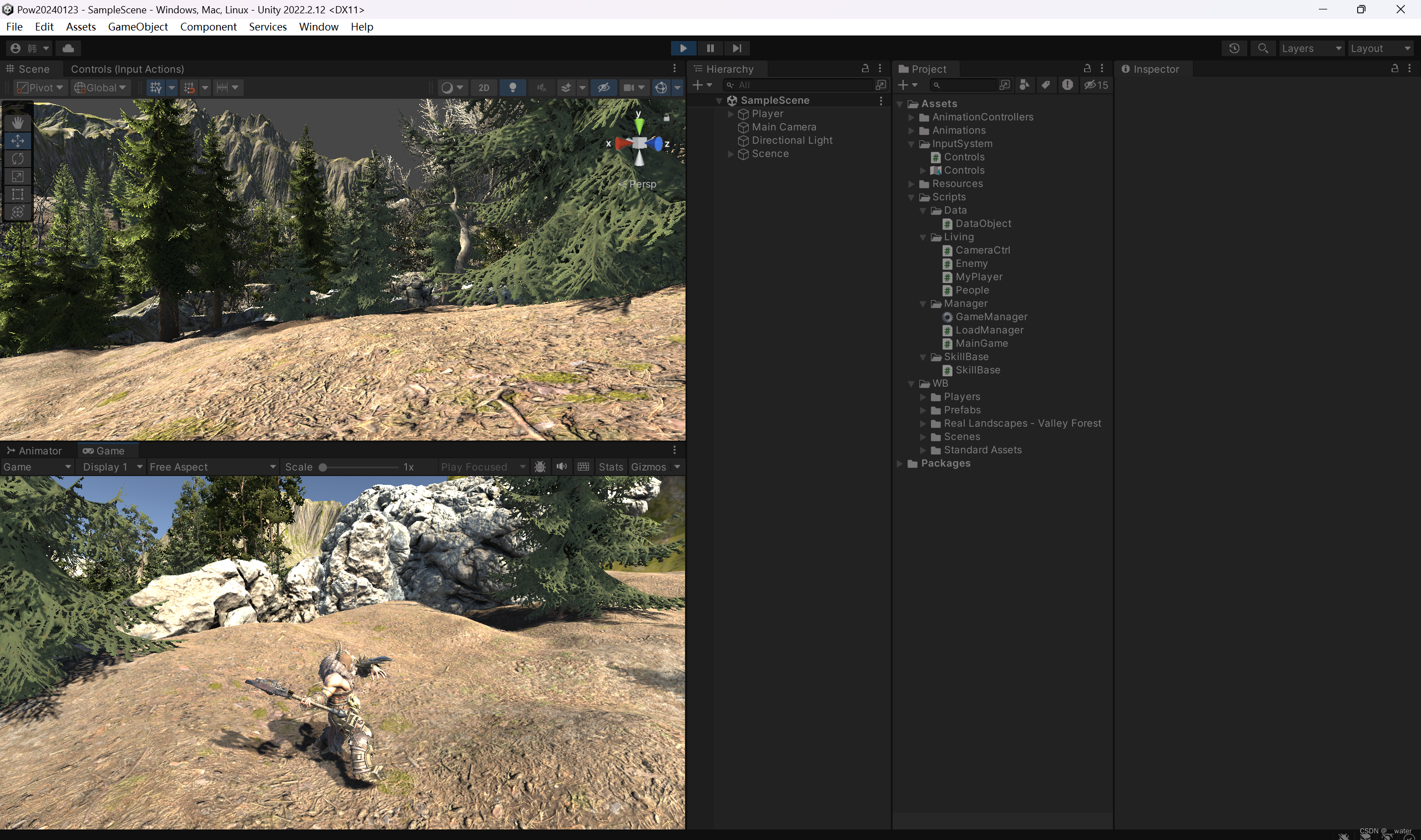
《游戏-03_3D-开发》之—新输入系统人物移动攻击连击
本次修改unity的新输入输出系统。本次修改unity需要重启,请先保存项目, 点击加号起名为MyCtrl, 点击加号设置为一轴的, 继续设置W键, 保存 生成自动脚本, 修改MyPlayer代码: using UnityEngine;…...
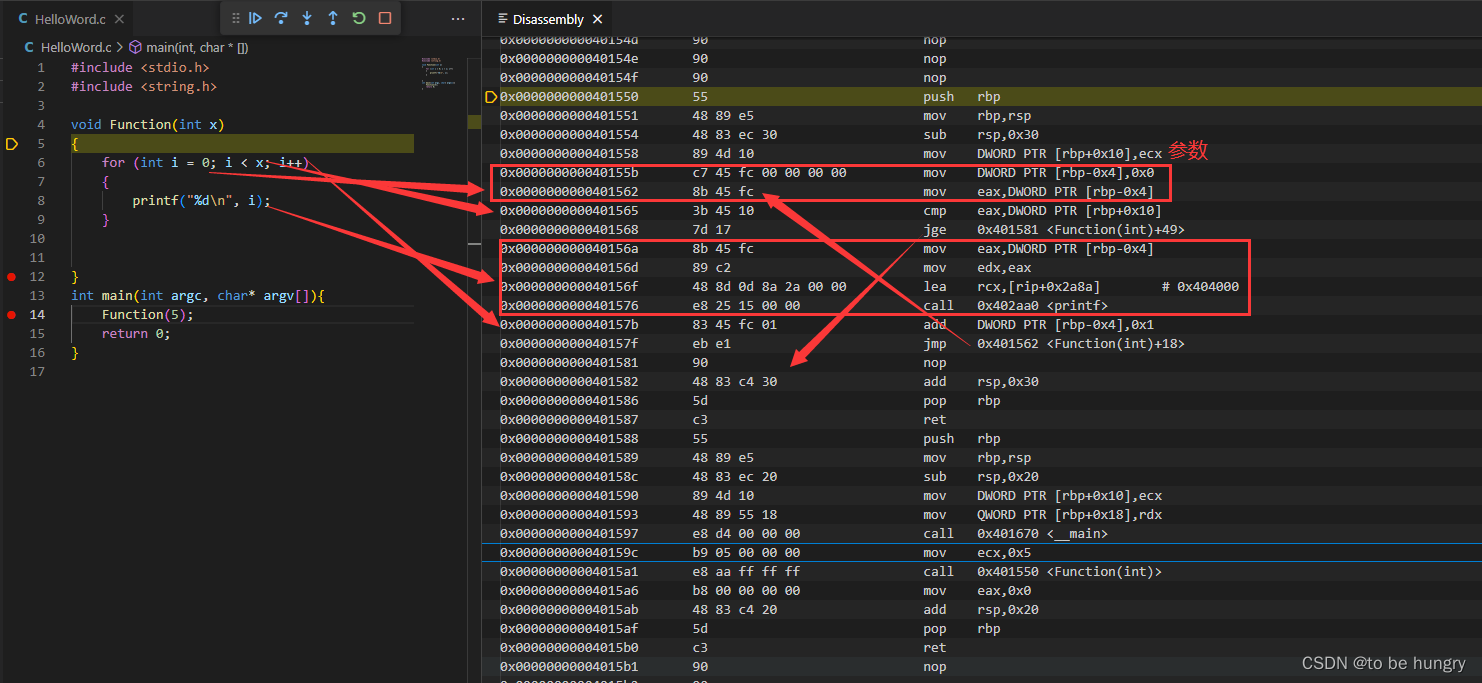
滴水逆向三期笔记与作业——02C语言——10 Switch语句反汇编
滴水逆向三期笔记与作业——02C语言——10 Switch语句反汇编 一、Switch语句1、switch语句 是if语句的简写2、break加与不加有什么特点?default语句可以省略吗?3、游戏中的switch语句(示例)4、添加case后面的值,一个一个增加&…...
燃烧的指针(三)
🌈个人主页:小田爱学编程 🔥 系列专栏:c语言从基础到进阶 🏆🏆关注博主,随时获取更多关于c语言的优质内容!🏆🏆 😀欢迎来到小田代码世界~ &#x…...

微服务架构实施攻略:如何选择合适的微服务通信机制?
随着业务的快速发展和系统的日益复杂,传统的单体应用逐渐显露出瓶颈,已无法满足现代软件研发的需求。微服务架构作为一种灵活、可扩展的解决方案,通过将复杂系统拆分为一系列小型服务来提高系统的可伸缩性、灵活性和可维护性。在实施微服务架…...
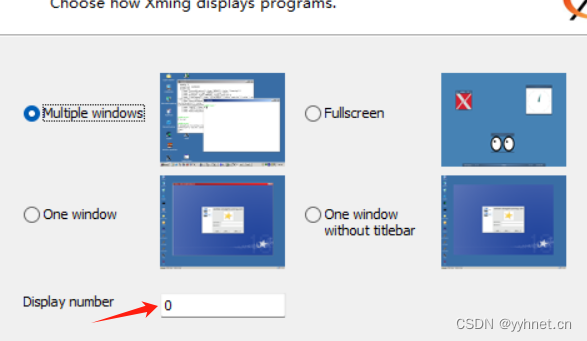
【jetson笔记】解决vscode远程调试qt.qpa.xcb: could not connect to display报错
配置x11转发 jetson远程安装x11转发 安装Xming Xming下载 安装完成后打开安装目录C:\Program Files (x86)\Xming 用记事本打开X0.hosts文件,添加jetson IP地址 后续IP改变需要重新修改配置文件 localhost 192.168.107.57打开Xlaunch Win菜单搜索Xlaundch打开 一…...

网络安全产品之认识安全隔离网闸
文章目录 一、什么是安全隔离网闸二、安全隔离网闸的主要功能三、安全隔离网闸的工作原理四、安全隔离网闸的分类五、安全隔离网闸与防火墙的区别四、安全隔离网闸的应用场景 随着互联网的发展,网络攻击和病毒传播的方式越来越复杂,对网络安全的要求也越…...

Arm Neoverse CMN-700 HN-F寄存器架构与缓存一致性配置详解
1. Arm Neoverse CMN-700 HN-F寄存器架构概述在现代SoC设计中,一致性互连网络(Coherent Mesh Network)是实现多核处理器高效协同工作的核心基础设施。作为Arm Neoverse平台的关键组件,CMN-700通过其独特的网格拓扑结构和分布式节点…...

Docker容器化Emacs:构建可移植、一致的开发环境解决方案
1. 项目概述:为什么要在Docker里运行Emacs?如果你是一个Emacs的重度用户,或者是一个开发者,你很可能遇到过这样的困境:你精心配置的Emacs环境,在换了一台新电脑、升级了操作系统,或者需要在多台…...

告别手动框选!用SUSTechPOINTS的V键批量标注,5分钟搞定一帧点云
解锁SUSTechPOINTS的V键批量标注:点云处理效率革命 在自动驾驶与机器人研发领域,点云标注是构建高精度感知模型的基础环节,但传统逐帧手动标注方式往往成为项目进度的瓶颈。我曾参与过一个城市级点云数据集标注项目,团队最初采用常…...

AI驱动全栈开发:Cursor集成模板与高效协作实践
1. 项目概述:当AI代码助手遇上全栈开发最近在GitHub上看到一个挺有意思的项目,叫“Cursor-FullStack-AI-App”。光看名字,你大概能猜到它和Cursor这个AI编程工具,以及全栈应用开发有关。作为一个在前后端都摸爬滚打过多年的开发者…...

Vim-ai插件深度指南:在Vim中无缝集成AI提升开发效率
1. 项目概述:当Vim遇上AI,一场编辑器生产力的革命如果你和我一样,是个在终端里泡了十多年的老Vim用户,那你一定经历过这样的场景:面对一个复杂的函数重构,手指在键盘上飞舞,:s、%s、宏录制轮番上…...

无代码物联网实战:基于ESP32与WipperSnapper的泳池水温监测方案
1. 项目概述:告别繁琐编程,用无代码方案守护泳池水温又到了打理泳池的季节,除了常规的清洁和化学平衡,水温其实是个挺关键的指标。水温不仅影响游泳的舒适度,也关系到泳池加热设备的能耗和泳池化学品的反应速率。以前想…...

All in Token, 移动,电信,联通,阿里,百度,华为,字节,Token石油战争,Token经济,百度要“重写”AI价值度量
AI Agent的价值,应该怎么被衡量? 2026年,AI行业的标志性拐点是Agent(智能体)快速普及。Agent作为核心生产力载体,将AI从Chatbot聊天模式带进主动执行的办事时代。 这个时候,如果我们还用旧尺子…...

Arm Fast Models中VGIC架构与中断虚拟化解析
1. Arm Fast Models中的VGIC架构解析虚拟通用中断控制器(Virtual Generic Interrupt Controller, VGIC)是Armv7/v8架构虚拟化扩展的核心组件之一。在Fast Models仿真环境中,Iris组件通过精确建模实现了VGIC的完整功能,包括:物理中断与虚拟中断…...
在Multi-Agent系统中的应用(图编排、动态DAG、Dynamic DAG)动态Agent Graph)
有向无环图(DAG)在Multi-Agent系统中的应用(图编排、动态DAG、Dynamic DAG)动态Agent Graph
文章目录有向无环图(DAG)在 Multi-Agent 系统中的应用一、什么是 DAG(有向无环图)二、为什么 Multi-Agent 需要 DAG三、Multi-Agent 的本质:任务图四、DAG 在 Multi-Agent 中的核心作用五、一个典型 Multi-Agent DAG六…...

汽车该多久换一代
汽车该多久换一代 买车的人其实不怕四年换代,怕的是刚提车半年就被新款打成旧款。李想这句话能引起讨论,原因也在这里:车企说的是研发验证周期,车主感受到的是价格、配置和二手残值。 汽车确实没法完全照着手机节奏跑。手机坏了可…...