Python环境下基于机器学习的NASA涡轮风扇发动机剩余使用寿命RUL预测
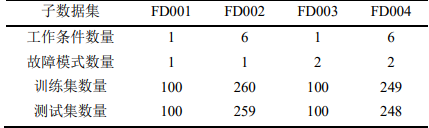
本例所用的数据集为C-MAPSS数据集,C-MAPSS数据集是美国NASA发布的涡轮风扇发动机数据集,其中包含不同工作条件和故障模式下涡轮风扇发动机多源性能的退化数据,共有 4 个子数据集,每个子集又可分为训练集、 测试集和RUL标签。其中,训练集包含航空发动机从开始运行到发生故障的所有状态参数; 测试集包含一定数量发动机从开始运行到发生故障前某一时间点的全部状态参数;RUL标签记录测试集中发动机的 RUL 值,可用于评估模 型的RUL预测能力。C-MAPSS数据集包含的基本信息如下:
添加图片注释,不超过 140 字(可选)
本例只采用FD001子数据集:

添加图片注释,不超过 140 字(可选)
关于python的集成环境,我一般Anaconda 和 winpython 都用,windows下主要用Winpython,IDE为spyder(类MATLAB界面)。

添加图片注释,不超过 140 字(可选)
正如peng wang老师所说
winpython, anaconda 哪个更好? - peng wang的回答 - 知乎 winpython, anaconda 哪个更好? - 知乎
winpython脱胎于pythonxy,面向科学计算,兼顾数据分析与挖掘;Anaconda主要面向数据分析与挖掘方面,在大数据处理方面有自己特色的一些包;winpython强调便携性,被做成绿色软件,不写入注册表,安装其实就是解压到某个文件夹,移动文件夹甚至放到U盘里在其他电脑上也能用;Anaconda则算是传统的软件模式。winpython是由个人维护;Anaconda由数据分析服务公司维护,意味着Winpython在很多方面都从简,而Anaconda会提供一些人性化设置。Winpython 只能在windows上用,Anaconda则有linux的版本。
抛开软件包的差异,我个人也推荐初学者用winpython,正因为其简单,问题也少点,由于便携性的特点系统坏了,重装后也能直接用。
请直接安装、使用winPython:WinPython download因为很多模块以及集成的模块

添加图片注释,不超过 140 字(可选)
可以选择版本,不一定要用最新版本,否则可能出现不兼容问题。
下载、解压后如下

添加图片注释,不超过 140 字(可选)
打开spyder就可以用了。
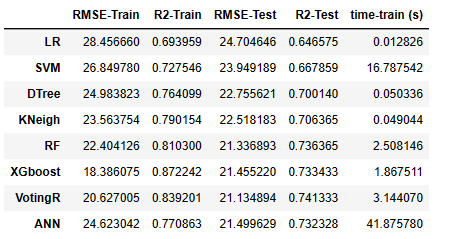
采用8种机器学习方法对NASA涡轮风扇发动机进行剩余使用寿命RUL预测,8种方法分别为:Linear Regression,SVM regression,Decision Tree regression,KNN model,Random Forest,Gradient Boosting Regressor,Voting Regressor,ANN Model。
首先导入相关模块
import pandas as pd import seaborn as sns import numpy as np import matplotlib.pyplot as plt from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.svm import SVR from sklearn.tree import DecisionTreeRegressor from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_squared_error, r2_score import tensorflow as tf from tensorflow.keras.layers import Dense
版本如下:
tensorflow=2.8.0 keras=2.8.0 sklearn=1.0.2
导入数据
path = '' # define column names col_names=["unit_nb","time_cycle"]+["set_1","set_2","set_3"] + [f's_{i}' for i in range(1,22)] # read data df_train = train_data = pd.read_csv(path+"train_FD001.txt", index_col=False, sep= "\s+", header = None,names=col_names )
df_test和y_test同理导入,看一下训练样本
df_train.head()

添加图片注释,不超过 140 字(可选)
进行探索性数据分析
df_train[col_names[1:]].describe().T

添加图片注释,不超过 140 字(可选)
数据可视化分析:
sns.set_style("darkgrid") plt.figure(figsize=(16,10)) k = 1 for col in col_names[2:] : plt.subplot(6,4,k) sns.histplot(df_train[col],color='Green') k+=1 plt.tight_layout() plt.show()

添加图片注释,不超过 140 字(可选)
def remaining_useful_life(df): # Get the total number of cycles for each unit grouped_by_unit = df.groupby(by="unit_nb") max_cycle = grouped_by_unit["time_cycle"].max() # Merge the max cycle back into the original frame result_frame = df.merge(max_cycle.to_frame(name='max_cycle'), left_on='unit_nb', right_index=True) # Calculate remaining useful life for each row remaining_useful_life = result_frame["max_cycle"] - result_frame["time_cycle"] result_frame["RUL"] = remaining_useful_life # drop max_cycle as it's no longer needed result_frame = result_frame.drop("max_cycle", axis=1) return result_frame df_train = remaining_useful_life(df_train) df_train.head()
绘制最大RUL的直方图分布
plt.figure(figsize=(10,5)) sns.histplot(max_ruls.RUL, color='r') plt.xlabel('RUL') plt.ylabel('Frequency') plt.axvline(x=max_ruls.RUL.mean(), ls='--',color='k',label=f'mean={max_ruls.RUL.mean()}') plt.axvline(x=max_ruls.RUL.median(),color='b',label=f'median={max_ruls.RUL.median()}') plt.legend() plt.show()

添加图片注释,不超过 140 字(可选)
plt.figure(figsize=(20, 8)) cor_matrix = df_train.corr() heatmap = sns.heatmap(cor_matrix, vmin=-1, vmax=1, annot=True) heatmap.set_title('Correlation Heatmap', fontdict={'fontsize':12}, pad=10);
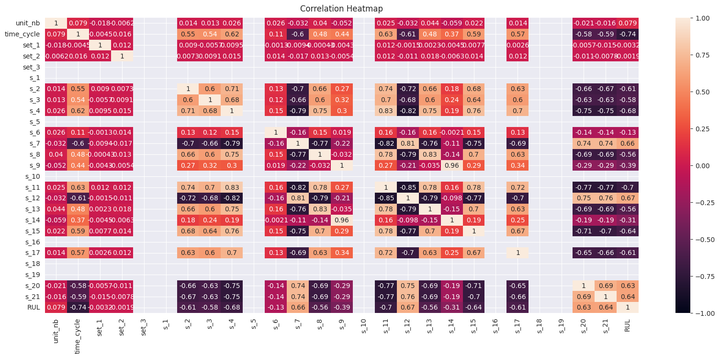
添加图片注释,不超过 140 字(可选)
col = df_train.describe().columns #we drop colummns with standard deviation is less than 0.0001 sensors_to_drop = list(col[df_train.describe().loc['std']<0.001]) + ['s_14'] print(sensors_to_drop) # df_train.drop(sensors_to_drop,axis=1,inplace=True) df_test.drop(sensors_to_drop,axis=1,inplace=True) sns.set_style("darkgrid") fig, axs = plt.subplots(4,4, figsize=(25, 18), facecolor='w', edgecolor='k') fig.subplots_adjust(hspace = .22, wspace=.2) i=0 axs = axs.ravel() index = list(df_train.unit_nb.unique()) for sensor in df_train.columns[1:-1]: for idx in index[1:-1:15]: axs[i].plot('RUL', sensor,data=df_train[df_train.unit_nb==idx]) axs[i].set_xlim(350,0) axs[i].set(xticks=np.arange(0, 350, 25)) axs[i].set_ylabel(sensor) axs[i].set_xlabel('Remaining Use Life') i=i+1

添加图片注释,不超过 140 字(可选)
X_train = df_train[df_train.columns[3:-1]] y_train = df_train.RUL X_test = df_test.groupby('unit_nb').last().reset_index()[df_train.columns[3:-1]] y_train = y_train.clip(upper=155) # create evalute function for train and test data def evaluate(y_true, y_hat): RMSE = np.sqrt(mean_squared_error(y_true, y_hat)) R2_score = r2_score(y_true, y_hat) return [RMSE,R2_score]; #Make Dataframe which will contain results Results = pd.DataFrame(columns=['RMSE-Train','R2-Train','RMSE-Test','R2-Test','time-train (s)'])
训练线性回归模型
import time Sc = StandardScaler() X_train1 = Sc.fit_transform(X_train) X_test1 = Sc.transform(X_test) # create and fit model start = time.time() lm = LinearRegression() lm.fit(X_train1, y_train) end_fit = time.time()- start # predict and evaluate y_pred_train = lm.predict(X_train1) y_pred_test = lm.predict(X_test1) Results.loc['LR']=evaluate(y_train, y_pred_train)+evaluate(y_test, y_pred_test)+[end_fit] Results def plot_prediction(y_test,y_pred_test,score): plt.style.use("ggplot") fig, ax = plt.subplots(1, 2, figsize=(17, 4), gridspec_kw={'width_ratios': [1.2, 3]}) fig.subplots_adjust(wspace=.12) ax[0].plot([min(y_test),max(y_test)], [min(y_test),max(y_test)],lw=3,c='r') ax[0].scatter(y_test,y_pred_test,lw=3,c='g') ax[0].annotate(text=('RMSE: ' + "{:.2f}".format(score[0]) +'\n' + 'R2: ' + "{:.2%}".format(score[1])), xy=(0,140), size='large'); ax[0].set_title('Actual vs predicted RUL') ax[0].set_xlabel('Actual') ax[0].set_ylabel('Predicted'); ax[1].plot(range(0,100),y_test,lw=2,c='r',label = 'actual') ax[1].plot(range(0,100),y_pred_test,lw=1,ls='--', c='b',label = 'prediction') ax[1].legend() ax[1].set_title('Actual vs predicted RUL') ax[1].set_xlabel('Engine num') ax[1].set_ylabel('RUL'); plot_prediction(y_test.RUL,y_pred_test,evaluate(y_test, y_pred_test))

添加图片注释,不超过 140 字(可选)
训练支持向量机模型
# create and fit model start = time.time() svr = SVR(kernel="rbf", gamma=0.25, epsilon=0.05) svr.fit(X_train1, y_train) end_fit = time.time()-start # predict and evaluate y_pred_train = svr.predict(X_train1) y_pred_test = svr.predict(X_test1) Results.loc['SVM']=evaluate(y_train, y_pred_train)+evaluate(y_test, y_pred_test)+[end_fit] Results plot_prediction(y_test.RUL,y_pred_test,evaluate(y_test, y_pred_test))

添加图片注释,不超过 140 字(可选)
训练决策树模型
start=time.time() dtr = DecisionTreeRegressor(random_state=42, max_features='sqrt', max_depth=10, min_samples_split=10) dtr.fit(X_train1, y_train) end_fit =time.time()-start # predict and evaluate y_pred_train = dtr.predict(X_train1) y_pred_test = dtr.predict(X_test1) Results.loc['DTree']=evaluate(y_train, y_pred_train)+evaluate(y_test, y_pred_test)+[end_fit] Results plot_prediction(y_test.RUL,y_pred_test,evaluate(y_test, y_pred_test))

添加图片注释,不超过 140 字(可选)
训练KNN模型
from sklearn.neighbors import KNeighborsRegressor # Evaluating on Train Data Set start = time.time() Kneigh = KNeighborsRegressor(n_neighbors=7) Kneigh.fit(X_train1, y_train) end_fit =time.time()-start # predict and evaluate y_pred_train = Kneigh.predict(X_train1) y_pred_test = Kneigh.predict(X_test1) Results.loc['KNeigh']=evaluate(y_train, y_pred_train)+evaluate(y_test, y_pred_test)+[end_fit] Results plot_prediction(y_test.RUL,y_pred_test,evaluate(y_test, y_pred_test))

添加图片注释,不超过 140 字(可选)
训练随机森林模型
start = time.time() rf = RandomForestRegressor(n_jobs=-1, n_estimators=130,max_features='sqrt', min_samples_split= 2, max_depth=10, random_state=42) rf.fit(X_train1, y_train) y_hat_train1 = rf.predict(X_train1) end_fit = time.time()-start # predict and evaluate y_pred_train = rf.predict(X_train1) y_pred_test = rf.predict(X_test1) Results.loc['RF']=evaluate(y_train, y_pred_train)+evaluate(y_test, y_pred_test)+[end_fit] Results plot_prediction(y_test.RUL,y_pred_test,evaluate(y_test, y_pred_test))

添加图片注释,不超过 140 字(可选)
训练Gradient Boosting Regressor模型
from sklearn.ensemble import GradientBoostingRegressor # Evaluating on Train Data Set start = time.time() xgb_r = GradientBoostingRegressor(n_estimators=45, max_depth=10, min_samples_leaf=7, max_features='sqrt', random_state=42,learning_rate=0.11) xgb_r.fit(X_train1, y_train) end_fit =time.time()-start # predict and evaluate y_pred_train = xgb_r.predict(X_train1) y_pred_test = xgb_r.predict(X_test1) Results.loc['XGboost']=evaluate(y_train, y_pred_train)+evaluate(y_test, y_pred_test)+[end_fit] Results plot_prediction(y_test.RUL,y_pred_test,evaluate(y_test, y_pred_test))

训练Voting Regressor模型
from sklearn.ensemble import VotingRegressor start=time.time() Vot_R = VotingRegressor([("rf", rf), ("xgb", xgb_r)],weights=[1.5,1],n_jobs=-1) Vot_R.fit(X_train1, y_train) end_fit =time.time()-start # predict and evaluate y_pred_train = Vot_R.predict(X_train1) y_pred_test = Vot_R.predict(X_test1) Results.loc['VotingR']=evaluate(y_train, y_pred_train)+evaluate(y_test, y_pred_test)+[end_fit] Results plot_prediction(y_test.RUL,y_pred_test,evaluate(y_test, y_pred_test))

训练ANN模型
star=time.time() model = tf.keras.models.Sequential() model.add(Dense(32, activation='relu')) model.add(Dense(64, activation='relu')) model.add(Dense(128, activation='relu')) model.add(Dense(128, activation='relu')) model.add(Dense(1, activation='linear')) model.compile(loss= 'msle', optimizer='adam', metrics=['msle']) history = model.fit(x=X_train1,y=y_train, epochs = 40, batch_size = 64) end_fit = time.time()-star # predict and evaluate y_pred_train = model.predict(X_train1) y_pred_test = model.predict(X_test1) Results.loc['ANN']=evaluate(y_train, y_pred_train)+evaluate(y_test, y_pred_test)+[end_fit] Results
工学博士,担任《Mechanical System and Signal Processing》审稿专家,担任《中国电机工程学报》优秀审稿专家,《控制与决策》,《系统工程与电子技术》,《电力系统保护与控制》,《宇航学报》等EI期刊审稿专家,担任《计算机科学》,《电子器件》 , 《现代制造过程》 ,《电源学报》,《船舶工程》 ,《轴承》 ,《工矿自动化》 ,《重庆理工大学学报》 ,《噪声与振动控制》 ,《机械传动》 ,《机械强度》 ,《机械科学与技术》 ,《机床与液压》,《声学技术》,《应用声学》,《石油机械》,《西安工业大学学报》等中文核心审稿专家。
擅长领域:现代信号处理,机器学习,深度学习,数字孪生,时间序列分析,设备缺陷检测、设备异常检测、设备智能故障诊断与健康管理PHM等。
相关文章:
Python环境下基于机器学习的NASA涡轮风扇发动机剩余使用寿命RUL预测
本例所用的数据集为C-MAPSS数据集,C-MAPSS数据集是美国NASA发布的涡轮风扇发动机数据集,其中包含不同工作条件和故障模式下涡轮风扇发动机多源性能的退化数据,共有 4 个子数据集,每个子集又可分为训练集、 测试集和RUL标签。其中&…...
Vite学习指南
那本课程都适合哪些人群呢? 想要学习前端工程化,在新项目中投入使用 Vite 构建工具的朋友 Webpack 转战到 Vite 的小伙伴 前端架构师们,可以充实自己的工具箱 当然如果你没有项目相关开发经验,也可以从本课程中受益࿰…...

无人机在三维空间中的转动问题
前提 这篇博客是对最近一个有关无人机拍摄图像项目中所学到的新知识的一个总结,比较杂乱,没有固定的写作顺序。 无人机坐标系旋转问题 上图是无人机坐标系,绕x轴是翻滚(Roll),绕y轴是俯仰(Pitch),绕z轴是偏航(Yaw)。…...
鸿蒙开发初体验
文章目录 前言一、环境配置1.1 安装DevEco Studio1.2 安装相关环境 二、工程创建三、工程结构介绍四、代码实现4.1 初识ArkTs4.2 具体实现 参考资料 前言 HarmonyOS是华为公司推出的一种操作系统,旨在为不同设备提供统一的操作系统和开发平台。鸿蒙开发的出现为用户…...
【Axure教程0基础入门】02高保真基础
02高保真基础 1.高保真原型的要素 (1)静态高保真原型图 尺寸:严格按照截图比例,参考线 色彩:使用吸取颜色,注意渐变色 贴图:矢量图/位图,截取,覆盖等 (…...

【GitHub项目推荐--常见的国内镜像】【转载】
由于国内网络原因,下载依赖包或者软件,对于不少互联网从业者来说,都有不小的挑战,时间浪费在这上边,实在可惜。这个项目介绍了常见依赖,软件的国内镜像,助力大家畅爽编码。 这是一个归纳梳理类…...
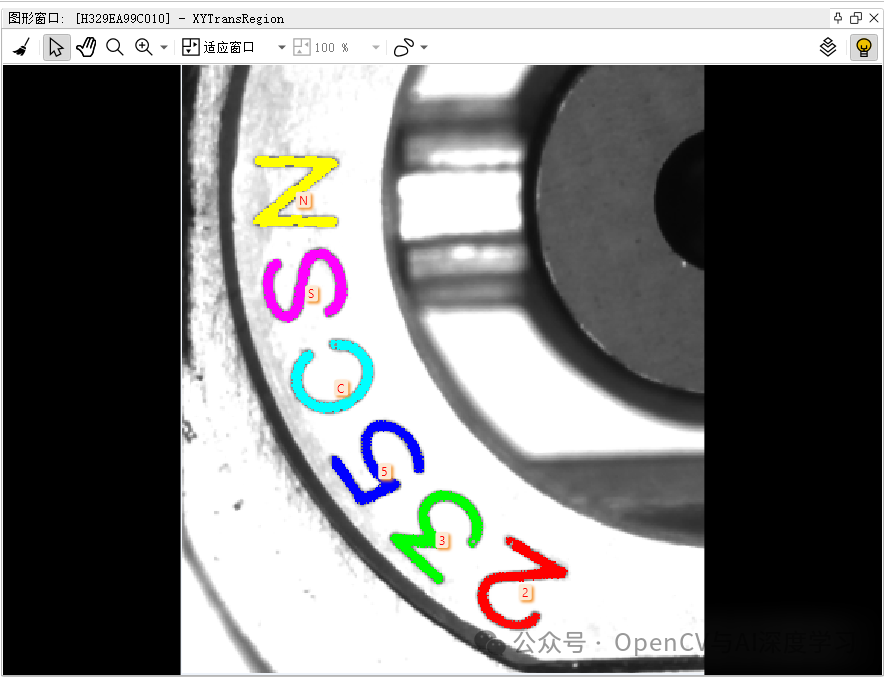
实战 | OpenCV+OCR实现弧形文字识别实例(详细步骤 + 源码)
导 读 本文主要介绍基于OpenCV+OCR实现弧形文字识别实例,并给详细步骤和代码。源码在文末。 背景介绍 测试图如下,目标是正确识别图中的字符。图片来源: https://www.51halcon.com/forum.php?mod=viewthread&tid=6712 同样,论坛中已经给出了Halcon实现代码,…...
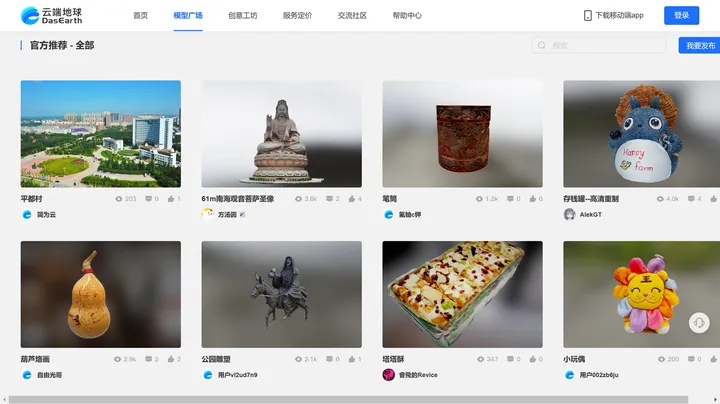
哪些 3D 建模软件值得推荐?
云端地球是一款免费的在线实景三维建模软件,不需要复杂的技巧,只要需要手机,多拍几张照片,就可以得到完整的三维模型! 无论是大场景倾斜摄影测量还是小场景、小物体建模,都可以通过云端地球将二维数据向三…...
AI论文指南|人大教授教你如何利用ChatGPT革新内容分析!【建议收藏】
点击下方▼▼▼▼链接直达AIPaperPass ! AIPaperPass - AI论文写作指导平台 公众号原文▼▼▼▼: AI论文指南|人大教授教你如何利用ChatGPT革新内容分析!【建议收藏】 目录 1.ChatGPT内容分析 2.书籍介绍 3.AIPaperPass智能论文写作平…...

leetcode 字符串相关题目
344. 反转字符串 - 力扣(LeetCode) 题解:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 541. 反转字符串 II - 力扣(LeetCode) 题解:https://leetcode.cn/problems/reverse-s…...

第二百九十一回
文章目录 1. 概念介绍2. 方法与细节2.1 实现方法2.2 具体细节 3. 示例代码4. 内容总结 我们在上一章回中介绍了"如何混合选择图片和视频文件"相关的内容,本章回中将介绍如何混合选择多个图片和视频文件.闲话休提,让我们一起Talk Flutter吧。 1…...
简化java代码:mapstruct + 策略模式
目录 目的 准备 注意 相同类型-属性名不同 实体类 映射 使用 验证-查看实现类 测试 不同类型(策略模式) 实体类 映射 工具类 使用:对象拷贝 验证-查看实现类 测试 使用:集合拷贝 测试 策略模式说明 准备-依赖 目的 简化 BeanUtils.…...

【Java】SpringMVC路径写法
1、多级路径 ✅类路径和方法路径都可以写成多级 ✅其中,类路径写在方法路径前面 ✅与Servlet不同,SpringMVC中写不写“/”都可以 RequestMapping("/hello/t1") RestController public class HelloSpring {RequestMapping( value "world…...

数据结构之生成树及最小生成树
数据结构之生成树及最小生成树 1、生成树概念2、最小生成树 数据结构是程序设计的重要基础,它所讨论的内容和技术对从事软件项目的开发有重要作用。学习数据结构要达到的目标是学会从问题出发,分析和研究计算机加工的数据的特性,以便为应用所…...

【java面试】常见问题(超详细)
目录 一、java常见问题JDK和JRE的区别是什么?Java中的String类是可变的还是不可变的?Java中的equals方法和hashCode方法有什么关系?Java中什么是重载【Overloading】?什么是覆盖【Overriding】?它们有什么区别…...

Labview for循环精讲
本文详细介绍Labview中For循环的使用方法,从所有细节让你透彻的看明白For循环是如何使用的,如果有帮助的话记得点赞加关注~ 1. For循环结构 从最简单的地方讲起,一个常用的for循环结构是由for循环结构框图、循环次数、循环计数(i)三部分组成…...

【STM32】STM32学习笔记-W25Q64简介(37)
00. 目录 文章目录 00. 目录01. SPI简介02. W25Q64简介03. 硬件电路04. W25Q64框图05. Flash操作注意事项06. 预留07. 附录 01. SPI简介 在大容量产品和互联型产品上,SPI接口可以配置为支持SPI协议或者支持I 2 S音频协议。SPI接口默认工作在SPI方式,可以…...

clickhouse数据库 使用http 方式交付查询sql
今天使用clickhouse 的HTTP 方式进行查询语句 clickhouse 服务 搭建在192.168.0.111 上面 那么我们如何快速的去查询呢 如下 我们可以使用curl 功能 或者直接在浏览器上输入对应的查询命令 如下: http://192.168.0.111:8123/userdefault&password123456&…...

深度学习-循环神经网络-RNN实现股价预测-LSTM自动生成文本
序列模型(Sequence Model) 基于文本内容及其前后信息进行预测 基于目标不同时刻状态进行预测 基于数据历史信息进行预测 序列模型:输入或者输出中包含有序列数据的模型 突出数据的前后序列关系 两大特点: 输入(输出)元素之间是具有顺序关系。不同的顺序,得到的结果应…...

案例分享 | 助力数字化转型:嘉为科技项目管理平台上线
嘉为科技项目管理平台(一期)基于易趋(EasyTrack)进行实施,通过近一年的开发及试运行,现已成功交付上线、推广使用,取得了良好的应用效果。 1.关于广州嘉为科技有限公司(以下简称嘉为…...

软阴影:那个让虚拟世界“温柔起来“的光影小秘密
一、从一只小猫的影子说起 前几天我在朋友家做客,他家养了一只胖乎乎的橘猫,正趴在阳台的窗边晒太阳。我无意间瞥了一眼那只猫脚边的影子,突然被一个细节震撼了—— 那只猫的影子——并不是一片均匀的黑。 仔细看——猫肚子紧贴地板的地方——…...

番茄小说下载器终极指南:三步构建你的离线阅读自由王国
番茄小说下载器终极指南:三步构建你的离线阅读自由王国 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否曾在地铁里读到精彩章节时突然断网?是否在…...

如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南
如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南 【免费下载链接】UAssetGUI A tool designed for low-level examination and modification of Unreal Engine game assets by hand. 项目地址: https://gitcode.com/gh_mirrors/ua/UAssetGUI UAss…...

DAIR-V2X-V数据集深度评测:与KITTI、nuScenes比,它到底强在哪?
DAIR-V2X-V数据集深度评测:与KITTI、nuScenes比,它到底强在哪? 当技术团队着手开发面向中国道路的自动驾驶系统时,数据集的选择往往成为第一个关键决策点。过去十年间,KITTI和nuScenes等国际数据集一直是行业标杆&…...

在模型广场灵活选型让我找到了更适合代码生成的Taotoken模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在模型广场灵活选型让我找到了更适合代码生成的Taotoken模型 开发代码辅助工具时,选择合适的模型是平衡效果与成本的关…...

机器学习在射电天文数据分类中的应用:以MIGHTEE巡天SFG/AGN分类为例
1. 项目概述:当机器学习遇见深空射电巡天在射电天文学领域,我们正经历一场数据洪流。以MeerKAT望远镜阵列主导的MIGHTEE巡天项目为例,其在COSMOS天区的一次早期科学数据释放,就在不到1平方度的天区内探测到了超过6000个射电源。传…...

ModernWMS核心功能详解:从ASN入库到Dispatch出库的完整工作流
ModernWMS核心功能详解:从ASN入库到Dispatch出库的完整工作流 【免费下载链接】ModernWMS The open source simple and complete warehouse management system is derived from our many years of experience in implementing erp projects. We stripped the origin…...
)
保姆级教程:手把手教你为ESXi 6.7配置主板BIOS(VT-x/VT-d/AES全开)
从零开始:ESXi 6.7主板BIOS设置完全指南当你第一次接触企业级虚拟化平台时,那种既兴奋又忐忑的心情我完全理解。作为过来人,我清楚地记得自己第一次为ESXi配置BIOS时的迷茫——那些专业术语像天书一样,生怕设置错误导致服务器无法…...

收藏干货|2026年程序员转型大模型指南,8个高薪岗位小白也能入局
分享一则身边真实职场经历,想必能戳中当下不少陷入职业迷茫的开发从业者。 同窗老友深耕Java后端开发整整六年,常年扎根业务开发模块,算得上行业内经验老道的技术老手。可从去年年初开始,他的职业焦虑感愈发强烈。传统业务开发同质…...

《关于 AI Agent 基础设施的一些奇思妙想》
目录 目录 目录 一、AI Agent 容器 问题背景 想法思路:API 中转站模式 多 Agent 切换 二、手机端操控 AI Agent(手机与电脑互联) 三、AI 开发依赖管理工具 总结 最近 AI Agent 越来越火,我作为一个重度使用者,…...