3. SQL 语言
MySQL 的 三种安装方式:包安装,二进制安装,源码编译安装。
SQL( Structured Query Language )结构化查询语言 是对 IBM 公司 San Jose,California 研究实验室的埃德加·科德的关系模型的第一个商业化语言实现。
这一模型在其 1970 年的一篇具有影响力的论文《一个对于大型共享型数据库的关系模型》中被描述。
尽管 SQL 并非完全按照科德的关系模型设计,但其依然成为最为广泛运用的数据库语言
1970 年代初,由埃德加·科德发表将资料组成表格的应用原则(Codd's Relational Algebra)
1974 年,同一实验室的 D.D.Chamberlin和R.F. Boyce对Codd's Relational Algebra在研制关系数据库管理系统 System R 中,研制出一套规范语言-SEQUEL(Structured English Query Language)
1976 年 11 月的IBM Journal of R&D 上公布新版本的SQL(叫SEQUEL/2)。1980年改名为 SQL
1979 年 ORACLE 公司首先提供商用的 SQL,IBM 公司在 DB2 和 SQL/DS 数据库系统中也实现了 SQL
1986 年 10 月美国国家标准学会 ANSI 采用 SQL 作为关系数据库管理系统的标准语言(ANSI X3. 135-1986)
1989 年美国 ANSI 采纳在 ANSI X3.135-1989 报告中定义的关系数据库管理系统的 SQL 标准语言,称为 ANSI SQL 89
后续 SQL 标准经过了一系列的增订,加入了大量新特性,有各种版本:ANSI SQL,SQL-1986,SQL-1989,SQL-1992, SQL-1999,SQL-2003,SQL-2008,SQL-2011
目前,所有主要的关系数据库管理系统支持某些形式的 SQL,大部分数据库至少遵守 ANSI SQL89 标准虽然有这一标准的存在,但大部分的 SQL 代码在不同的数据库系统中并不具有完全的跨平台性业内标准微软和 Sybase 的 T-SQL,Oracle 的 PL/SQL
关键词不能跨多行或简写 ( 比如:SELECT 这个你不能分成多行写 )
#单行注释, 注意有空格-- 注释内容#多行注释/*注释内容注释内容注释内容*/MySQL 注释:# 注释内容数据库、表、索引、视图、用户、存储过程、函数、触发器、事件调度器等
必须以字母开头,后续可以包括字母,数字和三个特殊字符(# _ $)
不要使用 MySQL 的保留字( 避免使用 MySQL 的关键字 )
DDL:Data Defination Language( 数据定义语言 )
DML:Data Manipulation Language( 数据操纵语言 )
DQL:Data Query Language( 数据查询语言 )
DCL:Data Control Language( 数据控制语言 )
TCL:Transaction Control Language( 事务控制语言 )
关健字 Keyword 组成子句 clause,多条 clause 组成语句
说明:一组 SQL 语句由三个子句构成,SELECT,FROM 和 WHERE 是关键字
FROM products # FROM 子句
WHERE price>666 # WHERE 子句
官方帮助:MySQL :: MySQL 8.0 Reference Manual :: 13 SQL Statements
mysql> HELP KEYWORD'例如'mysql> HELP SELECTmysql> HELP CREATEmysql> HELP CREATE DATABASE
参考:滑动验证页面
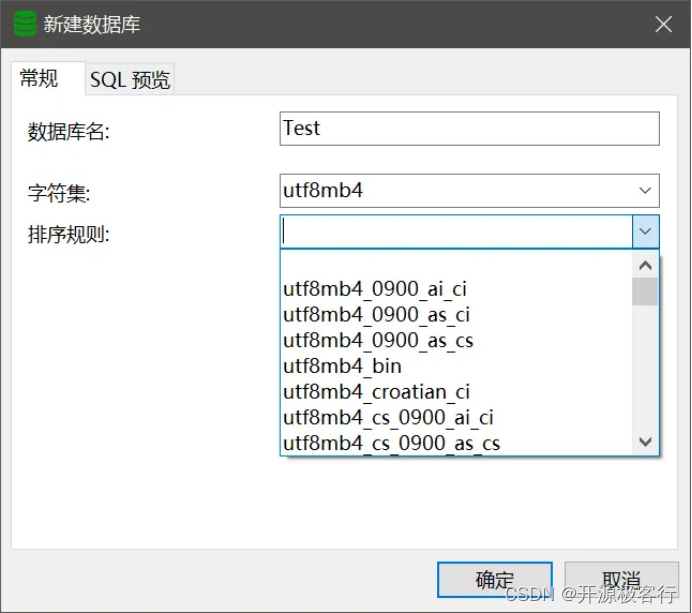
MySQL 在创建数据库是,需要设置数据库的 字符集 和 排序规则,如图所示:
说到字符集,需要先提下 字符、字符集 和 字符编码 这几个词的含义。
字符(Character):是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
字符集(Character set):是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同,常见字符集名称:ASCII 字符集、GB2312 字符集、BIG5 字符集、 GB18030 字符集、Unicode 字符集等。
字符编码:是把字符集中的字符编码为特定的二进制数,以便在计算机中存储。编码方式一般就是对二维表的横纵坐标进行变换的算法。一般都比较简单,直接把横纵坐标拼一起就完事了。后来随着字符集的不断扩大,为了节省存储空间,才出现了各种各样的算法。
MySQL 中常用的排序规则( 这里以 utf8 字符集为例)主要有:utf8_general_ci、utf8_general_cs、utf8_unicode_ci 等。
ci 的完整英文是 'Case Insensitive',即 大小写不敏感,a 和 A 会在字符判断中会被当做一样的;
cs 的完整英文是 'Case Sensitive',即 大小写敏感,a 和 A 会有区分;
MySQL 有 4 个级别的 字符集 和 排序规则,分别是:
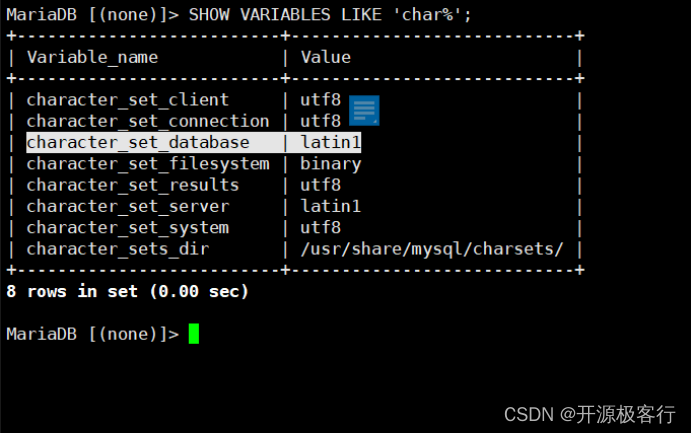
服务器级别( server ):可以通过设置 character_set_server 和 collation_server 系统变量指定服务器字符集和排序规则;
数据库级别( database ):给数据库指定字符集和排序规则;
列级别( column ):同一个表中不同的列也可以有不同的字符集和排序规则。
注意:从 MySQL8.0 开始默认字符集已经为 utf8mb4
UTF-8( 8-bit Unicode Transformation Format )是一种针对 Unicode 的可变长度字符编码,又称 万国码。
utf8mb4:存储 emoji 符号和一些比较复杂的汉字、繁体字
| 字符集 | 说明 | |
| 2 | ||
| UTF-8 | 支持中英文混合场景,是国际通用字符集 | |
| 1 | ||
| utf8mb4 |
SHOW CHARSET;
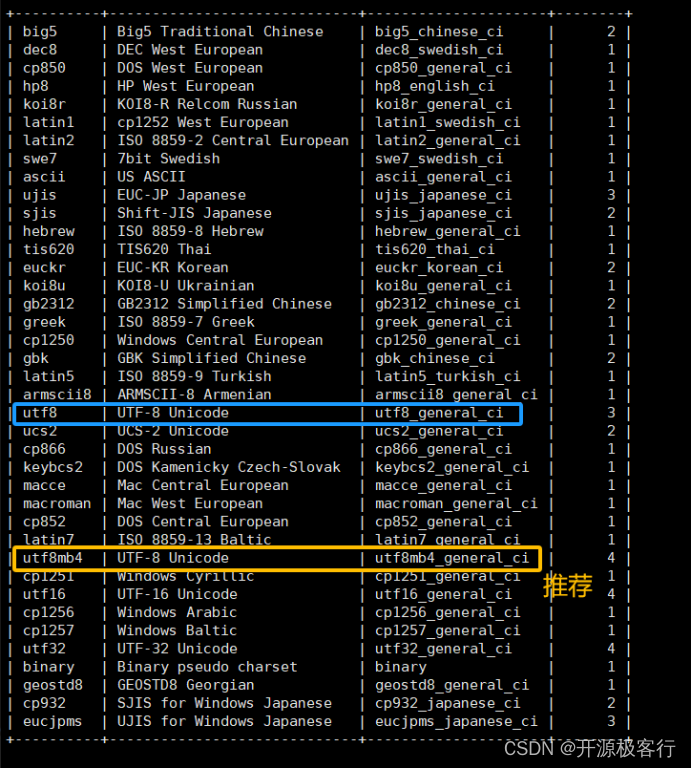
// 注意
utf8_general_ci // 不区分大小写 ( utf8mb4 字符集的默认排序规则 )
utf8_bin // 区分大小写
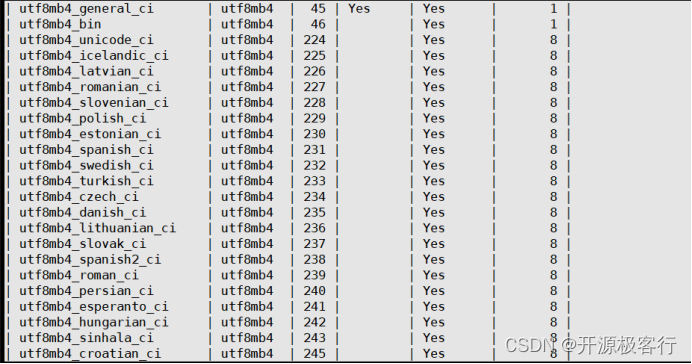
因此:蓝色框选部分表示 big5 字符集有两个排序规则,当前 Big5 字符集的默认排序规则为 big5_chinese_ci
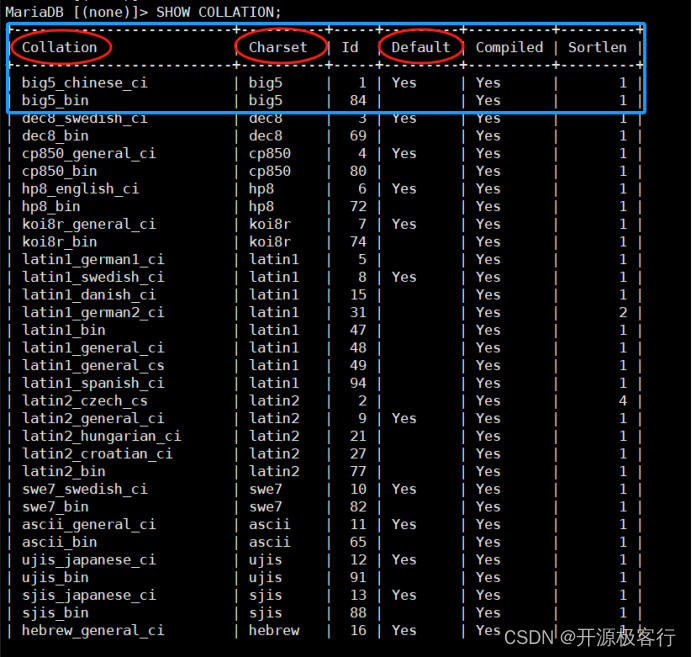
因此如下表示 utf8mb4 字符集有 23 个排序规则,当前 utf8mb4 字符集的默认排序规则为 utf8mb4_general_ci
MySQL 8.0 默认使用的 字符集 就是 utf8mb4

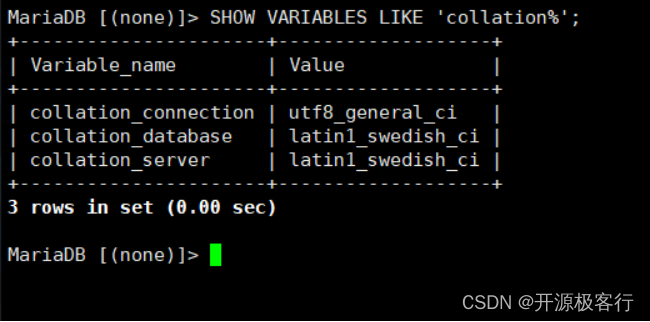
SHOW VARIABLES LIKE 'collation%';
vim /etc/my.cnf// 针对 MySQL 服务端[mysqld]character-set-server=utf8mb4// 重启服务systemctl restart mariadb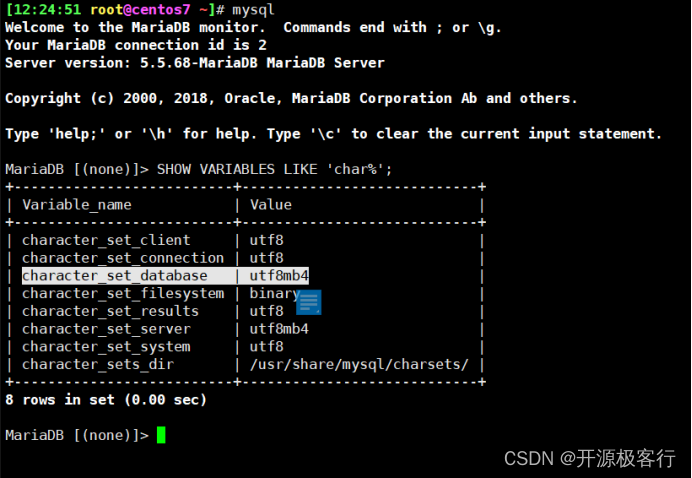
vim /etc/my.cnf// 针对 MySQL 客户端[mysql]default-character-set=utf8mb4// 针对所有 MySQL 客户端[client]default-character-set=utf8mb4// 重启服务systemctl restart mariadb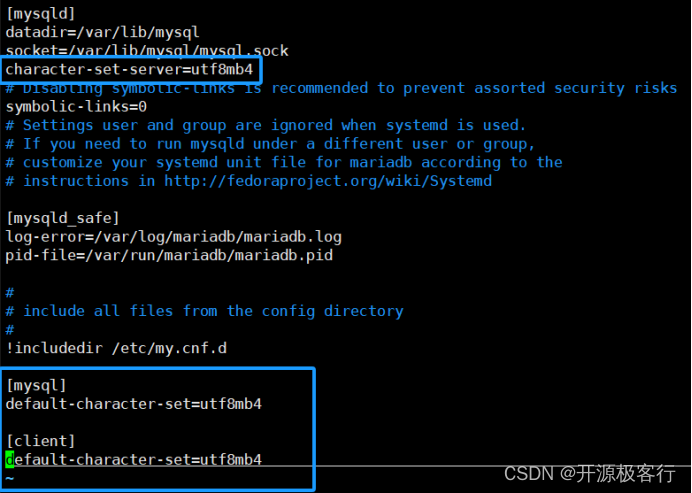

1. 创建数据库 db1CREATE DATABASE db1;2. 显示数据库 db1 的创建语句SHOW CREATE DATABASE db1;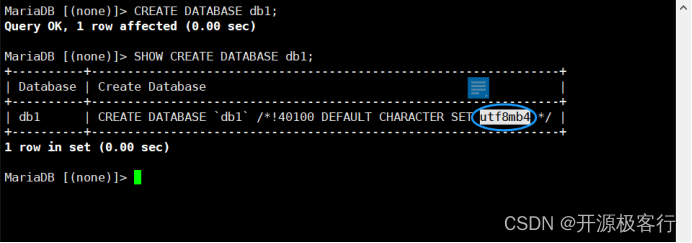
比如 默认字符集、排序规则、存储引擎 等等。

mysql> SHOW CHARACTER SET;+----------+---------------------------------+---------------------+--------+| Charset | Description | Default collation | Maxlen |+----------+---------------------------------+---------------------+--------+| armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 || ascii | US ASCII | ascii_general_ci | 1 || big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 || binary | Binary pseudo charset | binary | 1 || cp1250 | Windows Central European | cp1250_general_ci | 1 || cp1251 | Windows Cyrillic | cp1251_general_ci | 1 || cp1256 | Windows Arabic | cp1256_general_ci | 1 || cp1257 | Windows Baltic | cp1257_general_ci | 1 || cp850 | DOS West European | cp850_general_ci | 1 || cp852 | DOS Central European | cp852_general_ci | 1 || cp866 | DOS Russian | cp866_general_ci | 1 || cp932 | SJIS for Windows Japanese | cp932_japanese_ci | 2 || dec8 | DEC West European | dec8_swedish_ci | 1 || eucjpms | UJIS for Windows Japanese | eucjpms_japanese_ci | 3 || euckr | EUC-KR Korean | euckr_korean_ci | 2 || gb18030 | China National Standard GB18030 | gb18030_chinese_ci | 4 || gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci | 2 || gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 || geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 || greek | ISO 8859-7 Greek | greek_general_ci | 1 || hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 || hp8 | HP West European | hp8_english_ci | 1 || keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 || koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 || koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 || latin1 | cp1252 West European | latin1_swedish_ci | 1 || latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 || latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 || latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 || macce | Mac Central European | macce_general_ci | 1 || macroman | Mac West European | macroman_general_ci | 1 || sjis | Shift-JIS Japanese | sjis_japanese_ci | 2 || swe7 | 7bit Swedish | swe7_swedish_ci | 1 || tis620 | TIS620 Thai | tis620_thai_ci | 1 || ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 || ujis | EUC-JP Japanese | ujis_japanese_ci | 3 || utf16 | UTF-16 Unicode | utf16_general_ci | 4 || utf16le | UTF-16LE Unicode | utf16le_general_ci | 4 || utf32 | UTF-32 Unicode | utf32_general_ci | 4 || utf8 | UTF-8 Unicode | utf8_general_ci | 3 || utf8mb4 | UTF-8 Unicode | utf8mb4_0900_ai_ci | 4 |+----------+---------------------------------+---------------------+--------+41 rows in set (0.01 sec)[root@centos8 ~] ll /usr/share/mysql/charsets/total 240-rw-r--r--. 1 root root 5961 Jul 1 2021 armscii8.xml-rw-r--r--. 1 root root 5947 Jul 1 2021 ascii.xml-rw-r--r--. 1 root root 8676 Jul 1 2021 cp1250.xml-rw-r--r--. 1 root root 8762 Jul 1 2021 cp1251.xml-rw-r--r--. 1 root root 6010 Jul 1 2021 cp1256.xml-rw-r--r--. 1 root root 9343 Jul 1 2021 cp1257.xml-rw-r--r--. 1 root root 5947 Jul 1 2021 cp850.xml-rw-r--r--. 1 root root 5963 Jul 1 2021 cp852.xml-rw-r--r--. 1 root root 6054 Jul 1 2021 cp866.xml-rw-r--r--. 1 root root 6970 Jul 1 2021 dec8.xml-rw-r--r--. 1 root root 5957 Jul 1 2021 geostd8.xml-rw-r--r--. 1 root root 6169 Jul 1 2021 greek.xml-rw-r--r--. 1 root root 5952 Jul 1 2021 hebrew.xml-rw-r--r--. 1 root root 5943 Jul 1 2021 hp8.xml-rw-r--r--. 1 root root 19474 Jul 1 2021 Index.xml-rw-r--r--. 1 root root 5970 Jul 1 2021 keybcs2.xml-rw-r--r--. 1 root root 5951 Jul 1 2021 koi8r.xml-rw-r--r--. 1 root root 6973 Jul 1 2021 koi8u.xml-rw-r--r--. 1 root root 10251 Jul 1 2021 latin1.xml-rw-r--r--. 1 root root 7673 Jul 1 2021 latin2.xml-rw-r--r--. 1 root root 5950 Jul 1 2021 latin5.xml-rw-r--r--. 1 root root 7879 Jul 1 2021 latin7.xml-rw-r--r--. 1 root root 8488 Jul 1 2021 macce.xml-rw-r--r--. 1 root root 8499 Jul 1 2021 macroman.xml-rw-r--r--. 1 root root 1749 Jul 1 2021 README-rw-r--r--. 1 root root 6971 Jul 1 2021 swe7.xmlMariaDB [(none)]> SELECT VERSION();+-----------------+| VERSION() |+-----------------+| 10.3.17-MariaDB |+-----------------+1 row in set (0.000 sec)MariaDB [(none)]> show variables like 'character%';+--------------------------+------------------------------+| Variable_name | Value |+--------------------------+------------------------------+| character_set_client | utf8 || character_set_connection | utf8 || character_set_database | latin1 || character_set_filesystem | binary || character_set_results | utf8 || character_set_server | latin1 || character_set_system | utf8 || character_sets_dir | /usr/share/mariadb/charsets/ |+--------------------------+------------------------------+8 rows in set (0.003 sec)MariaDB [(none)]> SHOW VARIABLES LIKE 'collation%';+----------------------+-------------------+| Variable_name | Value |+----------------------+-------------------+| collation_connection | utf8_general_ci | | collation_database | latin1_swedish_ci || collation_server | latin1_swedish_ci |+----------------------+-------------------+3 rows in set (0.001 sec)mysql> SELECT VERSION();+-----------+| VERSION() |+-----------+| 8.0.17 |+-----------+1 row in set (0.00 sec)mysql> show variables like 'character%';+--------------------------+----------------------------+| Variable_name | Value |+--------------------------+----------------------------+| character_set_client | utf8mb4 || character_set_connection | utf8mb4 || character_set_database | utf8mb4 || character_set_filesystem | binary || character_set_results | utf8mb4 || character_set_server | utf8mb4 || character_set_system | utf8 || character_sets_dir | /usr/share/mysql/charsets/ |+--------------------------+----------------------------+8 rows in set (0.01 sec)mysql> show variables like 'collation%';+----------------------+--------------------+| Variable_name | Value |+----------------------+--------------------+| collation_connection | utf8mb4_0900_ai_ci || collation_database | utf8mb4_0900_ai_ci || collation_server | utf8mb4_0900_ai_ci |+----------------------+--------------------+3 rows in set (0.00 sec)CREATE DATABASE|SCHEMA [IF NOT EXISTS] 'DB_NAME'CHARACTER SET 'character set name'COLLATE 'collate name';
// 不指定字符集创建数据库 ( 低版本 MySQL 数据库会默认使用 latin1 字符集 )MariaDB [(none)]> create database db1;Query OK, 1 row affected (0.001 sec)
// 查看指定数据库字符集信息MariaDB [(none)]> show create database db1;+----------+----------------------------------------------------------------+| Database | Create Database |+----------+----------------------------------------------------------------+| db1 | CREATE DATABASE `db1` /*!40100 DEFAULT CHARACTER SET latin1 */ |+----------+----------------------------------------------------------------+1 row in set (0.000 sec)// 也可以使用该方式查看[root@centos7 ~] cat /var/lib/mysql/db1/db.optdefault-character-set=latin1default-collation=latin1_swedish_ci// 创建已经存在的数据库名称 ( 报错 )MariaDB [(none)]> create database db1;ERROR 1007 (HY000): Cant create database 'db1'; database exists// 我们可以使用如下方法创建// 关键字 IF NOT EXISTS 的作用// 是在执行创建数据库的操作之前检查数据库是否已经存在, 如果数据库已经存在// 则不会执行创建操作, 避免出现重复创建同名数据库的错误.MariaDB [(none)]> create database IF NOT EXISTS db1;Query OK, 0 rows affected, 1 warning (0.001 sec)MariaDB [(none)]> show warnings;+-------+------+----------------------------------------------+| Level | Code | Message |+-------+------+----------------------------------------------+| Note | 1007 | Can't create database 'db1'; database exists |+-------+------+----------------------------------------------+1 row in set (0.000 sec)// 指定字符集 创建新数据库MariaDB [(none)]> create database IF NOT EXISTS db2 CHARACTER SET 'utf8';Query OK, 1 row affected (0.000 sec)// 查看指定数据库字符集信息MariaDB [(none)]> SHOW CREATE DATABASE db2;+----------+--------------------------------------------------------------+| Database | Create Database |+----------+--------------------------------------------------------------+| db2 | CREATE DATABASE `db2` /*!40100 DEFAULT CHARACTER SET utf8 */ |+----------+--------------------------------------------------------------+1 row in set (0.00 sec)// 也可以使用该方式查看[root@centos7 ~] cat /var/lib/mysql/db2/db.optdefault-character-set=utf8default-collation=utf8_general_ci// 可以用以下简写 ( 建议 )mysql> create database test1 charset=utf8;Query OK, 1 row affected, 1 warning (0.00 sec)// 查看指定数据库字符集信息MariaDB [(none)]> show create database test1;+----------+----------------------------------------------------------------+| Database | Create Database |+----------+----------------------------------------------------------------+| test1 | CREATE DATABASE `test1` /*!40100 DEFAULT CHARACTER SET utf8 */ |+----------+----------------------------------------------------------------+1 row in set (0.00 sec)因此,这条命令将创建一个名为 zabbix 的数据库,使用 UTF-8 字符集存储数据,并使用区分大小写的二进制排序规则。
mysql> create database zabbix character set utf8 collate utf8_bin;
[root@centos8 ~] docker run --name mysql-server -t \-e MYSQL_DATABASE="zabbix" \-e MYSQL_USER="zabbix" \-e MYSQL_PASSWORD="zabbix_pwd" \-e MYSQL_ROOT_PASSWORD="root_pwd" \-d mysql:5.7 \--character-set-server=utf8 --collation-server=utf8_bin[root@centos8 ~] docker run -d -p 3306:3306 --name mysql \-e MYSQL_ROOT_PASSWORD=123456 \-e MYSQL_DATABASE=jumpserver-e MYSQL_USER=jumpserver-e MYSQL_PASSWORD=123456 -v /data/mysql:/var/lib/mysql-v /etc/mysql/mysql.conf.d/mysqld.cnf:/etc/mysql/mysql.conf.d/mysqld.cnf \-v /etc/mysql/conf.d/mysql.cnf:/etc/mysql/conf.d/mysql.cnfmysql:5.7.30ALTER DATABASE DB_NAME character set utf8;
// 修改名为 db1 的数据库的字符集嘻嘻和排序规则MariaDB [(none)]> ALTER DATABASE db1 character set utf8 COLLATE utf8_bin;Query OK, 1 row affected (0.001 sec)// 验证MariaDB [(none)]> show create database db1;+----------+-------------------------------------------------------------------------------+| Database | Create Database |+----------+-------------------------------------------------------------------------------+| db1 | CREATE DATABASE `db1` /*!40100 DEFAULT CHARACTER SET utf8 COLLATE utf8_bin */ |+----------+-------------------------------------------------------------------------------+1 row in set (0.00 sec)// 验证[root@centos7 ~] cat /var/lib/mysql/db1/db.optdefault-character-set=utf8default-collation=utf8_bin
DROP DATABASE|SCHEMA [IF EXISTS] 'DB_NAME';// 删库MariaDB [(none)]> drop database db1;Query OK, 0 rows affected (0.002 sec)// 跑路 MariaDB [(none)]> show databases;+--------------------+| Database |+--------------------+| information_schema || mysql || performance_schema |+--------------------+3 rows in set (0.000 sec)// 数据库文件夹也随之消失[root@centos7 ~] ls /var/lib/mysql/MariaDB [(none)]> show databases;+--------------------+| Database |+--------------------+| information_schema || mysql || performance_schema |+--------------------+3 rows in set (0.000 sec)数据类型参考链接:MySQL :: MySQL 8.0 Reference Manual :: 11 Data Types
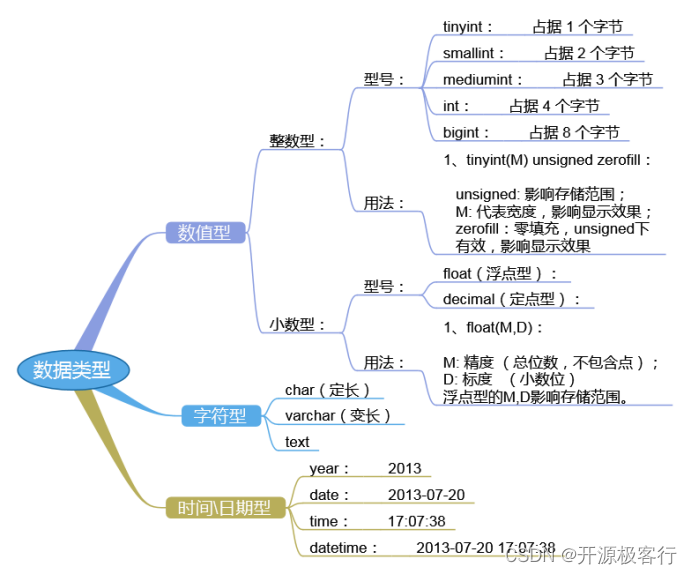
尽量避免 NULL,包含为 NULL 的列,对 MySQL 更难优化
tinyint(m) 1 个字节范围( -128~127 )0 ~ 255举例:年龄
smallint(m)2 个字节范围( -32768~32767 )0 ~ 65535举例:端口
mediumint(m)3 个字节范围( -8388608~8388607 )0 ~ 16777215举例:年薪
int(m) 4 个字节范围( -2147483648~2147483647 )0 ~ 4294967295
bigint(m) 8 个字节范围( +-9.22*10 的 18 次方 )
注意:上述数据类型,如果加修饰符 unsigned 后,则最大值翻倍。

如:tinyint unsigned 的取值范围为( 0 ~ 255 )
int(m)里的 m 是表示 SELECT 查询结果集中的显示宽度,并不影响实际的取值范围,规定了 MySQL 的一些交互工具( 例如 MySQL 命令行客户端 )用来显示字符的个数。对于存储和计算来说,Int(1)和 Int(20)是相同的 BOOL,BOOLEAN:布尔型,是 TINYINT(1)的同义词。zero 值被视为假,非 zero 值视为真。
3.4.2)浮点型( float 和 double ),近似值
float(m,d)单精度浮点型 8 位精度(4字节) m 总个数,d 小数位
double(m,d)双精度浮点型 16 位精度( 8字节)m 总个数,d 小数位
设一个字段定义为 float(6,3),如果插入一个数 123.45678,实际数据库里存的是123.457,但总个数还以实际为准,即 6 位。
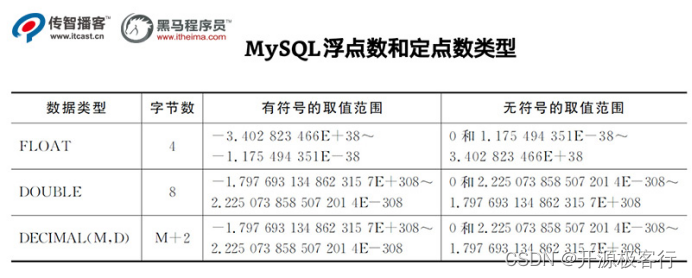
格式 decimal(m,d) 表示:最多 m 位数字,其中 d 个小数,小数点不算在长度内。
比如:DECIMAL(6,2)总共能存 6 位数字,末尾 2 位是小数,字段最大值 9999.99( 小数点不算在长度内 )参数 m<65 是总个数,d<30 且 d<m 是小数位。
MySQL5.0 和更高版本将数字打包保存到一个二进制字符串中( 每 4 个字节存 9 个数字 )。
例如:decimal(18,9)小数点两边将各存储 9 个数字,一共使用 9 个字节:其中,小数点前的 9 个数字用 4 个字节,小数点后的 9 个数字用 4 个字节,小数点本身占 1 个字节。
浮点类型在存储同样范围的值时,通常比 decimal 使用更少的空间。float 使用 4 个字节存储。double 占用 8 个字节。
因为需要额外的空间和计算开销,所以应该尽量只在对小数进行精确计算时才使用 decimal,例如存储财务数据。但在数据量比较大的时候,可以考虑使用 bigint 代替 decimal。
mediumtext 可变长度,最多 2 的 24 次方 -1 个字符
longtext 可变长度,最多 2 的 32 次方 -1 个字符
BINARY(M)固定长度,可存二进制或字符,长度为 0-M 字节
VARBINARY(M)可变长度,可存二进制或字符,允许长度为 0-M 字节

参考:MySQL :: MySQL 8.0 Reference Manual :: 11.3.2 The CHAR and VARCHAR Types
使用 固定长度 存储数据,无论实际存入多少字符,都将占用固定数量的存储空间。比如 CHAR(4) 类型无论存入几个字符,都会占用 4 个字节。
当存入的字符串长度少于指定长度时,系统会自动用空格填充至指定长度。
查询时末尾的空格会被自动去除,因此 CHAR 类型的字符串末尾不能包含空格。
由于是固定长度,对于定长数据的查询速度通常比 VARCHAR 类型更快。
存储长度是可变的,根据实际存入的字符数加 1 个字节来计算存储空间。
节省存储空间,但可能因为变长而在某些情况下对查询速度稍慢一些。
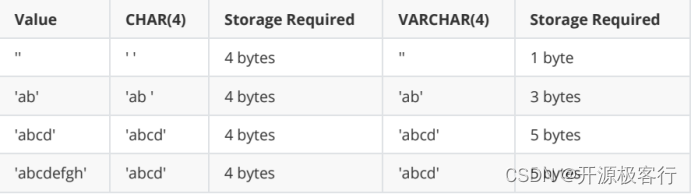
char 类型是 固定长度[ 根据定义的字符串长度分配足够的空间 ]不够灵活
varchar 类型是 可变长度的[ 只使用字符串长度所需要的空间 ]灵活


面试题:varchar(50) 能存放几个 UTF8 编码的汉字?
MySQL 5.0 以上版本, varchar(50) 指的是 50 字符, 无论存放的是数字, 字母还是 UTF8 编码的汉字, 都可以存放 50 个
// 存放的汉字个数与版本相关1) mysql 4.0 以下版本, varchar(50) 指的是 50 字节, 如果存放 UTF8 格式编码的汉字时 (每个汉字 3 字节), 只能存放 16 个.2) mysql 5.0 以上版本, varchar(50) 指的是 50 字符, 无论存放的是数字, 字母还是 UTF8 编码的汉字, 都可以存放 50 个.BLOB 和 TEXT 存储方式不同,TEXT 以文本方式存储,英文存储区分大小写,而 Blob 以二进制方式存储,不分大小写。
datetime 日期时间 '2008-12-2 22:06:44'
timestamp 此字段里的时间数据会随其他字段修改的时候自动刷新,这个数据类型的字段可以存放这条记录最后被修改的时间。
PRIMARY KEY 主键,所有记录中此字段的值不能重复,且不能为 NULL
UNIQUE KEY 唯一键,所有记录中此字段的值不能重复,但可以为 NULL
AUTO_INCREMENT 自动递增,适用于整数类型。必须作用于某个 key 的字段,比如 primary key。( 举例:ID 号 )
MariaDB [hellodb]> SHOW VARIABLES LIKE 'auto_inc%';+--------------------------+-------+| Variable_name | Value |+--------------------------+-------+| auto_increment_increment | 1 || auto_increment_offset | 1 |+--------------------------+-------+2 rows in set (0.001 sec)// auto_increment_offset 定义初始值// auto_increment_increment 定义步进mysql> create database test;Query OK, 1 row affected (0.00 sec)mysql> use testDatabase changedmysql> create table t1(id int unsigned auto_increment primary key)auto_increment = 4294967294;Query OK, 0 rows affected (0.01 sec)MariaDB [db1]> show table status from db1 like "t1" \G*************************** 1. row ***************************Name: t1Engine: InnoDBVersion: 10Row_format: DynamicRows: 0Avg_row_length: 0Data_length: 16384Max_data_length: 0Index_length: 0Data_free: 0Auto_increment: 4294967294Create_time: 2021-01-29 16:22:00Update_time: NULLCheck_time: NULLCollation: latin1_swedish_ciChecksum: NULLCreate_options:Comment:Max_index_length: 0Temporary: N1 row in set (0.000 sec)MariaDB [db1]>mysql> insert into t1 values(null);Query OK, 1 row affected (0.01 sec)mysql> select * from t1;+------------+| id |+------------+| 4294967294 |+------------+1 row in set (0.00 sec)mysql> insert into t1 values(null); Query OK, 1 row affected (0.00 sec)mysql> select * from t1;+------------+| id |+------------+| 4294967294 || 4294967295 |+------------+2 rows in set (0.00 sec)mysql> insert into t1 values(null); ERROR 1062 (23000): Duplicate entry '4294967295' for key 'PRIMARY'MariaDB [testdb]> insert t1 value(null);ERROR 167 (22003): Out of range value for column 'id' at row 1# 上面表的数据类型无法存放所有数据,修改过数据类型实现MariaDB [db1]> alter table t1 modify id bigint auto_increment;Query OK, 2 rows affected (0.023 sec)Records: 2 Duplicates: 0 Warnings: 0MariaDB [db1]> desc t1;+-------+------------+------+-----+---------+----------------+| Field | Type | Null | Key | Default | Extra |+-------+------------+------+-----+---------+----------------+| id | bigint(20) | NO | PRI | NULL | auto_increment |+-------+------------+------+-----+---------+----------------+1 row in set (0.001 sec)MariaDB [db1]> insert t1 values(null);Query OK, 1 row affected (0.001 sec)MariaDB [db1]> select * from t1;+------------+| id |+------------+| 4294967294 || 4294967295 || 4294967296 |+------------+3 rows in set (0.000 sec)相关文章:
3. SQL 语言
重点: MySQL 的 三种安装方式:包安装,二进制安装,源码编译安装。 MySQL 的 基本使用 MySQL 多实例 DDLcreate alter drop DML insert update delete DQL select 3)SQL 语言 3.1)关系型数据库的常见…...
Android音量调节修改
前言 今日公司,安卓设备的音量显示不正常,让我来修复这个bug,现在已修复,做个博客,记录一下,以后碰到类似一下子就好解决。 Android音量调节相关 路径 frameworks\base\services\core\java\com\android…...

九州金榜|为什么鼓励式家庭教育?
鼓励式教育是一种积极的教育方式,它强调通过鼓励和肯定来激发孩子的积极性和自信心,帮助孩子更好地成长和发展。在家庭教育中,鼓励式教育同样具有重要意义。九州金榜家庭教育和大家一起探讨关于鼓励式教育的好处以及意义: 一.有助…...

Java复习系列之阶段二:数据库
1. 基础语法 1.1 DQL(数据查询语句) 执行顺序: from、join 、on、where、group by、having、select、distinct、order by、limit 1.2 DML(数据修改语言) 对数据表的增删改 insert into update set delete form 1.…...
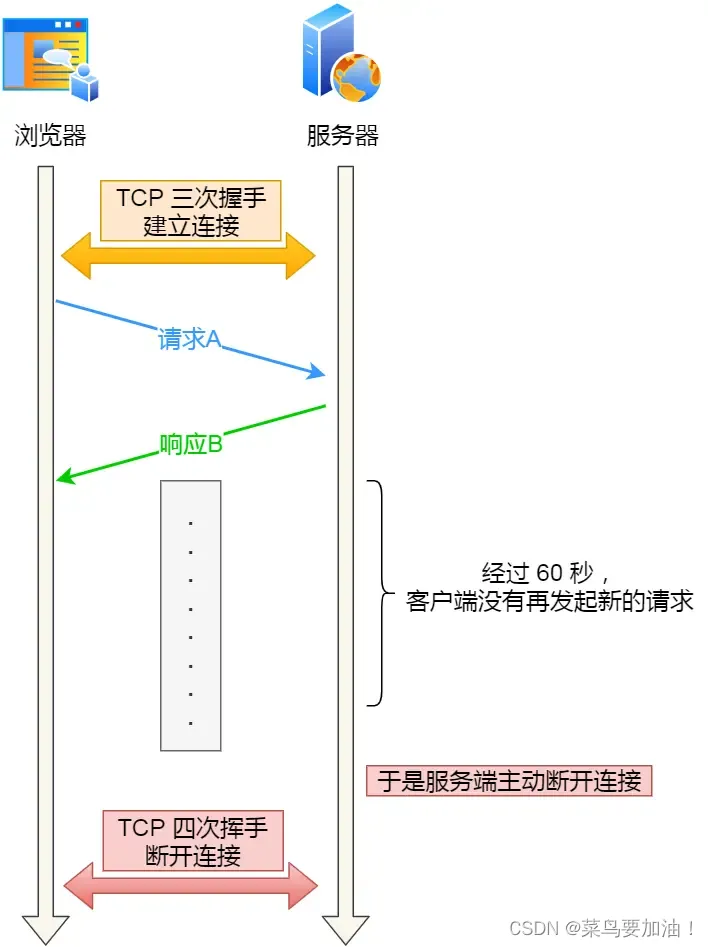
TCP 异常断开连接【重点】
参考链接 https://xiaolincoding.com/network/3_tcp/tcp_down_and_crash.html https://xiaolincoding.com/network/3_tcp/tcp_unplug_the_network_cable.html#%E6%8B%94%E6%8E%89%E7%BD%91%E7%BA%BF%E5%90%8E-%E6%9C%89%E6%95%B0%E6%8D%AE%E4%BC%A0%E8%BE%93 关键词:…...

Biotin-PEG4-TSA,生物素-PEG4-酪胺,用于标记蛋白质、核酸等生物分子
您好,欢迎来到新研之家 文章关键词:Biotin-PEG4-Tyramide,Biotin-PEG4-TSA,生物素-PEG4-酪胺,Biotin PEG4 Tyramide,Biotin PEG4 TSA 一、基本信息 产品简介:Biotin PEG4 Tyramide is compos…...
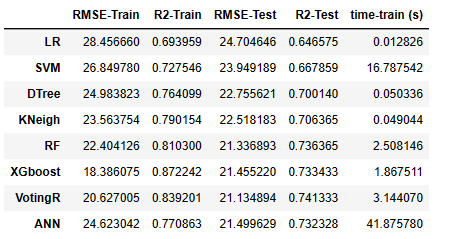
Python环境下基于机器学习的NASA涡轮风扇发动机剩余使用寿命RUL预测
本例所用的数据集为C-MAPSS数据集,C-MAPSS数据集是美国NASA发布的涡轮风扇发动机数据集,其中包含不同工作条件和故障模式下涡轮风扇发动机多源性能的退化数据,共有 4 个子数据集,每个子集又可分为训练集、 测试集和RUL标签。其中&…...
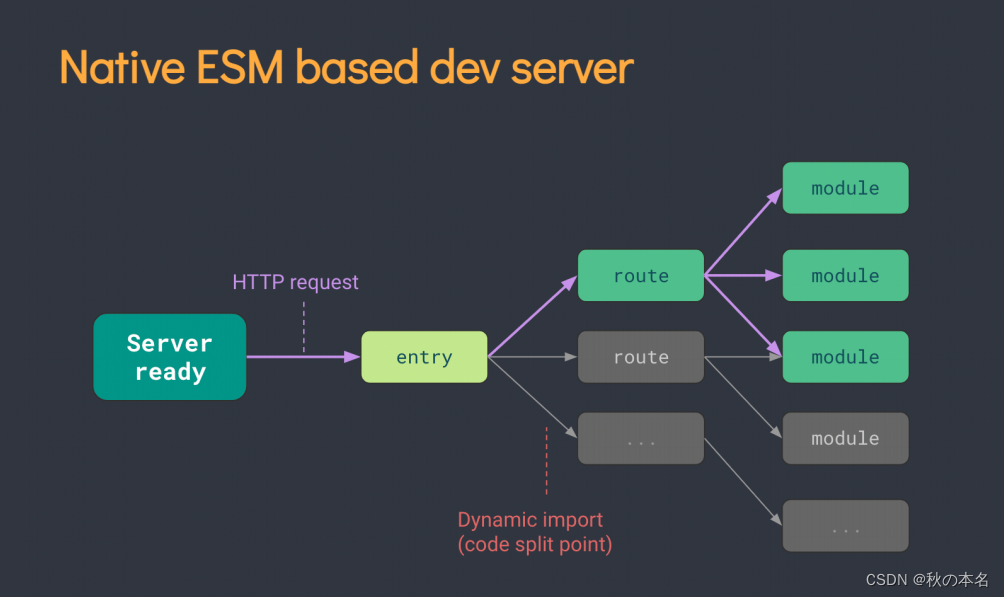
Vite学习指南
那本课程都适合哪些人群呢? 想要学习前端工程化,在新项目中投入使用 Vite 构建工具的朋友 Webpack 转战到 Vite 的小伙伴 前端架构师们,可以充实自己的工具箱 当然如果你没有项目相关开发经验,也可以从本课程中受益࿰…...

无人机在三维空间中的转动问题
前提 这篇博客是对最近一个有关无人机拍摄图像项目中所学到的新知识的一个总结,比较杂乱,没有固定的写作顺序。 无人机坐标系旋转问题 上图是无人机坐标系,绕x轴是翻滚(Roll),绕y轴是俯仰(Pitch),绕z轴是偏航(Yaw)。…...
鸿蒙开发初体验
文章目录 前言一、环境配置1.1 安装DevEco Studio1.2 安装相关环境 二、工程创建三、工程结构介绍四、代码实现4.1 初识ArkTs4.2 具体实现 参考资料 前言 HarmonyOS是华为公司推出的一种操作系统,旨在为不同设备提供统一的操作系统和开发平台。鸿蒙开发的出现为用户…...
【Axure教程0基础入门】02高保真基础
02高保真基础 1.高保真原型的要素 (1)静态高保真原型图 尺寸:严格按照截图比例,参考线 色彩:使用吸取颜色,注意渐变色 贴图:矢量图/位图,截取,覆盖等 (…...

【GitHub项目推荐--常见的国内镜像】【转载】
由于国内网络原因,下载依赖包或者软件,对于不少互联网从业者来说,都有不小的挑战,时间浪费在这上边,实在可惜。这个项目介绍了常见依赖,软件的国内镜像,助力大家畅爽编码。 这是一个归纳梳理类…...
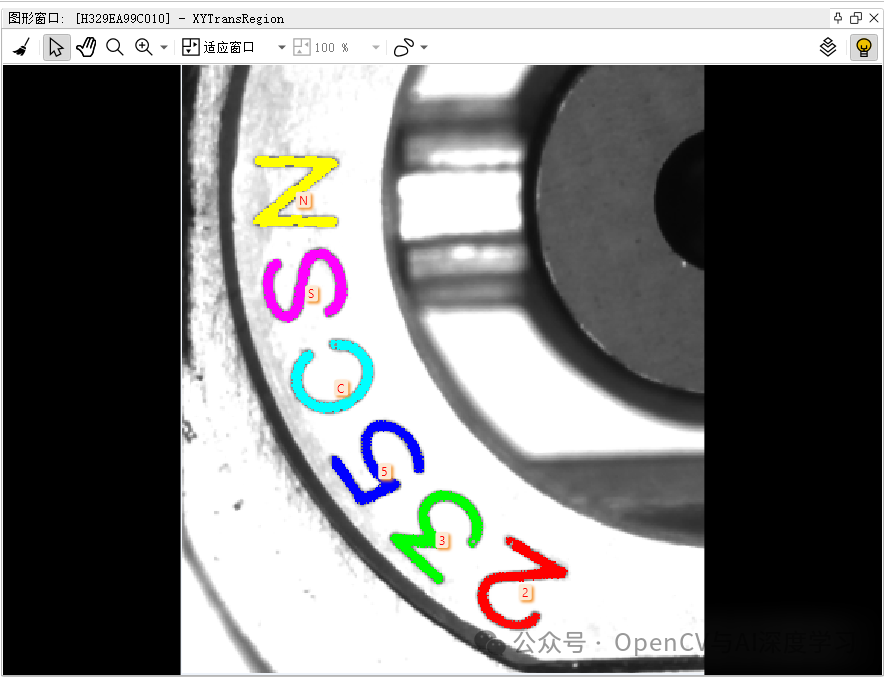
实战 | OpenCV+OCR实现弧形文字识别实例(详细步骤 + 源码)
导 读 本文主要介绍基于OpenCV+OCR实现弧形文字识别实例,并给详细步骤和代码。源码在文末。 背景介绍 测试图如下,目标是正确识别图中的字符。图片来源: https://www.51halcon.com/forum.php?mod=viewthread&tid=6712 同样,论坛中已经给出了Halcon实现代码,…...
哪些 3D 建模软件值得推荐?
云端地球是一款免费的在线实景三维建模软件,不需要复杂的技巧,只要需要手机,多拍几张照片,就可以得到完整的三维模型! 无论是大场景倾斜摄影测量还是小场景、小物体建模,都可以通过云端地球将二维数据向三…...
AI论文指南|人大教授教你如何利用ChatGPT革新内容分析!【建议收藏】
点击下方▼▼▼▼链接直达AIPaperPass ! AIPaperPass - AI论文写作指导平台 公众号原文▼▼▼▼: AI论文指南|人大教授教你如何利用ChatGPT革新内容分析!【建议收藏】 目录 1.ChatGPT内容分析 2.书籍介绍 3.AIPaperPass智能论文写作平…...

leetcode 字符串相关题目
344. 反转字符串 - 力扣(LeetCode) 题解:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 541. 反转字符串 II - 力扣(LeetCode) 题解:https://leetcode.cn/problems/reverse-s…...

第二百九十一回
文章目录 1. 概念介绍2. 方法与细节2.1 实现方法2.2 具体细节 3. 示例代码4. 内容总结 我们在上一章回中介绍了"如何混合选择图片和视频文件"相关的内容,本章回中将介绍如何混合选择多个图片和视频文件.闲话休提,让我们一起Talk Flutter吧。 1…...
简化java代码:mapstruct + 策略模式
目录 目的 准备 注意 相同类型-属性名不同 实体类 映射 使用 验证-查看实现类 测试 不同类型(策略模式) 实体类 映射 工具类 使用:对象拷贝 验证-查看实现类 测试 使用:集合拷贝 测试 策略模式说明 准备-依赖 目的 简化 BeanUtils.…...

【Java】SpringMVC路径写法
1、多级路径 ✅类路径和方法路径都可以写成多级 ✅其中,类路径写在方法路径前面 ✅与Servlet不同,SpringMVC中写不写“/”都可以 RequestMapping("/hello/t1") RestController public class HelloSpring {RequestMapping( value "world…...

数据结构之生成树及最小生成树
数据结构之生成树及最小生成树 1、生成树概念2、最小生成树 数据结构是程序设计的重要基础,它所讨论的内容和技术对从事软件项目的开发有重要作用。学习数据结构要达到的目标是学会从问题出发,分析和研究计算机加工的数据的特性,以便为应用所…...

Claude Code 之父:2026 年我一行代码都没写,编程已被 AI 解决
2026 年,你还在一行一行敲代码吗?Claude Code 的创造者、Anthropic 核心人物 Boris Cherny,在公开访谈里抛出一句让整个行业震动的话:2026 年到现在,我没有写过一行代码。所有开发工作,100% 交给 AI 代理完…...

QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由
QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目…...

基于ESP32与MQTT的家庭环境监测系统:从传感器选型到数据可视化实战
1. 项目概述与核心价值最近几年,我身边越来越多的朋友开始关注家里的空气质量、温湿度这些看不见摸不着,但又实实在在影响生活舒适度和健康的环境指标。从新装修的房子担心甲醛,到有老人小孩的家庭在意PM2.5和二氧化碳浓度,再到南…...
)
Claude端到端测试设计:从零搭建可审计、可回放、可量化的AI服务测试流水线(含开源Schema校验工具)
更多请点击: https://codechina.net 第一章:Claude端到端测试设计 端到端测试是验证Claude模型在真实用户交互链路中行为一致性的关键手段。它覆盖从原始提示输入、上下文管理、流式响应生成,到输出解析与业务校验的全路径,确保模…...

在多轮对话应用中观察Taotoken计费对成本的影响
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话应用中观察Taotoken计费对成本的影响 效果展示类,结合一个需要维护长上下文的多轮对话应用案例,…...

如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南
如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...
【php语法学习,iscc校赛wp】)
学习日志(三)【php语法学习,iscc校赛wp】
1. 任务 1.1.1.1.1.1. 知识部分 rce看【之前的笔记?】php的知识点学习继续jwt token好像是比赛的题目考察内容,我看看php伪协议 1.1.1.1.1.2. 题目 参加iscc比赛【五一】rce题目 1.1.1.1.1.3. 环境配置 把vscode搞好,上学期没有把Php配…...

猫抓浏览器扩展终极指南:5分钟掌握全网视频资源下载技巧
猫抓浏览器扩展终极指南:5分钟掌握全网视频资源下载技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否经常遇到心仪的视频无法…...
)
DeepSeek安全测试辅助Prompt工程白皮书(含17个CVE靶场验证指令模板)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek安全测试辅助 DeepSeek系列大模型在代码生成、漏洞模式识别与安全上下文理解方面展现出独特优势,可作为安全测试工程师的智能协作者。其对OWASP Top 10、CWE分类体系及常见PoC结构具…...

Hermes Agent工具如何自定义接入Taotoken提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent工具如何自定义接入Taotoken提供商 Hermes Agent 是一款功能强大的AI智能体开发框架,它支持通过自定义提供…...