LLM之RAG实战(二十一)| 使用LlamaIndex的Text2SQL和RAG的功能分析产品评论
亚马逊和沃尔玛等电子商务平台上每天都有大量的产品评论,这些评论是反映消费者对产品情绪的关键接触点。但是,企业如何从庞大的数据库获得有意义的见解?
我们可以使用LlamaIndex将SQL与RAG(Retrieval Augmented Generation)相结合来实现。
一、产品评论样本数据集
为了进行此演示,我们使用GPT-4生成了一个样本数据集,其中包括三种产品的评论:iPhone 13、SamsungTV和Ergonomic Chair。下面是评论示例:
iPhone 13:“Amazing battery life and camera quality. Best iPhone yet.”
SamsungTV:“Impressive picture clarity and vibrant colors. A top-notch TV.”
Ergonomic Chair:“Feels really comfortable even after long hours.”
下面是一个示例数据集:
rows = [# iPhone13 Reviews{"category": "Phone", "product_name": "Iphone13", "review": "The iPhone13 is a stellar leap forward. From its sleek design to the crystal-clear display, it screams luxury and functionality. Coupled with the enhanced battery life and an A15 chip, it's clear Apple has once again raised the bar in the smartphone industry."},{"category": "Phone", "product_name": "Iphone13", "review": "This model brings the brilliance of the ProMotion display, changing the dynamics of screen interaction. The rich colors, smooth transitions, and lag-free experience make daily tasks and gaming absolutely delightful."},{"category": "Phone", "product_name": "Iphone13", "review": "The 5G capabilities are the true game-changer. Streaming, downloading, or even regular browsing feels like a breeze. It's remarkable how seamless the integration feels, and it's obvious that Apple has invested a lot in refining the experience."},# SamsungTV Reviews{"category": "TV", "product_name": "SamsungTV", "review": "Samsung's display technology has always been at the forefront, but with this TV, they've outdone themselves. Every visual is crisp, the colors are vibrant, and the depth of the blacks is simply mesmerizing. The smart features only add to the luxurious viewing experience."},{"category": "TV", "product_name": "SamsungTV", "review": "This isn't just a TV; it's a centerpiece for the living room. The ultra-slim bezels and the sleek design make it a visual treat even when it's turned off. And when it's on, the 4K resolution delivers a cinematic experience right at home."},{"category": "TV", "product_name": "SamsungTV", "review": "The sound quality, often an oversight in many TVs, matches the visual prowess. It creates an enveloping atmosphere that's hard to get without an external sound system. Combined with its user-friendly interface, it's the TV I've always dreamt of."},# Ergonomic Chair Reviews{"category": "Furniture", "product_name": "Ergonomic Chair", "review": "Shifting to this ergonomic chair was a decision I wish I'd made earlier. Not only does it look sophisticated in its design, but the level of comfort is unparalleled. Long hours at the desk now feel less daunting, and my back is definitely grateful."},{"category": "Furniture", "product_name": "Ergonomic Chair", "review": "The meticulous craftsmanship of this chair is evident. Every component, from the armrests to the wheels, feels premium. The adjustability features mean I can tailor it to my needs, ensuring optimal posture and comfort throughout the day."},{"category": "Furniture", "product_name": "Ergonomic Chair", "review": "I was initially drawn to its aesthetic appeal, but the functional benefits have been profound. The breathable material ensures no discomfort even after prolonged use, and the robust build gives me confidence that it's a chair built to last."},]
二、设置内存数据库
为了处理我们的数据,我们使用了一个SQLite数据库。SQLAlchemy提供了一种高效的方式来建模、创建和与此数据库交互。以下是表product_reviews的结构:
- id (Integer, Primary Key)
- category (String)
- product_name (String)
- review (String, Not Null)
一旦我们定义了我们的表结构,我们就用我们的样本数据集来填充它。
engine = create_engine("sqlite:///:memory:")metadata_obj = MetaData()# create product reviews SQL tabletable_name = "product_reviews"city_stats_table = Table(table_name,metadata_obj,Column("id", Integer(), primary_key=True),Column("category", String(16), primary_key=True),Column("product_name", Integer),Column("review", String(16), nullable=False))metadata_obj.create_all(engine)sql_database = SQLDatabase(engine, include_tables=["product_reviews"])for row in rows:stmt = insert(city_stats_table).values(**row)with engine.connect() as connection:cursor = connection.execute(stmt)connection.commit()
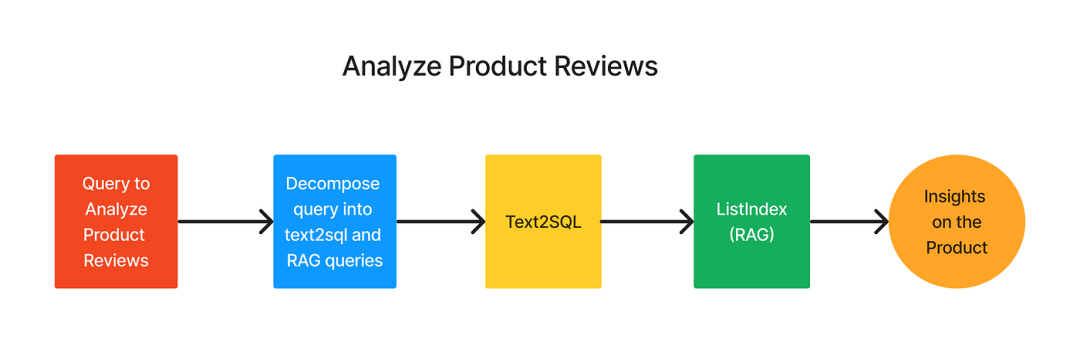
三、分析产品评论——Text2SQL+RAG
LlamaIndex中的SQL+RAG通过将其分解为三个步骤来简化这一过程:
1.问题分解:
- 主查询:用自然语言构建主要问题,从SQL表中提取初步数据;
- 次要查询:构造一个辅助问题,以细化或解释主查询的结果。
2.数据检索:使用Text2SQL LlamaIndex模块运行主查询,以获得初始结果集。
3.最终答案生成:使用列表索引在次要问题的基础上进一步细化结果,得出结论性答案。
四、将用户查询分解为两个阶段
在使用关系数据库时,将用户查询分解为更易于管理的部分通常很有帮助。这样可以更容易地从我们的数据库中检索准确的数据,并随后处理或解释这些数据以满足用户的需求。我们设计了一种方法,通过给gpt-3.5-turbo模型一个例子让其生成两个不同的问题,将查询分解为两个不同的问题。
让我们将其应用于查询“Get the summary of reviews of Iphone13”,系统将生成:
数据库查询:“Retrieve reviews related to iPhone13 from the table.”
解释查询:“Summarize the retrieved reviews.”
这种方法确保我们满足数据检索和数据解释的需求,从而对用户查询做出更准确、更具针对性的响应。
def generate_questions(user_query: str) -> List[str]:system_message = '''You are given with Postgres table with the following columns.city_name, population, country, reviews.Your task is to decompose the given question into the following two questions.1. Question in natural language that needs to be asked to retrieve results from the table.2. Question that needs to be asked on the top of the result from the first question to provide the final answer.Example:Input:How is the culture of countries whose population is more than 5000000Output:1. Get the reviews of countries whose population is more than 50000002. Provide the culture of countries'''messages = [ChatMessage(role="system", content=system_message),ChatMessage(role="user", content=user_query),]generated_questions = llm.chat(messages).message.content.split('\n')return generated_questionsuser_query = "Get the summary of reviews of Iphone13"text_to_sql_query, rag_query = generate_questions(user_query)
五、数据检索——执行主查询
当我们将用户的问题分解为两部分时,第一步是将“自然语言数据库查询”转换为可以针对我们的数据库运行的实际SQL查询。在本节中,我们将使用LlamaIndex的NLSQLTableQueryEngine来处理此SQL查询的转换和执行。
设置NLSQLTableQueryEngine:
NLSQLTableQueryEngine是一个功能强大的工具,可以接受自然语言查询并将其转换为SQL查询。下面是关键详细信息:
sql_database:表示我们的sql数据库连接详细信息。
tables:指定查询运行的表。在这个场景中,我们的目标是product_reviews表。
synthesize_response:当设置为False时,这确保我们在没有额外合成的情况下接收原始SQL响应。
service_context:这是一个可选参数,可用于提供特定于服务的设置或插件。
sql_query_engine = NLSQLTableQueryEngine(sql_database=sql_database,tables=["product_reviews"],synthesize_response=False,service_context=service_context)
执行自然语言查询:
设置好引擎后,下一步使用query()方法对其执行自然语言查询。
sql_response = sql_query_engine.query(text_to_sql_query)处理SQL响应:
SQL查询的结果通常是一个按行存储的列表(每一行都表示为一个评论列表)。为了使其更易于阅读和用于处理总结评论的第三步,我们将此结果转换为单个字符串。
sql_response_list = ast.literal_eval(sql_response.response)text = [' '.join(t) for t in sql_response_list]text = ' '.join(text)
可以在SQL_response.metadata[“SQL_query”]中检查生成的SQL查询。
按照这个过程,我们能够将自然语言处理与SQL查询执行无缝集成。让我们看一下这个过程的最后一步,以获得评论摘要。
六、使用ListIndex完善和解释评论:
从SQL查询中获得主要结果集后,通常需要进一步细化或解释的情况。这就是LlamaIndex的ListIndex发挥关键作用的地方,它允许我们对获得的文本数据执行第二个问题,以获得精确的答案。
listindex = ListIndex([Document(text=text)])list_query_engine = listindex.as_query_engine()response = list_query_engine.query(rag_query)print(response.response)
现在,让我们将所有内容都封装在一个函数下,并尝试几个有趣的示例:
"""Function to perform SQL+RAG"""def sql_rag(user_query: str) -> str:text_to_sql_query, rag_query = generate_questions(user_query)sql_response = sql_query_engine.query(text_to_sql_query)sql_response_list = ast.literal_eval(sql_response.response)text = [' '.join(t) for t in sql_response_list]text = ' '.join(text)listindex = ListIndex([Document(text=text)])list_query_engine = listindex.as_query_engine()summary = list_query_engine.query(rag_query)return summary.response
例子
sql_rag("How is the sentiment of SamsungTV product?")The sentiment of the reviews for the Samsung TV product is generally positive. Users express satisfaction with the picture clarity, vibrant colors, and stunning picture quality. They appreciate the smart features, user-friendly interface, and easy connectivity options. The sleek design and wall-mounting capability are also praised. The ambient mode, gaming mode, and HDR content are mentioned as standout features. Users find the remote control with voice command convenient and appreciate the regular software updates. However, some users mention that the sound quality could be better and suggest using an external audio system. Overall, the reviews indicate that the Samsung TV is considered a solid investment for quality viewing.
sql_rag("Are people happy with Ergonomic Chair?")The overall satisfaction of people with the Ergonomic Chair is high.
七、结论
在电子商务时代,用户评论决定了产品的成败,快速分析和解释大量文本数据的能力至关重要。LlamaIndex通过巧妙地集成SQL和RAG,为企业提供了一个强大的工具,可以从这些数据集中收集可操作的见解。通过将结构化SQL查询与自然语言处理的抽象无缝结合,我们展示了一种将模糊的用户查询转换为精确、信息丰富的答案的简化方法。
有了这种方法,企业现在可以有效地筛选堆积如山的评论,提取用户情感的本质,并做出明智的决定。无论是衡量产品的整体情绪、了解特定功能反馈,还是跟踪评论随时间的演变,LlamaIndex中的Text2SQL+RAG方法都是数据分析新时代的先驱。
参考文献:
[1] https://blog.llamaindex.ai/llamaindex-harnessing-the-power-of-text2sql-and-rag-to-analyze-product-reviews-204feabdf25b
[2] https://colab.research.google.com/drive/13le_rgEo-waW5ZWjWDEyUf64R6n_4Cez?usp=sharing
相关文章:
LLM之RAG实战(二十一)| 使用LlamaIndex的Text2SQL和RAG的功能分析产品评论
亚马逊和沃尔玛等电子商务平台上每天都有大量的产品评论,这些评论是反映消费者对产品情绪的关键接触点。但是,企业如何从庞大的数据库获得有意义的见解? 我们可以使用LlamaIndex将SQL与RAG(Retrieval Augmented Generation&#x…...
Scikit-learn (sklearn)速通 -【莫凡Python学习笔记】
视频教程链接:【莫烦Python】Scikit-learn (sklearn) 优雅地学会机器学习 视频教程代码 scikit-learn官网 莫烦官网学习链接 本人matplotlib、numpy、pandas笔记 1 为什么学习 Scikit learn 也简称 sklearn, 是机器学习领域当中最知名的 python 模块之一. Sk…...

支持向量机(SVM)详解
支持向量机(support vector machines,SVM)是一种二分类模型。它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机。 1、线性可分支持向量机与硬间隔最大化 1.1、线性可分支持向量机 考虑一个二分…...

huggingface学习|云服务器部署Grounded-Segment-Anything:bug总会一个一个一个一个又一个的解决的
文章目录 一、环境部署(一)模型下载(二)环境配置(三)库的安装 二、运行(一) 运行grounding_dino_demo.py文件(二)运行grounded_sam_demo.py文件(三…...

【最佳实践】Go 组合模式对业务解耦
在 Go 语言中,组合模式(Composition)是通过嵌入结构体(embedding structs)来实现的。它允许我们构建复杂的对象,通过将简单对象组合成树形结构来表示整个部分的层次结构。在 Go 中,这种模式不仅…...

arm 汇编调用C
arm64 汇编调用C函数 main.s .section .text .globl main main:stp x29, x30, [sp, -16]! //store fp x29 lr x30mov x0, #0mov x1, #1bl addmov x1, x0 // x0 return ldp x29, x30, [sp], 16 //restore fp lrretadd.c #include <stdio.h> int add(int a, int…...
Vue3+Vite使用Puppeteer进行SEO优化(SSR+Meta)
1. 背景 【笑小枫】https://www.xiaoxiaofeng.com上线啦 资源持续整合中,程序员必备网站,快点前往围观吧~ 我的个人博客【笑小枫】又一次版本大升级,虽然知道没有多少访问量,但我还是整天没事瞎折腾。因为一些功能在Halo上不太好实…...

uni-app学习与快速上手
文章目录 一、uni-app二、学习与快速上手三、案例四、常见问题五、热门文章 一、uni-app uni-app是一种基于Vue.js开发框架的跨平台应用开发框架,可以用于同时开发iOS、Android、H5和小程序等多个平台的应用。uni-app的设计理念是一套代码可以编译到多个平台运行&a…...

orchestrator介绍3.4 web API 的使用
目录 使用 web API API使用简单举例 查看所有的API 实例 JSON 详解 API使用举例 使用 web API orchestrator提供精心设计的 Web API。 敏锐的 Web 开发人员会注意到(通过Firebug or Developer Tools)Web 界面如何完全依赖于 JSON API 请求。 开发人员可…...
市场复盘总结 20240122
仅用于记录当天的市场情况,用于统计交易策略的适用情况,以便程序回测 短线核心:不参与任何级别的调整,采用龙空龙模式 昨日主题投资 连板进级率 6/39 15.3% 二进三: 进级率低 0% 最常用的二种方法: 方法…...
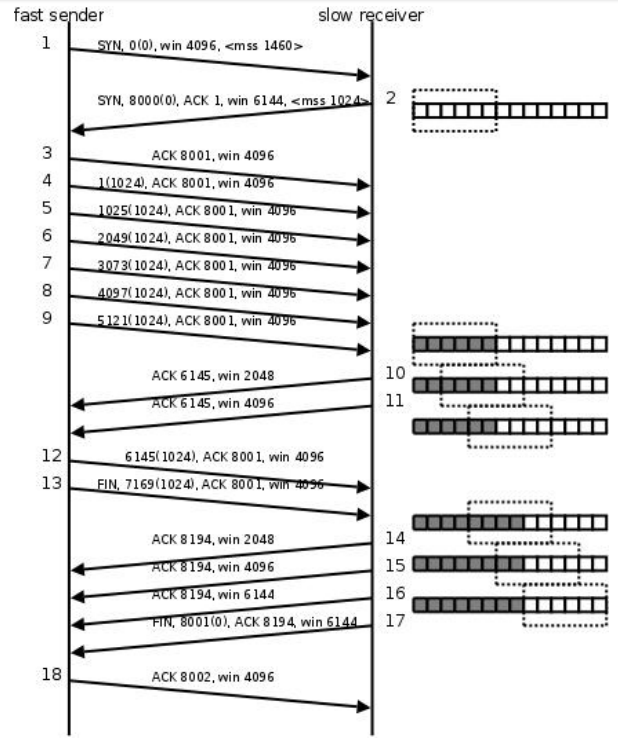
TCP 三次握手 四次挥手以及滑动窗口
TCP 三次握手 简介: TCP 是一种面向连接的单播协议,在发送数据前,通信双方必须在彼此间建立一条连接。所谓的 “ 连接” ,其实是客户端和服务器的内存里保存的一份关于对方的信息,如 IP 地址、端口号等。 TCP 可以…...
yum指令——Linux的软件包管理器
. 个人主页:晓风飞 专栏:数据结构|Linux|C语言 路漫漫其修远兮,吾将上下而求索 文章目录 什么是软件包yum指令1.yum 是什么?2.Linux系统(Centos)的生态 3.yum的相关操作安装卸载yum的相关操作小结 软件源安…...

【WPF.NET开发】规划WPF应用程序性能
本文内容 对各种场景进行考虑定义目标了解平台使性能优化成为一个迭代过程构建图形丰富性 能否成功实现性能目标取决于如何制定性能策略。 规划是开发任何产品的第一阶段。 本主题介绍一些非常简单的规则,用于开发良好的性能策略。 1、对各种场景进行考虑 场景可…...

Ubuntu22.04报错:ValueError: the symlink /usr/bin/python3 does not point to ...
目录 一、背景 二、如何解决呢? 三、解决步骤 1. 确定可用的 Python 版本 2. 重新设置符号链接 3. 选择默认版本 4. 验证: 四、update-alternatives 详解 1. 命令语法 2. 常用选项 --install添加备选项。 --config:选择默认版本。 …...

什么是 React的refs?为什么它们很重要
Refs是React中的一个特殊属性,用于访问在组件中创建的DOM元素或组件实例。 Refs的重要性在于它们提供了一种直接访问DOM元素或组件实例的方式,使得我们可以在需要时操作它们。在某些情况下,例如在处理表单输入、媒体播放或触发动画等场景下&…...

使用yarn时--解决error Error: certificate has expired问题
【HTTPS 证书验证失败】导致的这个问题! 解决方案:将yarn配置中的 strict-ssl 设置为 flase , 在 info yarn config 信息中, strict-ssl 为 true,表示需要验证 HTTPS 证书。我们可以将 strict-ssl 设置为 false,跳过 H…...

Sql server强制走索引
遇到一个奇怪的问题,同样的SQL,只是一个where条件不一样,一个是column1 AAA,一个是column1 BBB,他们的查询效率却差距甚大,一个要60秒,一个1秒以下。查看查询计划,一个使用了索引&…...

解决Android Studio gradle下载超时和缓慢问题(win10)
解决超时问题 一般配置阿里云代理就可以解决。 具体配置方法,参考:https://blog.csdn.net/zhangjin1120/article/details/121739782 解决下载缓慢问题 直接去腾讯云镜像下载: https://mirrors.cloud.tencent.com/gradle/ 下载好了之后&…...

Ps:根据 HSB 调色(以可选颜色命令为例)
在数字色彩中,RGB 和 HSV(又称 HSB)是两种常用的颜色表示方式(颜色模型)。 在 RGB 颜色模式下,Photoshop 的红(Red)、绿(Green)、蓝(Blue…...

MySQL:事务隔离级别详解
事务一共有四个特性:原子性、隔离性、持久性、一致性。简称ACID。本文所将就是其中的隔离性。 1、事务中因为隔离原因导致的并发问题有哪些? 脏读:当事务A对一个数据进行修改,但这个操作还未提交,但此时事务B就已经读…...

Unity安卓打包实战指南:从环境配置到APK生成全链路排错
1. 这不是“入门教程”,而是一份写给真实开发现场的生存指南你打开Unity,新建一个3D项目,拖进一个Cube,点击Play——它动了。你松了口气,觉得“Unity好像也没那么难”。但当你把APK打包发给测试同事,对方回…...
)
告别网盘客户端!用Alist+RaiDrive把百度云盘变成电脑本地文件夹(保姆级图文教程)
用AlistRaiDrive实现网盘本地化管理的终极方案 你是否厌倦了电脑上安装多个网盘客户端,不仅占用系统资源,操作还繁琐割裂?每次上传下载文件都要在不同客户端间切换,效率低下。现在,通过Alist和RaiDrive的组合…...

用STM32CubeMX和HAL库快速上手WS2812B:告别手动计算延时,一键生成驱动框架
基于STM32CubeMX的WS2812B智能灯光控制:从零构建现代化驱动方案在智能硬件和物联网设备快速发展的今天,WS2812B可编程LED灯带因其丰富的色彩表现和简单的单线控制方式,成为创客和工程师们最喜爱的显示组件之一。然而,传统的寄存器…...

基于双T振荡器的正弦波LED调光电路设计与实践
1. 项目概述:用双T振荡器实现正弦波LED调光最近在捣鼓一些氛围灯项目,总感觉用单片机PWM做的呼吸灯效果有点“硬”,那种线性的明暗变化看久了难免审美疲劳。于是翻出以前模拟电路的老本行,琢磨着能不能用纯硬件的方式,…...

2026 文章代码高亮方案选型
将基于 Prism.js 或 Highlight.js 的传统高亮方案与基于 Shiki 的现代化高亮方案进行对比,其核心区别在于底层解析原理的不同(正则表达式 vs. TextMate 语法树)。 以下是两种方案的底层原理、各自优缺点、核心对比矩阵以及适用场景的详细分析…...
)
Allegro PCB设计小技巧:如何让Route Keepout区域既能走线又能打过孔(附详细步骤图)
Allegro PCB设计实战:Route Keepout区域的灵活控制技巧 在高速PCB设计中,Route Keepout区域的管理常常让工程师陷入两难境地——元件封装自带的限制区域与实际布线需求产生冲突。特别是处理PCIE等高速信号时,这种矛盾尤为突出。传统做法要么完…...

树莓派Zero离线语音交互实战:TTS与STT引擎部署与优化
1. 项目概述:为什么选择树莓派 Zero 来实现语音功能?如果你玩过 Arduino、ESP32 这类微控制器,也接触过树莓派 4B 这样的单板电脑,那你大概能理解那种“选择困难症”:微控制器实时性强、功耗低,但算力有限&…...
)
YOLOv8道路交通信号标志识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 道路交通信号标志的自动检测是智能驾驶与交通管理系统中的核心环节。本文基于YOLOv8目标检测算法,构建了一个涵盖21类常见交通信号标志的检测系统,包括禁令标志、指示标志、警告标志及信号灯等。模型在包含1376张训练图像、488张验证图像和229张测…...

ROS机器人仿真架构解析:基于wpr_simulation的移动操作机器人技术实现
ROS机器人仿真架构解析:基于wpr_simulation的移动操作机器人技术实现 【免费下载链接】wpr_simulation 项目地址: https://gitcode.com/gh_mirrors/wp/wpr_simulation 在机器人操作系统(ROS)开发领域,硬件依赖和测试成本一直是制约算法迭代效率的…...

Safe Exam Browser虚拟机绕过实战:深度解析与安全研究指南
Safe Exam Browser虚拟机绕过实战:深度解析与安全研究指南 【免费下载链接】safe-exam-browser-bypass A VM and display detection bypass for SEB. 项目地址: https://gitcode.com/gh_mirrors/sa/safe-exam-browser-bypass 在数字化教育快速发展的今天&…...