在windows环境下安装hadoop
Hadoop是一个分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。但这个架构是基于java语言开发的,所以要先进行jdk的安装,如果电脑已经配置过jdk或者是曾经运行成功过java文件,那就可以跳过第一步。
一.JDK安装
## Hadoop支持的 Java 版本- Apache Hadoop 3.3 及更高版本支持 Java 8 和 Java 11(仅限运行时)- 请使用 Java 8 编译 Hadoop。不支持使用 Java 11 编译 Hadoop: [HADOOP-16795](https://issues.apache.org/jira/browse/HADOOP-16795)-Java 11 编译支持**OPEN** [](https://issues.apache.org/jira/browse/HADOOP-16795) - 从 3.0.x 到 3.2.x 的 Apache Hadoop 现在仅支持 Java 8 - 从 2.7.x 到 2.10.x 的 Apache Hadoop 支持 Java 7 和 8
所以我们安装jdk8来运行Hadoop,最好去官网进行下载:https://www.oracle.com/java/technologies/downloads/#jre8-windows
自己看自己电脑的配置选择
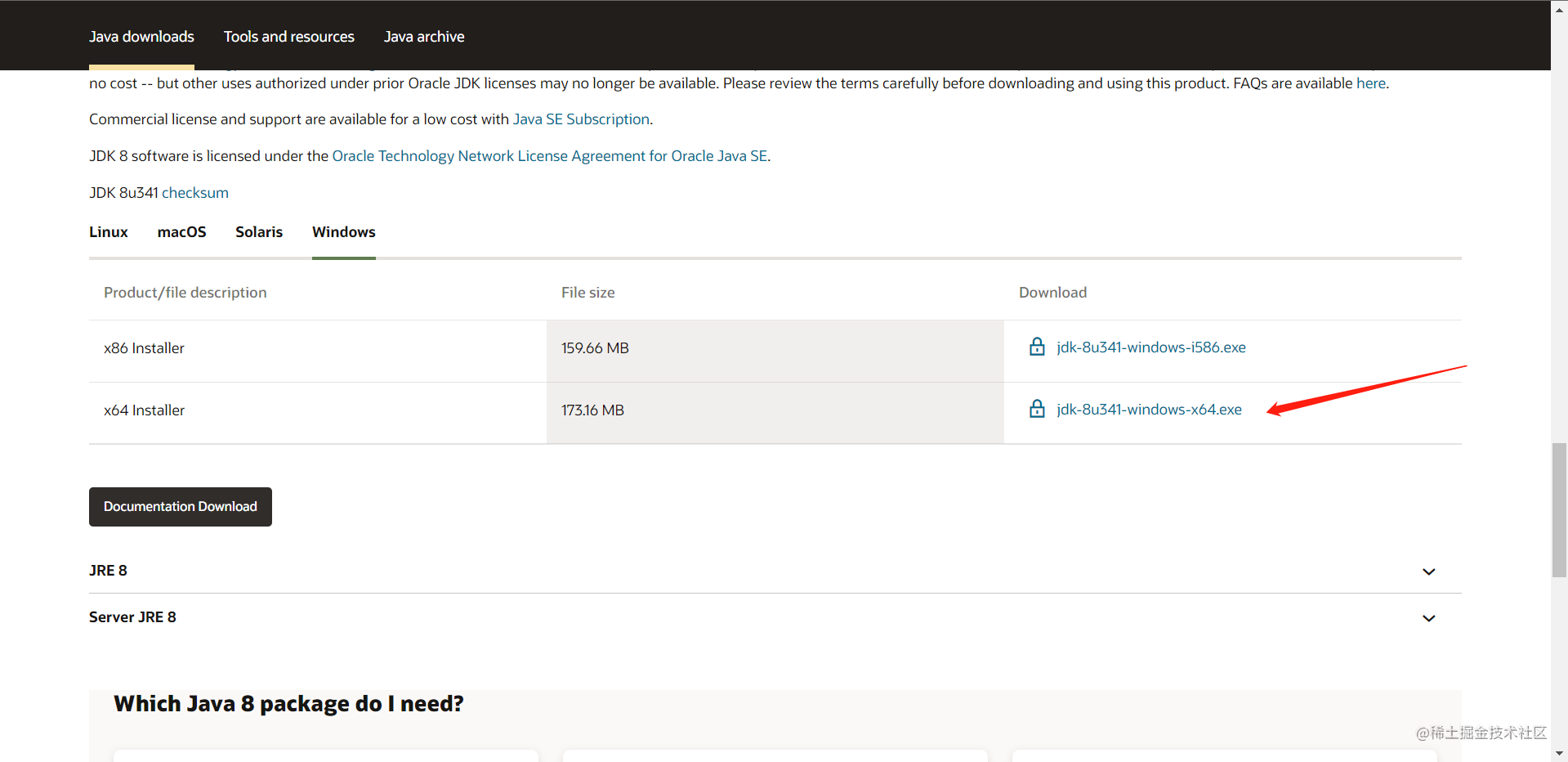
我是64位就下载这个,32位的下载上面一个。运行安装程序即可,不需要配置环境变量。
二.Hadoop安装
可以去阿里云开源镜像站下载快点
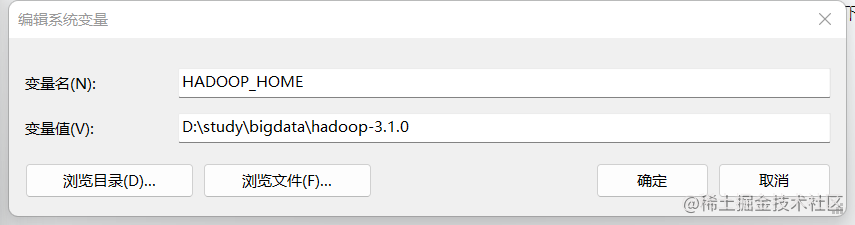
windows的环境变量配置
设置->系统->系统信息->高级系统设置(也可以用win11的搜索编辑系统环境变量)
在下面的系统变量处新建:
HADOOP_HOME
值为(你解压缩hadoop所在路径)
D:\study\bigdata\hadoop-3.1.0
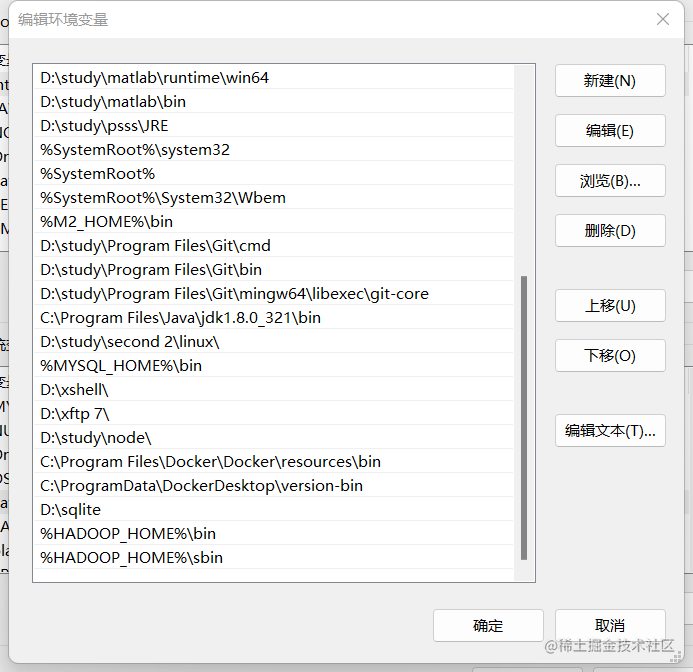
然后在系统变量的Path下新建两个变量
%HADOOP_HOME%\bin
%HADOOP_HOME%\sbin
hadoop文件配置
在D:\study\bigdata\hadoop-3.1.0 (即你放hadoop的路径下)
去\etc\hadoop目录找到hadoop-env.cmd这个文件,右键编辑,然后搜索(或者Ctrl+F)搜索JAVA_HOME找到set JAVA_HOME这一项,将其修改为jdk8的安装路径:
set JAVA_HOME=C:\PROGRA~1\Java\jdk-8
为什么要使用PROGRA~1来代替Program Files,因为这是其dos文件名模式下的缩写,直接使用Program Files会报错,里面包含一个空格
然后去cmd查看是否安装成功,没有报错说明配置已经成功了。
hadoop -version
从这里开始出现bug的话,发现没有安装成功,没有出现配置信息的话,那就继续往下看。如果成功跳到三.启动测试
1.先进入D:\study\bigdata\hadoop-3.1.0\etc这个目录(对应的是你放hadoop的目录)
2.修改core-site.xml这个文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:900</value>
</property>
</configuration>
2.修改mapred-site.xml文件
<!-- 2. Edit mapred-site.xml and copy this property in the cofiguration -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
3.修改yarn-site.xml文件
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
4.修改hdfs-site.xml文件
<!-- Put site-specific property overrides in this file. -->
<!-- 3. Create a new folder named "data2020" in ../hadoop-3.1.0/ in the same
directory of etc folder -->
<!-- 4. Edit the file hdfs-site.xml and add below property in the configuration -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>D:\study\bigdata\hadoop-3.1.0\data2022\namenode</value>
</property>
<property>
<name>dfs.datanode.name.dir</name>
<value>D:\study\bigdata\hadoop-3.1.0\data2022\datanode</value>
</property>
</configuration>5.创建一个data目录在D:\study\bigdata\hadoop-3.1.0,我取名叫data2022
6.在5的data2022目录下创建4你的两个文件夹名字:namenode和datanode
7.依然在D:\study\bigdata\hadoop-3.1.0\etc这个目录下找到hadoop-env.sh这个文件,找到这里修改配置:
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
# export JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_321
export JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_321
8.找到hadoop-env.cmd文件,修改(7和8都是修改成自己的jdk路径)
@rem The java implementation to use. Required. set JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_321
9.然后去这个网站下载如果要在windows下运行hadoop专门的bin文件夹,点赞私聊我也会私发给你这份文件夹。
三.启动测试
1.进入命令行窗口,格式化hadoop
hadoop namenode -format
2.然后去到D:\study\bigdata\hadoop-3.1.0\bin这个目录下,在地址栏输入cmd,再使用以下命令
start-dfs.cmd
这时候会跳出两个窗口不要关掉它们,然后继续下一步
3.继续输入以下命令:
start-yarn.cmd
又跳出两个窗口,也不要关掉,要不然会有错误出现
4.然后打开这个链接:http://localhost:9870/
5.以后你都要同时重复23就可以使用hadoop了
6.之后你就可以在刚刚的命令行窗口通过输入命令使用hadoop了
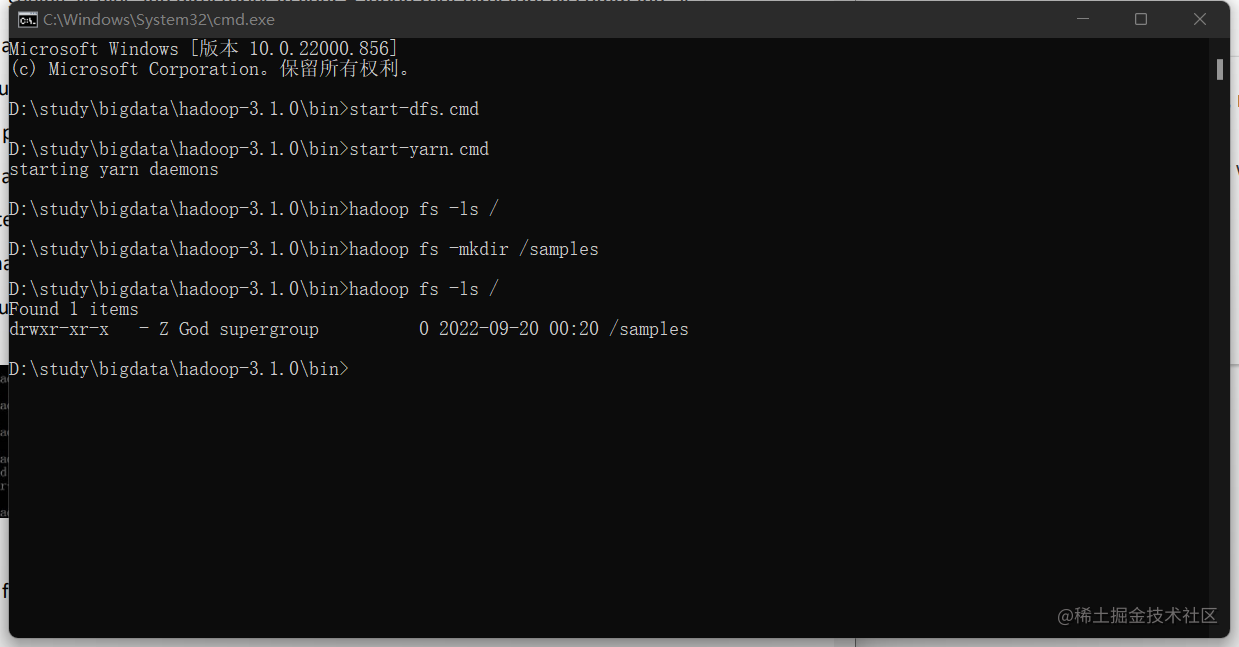
以上便是全流程。
相关文章:
在windows环境下安装hadoop
Hadoop是一个分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。但这个架构是基于java语言开发的,所以要先进行jdk的安装,如果电脑已经配置过jdk或者是曾经运行成功过java文件,那就可以跳过第一步。 …...

大数据分析组件Hive-集合数据结构
Hive的数据结构 前言一、array数组类型二、map键值对集合类型三、struct结构体类型 前言 Hive是一个基于Hadoop的数据仓库基础设施,用于处理大规模分布式数据集。它提供了一个类似于SQL的查询语言(称为HiveQL),允许用户以类似于关…...

单核QPS近6000S,陌陌基于OceanBase的持久化缓存探索与实践
挚文集团于 2011 年 8 月推出了陌陌,这款立足地理位置服务的开放式移动视频社交应用在中国社交平台领域内独树一帜。陌陌和探探作为陌生人社交领域的主流应用,涵盖了多种核心业务模块,包括直播服务、附近动态功能、即时通讯(IM&am…...

关于css 的基础试题
CSS是什么的缩写? A. Creative Style SheetsB. Cascading Style SheetsC. Computer Style SheetsD. Colorful Style Sheets 在HTML中,通过什么标签引入CSS样式? A. <script>B. <style>C. <link>D. <css> 以下哪个选项…...

Keil-C语言小总结
1、 &取地址符,*取地址内容 int *ptr;//声明指针 2、ptr &c; // 将c的地址赋值给指针变量ptr 3、可选参数函数 4、C宏定义 5、 memset:最快的数据清零函数 void *memset(void *s, int ch, size_t n); 分别是 字符串 要值的数据(0…...

react的withRouter高阶组件:
withRouter的作用就是, 如果我们某个东西不是一个Router, 但是我们要依靠它去跳转一个页面, 比如点击页面的logo, 返回首页, 这时候就可以使用withRouter来做. 在 React Router 中,withRouter 是一个函数,用于与路由相关的组件。它接受一个组件作为参数&…...

小程序 样式 WXSS
文章目录 样式 WXSS尺⼨单位样式导⼊选择器⼩程序中使⽤less 样式 WXSS WXSS( WeiXin Style Sheets )是⼀套样式语⾔,⽤于描述 WXML 的组件样式。 与 CSS 相⽐,WXSS 扩展的特性有: 响应式⻓度单位 rpx样式导⼊ 尺⼨单位 rpx (…...
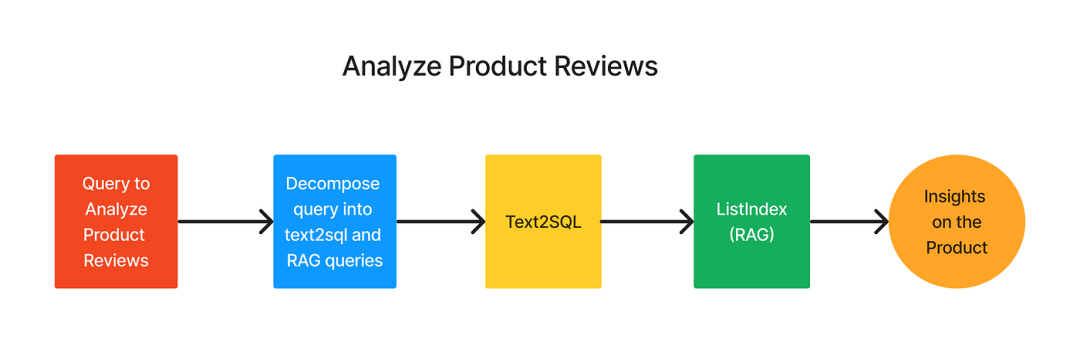
LLM之RAG实战(二十一)| 使用LlamaIndex的Text2SQL和RAG的功能分析产品评论
亚马逊和沃尔玛等电子商务平台上每天都有大量的产品评论,这些评论是反映消费者对产品情绪的关键接触点。但是,企业如何从庞大的数据库获得有意义的见解? 我们可以使用LlamaIndex将SQL与RAG(Retrieval Augmented Generation&#x…...
Scikit-learn (sklearn)速通 -【莫凡Python学习笔记】
视频教程链接:【莫烦Python】Scikit-learn (sklearn) 优雅地学会机器学习 视频教程代码 scikit-learn官网 莫烦官网学习链接 本人matplotlib、numpy、pandas笔记 1 为什么学习 Scikit learn 也简称 sklearn, 是机器学习领域当中最知名的 python 模块之一. Sk…...

支持向量机(SVM)详解
支持向量机(support vector machines,SVM)是一种二分类模型。它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机。 1、线性可分支持向量机与硬间隔最大化 1.1、线性可分支持向量机 考虑一个二分…...

huggingface学习|云服务器部署Grounded-Segment-Anything:bug总会一个一个一个一个又一个的解决的
文章目录 一、环境部署(一)模型下载(二)环境配置(三)库的安装 二、运行(一) 运行grounding_dino_demo.py文件(二)运行grounded_sam_demo.py文件(三…...

【最佳实践】Go 组合模式对业务解耦
在 Go 语言中,组合模式(Composition)是通过嵌入结构体(embedding structs)来实现的。它允许我们构建复杂的对象,通过将简单对象组合成树形结构来表示整个部分的层次结构。在 Go 中,这种模式不仅…...

arm 汇编调用C
arm64 汇编调用C函数 main.s .section .text .globl main main:stp x29, x30, [sp, -16]! //store fp x29 lr x30mov x0, #0mov x1, #1bl addmov x1, x0 // x0 return ldp x29, x30, [sp], 16 //restore fp lrretadd.c #include <stdio.h> int add(int a, int…...
Vue3+Vite使用Puppeteer进行SEO优化(SSR+Meta)
1. 背景 【笑小枫】https://www.xiaoxiaofeng.com上线啦 资源持续整合中,程序员必备网站,快点前往围观吧~ 我的个人博客【笑小枫】又一次版本大升级,虽然知道没有多少访问量,但我还是整天没事瞎折腾。因为一些功能在Halo上不太好实…...

uni-app学习与快速上手
文章目录 一、uni-app二、学习与快速上手三、案例四、常见问题五、热门文章 一、uni-app uni-app是一种基于Vue.js开发框架的跨平台应用开发框架,可以用于同时开发iOS、Android、H5和小程序等多个平台的应用。uni-app的设计理念是一套代码可以编译到多个平台运行&a…...

orchestrator介绍3.4 web API 的使用
目录 使用 web API API使用简单举例 查看所有的API 实例 JSON 详解 API使用举例 使用 web API orchestrator提供精心设计的 Web API。 敏锐的 Web 开发人员会注意到(通过Firebug or Developer Tools)Web 界面如何完全依赖于 JSON API 请求。 开发人员可…...
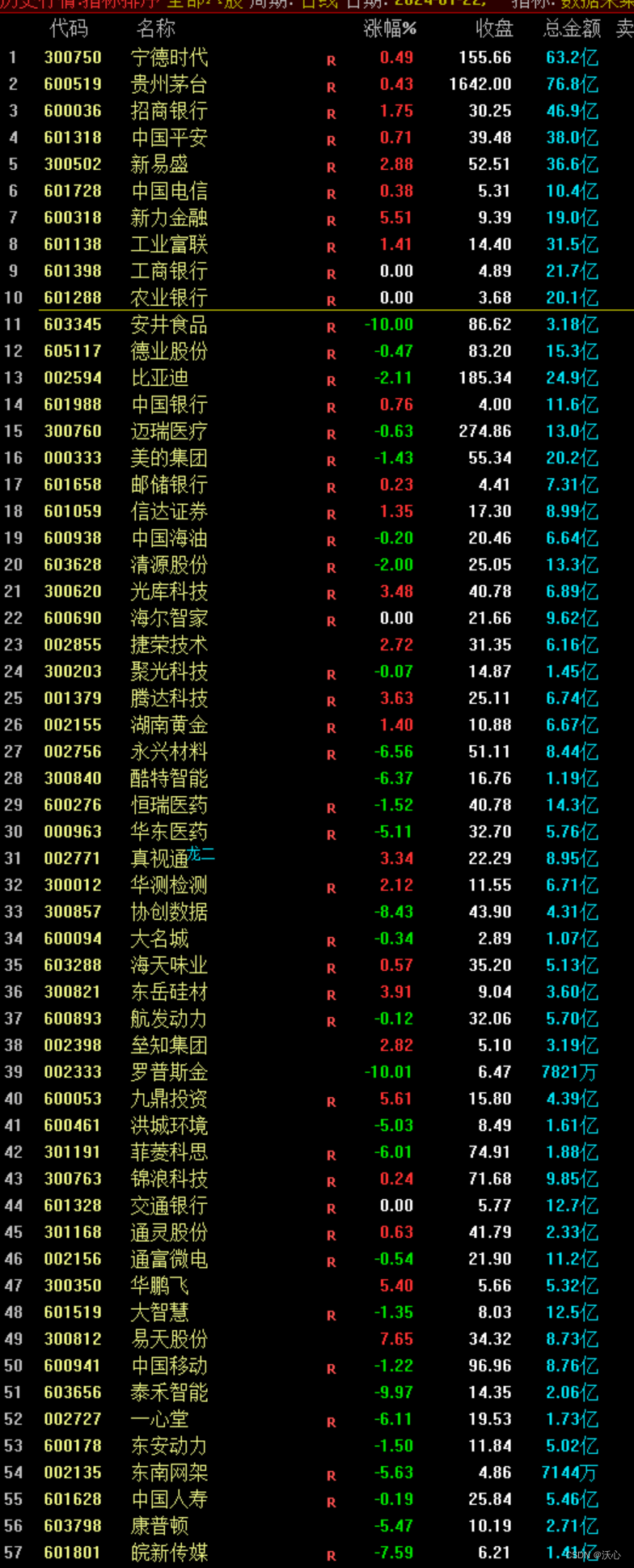
市场复盘总结 20240122
仅用于记录当天的市场情况,用于统计交易策略的适用情况,以便程序回测 短线核心:不参与任何级别的调整,采用龙空龙模式 昨日主题投资 连板进级率 6/39 15.3% 二进三: 进级率低 0% 最常用的二种方法: 方法…...
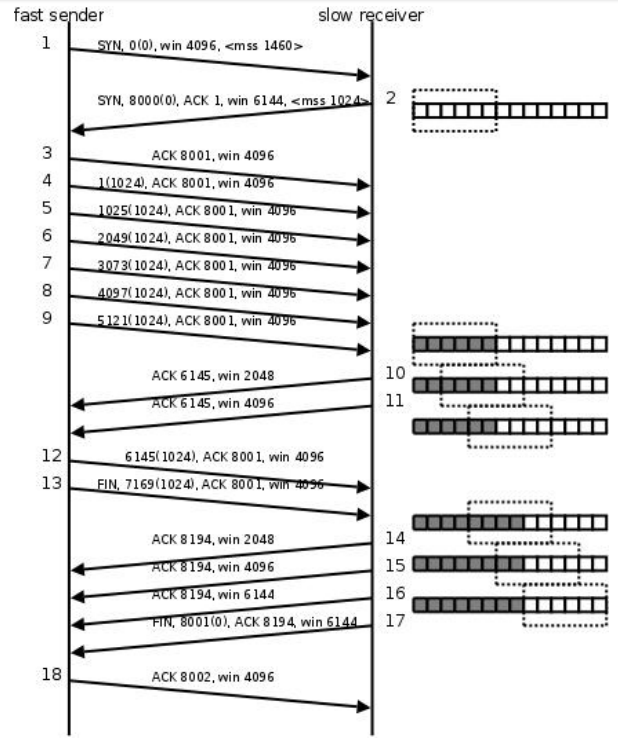
TCP 三次握手 四次挥手以及滑动窗口
TCP 三次握手 简介: TCP 是一种面向连接的单播协议,在发送数据前,通信双方必须在彼此间建立一条连接。所谓的 “ 连接” ,其实是客户端和服务器的内存里保存的一份关于对方的信息,如 IP 地址、端口号等。 TCP 可以…...
yum指令——Linux的软件包管理器
. 个人主页:晓风飞 专栏:数据结构|Linux|C语言 路漫漫其修远兮,吾将上下而求索 文章目录 什么是软件包yum指令1.yum 是什么?2.Linux系统(Centos)的生态 3.yum的相关操作安装卸载yum的相关操作小结 软件源安…...

【WPF.NET开发】规划WPF应用程序性能
本文内容 对各种场景进行考虑定义目标了解平台使性能优化成为一个迭代过程构建图形丰富性 能否成功实现性能目标取决于如何制定性能策略。 规划是开发任何产品的第一阶段。 本主题介绍一些非常简单的规则,用于开发良好的性能策略。 1、对各种场景进行考虑 场景可…...

浅聊26上半年软考架构师
2026年上半年架构师考试已然落幕,大家都考的如何?架构师共有三门考试,上午综合知识(75道选择题)案例分析,时间为8.30-12.30;下午论文,时间为14.30-16.30。下面说说我整体的备考过程。…...
)
双系统Ubuntu磁盘告急?别重装!用GParted无损扩容保姆级教程(附U盘启动盘制作)
双系统Ubuntu磁盘告急?别重装!用GParted无损扩容保姆级教程(附U盘启动盘制作)当你在Windows和Ubuntu双系统环境下工作时,是否遇到过这样的窘境:当初安装时给Ubuntu分配的空间捉襟见肘,而Windows…...

科华UPS电源全品类汇总:选型与场景适配指南
科华UPS电源作为国内智慧电能领域的主流产品,覆盖家用、办公、机房、工业等全场景,产品系列丰富、规格齐全,但多数用户在选型时,常因分不清系列差异、功率适配、架构类型而踩坑。本文系统汇总科华UPS电源的核心分类、主流系列、核…...

我们公司全员把 Cursor 换成了自研的 全开源AtomCode
【引子】这是一篇实录——一位 CTO 用 28 天,用 Claude GLM 双模型调度,造出了一个让全公司放弃 Cursor 的工具。然后我意识到我们正在经历的事情,比"换工具"大得多。【读者承诺】接下来 15 分钟,你会拿到三件东西:一个真实案例(28 天 1,146 commits 是怎么做出来的…...

氘可来昔替尼常见副作用为鼻咽炎头痛及腹泻,如何应对
任何口服药物的临床价值,都必须在疗效与安全性的天平上找到精准的平衡点。氘可来昔替尼以PASI 75应答率的全面胜出证明了自己在银屑病治疗中的卓越地位,而其不良反应谱同样经过了严苛的临床验证。鼻咽炎、头痛和腹泻构成了这款药物最需关注的三大安全信号…...

如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南
如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南 【免费下载链接】Sony-PMCA-RE Reverse Engineering Sony Digital Cameras 项目地址: https://gitcode.com/gh_mirrors/so/Sony-PMCA-RE 索尼相机逆向工程工具Sony-PMCA-RE是一款专业的开源工具&…...

如何高效使用HiveWE:魔兽争霸III地图制作的完整秘籍
如何高效使用HiveWE:魔兽争霸III地图制作的完整秘籍 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为魔兽争霸III原版编辑器加载缓慢、操作卡顿而烦恼吗?HiveWE作为一款专注于速…...

鼎讯AM-601光纤熔接机:交通通信建设与维护的可靠伙伴
在铁路、高速公路等交通基础设施的智能化建设中,稳定高效的光纤网络是指挥调度、安全监控等核心系统运行的生命线。鼎讯AM-601光纤熔接机,作为一款专为严苛环境设计的六马达便携式熔接设备,正成为保障这些关键通信链路畅通无阻的可靠选择。无…...

无声输入革命:如何用Chaplin在5分钟内构建本地唇语识别系统
无声输入革命:如何用Chaplin在5分钟内构建本地唇语识别系统 【免费下载链接】chaplin A real-time silent speech recognition tool. 项目地址: https://gitcode.com/gh_mirrors/chapl/chaplin 在嘈杂的办公室、安静的图书馆,或是需要绝对隐私的医…...

ABS+神经网络:端到端宇宙学参数推断新范式解析
1. 项目概述:当ABS遇上神经网络,一个端到端宇宙学参数推断新范式的诞生 在宇宙学研究的核心地带,有一项任务既令人着迷又充满挑战:如何从宇宙微波背景(CMB)这张宇宙婴儿时期的“照片”中,精准地…...