经典目标检测YOLO系列(三)YOLOv3的复现(2)正样本的匹配、损失函数的实现
经典目标检测YOLO系列(三)YOLOv3的复现(2)正样本的匹配、损失函数的实现
我们在之前实现YOLOv2的基础上,加入了多级检测及FPN,快速的实现了YOLOv3的网络架构,并且实现了前向推理过程。
经典目标检测YOLO系列(三)YOLOV3的复现(1)总体网络架构及前向处理过程
我们继续进行YOLOv3的复现。
1 正样本匹配策略
1.1 基于先验框的正样本匹配策略
-
官方YOLOv2的正样本匹配思路是根据
预测框和目标框的IoU来确定中心点所在的网格,哪一个预测框是正样本。 -
大体上,官方YOLOv3也沿用这一思路,但是细节上有差距。官方YOLOv3也会出现之前所说的三种情况:
- 前2种情况,IoU都小于iou_thresh或者仅有一个IoU值大于iou_thresh,那么此时会有一个正样本;
- 第3种情况,即有多个IoU值大于iou_thresh时候,仅仅将IoU最大的哪一个作为正样本。对于剩下样本,由于IoU值已经大于iou_thresh,因此不会被标记为正样本,将其忽略。
-
我们继续沿用之前复现YOLOv2的做法。对于第3种情况,我们不忽略,还是标记为正样本。
- 第1种情况:如果IoU都小于iou_thresh,为了不丢失这个训练样本,我们选择选择IoU值最大的先验框P_A。将P_A对应的预测框B_A,标记为正样本,即
先验框决定哪些预测框会参与到何种损失的计算中去。 - 第2种情况:仅有一个IoU值大于iou_thresh,那么这个先验框所对应的预测框会被标记为正样本,会参与到置信度、类别及位置损失的计算。
- 第3种情况:有多个IoU值大于iou_thresh,那么这些先验框所对应的预测框都会被标记为正样本,即
一个目标会被匹配上多个正样本。
- 第1种情况:如果IoU都小于iou_thresh,为了不丢失这个训练样本,我们选择选择IoU值最大的先验框P_A。将P_A对应的预测框B_A,标记为正样本,即
-
由于YOLOv3中添加了多级检测,因此部分代码细节有所差异。
1.2 代码实现
1.2.1 正样本匹配
pytorch读取VOC数据集:
-
一批图像数据的维度是 [B, 3, H, W] ,分别是batch size,色彩通道数,图像的高和图像的宽。
-
标签数据是一个包含 B 个图像的标注数据的python的list变量(如下所示),其中,每个图像的标注数据的list变量又包含了 M 个目标的信息(类别和边界框)。
-
获得了这一批数据后,图片是可以直接喂到网络里去训练的,但是标签不可以,需要再进行处理一下。
[{'boxes': torch.tensor([[120., 0., 408., 23.],[160., 59., 416., 256.],[172., 24., 218., 128.],[408., 35., 416., 75.],[ 0., 64., 8., 186.]]), # bbox的坐标(xmin, ymin, xmax, ymax'labels': torch.tensor([ 6, 6, 14, 6, 19]), # 标签'orig_size': [416, 416] # 图片的原始大小},{'boxes': torch.tensor([[367., 255., 416., 416.],[330., 302., 416., 416.]]),'labels': torch.tensor([14, 13]),'orig_size': [416, 416]}
]
标签处理主要包括3个部分,
- 一是将真实框中心所在网格对应
正样本位置(anchor_idx)的置信度置为1,其他默认为0 - 二是将真实框中心所在网格对应
正样本位置(anchor_idx)的标签类别为1(one-hot格式),其他类别设置为0 - 三是将真实框中心所在网格对应
正样本位置(anchor_idx)的bbox信息设置为真实框的bbox信息。
# 处理好的shape如下:
# gt_objectness
torch.Size([2, 10647, 1]) # 10647=52×52×3 + 26×26×3 + 13×13×3
# gt_classes
torch.Size([2, 10647, 20])
# gt_bboxes
torch.Size([2, 10647, 4])
1.2.2 具体代码实现
- 对于一个目标框,我们先计算它和9个先验框的IoU,然后先用阈值进行筛选
- 然后,我们会遇到之前说的3种情况,处理方法和YOLOv2一致。
- 在确定哪个先验框为正样本后,我们还要通过公式
iou_ind // self.num_anchors确定这个先验框来自哪个尺度。- 一个很小的目标框,它和较小的先验框的IoU理应大一些,因此会被分配到网格密集的C3尺度上;
- 相反,一个很大的目标框,它和较大的先验框的IoU理应大一些,因此会被分配到网格稀疏的C5尺度上;
- 中等大小的目标框,被分配到C4尺度上。
# RT-ODLab/models/detectors/yolov3/matcher.py
import numpy as np
import torchclass Yolov3Matcher(object):def __init__(self, num_classes, num_anchors, anchor_size, iou_thresh):self.num_classes = num_classesself.num_anchors = num_anchorsself.iou_thresh = iou_threshself.anchor_boxes = np.array([[0., 0., anchor[0], anchor[1]]for anchor in anchor_size]) # [KA, 4]def compute_iou(self, anchor_boxes, gt_box):"""函数功能: 计算目标框和9个先验框的IoU值anchor_boxes : ndarray -> [KA, 4] (cx, cy, bw, bh).gt_box : ndarray -> [1, 4] (cx, cy, bw, bh).返回值: iou变量,类型为ndarray类型,shape为[9,], iou[i]就表示该目标框和第i个先验框的IoU值"""# 1、计算9个anchor_box的面积# anchors: [KA, 4]anchors = np.zeros_like(anchor_boxes)anchors[..., :2] = anchor_boxes[..., :2] - anchor_boxes[..., 2:] * 0.5 # x1y1anchors[..., 2:] = anchor_boxes[..., :2] + anchor_boxes[..., 2:] * 0.5 # x2y2anchors_area = anchor_boxes[..., 2] * anchor_boxes[..., 3]# 2、gt_box复制9份,计算9个相同gt_box的面积# gt_box: [1, 4] -> [KA, 4]gt_box = np.array(gt_box).reshape(-1, 4)gt_box = np.repeat(gt_box, anchors.shape[0], axis=0)gt_box_ = np.zeros_like(gt_box)gt_box_[..., :2] = gt_box[..., :2] - gt_box[..., 2:] * 0.5 # x1y1gt_box_[..., 2:] = gt_box[..., :2] + gt_box[..., 2:] * 0.5 # x2y2gt_box_area = np.prod(gt_box[..., 2:] - gt_box[..., :2], axis=1)# 3、计算计算目标框和9个先验框的IoU值# intersectioninter_w = np.minimum(anchors[:, 2], gt_box_[:, 2]) - \np.maximum(anchors[:, 0], gt_box_[:, 0])inter_h = np.minimum(anchors[:, 3], gt_box_[:, 3]) - \np.maximum(anchors[:, 1], gt_box_[:, 1])inter_area = inter_w * inter_h# unionunion_area = anchors_area + gt_box_area - inter_area# iouiou = inter_area / union_areaiou = np.clip(iou, a_min=1e-10, a_max=1.0)return iou@torch.no_grad()def __call__(self, fmp_sizes, fpn_strides, targets):"""fmp_size: (List) [fmp_h, fmp_w]fpn_strides: (List) -> [8, 16, 32, ...] stride of network output.targets: (Dict) dict{'boxes': [...], 'labels': [...], 'orig_size': ...}"""assert len(fmp_sizes) == len(fpn_strides)# preparebs = len(targets)gt_objectness = [torch.zeros([bs, fmp_h, fmp_w, self.num_anchors, 1]) for (fmp_h, fmp_w) in fmp_sizes]gt_classes = [torch.zeros([bs, fmp_h, fmp_w, self.num_anchors, self.num_classes]) for (fmp_h, fmp_w) in fmp_sizes]gt_bboxes = [torch.zeros([bs, fmp_h, fmp_w, self.num_anchors, 4]) for (fmp_h, fmp_w) in fmp_sizes]# 第一层for循环遍历每一张图像for batch_index in range(bs):targets_per_image = targets[batch_index]# [N,] N表示一个图像中有N个目标对象tgt_cls = targets_per_image["labels"].numpy()# [N, 4]tgt_box = targets_per_image['boxes'].numpy()# 第二层for循环遍历这张图像标签的每一个目标数据for gt_box, gt_label in zip(tgt_box, tgt_cls):# get a bbox coordsx1, y1, x2, y2 = gt_box.tolist()# xyxy -> cxcywhxc, yc = (x2 + x1) * 0.5, (y2 + y1) * 0.5bw, bh = x2 - x1, y2 - y1gt_box = [0, 0, bw, bh]# check targetif bw < 1. or bh < 1.:# invalid targetcontinue# 1、计算该目标框和9个先验框的IoU值# compute IoUiou = self.compute_iou(self.anchor_boxes, gt_box)iou_mask = (iou > self.iou_thresh)# 2、基于先验框的标签分配策略label_assignment_results = []# 第一种情况:所有的IoU值均低于阈值,选择IoU最大的先验框if iou_mask.sum() == 0:# We assign the anchor box with highest IoU score.iou_ind = np.argmax(iou)# 确定选择的先验框在pyramid上的level及anchor indexlevel = iou_ind // self.num_anchors # pyramid levelanchor_idx = iou_ind - level * self.num_anchors # anchor index# get the corresponding stridestride = fpn_strides[level]# compute the grid cell# 计算该目标框在level尺度的网格坐标xc_s = xc / strideyc_s = yc / stridegrid_x = int(xc_s)grid_y = int(yc_s)# 存下网格坐标、尺度level以及anchor_idxlabel_assignment_results.append([grid_x, grid_y, level, anchor_idx])else:# 第二种和第三种情况:至少有一个IoU值大于阈值for iou_ind, iou_m in enumerate(iou_mask):if iou_m:level = iou_ind // self.num_anchors # pyramid levelanchor_idx = iou_ind - level * self.num_anchors # anchor index# get the corresponding stridestride = fpn_strides[level]# compute the gride cellxc_s = xc / strideyc_s = yc / stridegrid_x = int(xc_s)grid_y = int(yc_s)label_assignment_results.append([grid_x, grid_y, level, anchor_idx])# label assignment# 获取到被标记为正样本的先验框,我们就可以为这次先验框对应的预测框制作学习标签for result in label_assignment_results:grid_x, grid_y, level, anchor_idx = resultfmp_h, fmp_w = fmp_sizes[level]if grid_x < fmp_w and grid_y < fmp_h:# objectness标签,采用0,1离散值(gt_objectness为list,存3个尺度的正样本)gt_objectness[level][batch_index, grid_y, grid_x, anchor_idx] = 1.0# classification标签,采用one-hot格式cls_ont_hot = torch.zeros(self.num_classes)cls_ont_hot[int(gt_label)] = 1.0gt_classes[level][batch_index, grid_y, grid_x, anchor_idx] = cls_ont_hot# box标签,采用目标框的坐标值gt_bboxes[level][batch_index, grid_y, grid_x, anchor_idx] = torch.as_tensor([x1, y1, x2, y2])# [B, M, C]gt_objectness = torch.cat([gt.view(bs, -1, 1) for gt in gt_objectness], dim=1).float()gt_classes = torch.cat([gt.view(bs, -1, self.num_classes) for gt in gt_classes], dim=1).float()gt_bboxes = torch.cat([gt.view(bs, -1, 4) for gt in gt_bboxes], dim=1).float()return gt_objectness, gt_classes, gt_bboxesif __name__ == '__main__':anchor_size = [[10, 13], [16, 30], [33, 23],[30, 61], [62, 45], [59, 119],[116, 90], [156, 198], [373, 326]]matcher = Yolov3Matcher(iou_thresh=0.5, num_classes=20, anchor_size=anchor_size, num_anchors=3)fmp_sizes = [torch.Size([52, 52]), torch.Size([26, 26]), torch.Size([13, 13])]fpn_strides = [8, 16, 32]targets = [{'boxes': torch.tensor([[120., 0., 408., 23.],[160., 59., 416., 256.],[172., 24., 218., 128.],[408., 35., 416., 75.],[ 0., 64., 8., 186.]]), # bbox的坐标(xmin, ymin, xmax, ymax'labels': torch.tensor([ 6, 6, 14, 6, 19]), # 标签'orig_size': [416, 416] # 图片的原始大小},{'boxes': torch.tensor([[367., 255., 416., 416.],[330., 302., 416., 416.]]),'labels': torch.tensor([14, 13]),'orig_size': [416, 416]}]gt_objectness, gt_classes, gt_bboxes = matcher(fmp_sizes=fmp_sizes, fpn_strides=fpn_strides, targets=targets)print(gt_objectness.shape)print(gt_classes.shape)print(gt_bboxes.shape)
2 损失函数的计算
- YOLOv3损失函数计算(RT-ODLab/models/detectors/yolov3/loss.py)和之前实现的YOLOv2基本一致,不再赘述
- 对于数据预处理、数据增强等,我们不再采用之前SSD风格的处理手段,而是选择YOLOv5的数据处理方法来训练我们的YOLOv3,我们下次再聊。
结语
-
我们现在已经知道,在多级检测框架时候,先验框自身尺度在标签分配环节起到了重要的作用。
-
自Faster R-CNN工作问世以来,anchor box几乎成为了大多数先进的目标检测器的标准配置之一。但是anchor box的缺陷也是十分明显的,比如以下几点:
- 首先,anchor box的长宽比、面积和数量依赖于人工设计。纵然YOLOv2给出了基于kmeans聚类算法的设计anchor box的尺寸,但是anchor box的数量仍旧是个问题;
- 无论多么精心设计anchor box,一旦固定下来后,就不会再被改变。模型在一个训练集上被训练之后,已设定好的anchor box尽管可能在这个数据分布上表现够好,可一旦遇到不位于该数据分布的场景时,anchor box就可能存在不能泛化到新目标的问题;
- 另外,大量的anchor box使得预测框的数量变多,从而使得后处理阶段要处理大量的预测框,不仅加剧了算力消耗,也会拖慢模型的检测速度;
-
但是,如果没有先验框,能否做多级检测呢?
-
没有先验框进行多级检测,即anchor-free架构,首先要解决
哪个目标框应该被来自哪个尺度的预测框学习,即多尺度标签匹配问题。 -
在2019年,FCOS检测器被提出,其最大的特点就是彻底抛去了一直以来的anchor box,那么FCOS如何解决多尺度匹配问题呢?
-
FCOS一共使用五个特征图 P3、P4、P5、P6和P7 ,其输出步长stride分别为 8、16、32、64和128。FCOS为这每一个尺度都设定了一个尺度范围,即对于特征图 P_i ,其尺度范围是 (m_i−1,m_i) ,这五个尺度范围分别为 (0,64) 、(64,128)、(128,256)、(256,512),以及(512,∞)。
首先,我们去遍历特征图Pi上的每一个anchor,假设每一个anchor的坐标为 (xs_a+0.5,ys_a+0.5) ,其中(xs_a,ys_a)为anchor的左上角点坐标,也就是我们以前熟悉的网格左上角坐标的概念,但我们又为之加上了0.5亚像素坐标,即网格的中心点。我们求出特征图P_i上的anchor在输入图像上的坐标 (x_a,y_a) ,计算公式如下所示:
x a = x s a ∗ s + s / 2 y a = y s a ∗ s + s / 2 x_a=xs_a∗s+s/2 \\ y_a=ys_a∗s+s/2 xa=xsa∗s+s/2ya=ysa∗s+s/2
然后,我们求出处在边界框内的每一个anchor到边界框的四条边的距离:
l ∗ = x a − x 1 t ∗ = y a − y 1 r ∗ = x 2 − x a b ∗ = y 2 − y a l^∗=x_a−x_1 \\ t^∗=y_a−y_1 \\ r^∗=x_2−x_a \\ b^∗=y_2−y_a l∗=xa−x1t∗=ya−y1r∗=x2−xab∗=y2−ya
我们取其中的最大值 m=max(l∗,t∗,r∗,b∗) ,如果 m 满足 m_i−1<m<m_i ,则该anchor将被视为正样本,去学习自己到目标框四条边的距离。反之则为负样本。若是目标框的尺寸偏小,那它内部的anchor就会更多地落在较小的范围内,比如: (0,64),反之,则会更多地落在较大的范围内,如: (256,512) 。
换言之,FCOS设置的五个范围本质上是一种和目标自身大小相关的尺度范围,是基于一种
小的目标框更应该让输出步长小的也就是更大的特征图去学习,大的目标框则应该让输出步长更大的特征图去学习的直观理解。 -
但这个尺度还需要人工设计,没有摆脱人工先验的超参。
-
-
旷视科技在YOLOX种提出了SimOTA,摆脱了人工先验的超参,实现了真正意义的anchor-free,具体细节以后再讲。
-
相关文章:
YOLOv3的复现(2)正样本的匹配、损失函数的实现)
经典目标检测YOLO系列(三)YOLOv3的复现(2)正样本的匹配、损失函数的实现
经典目标检测YOLO系列(三)YOLOv3的复现(2)正样本的匹配、损失函数的实现 我们在之前实现YOLOv2的基础上,加入了多级检测及FPN,快速的实现了YOLOv3的网络架构,并且实现了前向推理过程。 经典目标检测YOLO系列(三)YOLOV3的复现(1)总体网络架构…...

编程笔记 html5cssjs 061 JavaScrip简介
编程笔记 html5&css&js 061 JavaScrip简介 一、JavaScript概述二、JavaScript的主要特点三、历史延革四、JavaScript与前端开发小结 JavaScript 是 web 开发者必学的三种语言之一:HTML 定义网页的内容;CSS 规定网页的布局;JavaScript…...

计算机网络 第5章(运输层)
系列文章目录 计算机网络 第1章(概述) 计算机网络 第2章(物理层) 计算机网络 第3章(数据链路层) 计算机网络 第4章(网络层) 计算机网络 第5章(运输层) 计算机…...

pythonSM4加密
数据安全法及密评要求,敏感数据系统需要使用国密算法进行加解密处理。 敏感数使用SM4/ECB加解密方式 #密钥参数epidemic_key #加密信息参数 message #加密算法SM4/ECB/PKCS5Padding #加密类型SM4-ECB #添加模式PKCS5Padding from cryptography.hazmat.primitives.…...
JSP在线阅读系统myeclipse定制开发SQLServer数据库网页模式java编程jdbc
一、源码特点 JSP 小说在线阅读系统是一套完善的web设计系统,对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库 ,系统主要采用B/S模式开发。开发环境为 TOMCAT7.0,Myeclipse8.5开发,数据库为SQLServer2008&#…...
el-date-picker设置default-time的默认时间
default-time :选择日期后的默认时间值。 如未指定则默认时间值为 00:00:00 默认值修改 <el-form-item label"计划开始时间" style"width: 100%;" prop"planStartTime"><el-date-picker v-model"formData.planStart…...

List集合根据对象某个元素去重
序言 检视代码时有下面这样一段代码(已脱敏处理), import java.util.*; import java.util.concurrent.ConcurrentHashMap; import java.util.function.Function; import java.util.function.Predicate; import java.util.stream.Collectors…...

QML Qt4版本移植到Qt5概述
C++代码 在Qt5中,QML应用程序使用OpenGL场景图架构来渲染,而在Qt4中使用的是图形视图框架。这种结构上的变化导致C++接口进行了大量重构。QtDeclarative模块已被弃用,该模块的类被移动到新的QtQML和QtQuick模块中,名称有了变化,如表3-1所列。如果需要使用Qt5中新的QQml和…...
【极数系列】Flink环境搭建Linux版本 (03)
文章目录 引言01 Linux部署JDK11版本1.下载Linux版本的JDK112.创建目录3.上传并解压4.配置环境变量5.刷新环境变量6.检查jdk安装是否成功 02 Linux部署Flink1.18.0版本1.下载Flink1.18.0版本包2.上传压缩包到服务器3.修改flink-config.yaml配置4.启动服务5.浏览器访问6.停止服务…...

2023年深圳市节假日人口迁入数据,shp/excel格式,需要自取!
基本信息. 数据名称: 深圳市节假日人口迁入数据 数据格式: Shp、excel 数据时间: 2023年国庆节 数据几何类型: 线 数据坐标系: WGS84 数据来源:网络公开数据 数据字段: 序号字段名称字段说明1a0928迁入人口占迁入深圳市人口的比值࿰…...
Windows10上通过MSYS2编译FFmpeg 6.1.1源码操作步骤
1.从github上clone代码,并切换到n6.1.1版本:clone到D:\DownLoad目录下 git clone https://github.com/FFmpeg/FFmpeg.git git checkout n6.1.1 2.安装MSYS2并编译FFmpeg源码: (1).从https://www.msys2.org/ 下载msys2-x86_64-20240113.exe &#…...

HiveSQL题——用户连续登陆
目录 一、连续登陆 1.1 连续登陆3天以上的用户 0 问题描述 1 数据准备 2 数据分析 3 小结 1.2 每个用户历史至今连续登录的最大天数 0 问题描述 1 数据准备 2 数据分析 3 小结 1.3 每个用户连续登录的最大天数(间断也算) 0 问题描述 1 数据准备 2 数据分析 3 小…...

题解仅供学习使用
...
)
Linux命令-apt-get命令(Debian Linux发行版中的APT软件包管理工具)
补充说明 apt-get命令 是Debian Linux发行版中的APT软件包管理工具。所有基于Debian的发行都使用这个 包管理系统。deb包可以把一个应用的文件包在一起,大体就如同Windows上的安装文件。 语法 apt-get [OPTION] PACKAGE选项 apt-get install 安装新包 apt-get r…...
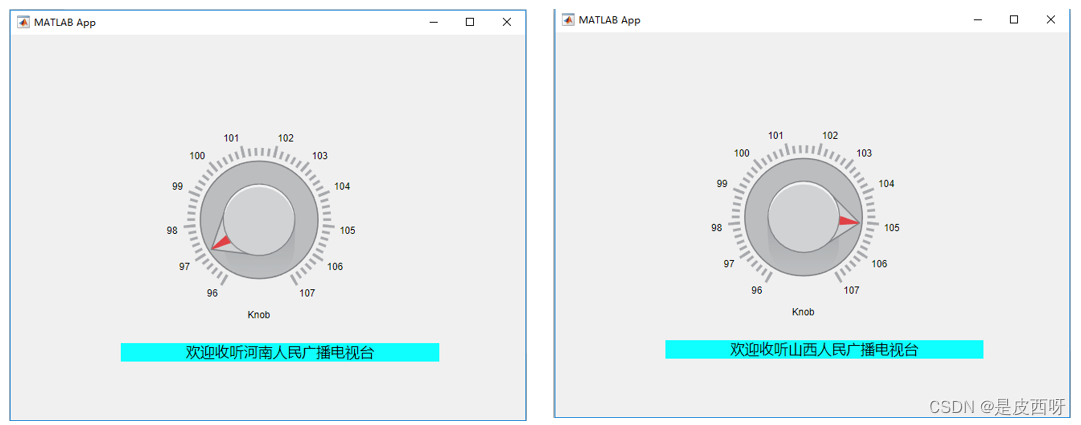
matlab appdesigner系列-仪器仪表3-旋钮
旋钮,同过旋转显示特定的值 示例:模拟收音机调频 操作步骤: 1)将旋钮、标签按钮拖拽到画布上,将标签文字修改为:欢迎收听,并将旋钮其数值范围改为90-107 2)设置旋钮的回调函数 代…...

常见の算法5
位图 一个int类型32字节,可以表示0-31这32个数出没出现过,出现过1没出现0,再扩大一点搞个数组,就可以表示0-1023出没出现过,一个long类型可储存64位 如何把10位组成的数,第四位由1改成零 package class05…...
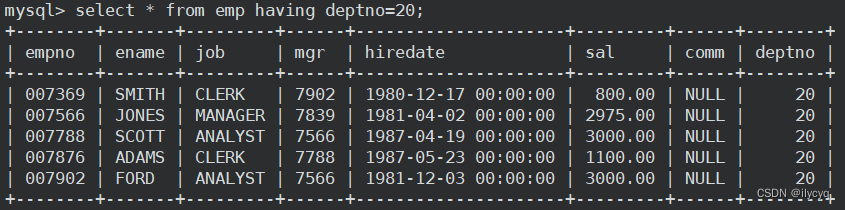
MYSQL中group by分组查询的用法详解(where和having的区别)!
文章目录 前言一、数据准备二、使用实例1.如何显示每个部门的平均工资和最高工资2.显示每个部门的每种岗位的平均工资和最低工资3.显示平均工资低于2000的部门和它的平均工资4.having 和 where 的区别5.SQL查询中各个关键字的执行先后顺序 前言 在前面的文章中,我们…...
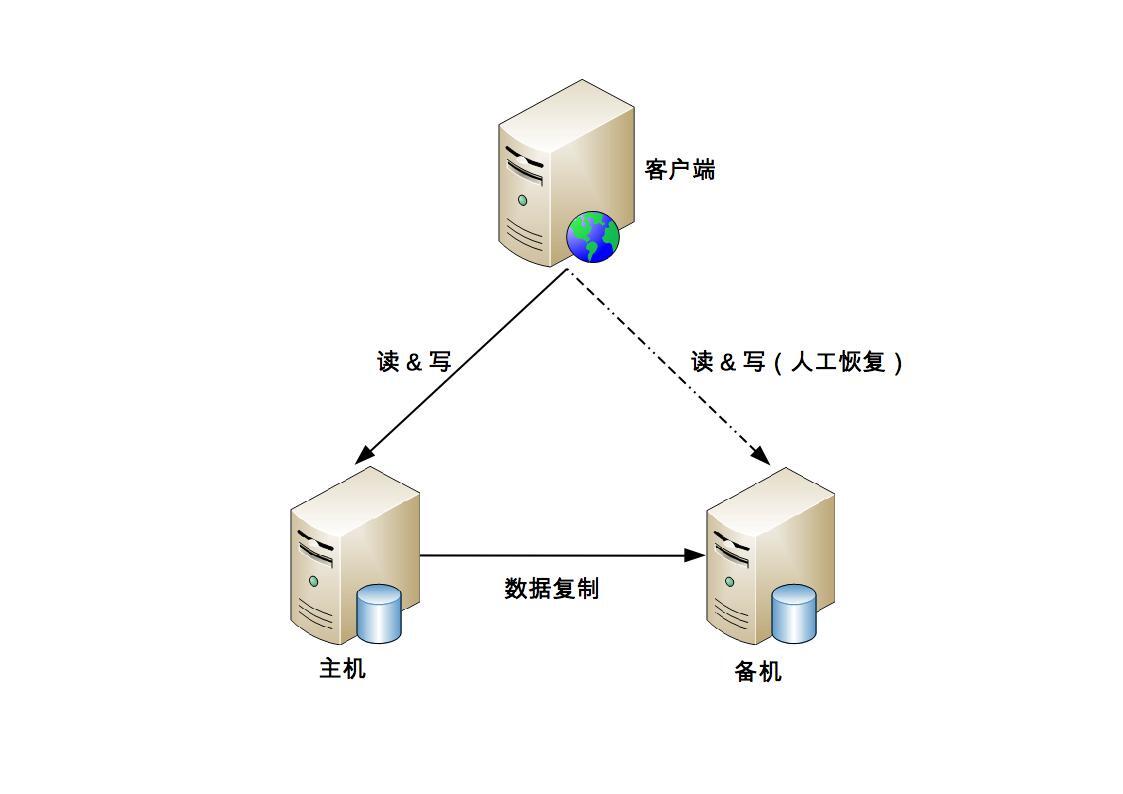
架构篇25:高可用存储架构-双机架构
文章目录 主备复制主从复制双机切换主主复制小结存储高可用方案的本质都是通过将数据复制到多个存储设备,通过数据冗余的方式来实现高可用,其复杂性主要体现在如何应对复制延迟和中断导致的数据不一致问题。因此,对任何一个高可用存储方案,我们需要从以下几个方面去进行思考…...

微信小程序(十五)自定义导航栏
注释很详细,直接上代码 上一篇 新增内容: 1.组件文件夹创建方法 2.自定义组件的配置方法 3.外部修改组件样式(关闭样式隔离或传参) 创建组件文件夹 如果是手动创建建议注意在json文件声明: mynav.json {//声明为组件可…...

Python3进行pdf文件分割及转word
今天有个pdf分割的需求,电脑装的Python3,网上查资料都是Python2的代码,所以整理一份3的 安装: pip install PyPDF2 import PyPDF2def funSplitPdf():pdf_file open(/path/fileName.pdf, rb)pdf_reader PyPDF2.PdfReader(pdf_fi…...

AX-MES生产制造管理系统-总览
前言说起 MES 就不得不说 ERP,但是 ERP 大家基本上都知道,MES 就不一定了,常见的 ERP 系统包括 SAP、金蝶、用友等,ERP的流程相对来说也比较统一;MES就不同了,基本上熟悉业务流程的软件公司都可以开发并实施…...

Kerberos身份认证原理与企业级排错实战指南
1. 这不是“另一个登录框”,而是一套精密运转的身份验证齿轮系统很多人第一次听说 Kerberos,是在公司内网登录邮箱或访问内部系统时,看到那个带小盾牌图标的弹窗——“正在使用 Kerberos 协议进行身份验证”。于是下意识觉得:“哦…...

HarmonyOS ArkTS DateUtil 日期增减与日历计算完整指南
文章目录 背景一、引言二、日期增减方法详解使用示例 三、日历计算方法详解四、Demo 演示:日期增减结果展示五、Demo 演示:月历视图完整实现六、日历视图关键点解析为什么要填充前置空格?getLastDayOfMonth 的实现技巧 七、小结 背景 近期发现…...

OpenClaw用户如何快速接入Taotoken并开始Agent工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 OpenClaw用户如何快速接入Taotoken并开始Agent工作流 对于使用OpenClaw框架构建AI智能体的开发者而言,快速接入稳定、多…...

长期使用Taotoken聚合服务对项目月度账单的可预测性提升
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken聚合服务对项目月度账单的可预测性提升 在AI驱动的项目开发与运营中,成本控制与预算规划是团队管理者…...

Burp Suite深度解析:从流量抓包到业务逻辑漏洞挖掘
1. 这不是“学个插件”——Burp Suite 是渗透测试的呼吸系统 很多人第一次听说 Burp Suite,是在某篇“三步拿下登录框”的速成教程里:装好Java、拖进浏览器代理、点几下Repeater就弹出密码明文。结果真去测一个中型SaaS后台,不到十分钟就卡在…...

FairyGUI Unity鼠标悬停与点击对象获取原理与实战
1. 这不是“加个OnMouseEnter就能用”的事:FairyGUI在Unity中处理鼠标交互的真实困境很多人第一次在Unity里集成FairyGUI,想实现“鼠标悬停显示提示”或“点击高亮当前按钮”,下意识就去翻Unity的MonoBehaviour文档,找OnMouseEnte…...

2026数据治理平台选型:五款产品如何赋能数据中台建设?
一、引言:数据中台的成败,关键在治理在数字化浪潮的席卷下,“数据中台”已成为当代企业信息化架构中的核心战略组件。然而,一个悖论正困扰着大量企业:数据中台的基础设施搭建日趋完善,但真正将数据转化为业…...

Driver Store Explorer终极指南:轻松管理Windows驱动存储区,释放宝贵磁盘空间
Driver Store Explorer终极指南:轻松管理Windows驱动存储区,释放宝贵磁盘空间 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否曾为Windows系统越来越慢而烦…...

反向海淘站点常见配置故障复盘与数据一致性优化方案
摘要反向海淘独立站运行过程中,容易出现价格换算异常、页面语种错乱、商品同步失败、订单状态停滞、运费计算偏差等问题。多数故障并非系统底层缺陷,而是配置逻辑理解偏差、数据规范不统一引发。本文结合实际运维场景,汇总高频故障成因&#…...