语义分割(2) :自定义Dataset和Dataloader
文章目录
- 1. 数据处理
- 1.1 标签转换(json2mask和json2yolo)
- 1.1.1 json2mask
- 1.1.2 json2yolo
- 1.2 划分数据集
- 1.2 不规范的标签图片处理
- 1.3 批量修改图片后缀
- 2 自定义Dataset 和 Dataloader
- 2.1 自定义Dataset
- 2.1.1 数据增强
- (1) 对图像进行缩放并且进行长和宽的扭曲
- (2) 随机翻转图像
- (3) 将图像多余的部分加上灰条
- (4) 高斯模糊
- (5) 旋转
- (6) 对图像进行色域变换
- 说明
- 2.1.2 HWC2CHW及one-hot编码
- 2.1.3 collate_fn实现
- 2.2 Dataloader
1. 数据处理
1.1 标签转换(json2mask和json2yolo)
1.1.1 json2mask
import argparse
import base64
import json
import os
import os.path as ospimport imgviz
import PIL.Imagefrom labelme.logger import logger
from labelme import utilsdef main():logger.warning("This script is aimed to demonstrate how to convert the ""JSON file to a single image dataset.")logger.warning("It won't handle multiple JSON files to generate a ""real-use dataset.")# json_file是标注完之后生成的json文件的目录。out_dir是输出目录,即数据处理完之后文件保存的路径json_file = r"D:\img\json_dir"out_jpgs_path = "datasets/JPEGImages"out_mask_path = "datasets/SegmentationClass"# 如果输出的路径不存在,则自动创建这个路径if not osp.exists(out_jpgs_path):os.mkdir(out_jpgs_path)if not osp.exists(out_mask_path):os.mkdir(out_mask_path)for file_name in os.listdir(json_file):# 遍历json_file里面所有的文件,并判断这个文件是不是以.json结尾if file_name.endswith(".json"):path = os.path.join(json_file, file_name)if os.path.isfile(path):data = json.load(open(path))# 获取json里面的图片数据,也就是二进制数据imageData = data.get("imageData")# 如果通过data.get获取到的数据为空,就重新读取图片数据if not imageData:imagePath = os.path.join(json_file, data["imagePath"])with open(imagePath, "rb") as f:imageData = f.read()imageData = base64.b64encode(imageData).decode("utf-8")# 将二进制数据转变成numpy格式的数据img = utils.img_b64_to_arr(imageData)# 将类别名称转换成数值,以便于计算label_name_to_value = {"_background_": 0}for shape in sorted(data["shapes"], key=lambda x: x["label"]):label_name = shape["label"]if label_name in label_name_to_value:label_value = label_name_to_value[label_name]else:label_value = len(label_name_to_value)label_name_to_value[label_name] = label_valuelbl, _ = utils.shapes_to_label(img.shape, data["shapes"], label_name_to_value)label_names = [None] * (max(label_name_to_value.values()) + 1)for name, value in label_name_to_value.items():label_names[value] = namelbl_viz = imgviz.label2rgb(label=lbl, image=imgviz.asgray(img), label_names=label_names, loc="rb")# 将输出结果保存,PIL.Image.fromarray(img).save(osp.join(out_jpgs_path, file_name.split(".")[0]+'.jpg'))utils.lblsave(osp.join(out_mask_path, "%s.png" % file_name.split(".")[0]), lbl)print("Done")if __name__ == "__main__":main()1.1.2 json2yolo
# -*- coding: utf-8 -*-
import json
import os
import argparse
from tqdm import tqdm
import glob
import cv2
import numpy as np
import shutil
import random
from pathlib import Pathimport os
import shutildef create_folder(path='./new'):# Create folderif os.path.exists(path):shutil.rmtree(path) # delete output folderos.makedirs(path) # make new output folderdef check_labels(txt_labels, images_dir):create_folder("output")txt_files = glob.glob(txt_labels + "/*.txt")[:20]for txt_file in txt_files:filename = os.path.splitext(os.path.basename(txt_file))[0]pic_path = images_dir +os.sep+ filename + ".png"img = cv2.imread(pic_path)if img is None:print('img not found:',pic_path)height, width, _ = img.shapefile_handle = open(txt_file)cnt_info = file_handle.readlines()new_cnt_info = [line_str.replace("\n", "").split(" ") for line_str in cnt_info]color_map = {"0": (0, 255, 0),"1":(0,0,255),"2":(255,0,0),"3":(125,225,0),"4":(0,255,255),"5": (100, 120, 0),"6":(120,0,155),"7":(200,50,0),"8":(125,25,10),"9":(80,60,155)}for new_info in new_cnt_info:# print(new_info)s = []for i in range(1, len(new_info), 2):b = [float(tmp) for tmp in new_info[i:i + 2]]s.append([int(b[0] * width), int(b[1] * height)])cv2.polylines(img, [np.array(s, np.int32)], True, color_map.get(new_info[0]))out_path =os.path.join("output",filename+".jpg")cv2.imwrite(out_path,img)def convert_label_json(json_dir, save_dir, classes):classes = classes.split(',')# lbl_jsons = glob.glob(os.path.join(json_dir, "*.json"))for json_path in tqdm(glob.glob(os.path.join(json_dir, "*.json")),desc='start convert'):json_name=Path(json_path).name# print(path)with open(json_path, 'r') as load_f:json_dict = json.load(load_f, )h, w = json_dict['imageHeight'], json_dict['imageWidth']# save txt pathtxt_path = os.path.join(save_dir, json_name.replace('json', 'txt'))with open(txt_path, 'w') as txt_file:for shape_dict in json_dict['shapes']:label = shape_dict['label']if label.lower() in ["_background_"]:continuelabel_index = classes.index(label)points = shape_dict['points']points_nor_list = []for point in points:points_nor_list.append(round(point[0] / w,4))points_nor_list.append(round(point[1] / h,4))points_nor_list = list(map(lambda x: str(x), points_nor_list))points_nor_str = ' '.join(points_nor_list)label_str = str(label_index) + ' ' + points_nor_str + '\n'txt_file.writelines(label_str)if __name__ == "__main__":parser = argparse.ArgumentParser(description='json convert to txt params')parser.add_argument('--ori-imgdir', type=str, default='Dataset/JPEGImages', help='json path dir')parser.add_argument('--json-dir', type=str, default='Dataset/Json', help='json path dir')parser.add_argument('--save-dir', type=str, default='Dataset/yolo_label', help='txt save dir')parser.add_argument('--classes', type=str, default='', help='classes')parser.add_argument('--check-img',action='store_true',help='check json label')args = parser.parse_args()json_dir = args.json_dirlbl_txt_dir = args.save_dirimages_dir = args.ori_imgdirclasses = "car,dog,train,bus,person,truck, boat, traffic light,bear"args.check_img = False if not args.check_img:if os.path.exists(lbl_txt_dir):shutil.rmtree(lbl_txt_dir)os.makedirs(lbl_txt_dir)convert_label_json(json_dir, lbl_txt_dir, classes)else:check_labels(lbl_txt_dir, images_dir)1.2 划分数据集
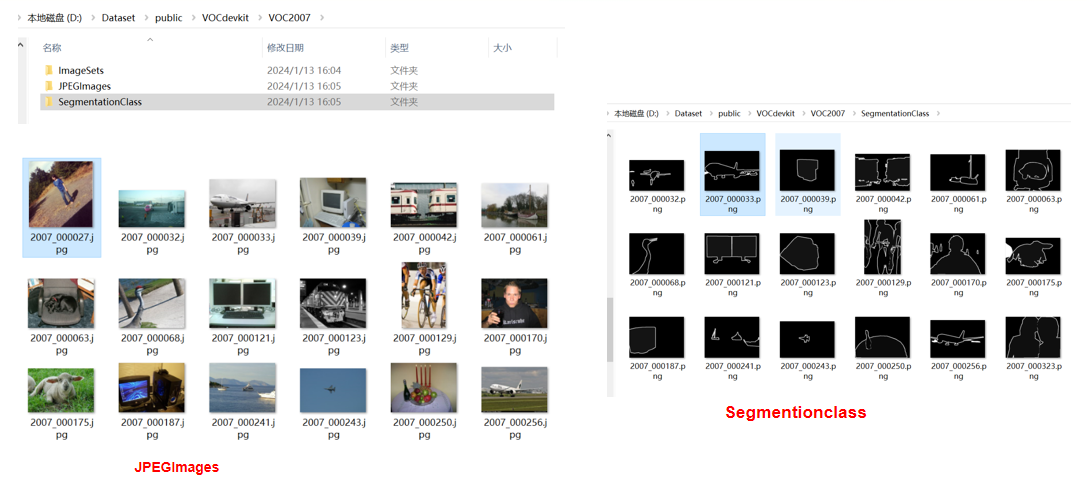
- 上图为VOC 2007的数据集,其中文件夹
JPEGImages存放原始images,Segmentionclass存放分割的标签, 标签的每个像素对应真实的类别索引。 - 图片和标签都已经准备好的话,接下来我们需要划分:
训练集、验证集、测试集, 代码实现如下:
import os
import randomimport numpy as np
from PIL import Image
from tqdm import tqdm#-------------------------------------------------------#
# 想要增加测试集修改trainval_percent
# 修改train_percent用于改变验证集的比例 9:1
#
# 当前该库将测试集当作验证集使用,不单独划分测试集
#-------------------------------------------------------#
trainval_percent = 1
train_percent = 0.9
#-------------------------------------------------------#
# 指向VOC数据集所在的文件夹
# 默认指向根目录下的VOC数据集
#-------------------------------------------------------#
VOCdevkit_path = 'VOCdevkit'if __name__ == "__main__":random.seed(0)print("Generate txt in ImageSets.")segfilepath = os.path.join(VOCdevkit_path, 'VOC2007/SegmentationClass')saveBasePath = os.path.join(VOCdevkit_path, 'VOC2007/ImageSets/Segmentation')temp_seg = os.listdir(segfilepath)total_seg = []for seg in temp_seg:if seg.endswith(".png"):total_seg.append(seg)num = len(total_seg) list = range(num) tv = int(num*trainval_percent) tr = int(tv*train_percent) trainval= random.sample(list,tv) train = random.sample(trainval,tr) print("train and val size",tv)print("train size",tr)ftrainval = open(os.path.join(saveBasePath,'trainval.txt'), 'w') ftest = open(os.path.join(saveBasePath,'test.txt'), 'w') ftrain = open(os.path.join(saveBasePath,'train.txt'), 'w') fval = open(os.path.join(saveBasePath,'val.txt'), 'w') for i in list: name = total_seg[i][:-4]+'\n' if i in trainval: ftrainval.write(name) if i in train: ftrain.write(name) else: fval.write(name) else: ftest.write(name) ftrainval.close() ftrain.close() fval.close() ftest.close()print("Generate txt in ImageSets done.")print("Check datasets format, this may take a while.")print("检查数据集格式是否符合要求,这可能需要一段时间。")classes_nums = np.zeros([256], np.int)for i in tqdm(list):name = total_seg[i]png_file_name = os.path.join(segfilepath, name)if not os.path.exists(png_file_name):raise ValueError("未检测到标签图片%s,请查看具体路径下文件是否存在以及后缀是否为png。"%(png_file_name))png = np.array(Image.open(png_file_name), np.uint8)if len(np.shape(png)) > 2:print("标签图片%s的shape为%s,不属于灰度图或者八位彩图,请仔细检查数据集格式。"%(name, str(np.shape(png))))print("标签图片需要为灰度图或者八位彩图,标签的每个像素点的值就是这个像素点所属的种类。"%(name, str(np.shape(png))))classes_nums += np.bincount(np.reshape(png, [-1]), minlength=256)print("打印像素点的值与数量。")print('-' * 37)print("| %15s | %15s |"%("Key", "Value"))print('-' * 37)for i in range(256):if classes_nums[i] > 0:print("| %15s | %15s |"%(str(i), str(classes_nums[i])))print('-' * 37)if classes_nums[255] > 0 and classes_nums[0] > 0 and np.sum(classes_nums[1:255]) == 0:print("检测到标签中像素点的值仅包含0与255,数据格式有误。")print("二分类问题需要将标签修改为背景的像素点值为0,目标的像素点值为1。")elif classes_nums[0] > 0 and np.sum(classes_nums[1:]) == 0:print("检测到标签中仅仅包含背景像素点,数据格式有误,请仔细检查数据集格式。")print("JPEGImages中的图片应当为.jpg文件、SegmentationClass中的图片应当为.png文件。")print("如果格式有误,参考:")print("https://github.com/bubbliiiing/segmentation-format-fix")
-
(1)首先划分数据集, 其中:trainval_percent表示train、val占整的数据集比率,如果不需要测试集的话,trainval_percent可以设置为1;train_percent表示train和val的占比,train_percent=0.9表示train和val为9:1 -
(2) 检测标签图片: 首先标签图片为单通道8位灰度图或者彩色图,标签图片的shape为2, 如果shape大小不为2, 说明标签图片是有问题的。
png = np.array(Image.open(png_file_name), np.uint8)
if len(np.shape(png)) > 2:print("标签图片%s的shape为%s,不属于灰度图或者八位彩图,请仔细检查数据集格式。"%(name, str(np.shape(png))))print("标签图片需要为灰度图或者八位彩图,标签的每个像素点的值就是这个像素点所属的种类。"%(name, str(np.shape(png))))
(3) 统计印像素类别与数量
for i in tqdm(list):name = total_seg[i]png_file_name = os.path.join(segfilepath, name)if not os.path.exists(png_file_name):raise ValueError("未检测到标签图片%s,请查看具体路径下文件是否存在以及后缀是否为png。"%(png_file_name))png = np.array(Image.open(png_file_name), np.uint8)if len(np.shape(png)) > 2:print("标签图片%s的shape为%s,不属于灰度图或者八位彩图,请仔细检查数据集格式。"%(name, str(np.shape(png))))print("标签图片需要为灰度图或者八位彩图,标签的每个像素点的值就是这个像素点所属的种类。"%(name, str(np.shape(png))))classes_nums += np.bincount(np.reshape(png, [-1]), minlength=256)print("打印像素点的值与数量。")print('-' * 37)print("| %15s | %15s |"%("Key", "Value"))print('-' * 37)for i in range(256):if classes_nums[i] > 0:print("| %15s | %15s |"%(str(i), str(classes_nums[i])))print('-' * 37)
1.2 不规范的标签图片处理
Convert_SegmentationClass.py
标签的像素值,应该为分割类别的索引,可以通过以下代码,将标签的像素值替换为类别索引
#--------------------------------------------------------#
# 该文件用于调整标签的格式
#--------------------------------------------------------#
import osimport numpy as np
from PIL import Image
from tqdm import tqdm#-----------------------------------------------------------------------------------#
# Origin_SegmentationClass_path 原始标签所在的路径
# Out_SegmentationClass_path 输出标签所在的路径
# 处理后的标签为灰度图,如果设置的值太小会看不见具体情况。
#-----------------------------------------------------------------------------------#
Origin_SegmentationClass_path = "SegmentationClass_Origin"
Out_SegmentationClass_path = "SegmentationClass"#-----------------------------------------------------------------------------------#
# Origin_Point_Value 原始标签对应的像素点值
# Out_Point_Value 输出标签对应的像素点值
# Origin_Point_Value需要与Out_Point_Value一一对应。
# 举例如下,当:
# Origin_Point_Value = np.array([0, 255]);Out_Point_Value = np.array([0, 1])
# 代表将原始标签中值为0的像素点,调整为0,将原始标签中值为255的像素点,调整为1。
#
# 示例中仅调整了两个像素点值,实际上可以更多个,如:
# Origin_Point_Value = np.array([0, 128, 255]);Out_Point_Value = np.array([0, 1, 2])
#
# 也可以是数组(当标签值为RGB像素点时),如
# Origin_Point_Value = np.array([[0, 0, 0], [1, 1, 1]]);Out_Point_Value = np.array([0, 1])
#-----------------------------------------------------------------------------------#
Origin_Point_Value = np.array([0, 255])
Out_Point_Value = np.array([0, 1])if __name__ == "__main__":if not os.path.exists(Out_SegmentationClass_path):os.makedirs(Out_SegmentationClass_path)#---------------------------## 遍历标签并赋值#---------------------------#png_names = os.listdir(Origin_SegmentationClass_path)print("正在遍历全部标签。")for png_name in tqdm(png_names):png = Image.open(os.path.join(Origin_SegmentationClass_path, png_name))w, h = png.sizepng = np.array(png)out_png = np.zeros([h, w])for i in range(len(Origin_Point_Value)):mask = png[:, :] == Origin_Point_Value[i]if len(np.shape(mask)) > 2:mask = mask.all(-1)out_png[mask] = Out_Point_Value[i]out_png = Image.fromarray(np.array(out_png, np.uint8))out_png.save(os.path.join(Out_SegmentationClass_path, png_name))#-------------------------------------## 统计输出,各个像素点的值得个数#-------------------------------------#print("正在统计输出的图片每个像素点的数量。")classes_nums = np.zeros([256], np.int)for png_name in tqdm(png_names):png_file_name = os.path.join(Out_SegmentationClass_path, png_name)if not os.path.exists(png_file_name):raise ValueError("未检测到标签图片%s,请查看具体路径下文件是否存在以及后缀是否为png。"%(png_file_name))png = np.array(Image.open(png_file_name), np.uint8)classes_nums += np.bincount(np.reshape(png, [-1]), minlength=256)print("打印像素点的值与数量。")print('-' * 37)print("| %15s | %15s |"%("Key", "Value"))print('-' * 37)for i in range(256):if classes_nums[i] > 0:print("| %15s | %15s |"%(str(i), str(classes_nums[i])))print('-' * 37)
- 假设8为单通道 分割的标签图片的像素值,只有两类,对应的像素值为
0, 255, 此时我们需要将像素值转换为类别索引0和1
1.3 批量修改图片后缀
#--------------------------------------------------------#
# 该文件用于调整输入彩色图片的后缀
#--------------------------------------------------------#
import osimport numpy as np
from PIL import Image
from tqdm import tqdm#--------------------------------------------------------#
# Origin_JPEGImages_path 原始标签所在的路径
# Out_JPEGImages_path 输出标签所在的路径
#--------------------------------------------------------#
Origin_JPEGImages_path = "JPEGImages_Origin"
Out_JPEGImages_path = "JPEGImages"
convert_suffix = ".jpg"if __name__ == "__main__":if not os.path.exists(Out_JPEGImages_path):os.makedirs(Out_JPEGImages_path)#---------------------------## 遍历标签并赋值#---------------------------#image_names = os.listdir(Origin_JPEGImages_path)print("正在遍历全部图片。")for image_name in tqdm(image_names):image = Image.open(os.path.join(Origin_JPEGImages_path, image_name))image = image.convert('RGB')image.save(os.path.join(Out_JPEGImages_path, os.path.splitext(image_name)[0] + convert_suffix))
2 自定义Dataset 和 Dataloader
- 自定义Dataset需要继承
Dataset - 需要实现
__len__和__getitem__方法, - 其中
__len__返回样本的总数量,__getitem__方法,根据传入的index,返回对应的图片和标签图片mask __getitem__主要对图片和标签进行数据增强- Dataset的完整代码实现如下:
2.1 自定义Dataset
import cv2
import numpy as np
import torch
from PIL import Image
from torch.utils.data.dataset import Datasetfrom utils.utils import cvtColor, preprocess_inputclass DeeplabDataset(Dataset):def __init__(self, annotation_lines, input_shape, num_classes, train, dataset_path):super(DeeplabDataset, self).__init__()self.annotation_lines = annotation_linesself.length = len(annotation_lines)self.input_shape = input_shapeself.num_classes = num_classesself.train = trainself.dataset_path = dataset_pathdef __len__(self):return self.lengthdef __getitem__(self, index):annotation_line = self.annotation_lines[index]name = annotation_line.split()[0]#-------------------------------## 从文件中读取图像#-------------------------------#jpg = Image.open(os.path.join(os.path.join(self.dataset_path, "VOC2007/JPEGImages"), name + ".jpg"))png = Image.open(os.path.join(os.path.join(self.dataset_path, "VOC2007/SegmentationClass"), name + ".png"))#-------------------------------## 数据增强#-------------------------------#jpg, png = self.get_random_data(jpg, png, self.input_shape, random = self.train)jpg = np.transpose(preprocess_input(np.array(jpg, np.float64)), [2,0,1])png = np.array(png)png[png >= self.num_classes] = self.num_classes#-------------------------------------------------------## 转化成one_hot的形式# 在这里需要+1是因为voc数据集有些标签具有白边部分# 我们需要将白边部分进行忽略,+1的目的是方便忽略。#-------------------------------------------------------#seg_labels = np.eye(self.num_classes + 1)[png.reshape([-1])]seg_labels = seg_labels.reshape((int(self.input_shape[0]), int(self.input_shape[1]), self.num_classes + 1))return jpg, png, seg_labelsdef rand(self, a=0, b=1):return np.random.rand() * (b - a) + adef get_random_data(self, image, label, input_shape, jitter=.3, hue=.1, sat=0.7, val=0.3, random=True):image = cvtColor(image)label = Image.fromarray(np.array(label))#------------------------------## 获得图像的高宽与目标高宽#------------------------------#iw, ih = image.sizeh, w = input_shapeif not random:iw, ih = image.sizescale = min(w/iw, h/ih)nw = int(iw*scale)nh = int(ih*scale)image = image.resize((nw,nh), Image.BICUBIC)new_image = Image.new('RGB', [w, h], (128,128,128))new_image.paste(image, ((w-nw)//2, (h-nh)//2))label = label.resize((nw,nh), Image.NEAREST)new_label = Image.new('L', [w, h], (0))new_label.paste(label, ((w-nw)//2, (h-nh)//2))return new_image, new_label#------------------------------------------## 对图像进行缩放并且进行长和宽的扭曲#------------------------------------------#new_ar = iw/ih * self.rand(1-jitter,1+jitter) / self.rand(1-jitter,1+jitter)scale = self.rand(0.25, 2)if new_ar < 1:nh = int(scale*h)nw = int(nh*new_ar)else:nw = int(scale*w)nh = int(nw/new_ar)image = image.resize((nw,nh), Image.BICUBIC)label = label.resize((nw,nh), Image.NEAREST)#------------------------------------------## 翻转图像#------------------------------------------#flip = self.rand()<.5if flip: image = image.transpose(Image.FLIP_LEFT_RIGHT)label = label.transpose(Image.FLIP_LEFT_RIGHT)#------------------------------------------## 将图像多余的部分加上灰条#------------------------------------------#dx = int(self.rand(0, w-nw))dy = int(self.rand(0, h-nh))new_image = Image.new('RGB', (w,h), (128,128,128))new_label = Image.new('L', (w,h), (0))new_image.paste(image, (dx, dy))new_label.paste(label, (dx, dy))image = new_imagelabel = new_labelimage_data = np.array(image, np.uint8)#------------------------------------------## 高斯模糊#------------------------------------------#blur = self.rand() < 0.25if blur: image_data = cv2.GaussianBlur(image_data, (5, 5), 0)#------------------------------------------## 旋转#------------------------------------------#rotate = self.rand() < 0.25if rotate: center = (w // 2, h // 2)rotation = np.random.randint(-10, 11)M = cv2.getRotationMatrix2D(center, -rotation, scale=1)image_data = cv2.warpAffine(image_data, M, (w, h), flags=cv2.INTER_CUBIC, borderValue=(128,128,128))label = cv2.warpAffine(np.array(label, np.uint8), M, (w, h), flags=cv2.INTER_NEAREST, borderValue=(0))#---------------------------------## 对图像进行色域变换# 计算色域变换的参数#---------------------------------#r = np.random.uniform(-1, 1, 3) * [hue, sat, val] + 1#---------------------------------## 将图像转到HSV上#---------------------------------#hue, sat, val = cv2.split(cv2.cvtColor(image_data, cv2.COLOR_RGB2HSV))dtype = image_data.dtype#---------------------------------## 应用变换#---------------------------------#x = np.arange(0, 256, dtype=r.dtype)lut_hue = ((x * r[0]) % 180).astype(dtype)lut_sat = np.clip(x * r[1], 0, 255).astype(dtype)lut_val = np.clip(x * r[2], 0, 255).astype(dtype)image_data = cv2.merge((cv2.LUT(hue, lut_hue), cv2.LUT(sat, lut_sat), cv2.LUT(val, lut_val)))image_data = cv2.cvtColor(image_data, cv2.COLOR_HSV2RGB)return image_data, labelDataset的使用
input_shape = [512, 512]
with open(os.path.join(VOCdevkit_path, "VOC2007/ImageSets/Segmentation/train.txt"),"r") as f:train_lines = f.readlines()
with open(os.path.join(VOCdevkit_path, "VOC2007/ImageSets/Segmentation/val.txt"),"r") as f:val_lines = f.readlines()
train_dataset = DeeplabDataset(train_lines, input_shape, num_classes, True, VOCdevkit_path)
val_dataset = DeeplabDataset(val_lines, input_shape, num_classes, False, VOCdevkit_path)
对获得的图片和标签图片数据增强,提供模型的泛化能力,通过get_random_data函数实现
2.1.1 数据增强
(1) 对图像进行缩放并且进行长和宽的扭曲
def rand(self, a=0, b=1):return np.random.rand() * (b - a) + anew_ar = iw/ih * self.rand(1-jitter,1+jitter) / self.rand(1-jitter,1+jitter)
scale = self.rand(0.25, 2)
if new_ar < 1:nh = int(scale*h)nw = int(nh*new_ar)
else:nw = int(scale*w)nh = int(nw/new_ar)
image = image.resize((nw,nh), Image.BICUBIC)
label = label.resize((nw,nh), Image.NEAREST)其中iw和ih分别为图片image的width和weight, h 和w为input_shape
- 根据随机数,对宽高比率进行调整,调整后的宽高比为new_ar,
jitter默认为0.3
new_ar = iw/ih * self.rand(1-jitter,1+jitter) / self.rand(1-jitter,1+jitter)
- 随机生成
0.25~2的缩放系数,将长边根据缩放系数进行缩放得到新的长边,短边根据新的宽高比new_ar进行调整,获得新的尺寸(nh,nw)
scale = self.rand(0.25, 2)
if new_ar < 1:nh = int(scale*h)nw = int(nh*new_ar)
else:nw = int(scale*w)nh = int(nw/new_ar)
- 然后将image和label 分别resize到
(nh,nw)
image = image.resize((nw,nh), Image.BICUBIC)
label = label.resize((nw,nh), Image.NEAREST)
由于标签label图片的每个像素值,为类别索引,是一个整数,所以只能用最近邻插值NEAREST
(2) 随机翻转图像
flip = self.rand()<.5
if flip: image = image.transpose(Image.FLIP_LEFT_RIGHT)label = label.transpose(Image.FLIP_LEFT_RIGHT)
(3) 将图像多余的部分加上灰条
dx = int(self.rand(0, w-nw))
dy = int(self.rand(0, h-nh))
new_image = Image.new('RGB', (w,h), (128,128,128))
new_label = Image.new('L', (w,h), (0))
new_image.paste(image, (dx, dy))
new_label.paste(label, (dx, dy))
image = new_image
label = new_label
将原始图片image和label,利用padding填充到input_shape(模型输入大小)
- 首先创建
new_image,大小为input_shape:(w,h),填充(128,128,128)的像素值;创建new_label, 大小为input_shape:(w,h),填充(0,0,0)的像素值 - 在image和label 粘贴到
new_image和new_label中,粘贴的其实位置(x,y)为(0, w-nw)和(0, h-nh)之间的随机值。
(4) 高斯模糊
blur = self.rand() < 0.25
if blur: image_data = cv2.GaussianBlur(image_data, (5, 5), 0)
(5) 旋转
rotate = self.rand() < 0.25
if rotate: center = (w // 2, h // 2)rotation = np.random.randint(-10, 11)M = cv2.getRotationMatrix2D(center, -rotation, scale=1)image_data = cv2.warpAffine(image_data, M, (w, h), flags=cv2.INTER_CUBIC, borderValue=(128,128,128))label = cv2.warpAffine(np.array(label, np.uint8), M, (w, h), flags=cv2.INTER_NEAREST, borderValue=(0))
- 对图片和标签图片利用放射变换
warpAffine,进行旋转 - 旋转中心为
(w // 2, h // 2), 旋转角度为: -10~10 度之间 - 主要
标签的插值,只能用最近邻插值
(6) 对图像进行色域变换
#---------------------------------#
# 对图像进行色域变换
# 计算色域变换的参数
#---------------------------------#
r = np.random.uniform(-1, 1, 3) * [hue, sat, val] + 1
#---------------------------------#
# 将图像转到HSV上
#---------------------------------#
hue, sat, val = cv2.split(cv2.cvtColor(image_data, cv2.COLOR_RGB2HSV))
dtype = image_data.dtype
#---------------------------------#
# 应用变换
#---------------------------------#
x = np.arange(0, 256, dtype=r.dtype)
lut_hue = ((x * r[0]) % 180).astype(dtype)
lut_sat = np.clip(x * r[1], 0, 255).astype(dtype)
lut_val = np.clip(x * r[2], 0, 255).astype(dtype)image_data = cv2.merge((cv2.LUT(hue, lut_hue), cv2.LUT(sat, lut_sat), cv2.LUT(val, lut_val)))
image_data = cv2.cvtColor(image_data, cv2.COLOR_HSV2RGB)
注意: 色域变换只作用于原始图片,颜色变换对label没有影像,因此label不发生变化。
说明
- 每种数据增强,都是以一定概率发生的,需要根据实际调整概率的大小
数据增强一般只作用于train过程,对于val和test不需要数据增强。不需要数据增强此时,只需要对图片image和label利用letterbox变换,进行不失真的缩放以及padding填充,然后返回经过letterbox处理的Image和label
if not random:iw, ih = image.sizescale = min(w/iw, h/ih)nw = int(iw*scale)nh = int(ih*scale)image = image.resize((nw,nh), Image.BICUBIC)new_image = Image.new('RGB', [w, h], (128,128,128))new_image.paste(image, ((w-nw)//2, (h-nh)//2))label = label.resize((nw,nh), Image.NEAREST)new_label = Image.new('L', [w, h], (0))new_label.paste(label, ((w-nw)//2, (h-nh)//2))return new_image, new_label
- 训练时, random=True, val和test时, random = False,即不需要数据增强,直接返回letterbox后的image和label。
2.1.2 HWC2CHW及one-hot编码
def preprocess_input(image):image /= 255.0return image
j
pg = np.transpose(preprocess_input(np.array(jpg, np.float64)), [2,0,1])
png = np.array(png)png[png >= self.num_classes] = self.num_classes
#-------------------------------------------------------#
# 转化成one_hot的形式
# 在这里需要+1是因为voc数据集有些标签具有白边部分
# 我们需要将白边部分进行忽略,+1的目的是方便忽略。
#-------------------------------------------------------#
seg_labels = np.eye(self.num_classes + 1)[png.reshape([-1])]
seg_labels = seg_labels.reshape((int(self.input_shape[0]), int(self.input_shape[1]), self.num_classes + 1))
- 利用
preprocess_input将图片数据进行归一化 - 利用
np.transpose,将HWC转为CHW - 处理异常的像素值,将像素值大于self.num_classes,设置为self.num_classes
pg = np.transpose(preprocess_input(np.array(jpg, np.float64)), [2,0,1])
png = np.array(png)
png[png >= self.num_classes] = self.num_classes
- 将标签转换为one-hot编码,便于softmax计算损失
seg_labels = np.eye(self.num_classes + 1)[png.reshape([-1])]
seg_labels = seg_labels.reshape((int(self.input_shape[0]), int(self.input_shape[1]), self.num_classes + 1))
- 利用
seg_labels = np.eye(self.num_classes + 1)[png.reshape([-1])],得到了seg_labels 的shape大小为(h*w,self.num_classes + 1),每个像素值,对应一个one-hot编码的类别表示形式。 - 然后将seg_labels ,进行reshape为
(h,w,self.num_classes + 1) - 在这里需要对
self.num_classes进行+1是因为voc数据集有些标签具有白边部分 - 我们
需要将白边部分进行忽略,+1的目的是方便忽略。
2.1.3 collate_fn实现
在Dataloader中需要传入实现好的collate_fn函数,告诉dataloader,每个batch需要返回的数据。
def deeplab_dataset_collate(batch):images = []pngs = []seg_labels = []for img, png, labels in batch:images.append(img)pngs.append(png)seg_labels.append(labels)images = torch.from_numpy(np.array(images)).type(torch.FloatTensor)pngs = torch.from_numpy(np.array(pngs)).long()seg_labels = torch.from_numpy(np.array(seg_labels)).type(torch.FloatTensor)return images, pngs, seg_labels
2.2 Dataloader
from torch.utils.data import DataLoader
train_dataset = DeeplabDataset(train_lines, input_shape, num_classes, True, VOCdevkit_path)
val_dataset = DeeplabDataset(val_lines, input_shape, num_classes, False, VOCdevkit_path)if distributed:train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset, shuffle=True,)val_sampler = torch.utils.data.distributed.DistributedSampler(val_dataset, shuffle=False,)batch_size = batch_size // ngpus_per_nodeshuffle = False
else:train_sampler = Noneval_sampler = Noneshuffle = Truetrain_dataloader = DataLoader(train_dataset, shuffle = shuffle, batch_size = batch_size, num_workers = num_workers, pin_memory=True,drop_last = True, collate_fn = deeplab_dataset_collate, sampler=train_sampler, worker_init_fn=partial(worker_init_fn, rank=rank, seed=seed))
val_loader = DataLoader(val_dataset , shuffle = shuffle, batch_size = batch_size, num_workers = num_workers, pin_memory=True, drop_last = True, collate_fn = deeplab_dataset_collate, sampler=val_sampler, worker_init_fn=partial(worker_init_fn, rank=rank, seed=seed))
- 利用自定义的Dataset类:
DeeplabDataset,获得train_dataset和val_dataset - 利用pytorch实现的DataLoader接口,传入
train_dataset和val_dataset,并指定batch_size,num_workers,pin_memory,collate_fn以及sampler, 就可以获得对应的train_dataloader和val_dataloader。 - 如果是
DDP训练,需要利用torch.utils.data.distributed.DistributedSampler实现train_sampler和val_sampler, 其中train_sampler需要对数据进行打乱,即shuffle设置为True,对于val_sampler则不需要打乱,即shuffle设置为False - 由于在
DDP模式下, train_sampler已经进行打乱设置了shuffle=True, 因此在构建Datalader时,传入的参数shuffle,就不需要再重复shuffle打扰了,因此Dataloader的shuffle参数设置为False
if distributed:train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset, shuffle=True,)val_sampler = torch.utils.data.distributed.DistributedSampler(val_dataset, shuffle=False,)shuffle = False
- 如果
不是DDP训练,train_sampler和val_sampler都设置为None, 由于没有对数据进行shuffle打乱,因此在Datalader中,需要指定shuffle为True
train_sampler = None
val_sampler = None
shuffle = True
相关文章:
语义分割(2) :自定义Dataset和Dataloader
文章目录 1. 数据处理1.1 标签转换(json2mask和json2yolo)1.1.1 json2mask1.1.2 json2yolo 1.2 划分数据集1.2 不规范的标签图片处理1.3 批量修改图片后缀 2 自定义Dataset 和 Dataloader2.1 自定义Dataset2.1.1 数据增强(1) 对图像进行缩放并且进行长和宽的扭曲(2) 随机翻转图…...
Android Automotive:在路上释放 Android 操作系统的力量
Android Automotive:在路上释放 Android 操作系统的力量 Android 在汽车行业的历程车载信息娱乐系统 (IVI) 的演变汽车中的 Android:演变和进步Android 汽车操作系统的崛起Polestar 2:开创 Android 汽车体验Android 开源项目 (AOSP) 及其他项…...

从零开始做题:逆向 ret2shellcode orw
1.题目信息 BUUCTF在线评测 下载orw时防病毒要关闭 2.题目分析 orw是open、read、write的简写。有时候binary会通过prctl、seccomp进行沙箱保护,并不能getshell。只能通过orw的方式拿到flag。 fdopen(‘./flag’); # 打开flag文件,得到fd…...
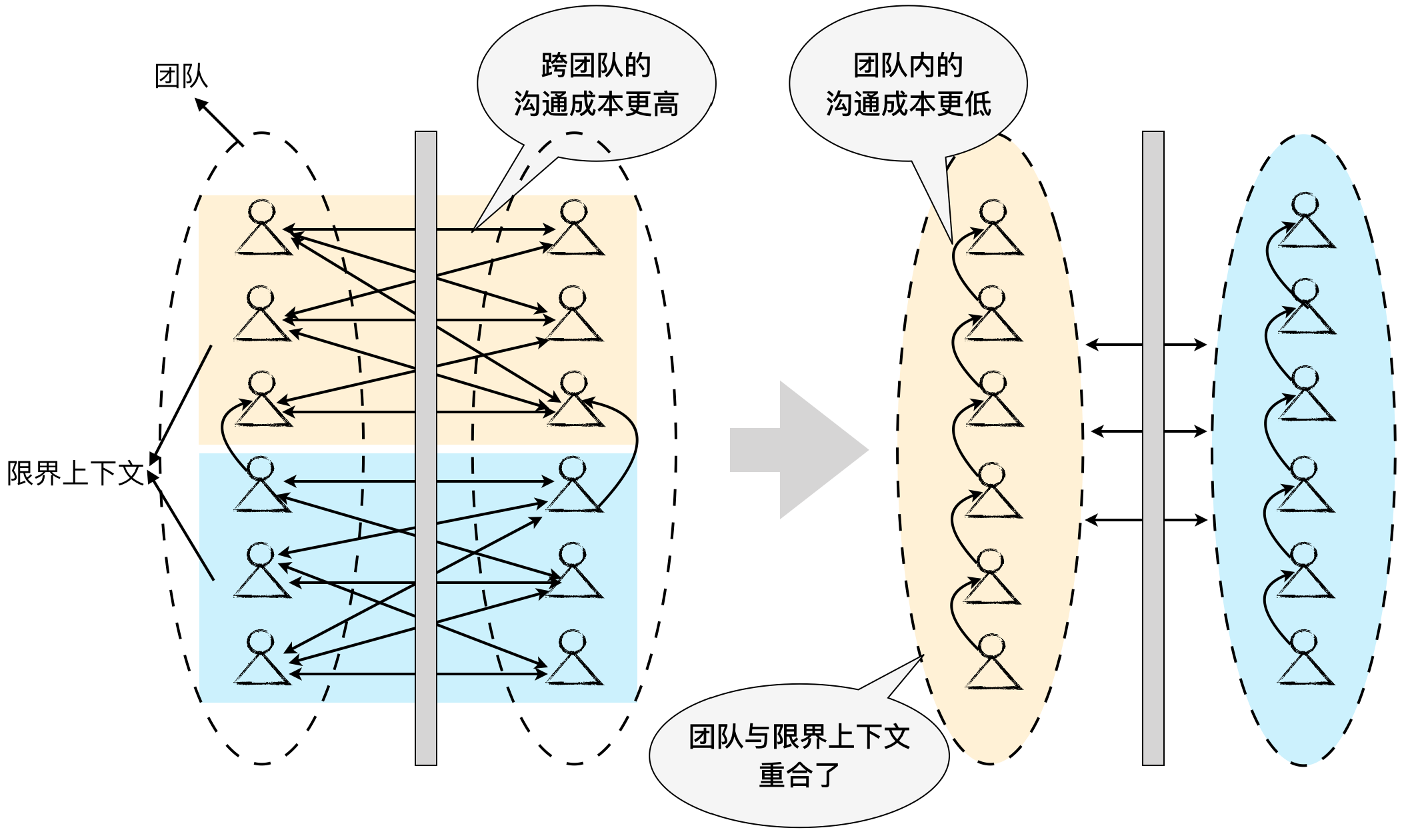
【DDD】学习笔记-限界上下文的控制力
引入限界上下文的目的,不在于如何划分,而在于如何控制边界。因此,我们就需要将对限界上下文的关注转移到对控制边界的理解。显然,对应于统一语言,限界上下文是语言的边界,对于领域模型,限界上下…...

springboot(ssm医院疫情防控系统 疫苗核酸预约系统Java系统
springboot(ssm医院疫情防控系统 疫苗核酸预约系统Java系统 开发语言:Java 框架:springboot(可改ssm) vue JDK版本:JDK1.8(或11) 服务器:tomcat 数据库:mysql 5.7&a…...

go语言中的Mutex
Golang以其并发性Goroutines而闻名。不仅是并发,还有更多。 因此,在这种情况下,我们必须确保多个goroutines不应该同时试图修改资源,从而导致冲突。 为了确保资源一次只能被一个goroutine访问,我们可以使用一个叫做syn…...

Vue的状态管理Vuex
文章目录 一、介绍二、install三、store1、介绍2、创建并全局引入3、单一状态树4、多模块状态树(无命名空间)5、多模块状态树(有命名空间) 本人最近在找工作,有推荐的小伙伴私我,不胜感激。 一、介绍 Vue…...
单片机14-17
目录 LCD1602 LCD1602液晶显示屏 直流电机驱动(PWM) LED呼吸灯 直流电机调速 AD/DA(SPI通信) AD模数转换 DA数模转换 红外遥控(外部中断) 红外遥控 红外遥控电机调速 LCD1602 LCD1602液晶显示屏 …...
)
DAY_12(树链剖分)
中途摆烂了几天加上考试比赛啥的,导致目前写博客断了。。差了好几天的题目没学了qwq,现在还是按照每天学的东西来写博客吧 今天主要学了树链剖分,怎么说呢,虽然随便拿出今天写的一道题目来看,码量都是一两百行的&…...
 | Column,Row - 线性布局)
Compose | UI组件(九) | Column,Row - 线性布局
文章目录 前言Column 的含义Column 的使用给 Column 加边框Column 使用 verticalArrangement 定位子项位置Column 使用 horizontalAlignment 定位子组件位置Column 设置了大小,可使用Modifier.align修饰符设置子组件对齐方式 Row 的含义Row 的使用 总结 前言 传统的…...
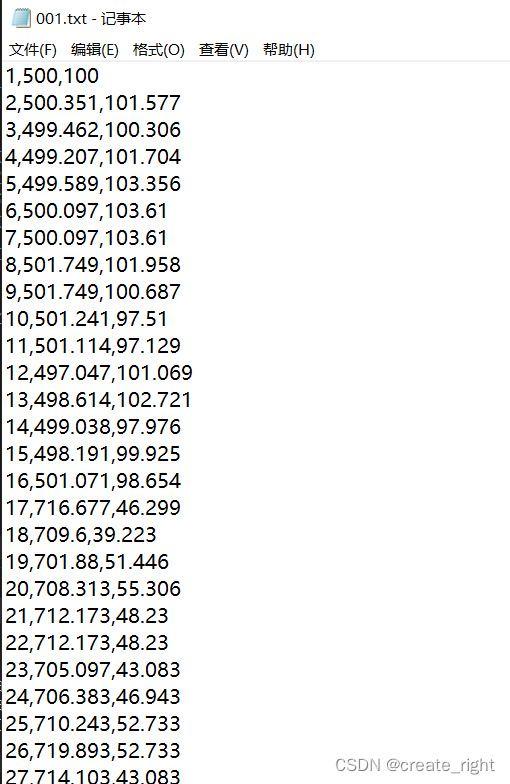
QT+VS实现Kmeans++
1、Kmeans的原理如下: (1)首先选取样本中任一数据点作为第一个聚类中心; (2)计算样本每一个数据点至现所有聚类中心的最近距离,并记录下来; (3)逐一挑选所…...

上位机图像处理和嵌入式模块部署(算法库的编写)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 作为图像处理的engineer来说,有时候我们需要提供上位机软件,有时候需要提供下位机程序,还有一种情况࿰…...

LeetCode1504. Count Submatrices With All Ones
文章目录 一、题目二、题解 一、题目 Given an m x n binary matrix mat, return the number of submatrices that have all ones. Example 1: Input: mat [[1,0,1],[1,1,0],[1,1,0]] Output: 13 Explanation: There are 6 rectangles of side 1x1. There are 2 rectangles…...
信息系统项目管理(第四版)(高级项目管理)考试重点整理第8章 项目整合管理(九))
(每日持续更新)信息系统项目管理(第四版)(高级项目管理)考试重点整理第8章 项目整合管理(九)
博主2023年11月通过了信息系统项目管理的考试,考试过程中发现考试的内容全部是教材中的内容,非常符合我学习的思路,因此博主想通过该平台把自己学习过程中的经验和教材博主认为重要的知识点分享给大家,希望更多的人能够通过考试&a…...

帕金森早期诊断准确率提高至 90.2%,深圳先进院联合中山一院提出 GSP-GCNs 模型
中山大学附属第一医院&中科大先进院等研究团队,提出了一种深度学习模型——图信号处理-图卷积网络 (GSP-GCNs),利用从涉及声调调节的特定任务中获得的事件相关脑电图数据来诊断帕金森病。 震颤、动作迟缓、表情僵硬……提起帕金森病,多数…...
java servlet果蔬产业监管系统Myeclipse开发mysql数据库web结构java编程计算机网页项目
一、源码特点 java Web果蔬产业监管系统是一套完善的java web信息管理系统 serlvetdaobean mvc 模式开发 ,对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主 要采用B/S模式开发。开发环境为TOMCAT7.0,Myeclipse8.5…...
Flask 入门
1. 关于 Flask Flask诞生于2010年, Armin Ronacher的一个愚人节玩笑。不过现在已经是一个用python语言基于Werkzeug工具箱编写的轻量级web开发框架,它主要面向需求简单,项目周期短的小应用。 Flask本身相当于一个内核,其他几乎所…...

微信小程序Skyline在手机端不渲染的问题之一及其解决方式
问题:电脑端是skyline渲染,手机端是webview渲染?如何解? 开发者工具 当前渲染模式:Skyline 当进行预览时手机端却是: 请注意看轮播图的显示情况 请注意看轮播图的显示情况 请注意看轮播图的显示情况 从轮播图上来看,手机端是webview渲染…...

怎样做好Code Review
Code Review方案 定义 Code Review代码评审是指在软件开发过程中,通过对源代码进行系统性检查的过程。通常的目的是查找各种缺陷,包括代码缺陷、功能实现问题、编码合理性、性能优化等;保证软件总体质量和提高开发者自身水平 code review …...

臻于至善,CodeArts Snap 二维绘图来一套不?
前言 我在体验 华为云的 CodeArts Snap 时,第一个例子就是绘制三角函数图像,功能注释写的也很简单。 业务场景中,有一类就是需要产出各种二维图形的,比如,折线图、散点图、柱状图等。 为了提前积累业务素材…...

从入门到上岗,Java+AI 复合型人才养成攻略
当下编程行业格局正在悄然改变,纯 Java 后端岗位内卷日趋严重,薪资增长逐步放缓;纯粹的 AI 算法岗门槛居高不下,对学历、数理功底要求严苛,普通开发者很难入局。 而Java+AI 复合型开发顺势成为行业刚需岗位,既依托成熟的 Java 体系承接业务开发,又能融入人工智能技术实…...

软阴影:那个让虚拟世界“温柔起来“的光影小秘密
一、从一只小猫的影子说起 前几天我在朋友家做客,他家养了一只胖乎乎的橘猫,正趴在阳台的窗边晒太阳。我无意间瞥了一眼那只猫脚边的影子,突然被一个细节震撼了—— 那只猫的影子——并不是一片均匀的黑。 仔细看——猫肚子紧贴地板的地方——…...

基于ATmega2560与ISD1700的智能语音时钟:硬件选型、软件架构与避坑指南
1. 项目概述与核心价值去年折腾那个用ATMega328驱动三块显示屏的时钟时,我主要精力都花在了如何在320x240的TFT屏幕上把时间、日期和图标画得又准又好看上。项目在《Elektor》杂志上发表后,一位热心的读者给我提了个新想法:能不能做个会“说话…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...

自制极低频电流探头:负电阻补偿原理与低频方波测量实践
1. 项目概述:为极低频电流测量而生在电子测试领域,电流探头是个再常见不过的工具,无论是排查开关电源的纹波,还是分析电机驱动的波形,都离不开它。但如果你尝试用市面上常见的电流探头去观察一个频率低至几赫兹&#x…...
)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)在游戏开发中,我们经常会遇到这样的场景:玩家拾取金币后,需要更新UI、播放音效、解锁成就、保存数据……如果把这些逻辑全部写在金币拾取的代…...

INT8量化下TVA注意力对齐精度保障方案
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

【DeepSeek灰度发布黄金法则】:20年SRE亲授7步零故障上线实战框架
更多请点击: https://intelliparadigm.com 第一章:DeepSeek灰度发布策略全景图 DeepSeek模型服务的灰度发布并非简单的流量切分,而是一套融合可观测性、渐进式验证与多维熔断机制的工程化闭环体系。其核心目标是在保障线上推理稳定性的同时&…...

工业云脑:06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例
06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例 今天第九篇06小节——现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例。新手照着做10分钟就能跑起来,老手一看就知道这玩意儿省了多少钱。以前想上AI检测,得花几万块买专业边缘盒子;现在?树莓派5(RPi 5)…...

鸿蒙HarmonyOS 5与Unity跨运行时通信实战指南
1. 这不是“调个API”那么简单:为什么鸿蒙Unity通信总在临门一脚卡住我第一次把Unity打包的AR模块塞进HarmonyOS 5 App里时,信心满满——毕竟文档里写着“支持JS/ArkTS调用Native能力”,Unity也标榜“跨平台通用”。结果呢?App一启…...