postgresql慢查询排查和复现
postgresql慢查询排查和复现
一. 介绍一张表:pg_stat_activity
pg_stat_activity 是 PostgreSQL 中一个非常有用的系统视图,提供了有关当前数据库连接和活动查询的信息。通过查询这个视图,你可以获取有关正在执行的查询、连接的用户、进程 ID 等信息。以下是 pg_stat_activity 视图中的一些关键列:
datid: 数据库标识符,表示正在连接的数据库的唯一标识符。datname: 数据库名称。pid: 进程 ID,表示数据库连接的唯一标识符。usesysid: 连接用户的系统标识符。usename: 连接用户名。application_name: 连接的应用程序名称(如果应用程序设置了名称)。client_addr: 客户端的 IP 地址。client_hostname: 客户端的主机名。client_port: 客户端连接使用的端口。backend_start: 连接开始时的时间戳。xact_start: 事务开始时的时间戳。query_start: 查询开始执行的时间戳。state: 连接状态(例如,idle、active、idle in transaction 等)。active: 表示当前连接正在执行查询或事务。idle: 表示当前连接处于空闲状态,没有正在执行的查询或事务。idle in transaction: 表示当前连接处于事务中,但没有正在执行的查询。可能是事务开始后一段时间没有活动。idle in transaction (aborted): 表示当前连接处于事务中,但由于某种原因事务已被中止。fastpath function call: 表示当前连接正在执行一个快速路径函数调用。disabled: 表示当前连接的活动状态已被禁用。
query: 当前正在执行的查询文本。waiting: 是否在等待锁。
用 pg_stat_activity 视图,可以监视当前数据库连接的活动状态,了解哪些查询正在执行及运行时间等信息。
二. 复现慢查询
在查询中引入延迟,pg_sleep() 是 PostgreSQL 中的一个函数,用于在查询中引入延迟。这个函数会使查询进程休眠指定的秒数。如果不提供参数,默认为 0 秒。切记不要再生产环境使用.
SELECT pg_sleep(100); -- 这将使查询休眠100秒钟
三. 排查慢查询语句
总的来说,这个查询可以识别数据库中运行时间较长的查询(下面是排查超过30秒的sql,可根据实际需要修改)。
SELECT pid, datname, usename, query, extract(epoch from (now() - query_start)) as total_time, count(1) AS slowsql_count FROM pg_stat_activity where state not in('idle') and query !='' and extract(epoch from (now() - query_start)) > 30 GROUP BY pid, datname, usename, query, total_time;
SELECT pid, datname, usename, query, extract(epoch from (now() - query_start)) as total_time, count(1) AS slowsql_countpid: 进程ID,表示数据库连接的唯一标识符。datname: 数据库名称。usename: 执行查询的用户名称。query: 正在执行的查询文本。extract(epoch from (now() - query_start)) as total_time: 通过计算当前时间与查询开始时间的差值,获取查询已运行的总时间(以秒为单位)。count(1) AS slowsql_count: 用于计算相同查询的数量,即慢查询的数量。
FROM pg_stat_activity- 从 PostgreSQL 的
pg_stat_activity视图中选择活跃的数据库连接信息。这个视图包含了关于当前数据库会话和查询的统计信息。
- 从 PostgreSQL 的
WHERE state NOT IN ('idle') AND query != '' AND extract(epoch from (now() - query_start)) > 10state NOT IN ('idle'): 确保排除处于空闲状态的数据库连接,只选择活跃的连接。query != '': 排除空查询,确保只选择正在执行的查询。extract(epoch from (now() - query_start)) > 30: 选择运行时间超过30秒的查询。
GROUP BY pid, datname, usename, query, total_time- 对选择的结果进行分组,以便聚合相同查询的统计信息。
查询结果:成功定位到慢查询语句:SELECT pg_sleep(100);

四. 慢查询优化方案
- 查询优化:
- 通过使用
EXPLAIN分析查询计划,了解 PostgreSQL 是如何执行查询的。优化查询计划可以提高查询性能。 - 调整查询,避免不必要的全表扫描,确保正确使用索引。
- 通过使用
- 索引优化:
- 确保表上的索引是合理的,并涵盖了查询中用于筛选和排序的列。
- 避免过多的索引,因为它们可能会导致性能下降。
- 统计信息更新:
- 确保 PostgreSQL 统计信息是最新的。自动化统计信息更新可以通过 PostgreSQL 的自动统计信息收集器来完成。
- 分区表:
- 对大型表进行分区,可以提高查询性能,尤其是对那些经常使用范围查询的表。
- 调整内存配置:
- 调整
shared_buffers和effective_cache_size参数,以确保数据库能够充分利用系统内存。
- 调整
- 定期维护:
- 定期执行
VACUUM和ANALYZE操作,以确保表的空间得到优化,同时更新统计信息。
- 定期执行
- 使用连接池:
- 考虑使用连接池,例如 PgBouncer,以减轻数据库服务器的负载。
- 日志和监控:
- 启用 PostgreSQL 的查询日志,并使用工具如 pgBadger 分析日志,以便及时发现慢查询。
- 使用监控工具,如 pg_stat_statements 扩展,监视查询性能。
- 升级 PostgreSQL 版本:
- 考虑升级到最新的 PostgreSQL 版本,因为新版本通常包含性能改进和优化。
- 使用扩展:
- 考虑使用一些性能优化的扩展,例如
pg_repack用于表重组,pg_partman用于表分区等。
- 考虑使用一些性能优化的扩展,例如
常包含性能改进和优化。
10. 使用扩展:
- 考虑使用一些性能优化的扩展,例如 pg_repack 用于表重组,pg_partman 用于表分区等。
相关文章:
postgresql慢查询排查和复现
postgresql慢查询排查和复现 一. 介绍一张表:pg_stat_activity pg_stat_activity 是 PostgreSQL 中一个非常有用的系统视图,提供了有关当前数据库连接和活动查询的信息。通过查询这个视图,你可以获取有关正在执行的查询、连接的用户、进程 …...

【服务器】搭建ChatGPT站点常见问题
目录 ❓ 常见问题 🌼1. 什么是OpenAI APIkey? 🌼2. 什么是Token? 🌼3. 为什么回复不是GPT-4? 🌼4. 如何区分 GPT-3.5 和 GPT-4 🌼5. 为什么回复到一半卡住? 🌼6.…...

QT+opengl 创建一个六边形
一.关键名词解释 VAO: Vertex Array Object, 顶点数组对象,你要绘制的图形。 VBO:Vertex Buffer Object, 顶点缓冲对象,所有顶点的集合。 EBO:Element Buffer Object, 元素缓冲对象,顶点的索引值。 IBO: Index Buffer Object, 索引缓冲对象。…...
 引发的卡顿问题)
Android imageView.setImageXXX() 引发的卡顿问题
在 Android 开发中,ImageView 是一个用户界面控件,用于在应用中显示图片。它是 Android UI 组件库中一个非常基础和常用的部分。使用 ImageView,你可以在屏幕上显示来自不同来源的图像,比如位图文件、绘图资源 drawable、网络来源…...

MavenGradle等引入jSerialComm
引入 jSerialComm [2.0.0,3.0.0) 此版本发布于 Nov 7, 2023 (23年11月) Maven: <dependency><groupId>com.fazecast</groupId><artifactId>jSerialComm</artifactId><version>[2.0.0,3.0.0)</version> </dependency>Ivy: …...

热门技术问答 | 请 GaussDB 用户查收
近年来,Navicat 与华为云 GaussDB 展开一系列技术合作,为 GaussDB 用户提供面向管理开发工具的生态工具。Navicat 现已完成 GaussDB 主备版(单节点、多节点)和分布式数据库的多项技术对接。Navicat 通过工具的流畅性和实用性&…...
【C/C++ 01】初级排序算法
排序算法通常是针对数组或链表进行排序,在C语言中,需要手写排序算法完成对数据的排序,排序规则通常为升序或降序(本文默认为升序),在C中,<algorithm>头文件中已经封装了基于快排算法的 st…...

Android Settings 显示电池点亮百分比
如题,Android 原生 Settings 里有个 电池电量百分比 的选项,打开后电池电量百分比会显示在状态栏。 基于 Android 13 , 代码在 ./packages/apps/Settings/src/com/android/settings/display/BatteryPercentagePreferenceController.java &am…...
Windows记事本不显示下划线的原因及解决方法
最近使用Windows 记事本敲代码发现一个问题:代码中的下划线无法显示!!!(字体为“微软雅黑”、字体大小为11下,代码中的下划线无法显示。当然每个人情况可能不同) 在 Windows 记事本中,下划线可能会因为 字体…...
(四十六))
嵌入式软件工程师面试题——2025校招社招通用(C/C++)(四十六)
说明: 面试群,群号: 228447240面试题来源于网络书籍,公司题目以及博主原创或修改(题目大部分来源于各种公司);文中很多题目,或许大家直接编译器写完,1分钟就出结果了。但…...
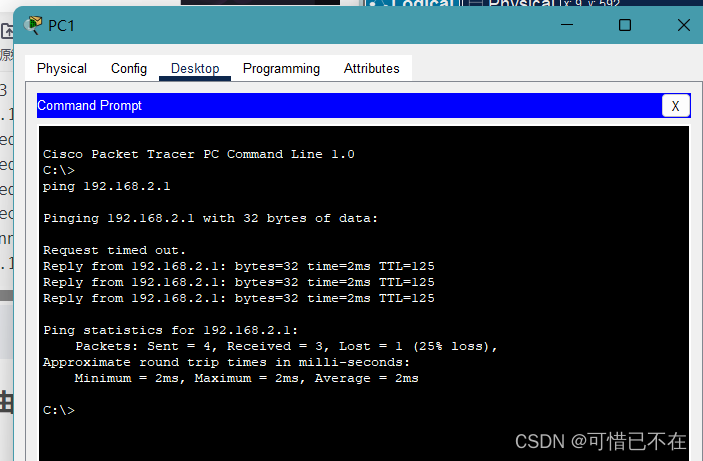
【学网攻】 第(13)节 -- 动态路由(OSPF)
系列文章目录 目录 系列文章目录 文章目录 前言 一、动态路由是什么? 二、实验 1.引入 实验拓扑图 实验配置 实验验证 总结 文章目录 【学网攻】 第(1)节 -- 认识网络【学网攻】 第(2)节 -- 交换机认识及使用【学网攻】 第(3)节 -- 交换机配置聚合端口【学…...

Asp.Net Core 获取应用程序相关目录
在ASP.NET Core中,可以通过以下三种方式获取应用程序所在目录: 1、使用AppContext.BaseDirectory属性: string appDirectory AppContext.BaseDirectory; 例如:D:\后端项目\testCore\test.WebApi\bin\Debug\net6.0\ 2、使用…...
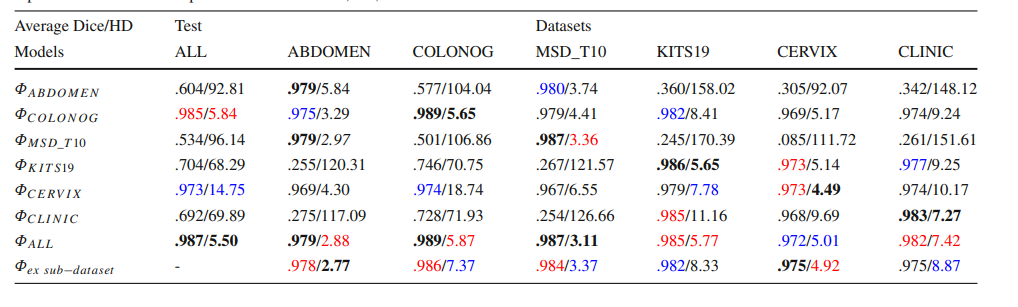
文献速递:人工智能医学影像分割--- 深度学习分割骨盆骨骼:大规模CT数据集和基线模型
文献速递:人工智能医学影像分割— 深度学习分割骨盆骨骼:大规模CT数据集和基线模型 我们为大家带来人工智能技术在医学影像分割上的应用文献。 人工智能在医学影像分析中发挥着至关重要的作用,尤其体现在图像分割技术上。这项技术的目的是准…...
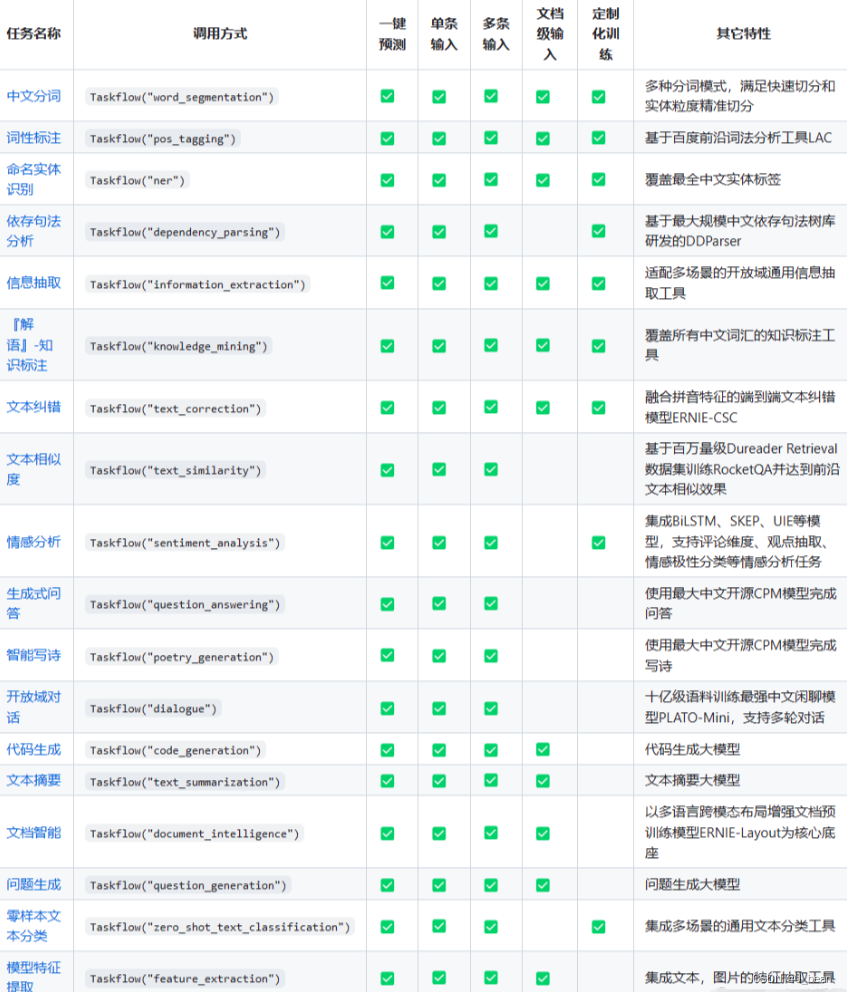
PaddleNLP的简单使用
1 介绍 PaddleNLP是一个基于PaddlePaddle深度学习平台的自然语言处理(NLP)工具库。 它提供了一系列用于文本处理、文本分类、情感分析、文本生成等任务的预训练模型、模型组件和工具函数。 PaddleNLP有统一的应用范式:通过 paddlenlp.Task…...
2. MySQL 多实例
重点: MySQL 的 三种安装方式:包安装,二进制安装,源码编译安装。 MySQL 的 基本使用 MySQL 多实例 DDLcreate alter drop DML insert update delete DQL select 2.5)通用 二进制格式安装 MySQL 2.5.1ÿ…...

两个五层决策树和一个十层决策树的区别
随机森林的弹性: 随机森林中的多个决策树是相互独立构建的,因此两个五层决策树和一个十层决策树之间的区别可能在于它们对训练数据的不同学习。这种弹性有助于模型更好地适应不同的数据模式。 过拟合风险: 十层决策树可能更容易过拟合训练数据,尤其是在数…...
案例分析技巧-软件工程
一、考试情况 需求分析(※※※※)面向对象设计(※※) 二、结构化需求分析 数据流图 数据流图的平衡原则 数据流图的答题技巧 利用数据平衡原则,比如顶层图的输入输出应与0层图一致补充实体 人物角色:客户、…...
如何使用docker compose安装APITable并远程访问登录界面
文章目录 前言1. 部署APITable2. cpolar的安装和注册3. 配置APITable公网访问地址4. 固定APITable公网地址 正文开始前给大家推荐个网站,前些天发现了一个巨牛的 人工智能学习网站, 通俗易懂,风趣幽默,忍不住分享一下给大家。 …...

深入了解Matplotlib中的子图创建方法
深入了解Matplotlib中的子图创建方法 一 add_axes( **kwargs):1.1 函数介绍1.2 示例一 创建第一张子图1.2 示例二 polar参数的运用1.3 示例三 创建多张子图 二 add_subplot(*args, **kwargs):2.1 函数介绍2.2 示例一 三 两种方法的区别3.1 参数形式3.2 布局灵活性3.3 适用场景3…...

云计算运维 · 第三阶段 · git
学习b记 第三阶段 三、持续集成 1、git #安装 yum -y install git[rootgit-git ~]# git config –-global user.name "qxl" # 配置git使用用户 [rootgit-git ~]# git config –-global user.email "qxlmail.com" # 配置git使用邮箱 [rootgit-git ~]# g…...

Hitboxer:开源SOCD清理工具,3分钟提升游戏操作精准度
Hitboxer:开源SOCD清理工具,3分钟提升游戏操作精准度 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否在激烈的游戏对抗中经历过这样的挫败:同时按下左右方向键时角色卡…...
)
手把手教你为WCH CH582移植CherryUSB主机栈(基于RT-Thread,含中断优化)
基于RT-Thread的WCH CH582 USB主机协议栈深度移植指南在嵌入式开发领域,USB主机功能的实现往往意味着设备能够直接连接各类USB外设,从简单的键盘鼠标到复杂的存储设备。对于使用WCH CH582这类RISC-V内核MCU的开发者而言,原厂SDK提供的USB主机…...

从多路复用到三维光阵:Arduino驱动8x8x8 LED立方体全解析
1. 项目概述:用Arduino点亮一个三维世界几年前,我第一次在创客展上看到一个8x8x8的LED立方体,那种由数百个光点构成的、在三维空间中流动的动画效果,瞬间就把我吸引住了。它不像普通的平面LED屏,而是真正有“深度”的光…...
)
Sora 2原生接入Unity 6.0:5步完成神经渲染管线嵌入,实测帧率提升47%(附GitHub认证插件)
更多请点击: https://kaifayun.com 第一章:Sora 2与Unity整合 Sora 2作为新一代AI视频生成引擎,其开放API设计天然支持与实时3D引擎的深度协同。Unity 2023.2版本通过URP(Universal Render Pipeline)与C# Job System提…...

2026年一键生成论文工具对比实测:5款神器从选题到格式全流程护航
写论文的焦虑,是每个科研人和学生都心照不宣的“隐形压力”。选题无从下手,文献检索耗时费力,逻辑框架反复推翻,格式排版让人抓狂,查重降重更是像在和系统玩“猫鼠游戏”。2026年的AI工具早已不是过去那种“打字机”&a…...

随机森林算法在儿童出行方式预测中的实战应用与优化
1. 项目概述:用随机森林预测孩子怎么上学做城市交通规划或者做家长接送方案的时候,你肯定想过一个问题:孩子们到底是怎么上学的?是走路、骑车、坐公交还是家长开车送?这个问题看似简单,背后却牵扯到城市规划…...

2026 文章代码高亮方案选型
将基于 Prism.js 或 Highlight.js 的传统高亮方案与基于 Shiki 的现代化高亮方案进行对比,其核心区别在于底层解析原理的不同(正则表达式 vs. TextMate 语法树)。 以下是两种方案的底层原理、各自优缺点、核心对比矩阵以及适用场景的详细分析…...

LangGraph状态机工程:构建复杂AI工作流的完整指南
传统RAG(检索增强生成)在处理简单的"单跳"问题时表现良好——“文章里提到了什么” “这个概念是什么意思”——但当问题涉及多个实体之间的关系、需要跨多个文档推理时,传统RAG就显得力不从心。GraphRAG(Graph-based R…...
)
实战对比:用直方图均衡化与CLAHE拯救你的背光/过曝照片(附Python完整代码)
拯救逆光废片:直方图均衡化与CLAHE的实战效果对比每次旅行回来整理照片时,总会有几张因为光线问题几乎要删除的废片——要么是逆光下的人脸黑得看不清五官,要么是天空过曝失去所有云层细节。这些照片往往记录着重要时刻,直接删除实…...

终极免费音乐解锁工具:打破平台枷锁,让音乐重获自由
终极免费音乐解锁工具:打破平台枷锁,让音乐重获自由 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...