PyTorch的nn.Module类的详细介绍
在PyTorch中,nn.Module 类是构建神经网络模型的基础类,所有自定义的层、模块或整个神经网络架构都需要继承自这个类。nn.Module 类提供了一系列属性和方法用于管理网络的结构和训练过程中的计算。

1. PyTorch中nn.Module基类的定义
在PyTorch中,nn.Module 是所有神经网络模块的基础类。尽管这里不能提供完整的源代码(因为它涉及大量内部逻辑和API细节),但我可以给出一个简化的 nn.Module 类的基本结构,并描述其关键方法:
Python
1# 此处简化了 nn.Module 的定义,实际 PyTorch 源码更为复杂
2import torch
3
4class nn.Module:
5 def __init__(self):
6 super().__init__()
7 # 存储子模块的字典
8 self._modules = dict()
9 # 参数和缓冲区的集合
10 self._parameters = OrderedDict()
11 self._buffers = OrderedDict()
12
13 def __setattr__(self, name, value):
14 # 特殊处理参数和子模块的设置
15 if isinstance(value, nn.Parameter):
16 # 注册参数到 _parameters 字典中
17 self.register_parameter(name, value)
18 elif isinstance(value, Module) and not isinstance(value, Container):
19 # 注册子模块到 _modules 字典中
20 self.add_module(name, value)
21 else:
22 # 对于普通属性,执行标准的 setattr 操作
23 object.__setattr__(self, name, value)
24
25 def add_module(self, name: str, module: 'Module') -> None:
26 r"""添加子模块到当前模块"""
27 # 内部实现细节省略...
28 self._modules[name] = module
29
30 def register_parameter(self, name: str, param: nn.Parameter) -> None:
31 r"""注册一个新的参数"""
32 # 内部实现细节省略...
33 self._parameters[name] = param
34
35 def parameters(self, recurse: bool = True) -> Iterator[nn.Parameter]:
36 r"""返回一个包含所有可学习参数的迭代器"""
37 # 内部实现细节省略...
38 return iter(getattr(self, '_parameters', {}).values())
39
40 def forward(self, *input: Tensor) -> Tensor:
41 r"""定义前向传播操作"""
42 raise NotImplementedError
43
44 # 还有许多其他的方法如:zero_grad、to、state_dict、load_state_dict 等等...
45
46# 在自定义模型时,继承 nn.Module 并重写 forward 方法
47class MyModel(nn.Module):
48 def __init__(self):
49 super(MyModel, self).__init__()
50 self.linear = nn.Linear(20, 30)
51
52 def forward(self, x):
53 return self.linear(x) 这段代码定义了 PyTorch 中 nn.Module 类的基础结构。在实际的 PyTorch 源码中,nn.Module 的实现更为复杂,但这里简化后的代码片段展示了其核心部分。
-
class nn.Module::定义了一个名为nn.Module的类,它是所有神经网络模块(如卷积层、全连接层、激活函数等)的基类。 -
def __init__(self)::这是类的初始化方法,在创建一个nn.Module或其子类实例时会被自动调用。这里的self参数代表将来创建出的实例自身。-
super().__init__():调用父类的构造函数,确保基类的初始化逻辑得到执行。在这里,虽然没有显示指定父类,但因为nn.Module是其他所有模块的基类,所以实际上它是在调用自身的构造函数来初始化内部状态。 -
self._modules = dict():声明并初始化一个字典_modules,用于存储模型中的所有子模块。每个子模块是一个同样继承自nn.Module的对象,并通过名称进行索引。这样可以方便地管理和组织复杂的层次化网络结构。 -
self._parameters = OrderedDict():使用有序字典(OrderedDict)类型声明和初始化一个变量_parameters,用来保存模型的所有可学习参数(权重和偏置等)。有序字典保证参数按添加顺序存储,这对于一些依赖参数顺序的操作(如加载预训练模型的权重)是必要的。 -
self._buffers = OrderedDict():类似地,声明并初始化另一个有序字典_buffers,用于存储模型中的缓冲区(Buffer)。缓冲区通常是不参与梯度计算的变量,比如在 BatchNorm 层中存储的均值和方差统计量。
-
总结来说,这段代码为构建神经网络模型提供了一个基础框架,其中包含了对子模块、参数和缓冲区的管理机制,这些基础设施对于构建、运行和优化深度学习模型至关重要。在自定义模块时,开发者通常会在此基础上添加更多的层和功能,并重写 forward 方法以定义前向传播逻辑。
以上代码仅展示了 nn.Module 类的部分核心功能,实际上 PyTorch 官方的实现会更加详尽和复杂,包括更多的内部机制来支持模块化构建深度学习模型。开发者通常需要继承 nn.Module 类并重写 forward 方法来实现自定义的神经网络层或整个网络架构。
2. nn.Module类中的关键属性和方法
在PyTorch的nn.Module类中,有以下几个关键属性和方法:
-
__init__(self, ...): 这是每个派生自nn.Module的类都必须重载的方法,在该方法中定义并初始化模型的所有层和参数。 -
._parameters和._buffers:这是内部字典属性,分别储存了模型的所有参数和缓冲区,虽然不推荐直接操作,但在自定义模块时可能需要用到。 -
.parameters():这是一个动态生成器,用于获取模型的所有可学习参数(权重和偏置等)。这些参数都是nn.Parameter类型的张量,在训练过程中可以自动计算梯度。示例:
Python1for param in model.parameters(): 2 print(param) -
.buffers():类似于.parameters(),但返回的是模块内定义的非可学习缓冲区变量,例如一些统计量或临时存储数据。 -
.named_parameters()和.named_buffers():与上面类似,但返回元组形式的迭代器,每个元素是一个包含名称和对应参数/缓冲区的元组,便于按名称访问特定参数。 -
.children()和.modules():这两个方法分别返回一个包含当前模块所有直接子模块的迭代器和包含所有层级子模块(包括自身)的迭代器。 -
.state_dict():该方法返回一个字典,包含了模型的所有状态信息(即参数和缓冲区),方便保存和恢复模型。 -
state_dict()和load_state_dict(state_dict):用于保存和加载模型的状态字典,其中包括模型的权重和配置信息,便于模型持久化和迁移。 -
.train()和.eval():方法用于切换模型的运行模式。在训练模式下,某些层如批次归一化层会有不同的行为;而在评估模式下,通常会禁用dropout层并使用移动平均统计量(对于批归一化层)。 -
train(mode=True)和eval():切换模型的工作模式,在训练模式下会启用批次归一化层和丢弃层等依赖于训练/预测阶段的行为,在评估模式下则关闭这些行为。 -
.to(device):将整个模型及其参数转移到指定设备上,比如从CPU到GPU。 -
其他内部维护的属性,如
_forward_pre_hooks和_forward_hooks用于实现向前传播过程中的预处理和后处理钩子,以及_backward_hooks用于反向传播过程中的钩子,这些通常在高级功能开发时使用。 -
forward(self, input):定义模型如何处理输入数据并生成输出,这是构建神经网络的核心部分,每次调用模型实例都会执行forward函数。 -
add_module(name, module):将一个子模块添加到当前模块,并通过给定的名字引用它。 -
register_parameter(name, param):注册一个新的参数到模块中。 -
zero_grad():将模块及其所有子模块的参数梯度设置为零,通常在优化器更新前调用。 -
其他与模型保存和恢复相关的方法,例如
save(filename)、load(filename)等。
请注意,具体的属性和方法可能会随着PyTorch版本的更新而有所增减或改进。
3. nn.Module子类的定义和使用
在PyTorch中,nn.Module 类扮演着核心角色,它是构建任何自定义神经网络层、复杂模块或完整神经网络架构的基础构建块。通过继承 nn.Module 并在其子类中定义模型结构和前向传播逻辑(forward() 方法),开发者能够方便地搭建并训练深度学习模型。
具体来说,在自定义一个 nn.Module 子类时,通常会执行以下操作:
-
初始化 (
__init__):在类的初始化方法中定义并实例化所有需要的层、参数和其他组件。Python1class MyModel(nn.Module): 2 def __init__(self, input_size, hidden_size, output_size): 3 super(MyModel, self).__init__() 4 self.layer1 = nn.Linear(input_size, hidden_size) 5 self.layer2 = nn.Linear(hidden_size, output_size) -
前向传播 (
forward):实现前向传播函数来描述输入数据如何通过网络产生输出结果。Python1class MyModel(nn.Module): 2 # ... 3 def forward(self, x): 4 x = torch.relu(self.layer1(x)) 5 x = self.layer2(x) 6 return x -
管理参数和模块:
- 使用
.parameters()或.named_parameters()访问模型的所有可学习参数。 - 使用
add_module()添加子模块,并给它们命名以便于访问。 - 使用
register_buffer()为模型注册非可学习的缓冲区变量。
- 使用
-
训练与评估模式切换:
- 使用
model.train()将模型设置为训练模式,这会影响某些层的行为,如批量归一化层和丢弃层。 - 使用
model.eval()将模型设置为评估模式,此时会禁用这些依赖于训练阶段的行为。
- 使用
-
保存和加载模型状态:
- 调用
model.state_dict()获取模型权重和优化器状态的字典形式。 - 使用
torch.save()和torch.load()来保存和恢复整个模型或者仅其状态字典。 - 通过
model.load_state_dict(state_dict)加载先前保存的状态字典到模型中。
- 调用
此外,nn.Module 还提供了诸如移动模型至不同设备(CPU或GPU)、零化梯度等实用功能,这些功能在整个模型训练过程中起到重要作用。
相关文章:
PyTorch的nn.Module类的详细介绍
在PyTorch中,nn.Module 类是构建神经网络模型的基础类,所有自定义的层、模块或整个神经网络架构都需要继承自这个类。nn.Module 类提供了一系列属性和方法用于管理网络的结构和训练过程中的计算。 1. PyTorch中nn.Module基类的定义 在PyTorch中ÿ…...

python使用activemq库ActiveMQClient类的连接activemq并订阅、发送和接收消息
引入activemq模块:from activemq import ActiveMQClient from activemq import ActiveMQClient 是一个Python的导入语句,它从activemq模块中导入了ActiveMQClient类。 解释一下各个部分: from activemq: 这表示我们正在从一个名为activemq…...

【Flutter 面试题】Dart是什么?Dart和Flutter有什么关系?
【Flutter 面试题】Dart是什么?Dart和Flutter有什么关系? 文章目录 写在前面Dart是什么Dart和Flutter有什么关系? 写在前面 👏🏻 正在学 Flutter 的同学,你好! 😊 本专栏是解决 Fl…...

前后台分离跨域交互
后台处理跨域 安装插件 >: pip install django-cors-headers插件参考地址:https://github.com/ottoyiu/django-cors-headers/项目配置:dev.py # 注册app INSTALLED_APPS [...corsheaders, ]# 添加中间件 MIDDLEWARE [...corsheaders.middleware.…...
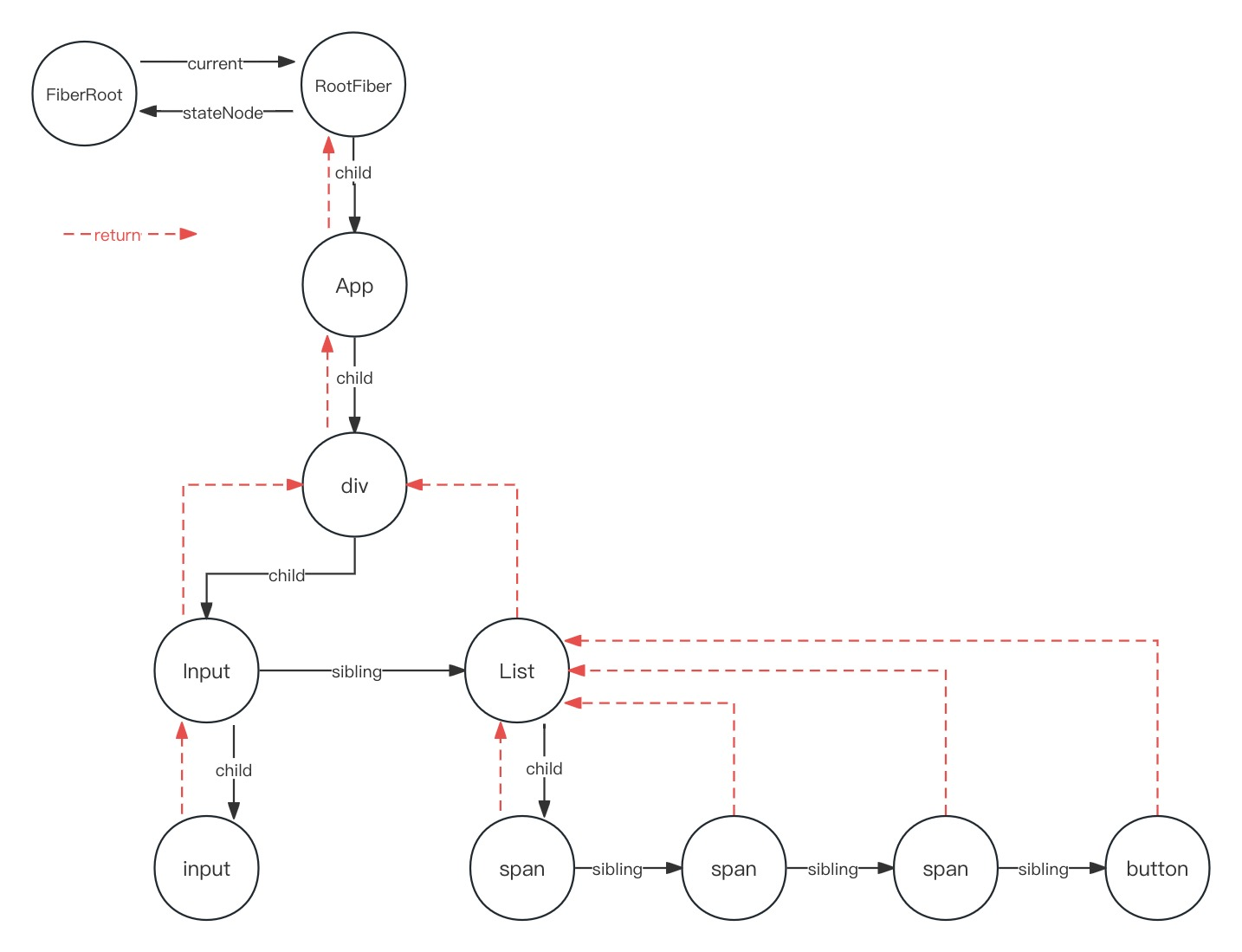
React16源码: React中处理LegacyContext相关的源码实现
LegacyContext 老的 contextAPI 也就是我们使用 childContextTypes 这种声明方式来从父节点为它的子树提供 context 内容的这么一种方式遗留的contextAPI 在 react 17 被彻底移除了,就无法使用了那么为什么要彻底移除这个contextAPI的使用方式呢?因为它…...
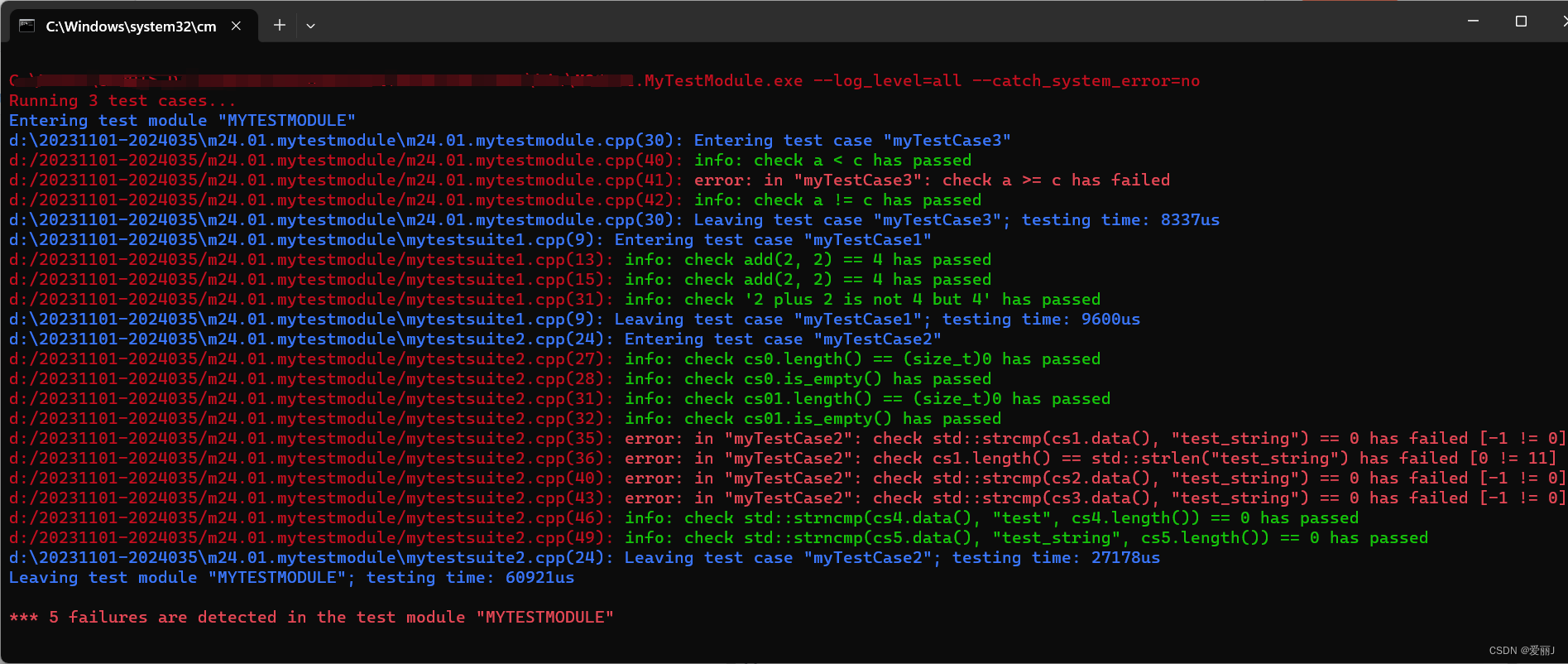
Boost.Test资源及示例
Note:boost_1_84_0的动态连接库资源链接 1.代码组织如下图: 2.包括程序入口的代码文件 示例: // M24.01.MyTestModule.cpp : 定义控制台应用程序的入口点。 //#include "stdafx.h" #define BOOST_TEST_MODULE MYTESTMODULE #def…...

数据结构二叉树
二叉树是数据结构中的一个基本概念,它是每个节点最多有两个子节点的树结构。在二叉树中,每个节点通常有两个指针,分别指向左子节点和右子节点。 数据结构定义 在二叉树的节点中,通常包含以下信息: 数据域࿱…...

JavaScript继承与原型链
继承和原型链是什么? 1.1 在继承中,子类继承父类的特征和行为,使得子类对象具有父类的实例域和方法。这意味着子类可以使用父类的方法和属性,使用继承的目的是为了更好设置实例的公共属性和方法,如下例子: …...

SouthLeetCode-打卡24年01月第4周
SouthLeetCode-打卡24年01月第4周 // Date : 2024/01/22 ~ 2024/01/28 022.设计链表 - 双链表 (1) 题目描述 022#LeetCode.707.#北岸计划2024/01/22 (2) 题解代码 import java.util.List;class ListNode {int val;ListNode prev;ListNode next;ListNode(){this.val 0;th…...

Linux——磁盘和文件系统(一)
Linux——磁盘和文件系统 磁盘机械式磁盘固态硬盘 机械式磁盘结构磁盘,磁道,扇区柱面 文件系统的初始化划卷(划盘) 挂载C盘放了什么东西Boot Block(启动模块) 0号组放了什么东西Super Block(超级…...
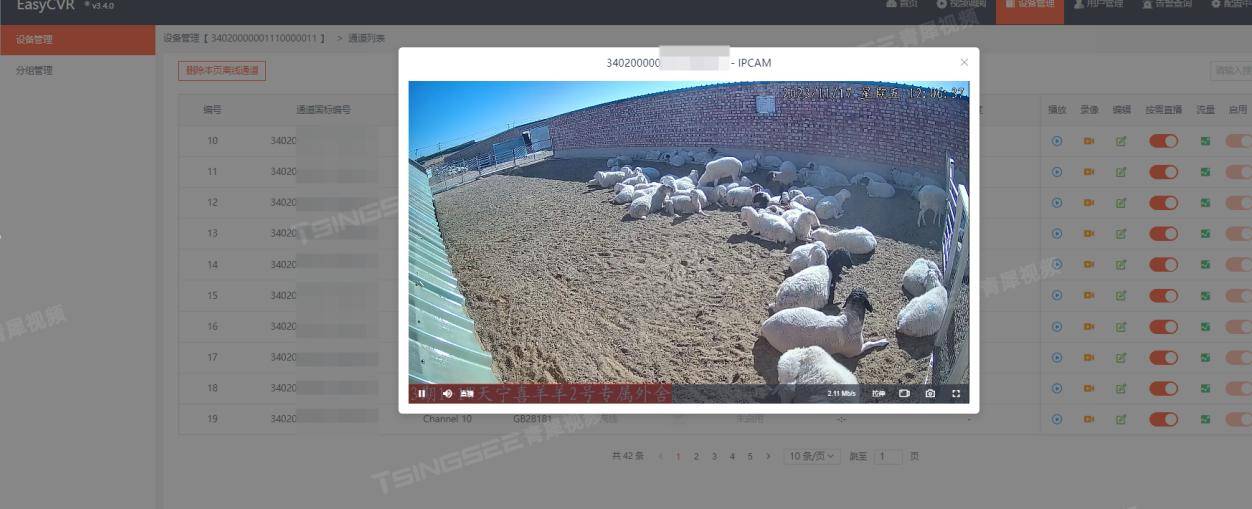
EasyCVR视频智能监管系统方案设计与应用
随着科技的发展,视频监控平台在各个领域的应用越来越广泛。然而,当前的视频监控平台仍存在一些问题,如视频质量不高、监控范围有限、智能化程度不够等。这些问题不仅影响了监控效果,也制约了视频监控平台的发展。 为了解决这些问…...

Ubuntu搭建国标平台wvp-GB28181-pro
目录 简介安装和编译1.查看操作系统信息2.安装最新版的nodejs3.安装java环境4.安装mysql5.安装redis6.安装编译器7.安装cmake8.安装依赖库9.编译ZLMediaKit9.1.编译结果说明 10.编译wvp-GB28181-pro10.1.编译结果说明 配置1.WVP-PRO配置文件1.1.Mysql数据库配置1.2.REDIS数据库…...

LC 2808. 使循环数组所有元素相等的最少秒数
2808. 使循环数组所有元素相等的最少秒数 难度: 中等 题目大意: 给你一个下标从 0 开始长度为 n 的数组 nums 。 每一秒,你可以对数组执行以下操作: 对于范围在 [0, n - 1] 内的每一个下标 i ,将 nums[i] 替换成 nums[i] &…...
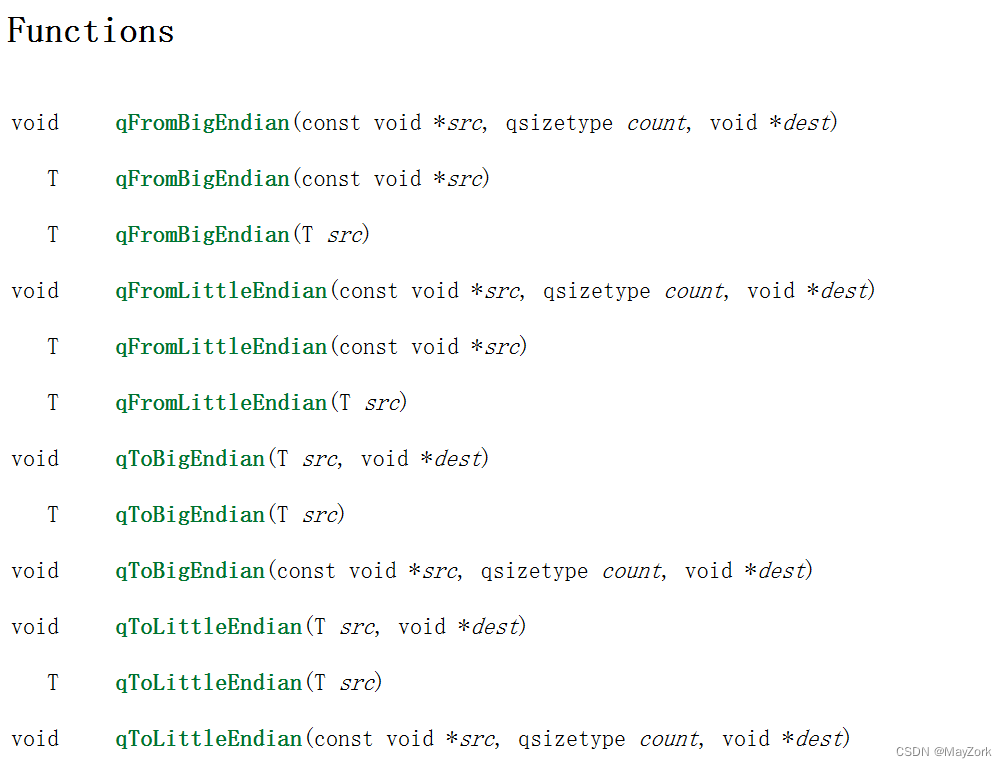
Qt|大小端数据转换
后面打算写Qt关于网络编程的博客,网络编程就绕不开字节流数据传输,字节流数据的传输一般是根据协议来定义对应的报文该如何组包,那这就必然牵扯到了大端字节序和小端字节序的问题了。不清楚的大小端的可以看一下相关资料:大小端模…...

禅道添加自定义字段
1,数据库表 zt_story 添加自定义字段 bakDate1,bakDate2,bakDate3,bakDate4 2,在 /opt/lampp/htdocs/zentaopms/extension/custom/story/ext/config 中添加bakDate.php文件 <?php $config->story->datatab…...

蓝桥杯2024/1/26笔记-----基于PCF8591的电压采集装置
功能实现要求: 每次建好工程文件夹,里边包含User(放工程文件,mian.c,可以在这里写如同我这个文章的文本文档)、Driver(存放底层文件如Led.c,Led.h等) 新建的工程先搭建框…...
【一】esp32芯片开发板环境搭建
1、esp32的源码在github上的地址 不同的芯片支持的源码版本不一样,需要根据自己的实际的esp32开发板的芯片下载不用版本的代码 esp32支持多种开发方式,如arduino,ESP-IDF等。官方推荐使用idf开发,ESP-IDF 是乐鑫官方推出的物联网开…...
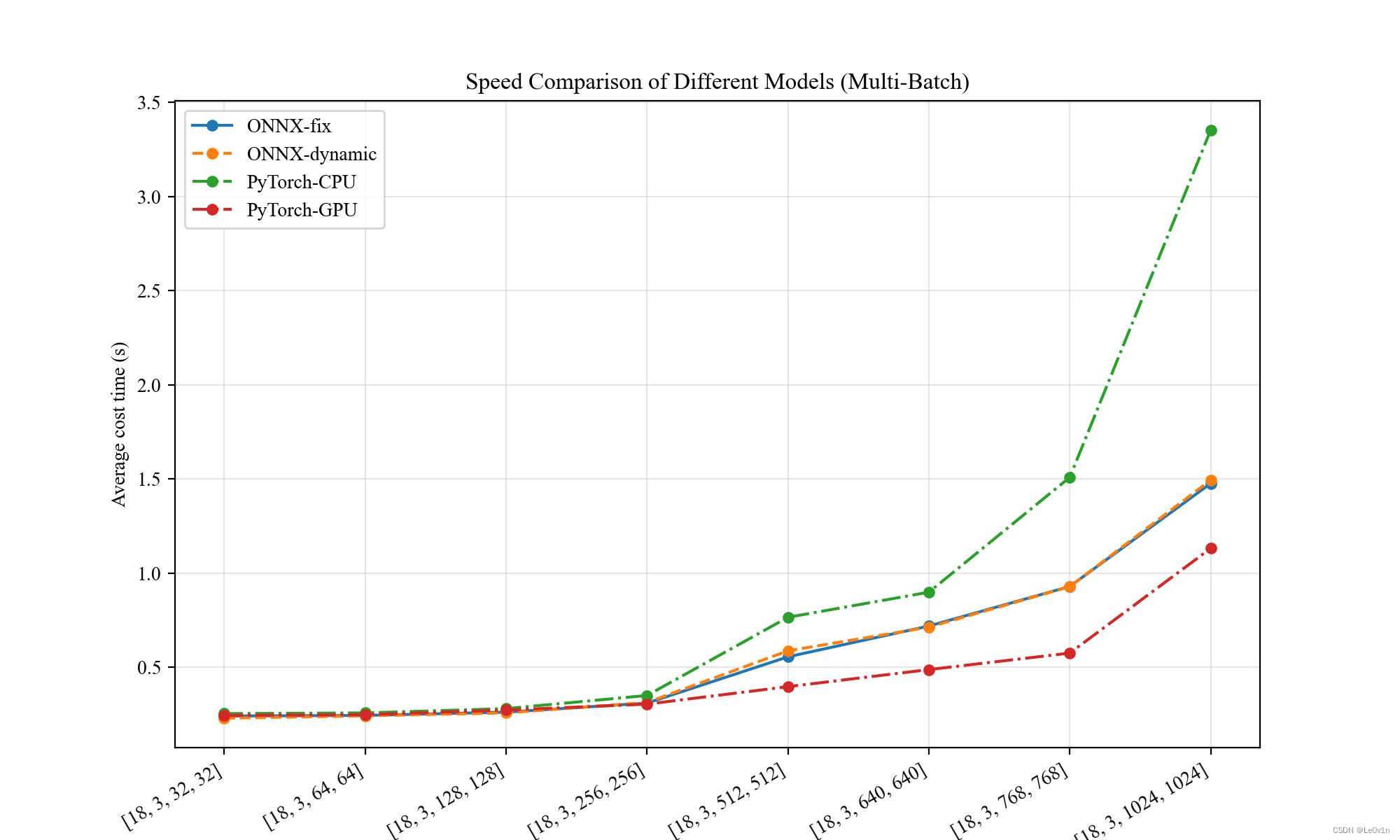
PyTorch2ONNX-分类模型:速度比较(固定维度、动态维度)、精度比较
图像分类模型部署: PyTorch -> ONNX 1. 模型部署介绍 1.1 人工智能开发部署全流程 #mermaid-svg-bAJun9u4XeSykIbg {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-bAJun9u4XeSykIbg .error-icon{fill:#552222;}…...

Docker命令快车道:一票通往高效开发之旅
欢迎登上 Docker 命令快车!在这趟旅程中,你不仅会学会如何驾驭 Docker 这辆神奇的车,还会发现如何让你的开发旅程变得更加轻松愉快。现在,请系好安全带,我们即将出发! Docker 是什么 Docker 就像是一辆超…...

IP类接口大全,含免费次数
IP查询 IP归属地-IPv4高精版:根据IP地址查询归属地信息,支持到中国地区(不含港台地区)街道级别,包含国家、省、市、区县、详细地址和运营商等信息。IP归属地-IPv4区县级:根据IP地址查询归属地信息…...

Kerberos身份认证原理与企业级排错实战指南
1. 这不是“另一个登录框”,而是一套精密运转的身份验证齿轮系统很多人第一次听说 Kerberos,是在公司内网登录邮箱或访问内部系统时,看到那个带小盾牌图标的弹窗——“正在使用 Kerberos 协议进行身份验证”。于是下意识觉得:“哦…...

如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南
如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南 【免费下载链接】UAssetGUI A tool designed for low-level examination and modification of Unreal Engine game assets by hand. 项目地址: https://gitcode.com/gh_mirrors/ua/UAssetGUI UAss…...

0.2毫秒快速启动的操作系统
在工业控制以及航空航天等核心场景,极速启动就是高可靠系统的生命线。0.2毫秒超快启动搭配硬件看门狗,让设备在掉电重启、异常恢复时瞬时归位,关键任务永不延误! https://www.bilibili.com/video/BV11mLY6VERt/?spm_id_from333.1…...
)
【2025】AWVS安装保姆级教程(最新25.1.2可用)
【2025】AWVS安装保姆级教程(最新25.1.2可用) 文章目录 工具下载Host 重定向AWVS安装AWVS查看安装失败原因 工具下载 点击下载即可 下载完的工具后缀格式为.apk,需要将其改为.zip,然后将其解压得到以下工具后续安装使用 Host 重…...

Keil µVision反汇编窗口内容导出方案与调试技巧
1. 问题背景与需求解析在嵌入式开发过程中,调试环节往往占据大量时间。Keil Vision作为业界广泛使用的集成开发环境(IDE),其调试器功能强大但某些细节功能仍有提升空间。最近我在使用C251架构开发汽车电子控制单元时,就遇到了一个看似简单却影…...

AhMyth位置跟踪:GPS定位与地理围栏技术深度解析
AhMyth位置跟踪:GPS定位与地理围栏技术深度解析 【免费下载链接】AhMyth Cross-Platform Android Remote Administration Tool | The only maintained version of AhMyth on github | A revival of the original repository at https://GitHub.com/AhMyth/AhMyth-An…...

用PyTorch复现FactorVAE:一个能同时预测收益和风险的量化模型实战教程
用PyTorch实战FactorVAE:构建收益与风险双预测的量化模型 在量化投资领域,传统线性因子模型正逐渐被非线性机器学习方法所取代。然而金融数据特有的低信噪比特性,使得直接从市场数据中提取有效因子成为一项艰巨挑战。本文将深入探讨如何利用P…...
)
Frida无Root Hook PC微信小程序源码(Electron+Chromium)
1. 这不是“破解”,而是一次对微信小程序运行机制的逆向观察 你有没有试过,在PC版微信里点开一个小程序,想看看它背后是怎么写的?比如某个电商小程序的优惠券逻辑、某个工具类小程序的数据渲染方式,甚至只是单纯好奇—…...

LeagueAkari:基于LCU接口的英雄联盟客户端自动化工具深度解析
LeagueAkari:基于LCU接口的英雄联盟客户端自动化工具深度解析 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 功能模块架构与核心技…...

【国家级攻防演练级建议】:DeepSeek私有化部署中4类隐蔽后门植入路径与实时检测方案
更多请点击: https://kaifayun.com 第一章:DeepSeek私有化部署中隐蔽后门植入的攻防对抗本质 在私有化场景下,DeepSeek模型的部署链路常跨越镜像构建、权重加载、推理服务启动及API网关接入等多个环节。攻击者可利用构建上下文污染、依赖包劫…...