通俗易懂理解注意力机制(Attention Mechanism)
重要说明:本文从网上资料整理而来,仅记录博主学习相关知识点的过程,侵删。
一、参考资料
大话注意力机制(Attention Mechanism)
注意力机制(Attention Mechanism)
深度学习中的注意力机制
注意力机制
二、注意力机制(Attention Mechanism)
Attention模型可以看到全局的信息。
1. 通俗理解Attention
人在观察事物时会有选择性的关注较为重要的信息,称其为注意力。通过持续关注这一关键位置以获得更多的信息,而忽略其他的无用信息,这种视觉注意力机制大大提高了我们处理信息的效率和准确性。深度学习中的注意力机制和人类视觉的注意力机制类似,就是在更多信息中把注意力集中放在重要的点上,选出关键信息,而忽略其他不重要的信息。

上图形象化展示了人类在看到一副图像时如何高效分配有限的注意力资源。其中红色区域表明视觉系统更关注目标,很明显对于上图所示的场景,人们会把注意力更多投入到人的脸部,文本的标题以及文章首句等位置。
注意力机制的灵感来源可以归结到人对环境的生理感知,当人类看东西时,一般会将注意力注视着某个地方,而不会关注全部所有信息。比如,视觉系统更倾向于挑选影像中的部分信息进行集中分析,忽略图像中无关的信息。再比如,当我们看到下面这张猫的图片时,主要会将目光停留在猫的脸部,以及注意猫的躯干,而后面的草地则会被当成背景忽略,这说明我们在每一处空间位置上的注意力分布不一样。

通过这种方式,人类在需要重点关注的目标区域,会投入更多的注意力资源,以获取更多的细节信息,而抑制其他区域信息。这样使人类能够利用有限的注意力资源从大量信息中快速获取高价值的信息,极大地提升了大脑处理信息的效率。
2. 注意力机制的原理
原始论文:[1]
注意力机制(Attention Mechanism)是机器学习中的一种数据处理方法,广泛应用在自然语言处理、图像识别以及语音识别等各种不同类型的机器学习任务中。注意力机制对不同信息的关注程度(重要程度)由权值来体现,注意力机制可以视为查询矩阵(Query)、键(key)以及加权平均值构成了多层感知机(Multilayer Perceptron, MLP)。
注意力的思想,类似于寻址。给定Target中的某个元素Query,通过计算Query和各个Key的相似性或相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到最终的Attention数值。所以,本质上Attention机制是Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。

Source:由一系列的<Key, Value>键值对构成。
Query:给定的Target元素;
Key:Source中元素的Key值;
Value:Source中元素的Value值;
权重系数:Query与key的相似性或相关性,权重系数 S i m i l a r i t y ( Q u e r y , K e y i ) Similarity(Query, Key_i) Similarity(Query,Keyi);
Attention Value:对Value值进行加权求和;
根据注意力机制的原理可知,其计算公式如下:
A t t e n t i o n ( Q u e r y , S o u r c e ) = ∑ i = 1 L x S i m i l a r i t y ( Q u e r y , K e y i ) ∗ V a l u e i Attention(Query, Source) = \sum_{i=1}^{L_x}Similarity(Query, Key_i)*Value_i Attention(Query,Source)=i=1∑LxSimilarity(Query,Keyi)∗Valuei
其中, L x = ∣ ∣ S o u r c e ∣ ∣ L_x=||Source|| Lx=∣∣Source∣∣,表示Source的长度。
Attention从大量信息中有选择地筛选出少量重要信息并聚焦到这些重要信息上,忽略大多不重要的信息。聚焦的过程体现在权重系数的计算上,权重越大,越聚焦在对应的Value值上,即权重代表了信息的重要性,而Value是其对应的信息。
3. 注意力机制的计算过程
大多数方法采用的注意力机制计算过程可以细化为如下三个阶段。
三阶段的注意力机制计算流程:
- 第一阶段,计算 Query和不同 Key 的相关性,即计算不同 Value 值的权重系数;
- 第二阶段,对上一阶段的输出进行归一化处理,将数值的范围映射到 0 和 1 之间。
- 第三阶段,根据权重系数对Value进行加权求和,从而得到最终的注意力数值。

3.1 第一阶段
计算 Query和不同 Key 的相似性或者相关性,即计算不同 Value 值的权重系数。
计算两者相似性或者相关性常用方法:
- 点积: S i m i l a r i t y ( Q u e r y , K e y i ) = Q u e r y ∗ K e y i Similarity(Query, Key_i) = Query*Key_i Similarity(Query,Keyi)=Query∗Keyi
- Cosin相似性: S i m i l a r i t y ( Q u e r y , K e y i ) = Q u e r y ∗ K e y i ∣ ∣ Q u e r y ∣ ∣ ∗ ∣ ∣ K e y i ∣ ∣ Similarity(Query, Key_i) = \frac{Query*Key_i}{||Query||*||Key_i||} Similarity(Query,Keyi)=∣∣Query∣∣∗∣∣Keyi∣∣Query∗Keyi
- MLP网络: S i m i l a r i t y ( Q u e r y , K e y i ) = M L P ( Q u e r y , K e y i ) Similarity(Query, Key_i) = MLP(Query, Key_i) Similarity(Query,Keyi)=MLP(Query,Keyi)
3.2 第二阶段
对第一阶段得到的原始权重进行归一化处理,将数值的范围映射到 0 和 1 之间。
根据产生方法的不同,第一阶段产生的分值的取值范围也不一样,第二阶段引入类似SoftMax的计算方式对第一阶段的得分就行数值转换。一方面,可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面,通过SoftMax的内在机制更加突出重要元素的权重。即一般采用如下公式:
a i = S o f t m a x ( S i m i ) = e S i m i ∑ j = 1 L x e S i m j a_i = Softmax(Sim_i) = \frac{e^{Sim_i}}{\sum_{j=1}^{L_x}e^{Sim_j}} ai=Softmax(Simi)=∑j=1LxeSimjeSimi
3.3 第三阶段
根据权重系数对Value进行加权求和,从而得到最终的注意力数值:
A t t e n t i o n ( Q u e r y , S o u r c e ) = ∑ i = 1 L x a i ∗ V a l u e i Attention(Query, Source) = \sum_{i=1}^{L_x}a_i*Value_i Attention(Query,Source)=i=1∑Lxai∗Valuei
4. 注意力机制的分类
4.1 按Attention的可微性分类
视觉注意力机制 | Non-local模块与Self-attention的之间的关系与区别?
4.1.1 硬注意力机制(Hard-Attention)
-
硬注意力更加关注点,也就是图像中的每个点都可能延伸出注意力。同时,硬注意力是一个随机的预测过程,更强调动态变化。硬注意力是一个不可微的注意力,训练过程往往是通过增强学习(
reinforcement learning) 来完成。 -
硬注意力是0/1问题,某个区域要么被关注,要么不关注,这是一个不可微的注意力。
4.1.2 软注意力机制(Soft-Attention)
-
软注意力更加关注区域或者通道,软注意力是确定性的注意力,学习完成后可以直接通过网络生成,最关键的地方是软注意力是可微的。可微的注意力可以通过神经网络计算梯度,通过前向传播和后向反馈来学习得到注意力的权重。
-
软注意力是[0,1]间连续分布问题,用0到1的不同分值表示每个区域被关注的程度高低。
-
在CV领域中,很多相关工作(例如,分类、检测、分割、生成模型、视频处理等)都在使用软注意力,这些工作也衍生了很多不同的软注意力使用方法。这些方法共同的部分,都是利用相关特征学习权重分布,再用学出来的权重施加在特征之上,进一步提取相关知识。
-
软注意力施加权重的方法:
- 加权可以作用在原图上;
- 加权可以作用在空间维度上,给不同区域加权;
- 加权可以作用在channel维度上,给不同通道特征加权;
- 加权可以作用在不同时刻历史特征上,结合循环结构添加权重。例如,机器翻译,或者视频相关的工作。
4.2 按注意力的关注域分类
4.2.1 空间域(spatial domain)
首先将通道本身进行降维,分别获取 MaxPool 和 AvgPool 的结果,然后拼接(concat),再使用一个卷积层进行学习。

4.2.2 通道域(channel domain)
分别获取 MaxPool 和 AvgPool 的结果,然后经过几个MLP层获得变换结果,最后分别应用于两个通道,使用Sigmoid函数得到通道的Attention结果。

4.2.3 其他域
-
层域(layer domain)
-
混合域(mixed domain)
-
时间域(time domain)
5. 基于Encoder-Decoder的注意力机制
人类视觉注意力机制,在处理信息时注意力的分布是不一样的。而 Encoder-Decoder 框架将输入X都编码转化为语义表示C,这样会导致所有输入的处理权重都一样,没有体现出注意力集中。因此,也可看成是“分心模型”。
为了能体现注意力机制,将语义表示C进行扩展,用不同的C来表示不同注意力的集中程度,每个C的权重不一样。扩展后的 Encoder-Decoder 框架变为:

下面通过一个英文翻译成中文的例子说明“注意力模型”:
例如,输入的英文句子是:Tom chase Jerry,目标的翻译结果是:”汤姆追逐杰瑞”。那么在语言翻译中,Tom,chase,Jerry这三个词对翻译结果的影响程度是不同的。其中,Tom是主语,Jerry是宾语,是两个人名,chase是谓语,是动词,这三个词的影响程度大小顺序分别是Jerry>Tom>chase,例如(Tom,0.3),(chase,0.2),(Jerry,0.5)。不同的影响程度代表模型在翻译时分配给不同单词的注意力大小,即分配的概率大小。
生成目标句子单词的过程,计算形式如下:
y 1 = f 1 ( C 1 ) y 2 = f 1 ( C 2 , y 1 ) y 3 = f 1 ( C 3 , y 1 , y 2 ) y_1 = f_1(C_1) \\ y_2 = f_1(C_2, y_1) \\ y_3 = f_1(C_3,y_1, y_2) y1=f1(C1)y2=f1(C2,y1)y3=f1(C3,y1,y2)
其中,f1是 Decoder 的非线性变换函数。每个 C i C_i Ci 对应不同单词的注意力分配概率分布,计算形式如:
C 汤姆 = g ( 0.6 ∗ f 2 ( " T o m " ) , 0.2 ∗ f 2 ( " c h a s e " ) , 0.2 ∗ f 2 ( " J e r r y " ) ) C 追逐 = g ( 0.2 ∗ f 2 ( " T o m " ) , 0.7 ∗ f 2 ( " c h a s e " ) , 0.1 ∗ f 2 ( " J e r r y " ) ) C 杰瑞 = g ( 0.3 ∗ f 2 ( " T o m " ) , 0.2 ∗ f 2 ( " c h a s e " ) , 0.5 ∗ f 2 ( " J e r r y " ) ) C_{汤姆} = g(0.6*f_2("Tom"), 0.2*f_2("chase"), 0.2*f_2("Jerry")) \\ C_{追逐} = g(0.2*f_2("Tom"), 0.7*f_2("chase"), 0.1*f_2("Jerry")) \\ C_{杰瑞} = g(0.3*f_2("Tom"), 0.2*f_2("chase"), 0.5*f_2("Jerry")) C汤姆=g(0.6∗f2("Tom"),0.2∗f2("chase"),0.2∗f2("Jerry"))C追逐=g(0.2∗f2("Tom"),0.7∗f2("chase"),0.1∗f2("Jerry"))C杰瑞=g(0.3∗f2("Tom"),0.2∗f2("chase"),0.5∗f2("Jerry"))
其中f2函数表示 Encoder 节点中对输入英文单词的转换函数,g函数表示 Encoder 合成整个句子中间语义表示的变换函数,一般采用加权求和的方式,如下式:
c i = ∑ j = 1 T x a i j h j c_i = \sum_{j=1}^{T_x}{a_{ij}h_j} ci=j=1∑Txaijhj
其中, a i j a_{ij} aij 表示权重, h j h_j hj 表示 Encoder 的转换函数,即 h1 = f2("Tom"), h2 = f2("chase"), h3 = f2("Jerry"), T x T_x Tx表示输入句子的长度。
当i是“汤姆”时,则注意力模型权重 a i j a_{ij} aij 分别是0.6,0.2,0.2。那么这个权重是如何得到的呢? a i j a_{ij} aij 可以看做是一个概率,反映了 h j h_j hj 对 c i c_i ci 的重要性,可使用softmax来表示:
a i j = e x p ( e i j ) ∑ k = 1 L e x p ( e i k ) a_{ij} = \frac{exp(e_{ij})}{\sum_{k=1}^{L}{exp(e_{ik})}} aij=∑k=1Lexp(eik)exp(eij)
其中, e i j = f ( h i − 1 , h j ) e_{ij} = f(h_{i-1}, h_j) eij=f(hi−1,hj),这里的f表示一个匹配度的打分函数,可以是一个简单的相似度计算,也可以是一个复杂的神经网络计算结果。在这里,由于在计算 c i c_i ci 时还没有 h i h_i hi,因此使用最接近的 h i − 1 h_{i-1} hi−1 代替。当匹配度越高,则 a i j a_{ij} aij 的概率越大。因此,得出 a i j a_{ij} aij 的过程如下图:

其中, h i h_i hi 表示 Encoder 的转换函数,F(hj,Hi) 表示预测与目标的匹配打分函数。将以上过程串起来,则注意力模型的结构如下图所示:

其中, h i h_i hi 表示 Encoder 阶段的转换函数, c i c_i ci 表示语义编码, h i ′ h^{\prime}_i hi′ 表示 Decoder 阶段的转换函数。
6. 注意力机制的应用
6.1 在图像描述(Image Caption)领域
图片描述,即输入一张图片,AI系统根据图片中的内容输出一句描述文字。如下图所示,左图是输入原图,右边是AI系统生成划横线单次的时候对应图片中聚焦的位置区域,下边的句子是AI系统自动生成的描述文字。

可以看到,在输出frishbee(飞碟)、dog(狗)等单次时,AI系统会将注意力更多地分配给图片中飞碟、狗的对应位置,以获得更加准确的输出。
7. Self-Attention
用MLP代替掉Self-Attention
三、参考文献
[1] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
相关文章:
通俗易懂理解注意力机制(Attention Mechanism)
重要说明:本文从网上资料整理而来,仅记录博主学习相关知识点的过程,侵删。 一、参考资料 大话注意力机制(Attention Mechanism) 注意力机制(Attention Mechanism) 深度学习中的注意力机制 注意力机制 二、注意力…...
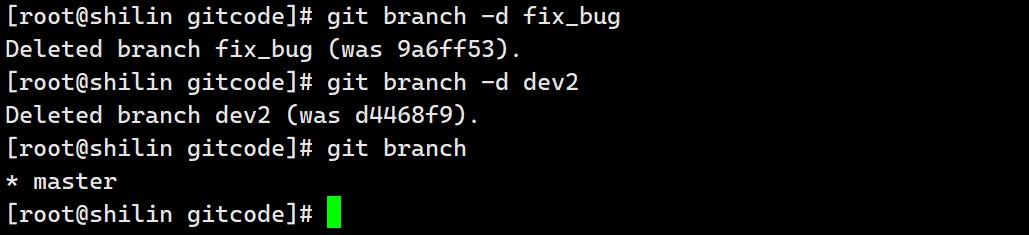
git的分支的使用,创建分支,合并分支,删除分支,合并冲突,分支管理策略,bug分支,强制删除分支
GIT | 分支 文章目录 GIT | 分支创建分支合并分支删除分支合并冲突分支管理策略bug分支强制删除分支 创建分支 查看当前本地仓库中有哪些分支 git branchHEAD所指向的分支就是当前正在工作的分支 cat .git/HEAD创建一个分支 git branch dev创建好了,但是目前还是…...

【leetcode100-081到090】【动态规划】一维五题合集1
【爬楼梯】 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 思路: 【状态】 dp[i];//爬i级台阶有几种方法 【初始】 dp[0] 1;//爬0级1种(不爬)dp[1] 1;/…...

数据结构-顺序表详解专题
目录 顺序表 1.简单了解顺序表 2.顺序表的分类 2.1静态顺序表 2.2动态顺序表 2.3typedef命名作用 3.动态顺序表的实现 SeqList.h SeqList.c test.c 顺序表 1.简单了解顺序表 顺序表是线性表的一种,线性表是在逻辑上是线性结构,在物理逻辑上并…...

对商业知识和思维的一些小体会
用途:个人学习笔录,欢迎指正 前言: 小生拙见,我认为商业知识和商业思维的理解对于每一个行业都有潜在的帮助,因为每个人的生活都离不开商业,生意、工作都是交换,用自身提供的价值换取薪酬。因此…...

【笔记】计算文件夹的大小
目标:遍历文件夹,计算文件夹下包含文件和文件夹的大小。将这些结果存入python自带的数据库。 用大模型帮我设计并实现。 Step1 创建一个测试用的目录结构 创建目录结构如下所示: TestDirectory/ │ ├── EmptyFolder/ │ ├── SmallF…...
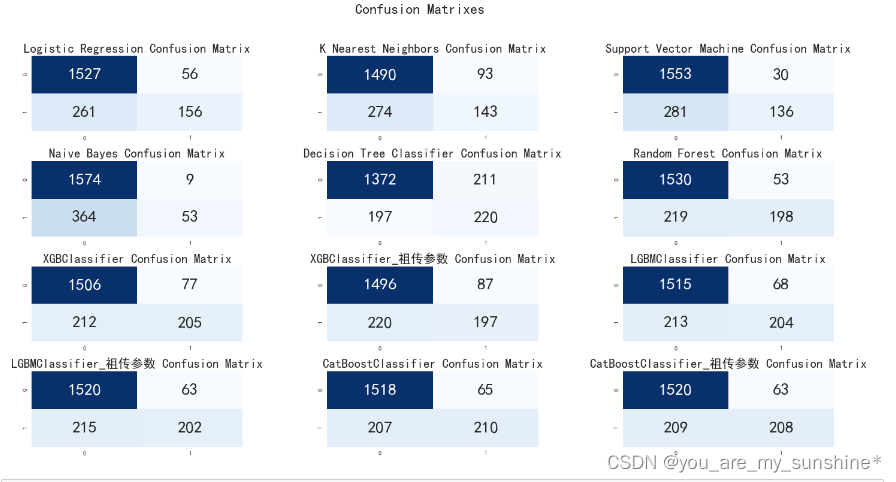
机器学习_常见算法比较模型效果(LR、KNN、SVM、NB、DT、RF、XGB、LGB、CAT)
文章目录 KNNSVM朴素贝叶斯决策树随机森林 KNN “近朱者赤,近墨者黑”可以说是 KNN 的工作原理。 整个计算过程分为三步: 计算待分类物体与其他物体之间的距离;统计距离最近的 K 个邻居;对于 K 个最近的邻居,它们属于…...

外包干了8个月,技术退步明显...
先说一下自己的情况,大专生,18年通过校招进入武汉某软件公司,干了接近4年的功能测试,今年年初,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落! 而我已经在一个企业干了四年的功能测…...
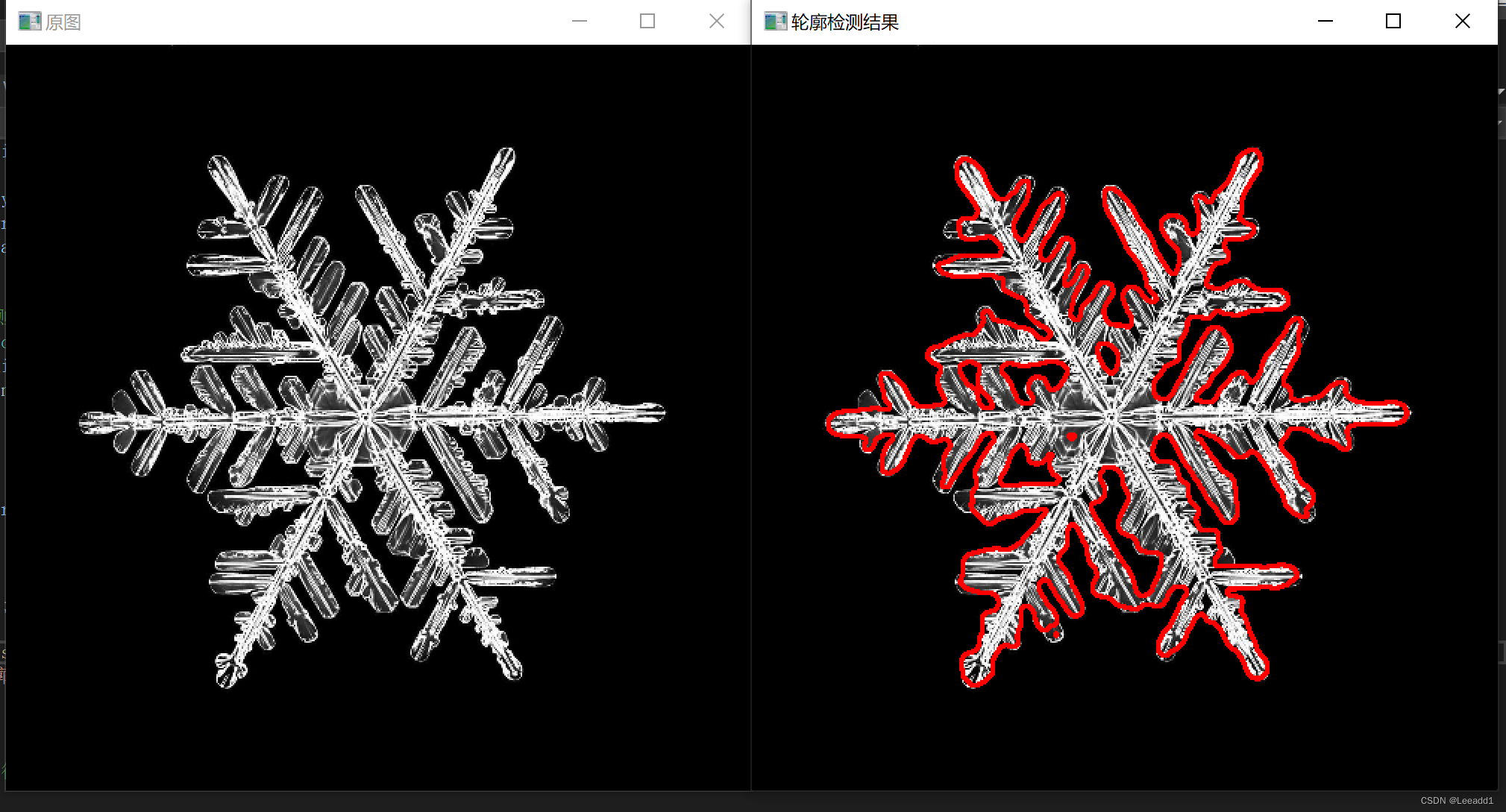
opencv#41 轮廓检测
轮廓概念介绍 通常我们使用二值化的图像进行轮廓检测,对轮廓以外到内进行数字命名,如下图,最外面的轮廓命名为0,向内部进行扩展,遇到黑色白色相交区域,就是一个新的轮廓,然后依次对轮廓进行编号…...
Websocket基本用法
1.Websocket介绍 WebSocket是基于TCP的一种新的网络协议。它实现了浏览器与服务器全双工通信——浏览器和服务器只需要完成一次握手,两者之间就可以创建持久性的连接,并进行双向数据传输。 应用场景: 视频弹幕网页聊天体育实况更新股票基金…...
node.js与express.js创建项目以及连接数据库
搭建项目 一、技术准备 node版本:16.16.0 二、安装node成功后,安装express,命令如下: npm install -g express 或者: npm install --locationglobal express 再安装express的命令工具: npm install --location…...

【Tomcat与网络8】从源码看Tomcat的层次结构
在前面我们介绍了如何通过源码来启动Tomcat,本文我们就来看一下Tomcat是如何一步步启动的,以及在启动过程中,不同的组件是如何加载的。 一般,我们可以通过 Tomcat 的 /bin 目录下的脚本 startup.sh 来启动 Tomcat,如果…...

Java Agent Premain Agentmain
概念 premain是在jvm启动的时候类加载到虚拟机之前执行的 agentmain是可以在jvm启动后类已经加载到jvm中了,才去转换类。 这种方式会转换会有一些限制,比如不能增加或移除字段。 具体的做法,两者的实际做法是差不多的: premain 定义个静…...

Python实现设计模式-策略模式
策略模式是一种行为型设计模式,它定义了一系列算法或策略,并将它们封装成独立的类,使得它们可以相互替换,而不影响客户端的使用。 在策略模式中,算法或策略被封装在单独的策略类中,这些策略类实现了相同的…...
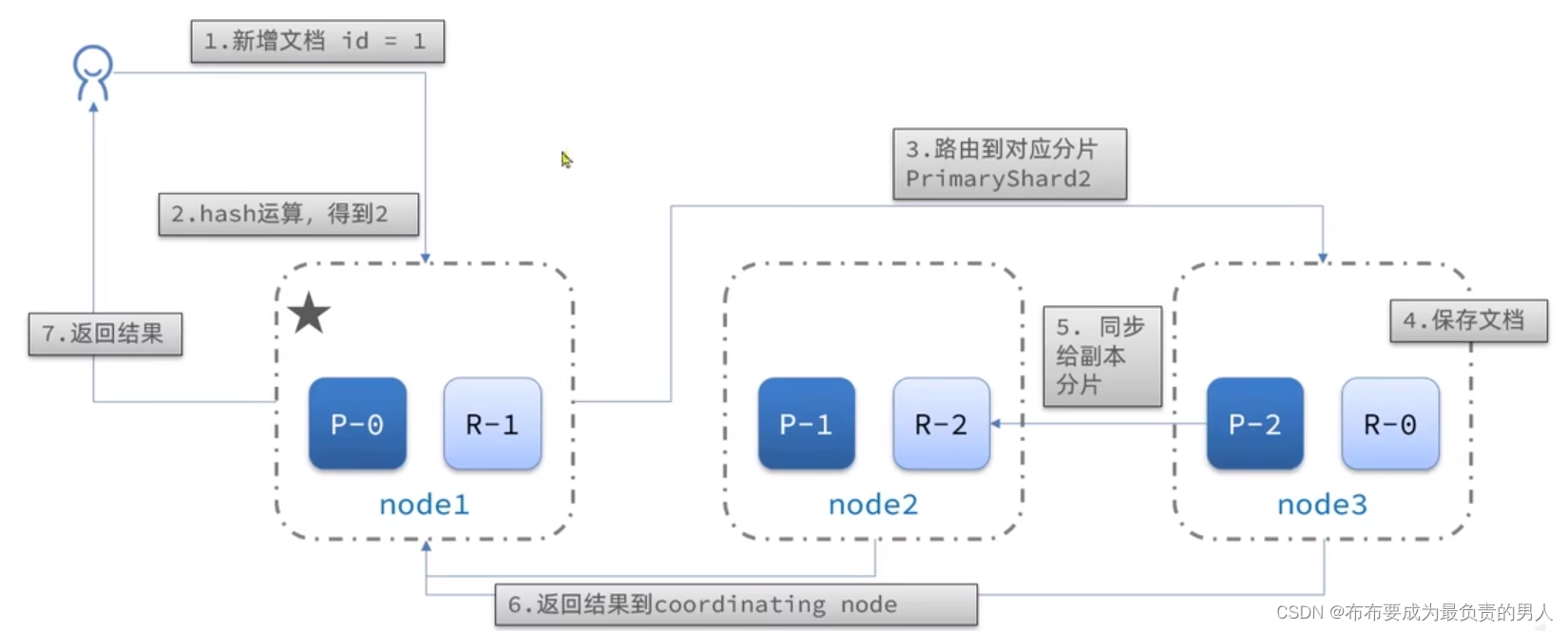
详解SpringCloud微服务技术栈:深入ElasticSearch(4)——ES集群
👨🎓作者简介:一位大四、研0学生,正在努力准备大四暑假的实习 🌌上期文章:详解SpringCloud微服务技术栈:深入ElasticSearch(3)——数据同步(酒店管理项目&a…...
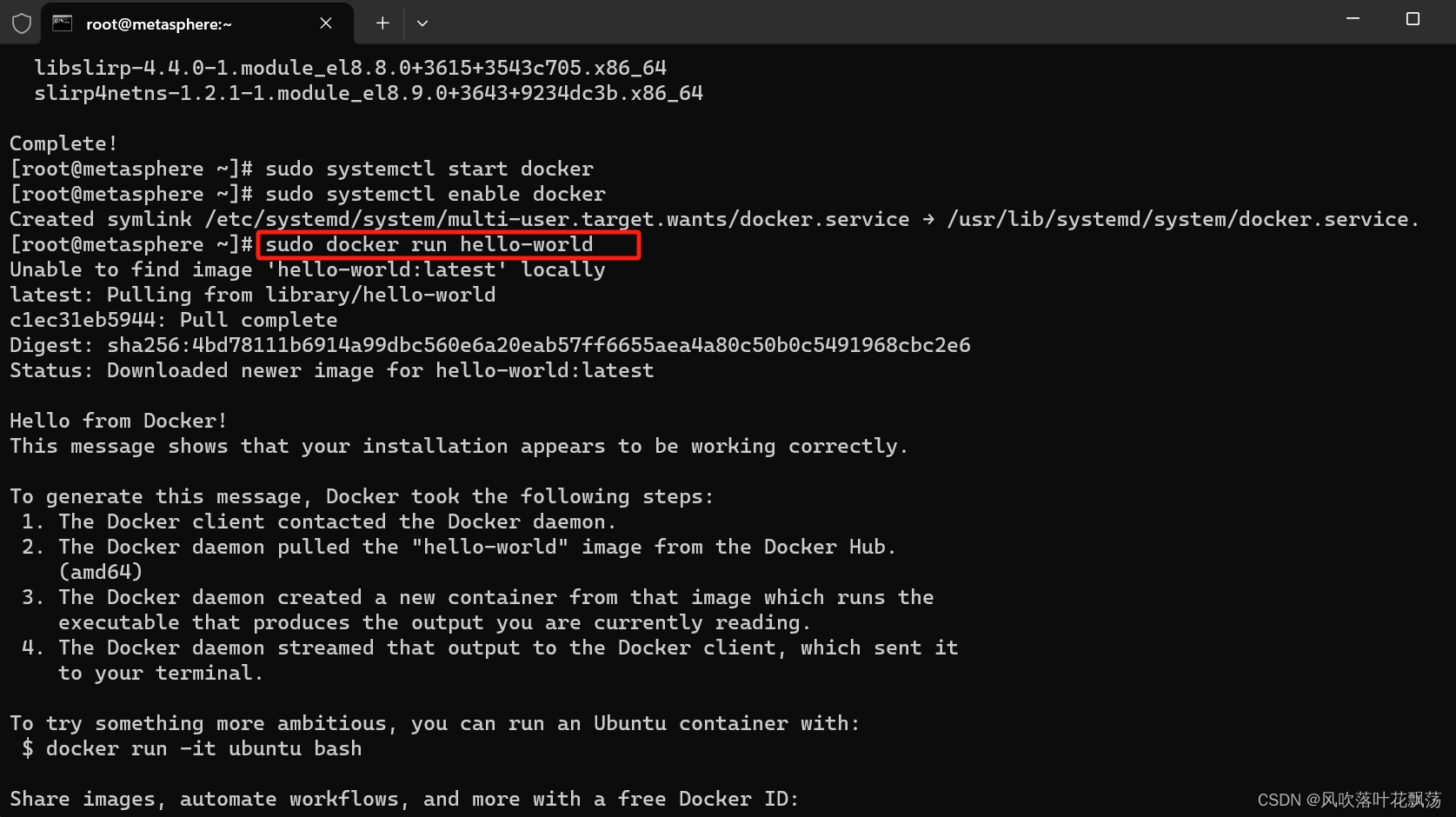
AlmaLinux上安装Docker
AlmaLinux上安装Docker 文章目录 AlmaLinux上安装Docker一、前言二、具体步骤1、Docker 下载更新系统包索引:添加Docker仓库:安装Docker引擎: 2、Docker服务启动启动Docker服务:设置Docker开机自启: 3、Docker 安装验证…...

熟悉MATLAB 环境
一、问题描述 熟悉MATLAB 环境。 二、实验目的 了解Matlab 的主要功能,熟悉Matlab 命令窗口及文件管理,Matlab 帮助系统。掌握命令行的输入及编辑,用户目录及搜索路径的配置。了解Matlab 数据的特点,熟悉Matlab 变量的命名规则&a…...
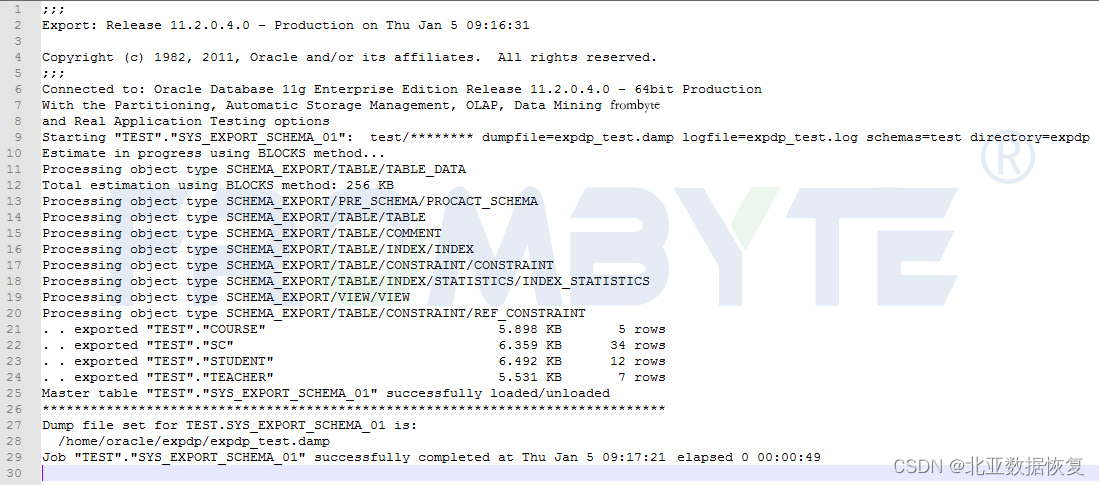
【数据库数据恢复】Oracle数据库ASM磁盘组数据恢复案例
oracle数据库故障&分析: oracle数据库ASM磁盘组掉线,ASM实例不能挂载。数据库管理员尝试修复数据库,但是没有成功。 oracle数据库数据恢复过程: 1、将oracle数据库所涉及磁盘以只读方式备份。后续的数据分析和数据恢复操作都…...
STM32CubeMX教程31 USB_DEVICE - HID外设_模拟键盘或鼠标
目录 1、准备材料 2、实验目标 3、模拟鼠标实验流程 3.0、前提知识 3.1、CubeMX相关配置 3.1.0、工程基本配置 3.1.1、时钟树配置 3.1.2、外设参数配置 3.1.3、外设中断配置 3.2、生成代码 3.2.0、配置Project Manager页面 3.2.1、设初始化调用流程 3.2.2、外设中…...

知道Wi-Fi名称和密码之后自动连接
这里写自定义目录标题 有Wi-Fi名称和密码自动连接Wi-Fi主Activity服务类 WIFIStateReceiver工具类 WIFIConnectionManager 有Wi-Fi名称和密码自动连接Wi-Fi 主Activity public class MainActivity extends AppCompatActivity implements View.OnClickListener{private static…...

初步认识假设检验
下面内容摘录自《用R探索医药数据科学》专栏文章的部分内容(原文6102字) 2篇3章3节:从案例中认识假设检验_认识参数假设检验-CSDN博客 假设检验是统计学中一种用于判断数据是否支持某一特定假设的常用方法。在数据分析中,假设检验…...

Rshell框架实战:红队内网渗透的信道管理与双平台协同
1. 这不是“教你怎么黑”,而是还原一次真实红队作业的完整切片Rshell框架——这个名字在渗透测试圈子里不算陌生,但真正把它用透、用稳、用出生产级效果的人,远比想象中少。我见过太多人把Rshell当成一个“带图形界面的msfvenomnc组合包”&am…...

ZXing条形码识别库的模块化架构演进与性能优化策略
ZXing条形码识别库的模块化架构演进与性能优化策略 【免费下载链接】zxing ZXing ("Zebra Crossing") barcode scanning library for Java, Android 项目地址: https://gitcode.com/gh_mirrors/zx/zxing ZXing("Zebra Crossing"…...

taotoken token plan套餐详解如何节省大模型调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken Token Plan 套餐详解:如何节省大模型调用成本 对于频繁使用大模型 API 的企业开发者或个人用户而言ÿ…...

5个高级技巧:掌握Dark Reader动态主题修复的最佳实践
5个高级技巧:掌握Dark Reader动态主题修复的最佳实践 【免费下载链接】darkreader Dark Reader Chrome and Firefox extension 项目地址: https://gitcode.com/gh_mirrors/da/darkreader Dark Reader是一款广受欢迎的浏览器扩展,它通过智能算法将…...

Cursor Free VIP终极指南:5步轻松实现AI编程助手永久免费使用
Cursor Free VIP终极指南:5步轻松实现AI编程助手永久免费使用 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached y…...

多模态大模型落地实战:对齐、融合与生成的工程化拆解
1. 这不是“多模态大模型”的科普文,而是一份实操者手记“Understanding Multimodal LLMs: The Next Evolution of AI”——这个标题乍看像学术综述的副标题,但在我过去三年深度参与7个跨模态AI落地项目(从工业质检图像-文本联合推理…...
)
Graphormer实战:用最短路径和虚拟节点搞定分子性质预测(附PyTorch代码)
Graphormer实战:从分子结构到性质预测的完整实现指南 在药物发现和材料科学领域,准确预测分子的物理化学性质可以大幅加速研发进程。传统方法依赖昂贵的实验测量或复杂的量子化学计算,而图神经网络(GNN)和Transformer的结合——Graphormer&a…...
)
HeyGen免费额度怎么用最值?我用1个积分做了个多语言口播视频(附保姆级教程)
HeyGen免费额度高效使用指南:1积分打造多语言口播视频 第一次接触HeyGen时,我被它逼真的口型同步技术震撼了——直到发现免费账户只有1个积分。这就像得到一颗钻石却只能刮一次玻璃。经过两周的反复测试,我总结出一套**"1积分最大化&quo…...

RT-Thread全局中断操作:原理、应用与低功耗设计关键
1. 项目概述:为什么需要深入理解全局中断操作?刚接触RT-Thread这类实时操作系统时,很多朋友都会对“全局中断”这个概念感到困惑。尤其是在看到代码里频繁出现的rt_hw_interrupt_disable()和rt_hw_interrupt_enable()这对函数时,心…...