【数据结构】链式二叉树
前言
在前面我们学习了一些二叉树的基本知识,了解了它的结构以及一些性质,我们还用数组来模拟二叉树建立了堆,并学习了堆排序,可是数组结构的二叉树有很大的局限性,平常我们用的最多树结构的还是链式二叉树,因此本章我们来学习一些链式二叉树的相关知识。
普通的链式二叉树作用不大,同时二叉树也不是经常用来存储数据,因为存储数据用顺序表或链表就已经够了,链式二叉树通常是为了后续更加高级的树结构做铺垫,就如同单链表一样。不过基础不牢,地动山摇,本章的学习还是很重要的。
关于本章的代码可以访问这里获取
链式二叉树结构的实现
- 一、创建一颗二叉树
- 1、节点的定义
- 2、节点的创建
- 3、节点链接成树
- 二、二叉树的遍历
- 1、前序、中序以及后序遍历介绍
- 2、前序、中序以及后序遍历的代码实现
- 三、二叉树的层序遍历
- 四、二叉树的节点个数以及高度
- 1、二叉树的节点个数
- 2、二叉树叶子节点的个数
- 3、二叉树第k层节点个数
- 4、树的高度
- 5、二叉树查找值为x的节点
- 五、二叉树的创建和销毁
- 1、二叉树的创建
- 2、二叉树的销毁
- 3、判断一棵树是不是完全二叉树
一、创建一颗二叉树
在学习二叉树的基本操作前,需先要创建一棵二叉树,然后才能学习其相关的基本操作。由于现在各位对二叉树结构掌握还不够深入,为了降低大家学习成本,此处手动快速创建一棵简单的二叉树,快速进入二叉树操作学习,等二叉树结构了解的差不多时,我们反过头再来研究二叉树真正的创建方式。
我们来手动创建下面的二叉树:
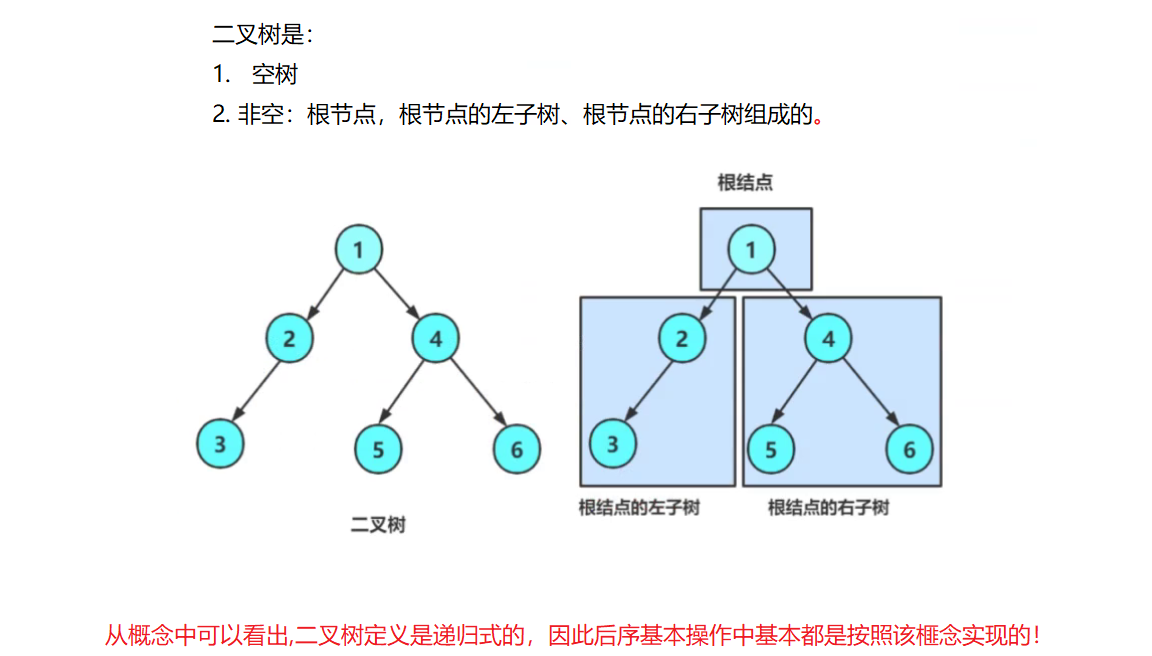
首先这里的二叉树每个节点都有一个数据域,两个指针域,于是我们可以用结构体去构建它们。
1、节点的定义
typedef int BTDataType;
typedef struct BinaryTreeNode
{BTDataType val;struct BinaryTreeNode* leftTree;struct BinaryTreeNode* rightTree;
}BTNode;
结构体有了,接下来我们就要去创建节点了,把一个个节点创建出来然后我们挨个手动链接就能完成我们想要的二叉树了!
2、节点的创建
//创建节点
BTNode* BuyNode(BTDataType val)
{BTNode* tmp = (BTNode*)malloc(sizeof(BTNode));if (NULL == tmp){perror("malloc fail:");return;}tmp->val = val;tmp->leftTree = tmp->rightTree = NULL;return tmp;
}
3、节点链接成树
int main()
{BTNode* n1 = BuyNode(1);BTNode* n2 = BuyNode(2);BTNode* n3 = BuyNode(3);BTNode* n4 = BuyNode(4);BTNode* n5 = BuyNode(5);BTNode* n6 = BuyNode(6);n1->leftTree = n2;n2->leftTree = n3;n1->rightTree = n4;n4->leftTree = n5;n4->rightTree = n6;}
这样上面的树我们就构建好了!
注意:上述代码并不是创建二叉树的方式,真正创建二叉树方式后序详解重点讲解。
二、二叉树的遍历
1、前序、中序以及后序遍历介绍
学习二叉树结构,最简单的方式就是遍历。所谓二叉树遍历(Traversal)是按照某种特定的规则,依次对二叉树中的节点进行相应的操作,并且每个节点只操作一次。访问结点所做的操作依赖于具体的应用问题。 遍历是二叉树上最重要的运算之一,也是二叉树上进行其它运算的基础。
按照规则,二叉树的遍历有:前序/中序/后序的递归结构遍历:
- 前序遍历(Preorder Traversal 亦称先序遍历)——访问根结点的操作发生在遍历其左右子树之前。
- 中序遍历(Inorder Traversal)——访问根结点的操作发生在遍历其左右子树之中(间)。
- 后序遍历(Postorder Traversal)——访问根结点的操作发生在遍历其左右子树之后。
由于被访问的结点必是某子树的根,所以N(Node)、L(Left subtree)和R(Right subtree)又可解释为根、根的左子树和根的右子树。NLR、LNR和LRN分别又称为先根遍历、中根遍历和后根遍历。
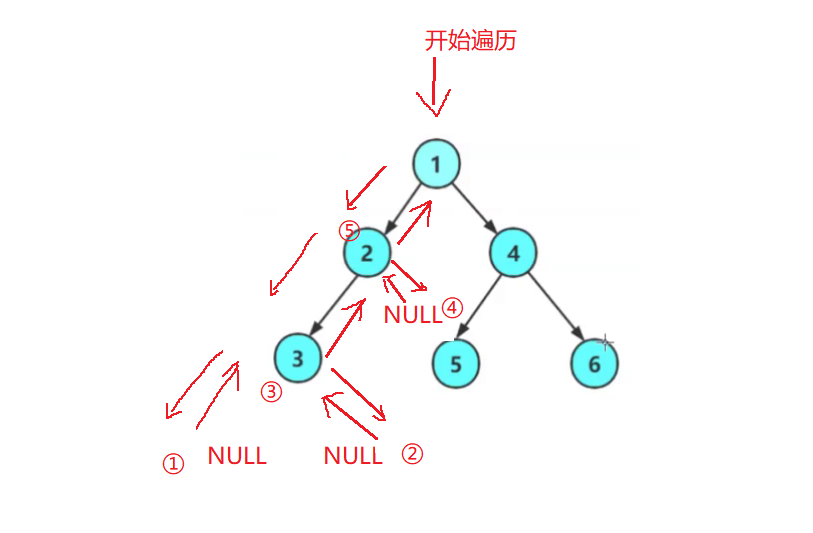
- 我们来看对于上面的树其前序遍历的顺序:
按照前序遍历的定义,我们应该先遍历根,再遍历左子树,再遍历右子树。
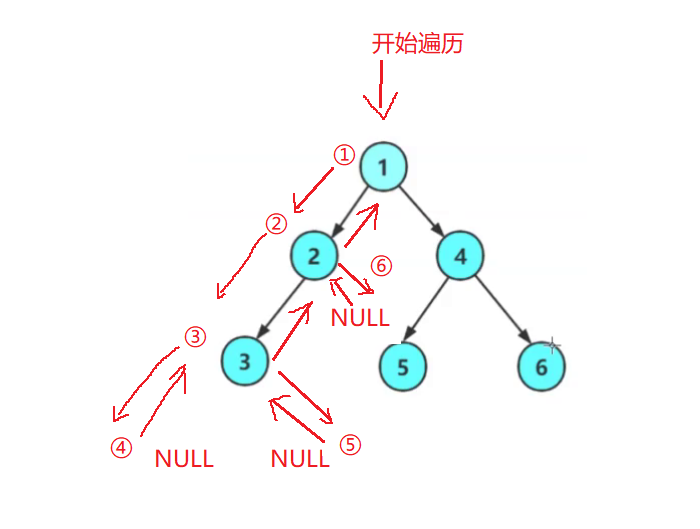
我们从根节点开始遍历,按照前序遍历的规则我们应该先访问根1,然后访问左子树,同时左子树2又是一个树按照前序遍历的规则我们应该先访问根节点,再访问左子树,于是我们要去访问3节点,3节点访问完毕后,我们又要去访问3节点的左子树,3节点的左子树是是空树于是返回,这时对于节点3这个树我们已经访问完了根节点与左子树了,接下来就要去访问3的右子树了,3节点的右子树是是空树于是返回。此时3节点已经访问完毕了。于是返回给2节点,此时2节点等到3节点返回后,2节点已经访问过了左子树,接下来就要去访问2的右子树了,2节点的右子树是是空树于是返回。
就这样层层递归,对于这颗树的前半部分遍历顺序就是:
1 2 3 NULL NULL NULL
对于右边的右子树,按照同样的规则先遍历根,再遍历左子树,再遍历右子树。
我们便可以得到这颗树的前序遍历顺序是:
1 2 3 NULL NULL NULL 4 5 NULL NULL 6 NULL NULL
- 我们来看对于上面的树其中序遍历的顺序:
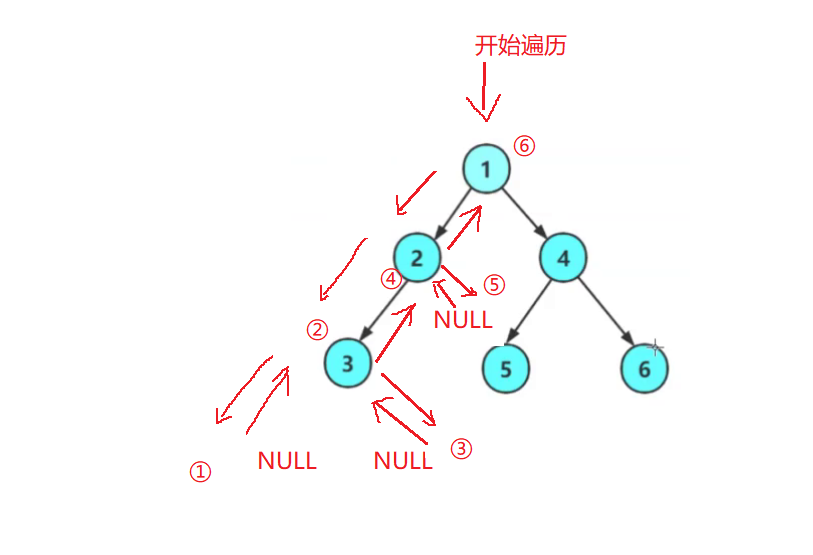
我们进入这颗树,看到了1,但是我们不能访问,我们应该先访问左子树2,进入这颗树,看到了2,但是我们不能访问,我们应该先访问左子树3,进入这颗树,看到了3,但是我们不能访问,我们应该先访问左子树NULL,左子树是NULL于是返回到3节点进行访问根,根访问完毕于是访问访问3的右子树,右子树是NULL于是返回到3节点,3节点中序遍历完毕返回给2节点…
就这样层层递归,我们便可以得到这颗树的中序序遍历顺序是:
NULL 3 NULL 2 NULL 1 NULL 5 NULL 4 NULL 6 NULL
- 我们来看对于上面的树其后序遍历的顺序:
同理层层递归,我们便可以得到这颗树的后序序遍历顺序是:
NULL NULL 3 NULL 2 NULL NULL 5 NULL NULL 6 4 1
2、前序、中序以及后序遍历的代码实现
//二叉树的前序遍历
void PrevOrder(BTNode* root)
{//判断是否为空,空直接返回if (NULL == root){return;}//前序遍历,先遍历根printf("%d ", root->val);//遍历完根再遍历左子树PrevOrder(root->leftTree);//遍历完左子树再遍历右子树PrevOrder(root->rightTree);
}
对于上面的树遍历结果为:
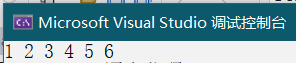
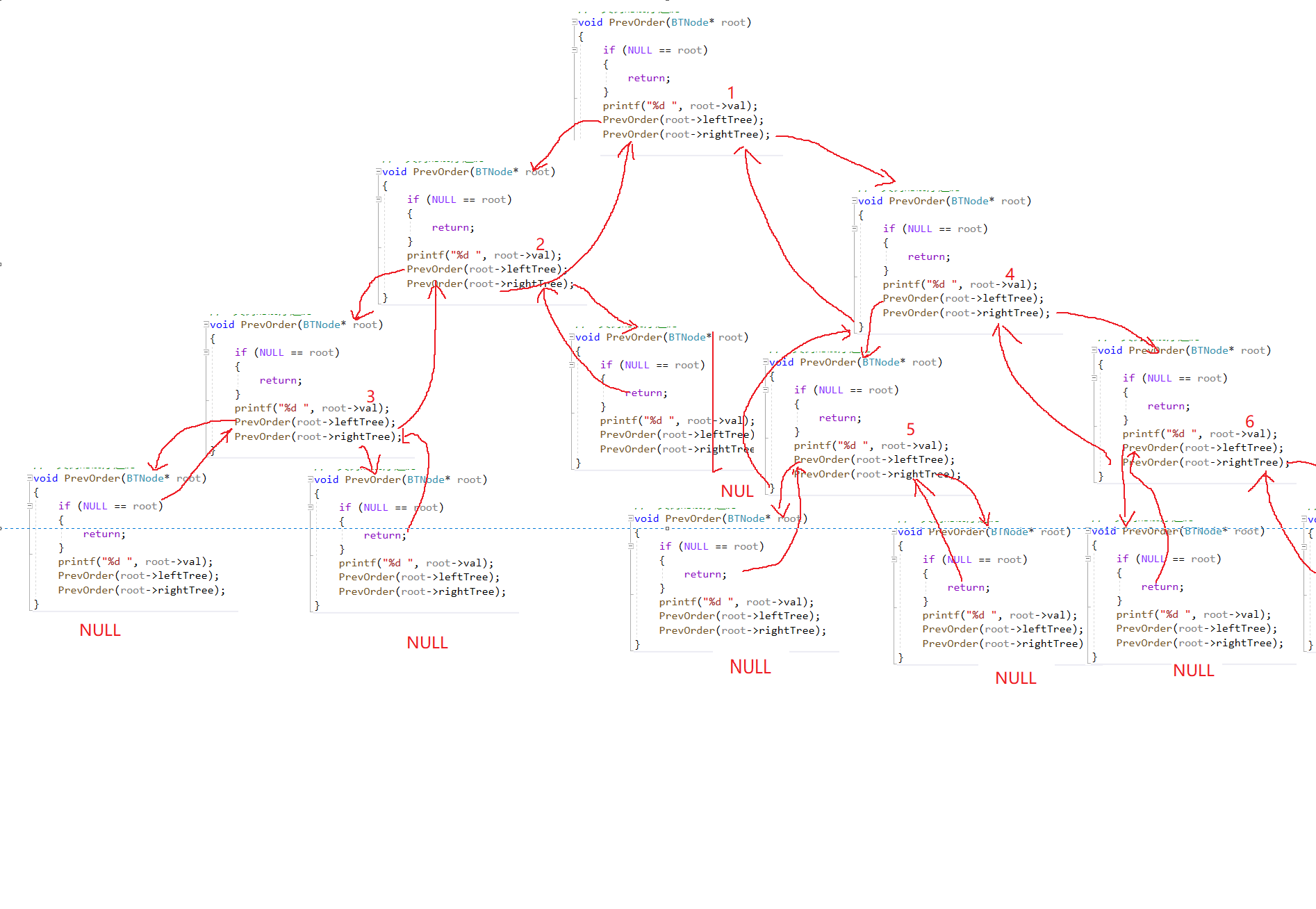
可以画出递归图帮助理解
中序遍历与前序遍历一样,只不过打印的位置发生了变化。
//二叉树的中序遍历
void InOrder(BTNode* root)
{if (NULL == root){return;}InOrder(root->leftTree);printf("%d ", root->val);InOrder(root->rightTree);
}
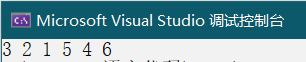
同理,后续遍历只不过打印的位置发生了变化。
//二叉树的后续遍历
void PostOrder(BTNode* root)
{if (NULL == root){return;}PostOrder(root->leftTree);PostOrder(root->rightTree);printf("%d ", root->val);
}

三、二叉树的层序遍历
二叉树的遍历方式有很多种,除了先序遍历、中序遍历、后序遍历外,还可以对二叉树进行层序遍历。
设二叉树的根节点所在层数为1,层序遍历就是从所在二叉树的根节点出发,首先访问第一层的树根节点,然后从左到右访问第2层上的节点,接着是第三层的节点,以此类推,自上而下,自左至右逐层访问树的结点的过程就是层序遍历。
其流程图如下:
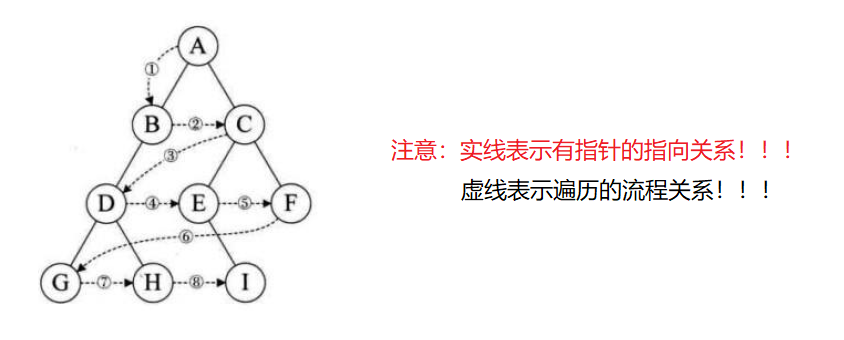
对于二叉树的前序遍历,中序遍历以及后续遍历,我们都采用了递归的方式,那是因为它们的遍历都可以将大问题分为小问题,进而递归解决,可是显然二叉树的层序遍历并不能用递归解决,因为同一层内的节点都没有办法直接访问到彼此,但是我们可以借助队列的特性来帮我们进行解决这个问题。
层序遍历的算法:
首先我们可以先判断根节点是否为NULL,如果为NULL,就结束程序,不为空先创建一个队列,将根节点的地址存入队列里面,然后获取队列里面的第一个元素,利用这个元素将此元素的左右孩子节点也带入队列里面,如果为空就不带入队列,然后删除队头元素,让队列里面的元素一个一个输出就行了。

//二叉树的层序遍历
void LevelOrder(BTNode* root)
{if (root == NULL){return;}Queue q;QueueInit(&q);QueuePush(&q, root);int KLevel = 1;while (!QueueEmpty(&q)){BTNode* front = QueueFront(&q);printf("%d ", front->val);QueuePop(&q);if (front->leftTree != NULL){QueuePush(&q, front->leftTree);}if (front->rightTree != NULL){QueuePush(&q, front->rightTree);}}printf("\n");QueueDestroy(&q);
}
还有的二叉树层序遍历,要求层序打印,也不难办,多加一个变量控制每一层的层数就行了。
//二叉树的层序遍历及层序打印
void LevelOrder2(BTNode* root)
{if (root == NULL){return;}Queue q;QueueInit(&q);QueuePush(&q, root);int KLevel = 1; //每一层的个数while (!QueueEmpty(&q)){while (KLevel--){BTNode* front = QueueFront(&q);printf("%d ", front->val);QueuePop(&q);if (front->leftTree != NULL){QueuePush(&q, front->leftTree);}if (front->rightTree != NULL){QueuePush(&q, front->rightTree);}}//运行到这里,说明上一层以经打印完了,队列中的数据就是下一层要打印的个数。printf("\n");KLevel = QueueSize(&q);}QueueDestroy(&q);
}
四、二叉树的节点个数以及高度
1、二叉树的节点个数
利用递归思想:二叉树的节点个数 = 根 + 左子树的节点个数 + 右节点的节点个数
// 二叉树节点个数
int TreeNodeSide(BTNode*root)
{if (NULL == root){return 0;}return TreeNodeSide(root->leftTree) + TreeNodeSide(root->rightTree) + 1;
}
2、二叉树叶子节点的个数
利用递归思想:二叉树叶子节点的个数 = 左子树叶子节点的个数 + 右子树叶子节点的个数
判断是否是叶子节点的条件是:左孩子 == 右孩子 == NULL
//求叶子节点
int TreeLeftSize(BTNode*root)
{if (root == NULL){return 0;}if (root->leftTree == NULL && root->rightTree == NULL){return 1;}return TreeLeftSize(root->leftTree) + TreeLeftSize(root->rightTree);
}
3、二叉树第k层节点个数
利用递归思想:
二叉树第k层节点个数 = 左子树第k-1层个数+右子树的第k-1层个数
①k >1 根的第k层==左子树第k-1层个数+右子树的第k-1层个数
②k == 1 不为NULL,就返回1;为NULL就返回0。
//求第K层节点的个数
int TreeKLevelSize(BTNode* root, int k)
{if (NULL == root){return 0;}if (k == 1){return 1;}return TreeKLevelSize(root->leftTree, k-1) + TreeKLevelSize(root->rightTree, k-1);
}
4、树的高度
利用递归思想:
树的高度 = 左子树的高度 与 右子树的高度 的较大者 + 1
//求树的高度
int TreeHeight(BTNode* root)
{if (NULL == root){return 0;}int left_height = TreeHeight(root->leftTree);int right_heignt=TreeHeight(root->rightTree);return left_height >= right_heignt ?left_height + 1 : right_heignt + 1;
}
5、二叉树查找值为x的节点
利用递归思想:
二叉树查找值为x的节点 = 判断根节点是否是值为x的节点,不是就去左子树去找,再找不到就去右子树去找,直到找不到。
// 二叉树查找值为x的节点
BTNode* TreeFind(BTNode* root, int x)
{if (NULL == root){return NULL;}if (root->val == x){return root;}BTNode* ret1 = TreeFind(root->leftTree, x);if (ret1 != NULL){return ret1;}BTNode* ret2 = TreeFind(root->rightTree, x);if (ret2 != NULL){return ret2;}return NULL;}
五、二叉树的创建和销毁
通过前面的学习相信你对与递归解决二叉树的相关问题已经有了一定的理解,二叉树本身就是递归定义的,所以对于二叉树创建与销毁也应该是递归的。
1、二叉树的创建
给我们一个序列,通过前序遍历的数组"ABD##E#H##CF##G##"构建二叉树, 其中“#”表示的是空格,空格字符代表空树。
算法:我们可以判断二叉树的值是否应该为空,来判断要不要创建一个节点来存储相应的值,如果创建完节点,我们可以递归创建根的左子树,左子树创建完毕我们可以递归的去创建右子树,左右子树都创建完毕了,我们的树也就创建完毕了,然后我们返回根节点的地址就行了。
//这里的pi是外面的int i=0;的地址,这里必须用&,为了让每一层递归中的i不一样
BTNode* TreeCreat(char* str, int* pi)
{if(str[(*pi)] == '#'){(*pi)++;return NULL;}BTNode* root = (BTNode*)malloc(sizeof(BTNode));root->ch = str[(*pi)];(*pi)++;root->left = TreeCreat(str, pi) ;root->right = TreeCreat(str, pi);return root;
}
2、二叉树的销毁
二叉树的销毁我们最好采用后序遍历的方式,因为采用前序遍历我们会先销毁根节点,根节点被销毁了我们就很难找到左右节点了,这样就会导致内存泄漏,同理如果采用中序遍历中间销毁根就会很难找到右节点了。
算法:采用递归,要销毁一个树就先销毁这棵树的左子树,再销毁右子树,最后再销毁根。
//二叉树的销毁
void TreeDestory(BTNode* root)
{if (root == NULL){return;}TreeDestory(root->leftTree);TreeDestory(root->rightTree);free(root);//root == NULL; 可以不写,这里root只是形参,改变root不会影响外面原本的指针
}
这里的是BTNode* root,销毁完了还要在外面手动将root置空。如果我们传递BTNode** root就可以解决这个问题,你可以实现一下。
3、判断一棵树是不是完全二叉树
判断一棵树是不是完全二叉树利用递归好像并不能解决问题,但是我们遍历一棵树的方式并不是只有递归的前中后序,我们可以利用层序遍历的方式来判断一棵树是不是完全二叉树。
算法:我们可以层序遍历整个树,并将所有节点的地址都存放到队列里面(NULL也放),然后从队列里面取数据,拿到第一个NULL后判断,后面的节点是不是都是NULL,如果都是NULL说明是完全二叉树。
//判断一棵树是不是完全二叉树
bool TreeComplete(BTNode* root)
{Queue q;QueueInit(&q);if (root){QueuePush(&q, root);}while (!QueueEmpty(&q)){BTNode* front = QueueFront(&q);QueuePop(&q);//遇到NULL,跳出去进行进一步判断。if (front == NULL){break;}else{QueuePush(&q, front->leftTree);QueuePush(&q, front->rightTree);}}//判断while (!QueueEmpty(&q)){BTNode* front = QueueFront(&q);QueuePop(&q);//如果队列里面还有非NULL元素,说明非完全二叉树if (front != NULL){QueueDestory(&q);return false;}}QueueDestory(&q);return true;
}
相关文章:
【数据结构】链式二叉树
前言 在前面我们学习了一些二叉树的基本知识,了解了它的结构以及一些性质,我们还用数组来模拟二叉树建立了堆,并学习了堆排序,可是数组结构的二叉树有很大的局限性,平常我们用的最多树结构的还是链式二叉树,…...
CentOS安装RStudio-Server的方法
R语言是生信分析、数据挖掘最常用最好用的软件之一,得到了广大生信工程师、数据分析师的厚爱。Rstudio 是 R 的集成开发环境,使得R语言的用户体验更强。一般个人电脑(PC, Personal Computer)使用单机版的 Rstudio 即可,…...

从交通信号灯看流控和拥塞控制
局部的效率和全局的公平一直都是矛盾的双方。对一个统计复用系统,局部效率由流控决定,而全局公平由拥塞控制决定。 交通信号灯是个典型的分时复用流控的实例,但我经常看到绿灯方向没有任何车辆通过,红灯方向却排成了长龙…...
【LinkedList】| 深度剥析Java SE 源码合集Ⅰ
目录一. 🦁 LinkedList介绍二. 🦁 结构以及对应方法分析2.1 结构组成2.1.1 节点类2.1.2 成员变量2.2 方法实现2.2.1 添加add(E e)方法2.2.2 头尾添加元素Ⅰ addFirst(E e)Ⅱ addLast(E e)2.2.3 查找get(int index)方法2.2.4 删除remove()方法三. &#x…...
黑马程序员7
算数运算符重载 运算符重载概念:对已有的运算符重新进行定义,赋予其另一种功能,以适应不同的数据类型 加号运算符 通过自己写函数,实现两个对象相加属性后返回新的对象 两种方式重载 成员函数方式重载 全局函数重载 上来 perso…...
Qt安装与使用经验分享;无.pro文件;无QTextCodec file;Qt小试;界面居中;无缝;更换Qt图标;更换Qt标题。
1、切换安装下载源 《Qt安装教程》先推荐一篇安装文章:《Qt安装教程》 Qt 5.15 之后已经不提供离线安装包了,就是那个 3.7G 的 exe 安装包。请看官方说明,所以只能用在线安装包。 1,下载在线安装包 QT 在线安装包链接ÿ…...
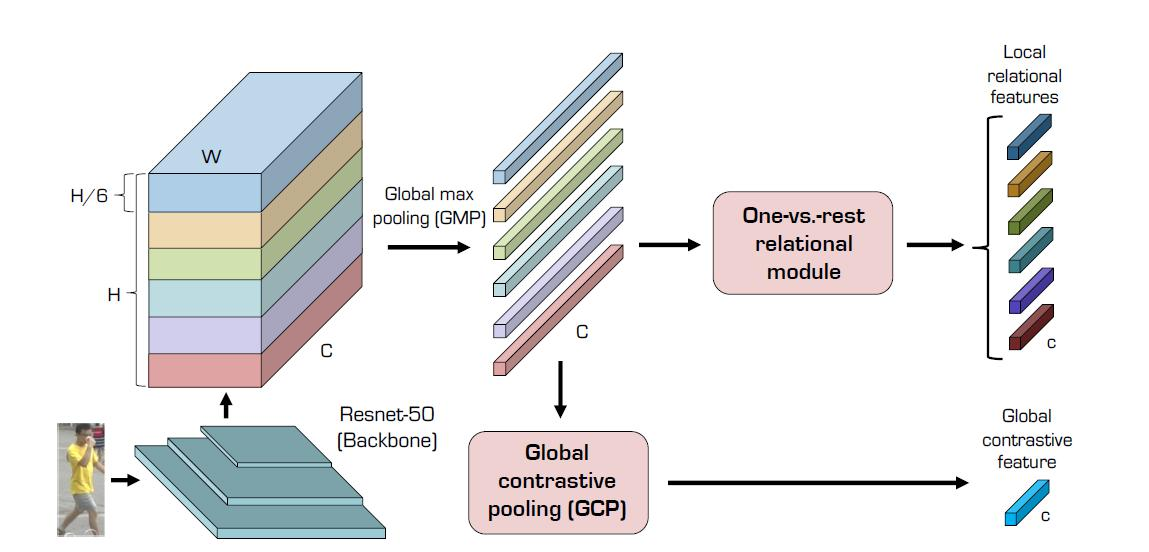
AAAI顶会行人重识别算法详解——Relation Network for Person Re-identification
1.论文整体框架概述 在行人重识别任务中,通常都是对整个输入数据进行特征提取,但是缺少了局部信息。能不能既考虑局部与整体信息,也同时加入他们的联系呢?这篇论文主要的思想就是局部信息和全局信息的融合。 整体流程如上图所示, 首先对整体进行特征提取, 通常采用…...
)
hadoop调优(二)
hadoop调优(二) 1 HDFS故障排除 1.1 NameNode故障处理 NameNode进程挂了并且存储数据丢失了,如何恢复NameNode? 如果NameNode进程挂掉并且数据丢失了,可以利用Secondary NameNode来恢复NameNode。Secondary NameNode主要用于备份NameNode…...

【基础算法】双指针---数组元素的目标和
🌹作者:云小逸 📝个人主页:云小逸的主页 📝Github:云小逸的Github 🤟motto:要敢于一个人默默的面对自己,强大自己才是核心。不要等到什么都没有了,才下定决心去做。种一颗树,最好的时间是十年前…...
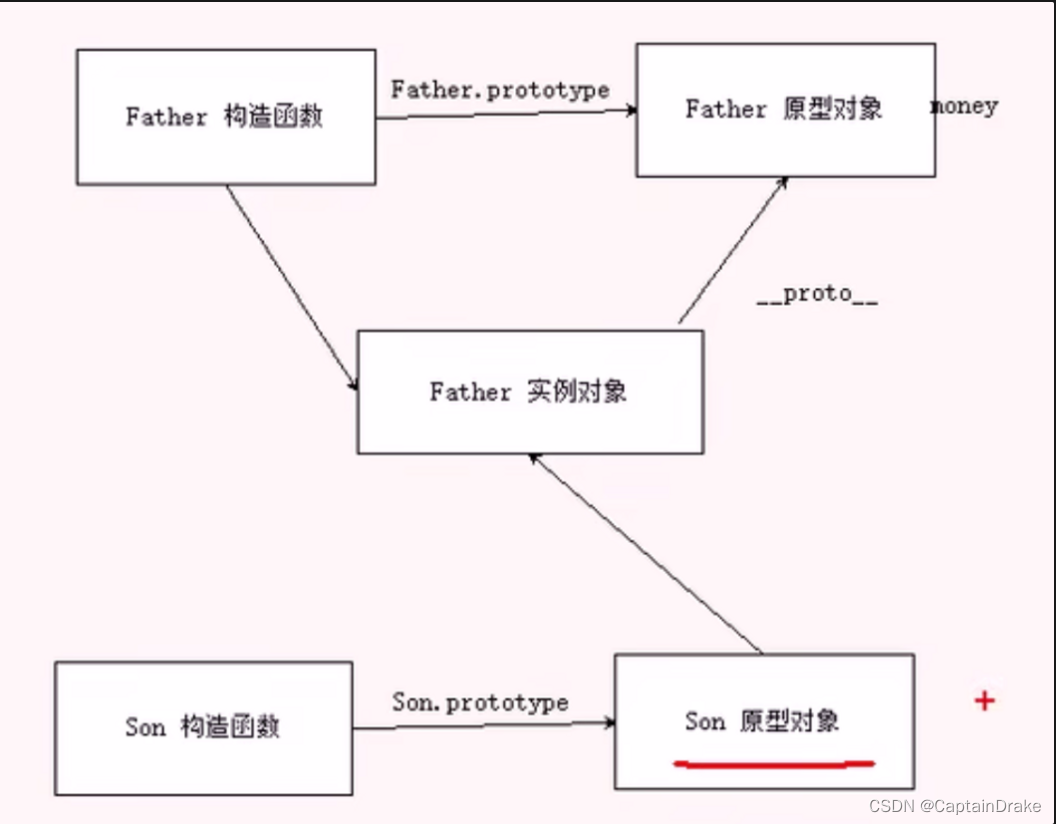
Javascript借用原型对象继承父类型方法
借用原型对象继承父类型方法 目的: 儿子继承父类属性和方法,父类之后新增的方法不会被儿子继承。 前言: 先理解一个问题: Son.prototype Father.prototype; 这一操作相当于把Son的原型对象指向Father。 意味着Son的prototype的地址与Fa…...

你不会工作1年了连枚举都还不知道吧?
💗推荐阅读文章💗 🌸JavaSE系列🌸👉1️⃣《JavaSE系列教程》🌺MySQL系列🌺👉2️⃣《MySQL系列教程》🍀JavaWeb系列🍀👉3️⃣《JavaWeb系列教程》…...
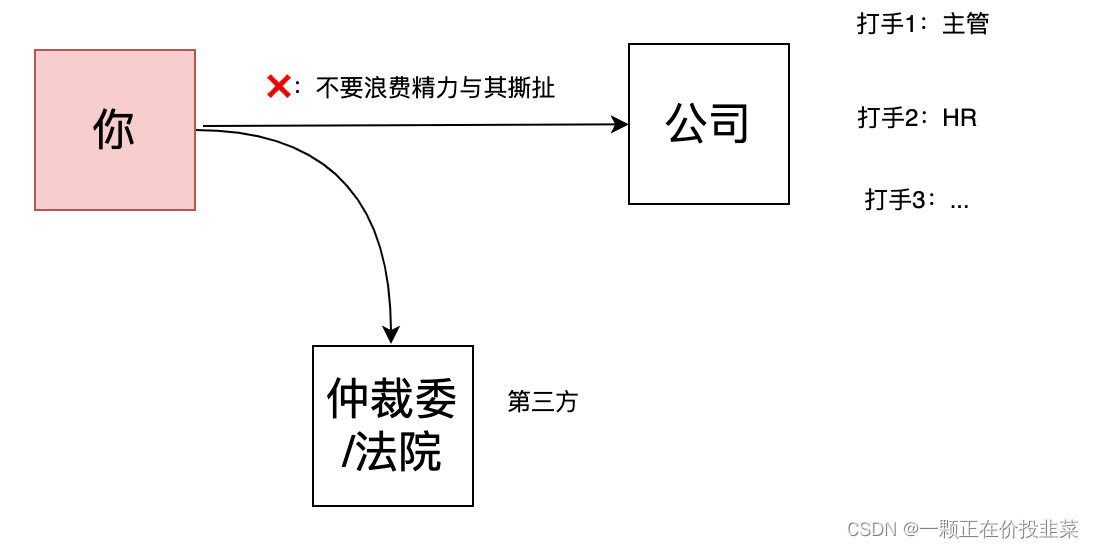
ks通过恶意低绩效来变相裁员(五)绩效申诉就是「小六自证吃了一碗凉粉」
目录 一、小六吃了一碗凉粉 二、给你差绩效 公司告诉你可以绩效申诉 1、公司的实际目的是啥 2、你一旦自证,就掉入了陷阱 三、谁主张谁举证——让公司证明它绩效考核的客观性和公平性 四、针对公司的流氓恶意绩效行为,还有其他招吗 五、当公司用各…...
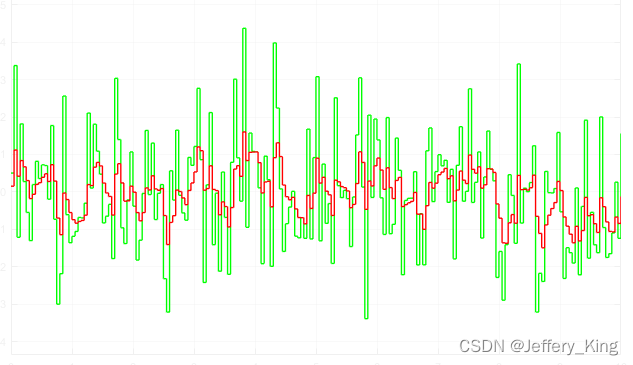
一阶低通滤波介绍及simulink模型
一阶低通滤波 背景介绍 低通滤波是一种过滤方式,规定低频信号能正常通过,而超过设定临界值的高频信号则被阻隔、减弱。低通滤波可以简单的认为:设定一个频率点,当信号频率高于这个频率时不能通过,在数字信号中&#…...

三十三、MongoDB PHP 扩展
PHP 语言访问 MongoDB 数据库需要使用 mongo 扩展 mongo 扩展不是 PHP 官方内置的扩展,需要开发者自己手动安装和配置 本章我们将学习如何在 Linux、Window、Mac 平台上安装 mongo 扩展 Linux 上安装 PHP MongoDB 扩展 通过 pecl 来安装 在 Linux 系统上可以通…...

2D图像处理:九点标定_上(机械手轴线与法兰轴线重合)(附源码)
文章目录 1. 九点标定2. 九点标定流程2.1 机械手轴线与法兰轴线重合代码实现1. 九点标定 在2D视觉抓取项目中,如果想要让机械手准确的抓取到工件,前提是需要知道机械手应该移动到哪里(位姿)。而移动到哪里(位姿)的获取就需要对相机和机械手进行标定。因此,九点标定(2D视…...
:vector内存预分配,左值引用和右值引用,move语义)
2023最新C++面经(一):vector内存预分配,左值引用和右值引用,move语义
文章目录零、前言一、在C中,往vector插入1000个数字,怎么做能保证性能最高二、在vector中对10000个数字删除偶数位置的数,怎么做保证性能较高三、malloc用delete会出现什么问题四、weak_ptr解决的是什么问题,lock返回的对象可以直接使用吗五、…...

【C语言经典例题】调整数组使奇数全部都位于偶数前面
目录 一、题目要求 二、解题思路 分步解析 从前往后找 从后往前找 交换 三、完整代码演示 一、题目要求 输入一个整数数组,实现一个函数, 来调整该数组中数字的顺序使得数组中所有的奇数位于数组的前半部分, 所有偶数位于数组的后半…...

C++经典20题型,满满知识,看这一篇就够了(含答案)
今天找了20道c的经典题型,看这一篇就够了,全是干货 目录 1、题目:有一对兔子,从出生后第3个月起每个月都生一对兔子,小兔子长到第三个月后每个月又生一对兔子,假如兔子都不死,问每个月的兔子总…...

卷积神经网络CNN之ZF Net网络模型详解(理论篇)
1.背景 2. ZF Net模型结构 3. 改进优缺点 一、背景 ZF Net是用作者的名字命名的,Matthew D.Zeiler 和 Rob Fergus (纽约大学),2013年撰写的论文; 论文原网址https://arxiv.org/abs/1311.2901 论文名:Vis…...

Vue 3.0 响应性 基础 【Vue3 从零开始】
#声明响应式状态 要为 JavaScript 对象创建响应式状态,可以使用 reactive 方法: import { reactive } from vue// 响应式状态const state reactive({count: 0}) reactive 相当于 Vue 2.x 中的 Vue.observable() API ,为避免与 RxJS 中的 ob…...

从编译错误到版本管理:C语言“商人过河”游戏代码的现代化改造之旅
1. 从古董代码到现代项目:一场技术考古与修复之旅 第一次打开那份"商人过河"的C语言游戏代码时,我仿佛穿越回了二十年前。满屏的编译错误、过时的函数调用、混乱的格式,还有那些早已被现代编译器抛弃的写法。这让我想起刚入行时接手…...

如何正确计算 CSV 文件中每行学生成绩的平均值
本文详解 python 中使用 csv 模块处理学生成绩数据时常见的累积错误,并提供结构清晰、健壮可靠的解决方案,重点解决因变量作用域不当导致的平均值计算失真问题。在使用 Python 的 csv 模块逐行读取学生成绩文件(如 "students.csv"&…...
在先进芯片制造中的关键作用与工艺优化)
电容耦合等离子刻蚀(CCP)在先进芯片制造中的关键作用与工艺优化
1. 电容耦合等离子刻蚀(CCP)技术解析 第一次接触CCP刻蚀设备时,我被它那看似简单却暗藏玄机的结构震撼到了——两块金属电极板,加上射频电源,就能实现纳米级的精密加工。这种利用电容耦合原理产生等离子体的技术&#…...

环境管理从未如此简单:Miniconda-Python3.9镜像快速入门指南
环境管理从未如此简单:Miniconda-Python3.9镜像快速入门指南 1. 为什么选择Miniconda-Python3.9镜像 Python作为当今最流行的编程语言之一,在数据科学、机器学习和Web开发等领域有着广泛应用。但Python环境管理一直是开发者面临的痛点之一,…...

英雄联盟智能游戏助手:提升游戏效率与自动化操作的全方位解决方案
英雄联盟智能游戏助手:提升游戏效率与自动化操作的全方位解决方案 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 在快节奏的英雄联…...
如何快速配置TranslucentTB:Windows任务栏美化终极教程
如何快速配置TranslucentTB:Windows任务栏美化终极教程 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 想要让Windows任务栏变…...

OFA-VE环境部署:Python 3.11+PyTorch+CUDA一站式配置手册
OFA-VE环境部署:Python 3.11PyTorchCUDA一站式配置手册 1. 引言:认识OFA-VE视觉推理系统 OFA-VE是一个基于阿里巴巴达摩院OFA大模型构建的多模态推理平台,专门用于分析图像内容与文本描述之间的逻辑关系。这个系统采用了现代化的赛博朋克视…...

《C语言学习:判断语句if-else》5
写在前面:本笔记为个人学习各平台C语言系列课程所作,仅供交流学习,不得作他用。1. if基本用法if(/*条件*/){/*做法*/ } //如果满足条件,则做大括号中的事情圆括号中是条件,或者说一个表达式。当它是0,则不执…...

FileConverter:重构文件格式转换流程,实现设计师与教育工作者的效率突破
FileConverter:重构文件格式转换流程,实现设计师与教育工作者的效率突破 【免费下载链接】FileConverter File Converter is a very simple tool which allows you to convert and compress files using the context menu in windows explorer. 项目地…...

快速体验WAN2.2文生视频:ComfyUI预置工作流,2分钟生成测试视频
快速体验WAN2.2文生视频:ComfyUI预置工作流,2分钟生成测试视频 1. 为什么选择WAN2.2文生视频工作流 如果你正在寻找一个简单易用、效果出色的文生视频工具,WAN2.2文生视频工作流绝对值得一试。这个预置在ComfyUI中的工作流,让视…...