MySQL入门
Mysql入门
- SQL语句
- SQL通用语法
- SQL语句的分类
- DDL-数据库操作
- DDL-数据表操作
- DML-添加数据
- DML-修改、删除数据
- DQL-语法
- DQL-语句练习
- DCL-语法
SQL语句
SQL通用语法
1、SQL语句可以单行或多行书写,以分号结尾。
2、SQL语句可以使用空格/缩进来增强语句的可读性。
3、MySQL数据库的SQL语句不区分大小写,关键字建议使用大小写。
4、注释:
- 单行注释:–注释内容或#注释内容(MySQL特有)
- 多行注释:/* 注释内容 */
SQL语句的分类
| 分类 | 说明 |
|---|---|
| DDL | 数据定义语言,用来定义数据库对象(数据库,表,字段) |
| DML | 数据操作语言,用来对数据库表中的数据进行增删改 |
| DQL | 数据查询语言,用来查询数据库中表的记录 |
| DCL | 数据控制语言,用来创建数据库用户,控制数据库的访问权限 |
DDL-数据库操作
- 查询
查询所有数据库
SHOW DATABASES;
查询当前数据库
SHOW DATABASE();
- 创建
CREAT DATABASE [IF NOT EXISTS] 数据库名 [DEFAULT CHARSET 字符集] [COLLATE 排序规则];
- 删除
DROP DATABASE[IF EXISTS] 数据库名;
- 使用
USE 数据库名;
DDL-数据表操作
1、查询
查询当前数据库所有表
SHOW TABLES;
查询表结构
DESC 表名;
查询指定表的建表语句
SHOW CREATE TABLE 表名;
2、创建
CREATE TABLE 表名(
字段1 字段1类型[COMMENT 字段1注释],
字段2 字段2类型[COMMENT 字段2注释],
字段3 字段3类型[COMMENT 字段3注释],
…
字段n 字段n类型[COMMENT 字段n注释] )[COMMENT 表注释];
注意:[…]为可选参数,最后一个字段后面没有逗号。
create table tb_user(id int comment '编号',name varchar(50) comment '姓名',age int comment '年龄',gender varchar(1) comment '性别'
)comment '用户表';
3、修改
- 添加字段
ALTER TABLE 表名 ADD 字段名 类型(长度) [COMMENT 注释] [约束];
例如:为emp表增加一个新的字段“昵称”为nickname,类型为varchar(20)
ALTER TABLE emp ADD nickname varchar(20) COMMENT ‘昵称’;
- 修改数据类型
ALTER TABLE 表名 MODIFY 字段名 新数据类型(长度);
- 修改字段名和字段类型
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 类型(长度) [COMMENT 注释] [约束];
- 删除字段
ALTER TABLE 表名 DROP 字段名;
- 修改表名
ALTER TABLE 表名 RENAME TO 新表名;
- 删除表
DROP TABLE[IF EXISTS] 表名;
- 删除指定表,并重新创建该表
TRUNCATE TABLE 表名;
DML-添加数据
1、给指定字段添加数据
INSERT INTO 表名 (字段名1, 字段名2,…) VALUES(值1,值2,…);
insert into employee(id, workno, name, gender, age, idcard, entrydate)
value (1,'1','Itcast','男',10,'123456789012345678','2000-01-01');
2、给全部字段添加数据
INSERT INTO 表名 VALUES(值1,值2,…);
insert into employee
value (2, '2', '张无忌', '男', '18', '123456789012345670', '2005-01-01');
3、批量添加数据
INSERT INTO 表名 (字段名1, 字段名2,…) VALUES(值1,值2,…),(值1,值2,…),(值1,值2,…);
INSERT INTO 表名 VALUES(值1,值2,…),(值1,值2,…),(值1,值2,…);
- 注意:
1、插入数据时,指定的字段顺序需要与值的顺序是一一对应的。
2、字符串和日期型数据应该包含在引号中。
3、插入的数据大小,应该在字段的规定范围内。
DML-修改、删除数据
- DML-修改数据
UPDATE 表名 SET 字段1 = 值1,字段名2 = 值2,…[WHERE 条件];
注意:修改语句的条件可以有,也可以没有,如果没有条件,则会修改整张表的所有数据。
-- 修改id为1的数据,将name修改为itheima
update employee set name = 'itheima'where id = 1;
-- 修改id为1的数据,将name修改为小昭,gender修改为女
update employee set name = '小昭', gender = '女' where id = 1;
-- 将所有的员工入职日期修改为2008-01-01
update employee set entrydate = '2008-01-01';
- DML-删除数据
DELETE FROM 表名 [WHERE 条件]
注意:
1、DELETE语句的条件可以有,也可以没有,如果没有条件,则会删除整张表的所有数据。
2、DELETE语句不能删除某一个字段的值(可以使用UPDATE)。
-- 删除gender为女的员工
delete from employee where gender = '女';
-- 删除所有员工
delete from employee;
DQL-语法
数据准备:
-- 数据准备
create table emp
(id int comment '编号',workno varchar(10) comment '工号',name varchar(10) comment '姓名',gender char comment '性别',age tinyint unsigned comment '年龄',idcard char(18) comment '身份证号',workaddress varchar(50) comment '工作地址',entrydate date comment '入职时间'
) comment '员工表';insert into emp (id, workno, name, gender, age, idcard, workaddress, entrydate)
values (1,'1','柳岩','女',20,'123456789012345678','北京','2000-01-01'),(2,'2','张无忌','男',18,'123456789012345670','北京','2005-09-01'),(3,'3','韦一笑','男',38,'123456789012345671','上海','2005-08-01'),(4,'4','赵敏','女',18,'123456789012345672','北京','2009-12-01'),(5,'5','小昭','女',16,'123456789012345673','上海','2007-07-01'),(6,'6','杨逍','男',28,'12345678901234567x','北京','2006-01-01'),(7,'7','范瑶','男',40,'123456789012345675','北京','2005-05-01'),(8,'8','黛绮丝','女',38,'123456789012345676','天津','2015-05-01'),(9,'9','范凉凉','女',45,'123456789012345677','北京','2010-04-01'),
(10,'10','陈友晾','男',53,'123456789012345679','上海','2011-01-01'),
(11,'11','张士诚','男',55,'123456789012345680','江苏','2015-05-01'),
(12,'12','常遇春','男',32,'123456789012345681','北京','2004-02-01'),
(13,'13','张三丰','男',88,'123456789012345682','江苏','2020-11-01'),
(14,'14','灭绝','女',65,'123456789012345683','西安','2019-05-01'),
(15,'15','胡青牛','男',70,'123456789012345684','西安','2018-04-01'),
(16,'16','周芷若','女',18,null,'北京','2012-06-01');
- DQL-语法
SELECT 字段列表
FROM 表名列表
WHERE 条件列表
GROUP BY 分组字段列表
HAVING 分组后条件列表
ORDER BY 排序字段列表
LIMIT 分页参数 - DQL基本查询
1、查询多个字段
SELECT 字段1,字段2,字段3…FROM 表名;
SELECT * FROM 表名;
2、设置别名
SELECT 字段1 [AS 别名1],字段2 [AS 别名2]… FROM 表名;
3、去除重复记录
SELECT DISTINCT 字段列表 FROM 表名;
- DQL-条件查询
1、语法:
SELECT 字段列表 FROM 表名 WHERE 条件列表;
-- 基本查询
-- 1.查询指定字段 name,workno,age 返回
select name,workno,age from emp;
-- 2.查询所有字段返回
select id, workno, name, gender, age, idcard, workaddress, entrydate from emp;
select * from emp;
-- 3.查询所有员工的工作地址,起别名
select workaddress as '工作地址' from emp;
select workaddress '工作地址' from emp;
-- 4.查询公司员工的上班地址(不要重复)
select distinct workaddress '工作地址' from emp;
2、条件:
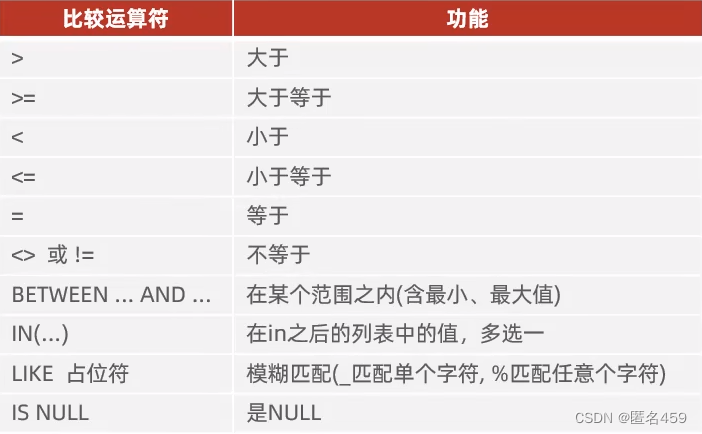
例如:
– 查询姓名为两个字的员工信息
select * from user where name like ‘__’;
– 查询密码最后一位为3的用户
select *from user where code like ‘%3’;
-- 条件查询
-- 1.查询年龄等于88的员工
select * from emp where age = 88;
-- 2.查询年龄小于20的员工信息
select * from emp where age < 20;
-- 3.查询年龄小于等于20的员工信息
select * from emp where age <= 20;
-- 4.查询没有身份证的员工信息
select * from emp where idcard is null;
-- 5.查询有身份证的员工信息
select * from emp where idcard is not null;
-- 6.查询年龄不等于88的员工信息
select * from emp where age != 88;
select * from emp where age <> 88;
-- 7.查询年龄在15岁(包含)到20岁(包含)之间的员工信息
select * from emp where age >= 15 && age <= 20;
select * from emp where age >= 15 and age <= 20;
select * from emp where age between 15 and 20;
-- 8.查询性别为女且年龄小于25岁的员工信息
select * from emp where gender = '女' and age < 25;
-- 9.查询年龄等于18或20或40的员工信息
select * from emp where age = 18 || age = 20 || age = 40;
select * from emp where age = 18 or age = 20 or age = 40;
select * from emp where age in(18,20,40);
-- 10.查询姓名为两个字的员工信息
select * from emp where name like '__';
-- 10.查询身份证号最后一位是x的员工信息
select * from emp where idcard like '%x';
select * from emp where idcard like '_________________x';
- DQL-聚合函数
1、介绍:
将一列数据作为一个整体,进行纵向计算。
2、常见聚合函数
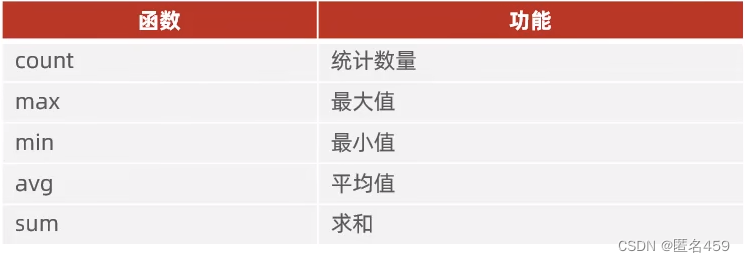
3、语法:
SELECT 聚合函数(字段列表) FROM 表名;
注意:null值不参与所有聚合函数运算
-- 聚合函数
-- 1.统计该企业员工数量
select count(*) from emp;
select count(id) from emp;
-- 2.统计该企业员工的平均年龄
select avg(age) from emp;
-- 3.统计该企业员工的最大年龄
select max(age) from emp;
-- 4.统计该企业员工的最小年龄
select min(age) from emp;
-- 5.统计西安地区的员工的年龄之和
select sum(age) from emp where workaddress = '西安';
- DQL-分组查询
1、语法:
SELECT 字段列表 FROM 表名 [WHERE 条件] GROUP BY 分组字段名 [HAVING 分组后过滤条件];
2、where与having区别
- 执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
- 判断条件不同:where不能对聚合函数进行判断,而having可以。
注意:
1、执行顺序:where > 聚合函数 > having。
2、分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义。
-- 分组查询
-- 1.根据性别分组,统计男性员工和女性员工的数量
select gender,count(*) from emp group by gender;
-- 2.根据性别分组,统计男性员工和女性员工的平均年龄
select gender,avg(age) from emp group by gender;
-- 3.查询年龄小于45的员工,并根据工作地址分组,获取员工数量大于等于3的工作地址
select workaddress,count(*) from emp where age < 45
group by workaddress having count(*) >= 3;
- DQL-排序查询
1、语法
SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式1,字段2 排序方式2;
2、排序方式
1、ASC:升序(默认值)
2、DESC:降序
注意:如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序。
-- 排序查询
-- 1.根据年龄对公司员工进行升序排序
select * from emp order by age asc;
select * from emp order by age;
-- 2.根据入职时间,对员工进行降序排序
select * from emp order by entrydate desc ;
-- 3.根据年龄对公司员工进行升序排序,年龄相同,再按照入职时间进行降序排序
select * from emp order by age asc ,entrydate desc ;
- DQL-分页查询
1、语法:
SELECT 字段列表 FROM 表名 LIMT 起始索引, 查询记录数;
2、注意:
a. 起始索引从0开始,起始索引=(查询页码-1)* 每页显示记录数。
b.分页查询数据库的方言,不同的数据库有不同的实现,MySQL中是LIMIT。
c.如果查询的是第一页数据,起始索引可以省略,直接简写为limit10。
-- 分页查询
-- 1.查询第1页员工数据,每页展示10条记录
select * from emp limit 0,10;
select * from emp limit 10;
-- 1.查询第2页员工数据,每页展示10条记录---->(页码-1)*页展示记录数
select * from emp limit 10,10;
DQL-语句练习
-- DQL语句练习
-- 1.查询年龄为20,21,22,23岁的女性员工信息
select * from emp where gender = '女' and age in(20,21,22,23);
-- 2.查询性别为男,并且年龄在20-40岁(含)以内的姓名为三个字的员工
select * from emp
where (gender = '男') and (age >= 20 and age <= 40) and (name like '___');
-- 3.统计员工表中,年龄小于60岁的,男性员工和女性员工的人数
select gender,count(*) from emp where age < 60 group by gender;
-- 4.查询所有年龄小于等于35岁员工的姓名和年龄,并对查询结果按年龄升序排序,
-- 如果年龄相同按入职时间降序排序
select name,age from emp where age <= 35 order by age asc ,entrydate desc ;
-- 5.查询性别为男,且年龄在20-40岁(含)以内的前5个员工信息,
-- 对查询的结果按年龄升序排序,年龄相同按入职时间升序排序
select * from emp where gender = '男' and agebetween 20 and 40 order by age asc,entrydate asc limit 5;
DCL-语法
- DCL-管理用户
1、查询用户
USE mysql;
SELECT * FROM user;
2、创建用户
CREATE USER ‘用户名’@‘主机名’ IDENTIFIED BY ‘密码’;
3、修改用户密码
ALTER USER ‘用户名’@‘主机名’ IDENTIFIED WITH mysql_native_password BY ‘新密码’;
4、删除用户
DROP USER ‘用户名’@‘主机名’;
注意:
1、主机名可以使用%通配。
2、这类SQL开发人员操作的比较少,主要是DBA(数据库管理员)使用。
-- 创建用户itcast,只能够在当前主机localhost访问,密码123456
create user 'itcast'@'localhost' identified by '123456';
-- 创建用户heima,可以在任意主机访问该数据库,密码123456
create user 'heima'@'%' identified by '123456';
-- 修改用户heima的访问密码为1234
alter user 'heima'@'%' identified with mysql_native_password by '1234';
-- 删除itcast@localhost用户
drop user 'itcast'@'localhost';
- DCL-权限控制
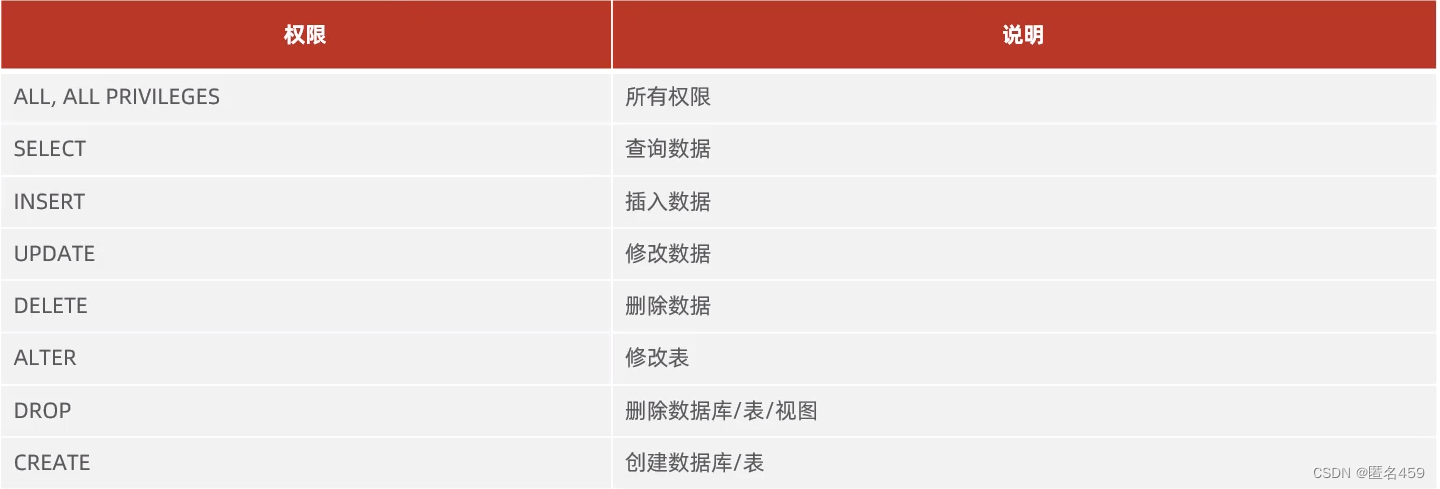
1、查询权限
SHOW GRANTS FOR ‘用户名’@‘主机名’;
2、授予权限
GRANT 权限列表 ON 数据库名.表名 TO ‘用户名’@‘主机名’;
3、撤销权限
REVOKE 权限列表 ON 数据库名.表名 FROM ‘用户名’@‘主机名’;
注意:
1、多个权限之间,使用逗号分隔。
2、授权时,数据库名和表名可以使用*进行通配,代表所有。
-- 查询权限
show grants for 'heima'@'%';
-- 授予权限
grant all on itcast.* to 'heima'@'%';
-- 撤销权限
revoke all on itcast.* from 'heima'@'%';
相关文章:
MySQL入门
Mysql入门SQL语句SQL通用语法SQL语句的分类DDL-数据库操作DDL-数据表操作DML-添加数据DML-修改、删除数据DQL-语法DQL-语句练习DCL-语法SQL语句 SQL通用语法 1、SQL语句可以单行或多行书写,以分号结尾。 2、SQL语句可以使用空格/缩进来增强语句的可读性。 3、MySQ…...

实验一 Python编程基础
目录 一、实验目标 二、实验内容 1.绘制如下图形 ,一个正方形,内有三个红点,中间红点在正方形中心。 2.使用turtle库绘制如下图形: 3.绘制奥运五环图 4.回文问题 5.身份证性别判别 6.数据压缩 7.验证哥德巴赫猜想 8.使…...
ThreadLocal介绍和理解)
java多线程(十五)ThreadLocal介绍和理解
一、对ThreadLocal的理解 ThreadLocal,很多地方叫做线程本地变量,也有些地方叫做线程本地存储,其实意思差不多。可能很多朋友都知道ThreadLocal为变量在每个线程中都创建了一个副本,那么每个线程可以访问自己内部的副本变量。这句…...
K8S 实用工具之三 - 图形化 UI Lens
开篇 📜 引言: 磨刀不误砍柴工工欲善其事必先利其器 第一篇:《K8S 实用工具之一 - 如何合并多个 kubeconfig?》第二篇:《K8S 实用工具之二 - 终端 UI K9S》 像我这种,kubectl 用的不是非常溜,经…...
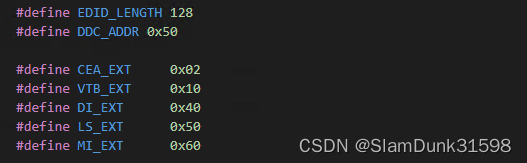
HDMI协议介绍(六)--EDID
目录 什么是EDID EDID结构 1)Header Information 头信息(厂商信息、EDID 版本等) (2)Basic Display Parameters and Features 基本显示参数(数字/模拟接口、屏幕尺寸、格式支持等) (3)色度信息 (4)Established Timings(VESA 定义的电脑使用 Timings) (5)Standard Timing…...
【项目实战】Linux下安装Nginx教程
一、环境准备 Linux版本:CentOS7 64位 二、具体步骤 2.1 步骤1:确认系统中安装以下基础依赖 确认系统中安装了gcc、pcre-devel、zlib-devel、openssl-devel。 在安装Nginx前首先要确认系统中安装了gcc、pcre-devel、zlib-devel、openssl-devel。 yu…...

【数据结构】链式二叉树
前言 在前面我们学习了一些二叉树的基本知识,了解了它的结构以及一些性质,我们还用数组来模拟二叉树建立了堆,并学习了堆排序,可是数组结构的二叉树有很大的局限性,平常我们用的最多树结构的还是链式二叉树,…...
CentOS安装RStudio-Server的方法
R语言是生信分析、数据挖掘最常用最好用的软件之一,得到了广大生信工程师、数据分析师的厚爱。Rstudio 是 R 的集成开发环境,使得R语言的用户体验更强。一般个人电脑(PC, Personal Computer)使用单机版的 Rstudio 即可,…...

从交通信号灯看流控和拥塞控制
局部的效率和全局的公平一直都是矛盾的双方。对一个统计复用系统,局部效率由流控决定,而全局公平由拥塞控制决定。 交通信号灯是个典型的分时复用流控的实例,但我经常看到绿灯方向没有任何车辆通过,红灯方向却排成了长龙…...
【LinkedList】| 深度剥析Java SE 源码合集Ⅰ
目录一. 🦁 LinkedList介绍二. 🦁 结构以及对应方法分析2.1 结构组成2.1.1 节点类2.1.2 成员变量2.2 方法实现2.2.1 添加add(E e)方法2.2.2 头尾添加元素Ⅰ addFirst(E e)Ⅱ addLast(E e)2.2.3 查找get(int index)方法2.2.4 删除remove()方法三. &#x…...
黑马程序员7
算数运算符重载 运算符重载概念:对已有的运算符重新进行定义,赋予其另一种功能,以适应不同的数据类型 加号运算符 通过自己写函数,实现两个对象相加属性后返回新的对象 两种方式重载 成员函数方式重载 全局函数重载 上来 perso…...
Qt安装与使用经验分享;无.pro文件;无QTextCodec file;Qt小试;界面居中;无缝;更换Qt图标;更换Qt标题。
1、切换安装下载源 《Qt安装教程》先推荐一篇安装文章:《Qt安装教程》 Qt 5.15 之后已经不提供离线安装包了,就是那个 3.7G 的 exe 安装包。请看官方说明,所以只能用在线安装包。 1,下载在线安装包 QT 在线安装包链接ÿ…...
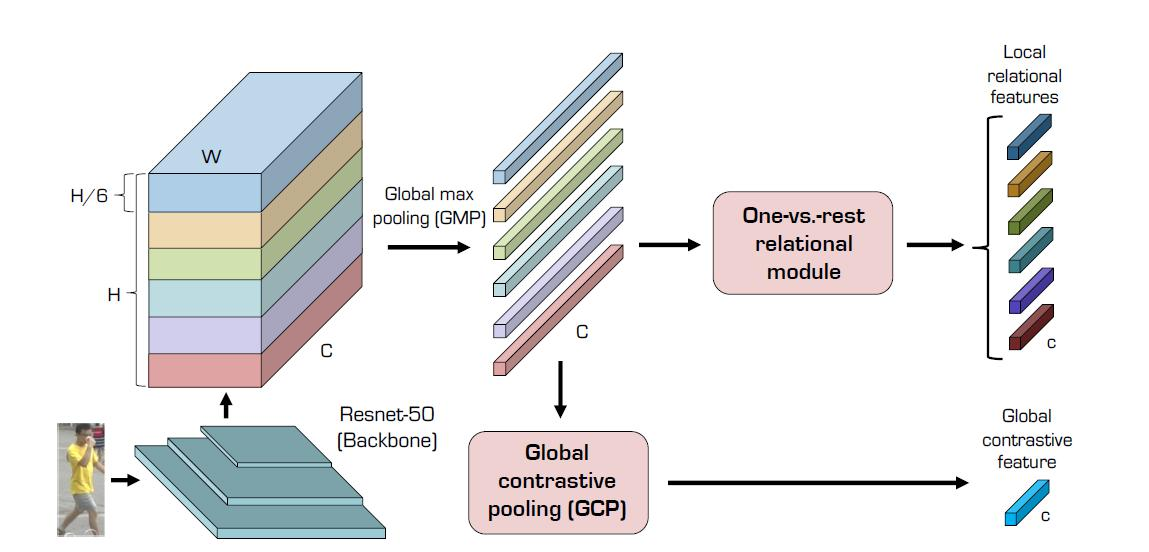
AAAI顶会行人重识别算法详解——Relation Network for Person Re-identification
1.论文整体框架概述 在行人重识别任务中,通常都是对整个输入数据进行特征提取,但是缺少了局部信息。能不能既考虑局部与整体信息,也同时加入他们的联系呢?这篇论文主要的思想就是局部信息和全局信息的融合。 整体流程如上图所示, 首先对整体进行特征提取, 通常采用…...
)
hadoop调优(二)
hadoop调优(二) 1 HDFS故障排除 1.1 NameNode故障处理 NameNode进程挂了并且存储数据丢失了,如何恢复NameNode? 如果NameNode进程挂掉并且数据丢失了,可以利用Secondary NameNode来恢复NameNode。Secondary NameNode主要用于备份NameNode…...

【基础算法】双指针---数组元素的目标和
🌹作者:云小逸 📝个人主页:云小逸的主页 📝Github:云小逸的Github 🤟motto:要敢于一个人默默的面对自己,强大自己才是核心。不要等到什么都没有了,才下定决心去做。种一颗树,最好的时间是十年前…...
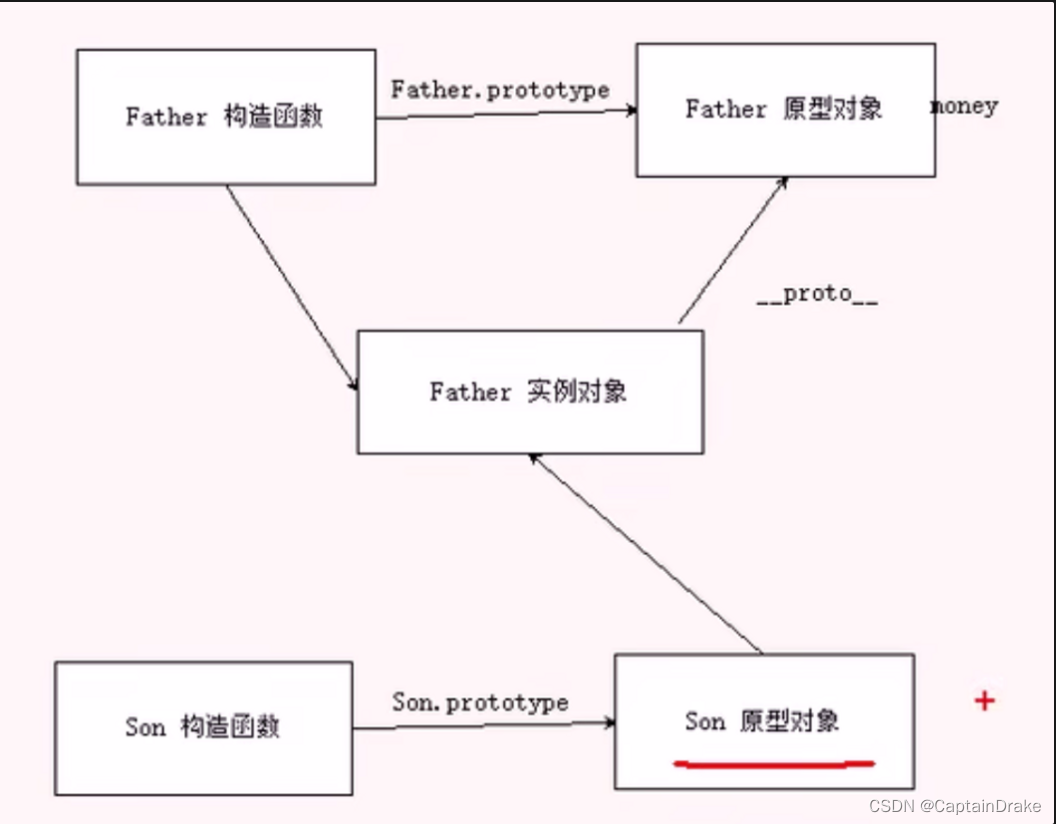
Javascript借用原型对象继承父类型方法
借用原型对象继承父类型方法 目的: 儿子继承父类属性和方法,父类之后新增的方法不会被儿子继承。 前言: 先理解一个问题: Son.prototype Father.prototype; 这一操作相当于把Son的原型对象指向Father。 意味着Son的prototype的地址与Fa…...

你不会工作1年了连枚举都还不知道吧?
💗推荐阅读文章💗 🌸JavaSE系列🌸👉1️⃣《JavaSE系列教程》🌺MySQL系列🌺👉2️⃣《MySQL系列教程》🍀JavaWeb系列🍀👉3️⃣《JavaWeb系列教程》…...
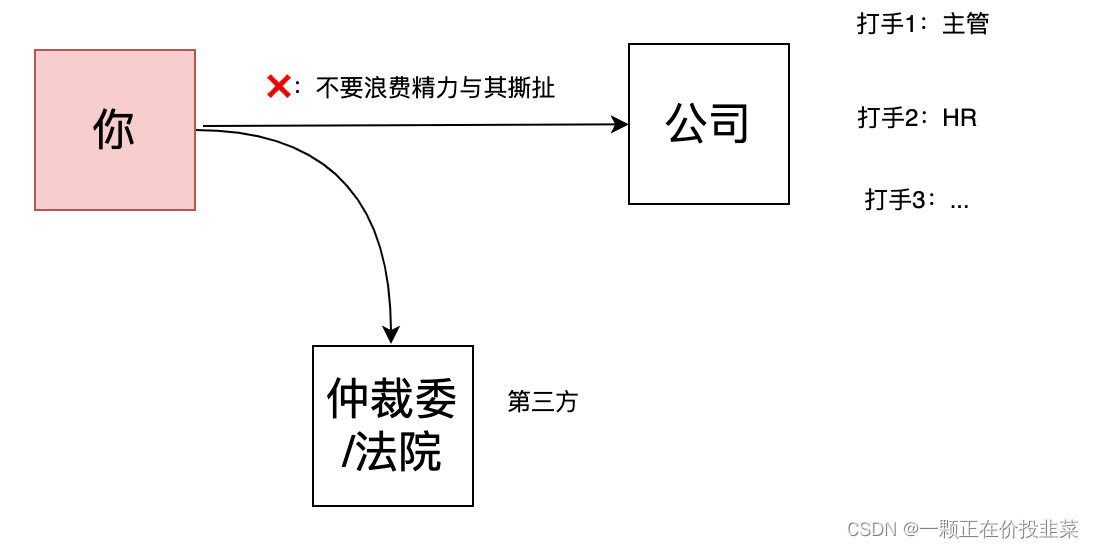
ks通过恶意低绩效来变相裁员(五)绩效申诉就是「小六自证吃了一碗凉粉」
目录 一、小六吃了一碗凉粉 二、给你差绩效 公司告诉你可以绩效申诉 1、公司的实际目的是啥 2、你一旦自证,就掉入了陷阱 三、谁主张谁举证——让公司证明它绩效考核的客观性和公平性 四、针对公司的流氓恶意绩效行为,还有其他招吗 五、当公司用各…...
一阶低通滤波介绍及simulink模型
一阶低通滤波 背景介绍 低通滤波是一种过滤方式,规定低频信号能正常通过,而超过设定临界值的高频信号则被阻隔、减弱。低通滤波可以简单的认为:设定一个频率点,当信号频率高于这个频率时不能通过,在数字信号中&#…...

三十三、MongoDB PHP 扩展
PHP 语言访问 MongoDB 数据库需要使用 mongo 扩展 mongo 扩展不是 PHP 官方内置的扩展,需要开发者自己手动安装和配置 本章我们将学习如何在 Linux、Window、Mac 平台上安装 mongo 扩展 Linux 上安装 PHP MongoDB 扩展 通过 pecl 来安装 在 Linux 系统上可以通…...

Cursor Pro完整解锁方案:一站式解决AI编程助手使用限制的终极指南
Cursor Pro完整解锁方案:一站式解决AI编程助手使用限制的终极指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reach…...
)
C语言学习笔记——2(数据类型,运算符)
数据类型机器中每个字节都有地址CPU通过地址访问字节空间#include <stdio.h>int main() {int a 0xEEAABAAA;printf("%#x, %d\n",a,a);unsigned int b 0xEEAABAAA;printf("%#x, %u\n",b,b);return 0; }运行结果:0xeeaabaaa, -290800982 …...

LangChain + AgentRun 浏览器沙箱极简集成指南
AgentRun Browser Sandbox 介绍 什么是 Browser Sandbox? Browser Sandbox 是 AgentRun 平台提供的云原生无头浏览器沙箱服务,基于阿里云函数计算(FC)构建。它为智能体提供了一个安全隔离的浏览器执行环境,支持通过标准的 Chrome DevTools Protocol (…...
)
UE5材质编辑器进阶:手把手教你创建并调用自定义ush函数库(附避坑指南)
UE5材质编辑器进阶:打造高效可复用的自定义ush函数库 在虚幻引擎5的材质创作中,重复编写相同的HLSL代码不仅效率低下,还容易引入错误。本文将带你深入理解如何创建并调用自定义ush函数库,提升材质开发的专业性和可维护性。 1. 为什…...

开源工具:IDM Activation Script彻底解决激活弹窗问题的技术方案
开源工具:IDM Activation Script彻底解决激活弹窗问题的技术方案 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script Internet Download Manager…...

Stable-Diffusion-v1-5-archive多风格生成效果:复古海报/科技感UI/手绘插画实拍
Stable Diffusion v1.5 Archive多风格生成效果:复古海报/科技感UI/手绘插画实拍 1. 模型介绍与核心能力 Stable Diffusion v1.5 Archive是经典SD1.5文生图模型的归档版本,作为AI图像生成领域的"常青树",它依然保持着强大的通用图…...

图片转PDF超简单!4个实用方法轻松搞定,新手一看就会的教程
在数字化办公场景中,图片转PDF几乎是必备的基础技能。无论是整理会议照片、整理证件扫描件,还是压缩文件传输,将多张图片合并为PDF都能大幅提升效率。本文为你介绍4种免费无损的图片转PDF方法,涵盖不同使用场景和操作需求…...

AUC 的两种等价定义:从排序概率到 ROC 曲线的统一理解
一、AUC 的本质:一个排序概率1. 问题设定假设我们面对的是一个二分类 / 排序问题:每个样本 �� 有真实标签 ��∈0,1模型给出一个连续预测分数 ��∈�分数越大,模…...

无人机飞控实战:四元数微分方程在PX4中的实现与调参技巧
无人机飞控实战:四元数微分方程在PX4中的实现与调参技巧 当无人机在复杂环境中执行高速机动时,传统欧拉角描述姿态会出现万向节锁死现象。去年调试一台行业级六旋翼时,就曾遇到俯仰角接近90时控制器突然发散的情况——这正是欧拉角奇异点的典…...
开源AI翻译新范式:Pixel Language Portal镜像免配置+GPU算力适配教程
开源AI翻译新范式:Pixel Language Portal镜像免配置GPU算力适配教程 1. 产品概览:像素语言跨维传送门 Pixel Language Portal(像素语言跨维传送门)是一款基于Tencent Hunyuan-MT-7B大模型构建的创新翻译工具。与传统翻译软件不同…...