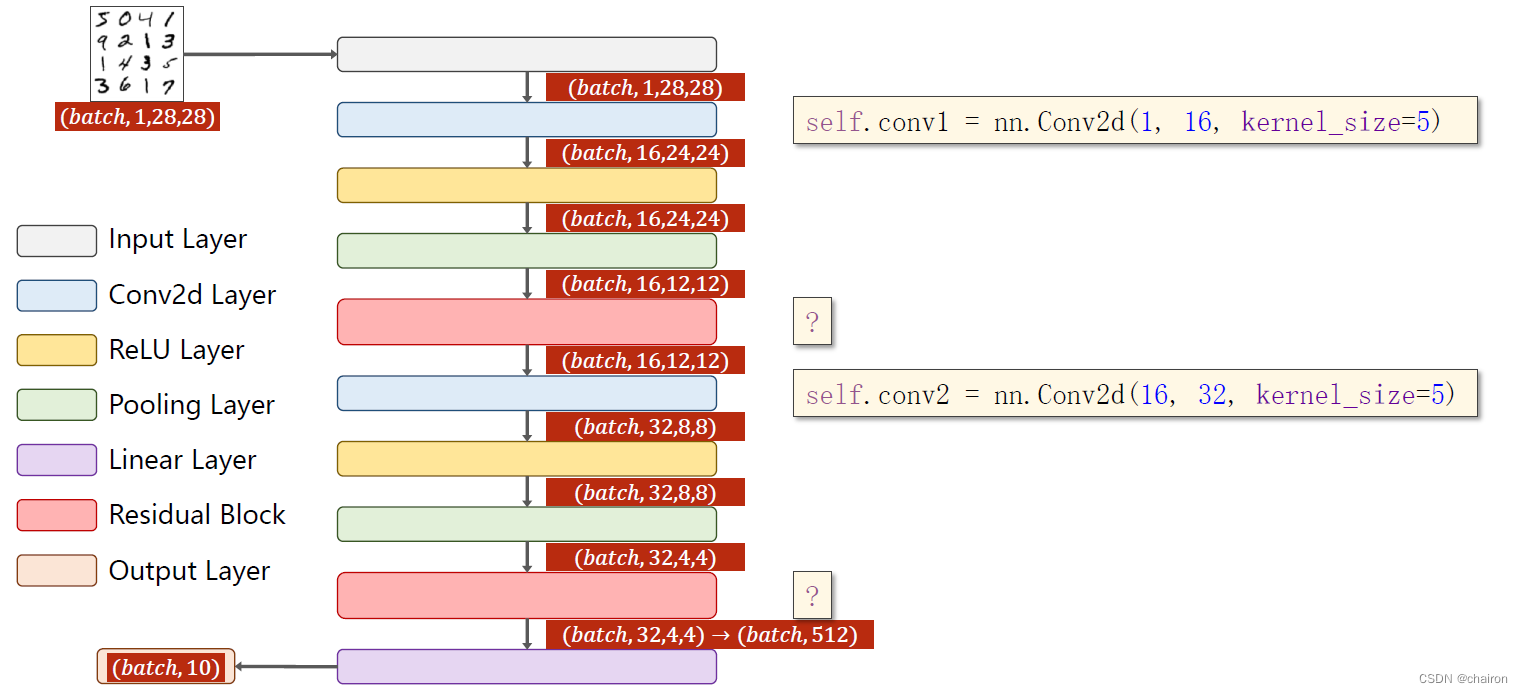
Advanced CNN
文章目录
- 回顾
- Google Net
- Inception
- 1*1卷积
- Inception模块的实现
- 网络构建
- 完整代码
- ResNet
- 残差模块 Resedual Block
- 残差网络的简单应用
- 残差实现的代码
- 练习
回顾
这是一个简单的线性的卷积神经网络
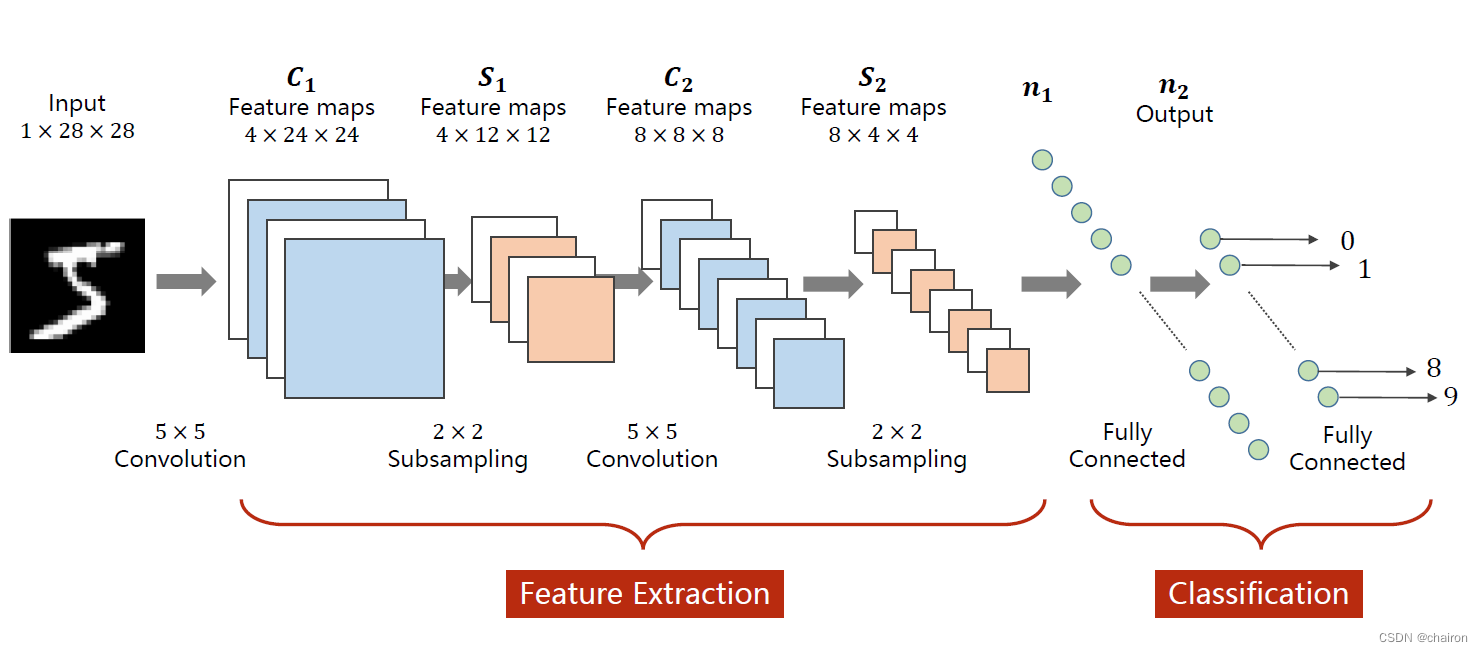
然而有很多更为复杂的卷积神经网络。
Google Net
Google Net 也叫Inception V1,是由Inception模块堆叠而成的卷积神经网络。
详情请见我的另一篇博客

Inception
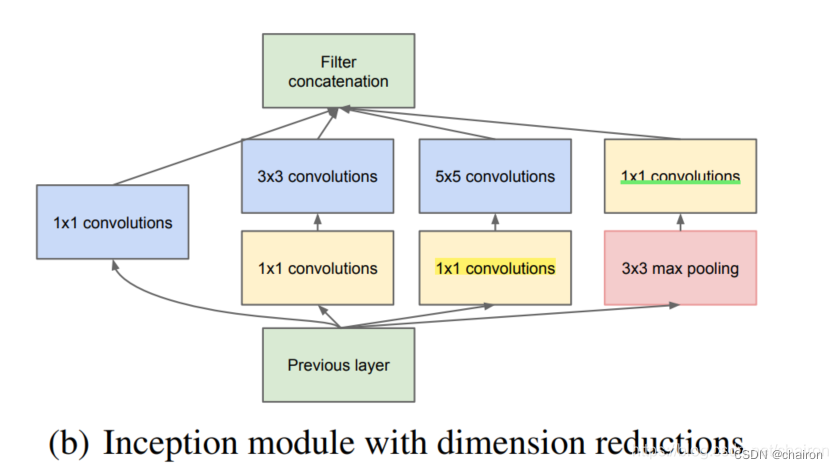
基本思想
- 首先通过1x1卷积来降低通道数把信息聚集
- 再进行不同尺度的特征提取以及池化,得到多个尺度的信息
- 最后将特征进行叠加输出
- (官方说法:可以将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能)
主要过程: - 在3x3卷积和5x5卷积前面、3x3池化后面添加1x1卷积,将信息聚集且可以有效减少参数量(称为瓶颈层);
- 下一层block就包含1x1卷积,3x3卷积,5x5卷积,3x3池化(使用这样的尺寸不是必需的,可以根据需要进行调整)。这样,网络中每一层都能学习到“稀疏”(3x3、5x5)或“不稀疏”(1x1)的特征,既增加了网络的宽度,也增加了网络对尺度的适应性;
- 通过按深度叠加(deep concat)在每个block后合成特征,获得非线性属性。
- 注:在进行卷积之后都需要进行ReLU激活,这里默认未注明。
1*1卷积
- 1*1卷积:卷积核大小为1的卷积,主要用于改变通道数,而不会改变特征图W、H。
- 也可以用于进行特征融合。
- 在执行计算昂贵的 3 x 3 卷积和 5 x 5 卷积前,往往会使用 1 x 1 卷积来减少计算量。


Inception模块的实现
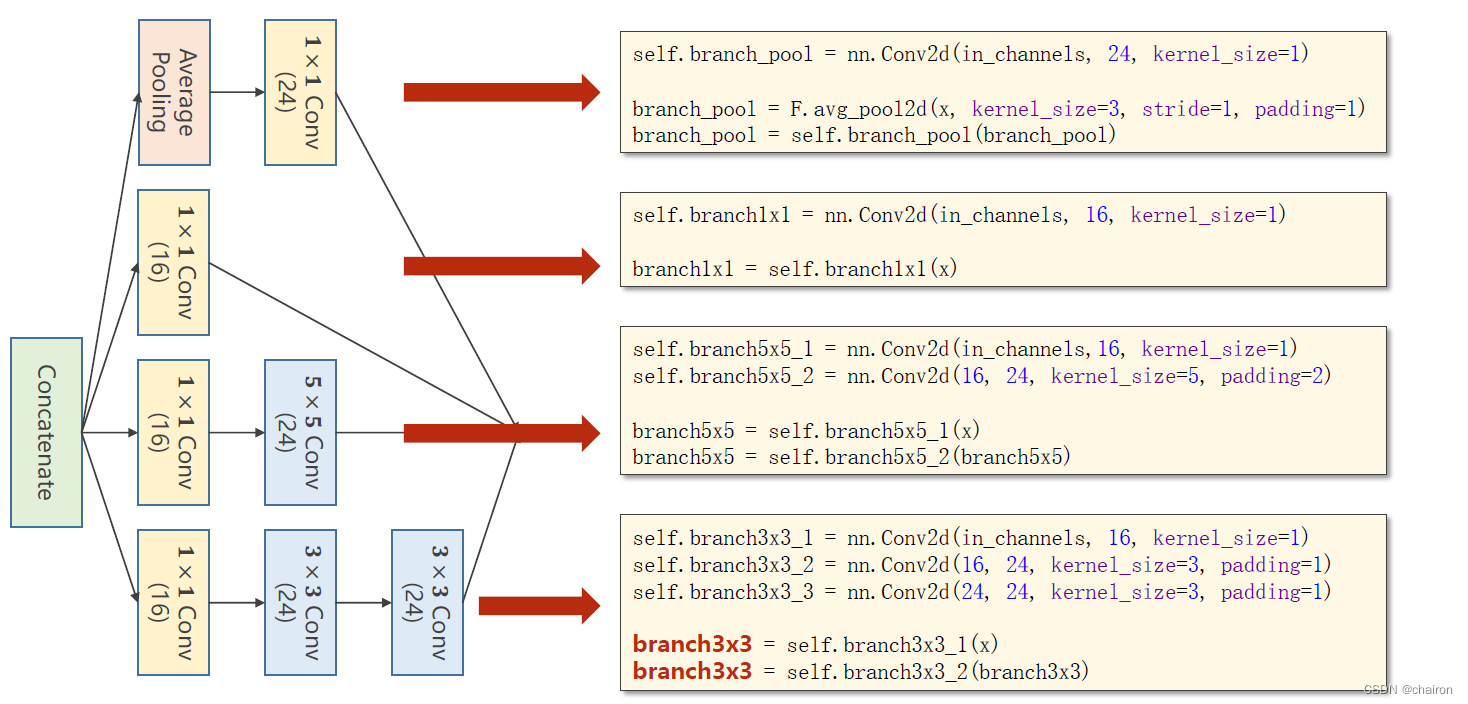
注意:只有所有特征图大小一样(W、H一样),才能进行拼接,通道数可以不同。

网络构建
# design model using class
class InceptionA(nn.Module):def __init__(self, in_channels):super(InceptionA, self).__init__()self.branch1x1 = nn.Conv2d(in_channels, 16, kernel_size=1)#1*1卷积self.branch5x5_1 = nn.Conv2d(in_channels, 16, kernel_size=1)#1*1卷积self.branch5x5_2 = nn.Conv2d(16, 24, kernel_size=5, padding=2)#padding=2,大小不变self.branch3x3_1 = nn.Conv2d(in_channels, 16, kernel_size=1)#1*1卷积self.branch3x3_2 = nn.Conv2d(16, 24, kernel_size=3, padding=1)#padding=1,大小不变self.branch3x3_3 = nn.Conv2d(24, 24, kernel_size=3, padding=1)#padding=1,大小不变self.branch_pool = nn.Conv2d(in_channels, 24, kernel_size=1)#1*1卷积def forward(self, x):branch1x1 = self.branch1x1(x)branch5x5 = self.branch5x5_1(x)branch5x5 = self.branch5x5_2(branch5x5)branch3x3 = self.branch3x3_1(x)branch3x3 = self.branch3x3_2(branch3x3)branch3x3 = self.branch3x3_3(branch3x3)branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)branch_pool = self.branch_pool(branch_pool)outputs = [branch1x1, branch5x5, branch3x3, branch_pool]return torch.cat(outputs, dim=1) # b,c,w,h c对应的是dim=1class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 10, kernel_size=5)self.incep1 = InceptionA(in_channels=10) # 与conv1 中的10对应self.conv2 = nn.Conv2d(88, 20, kernel_size=5) # 88 = 24x3 + 16self.incep2 = InceptionA(in_channels=20) # 与conv2 中的20对应self.mp = nn.MaxPool2d(2)self.fc = nn.Linear(1408, 10)#1408=88*4*4,是x展开之后的值;其实可以不用自己计算def forward(self, x):in_size = x.size(0)x = F.relu(self.mp(self.conv1(x)))#W、H=12x = self.incep1(x)x = F.relu(self.mp(self.conv2(x)))#W、H=4x = self.incep2(x)x = x.view(in_size, -1)x = self.fc(x)return x
完整代码
import numpy as np
import torch
import torch.nn as nn
from matplotlib import pyplot as plt
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim# prepare datasetbatch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) # 归一化,均值和方差train_dataset = datasets.MNIST(root='dataset', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='dataset', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)# design model using class
class InceptionA(nn.Module):def __init__(self, in_channels):super(InceptionA, self).__init__()self.branch1x1 = nn.Conv2d(in_channels, 16, kernel_size=1)#1*1卷积self.branch5x5_1 = nn.Conv2d(in_channels, 16, kernel_size=1)#1*1卷积self.branch5x5_2 = nn.Conv2d(16, 24, kernel_size=5, padding=2)#padding=2,大小不变self.branch3x3_1 = nn.Conv2d(in_channels, 16, kernel_size=1)#1*1卷积self.branch3x3_2 = nn.Conv2d(16, 24, kernel_size=3, padding=1)#padding=1,大小不变self.branch3x3_3 = nn.Conv2d(24, 24, kernel_size=3, padding=1)#padding=1,大小不变self.branch_pool = nn.Conv2d(in_channels, 24, kernel_size=1)#1*1卷积def forward(self, x):branch1x1 = self.branch1x1(x)branch5x5 = self.branch5x5_1(x)branch5x5 = self.branch5x5_2(branch5x5)branch3x3 = self.branch3x3_1(x)branch3x3 = self.branch3x3_2(branch3x3)branch3x3 = self.branch3x3_3(branch3x3)branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)branch_pool = self.branch_pool(branch_pool)outputs = [branch1x1, branch5x5, branch3x3, branch_pool]return torch.cat(outputs, dim=1) # b,c,w,h c对应的是dim=1class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 10, kernel_size=5)self.incep1 = InceptionA(in_channels=10) # 与conv1 中的10对应self.conv2 = nn.Conv2d(88, 20, kernel_size=5) # 88 = 24x3 + 16self.incep2 = InceptionA(in_channels=20) # 与conv2 中的20对应self.mp = nn.MaxPool2d(2)self.fc = nn.Linear(1408, 10)#1408=88*4*4,是x展开之后的值;其实可以不用自己计算def forward(self, x):in_size = x.size(0)x = F.relu(self.mp(self.conv1(x)))#W、H=12x = self.incep1(x)x = F.relu(self.mp(self.conv2(x)))#W、H=4x = self.incep2(x)x = x.view(in_size, -1)x = self.fc(x)return xmodel = Net()device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#定义device,如果有GPU就用GPU,否则用CPUmodel.to(device)
# 将所有模型的parameters and buffers转化为CUDA Tensor.criterion=torch.nn.CrossEntropyLoss()
optimizer=torch.optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
def train(epoch):running_loss=0.0for batch_id,data in enumerate(train_loader,0):inputs,target=datainputs,target=inputs.to(device),target.to(device)#将数据送到GPU上optimizer.zero_grad()# forward + backward + updateoutputs=model(inputs)loss=criterion(outputs,target)loss.backward()optimizer.step()running_loss +=loss.item()if batch_id% 300==299:print('[%d,%5d] loss: %.3f' % (epoch+1,batch_id,running_loss/300))running_loss=0.0accracy = []
def test():correct=0total=0with torch.no_grad():for data in test_loader:inputs,target=datainputs,target=inputs.to(device),target.to(device)#将数据送到GPU上outputs=model(inputs)predicted=torch.argmax(outputs.data,dim=1)total+=target.size(0)correct+=(predicted==target).sum().item()print('Accuracy on test set : %d %% [%d/%d]'%(100*correct/total,correct,total))accracy.append([100*correct/total])if __name__ == '__main__':for epoch in range(10):train(epoch)test()x=np.arange(10)plt.plot(x, accracy)plt.xlabel("Epoch")plt.ylabel("Accuracy")plt.grid()plt.show()训练结果:
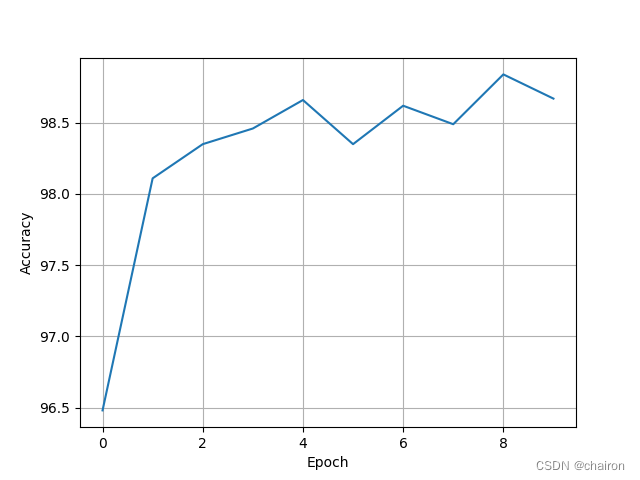
ResNet
卷积层是不是越多越好?
- 在CIFAR数据集上利用20层卷积和56层卷积进行训练,56层卷积的loss还要大一些。
- 这是因为网络层数太多,可能会出现梯度消失和梯度爆炸。
- 梯度消失和梯度爆炸:是在反向传播计算梯度时,梯度太小或者太大,随着网络层数不断加深,梯度值是呈现指数增长,变得趋近于0或者很大。比如说 0. 4 n 0.4^n 0.4n,n=100时,值就已结很小了;比如说 1. 5 n 1.5^n 1.5n,n=100时也非常大了。

残差模块 Resedual Block
**残差连接:
- **很简单!就是一个跳连接,将输入X和卷积之后的特征图相加就行了,即y=x+f(x)。
- 相加需要两个特征图的大小和通道数都一样。
- 可以获得更丰富的语义特征,避免梯度消失和爆炸。
- 非常常用!!!是必须学会的一个小技巧。


残差连接,可以跨层进行跳连接!发挥创造力炼丹吧!

残差网络的简单应用
残差实现的代码

class ResidualBlock(torch.nn.Module):def __init__(self,channels):super(ResidualBlock,self).__init__()self.channels=channelsself.conv1=torch.nn.Conv2d(channels,channels,kernel_size=3,padding=1)#保证输出输入通道数都一样self.conv2=torch.nn.Conv2d(channels,channels,kernel_size=3,padding=1)self.conv3=torch.nn.Conv2d(channels,channels,kernel_size=1)def forward(self,x):y=F.relu(self.conv1(x))y=self.conv2(y)return F.relu(x+y)
接下来,笔交给你了!

我的训练结果:
Accuracy on test set : 98 % [9872/10000]
[7, 299] loss: 0.027
[7, 599] loss: 0.032
[7, 899] loss: 0.032
Accuracy on test set : 98 % [9874/10000]
[8, 299] loss: 0.028
[8, 599] loss: 0.026
[8, 899] loss: 0.026
Accuracy on test set : 99 % [9901/10000]
[9, 299] loss: 0.022
[9, 599] loss: 0.025
[9, 899] loss: 0.027
Accuracy on test set : 99 % [9900/10000]
[10, 299] loss: 0.024
[10, 599] loss: 0.019
[10, 899] loss: 0.027
Accuracy on test set : 98 % [9895/10000]
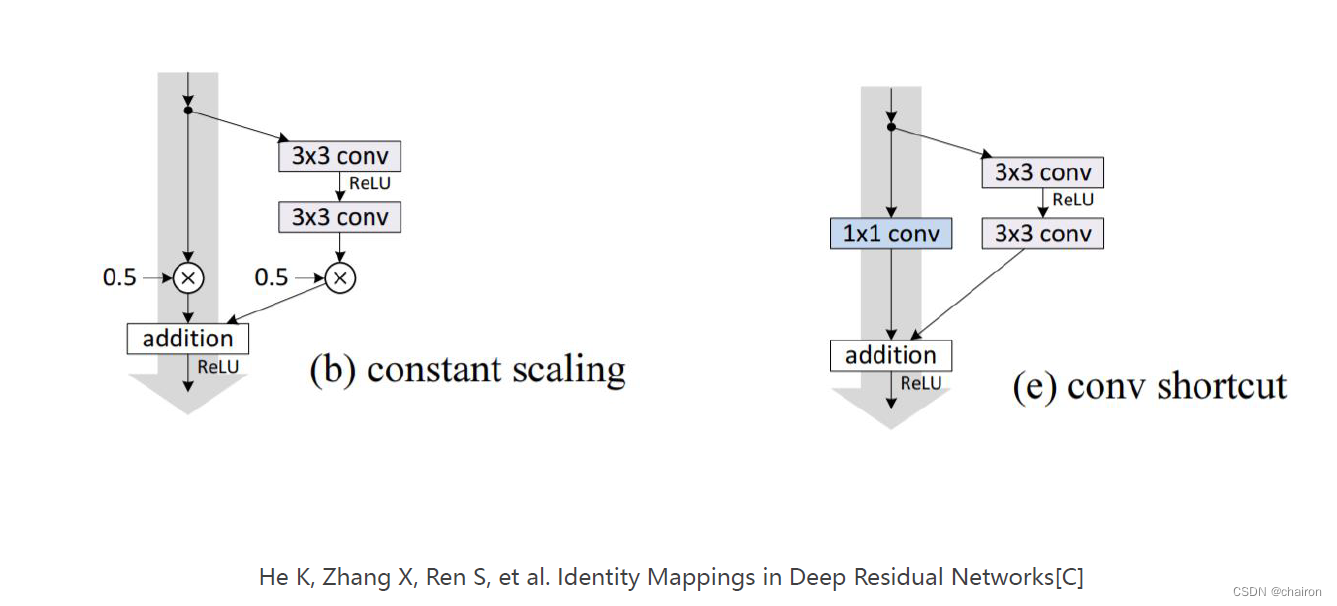
练习
请实现以下两种残差结构,并用他们构建网络跑模型。
相关文章:
Advanced CNN
文章目录 回顾Google NetInception1*1卷积Inception模块的实现网络构建完整代码 ResNet残差模块 Resedual Block残差网络的简单应用残差实现的代码 练习 回顾 这是一个简单的线性的卷积神经网络 然而有很多更为复杂的卷积神经网络。 Google Net Google Net 也叫Inception V…...
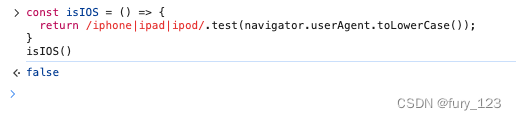
判断当前设备是不是安卓或者IOS?
代码(重要点): 当前文件要是 xxx.js文件,就需要写好代码后调用才会执行: // 判断是不是安卓 const isAndroid () > {return /android/.test(navigator.userAgent.toLowerCase()); }// 判断是不是ios const isIOS () > {return /iphone|ipad|ipod/.test(navigator.use…...

使用C++操作Matlab中的mat文件
matlab提供读写MAT文件的头文件和库函数,下面列出这些文件的路径,其中matlabroot指matlab安装的路径,arch来识别平台架构 头文件在matlabroot\extern\include库函数在matlabroot\bin\win64例程在matlabroot\extern\examples\eng_mat头文件 …...

【OCPP】ocpp1.6协议第3.5章节:本地授权和离线行为-介绍及翻译
目录 3.5章节 概述 3.5 本地鉴权和离线行为-译文(Local Authorization & Offline Behavior) 3.5.1 鉴权缓存-译文(3.5.1. Authorization Cache) 3.5.2 本地鉴权列表-译文(Local Authorization List) 3.5.3 授权缓存和本地授权列表之间的关系-译文(Relation between A…...

OpenGL查询对象 Query Objects
查询对象和异步查询(Query Objects and Asynchronous Queries) Query Objects(查询对象)是OpenGL中的一种机制,用于获取有关一系列GL命令处理过程的信息。这些信息可以包括: 绘图命令处理的图元数量。写入变换反馈缓冲区的图元数…...

【数据分享】1929-2023年全球站点的逐日最高气温数据(Shp\Excel\免费获取)
气象数据是在各项研究中都经常使用的数据,气象指标包括气温、风速、降水、湿度等指标,其中又以气温指标最为常用!说到气温数据,最详细的气温数据是具体到气象监测站点的气温数据! 之前我们分享过1929-2023年全球气象站…...
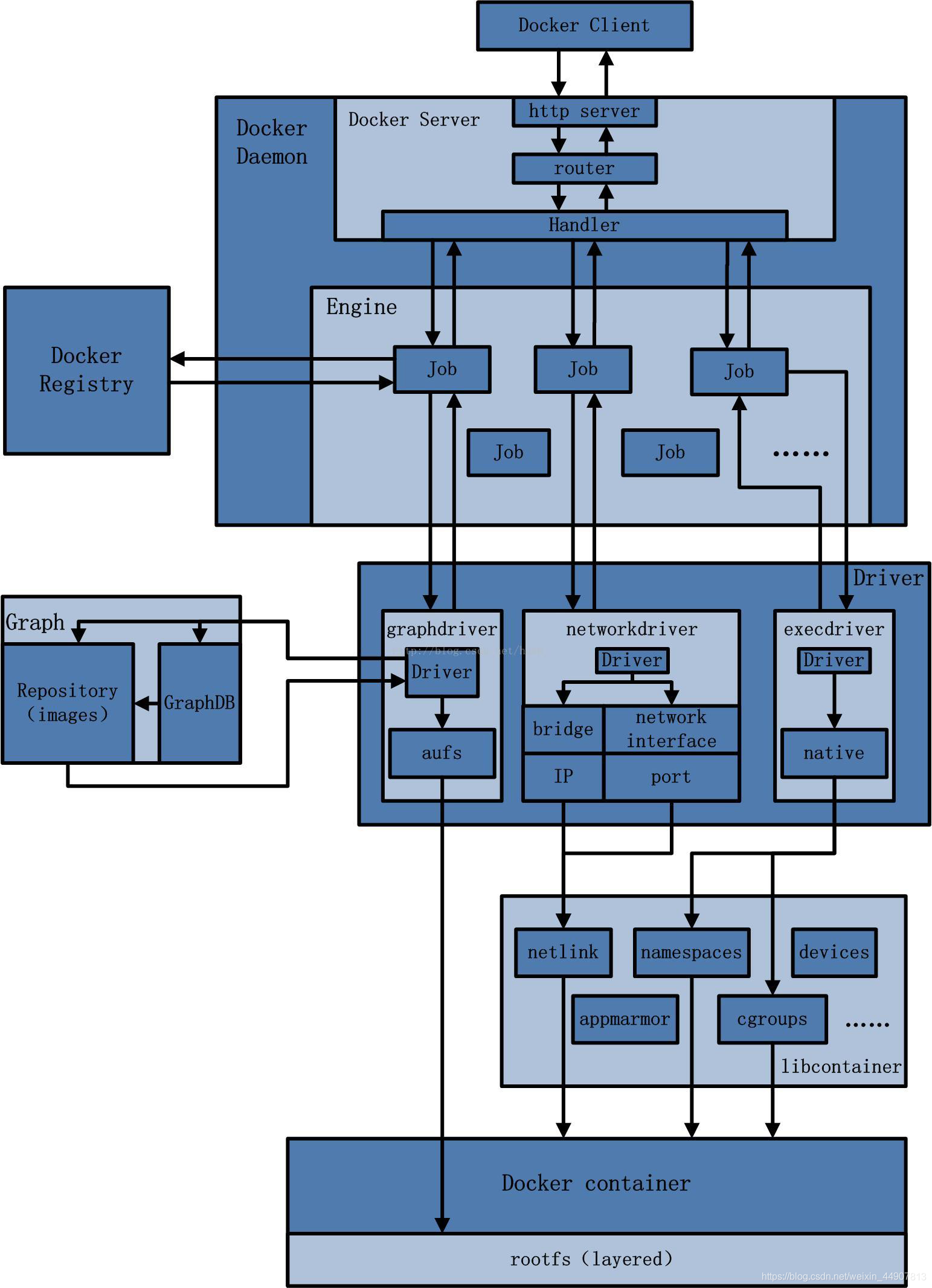
Docker深入解析:从基础到实践
Docker基础知识 Docker是什么:定义和核心概念解释 Docker是一个开源项目,它诞生于2013年,旨在自动化应用程序的部署过程, 让应用程序能够在轻量级的、可移植的、自给自足的容器中运行。这些容器可以在几乎任何机器上运行…...
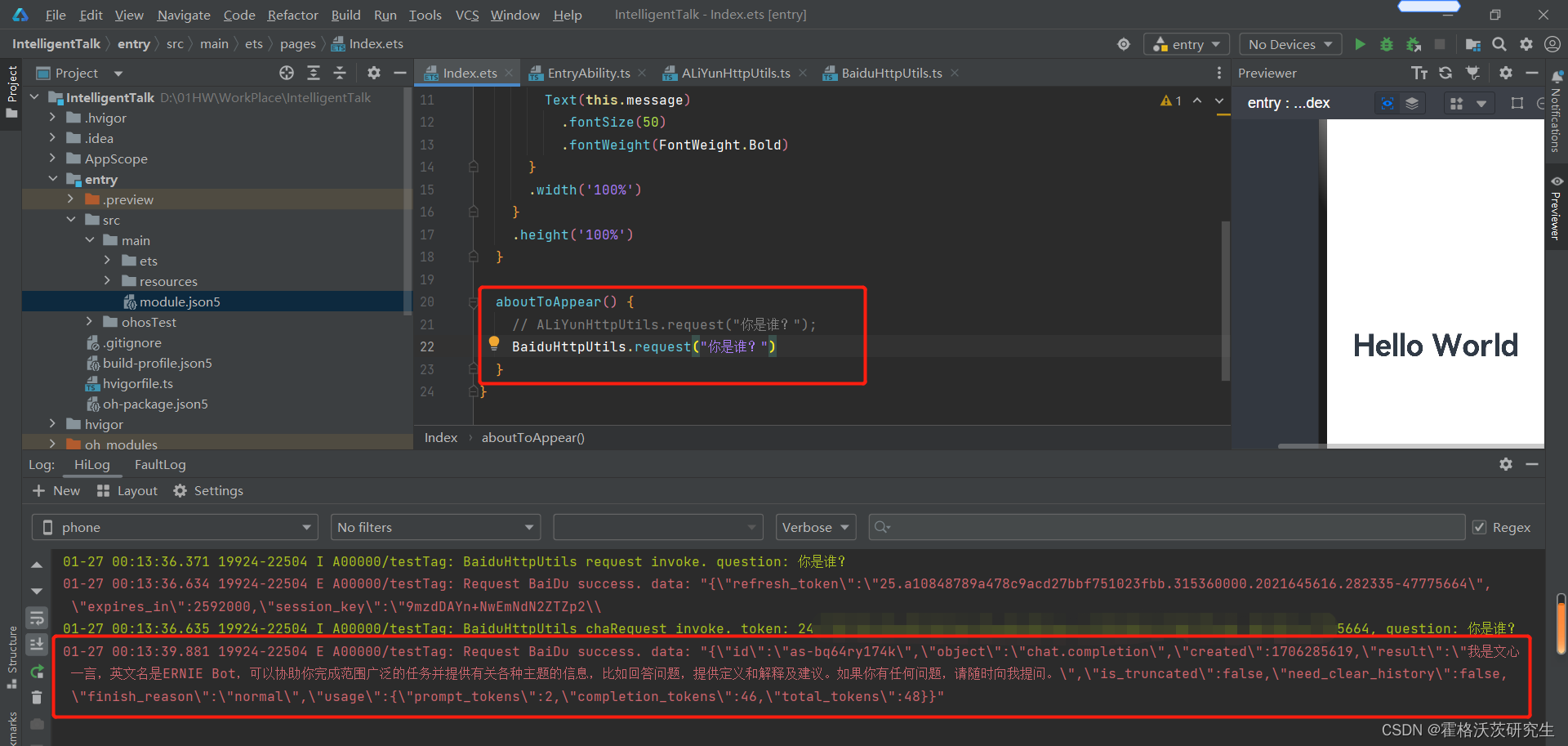
【鸿蒙】大模型对话应用(一):大模型接口对接与调试
Demo介绍 本demo对接阿里云和百度的大模型API,实现一个简单的对话应用。 DecEco Studio版本:DevEco Studio 3.1.1 Release HarmonyOS API版本:API9 关键点:ArkTS、ArkUI、UIAbility、网络http请求、列表布局 官方接口文档 此…...

SQL的函数类型
目录 一、聚合函数 二、数值型函数 三、字符串函数 四、日期函数 五、流程控制函数 一、聚合函数 定义:聚合函数是指对一组值进行运算,最终返回是单个值,也可以被称为组合函数。 COUNT() 统计目标行数量的函数 AVG() 求平均值 SU…...
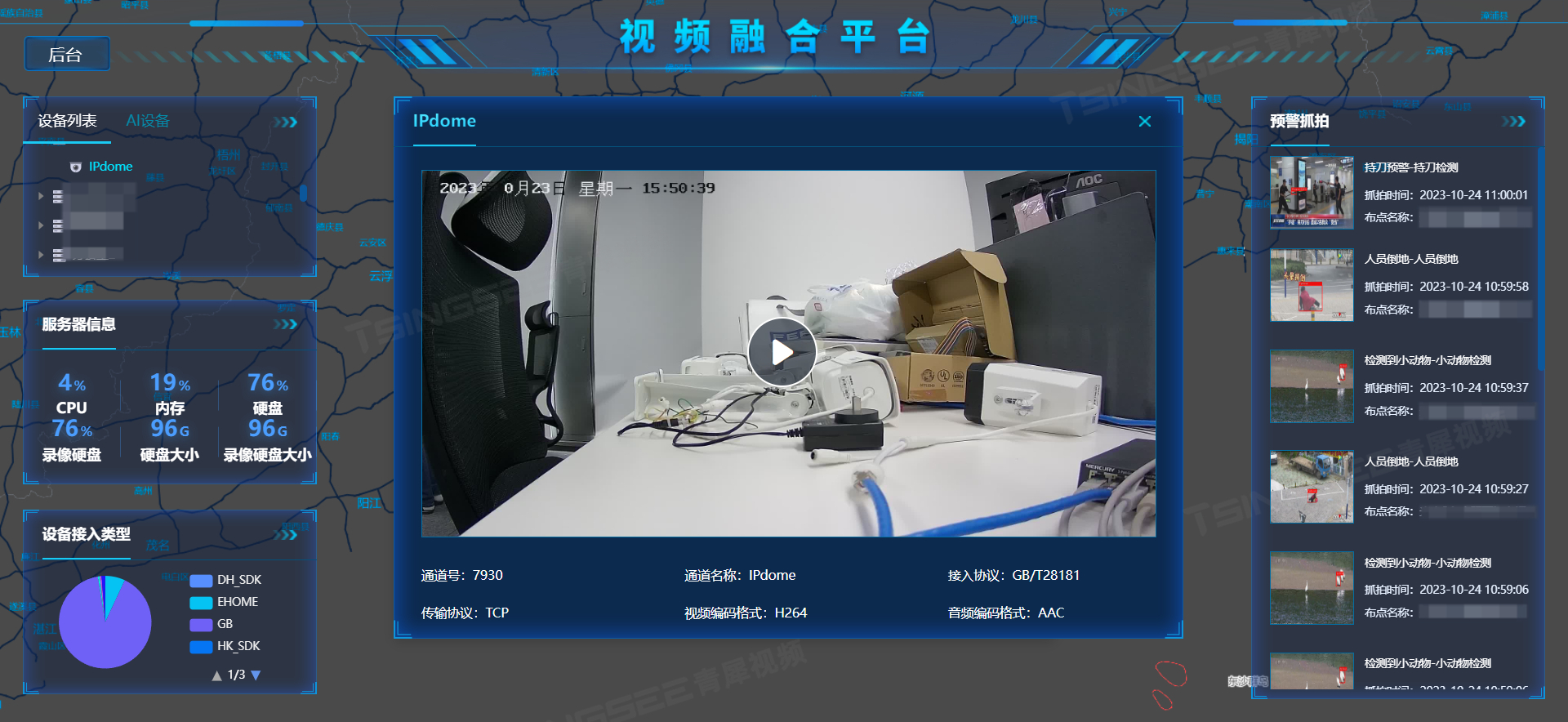
TSINGSEE青犀视频智慧电梯管理平台,执行精准管理、提升乘梯安全
一、方案背景 随着城市化进程的不断加快,我国已经成为全球最大的电梯生产和消费市场,电梯也成为人们日常生活中不可或缺的一部分。随着电梯数量的激增,电梯老龄化,维保数据不透明,物业管理成本高,政府监管…...

VMware:在部分链上无法执行所调用的函数,请打开父虚拟磁
VMware:在部分链上无法执行所调用的函数,请打开父虚拟磁 问题:VMware给虚拟机扩展硬盘容量,提示:在部分链上无法执行所调用的函数,请打开父虚拟磁。原因:是因为你的虚拟磁盘文件是分多个文件存储的…...
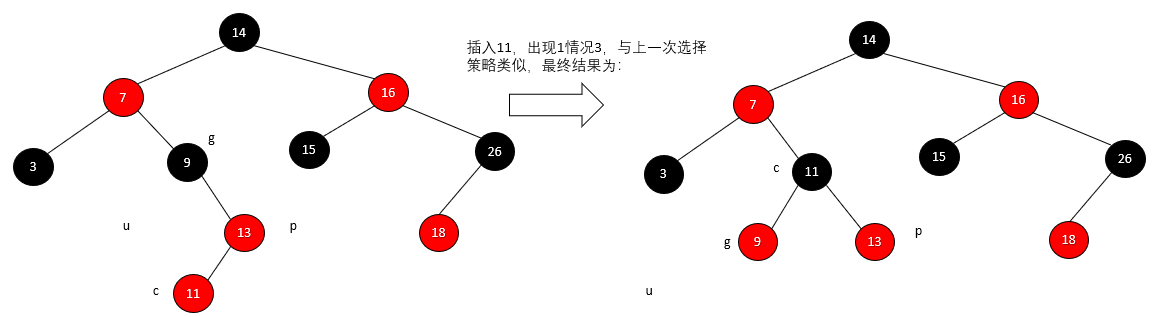
【数据结构 08】红黑树
一、概述 红黑树,是一种二叉搜索树,每一个节点上有一个存储位表示节点的颜色,可以是Red或Black。 通过对任何一条从根到叶子的路径上各个节点着色方式的限制,红黑树确保没有一条路径会比其他路径长上两倍,因而是接进…...
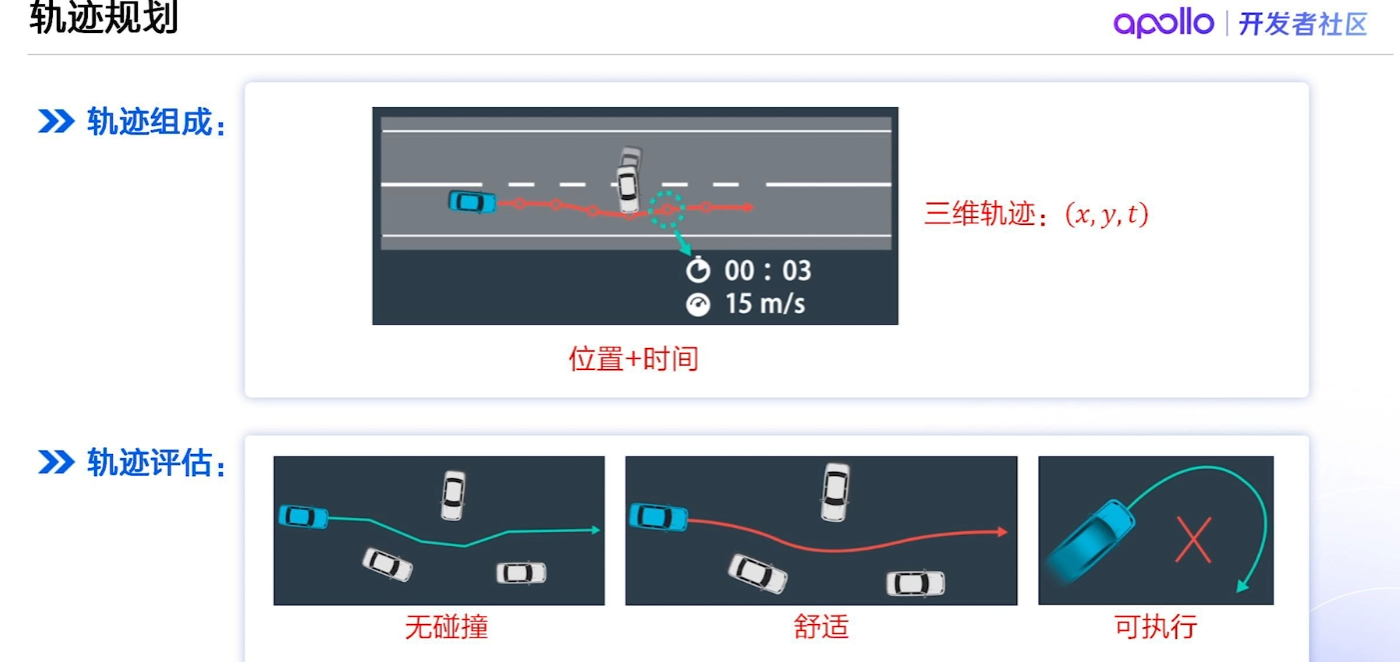
【百度Apollo】自动驾驶规划技术:实现安全高效的智能驾驶
🎬 鸽芷咕:个人主页 🔥 个人专栏:《linux深造日志》《粉丝福利》 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下…...

《C程序设计》上机实验报告(五)之一维数组二维数组与字符数组
实验内容: 1.运行程序 #include <stdio.h> void main( ) { int i,j,iRow0,iCol0,m; int x[3][4]{{1,11,22,33},{2,28,98,38},{3,85,20,89}}; mx[0][0]; for(i0;i<3;i) for(j0;j<4;j) if (x[i][j]>m) { mx[i][j]; iRowi…...

【BUG】联想Y7000电池电量为0且无法充电解决方案汇总
因为最近火灾很多,所以昨天夜晚睡觉的时候把插线板电源关掉了,电脑也关机了。 各位一定要注意用电安全,网上的那些事情看着真的很难受qvq。 第二天早上起床的时候一看发现电脑直接没电了,插上电源后也是显示 你一定要冲进去啊(ू˃…...

centos7常用命令之安装插件2
centos7安装插件1 7、kibana 【启动kibana,需要调整这个配置文件(/opt/kibana-6.3.0/config/kibana.yml)的一处ip地址,因为每次虚拟机的ip地址可能会有所不同, 同时访问页面地址的ip:5601时,ip地址也对应修改】 1.解压缩包 cd /opt/ tar -xvf kibana-6.3.0-linux-x…...
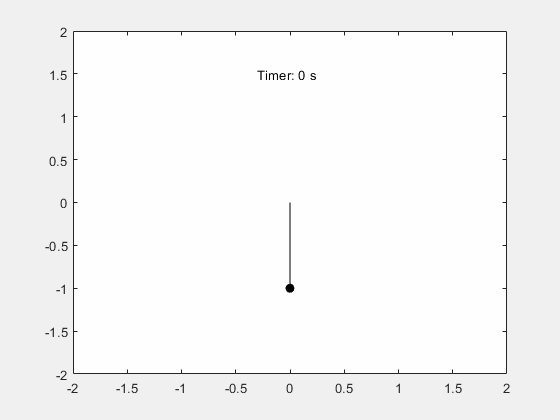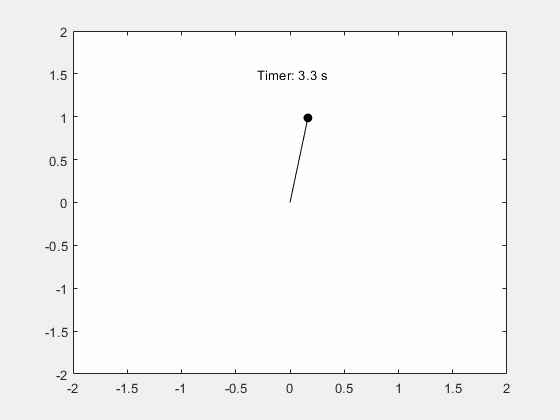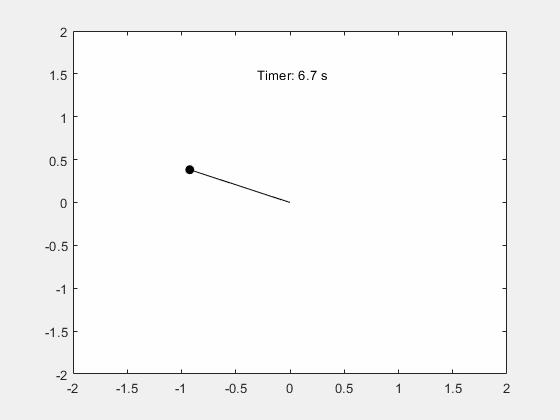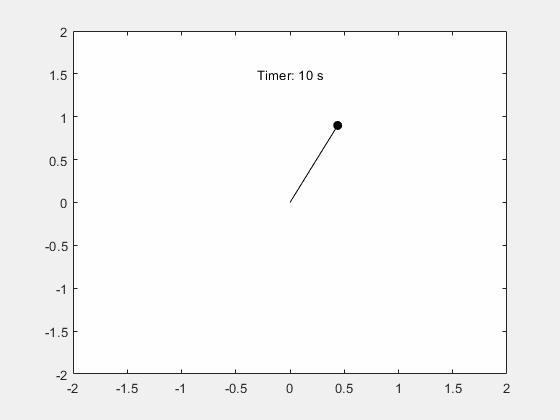
MATLAB - 仿真单摆的周期性摆动
系列文章目录 前言 本例演示如何使用 Symbolic Math Toolbox™ 模拟单摆的运动。推导摆的运动方程,然后对小角度进行分析求解,对任意角度进行数值求解。 一、步骤 1:推导运动方程 摆是一个遵循微分方程的简单机械系统。摆最初静止在垂直位置…...
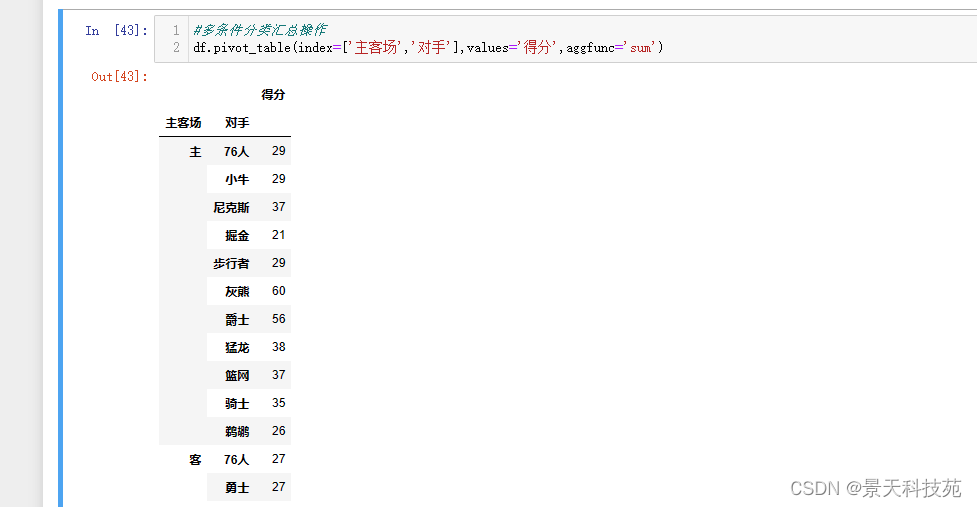
Pandas进阶--map映射,分组聚合和透视pivot_table详解
文章目录 1.Pandas的map映射(1)映射(2)map充当运算工具 2.数据分组和透视(1)分组统计 - groupby功能 是pandas最重要的功能(2)聚合agg 3.透视表pivot_table(1)…...

Visual Studio 和Clion配置Cocos2d-x环境
Visual Studio 和Clion配置Cocos2d-x环境 我就不贴图片的,懒得上传图床。懒。开发环境: 系统: Window11 编译器: CMake MSVC 开发工具:Clion or Visual Studio 请自行配置好,Python2.7,和Cmake Cocos2d-x下载…...
【百度Apollo】本地调试仿真:加速自动驾驶系统开发的利器
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《linux深造日志》《粉丝福利》 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下…...

量子计算入门:从量子比特到量子退火的核心原理与实践
1. 项目概述:推开量子世界的大门最近几年,量子计算这个词的热度是越来越高,从科技新闻到投资风口,似乎无处不在。但说实话,很多朋友一听到“量子叠加”、“量子纠缠”这些词,第一反应可能就是“不明觉厉”&…...

Proxifier+Charles实现Windows桌面程序HTTPS抓包
1. 为什么单靠Charles抓不到某些exe的HTTPS流量?你有没有遇到过这种情况:装好Charles、配好系统代理、证书也信任了,浏览器和大部分App的HTTPS请求都能清清楚楚看到明文,可偏偏某个本地运行的.exe程序——比如某款桌面版网盘客户端…...

MQTTClient技术深度解析:嵌入式物联网通信的高性能解决方案
MQTTClient技术深度解析:嵌入式物联网通信的高性能解决方案 【免费下载链接】mqttclient A high-performance, high-stability, cross-platform MQTT client, developed based on the socket API, can be used on embedded devices (FreeRTOS / LiteOS / RT-Thread …...
-更高级训练,如何把大规模知识“刻”入模型)
大模型训练师的炼丹之道 (3)-更高级训练,如何把大规模知识“刻”入模型
前言 在《炼丹之道》前两篇中,我们完成了从基础认知到身份重塑的入门仪式——当模型脱口而出“我是威震天”时,你已触摸到微调的魔法边缘。但那终究只是角色扮演的雏形,真正的炼丹术,在于将冰冷、精确的商业事实熔铸为模型的“肌…...

stm32f4 + Helix + Max98357播放mp3文件
stm32f4的SDIO + FataFs读取SD卡文件在前面的文章中已经实现,下面的配置和修改基于之前的配置实现 配置I2S 模式设置 参数设置 DMA配置 勾选 SPI2 global interrupt 以上都配置完Helix 解码出来的 PCM 数据就发给 MAX98357了 Helix解码库移植...

H3CSE 高性能园区网:生成树保护机制
H3CSE 高性能园区网:生成树保护机制一、生成树保护机制1. BPDU保护1.1 边缘端口特点及问题端口基础特性存在的安全隐患1.2 BPDU保护机制核心防护逻辑机制运行优势1.3 BPDU保护配置配置使用规范H3C设备配置命令2. 根桥保护2.1 根桥保护机制2.2 根桥保护配置要求2.3 根…...
)
别再手动删了!用Notepad++正则表达式5分钟批量清理课程目录(附实战案例)
5分钟极简正则表达式实战:用Notepad智能清洗杂乱课程目录 每次整理网课资源时,最头疼的莫过于面对几十个类似03_Python基础--循环结构实战.mp4这样的文件名。手动一个个删除序号和分类不仅耗时,还容易出错。上周帮同事整理200多份培训视频时&…...

实时反欺诈Agent部署失败率高达68%?金融IT总监亲述4类典型故障链及容灾切换黄金12分钟法则
更多请点击: https://codechina.net 第一章:实时反欺诈Agent部署失败率高达68%?金融IT总监亲述4类典型故障链及容灾切换黄金12分钟法则 某头部城商行在2023年Q3上线新一代实时反欺诈Agent集群后,监控平台显示首次部署成功率仅32…...

2026年国内镜像站安全与效率评测:GPT-5.5的真实体验
在国内访问海外大模型,延迟高、连接不稳、支付合规是老生常谈的三座大山。为了完成本次GPT-5.5的全流程实测,我借助库拉AI聚合平台完成了所有调用——该平台支持国内外主流AI模型的统一对接,国内可直连访问,注册用户每日提供可用额…...

【安全基线】测试数据脱敏规范:喂给大模型的数据,如何确保不泄露公司机密?
一、开篇:当“喂数据”变成“泄机密” 2026年4月,一条消息震动了整个AI行业:为OpenAI、Anthropic和Meta提供训练数据的明星初创公司Mercor确认发生安全事件,黑客组织TeamPCP通过污染开源项目LiteLLM的CI/CD流水线,发布了恶意版本1.82.7和1.82.8到PyPI仓库,Mercor正是数千…...