现代卷积神经网络(AlexNet)
专栏:神经网络复现目录
本章介绍的是现代神经网络的结构和复现,包括深度卷积神经网络(AlexNet),VGG,NiN,GoogleNet,残差网络(ResNet),稠密连接网络(DenseNet)。
文章部分文字和代码来自《动手学深度学习》
文章目录
- 深度卷积神经网络(AlexNet)
- 学习表征
- AlexNet 架构
- 模型设计
- 使用模型进行Fashion-MNIST分类
- 数据集
- 超参数、优化器,损失函数
- 训练
- 测试
- 结果
深度卷积神经网络(AlexNet)
学习表征
学习表征(Representation Learning)是机器学习中一个重要的研究领域,旨在通过学习数据的表征,从而更好地完成各种任务。在传统机器学习中,通常需要手工设计特征,然后将这些特征输入到模型中进行训练。这种方法需要具有专业领域知识的人员手工设计特征,费时费力,且很难设计出完美的特征。
而学习表征则是通过机器自动学习数据的特征表示,省去了手动设计特征的过程,提高了效率和性能。学习表征的方法可以分为无监督学习和监督学习两种。其中,无监督学习是指在没有标注信息的情况下学习数据的表征,比如自编码器、受限玻尔兹曼机、深度信念网络等;监督学习则是利用带有标注信息的数据进行学习,比如卷积神经网络、递归神经网络等。
通过学习表征,可以更好地完成各种任务,如图像分类、目标检测、语音识别等。同时,学习表征也是深度学习领域的一个重要研究方向,有助于深入理解深度神经网络的工作原理和特性。
有趣的是,在网络的最底层,模型学习到了一些类似于传统滤波器的特征抽取器。 下图从AlexNet论文 (Krizhevsky et al., 2012)复制的,描述了底层图像特征。

AlexNet的更高层建立在这些底层表示的基础上,以表示更大的特征,如眼睛、鼻子、草叶等等。而更高的层可以检测整个物体,如人、飞机、狗或飞盘。最终的隐藏神经元可以学习图像的综合表示,从而使属于不同类别的数据易于区分。尽管一直有一群执着的研究者不断钻研,试图学习视觉数据的逐级表征,然而很长一段时间里这些尝试都未有突破。深度卷积神经网络的突破出现在2012年。突破可归因于两个关键因素。
AlexNet 架构
若图像大小为A ×\times× A,卷积核大小为D ×\times× D,扩充边缘padding=B,步长stride=C
则卷积后的特征图FeatureMap大小为(A-D+B*2+C)/ C
值得注意的一点:原图输入224 × 224,实际上进行了随机裁剪,实际大小为227 × 227。
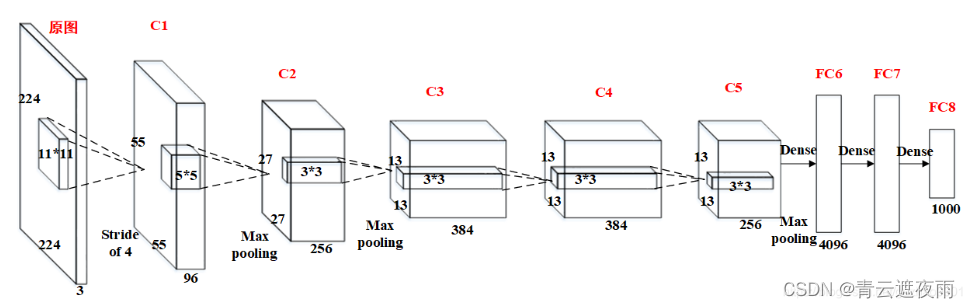
- 卷积层C1
C1的基本结构为:卷积–>ReLU–>池化
卷积:输入227 × 227 × 3,96个11×11×3的卷积核,不扩充边缘padding = 0,步长stride = 4,因此其FeatureMap大小为(227-11+0×2+4)/4 = 55,即55×55×96;
激活函数:ReLU;
池化:池化核大小3 × 3,不扩充边缘padding = 0,步长stride = 2,因此其FeatureMap输出大小为(55-3+0×2+2)/2=27, 即C1输出为27×27×96(此处未将输出分到两个GPU中,若按照论文将分成两组,每组为27×27×48) - 卷积层C2
C2的基本结构为:卷积–>ReLU–>池化
卷积:输入27×27×96,256个5×5×96的卷积核,扩充边缘padding = 2, 步长stride = 1,因此其FeatureMap大小为(27-5+2×2+1)/1 = 27,即27×27×256;
激活函数:ReLU;
池化:池化核大小3 × 3,不扩充边缘padding = 0,步长stride = 2,因此其FeatureMap输出大小为(27-3+0+2)/2=13, 即C2输出为13×13×256(此处未将输出分到两个GPU中,若按照论文将分成两组,每组为13×13×128); - 卷积层C3
C3的基本结构为:卷积–>ReLU。注意一点:此层没有进行MaxPooling操作。
卷积:输入13×13×256,384个3×3×256的卷积核, 扩充边缘padding = 1,步长stride = 1,因此其FeatureMap大小为(13-3+1×2+1)/1 = 13,即13×13×384;
激活函数:ReLU,即C3输出为13×13×384(此处未将输出分到两个GPU中,若按照论文将分成两组,每组为13×13×192) - 卷积层C4
C4的基本结构为:卷积–>ReLU。注意一点:此层也没有进行MaxPooling操作。
卷积:输入13×13×384,384个3×3×384的卷积核, 扩充边缘padding = 1,步长stride = 1,因此其FeatureMap大小为(13-3+1×2+1)/1 = 13,即13×13×384;
激活函数:ReLU,即C4输出为13×13×384(此处未将输出分到两个GPU中,若按照论文将分成两组,每组为13×13×192); - 卷积层C5
C5的基本结构为:卷积–>ReLU–>池化
卷积:输入13×13×384,256个3×3×384的卷积核,扩充边缘padding = 1,步长stride = 1,因此其FeatureMap大小为(13-3+1×2+1)/1 = 13,即13×13×256;
激活函数:ReLU;
池化:池化核大小3 × 3, 扩充边缘padding = 0,步长stride = 2,因此其FeatureMap输出大小为(13-3+0×2+2)/2=6, 即C5输出为6×6×256(此处未将输出分到两个GPU中,若按照论文将分成两组,每组为6×6×128); - 全连接层FC6
FC6的基本结构为:全连接–>>ReLU–>Dropout
全连接:此层的全连接实际上是通过卷积进行的,输入6×6×256,4096个6×6×256的卷积核,扩充边缘padding = 0, 步长stride = 1, 因此其FeatureMap大小为(6-6+0×2+1)/1 = 1,即1×1×4096;
激活函数:ReLU;
Dropout:全连接层中去掉了一些神经节点,达到防止过拟合,FC6输出为1×1×4096; - 全连接层FC7
FC7的基本结构为:全连接–>>ReLU–>Dropout
全连接:此层的全连接,输入1×1×4096;
激活函数:ReLU;
Dropout:全连接层中去掉了一些神经节点,达到防止过拟合,FC7输出为1×1×4096; - 全连接层FC8
FC8的基本结构为:全连接–>>softmax
全连接:此层的全连接,输入1×1×4096;
softmax:softmax为1000,FC8输出为1×1×1000;
模型设计
class AlexNet(nn.Module):def __init__(self):super(AlexNet,self).__init__()#卷积层self.conv = nn.Sequential(#C1nn.Conv2d(in_channels=1,out_channels=96,kernel_size=11,padding=0,stride=4),nn.ReLU(),nn.MaxPool2d(kernel_size=3,stride=2),#C2nn.Conv2d(in_channels=96,out_channels=256,kernel_size=5,padding=2,stride=1),nn.ReLU(),nn.MaxPool2d(kernel_size=3,stride=2),#C3nn.Conv2d(in_channels=256,out_channels=384,kernel_size=3,padding=1,stride=1),nn.ReLU(),nn.MaxPool2d(kernel_size=3,stride=2),#C4nn.Conv2d(in_channels=384,out_channels=384,kernel_size=3,padding=1,stride=1),nn.ReLU(),#C5nn.Conv2d(in_channels=384,out_channels=256,kernel_size=3,padding=1,stride=1),nn.ReLU(),nn.MaxPool2d(kernel_size=3,stride=2),nn.Flatten(),#拉直层)#全连接层self.fc=nn.Sequential(#FC6nn.Linear(256*5*5,4096),nn.ReLU(),nn.Dropout(0.5),#FC7nn.Linear(4096,4096),nn.ReLU(),nn.Dropout(0.5),nn.Linear(4096,10),)def forward(self,img):feature=self.conv(img)output=self.fc(feature)return outputdef layers(self):return [self.conv, self.fc]
使用模型进行Fashion-MNIST分类
数据集
def get_dataloader_workers(): #@save"""使用4个进程来读取数据"""return 4def load_data_fashion_mnist(batch_size, resize=None): #@save"""下载Fashion-MNIST数据集,然后将其加载到内存中"""trans = [transforms.ToTensor()]if resize:trans.insert(0, transforms.Resize(resize))trans = transforms.Compose(trans)mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True)mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)return (data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=get_dataloader_workers()),data.DataLoader(mnist_test, batch_size, shuffle=False,num_workers=get_dataloader_workers()))
超参数、优化器,损失函数
#超参数,优化器和损失函数
batch_size = 128
train_iter, test_iter = load_data_fashion_mnist(batch_size, resize=224)
lr, num_epochs = 0.01, 10
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
训练
def train(net, train_iter, test_iter, num_epochs, lr, device):def init_weights(m):if type(m) == nn.Linear or type(m) == nn.Conv2d:nn.init.xavier_uniform_(m.weight)net.apply(init_weights)print('training on', device)net.to(device)for epoch in range(num_epochs):# 训练损失之和,训练准确率之和,样本数net.train()train_step = 0total_loss = 0.0#总损失total_correct = 0#总正确数total_examples = 0#总训练数for i, (X, y) in enumerate(train_iter):optimizer.zero_grad()X, y = X.to(device), y.to(device)y_hat = net(X)l = loss(y_hat, y)l.backward()optimizer.step()total_loss += l.item()total_correct += (y_hat.argmax(dim=1) == y).sum().item()total_examples += y.size(0)train_step+=1if(train_step%50==0):#每训练一百组输出一次损失print("第{}轮的第{}次训练的loss:{}".format((epoch+1),train_step,l.item()))train(net,train_iter,test_iter,num_epochs,lr,device)测试
from d2l import torch as d2l
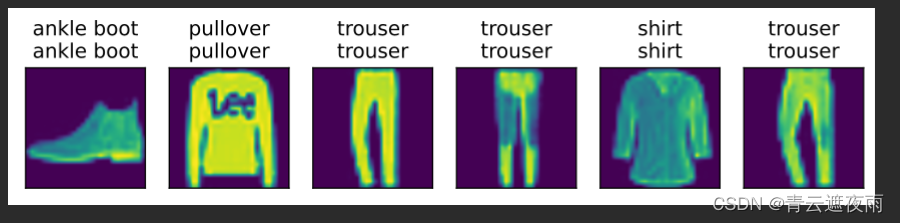
def predict(net, test_iter, n=6): #@savefor X, y in test_iter:X, y = X.to('cuda'), y.to('cuda')breaktrues = d2l.get_fashion_mnist_labels(y)preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1))titles = [true +'\n' + pred for true, pred in zip(trues, preds)]d2l.show_images(X[0:n].cpu().reshape((n, 224, 224)), 1, n, titles=titles[0:n])
predict(net, test_iter)结果
相关文章:
现代卷积神经网络(AlexNet)
专栏:神经网络复现目录 本章介绍的是现代神经网络的结构和复现,包括深度卷积神经网络(AlexNet),VGG,NiN,GoogleNet,残差网络(ResNet),稠密连接网络…...
单向非循环链表
1、顺序表遗留问题 1. 中间/头部的插入删除,时间复杂度为O(N) 2. 增容需要申请新空间,使用malloc、realloc等函数拷贝数据,释放旧空间。会有不小的消耗。 3. 当我们以2倍速度增容时,势必会有一定的空间浪费。例如当前容量为100&a…...

Vue2的基本内容(一)
目录 一、插值语法 二、数据绑定 1.单向数据绑定 2.双向数据绑定 三、事件处理 1.绑定监听 2.事件修饰符 四、计算属性computed和监视属性watch 1.计算属性-computed 2.监视属性-watch (1)通过 watch 监听 msg 数据的变化 (2&a…...

蚁群算法优化最优值
%%%%%%%%%%%%%%蚁群算法求函数极值%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%初始化%%%%%%%%%%%%%%%%%%%%% clear all; %清除所有变量 close all; %清图 clc; %清屏 m 20; %蚂蚁个数 G 500; %最大迭代次数 Rho 0.9; %信息素蒸发系数 P0 0.2; %转移概率常数 XMAX 5; %搜索变量 x…...

Docker镜像的内部机制
Docker镜像的内部机制 镜像就是一个打包文件,里面包含了应用程序还有它运行所依赖的环境,例如文件系统、环境变量、配置参数等等。 环境变量、配置参数这些东西还是比较简单的,随便用一个 manifest 清单就可以管理,真正麻烦的是文…...
每日的时间安排规划
14:23 2023年3月4日星期六 开始 现在我要做一套试卷。模拟6级考试。 现在是: 16:22 2023年3月4日星期六。 做完了线上的试卷! 发现我真的是不太聪明的样子! 明明买的有历年真题,做真题就行了,还要做它们出的模拟的…...
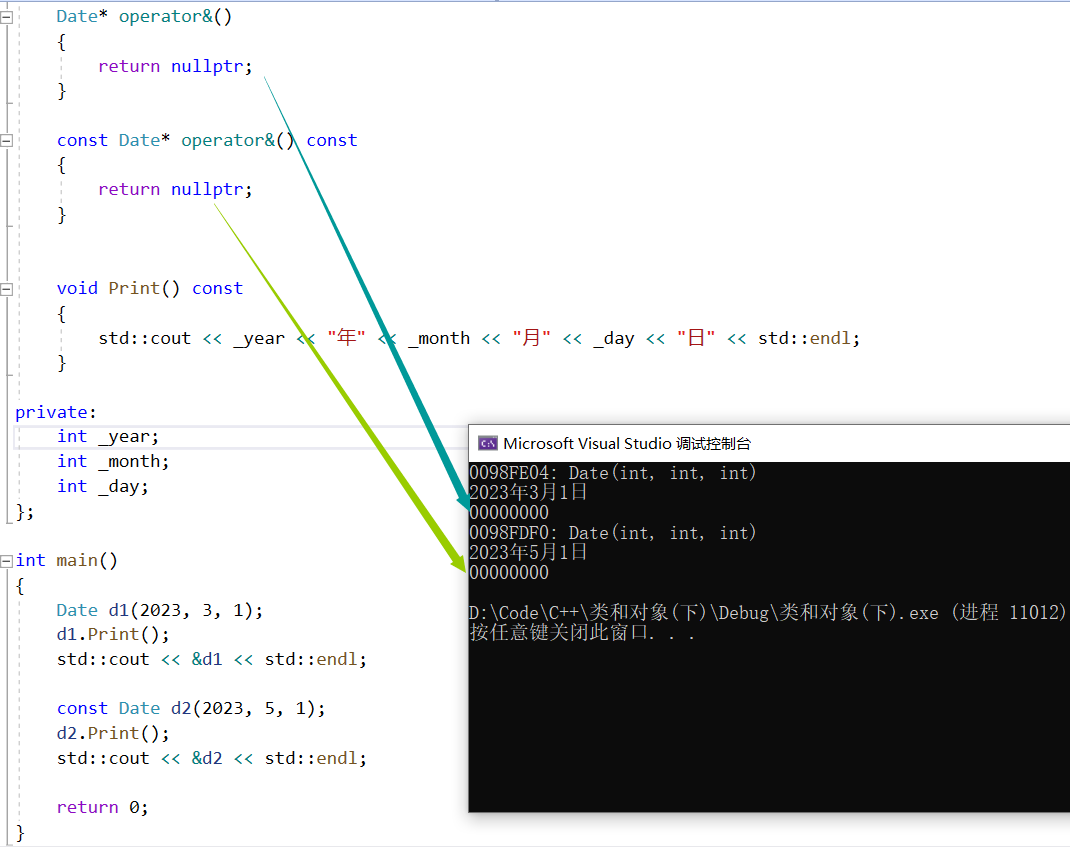
【C++】类和对象——六大默认成员函数
🏖️作者:malloc不出对象 ⛺专栏:C的学习之路 👦个人简介:一名双非本科院校大二在读的科班编程菜鸟,努力编程只为赶上各位大佬的步伐🙈🙈 目录前言一、类的6个默认成员函数二、构造…...

远程debug被arthas watch了的idea
开发工具idea端(2021.2.1) 远程调试 被 应用了 修改的arthas端 的 鸡idea端(2022.3.2) A. 鸡idea端 鸡idea: “D:\IntelliJ IDEA 2022.3.2\bin\idea64.exe” 中安装有目标插件 比如 RedisNew-2022.07.24.zip 对文件 “D:\IntelliJ IDEA 2022.3.2\bin\idea64.exe.vmoptions” 新…...
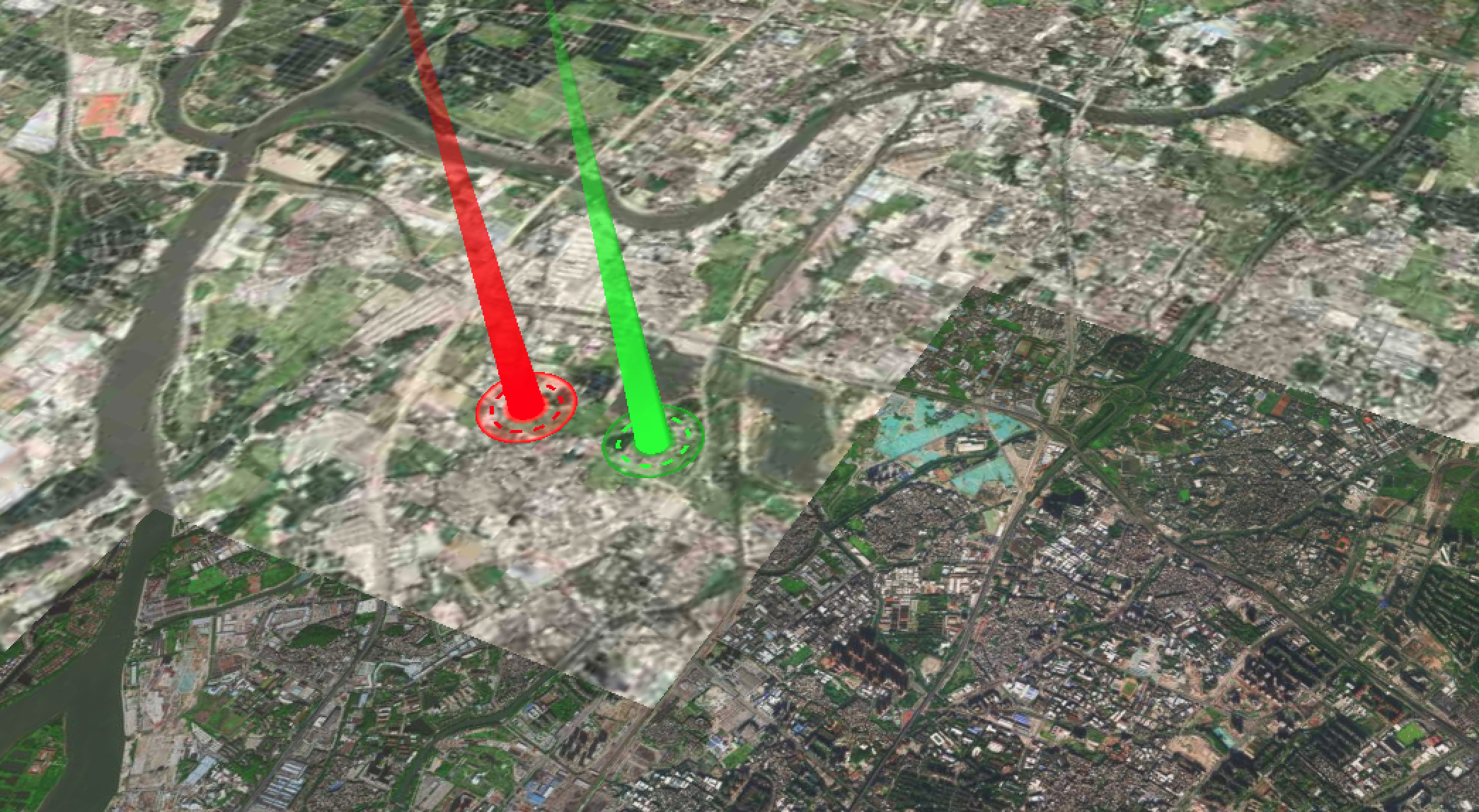
Cesium实现的光柱效果
Cesium实现的光柱效果 效果展示: 可以通过拼接两个entity来实现这个效果: 全部代码; index.html <!DOCTYPE html> <html><head><meta charset...
和splice())
你最爱记混的slice()和splice()
slice()方法:选取数组的一部分,并返回一个新数组 该方法不会改变原始数组,而是将截取到的元素封装到一个新数组中返回 语法:array.slice(start,end),参数的介绍如下: 语法:array.slice(start,end),参数的介绍如下: 1.start:截取开始的位置的索引,包含开始索引 2.…...

【LeetCode】剑指 Offer(15)
目录 题目:剑指 Offer 32 - II. 从上到下打印二叉树 II - 力扣(Leetcode) 题目的接口: 解题思路: 代码: 过啦!!! 题目:剑指 Offer 32 - III. 从上到下打…...

【刷题笔记】之二分查找(搜索插入位置。在排序数组中查找元素的第一个和最后一个位置、x的平方根、有效的完全平方数)
1. 二分查找题目链接 704. 二分查找 - 力扣(LeetCode)给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -…...
)
一起Talk Android吧(第五百一十五回:绘制向外扩散的水波纹)
文章目录整体思路实现方法示例代码各位看官们大家好,上一回中咱们说的例子是"Java中的进制转换",这一回中咱们说的例子是"绘制向外扩散的水波纹"。闲话休提,言归正转, 让我们一起Talk Android吧! 整体思路 …...

基于粒子群改进的支持向量机SVM的情感分类识别,pso-svm情感分类识别
目录 支持向量机SVM的详细原理 SVM的定义 SVM理论 Libsvm工具箱详解 简介 参数说明 易错及常见问题 SVM应用实例,基于SVM的情感分类预测 代码 结果分析 展望 支持向量机SVM的详细原理 SVM的定义 支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型…...
【python中的列表和元组】
文章目录前言一、列表及其使用1.列表的特点2. 列表的使用方法二、元组及其特点1.元组的类型是tuple1.元组的查找操作2. 计算元组某个元素出现的次数3.统计元组内元素的个数总结前言 本文着重介绍python中的列表和元组以及列表和元组之间的区别 一、列表及其使用 1.列表的特点…...

世界顶级五大女程序媛,不仅技术强还都是美女
文章目录1.计算机程序创始人:勒芙蕾丝伯爵夫人2.首位获得图灵奖的女性:法兰艾伦3.谷歌经典首页守护神:玛丽莎梅耶尔4.COBOL之母:葛丽丝穆雷霍普5.史上最强游戏程序媛-余国荔说起程序员的话,人们想到的都会是哪些理工科…...
Linux- 系统随你玩之--文件管理-双生姐妹花
文章目录1、前言2、文件管理-双生姐妹花2.1、 df2.1.1、 df 语法2.1.1 、常用参数2.2、 du2.2.1、du 语法2.1.1、 常用参数2.3、双生姐妹花区别2.3.1、 查看文件统计 的计算方式不同2.3.2 、删除文件情况下统计结果 不同2.3.3 、针对双生姐妹花区别 结语3、双生姐妹花实操3.1 、…...
18、多维图形绘制
目录 一、三维图形绘制 (一)曲线图绘制plot3() (二)网格图绘制 mesh() (三)曲面图绘制 surf() (四)光照模型 surfl() (五)等值线图(等高线图)绘制 cont…...
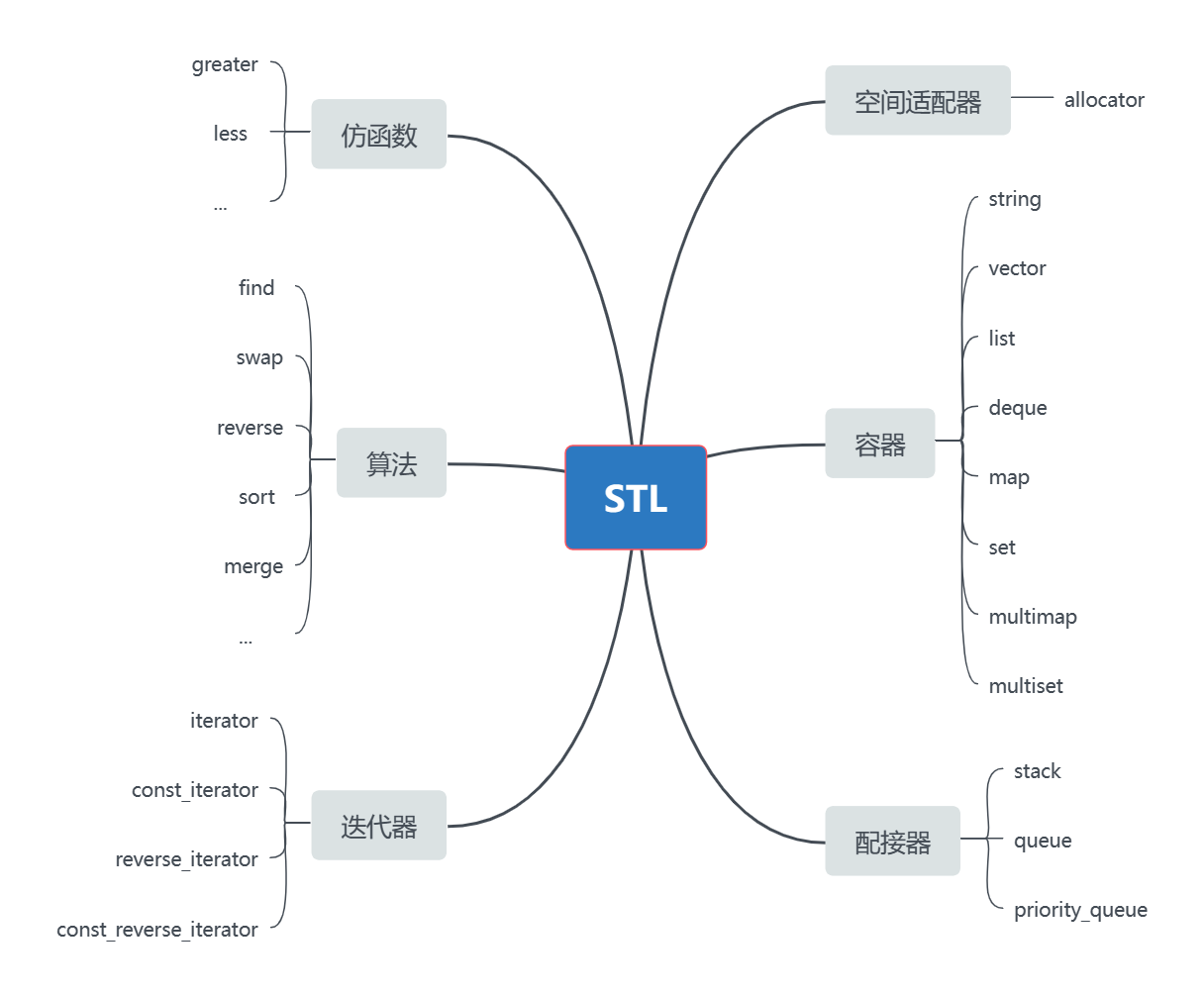
【C++】30h速成C++从入门到精通(STL介绍、string类)
STL简介什么是STLSTL(standard template libaray-标准模板库):是C标准库的重要组成部分,不仅是一个可复用的组件库,而且是一个包罗数据结构与算法的软件框架。STL的版本原始版本Alexander Stepanov、Meng Lee 在惠普实验室完成的原始版本&…...

PMP是什么意思?适合哪些人学呢?
PMP简而言之,就是提高项目管理理论基础和实践能力的考试。 官方一点的说明呢,就是:PMP证书全称为Project Management Professional,也叫项目管理专业人士资格认证。 PMP证书由美国项目管理协会(PMI)发起,是严格评估项…...

WRF和WPS模型在Ubuntu系统上的安装与常见问题解决指南
1. WRF和WPS模型简介 WRF(Weather Research and Forecasting)模型是一个广泛应用于气象研究和业务预报的中尺度数值天气预报系统。它由美国国家大气研究中心(NCAR)等多个机构联合开发,能够模拟从全球尺度到云尺度的各种…...

解决Calibre中文路径乱码的终极方案:从根本上保护中文文件名
解决Calibre中文路径乱码的终极方案:从根本上保护中文文件名 【免费下载链接】calibre-do-not-translate-my-path Switch my calibre library from ascii path to plain Unicode path. 将我的书库从拼音目录切换至非纯英文(中文)命名 项目地…...
)
飞腾CPU+银河麒麟V10系统安装Zotero 6.0.37保姆级教程(含Arch Linux ARM源转换避坑指南)
飞腾CPU银河麒麟V10系统安装Zotero 6.0.37全流程解析与深度优化指南 在国产化技术生态快速发展的背景下,飞腾CPU与银河麒麟操作系统的组合已成为科研机构和关键领域的重要选择。然而,当科研人员需要在这套平台上使用国际主流学术工具时,往往会…...

阿里开源绘画模型Qwen-Image-2512:ComfyUI镜像内置工作流,支持2512高清分辨率
阿里开源绘画模型Qwen-Image-2512:ComfyUI镜像内置工作流,支持2512高清分辨率 1. 引言:高清图像生成的新选择 在AI绘画领域,分辨率一直是衡量生成质量的重要指标。阿里通义千问团队最新开源的Qwen-Image-2512模型,将…...

不升级系统也能用VSCode远程开发:老版本Linux的glibc兼容方案大全
老版本Linux系统下VSCode远程开发的五大兼容方案 在企业开发环境中,生产服务器往往运行着CentOS 7或Ubuntu 18.04等长期支持版本,这些系统的glibc库版本可能无法满足最新VSCode远程开发组件的需求。本文将深入探讨五种无需升级系统即可解决glibc兼容性问…...

突破硬件限制:OpenCore Legacy Patcher实现老旧Mac现代化升级的完整方案
突破硬件限制:OpenCore Legacy Patcher实现老旧Mac现代化升级的完整方案 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 在苹果生态系统中&#x…...

TTS-Vue终极指南:如何快速构建高性能本地语音合成应用
TTS-Vue终极指南:如何快速构建高性能本地语音合成应用 【免费下载链接】tts-vue 🎤 微软语音合成工具,使用 Electron Vue ElementPlus Vite 构建。 项目地址: https://gitcode.com/gh_mirrors/tt/tts-vue 在数据安全和网络稳定性成…...

50天学习FPGA第41天-PCIe的的介绍及使用
目录 简介 配置过程 简介 XDMA是一种DMA/Bridge Subsystem for PCI Express IP,由Xilinx提供。 XDMA IP核设计使用Xilinx提供的DMASubsystem for PCI Express IP是一个高性能、可配置的适用于PCIE 2.0、PCIE 3.0的SG模式DMA,提供用户可选择的AXI4接口或者AXI4-Stream接口。…...

解决GitHub打不开问题,顺利获取Lingbot模型开源代码与资源
解决GitHub打不开问题,顺利获取Lingbot模型开源代码与资源 你是不是也遇到过这种情况?项目开发到一半,需要去GitHub上拉取一个关键的模型代码,比如最近很火的Lingbot-Depth-Pretrain-ViTL-14,结果页面一直转圈圈&…...

如何在Windows系统上3分钟搞定PDF处理:Poppler预编译包终极指南
如何在Windows系统上3分钟搞定PDF处理:Poppler预编译包终极指南 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 还在为Windows上的PDF处…...