Scrapy框架(高效爬虫)
文章目录
- 一、环境配置
- 二、创建项目
- 三、scrapy数据解析
- 四、基于终端指令的持久化存储
- 1、基于终端指令
- 2、基于管道
- 3、数据同时保存至本地及数据库
- 4、基于spider爬取某网站各页面数据
- 5、爬取本页和详情页信息(请求传参)
- 6、图片数据爬取ImagesPipeline
- 五、中间件
- 1、拦截请求中间件(UA伪装,代理IP)
- 2、拦截响应中间件(动态加载)
- 六、CrawlSpider(自动请求全站爬取,全部页面,自动下拉滚轮爬取)
- 七、分布式爬虫
- 八、增量式爬虫
Scrapy拥有高性能持久化存储,异步数据下载,高性能数据解析,分布式功能
一、环境配置
环境配置步骤如下(要按步骤来):
pip install wheel
下载twisted:https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
安装twisted:pip install Twisted-17.1.0-cp36m-win_amd64.whl (这个文件的路劲)
pip install pywin32
pip install scrapy
测试:在终端输入scrapy指令,没有报错表示安装成功
二、创建项目
步骤:
1、打开pycharm的terminal
2、scrapy startproject first
3、cd first
4、scrapy genspider main www.xxx.com
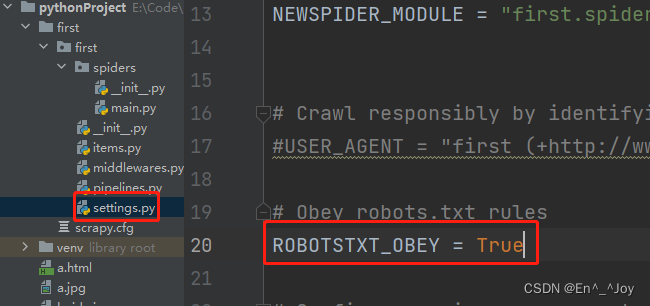
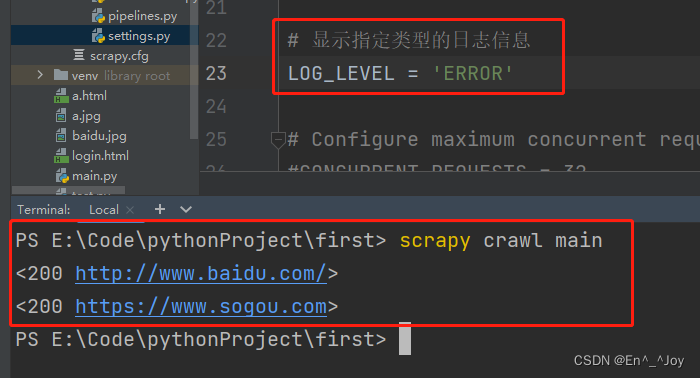
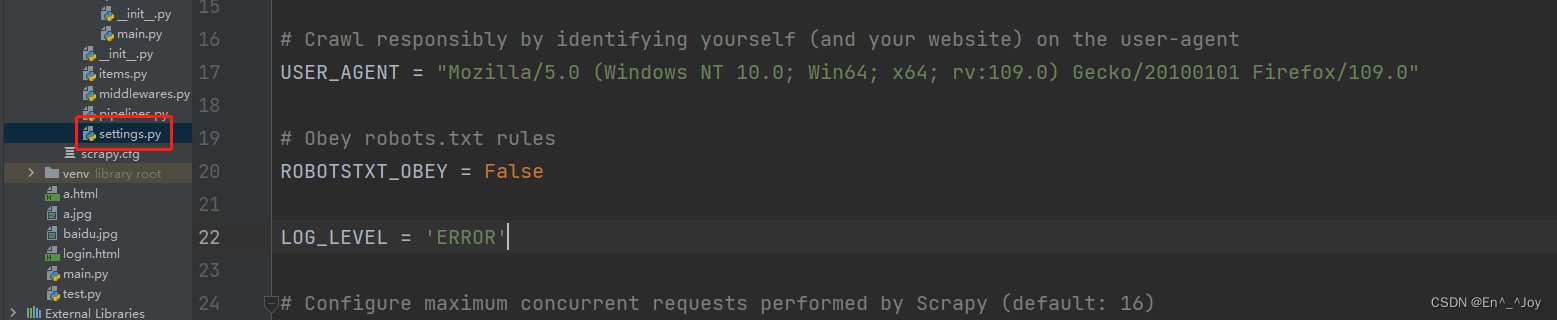
5、需要有main.py里面的输出,则修改settings.py里面的ROBOTSTXT_OBEY = True改为False
6、scrapy crawl main不需要额外的输出则执行scrapy crawl main --nolog或者在settings.py里面添加LOG_LEVEL='ERROR',main.py有错误代码会报错(不添加有错误时则不会报错)(常用)
实际操作如下:
打开pycharm的terminal
执行scrapy startproject first,当前目录下会出现个first项目工程,里面有个spiders文件夹,称为爬虫文件夹,在这里放爬虫源文件
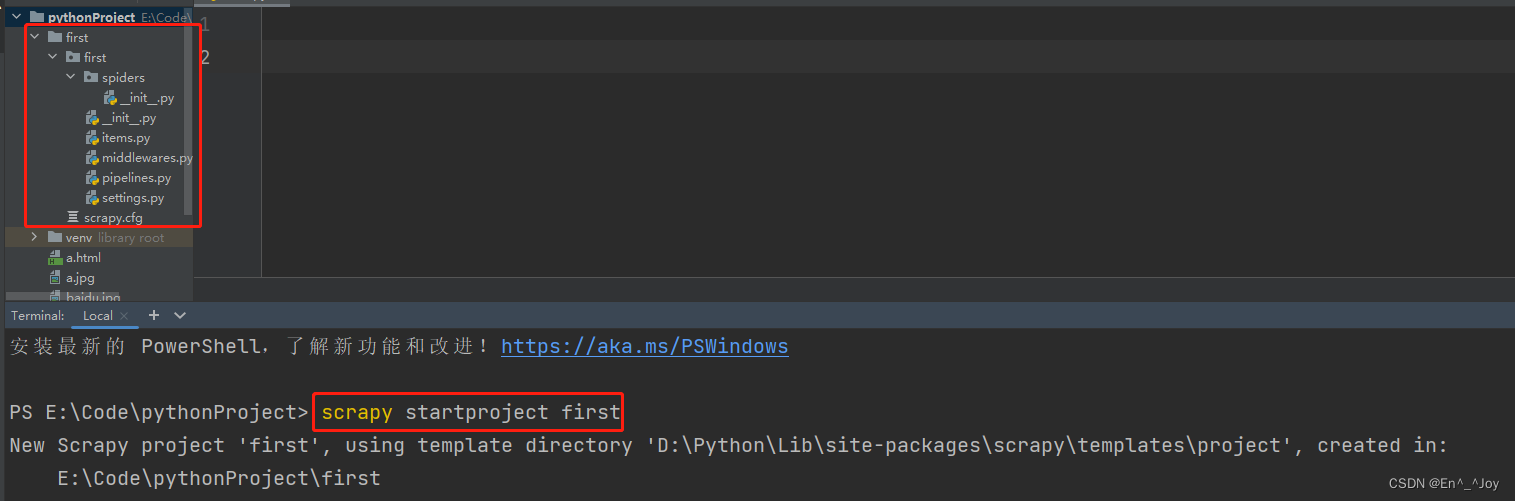
cd first 进入工程目录
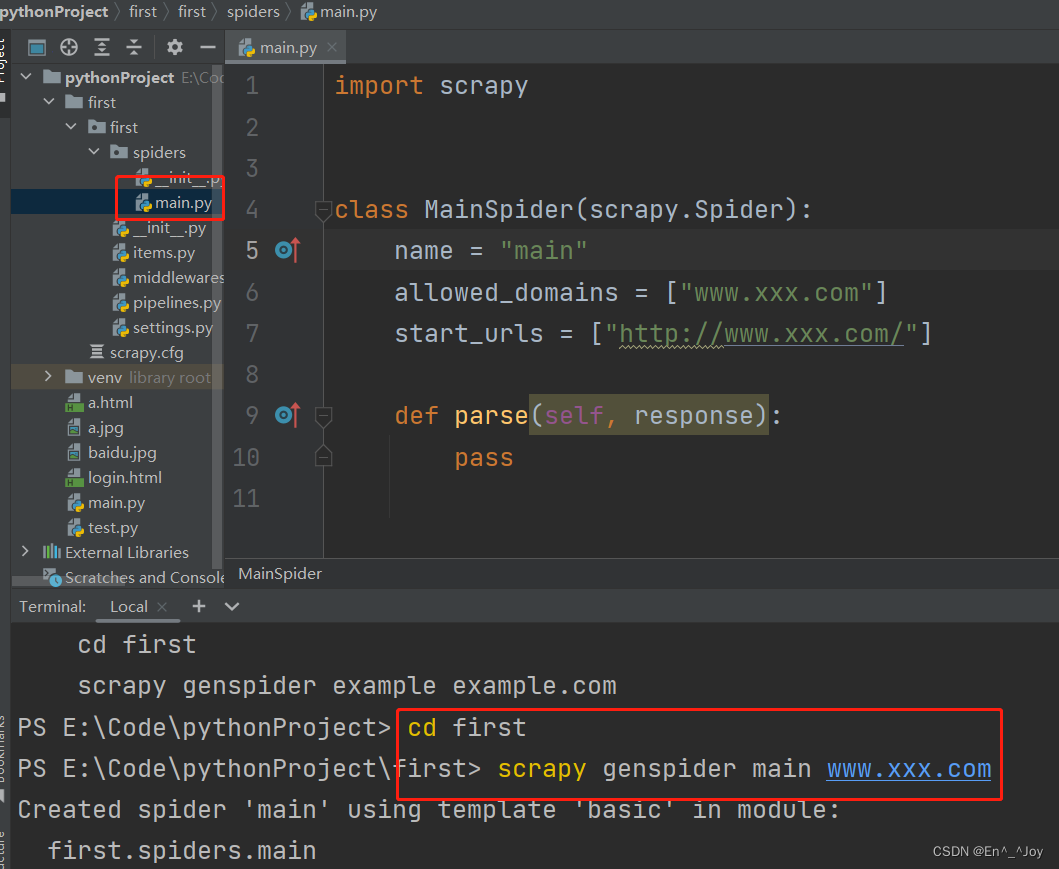
执行scrapy genspider main www.xxx.com,在spiders目录中创建一个名为main的爬虫文件,创建的文件自带部分内容
执行工程:scrapy crawl main (运行main爬虫文件)
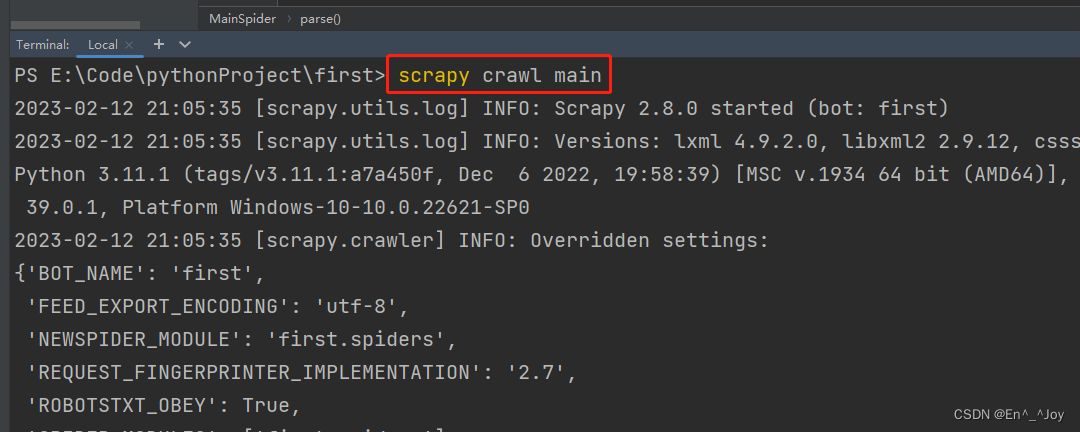
上面parse里面如果有输出运行时没有输出,则需要将settings.py里面的ROBOTSTXT_OBEY = True改为False
改成False后,修改main.py文件内容如下,运行就会有输出
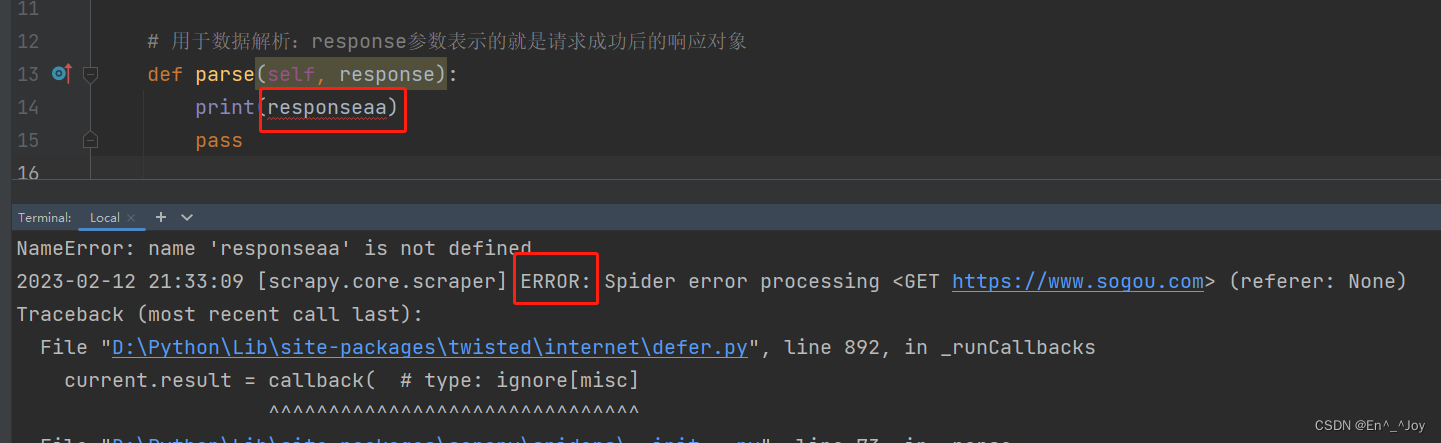
import scrapyclass MainSpider(scrapy.Spider):# 爬虫文件的名称:爬虫源文件的唯一标识name = "main"# 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送,一般不用# allowed_domains = ["www.xxx.com"]# 起始的url列表:该列表中存放的url会被scrapy自动进行请求发送start_urls = ["http://www.baidu.com/","https://www.sogou.com"]# 用于数据解析:response参数表示的就是请求成功后的响应对象def parse(self, response):print(response)pass
 使用指令
使用指令scrapy crawl main --nolog,输出内容就不会输出多余的内容,只输出打印的内容

如果里面的代码输入错误,运行加上–nolog后不会有输出,看不出报错
有个好方法,运行不用加–nolog,在settings.py里面添加LOG_LEVEL='ERROR',如果输入错误,就会报ERROR,如果没错,输出内容和上面运行带上–nolog一样,这里就不用加–nolog
三、scrapy数据解析
首先创建项目
scrapy startproject first
cd first
scrapy genspider main www.xxx.com
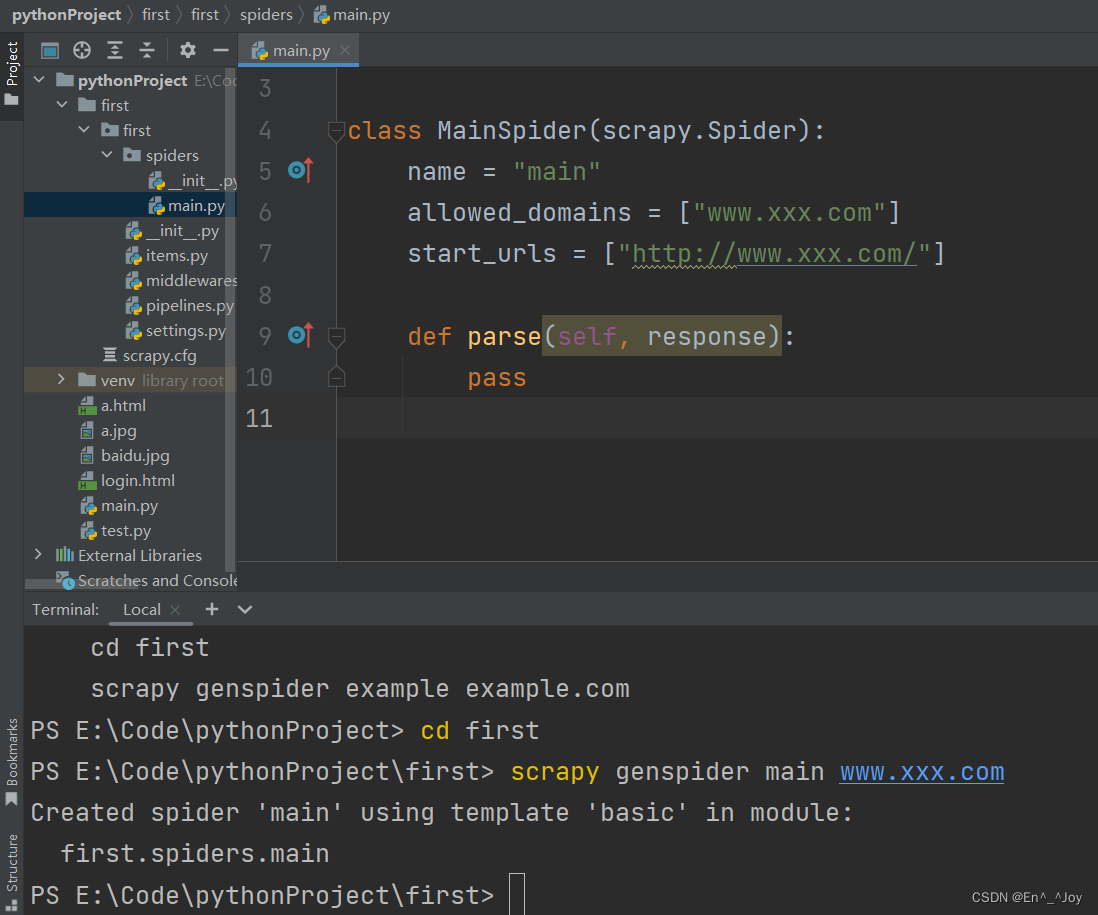
修改settings.py文件的ROBOTSTXT_OBEY = True改为False,才会有输出,添加LOG_LEVEL='ERROR'
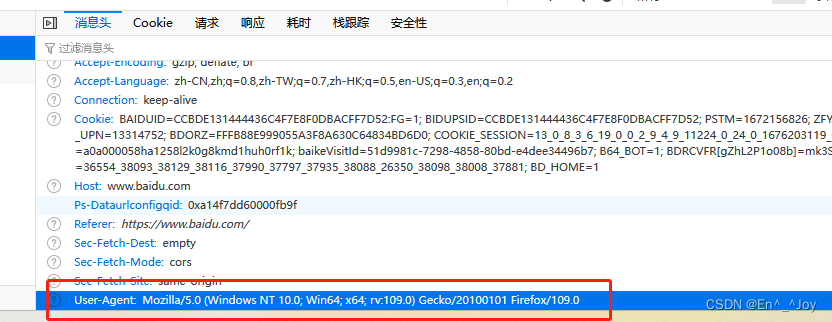
在将注释的USER_AGENT取消注释,在页面中复制该内容到这个变量中
修改main.py文件
import scrapyclass MainSpider(scrapy.Spider):name = "main"# allowed_domains = ["www.xxx.com"]start_urls = ["http://www.baidu.com/"]def parse(self, response):# 解析数据# xpath返回的是列表,列表元素一定是Selector类型的对象div_list = response.xpath('//div')for div in div_list:# extract可以将selector对象中data参数存储的字符串提取出来(可以是列表)print(div.extract())
执行scrapy crawl main 就会将解析的数据输出
关于Xpath使用请看:https://blog.csdn.net/weixin_46287157/article/details/116432393
四、基于终端指令的持久化存储
1、基于终端指令
只可以将parse方法的返回值存储到本地的文本文件中
基于上面解析的数据,将要保存的数据保存在datas中,然后return返回
再执行指令scrapy crawl main -o ./a.csv,就可以将返回的datas数据保存在a.csv中(要加-o参数保存文件,也可以./a,txt)
注意:持久化存储的文本类型只可以为json, jsonlines, jsonl, jl, csv, xml, marshal, pickle
import scrapyclass MainSpider(scrapy.Spider):name = "main"allowed_domains = ["www.baidu.com"]start_urls = ["http://www.baidu.com/"]def parse(self, response):datas = []# 解析数据# xpath返回的是列表,列表元素一定是Selector类型的对象div_list = response.xpath('//div[@id="..."]/div')for div in div_list:# extract可以将selector对象中data参数存储的字符串提取出来(可以是列表)datas.append(div.xpath('./div').extract())return datas
2、基于管道
首先需要创建项目:
1、打开pycharm的terminal
2、scrapy startproject first
3、cd first
4、scrapy genspider main www.xxx.com
5、修改settings.py里面的ROBOTSTXT_OBEY = True改为False并添加LOG_LEVEL='ERROR'
6、scrapy crawl main
接着需要在主函数(main.py文件)中进行数据解析,main.py内容如下
import scrapy
from first.items import FirstItemclass MainSpider(scrapy.Spider):name = "main"# allowed_domains = ["www.xxx.com"]start_urls = ["https://www.gushiwen.cn/"]def parse(self, response):# 解析数据# xpath返回的是列表,列表元素一定是Selector类型的对象div_list = response.xpath('/html/body/div[2]/div[1]/div')for div in div_list:# extract可以将selector对象中data参数存储的字符串提取出来(可以是列表)# 解析诗歌标题和内容# 加个if判断,如果解析到的不为空,就进行存储if len(div.xpath('./div[1]/p[1]/a/b/text()')) != 0 and len(div.xpath('./div[1]/div[2]/text()')) !=0:# 解析数据title = div.xpath('./div[1]/p[1]/a/b/text()')[0].extract()content = div.xpath('./div[1]/div[2]/text()')[0].extract()
然后在item类中定义相关的属性,将解析的数据存储到item类型的对象(items.py里面有个FirstItem类,可以实例化对象,即item类的实例对象)。修改items.py文件,定义相关属性,比如诗歌、内容,将解析到的数据封装到item对象中:
class FirstItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()title = scrapy.Field()content = scrapy.Field()pass
用item实例化对象后,这个对象就能取得title和content。将item类型的对象提交给管道进行持久化存储操作。pipelines.py中定义了FirstPipeline类,专门用来处理item类型对象。在管道类的process_item中要将其接受到的item对象中存储的数据进行持久化存储操作
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapterclass FirstPipeline:fp = None# 重写父类的一个方法:该方法只在开始爬虫的时候被调用一次def open_spider(self, spider):print('开启爬虫')self.fp = open('./a.txt', 'w', encoding='utf-8')# 用来处理item类型对象# 该方法可以接收爬虫文件提交过来的item对象# 该方法每接收到一个人item就会被调用一次# 如果把打开关闭文件放这,则需要多次打开关闭文件,则另外创建函数,减少打开关闭文件次数def process_item(self, item, spider): # item为item对象title = item['title']content = item['content']self.fp.write(title+':'+content+'\n')return itemdef close_spider(self, spider):print('结束爬虫')self.fp.close()在配置文件setting.py中开启管道,即取消管道的注释
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {"first.pipelines.FirstPipeline": 300,
}
最后在主函数main.py中添加调库及将解析的数据存储到item类型的对象和将item提交给管道的代码
import scrapy
from first.items import FirstItemclass MainSpider(scrapy.Spider):name = "main"# allowed_domains = ["www.xxx.com"]start_urls = ["https://www.gushiwen.cn/"]def parse(self, response):# 解析数据# xpath返回的是列表,列表元素一定是Selector类型的对象div_list = response.xpath('/html/body/div[2]/div[1]/div')for div in div_list:# extract可以将selector对象中data参数存储的字符串提取出来(可以是列表)# 解析诗歌标题和内容# 加个if判断,如果解析到的不为空,就进行存储if len(div.xpath('./div[1]/p[1]/a/b/text()')) != 0 and len(div.xpath('./div[1]/div[2]/text()')) !=0:title = div.xpath('./div[1]/p[1]/a/b/text()')[0].extract()content = div.xpath('./div[1]/div[2]/text()')[0].extract()# 将解析的数据存储到item类型的对象item = FirstItem()item['title'] = titleitem['content'] = content# 将item提交给管道,进行数据存储yield item
最后运行程序:scrapy crawl main
3、数据同时保存至本地及数据库
举例:将爬取的数据一份存到本地,一份存到数据库
在上面代码的基础上,再在管道中定义多个管道类,一个类制定存储到某个地方(一个存储到本地,一个存储到数据库)
在piplines.py中新增如下类
# 导入数据库
# import pymysql
# 管道文件中一个管道类对应将一组数据存储到一个平台或者载体中
class mysqlPileLine(object):conn = Nonecursor = Nonedef open_spider(self, spider):self.conn = pymysql.Connect(host='127.0.0.1', port=3306, user='root', password='123456', db='qiubai', charset='utf8')def process_item(self, item, spider):self.cursor =self.conn.cursor()try:self.cursor.execute('insert into qiubai values("%s","%s")'%(item["title"],item["content"]))self.conn.commit()except Exception as e:pritn(e)self.conn.rollback()return itemdef close_spider(self, spider):self.cursor.close()self.conn.close()
在settings.py中开启管道,添加个优先级
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {# 300表示优先级,数值越小,优先级越高"first.pipelines.FirstPipeline": 300,"first.pipelines.mysqlPileLine": 301,
}
爬虫文件提交的item类型的对象最终会提交给先执行的类(优先级高的类)。在优先级高的里面添加return item,return就会传递给下一个即将执行的管道类,pipelines.py优先级高的类中给一个函数添加return
def process_item(self, item, spider): # item为item对象title = item['title']content = item['content']self.fp.write(title+':'+content+'\n')# return就会传递给下一个即将执行的管道类return item
管道文件中一个管道类对应的是将数据存储到一个平台。爬虫文件提交的item只会给管道文件中第一个被执行的管道类接收(优先级高的)。process_item中的return item表示将item传递给下一个即将被执行的管道类
4、基于spider爬取某网站各页面数据
以某网站为例,对某网站的全部页面(有分页栏)对应的页面进行爬取,这里需要获取所有页面的URL,并将其加入到start_url中,然后进行请求发送
首先创建项目并初始化操作
1、打开pycharm的terminal
2、scrapy startproject first
3、cd first
4、scrapy genspider main www.xxx.com
5、修改settings.py里面的ROBOTSTXT_OBEY = True改为False并添加LOG_LEVEL='ERROR'
6、scrapy crawl main (最后一步运行)
然后编辑main.py文件
import scrapyclass MainSpider(scrapy.Spider):name = "main"# allowed_domains = ["www.xxx.com"]# 第一个页面start_urls = ["https://www.woyaogexing.com/touxiang/katong/new/index.html"]# 生成一个通用的url# %d可以被page_num取代url = 'https://www.woyaogexing.com/touxiang/katong/new/index_%d.html'# 页码数page_num = 2def parse(self, response):# 解析数据div_list = response.xpath('/html/body/div[3]/div[3]/div[1]/div[2]/div')for li in div_list:img_name = li.xpath('./a[2]/text()')[0].extract()print(img_name)# 递归if self.page_num <= 5: # 前5页# 每个页码对应的url,page_num替换url中的%dnew_url = format(self.url%self.page_num)self.page_num += 1# 手动请求发送:callback回调函数是专门用于数据解析yield scrapy.Request(url=new_url, callback=self.parse)
5、爬取本页和详情页信息(请求传参)
爬取本页面信息,然后再爬取详情页面信息,即本页面点击进入详情页之后爬取详细信息,这需要解析当前页获取详情页URL,然后对详情页URL发起请求并解析,然后存储。在scrapy.Request中传入meta={‘item’:item}参数,即传入item
import scrapy
from first.items import FirstItemclass MainSpider(scrapy.Spider):name = "main"# allowed_domains = ["www.baidu.com"]# 第一页面URLstart_urls = ["https://www.qidian.com/rank/yuepiao/"]# 后续页面URLurl = 'https://www.qidian.com/rank/yuepiao/year2023-month03-page%d/'page_num = 2# 回调函数接收item,解析详情页def parse_detail(self,response):item = response.meta['item']# 这里解析详情页信息content = response.xpath('...')item['content'] = contentprint(item['title'], item['content'])yield item# 解析首页的岗位名称def parse(self, response):li_list = response.xpath('/html/body/div[1]/div[6]/div[2]/div[2]/div/div/ul/li')for li in li_list:item = FirstItem()title = li.xpath('./div[2]/h2/a/text()')[0].extract()item['title'] = titledetail_url = 'https:' + li.xpath('./div[2]/h2/a/@href')[0].extract()# 对详情页发送请求获取详情页的信息源码数据# 手动请求的发送# 请求传参:meta={},可以将meta字典传递给请求对应的回调函数yield scrapy.Request(detail_url, callback=self.parse_detail, meta={'item': item})# 分页操作,爬取前5页数据if self.page_num <= 5:new_url = format(self.url%self.page_num)self.page_num += 1yield scrapy.Request(new_url, callback=self.parse)
6、图片数据爬取ImagesPipeline
基于scrapy爬取字符串类型的数据后可以直接提交给管道进行存储,但爬取图片需要解析图片的src,然后单独对图片的地址发起请求后去图片二进制类型的数据。pipelines.py里面的类只需要将img的src的属性值进行解析,提交到管道,管道就会对图片的src进行请求发送获取图片的二进制类型的数据,且还会进行持久化存储
在配置文件中添加文件存储目录,修改settings.py
#修改
ITEM_PIPELINES = {# 300表示优先级,数值越小,优先级越高"first.pipelines.imgPipeline": 300,
}# 在配置文件末尾添加文件存储目录
IMAGES_STORE = './imgs'
将pipelines.py文件内容全部删除,修改为如下内容
from scrapy.pipelines.images import ImagesPipeline
import scrapyclass imgPipeLine(ImagesPipeline):# 可以根据图片地址进行图片数据的请求def get_media_requests(self, item, info):yield scrapy.Request(item['src'])# 指定图片存储的路径def file_path(self, request, response=None, info=None, *, item=None):imgName = request.url.split('/')[-1]return imgNamedef item_completed(self, results, item, info):# 返回给下一个即将被执行的管道类return item
main.py内容如下
import scrapy
from first.items import FirstItemclass MainSpider(scrapy.Spider):name = "main"# allowed_domains = ["www.baidu.com"]start_urls = ["..."]def parse(self, response):li_list = response.xpath('...')for li in li_list:item = FirstItem()src = li.xpath('...').extract_first()# 图片地址item['src'] = srcyield item
五、中间件
下载中间件在引警和下载器之间,批量拦截到整个工程中所有的请求和响应
拦截请求作用:UA伪装(在process_request函数中),代理IP(在process_exception函数中 ,这里一定需要return request将修正之后的请求对象进行重写的请求发送)
拦截响应作用:篡改响应数据,响应对象
1、拦截请求中间件(UA伪装,代理IP)
1、打开pycharm的terminal
2、scrapy startproject first
3、cd first
4、scrapy genspider main www.xxx.com
5、修改settings.py里面的ROBOTSTXT_OBEY = True改为False并添加LOG_LEVEL='ERROR'
6、scrapy crawl main (最后一步运行)
项目中的middlewares.py就是对应的中间件,MiddleproSpiderMiddleware类对应的就是爬虫中间件,这里不用可以删除,用的是下载中间件,即MiddleproDownloaderMiddleware类。MiddleproDownloaderMiddleware类中重点的是三个函数,即process_request(拦截请求),process_response(拦截所有响应),process_exception(拦截发送异常请求)
middlewares.py文件内容如下
class MiddleproDownloaderMiddleware:# Not all methods need to be defined. If a method is not defined,# scrapy acts as if the downloader middleware does not modify the# passed objects.@classmethoddef from_crawler(cls, crawler):# This method is used by Scrapy to create your spiders.s = cls()crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)return s# UA池user_agent_list = ["Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 ""(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1","Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 ""(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 ""(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 ""(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6","Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 ""(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 ""(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5","Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 ""(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 ""(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3","Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 ""(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 ""(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 ""(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 ""(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 ""(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 ""(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 ""(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 ""(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 ""(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24","Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 ""(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"]# ipPROXY_http = ['153.180.102.104:80','195.208.131.189:56055']PROXY_https = ['120.83.49.90:9000', '95.189.112.214:35508']# 拦截请求def process_request(self, request, spider):# UA伪装request.headers['User-Agent'] = random.choice(self.user_agent_list)return None# 拦截所有响应def process_response(self, request, response, spider):# Called with the response returned from the downloader.# Must either;# - return a Response object# - return a Request object# - or raise IgnoreRequestreturn response# 拦截发送异常请求def process_exception(self, request, exception, spider):# 当请求IP被禁用,爬取失败,进入到这里# 代理if request.url.split(':')[0] == 'http':request.meta['proxy'] = 'http://' + random.choice(self.PROXY_http)else:request.meta['proxy'] = 'http://' + random.choice(self.PROXY_https)# 将修正之后的请求对象进行重新的请求发送return requestdef spider_opened(self, spider):spider.logger.info("Spider opened: %s" % spider.name)将settings.py中的如下内容的注释取消
# Obey robots.txt rules
ROBOTSTXT_OBEY = False# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {"middlePro.middlewares.MiddleproDownloaderMiddleware": 543,
}
main.py主函数内容如下:
import scrapyclass MiddleSpider(scrapy.Spider):# 爬取百度(搜索ip)name = "middle"# allowed_domains = ["www.xxx.com"]start_urls = ["https://www.baidu.com/s?wd=ip"]def parse(self, response):page_text = response.textwith open('./ip.html', 'w', encoding='utf-8') as fp:fp.write(page_text)2、拦截响应中间件(动态加载)
这里还是用的下载中间件,用来篡改响应数据,响应对象。以爬取某页面数据(标题和内容)为例,通首页解析一些标题栏的板块对应详情页的url(没有动态加载),每一个板块对应的标题都是动态加载出来的(动态加载),通过解析出每一条新闻详情页的url获取详情页的页面源码,解析出其详细的内容
首先创建项目
1、打开pycharm的terminal
2、scrapy startproject wangyipro
3、cd wangyipro
4、scrapy genspider main www.xxx.com
5、修改settings.py里面的ROBOTSTXT_OBEY = True改为False并添加LOG_LEVEL='ERROR'
6、scrapy crawl main (最后一步运行)
注:标题栏每个标题栏里面固定位子的解析方式可能不一样,可能不能解析到正确的内容
settings.py取消如下注释
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {"wangyiPro.middlewares.WangyiproDownloaderMiddleware": 543,
}# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {"wangyiPro.pipelines.WangyiproPipeline": 300,
}
修改items.py
import scrapyclass WangyiproItem(scrapy.Item):# define the fields for your item here like:title = scrapy.Field()content = scrapy.Field()pass
在pipelines.py添加输出
class WangyiproPipeline:# 这里存储数据def process_item(self, item, spider):print(item)return item
修改middlewares.py内容
from scrapy.http import HtmlResponse
from time import sleepclass WangyiproDownloaderMiddleware:# Not all methods need to be defined. If a method is not defined,# scrapy acts as if the downloader middleware does not modify the# passed objects.@classmethoddef from_crawler(cls, crawler):# This method is used by Scrapy to create your spiders.s = cls()crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)return sdef process_request(self, request, spider):# Called for each request that goes through the downloader# middleware.# Must either:# - return None: continue processing this request# - or return a Response object# - or return a Request object# - or raise IgnoreRequest: process_exception() methods of# installed downloader middleware will be calledreturn None# 通过该方法拦截各特定板块对应的响应对象,进行篡改def process_response(self, request, response, spider): # spider爬虫对象# 获取爬虫类转给你定义的浏览器对象bro = spider.bro# 挑选出指定的响应对象进行篡改# 通过url指定让request# 通过request指定responseif request.url in spider.models_urls:# 指定的个板块对应的url进行请求bro.get(response.url)sleep(2)# 包含了动态加载的新闻数据page_text = bro.page_source# response # 特定板块对应的响应对象# 针对定位到的这些response进行篡改# 实例化一个新的响应对象(符合需求:包含动态加载出的新闻数据),替代原来旧的响应对象# 基于selenium便捷的获取动态加载数据new_response = HtmlResponse(url=request.url, body=page_text, encoding='utf-8', request=request)return new_responseelse:# response # 其他请求对应的响应对象return responsedef process_exception(self, request, exception, spider):# Called when a download handler or a process_request()# (from other downloader middleware) raises an exception.# Must either:# - return None: continue processing this exception# - return a Response object: stops process_exception() chain# - return a Request object: stops process_exception() chainpassdef spider_opened(self, spider):spider.logger.info("Spider opened: %s" % spider.name)编写主函数main.py
import scrapy
from selenium import webdriver
from wangyiPro.items import WangyiproItemclass WangyiSpider(scrapy.Spider):name = "wangyi"# allowed_domains = ["www.xxx.com"]start_urls = ["..."]# 存储各板块urlmodels_url = []# 解析各板块对应详情页的url# 实例化浏览器对象def __init__(self):self.bro = webdriver.Chrome(executable_path='')def parse(self, response):li_list = response.xpath('...')# 解析获取每个标题栏的URL,并存储到列表中for li in li_list:model_url = li.xpath('...')[0].extract()self.models_url.append(model_url)# 依次对每个标题栏对应的页面进行请求for url in self.models_url:# 对每个板块的url进行请求发送yield scrapy.Request(url, callback=self.parse_model)# 每一个标题栏对应的内容标题相关的内容都是动态加载# 解析每一个板块页面中对应新闻的标题和新闻详情页的urldef parse_model(self, response):# 因为这里内容是动态加载出来的,所以用通常的方法response.xpath()是抓取不到的,需要在middleware.py文件中的process_response函数中编辑# 标题栏每个标题栏里面固定位子的解析方式可能不一样,需要分析每个页面的解析方式,可以根据属性值匹配div_list = response.xpath('...')for div in div_list:title = div.xpath('').extract_first()new_detail_url = div.xpath('').extract_first()item = WangyiproItem()item['title'] = title# 对新闻详情页的url发起请求yield scrapy.Request(url=new_detail_url, callback=self.parse_detail, meta={'item':item})# 解析新闻内容def parse_detail(self, response):content = response.xpath('').extract()content = ''.join(content)item = response.mate['item']item['content'] = contentyield itemdef close(self, spider):self.bro.quit()
六、CrawlSpider(自动请求全站爬取,全部页面,自动下拉滚轮爬取)
可以提取页面显示栏中显示及未显示页面的所有页码链接等信息
CrawlSpider是Spider的一个子类,和Spider(手动请求)一样可以爬取全站数据
链接提取器:根据指定规则(参数allow=“正则”)进行指定链接的提取
规则解析器:将链接提取器提取到的链接进行指定规则(callback)的解析操作
爬取全站数据:爬取的数据没有在同一个页面,多个页码
1.可以使用链接提取器提取所有的页码链接
2.让链接提取器提取所有的详情页链接
CrawlSpider的使用(加 -t crawl):
1、打开pycharm的terminal
2、scrapy startproject first
3、cd first
4、scrapy genspider -t crawl main www.xxx.com
5、修改settings.py里面的ROBOTSTXT_OBEY = True改为False并添加LOG_LEVEL='ERROR'
6、scrapy crawl main (最后一步运行)
items.py创建两个item类,
import scrapyclass SunproItem(scrapy.Item):# define the fields for your item here like:title = scrapy.Field()new_num = scrapy.Field()class DetailItem(scrapy.Item):new_id = scrapy.Field()content = scrapy.Field()
pipelines.py
class SunproPipeline:def process_item(self, item, spider):# 如何判定item类型if item.__class__.__name__ == 'DetailItem':print(item['new_id'],item['new_content'])else:print(item['new_num'],item['new_title'])return itemsun.py主函数
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from sunPro.item import SunproItem,DetailItem# 需求爬取某网站的所有标签页的所有内容
class SunSpider(CrawlSpider):name = "sun"# allowed_domains = ["www.xxx.com"]start_urls = ["http://www.xxx.com/"]# 链接提取器:根据指定规则(allow="正则")进行指定链接的提取# 提取页码链接link = LinkExtractor(allow=r"Items/")# 提取详情页链接link_detail = LinkExtractor(allow=r"...") ## Rule为规则解析器:将链接提取器提取到的链接进行指定规则(callback)的解析操作# Rule参数:链接提取器# follow改为True可以将链接提取器 继续作用到 链接提取器提取到的链接 所对应的页面中# follow为True可以提取下面显示及未显示页面的所有页码链接# follow为False只能提取下面显示的几个页面的链接# Rule中的callback调用对应parse_item函数rules = (Rule(link, callback="parse_item", follow=True), # 提取页面链接Rule(link_detail, callback='parse_detail')) # 提取详情页链接# 如下两个解析方法中是不可以实现请求传参# 如果将两个解析方法解析的数据存储到同一个item中,可以依次存储到两个item中,在items.py文件中建两个item类def parse_item(self, response):# xpath表达式中不可以出现tbgodybiao标签tr_list = response.xpath('...')for tr in tr_list:new_num = tr.xpath('...').extract_first()new_title = tr.xpath('...').extract_first()item = SunproItem()item['new_num'] = new_numitem['new_title'] = new_title# 解析详情页内容def parse_detail(self, response):new_id = response.xpath('...')new_content = response.xpath('...')item = DetailItem()item['new_id'] = new_iditem['new_content'] = new_content
七、分布式爬虫
搭建一个分布式的机群(多台电脑),当其中一台发出请求(多个url需要爬取),其他机器会一起爬取数据,提高效率
概念:需要搭建一个分布式的机群,让其对一组资源进行分布式联合爬取
作用:提升爬取数据效率
安装scrapy-redis组件pip install scrapy-redis
原生的scrapy不可以实现分布式爬虫,必须让scrapy组合这scrapy-redis组件一起实现分布式爬虫
原生的scrapy不可以实现分布式爬虫是因为调度器和管道都不可以被分布式机群共享
scrapy-redis组件可以给原生的scrapy框架提供可以被共享的管道和调度器
实现流程
创建一个工程
创建一个基于CrawlSpider的爬虫文件
修改当前的爬虫文件:
导包:from scrapy_redis.spoders import RedisCrawlSpider
将start_urls和allowed_domains进行注释
添加一个属性:redis_key = 'sun' 可以被空闲的调度器队列名称
编写数据解析相关的操作
将当前爬虫类的父类修改成RedisCrawlSpider
主函数
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rulefrom scrapy_redis.spiders import RedisCrawlSpider# 需求爬取某网站的所有标签页的所有内容
class SunSpider(RedisCrawlSpider):name = "sun"# allowed_domains = ["www.xxx.com"]# start_urls = ["http://www.xxx.com/"]redis_key = 'sun'link = LinkExtractor(allow=r"Items/")link_detail = LinkExtractor(allow=r"...")rules = (Rule(link, callback="parse_item", follow=True),Rule(link_detail, callback='parse_detail'))def parse_item(self, response):# xpath表达式中不可以出现tbgodybiao标签tr_list = response.xpath('...')for tr in tr_list:new_num = tr.xpath('...').extract_first()new_title = tr.xpath('...').extract_first()item = SunproItem()item['new_num'] = new_numitem['new_title'] = new_titleyield item
修改配置文件settings,除了和上面常规的修改,还有添加如下内容
# 指定使用可以被共享的管道
ITEM_PIPELINES = {'scrapy_redis.pipelines.RedisPipeline':400
}
# 指定调度器
# 增加一个去重容器类的配置,作用使用Redis的set集合来存储请求的指纹数据,从而实现请求取重的持久化存储
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用scrapy_redis组件自己的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 配置调度器是否要持久化,也就是当爬虫结束了,要不要清空Redis中请求队列和去重指纹的set,如果True
SCHEDULER_PERSIST = True# 指定redis服务器
REDIS_HOST = 'redis服务器ip地址' # 写成redis远程服务器的ip
REDIS_PORT = 6379
redis相关操作配置:
配置redis配置文件linux或mac:redis.confwindows:redis.windows.conf打开配置文件修改:将bind 127.0.0.1注释关闭保护模式:protected-mode yes改为no
结合着配置文件开启redis服务redis-server 配置文件
启动客户端redis-cli
执行工程:scrapy runspider xxx.py
向调度器的队列中放入一个起始的url
调度器的队列在redis的客户端中lpush xxx www.xxx.com
爬取到的数据存储在redis的proName:items这个数据结构中
八、增量式爬虫
比如某个网站一定时间会更新一部分内容,有些不会更新,今天我们爬取了网站的所有内容,明天再爬取的时候,我们只需要爬取比昨天新增的内容,原先的不用再爬取,这就是增量式爬虫(如下核心部分)
检测网站数据更新的情况,只会爬取网站最新更新出来的数据
分析:
指定起始url:www.4567tv.tv
基于CrawlSpider获取其他页码链接
基于Rule将其他页码链接进行请求
从每一个页码对应的页面源码中解析出每一个电影详情页的URL
核心:检测电影详情页的url之前有没有请求过将爬取过的电影详情页的URL存储存储到redis的set数据结构(自动清楚重复数据,即存在过添加不进去,返回1表示不存在可以添加,返回0表示存在不添加)
对详情页的url发起请求,然后解析出电影的名称和简介
进行持久化存储
pipelines.py
from redis import Redis
class SunproPipeline:conn = Nonedef open_spider(self, spider):self.conn = spider.conndef process_item(self, item, spider):dic = {'name':item['name']}self.conn.lpush('movieData', dic)return item
主函数
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from sunPro.item import SunproItem,DetailItem
from redis import Redisfrom scrapy_redis.spiders import RedisCrawlSpiderclass SunSpider(RedisCrawlSpider):name = "sun"# allowed_domains = ["www.xxx.com"]start_urls = ["http://www.xxx.com/"]link = LinkExtractor(allow=r"Items/")rules = (Rule(link, callback="parse_item", follow=True))# 创建redis链接对象conn = Redis(host='127.0.0.1', port=6379)def parse_item(self, response):# xpath表达式中不可以出现tbgodybiao标签tr_list = response.xpath('...')for tr in tr_list:detail_url = tr.xpath('...').extract_first()# 将详情页的url存入redis的set中ex = self.conn.sadd('urls', detail_url)# ex=1表示数据结构中不存在该url,即没爬取过,可以爬取# ex=0表示数据结构中存在该url,即之前爬取过,不用爬取if ex == 1:print('该url没有被爬取过')yield scrapy.Request(url=detail_url, callback=self.parst_detail)else:print("该url爬取过,还没更新")# 解析详情页中的电影名称和类型,进行持久化存储def parst_detail(self, response):item = SunproItem()item['name'] = response.xpath('')yield item
相关文章:
Scrapy框架(高效爬虫)
文章目录一、环境配置二、创建项目三、scrapy数据解析四、基于终端指令的持久化存储1、基于终端指令2、基于管道3、数据同时保存至本地及数据库4、基于spider爬取某网站各页面数据5、爬取本页和详情页信息(请求传参)6、图片数据爬取ImagesPipeline五、中…...

程序设计语言-软件设计(二十一)
数据结构与算法(二十)快速排序、堆排序(四)https://blog.csdn.net/ke1ying/article/details/129269655 这篇主要讲的是 编译与解释、文法、正规式、有限自动机、表达式、传值与传址、多种程序语言特点。 编译的过程 解释型 和 编译型 编译型过程&#…...
【小破站下载工具】Python tkinter 实现网站下载工具,所有数据一键获取
目录前言开发环境本次项目案例步骤先展示下完成品的效果界面导入模块先创建个窗口功能按键主要功能代码编写功能一功能二功能三前言 最近很多同学想问我,怎么把几个代码的功能集合到一起? 很简单,写一个界面就行了,想要哪个代码…...

C51---IO口状态翻转
1.example #include "reg52.h" #include "intrins.h" //main.c(11): error C264: intrinsic _nop_: declaration/activation error,?????????? sbit led1 P3^7;//????,??????? sbit key1 P2^1; sbit key2 P2^0; void Delay50ms()…...
-1 ||| 附:【Markdow语法】向上取整 向下取整。)
2023年春【移动计算技术】文献精读(一)-1 ||| 附:【Markdow语法】向上取整 向下取整。
沉默着走了有 // 多遥远 // 抬起头 // 蓦然间 // 才发现 // 一直倒退 // 倒退到原点 // 倔强坚持 // 对抗时间 “在光芒万丈之前,我们都要欣然接受眼下的难堪和不易,接受一个人的孤独和偶然无助,认真做好眼前的每件事,你想要的都会有。”——毕淑敏 🎯作者主页:追光者♂…...

Java 包装类的二进制操作
Integer 位翻转 位翻转就是将二进制左边的位与右边的位进行互换,reverse 是按位进行互换, reverseBytes 是按 byte 进行互换。 public static int reverse(int i)public static int reverseBytes(int i)来看个例子: int a 0x12345678; S…...

CSS居中之 { left:50%; top:50%; transform:translate(-50%,-50%); }
CSS居中之 { left:50%; top:50%; transform:translate(-50%,-50%); } left:50%; top:50%; transform:translate(-50%,-50%); left:50%; top:50%; transform:translate(-50%,-50%);也可以写成: left:50%; top:50%; translate: -50% -50%; left:50%; top:50%; translate: -50%…...

AcWing 4868. 数字替换(DFS + 剪枝优化)
AcWing 4868. 数字替换(DFS 剪枝优化)一、问题二、思路三、代码一、问题 二、思路 题目中要求变换次数最小,其实第一印象应该是贪心,即我们每一次都去成各位中最大的那个数字。但是这个想法很容易推翻。因为你这次乘了一个最大的…...

【教学典型案例】01.redis只管存不管删除让失效时间删除的问题
目录一:背景介绍二:redis1)redis数据类型①String(字符串)②Hash(哈希)③List(列表)④Set(集合)2)缓存同步①设置有效期②同步双写③异步通知3&am…...

电话号码管理
电话号码管理 文章目录 电话号码管理综述链表结构initcreatedeleteallfreeANSI颜色转义颜色列表如下:字背景颜色范围:40--49 字颜色: 30--39输出特效格式控制:光标位置等的格式控制:Makefile顶层Makefilescripts Makefilesearch main init include display delete create all…...

Shell 教程
Shell 是一个用 C 语言编写的程序,它是用户使用 Linux 的桥梁。Shell 既是一种命令语言,又是一种程序设计语言。 Shell 是指一种应用程序,这个应用程序提供了一个界面,用户通过这个界面访问操作系统内核的服务。 Ken Thompson 的…...
Shader 阴影
阴影生成原理 以平行光为例,把相机移动到光源位置,计算阴影映射纹理(shadowmap),这张shadowmap本质上是一张深度图,它记录了从该光源的位置出发、能看到的场景中距离它最近的表面位置(深度信息&…...
【冲刺蓝桥杯的最后30天】day2
大家好😃,我是想要慢慢变得优秀的向阳🌞同学👨💻,断更了整整一年,又开始恢复CSDN更新,从今天开始更新备战蓝桥30天系列,一共30天,如果对你有帮助或者正在备…...

docker系列1:docker安装
传送门 docker官网地址: Docker: Accelerated, Containerized Application Development 安装地址:Install Docker Engine docker hub地址 docker hub:Docker 安装步骤 前置条件 由于安装docker,需要根据操作系统版本选择…...
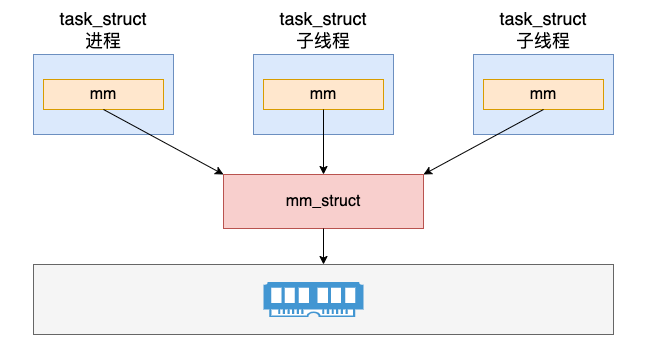
内核角度谈谈Linux进程和线程
目录前言内核对进程和线程的表示创建进程的过程创建线程的过程创建进程和线程的异同揭秘 do_fork 系统调用结论前言 昨天面试的时候,面试官问我了个平平淡淡的问题–>“聊聊Linux中进程和线程”; 相比大家不管是在考试还是面试中或多或少都遇到过这个问题&…...

【mmdeploy部署系列】使用Tensorrt加速部署mmpose人体姿态库
【mmdeploy部署系列】使用Tensorrt加速部署mmpose人体姿态库0.引言1.安装mmcv2.使用mmpose(1)安装mmpose(2)运行mmpose3.使用mmdeploy(1)安装ppl.cv(2)编译安装mmdeploy(…...

IDEA 每次新建工程都要重新配置 Maven 解决方案
IDEA 每次新建工程都要重新配置 Maven 解决方案 IDEA 每次新建工程都要重新配置 Maven,是一件相当浪费时间的事情。这是因为在创建一个项目后,在 File -> Settings -> Build,Execution,Deployment -> Build Tools -> Maven下配置了 Maven h…...
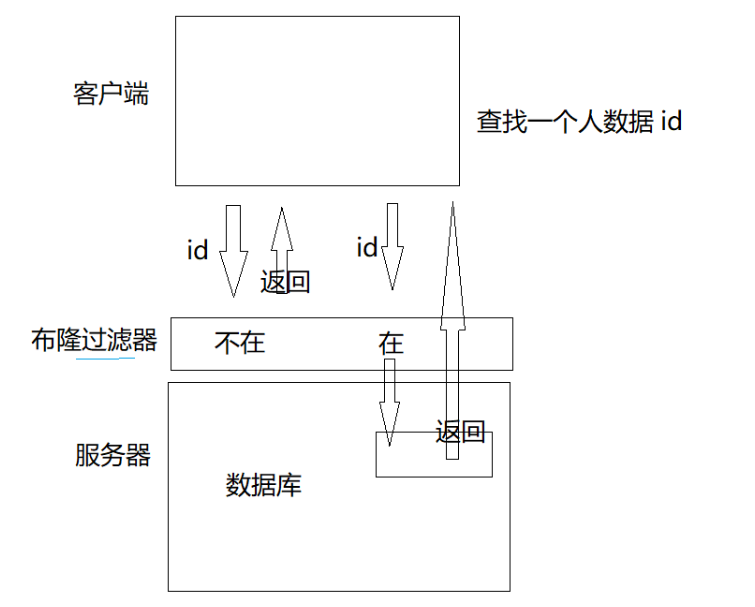
【C++修炼之路】25.哈希应用--布隆过滤器
每一个不曾起舞的日子都是对生命的辜负 布隆过滤器前言一.布隆过滤器提出二.布隆过滤器概念三. 布隆过滤器的操作3.1 布隆过滤器的插入3.2 布隆过滤器的查找3.3 布隆过滤器的删除四.布隆过滤器的代码4.1 HashFunc的仿函数参考4.2 BloomFilter.h五.布隆过滤器的优缺点六.布隆过滤…...

linux入门---权限
目录标题什么是权限人的分类为什么会有所属组查看文件属性文件的分类如何查看权限文件不同权限的表现rwx权限修改八进制权限修改umask有关内容文件中人的修改目录不同权限的表现rwx什么是权限 首先来看一个例子:比如说我没有爱奇艺的vip,那么我也就没有…...
Unity记录2.1-动作-多段跳、蹬墙跳、墙体滑落
文章首发及后续更新:https://mwhls.top/4450.html,无图/无目录/格式错误/更多相关请至首发页查看。 新的更新内容请到mwhls.top查看。 欢迎提出任何疑问及批评,非常感谢! 汇总:Unity 记录 摘要:实现跳跃、蹬…...

Obsidian-skills恢复环境:3步从备份快速恢复技能配置和数据
Obsidian-skills恢复环境:3步从备份快速恢复技能配置和数据 【免费下载链接】obsidian-skills Agent skills for Obsidian. Teach your agent to use Markdown, Bases, JSON Canvas, and use the CLI. 项目地址: https://gitcode.com/GitHub_Trending/ob/obsidian…...

Ansible Roles深度指南:如何像搭积木一样管理复杂Playbook?
Ansible Roles架构设计:构建企业级配置管理的乐高积木 在电商系统多环境部署的复杂场景中,开发团队经常面临这样的困境:测试环境的配置意外污染了生产环境,不同服务间的变量命名冲突导致部署失败,或者新增服务器时需要…...
)
Python实战:5分钟搞定微博爬虫,自动备份你的微博内容(附完整代码)
Python实战:5分钟搞定微博个人内容备份(零基础友好版) 每次刷微博时,看到自己多年前发的动态总有种时光穿越的错觉。那些深夜的碎碎念、旅行的打卡照、突发奇想的段子,都是珍贵的数字记忆。但平台内容随时可能调整展示…...

Palworld存档转换工具终极指南:轻松编辑游戏数据的完整方案
Palworld存档转换工具终极指南:轻松编辑游戏数据的完整方案 【免费下载链接】palworld-save-tools Tools for converting Palworld .sav files to JSON and back 项目地址: https://gitcode.com/gh_mirrors/pa/palworld-save-tools Palworld存档工具是一个强…...

DecompilerMC:揭秘Minecraft源码反编译的高效方案
DecompilerMC:揭秘Minecraft源码反编译的高效方案 【免费下载链接】DecompilerMC This repository allows you to decompile any minecraft version that was published after 19w36a without any 3rd party mappings, you just need to execute the script or the …...

WiFi密码安全测试:如何用hashcat的掩码模式快速爆破简单密码?
WiFi密码安全测试:hashcat掩码模式的高效爆破策略 在网络安全评估中,WiFi密码强度测试是基础但关键的一环。传统字典攻击虽然简单直接,但面对特定密码模式时效率低下。本文将深入探讨如何利用hashcat的掩码模式(Mask Attack&#…...

微软VibeVoice-TTS真实案例:用AI生成多人访谈节目音频
微软VibeVoice-TTS真实案例:用AI生成多人访谈节目音频 1. 从零开始认识VibeVoice-TTS 你是否曾经想过,用AI来制作一档完整的访谈节目?不是简单的单人口播,而是包含主持人、嘉宾互动、自然对话转折的专业级音频内容。微软开源的V…...

3步找回青春记忆:GetQzonehistory完整导出QQ空间说说终极指南
3步找回青春记忆:GetQzonehistory完整导出QQ空间说说终极指南 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你是否曾在深夜翻看QQ空间,想要重温那些年写下的心…...

保姆级教程:用LangFlow可视化工具3步搭建智能问答机器人,无需代码
保姆级教程:用LangFlow可视化工具3步搭建智能问答机器人,无需代码 1. 为什么选择LangFlow? 想象一下,你有一个绝妙的AI应用创意,但面对复杂的代码和API文档却无从下手。LangFlow就是为解决这个问题而生的可视化工具&…...

OpenClaw电商运营助手:Qwen2.5-VL-7B批量生成商品图文详情
OpenClaw电商运营助手:Qwen2.5-VL-7B批量生成商品图文详情 1. 为什么需要自动化商品详情生成 每次大促前,运营团队最头疼的就是商品详情页的批量更新。去年双十一前,我手动处理了200多个SKU的图文优化,连续加班一周后࿰…...