【C++修炼之路】25.哈希应用--布隆过滤器
每一个不曾起舞的日子都是对生命的辜负

布隆过滤器
- 前言
- 一.布隆过滤器提出
- 二.布隆过滤器概念
- 三. 布隆过滤器的操作
- 3.1 布隆过滤器的插入
- 3.2 布隆过滤器的查找
- 3.3 布隆过滤器的删除
- 四.布隆过滤器的代码
- 4.1 HashFunc的仿函数参考
- 4.2 BloomFilter.h
- 五.布隆过滤器的优缺点
- 六.布隆过滤器的应用场景
前言
上一节中,我们学到了位图,可以看出位图有如下优点:1.节省空间。2.快。
但相对的,位图同样有缺点存在:1. 一般要求范围相对集中,如果范围特别分散,空间消耗就会上升。2. 只能针对整形
那如果此时是字符串类型,能不能通过位图的思想来确定字符串在不在呢?
一.布隆过滤器提出
我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉那些已经看过的内容。问题来了,新闻客户端推荐系统如何实现推送去重的? 用服务器记录了用户看过的所有历史记录,当推荐系统推荐新闻时会从每个用户的历史记录里进行筛选,过滤掉那些已经存在的记录。 如何快速查找呢?
- 用哈希表存储用户记录,缺点:浪费空间
- 用位图存储用户记录,缺点:位图一般只能处理整形,如果内容编号是字符串,就无法处理了。
- 将哈希与位图结合,即布隆过滤器
即通过位图的方式确定字符串在还是不在,我们可以采用HashFunc将字符串转换成整形映射到位图中,这就是布隆过滤器。
二.布隆过滤器概念
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。
但实际上这种布隆过滤器的方式可能会产生误判:
- 在是不一定准确的。(hashFunc映射冲突)
- 不在一定是准确的。
可能存在是因为映射可能出现重复,即产生冲突,这是布隆过滤器无法避免的,但是可以通过增加HashFunc的映射次数从而降低冲突引起的误判率。

如图,映射之后,当查找时,如果三个映射值都不为0,那么可以大概认为这个变量是存在的。(映射越多,越准确)当然映射越多的话,同样会浪费空间,因此需要根据需求设计HashFunc的个数。
如何选择哈希函数个数和布隆过滤器长度
很显然,过小的布隆过滤器很快所有的 bit 位均为 1,那么查询任何值都会返回“可能存在”,起不到过滤的目的了。布隆过滤器的长度会直接影响误报率,布隆过滤器越长其误报率越小。
另外,哈希函数的个数也需要权衡,个数越多则布隆过滤器 bit 位置位 1 的速度越快,且布隆过滤器的效率越低;但是如果太少的话,那我们的误报率会变高。
k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数,p 为误报率
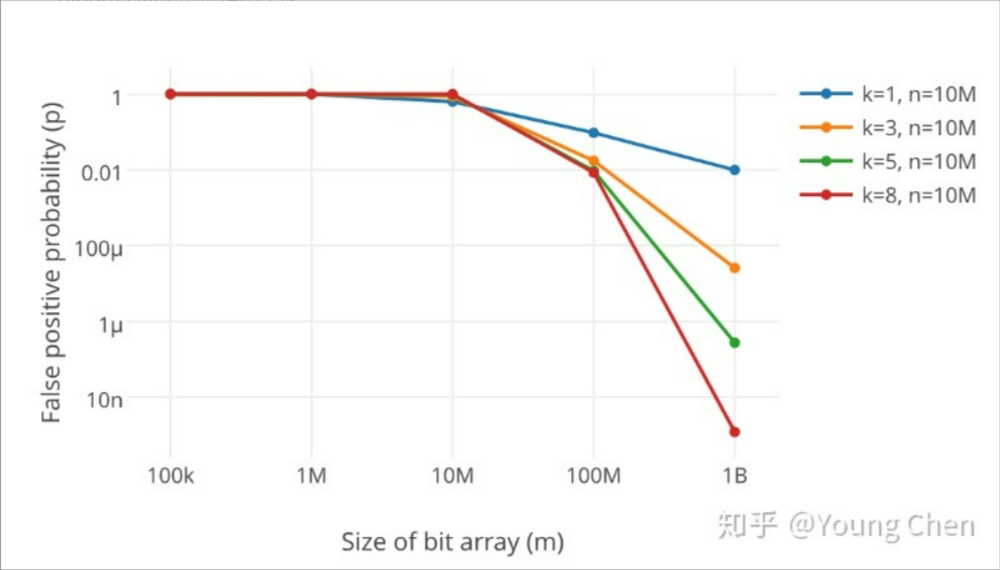
如何选择适合业务的 k 和 m 值呢,这里直接贴一个公式:k=m∗ln2/nk = m*ln2 / nk=m∗ln2/n
可以看出,当k=3时,m≈4.2*n。因此,下面代码中我们采用5*N大小的布隆过滤器长度无疑是非常合适的。
三. 布隆过滤器的操作
上述虽然将大致的思路提到,但还是需要具体描述一下步骤
3.1 布隆过滤器的插入
向布隆过滤器中插入:“baidu”
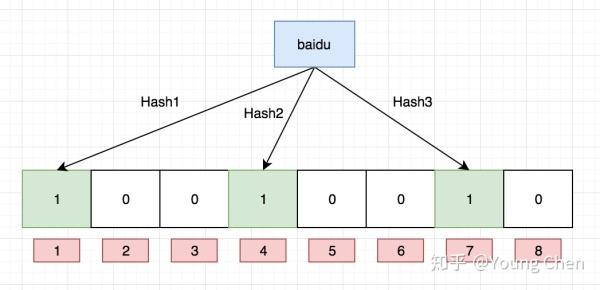
此过程就需要用到指定的HashFunc了。
3.2 布隆过滤器的查找
布隆过滤器的思想是将一个元素用多个哈希函数映射到一个位图中,因此被映射到的位置的比特位一定为1。所以可以按照以下方式进行查找:分别计算每个哈希值对应的比特位置存储的是否为零,只要有一个为零,代表该元素一定不在哈希表中,否则可能在哈希表中。
注意:布隆过滤器如果说某个元素不存在时,该元素一定不存在,如果该元素存在时,该元素可能存在,因为有些哈希函数存在一定的误判。
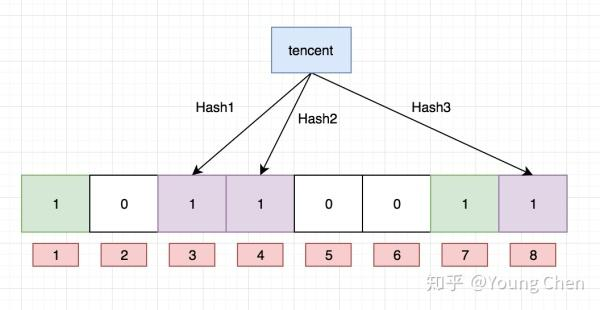
比如:在布隆过滤器中查找"alibaba"时,假设3个哈希函数计算的哈希值为:1、3、7,刚好和其他元素的比特位重叠,此时布隆过滤器告诉该元素存在,但实该元素是不存在的。
3.3 布隆过滤器的删除
布隆过滤器不能直接支持删除工作,因为在删除一个元素时,可能会影响其他元素。
比如:删除上图中"tencent"元素,如果直接将该元素所对应的二进制比特位置0,“baidu”元素也被删除了,因为这两个元素在多个哈希函数计算出的比特位上刚好有重叠。
一种支持删除的方法:将布隆过滤器中的每个比特位扩展成一个小的计数器,插入元素时给k个计数器(k个哈希函数计算出的哈希地址)加一,删除元素时,给k个计数器减一,通过多占用几倍存储空间的代价来增加删除操作。
缺陷:
- 无法确认元素是否真正在布隆过滤器中
- 存在计数回绕
四.布隆过滤器的代码
4.1 HashFunc的仿函数参考
各种字符串Hash函数 - clq - 博客园 (cnblogs.com)
我们没必要重复造轮子,因此直接采用上面链接的仿函数即可,有评分高的选高的,有需要就稍微改一下参数类型即可。
4.2 BloomFilter.h
#pragma once
#include<bitset>//设置的仿函数
struct BKDRHash
{size_t operator()(const string& key){size_t hash = 0;for (auto ch : key){hash *= 131;hash += ch;}return hash;}
};struct APHash
{size_t operator()(const string& key){unsigned int hash = 0;int i = 0;for (auto ch : key){if ((i & 1) == 0){hash ^= ((hash << 7) ^ (ch) ^ (hash >> 3));}else{hash ^= (~((hash << 11) ^ (ch) ^ (hash >> 5)));}i++;}return hash;}
};struct DJBHash
{size_t operator()(const string& key){unsigned int hash = 5381;for (auto ch : key){hash += (hash >> 5) + ch;}return hash;}
};template<size_t N,size_t X = 5,class K = string,class HashFunc1 = BKDRHash,class HashFunc2 = APHash,class HashFunc3 = DJBHash>class BloomFilter
{
public:void set(const K& key){size_t hash1 = HashFunc1()(key) % (X * N);size_t hash2 = HashFunc2()(key) % (X * N);size_t hash3 = HashFunc3()(key) % (X * N);_bs.set(hash1);_bs.set(hash2);_bs.set(hash3);}bool test(const K& key){size_t hash1 = HashFunc1()(key) % (X * N);if (!_bs.test(hash1))//如果不在,没必要往后走了{return false;//不存在误判}size_t hash2 = HashFunc2()(key) % (X * N);if (!_bs.test(hash2))//如果不在,没必要往后走了{return false;//不存在误判}size_t hash3 = HashFunc3()(key) % (X * N);if (!_bs.test(hash3))//如果不在,没必要往后走了{return false;//不存在误判}return true;//可能存在误判}
private:std::bitset<N * X> _bs;};
通过大量的数据可以判断冲突率:
void test_bloomfilter2()
{srand(time(0));const size_t N = 100000;BloomFilter<N> bf;std::vector<std::string> v1;std::string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";for (size_t i = 0; i < N; ++i){v1.push_back(url + std::to_string(i));}for (auto& str : v1){bf.set(str);}// v2跟v1是相似字符串集,但是不一样std::vector<std::string> v2;for (size_t i = 0; i < N; ++i){std::string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";url += std::to_string(999999 + i);v2.push_back(url);}size_t n2 = 0;for (auto& str : v2){if (bf.test(str)){++n2;}}cout << "相似字符串误判率:" << (double)n2 / (double)N << endl;// 不相似字符串集std::vector<std::string> v3;for (size_t i = 0; i < N; ++i){string url = "zhihu.com";url += std::to_string(i + rand());v3.push_back(url);}size_t n3 = 0;for (auto& str : v3){if (bf.test(str)){++n3;}}cout << "不相似字符串误判率:" << (double)n3 / (double)N << endl;
}
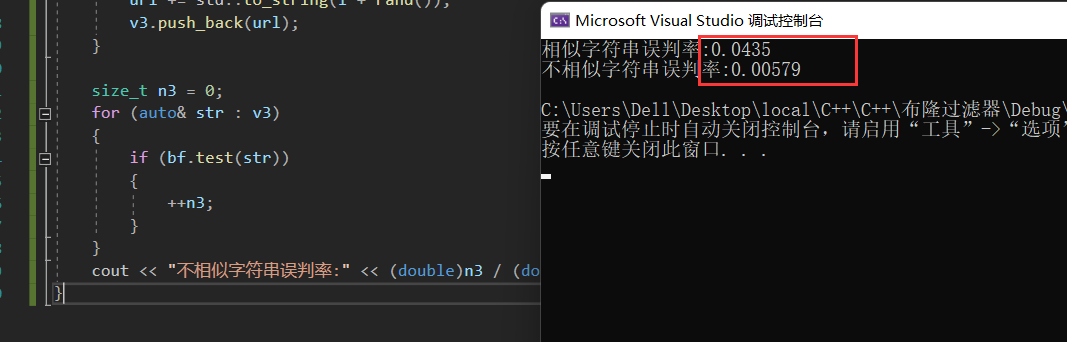
通过控制X,X越大,空间就越大,越不易产生冲突,误判率越低。当然,增加HashFunc也可以降低误判率。
五.布隆过滤器的优缺点
优点:
-
增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无关
-
哈希函数相互之间没有关系,方便硬件并行运算
-
布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
-
在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势
-
数据量很大时,布隆过滤器可以表示全集,其他数据结构不能
-
使用同一组散列函数的布隆过滤器可以进行交、并、差运算
缺点:
- 有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再
建立一个白名单,存储可能会误判的数据) - 不能获取元素本身
- 一般情况下不能从布隆过滤器中删除元素
- 如果采用计数方式删除,可能会存在计数回绕问题
六.布隆过滤器的应用场景
不需要一定准确的场景。注册时候的昵称判重。提高效率
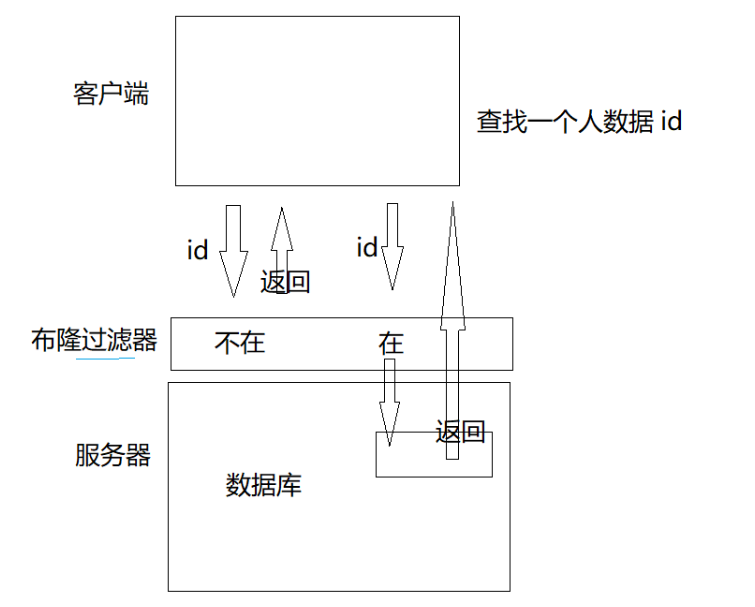
在客户端和数据库之间建立一个布隆过滤器,如果通过布隆的结果发现没有找到,那么一定不在,也就不用继续向数据库中查找了。如果在,那么就需要进数据库中一一查找,因为布隆对于找到的值是不一定存在的。所以通过布隆可以提高数据不在时查找的效率。
相关文章:
【C++修炼之路】25.哈希应用--布隆过滤器
每一个不曾起舞的日子都是对生命的辜负 布隆过滤器前言一.布隆过滤器提出二.布隆过滤器概念三. 布隆过滤器的操作3.1 布隆过滤器的插入3.2 布隆过滤器的查找3.3 布隆过滤器的删除四.布隆过滤器的代码4.1 HashFunc的仿函数参考4.2 BloomFilter.h五.布隆过滤器的优缺点六.布隆过滤…...

linux入门---权限
目录标题什么是权限人的分类为什么会有所属组查看文件属性文件的分类如何查看权限文件不同权限的表现rwx权限修改八进制权限修改umask有关内容文件中人的修改目录不同权限的表现rwx什么是权限 首先来看一个例子:比如说我没有爱奇艺的vip,那么我也就没有…...
Unity记录2.1-动作-多段跳、蹬墙跳、墙体滑落
文章首发及后续更新:https://mwhls.top/4450.html,无图/无目录/格式错误/更多相关请至首发页查看。 新的更新内容请到mwhls.top查看。 欢迎提出任何疑问及批评,非常感谢! 汇总:Unity 记录 摘要:实现跳跃、蹬…...
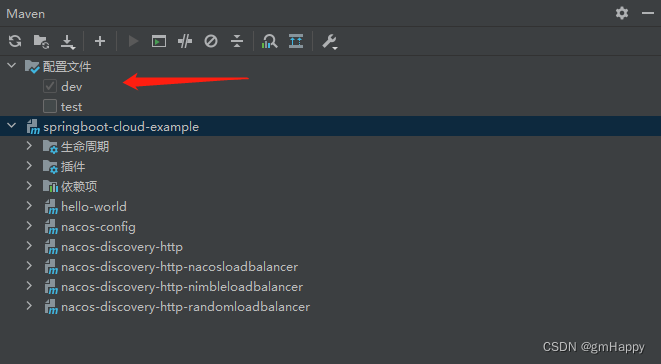
Spring Boot结合IDEA自带Maven插件快速切换profile | Spring Cloud 10
一、前言 IDEA是目前 Java 开发者中使用最多的开发工具,它有着简约的设计风格,强大的集成工具,便利的快捷键。 在项目项目整个开发运维周期中,我们的的项目往往需要根据不同的环境,使用不同的文件配置。 比如以下部…...
ES 7.7.0 数据迁移
本文使用 elasticdump 做数据迁移,支持在线和离线俩种方式,适用于数据量比较小的情况。 1、Node 安装 由于elasticdump 依赖于 node,首先需要安装下node。 1.1、 Linux 安装 $ wget https://nodejs.org/dist/v10.15.0/node-v10.15.0-linu…...

【玩转c++】vector讲解和模拟底层实现
本期主题:vector的讲解和模拟实现博客主页:小峰同学分享小编的在Linux中学习到的知识和遇到的问题小编的能力有限,出现错误希望大家不吝赐vector的介绍及使用1.1vector的介绍vector其实就是一个数组的模板 ,存放的数据可以改变而已…...

基本类型、包装类型、引用类型、String等作为实参传递后值会不会改变?
看了半天帖子,讲得乱七八糟,坑死了 [1] 先说结论 基本类型、包装类型、String类型作为参数传递之后,在方法里面修改他们的值,原值不会改变!引用类型不一定,要看是怎么修改它的。 [2] 为什么基本类型、包装类…...
Tomcat服务器配置以及问题解决方案
文章目录01 Tomcat简介02 Tomcat的安装03 Tomcat的使用启动Tomcat服务器 (解决一闪而过)测试 Tomcat 是否启动Tomcat 服务器的关闭04 Tomcat的配置配置端口控制台配置(乱码解决)部署工程到Tomcat中01 Tomcat简介 Tomcat是一款开源…...

【Node.js】HTTP协议、HTTP的请求报文和响应报文
HTTP协议、HTTP的请求报文和响应报文HTTP协议HTTP主要特点HTTP的请求报文和响应报文请求报文请求行请求消息头空行请求体响应报文响应状态行响应消息头空行响应体总结HTTP协议 HTTP 全称为超文本传输协议,是用于从WWW服务器传输超文本到本地浏览器的传送协议&#…...

CodeForce 455A. Boredom
题目链接 CodeForce 455A. Boredom 思路 因为跟序列的下标无关,所以先对数组a排个序。那么每次选择只会影响两侧的元素。 记号 令dp[i]dp[i]dp[i]表示排序后a[1..i]a[1..i]a[1..i]能够获得的最大点数。 但是这样不足以区分是否当前元素可以被使用,所…...

geoserver之BlobStores使用
概述 geoserver是常用的地图服务器之一,除了基本的能力之外,也提供了很多的插件方便大家使用。在本文,讲述一下如何在geoserver中使用BlobStores和gwc-sqlite-plugin插件实现地图的切片和部署。 BlobStores简介 在geoserver中,…...

跨域问题以及Ajax和Axios的区别
文章目录1. 同源策略2. 同源策略案例3. 什么是跨域4. 跨域解决方法4.1 Ajax的jsonp4.2 CORS方式4.3 Nginx 反向代理5. Axios 和 Ajax 的区别6. Axios 和 Ajax 的区别及优缺点6.1 Ajax:6.1.1 什么是Ajax6.1.2 Ajax的原理6.1.3 核心对象6.1.4 Ajax优缺点6.1.4.1 优点&…...
现代卷积神经网络(AlexNet)
专栏:神经网络复现目录 本章介绍的是现代神经网络的结构和复现,包括深度卷积神经网络(AlexNet),VGG,NiN,GoogleNet,残差网络(ResNet),稠密连接网络…...
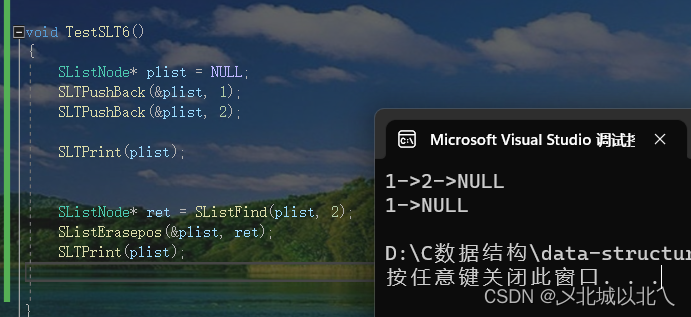
单向非循环链表
1、顺序表遗留问题 1. 中间/头部的插入删除,时间复杂度为O(N) 2. 增容需要申请新空间,使用malloc、realloc等函数拷贝数据,释放旧空间。会有不小的消耗。 3. 当我们以2倍速度增容时,势必会有一定的空间浪费。例如当前容量为100&a…...

Vue2的基本内容(一)
目录 一、插值语法 二、数据绑定 1.单向数据绑定 2.双向数据绑定 三、事件处理 1.绑定监听 2.事件修饰符 四、计算属性computed和监视属性watch 1.计算属性-computed 2.监视属性-watch (1)通过 watch 监听 msg 数据的变化 (2&a…...

蚁群算法优化最优值
%%%%%%%%%%%%%%蚁群算法求函数极值%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%初始化%%%%%%%%%%%%%%%%%%%%% clear all; %清除所有变量 close all; %清图 clc; %清屏 m 20; %蚂蚁个数 G 500; %最大迭代次数 Rho 0.9; %信息素蒸发系数 P0 0.2; %转移概率常数 XMAX 5; %搜索变量 x…...

Docker镜像的内部机制
Docker镜像的内部机制 镜像就是一个打包文件,里面包含了应用程序还有它运行所依赖的环境,例如文件系统、环境变量、配置参数等等。 环境变量、配置参数这些东西还是比较简单的,随便用一个 manifest 清单就可以管理,真正麻烦的是文…...
每日的时间安排规划
14:23 2023年3月4日星期六 开始 现在我要做一套试卷。模拟6级考试。 现在是: 16:22 2023年3月4日星期六。 做完了线上的试卷! 发现我真的是不太聪明的样子! 明明买的有历年真题,做真题就行了,还要做它们出的模拟的…...
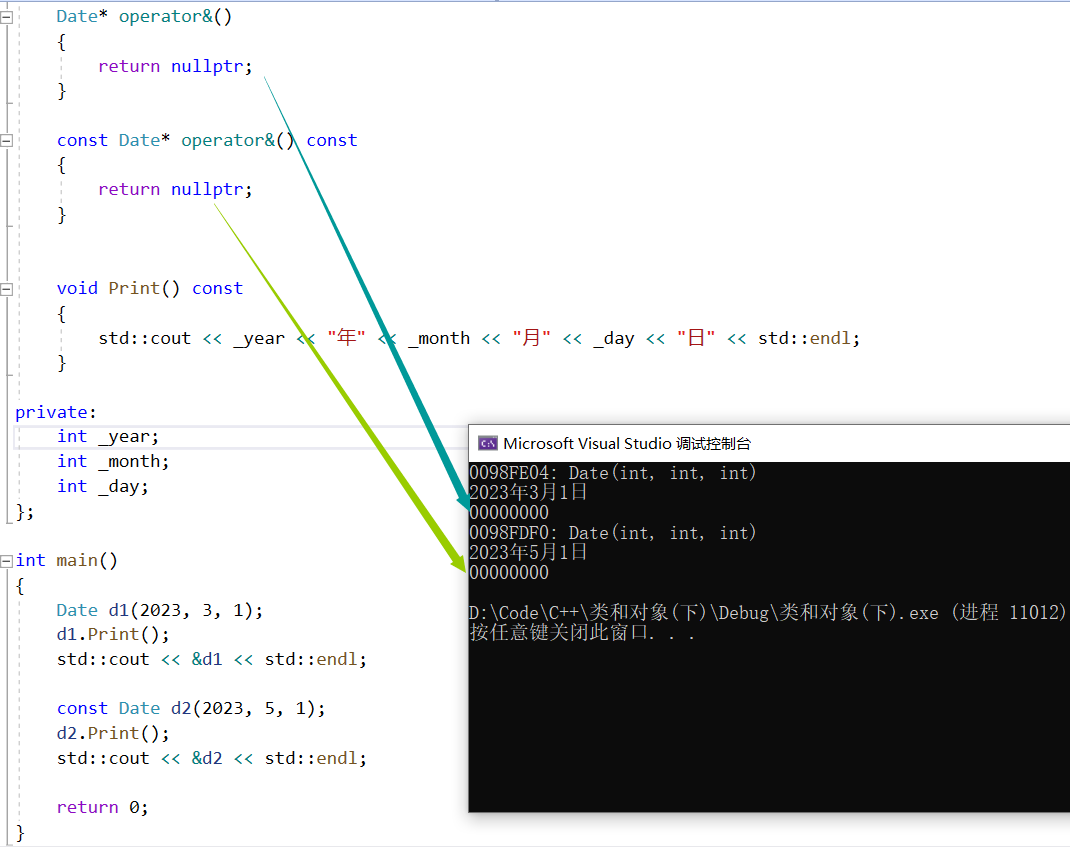
【C++】类和对象——六大默认成员函数
🏖️作者:malloc不出对象 ⛺专栏:C的学习之路 👦个人简介:一名双非本科院校大二在读的科班编程菜鸟,努力编程只为赶上各位大佬的步伐🙈🙈 目录前言一、类的6个默认成员函数二、构造…...

远程debug被arthas watch了的idea
开发工具idea端(2021.2.1) 远程调试 被 应用了 修改的arthas端 的 鸡idea端(2022.3.2) A. 鸡idea端 鸡idea: “D:\IntelliJ IDEA 2022.3.2\bin\idea64.exe” 中安装有目标插件 比如 RedisNew-2022.07.24.zip 对文件 “D:\IntelliJ IDEA 2022.3.2\bin\idea64.exe.vmoptions” 新…...

AI辅助开发:探索快马AI生成智能命令提示与分析的下一代终端工具
今天想和大家分享一个有趣的开发实践:如何用前端技术模拟实现一个具备AI辅助功能的智能命令行终端Web应用。这个项目的灵感来源于日常开发中频繁使用终端工具时遇到的痛点,比如记不住复杂命令、报错信息难以理解等问题。 基础终端界面搭建 首先需要创建一…...

AITemplate终极指南:动态形状与静态形状性能对比及选择策略
AITemplate终极指南:动态形状与静态形状性能对比及选择策略 【免费下载链接】AITemplate AITemplate is a Python framework which renders neural network into high performance CUDA/HIP C code. Specialized for FP16 TensorCore (NVIDIA GPU) and MatrixCore (…...

JSP 核心基础|动作标签与内置对象全解析
目录 一、JSP 核心基础 二、JSP 动作元素 1. include 动作标签 案例: (1)被包含页面(includedemo.jsp) (2)主包含页面(testinclude.jsp) 2. forward 动作标签 案…...

一次企业知识库同步系统改造复盘:从全量拉取到增量消息的演进与多级缓存一致性保障
2026 年 4 月 6 日凌晨 3:17,我们收到一条告警:知识库同步服务 CPU 飙升至 98%,同步任务积压超过 12 万条,下游 AI 助手响应延迟突破 8 秒。这不是第一次了——过去三个月,每逢周一早高峰或知识库批量更新后࿰…...
)
用Python和Keras从零搭建一个BiLSTM入侵检测模型(基于NSL-KDD数据集)
用Python和Keras从零搭建BiLSTM入侵检测模型实战指南 在网络安全领域,入侵检测系统(IDS)正经历着从传统规则匹配到智能分析的范式转变。本文将带您使用Python生态中的Keras框架,基于经典的NSL-KDD数据集,构建一个具备实战价值的双向长短期记…...

PyTorch Playground量化评估报告:不同bit宽度的精度损失分析
PyTorch Playground量化评估报告:不同bit宽度的精度损失分析 【免费下载链接】pytorch-playground Base pretrained models and datasets in pytorch (MNIST, SVHN, CIFAR10, CIFAR100, STL10, AlexNet, VGG16, VGG19, ResNet, Inception, SqueezeNet) 项目地址: …...

别再手动配IP了!用NI-USRP Configuration Utility快速搞定USRP 2954与LabVIEW连接
告别手动配置:NI-USRP Configuration Utility 快速连接 USRP 2954 与 LabVIEW 全攻略 刚拿到 USRP 2954 设备时,许多工程师和研究人员的第一道坎往往不是复杂的信号处理算法,而是看似基础却令人头疼的网络配置问题。传统的手动 IP 配置方式不…...

手机网站优化与App优化有什么不同_网站 SEO 外链建设应该如何进行
手机网站优化与App优化有什么不同_网站 SEO 外链建设应该如何进行 在当今移动互联网时代,无论是手机网站优化还是App优化,都是提升用户体验和提高网站流量的重要手段。这两者之间有许多不同之处,特别是在搜索引擎优化(SEO&#x…...

MacBook安装OpenClaw全记录:Phi-3-vision-128k-instruct多模态初体验
MacBook安装OpenClaw全记录:Phi-3-vision-128k-instruct多模态初体验 1. 为什么选择OpenClawPhi-3组合 去年第一次听说OpenClaw时,我就被这个"能直接操作电脑的AI助手"吸引了。作为一个经常需要处理多模态内容的创作者,传统AI工具…...

CosyVoice语音生成效果对比:原声vs克隆声,几乎听不出区别
CosyVoice语音生成效果对比:原声vs克隆声,几乎听不出区别 1. 语音克隆技术的新高度 最近测试了CosyVoice语音克隆模型的效果,结果让我大吃一惊。这个由阿里巴巴通义实验室开发的语音生成模型,仅需3-10秒的参考音频就能克隆出几乎…...