《Pandas 简易速速上手小册》第8章:Pandas 高级数据分析技巧(2024 最新版)

文章目录
- 8.1 使用 apply 和 map 函数
- 8.1.1 基础知识
- 8.1.2 重点案例:客户数据清洗和转换
- 8.1.3 拓展案例一:产品评分调整
- 8.1.4 拓展案例二:地址格式化
- 8.2 性能优化技巧
- 8.2.1 基础知识
- 8.2.2 重点案例:大型销售数据分析
- 8.2.3 拓展案例一:内存优化通过更高效的数据类型
- 8.2.4 拓展案例二:使用并行处理加速数据清洗
- 8.3 处理大型数据集
- 8.3.1 基础知识
- 8.3.2 重点案例:分块读取并处理销售数据
- 8.3.3 拓展案例一:使用高效数据格式存储和读取
- 8.3.4 拓展案例二:利用 Dask 处理超大数据集
8.1 使用 apply 和 map 函数
在 Pandas 中,apply 和 map 函数是进行数据转换和运算的强大工具,它们提供了一种高效的方法来处理数据集中的元素。
8.1.1 基础知识
- apply 函数: 可以在 DataFrame 的轴(行或列)上应用一个函数,适用于需要访问多个列,或整个行/列的操作。
- map 函数: 主要用于 Series,将一个函数映射到 Series 的每个元素上,适用于元素级的转换和运算。
- applymap 函数: 在 DataFrame 的每个元素上应用一个函数,适用于元素级的操作,是
map函数在 DataFrame 上的对应操作。
8.1.2 重点案例:客户数据清洗和转换
假设你有一份包含客户信息的数据集,需要进行数据清洗和转换。
数据准备
import pandas as pd# 示例客户数据
customer_data = {'name': ['Alice Smith', 'bob Johnson', 'CHARLIE BROWN'],'age': ['25', 'thirty-five', '40'],'email': ['alice@example.com', 'BOB@example.com', 'charlie@example.net']
}
customer_df = pd.DataFrame(customer_data)
数据清洗和转换
# 标准化姓名格式:首字母大写,其他字母小写
customer_df['name'] = customer_df['name'].apply(lambda x: x.title())# 转换年龄为数值类型:将非数字的年龄转换为 NaN,然后填充平均年龄
customer_df['age'] = pd.to_numeric(customer_df['age'], errors='coerce').fillna(customer_df['age'].dropna().astype(int).mean())# 邮箱地址转小写
customer_df['email'] = customer_df['email'].map(lambda x: x.lower())
8.1.3 拓展案例一:产品评分调整
有一份包含产品评分的数据集,需要对评分进行一定的调整。
数据准备
# 示例产品评分数据
product_scores = {'product_id': [1, 2, 3],'score': [4, 3.5, 5]
}
scores_df = pd.DataFrame(product_scores)
评分调整
# 对评分加权调整:评分低于5的乘以1.1,但不超过5
scores_df['adjusted_score'] = scores_df['score'].apply(lambda x: min(x * 1.1, 5))
8.1.4 拓展案例二:地址格式化
假设有一份包含客户地址的数据集,需要将地址格式统一化,去除多余的空格和标点。
数据准备
# 示例客户地址数据
address_data = {'customer_id': [1, 2, 3],'address': ['123 Elm St.', ' 456 Maple Ave', '789 Oak Dr, ']
}
address_df = pd.DataFrame(address_data)
地址格式化
# 去除地址中的标点和多余空格
import re
address_df['address'] = address_df['address'].apply(lambda x: re.sub(r'[^\w\s]', '', x.strip()))
通过这些案例,我们展示了如何使用 apply 和 map 函数进行数据清洗和转换。这些函数为处理复杂的数据转换提供了灵活而强大的方法,使得数据预处理变得更加高效和简洁。

8.2 性能优化技巧
在处理大型数据集时,性能成为一个不可忽视的因素。优化数据处理性能不仅可以节省时间,还能提高数据分析的效率。
8.2.1 基础知识
- 向量化操作: 利用 Pandas 和 NumPy 的向量化操作代替循环,可以显著提高执行速度。
- 使用更高效的数据类型: 比如将浮点数列转换为整数类型(如果可能),使用分类类型等,可以减少内存使用。
- 批处理处理大数据: 分批次处理数据而不是一次性加载整个数据集到内存中。
- 并行处理: 在可能的情况下,利用多核 CPU 进行并行处理。
8.2.2 重点案例:大型销售数据分析
假设你有一份非常大的销售数据集,需要计算每个产品的总销售额。
数据准备
import pandas as pd
import numpy as np# 生成大型销售数据示例
np.random.seed(0)
sales_data = {'product_id': np.random.randint(1, 100, 1000000),'sales_amount': np.random.rand(1000000) * 100
}
sales_df = pd.DataFrame(sales_data)
性能优化
# 向量化计算总销售额
total_sales = sales_df.groupby('product_id')['sales_amount'].sum()
8.2.3 拓展案例一:内存优化通过更高效的数据类型
处理包含数百万条记录的客户数据集,需要将数据类型转换为更高效的格式以减少内存使用。
数据准备
# 生成大型客户数据示例
customer_data = {'customer_id': np.arange(1, 1000001),'age': np.random.randint(18, 80, 1000000),'email_count': np.random.randint(1, 10, 1000000)
}
customer_df = pd.DataFrame(customer_data)
内存优化
# 转换数据类型
customer_df['customer_id'] = customer_df['customer_id'].astype('int32')
customer_df['age'] = customer_df['age'].astype('int8')
customer_df['email_count'] = customer_df['email_count'].astype('int8')
8.2.4 拓展案例二:使用并行处理加速数据清洗
假设需要对一份大型文本数据集进行清洗,包括去除特殊字符、转换大小写等。
数据准备
# 生成大型文本数据示例
text_data = ['This is a SAMPLE text.' * 10 for _ in range(100000)]
text_df = pd.DataFrame(text_data, columns=['text'])
并行处理
由于 Pandas 直接不支持并行处理,此示例暂略。在实际应用中,可以考虑使用 dask 库或 multiprocessing 库来实现数据的并行处理。
通过这些案例,我们展示了如何通过向量化操作、优化数据类型、批处理处理大数据以及并行处理等技巧来提高数据处理的性能。这些方法对于处理大型数据集尤其重要,可以帮助你在保证分析质量的同时,显著减少处理时间和内存消耗。

8.3 处理大型数据集
处理大型数据集时,传统的数据处理方法可能会受到内存限制的影响,导致效率低下或无法执行。优化数据处理流程,使其能够高效地处理大型数据集,是提高分析效率的关键。
8.3.1 基础知识
- 分块处理: 将大型数据集分成小块,逐块加载处理,而不是一次性加载整个数据集到内存中。
- 高效的数据格式: 使用如 Parquet、HDF5 等高效的数据存储格式,可以加速数据读写操作,并降低内存使用。
- 使用 Dask 等工具: 对于特别大的数据集,可以使用如 Dask 这样的库,它支持并行计算并优化内存使用。
8.3.2 重点案例:分块读取并处理销售数据
假设你有一个非常大的销售记录文件,无法一次性加载到内存中,需要分块进行处理。
数据准备
此处我们模拟创建一个大型文件的过程,实际操作中你可能直接操作现有的大文件。
import pandas as pd
import numpy as np# 生成示例销售数据并保存到 CSV 文件
chunk_size = 10000
num_chunks = 500
for i in range(num_chunks):df = pd.DataFrame({'SaleID': range(i * chunk_size, (i + 1) * chunk_size),'ProductID': np.random.randint(1, 100, chunk_size),'SaleAmount': np.random.rand(chunk_size) * 100})df.to_csv('/mnt/data/sales_large.csv', mode='a', index=False, header=(i == 0))
分块读取和处理
chunk_iter = pd.read_csv('/mnt/data/sales_large.csv', chunksize=chunk_size)total_sales = 0
for chunk in chunk_iter:total_sales += chunk['SaleAmount'].sum()
print(f"Total sales amount: {total_sales}")
8.3.3 拓展案例一:使用高效数据格式存储和读取
将大型数据集转换为更高效的格式,如 Parquet,以优化读写速度和降低内存消耗。
# 假设 df 是一个大型 DataFrame
df.to_parquet('/mnt/data/sales_large.parquet')# 读取 Parquet 文件
df_parquet = pd.read_parquet('/mnt/data/sales_large.parquet')
8.3.4 拓展案例二:利用 Dask 处理超大数据集
对于超大型数据集,Pandas 可能不足以高效处理。此时可以考虑使用 Dask。
# 注意:此代码示例需要在支持 Dask 的环境中运行
from dask import dataframe as dd# 读取数据
dask_df = dd.read_csv('/mnt/data/sales_large.csv')# 使用 Dask 进行计算
total_sales_dask = dask_df['SaleAmount'].sum().compute()
print(f"Total sales amount with Dask: {total_sales_dask}")
通过这些案例,我们展示了如何处理大型数据集,包括分块处理数据、使用高效的数据格式,以及利用 Dask 进行超大数据集的分析。这些技巧对于处理和分析大规模数据集至关重要,可以帮助你克服内存限制,提高数据处理效率。
相关文章:
《Pandas 简易速速上手小册》第8章:Pandas 高级数据分析技巧(2024 最新版)
文章目录 8.1 使用 apply 和 map 函数8.1.1 基础知识8.1.2 重点案例:客户数据清洗和转换8.1.3 拓展案例一:产品评分调整8.1.4 拓展案例二:地址格式化 8.2 性能优化技巧8.2.1 基础知识8.2.2 重点案例:大型销售数据分析8.2.3 拓展案…...

计算机网络_1.6.2 计算机网络体系结构分层的必要性
1.6.2 计算机网络体系结构分层的必要性 一、五层原理体系结构每层各自主要解决什么问题1、物理层2、数据链路层3、网络层4、运输层5、应用层 二、总结三、练习 笔记来源: B站 《深入浅出计算机网络》课程 本节主要介绍实现计算机网络需要解决哪些问题?以…...
跟着cherno手搓游戏引擎【18】抽象Shader、项目小修改
抽象: Shader.h: #pragma once #include <string>namespace YOTO {class Shader {public:virtual~Shader()default;virtual void Bind()const0;virtual void UnBind()const0;static Shader* Create(const std::string& vertexSrc, const std::string&am…...

每日OJ题_算法_模拟②_力扣495. 提莫攻击
目录 力扣495. 提莫攻击 解析代码 力扣495. 提莫攻击 495. 提莫攻击 难度 简单 在《英雄联盟》的世界中,有一个叫 “提莫” 的英雄。他的攻击可以让敌方英雄艾希(编者注:寒冰射手)进入中毒状态。 当提莫攻击艾希,…...

freertos 源码分析二 list链表源码
list.c 一、链表初始化 void vListInitialise( List_t * const pxList ) { pxList->pxIndex ( ListItem_t * ) &…...
Peter算法小课堂—Dijkstra最短路算法
大家好,我们人见人爱、花见花开、车见车爆胎的Peter Pan来啦,hia~hia~hia。今天,我们今天来学习毒瘤的最短路算法啦。啊这……什么是Dijkstra算法?长文警告⚠ 正经点啊 手算样例 大家思考一下,你在手算样例的时候&am…...

Python 读取和写入包含中文的csv、xlsx、json文件
背景 最近在做数据的训练,经常需要读取写入csv、xlsx、json文件来获取数据,在这里做简单总结记录。 ps: 读取和写入中文文件时,需要确保文件的编码格式是正确的。通常情况使用UTF-8编码格式。如果使用其他编码格式可能会导致读取或写入时出…...
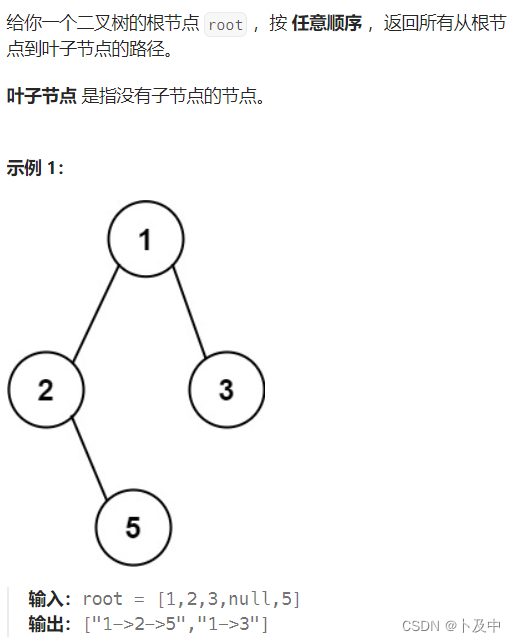
【算法】利用递归dfs解决二叉树算法题(C++)
文章目录 1. 前言2. 算法题2331.计算布尔二叉树的值129.求根节点到叶节点数字之和LCR047.二叉树剪枝98.验证二叉搜索树230.二叉搜索树中第K小的元素257.二叉树的所有路径 1. 前言 有关 递归 的相关解释与解题 请看下文: 以汉诺塔理解递归、并用递归解决算法题 对于…...

计算机网络_1.6.1 常见的三种计算机网络体系结构
1.6.1 常见的三种计算机网络体系结构 1、OSI(七层协议)标准失败的原因2、TCP/IP参考模型3、三种网络体系结构对比 笔记来源: B站 《深入浅出计算机网络》课程 1、OSI(七层协议)标准失败的原因 (1…...
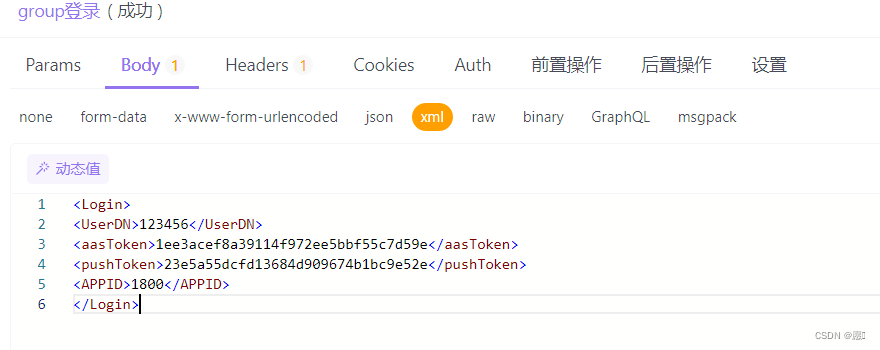
XML传参方式
export function groupLoginAPI(xmlData) {return http.post(/tis/group/1.0/login, xmlData, {headers: {Content-Type: application/xml,X-Requested-With: AAServer/4.0,}}) }import {groupLoginAPI} from "../api/user"; function (e) { //xml格式传参let groupX…...
Pyecharts炫酷散点图构建指南【第50篇—python:炫酷散点图】
文章目录 Pyecharts炫酷散点图构建指南引言安装Pyecharts基础散点图自定义散点图样式渐变散点图动态散点图高级标注散点图多系列散点图3D散点图时间轴散点图笛卡尔坐标系下的极坐标系散点图 总结: Pyecharts炫酷散点图构建指南 引言 在数据可视化领域,…...
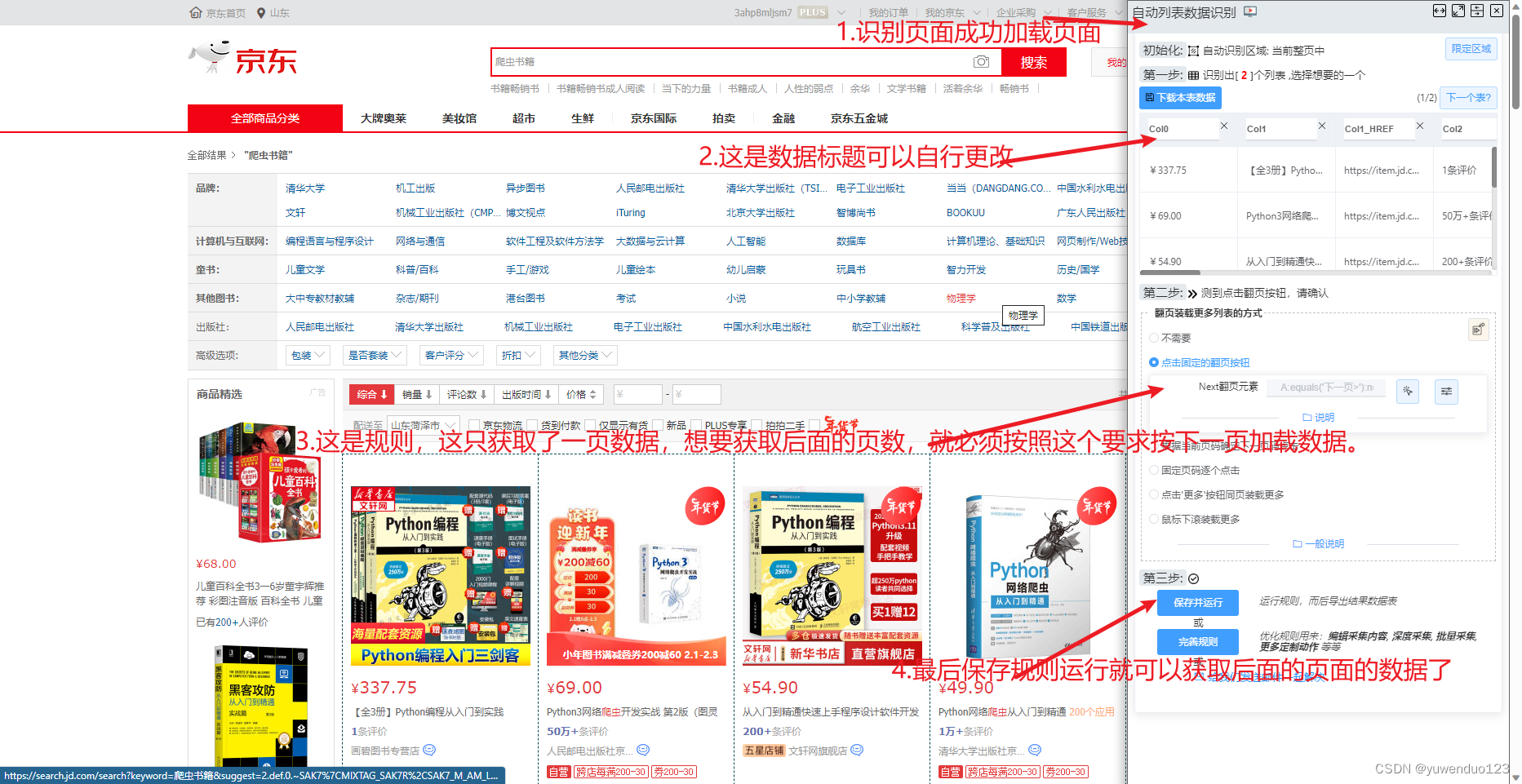
关于爬取所有哔哩哔哩、任意图片、所有音乐、的python脚本语言-Edge浏览器插件 全是干货!
这些都是现成的并且实时更新的!从次解放双手! 首先有自己的edge浏览器基本上都有并且找到插件选项 1.哔哩哔哩视频下载助手(爬取哔哩哔哩视频) bilibili哔哩哔哩视频下载助手 - Microsoft Edge Addons 下面是效果: 2.图…...
压力测试工具-Jmeter使用总结
目录 一.前言 二.线程组 三.线程组的组件 四.线程组-HTTP请求 1、JSON提取器 2、XPATH提取器 3、正则表达式提取器 五.线程组-断言 1、响应断言 2、JSON断言 六.创建测试 1.创建线程组 2.配置元件 3.构造HTTP请求 4.添加HTTP请求头 5.添加断言 6.添加查看结果树…...

[cmake]CMake Error: Could not create named generator Visual Studio 16 2019解决方法
配置flycv时,cmake以下代码会报错第二行的错误,网上解决方法为第三行代码 cmake .. -G "Visual Studio 16 2019 Win64" CMake Error: Could not create named generator Visual Studio 16 2019 cmake .. -G "Visual Studio 16 2019"…...

2024美赛数学建模D题思路分析 - 大湖区水资源问题
1 赛题 问题D:大湖区水资源问题 背景 美国和加拿大的五大湖是世界上最大的淡水湖群。这五个湖泊和连接的水道构成了一个巨大的流域,其中包含了这两个国家的许多大城市地区,气候和局部天气条件不同。 这些湖泊的水被用于许多用途࿰…...

2024 高级前端面试题之 HTTP模块 「精选篇」
该内容主要整理关于 HTTP模块 的相关面试题,其他内容面试题请移步至 「最新最全的前端面试题集锦」 查看。 HTTP模块精选篇 1. HTTP 报文的组成部分2. 常见状态码3. 从输入URL到呈现页面过程3.1 简洁3.2 详细 4. TCP、UDP相关5. HTTP2相关6. https相关7. WebSocket的…...

【Linux C | 网络编程】netstat 命令图文详解 | 查看网络连接、查看路由表、查看统计数据
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 🤣本文内容🤣&a…...

Python爬虫存储库安装
如果你还没有安装好MySQL、MongoDB、Redis 数据库,请参考这篇文章进行安装: Windows、Linux、Mac数据库的安装(mysql、MongoDB、Redis)-CSDN博客 存储库的安装 上节中,我们介绍了几个数据库的安装方式,但…...
)
用函数求最小公倍数和最大公约数(c++题解)
题目描述 输入两个正整数m和n,求其最大公约数和最小公倍数。 提示,求最大公约数用一个函数实现。本题求最大公约数必须用高效算法,如辗转相除法,朴素算法要超时。 输入格式 第1行:两个非整数,值在0&…...

鲜花销售|鲜花销售小程序|基于微信小程序的鲜花销售系统设计与实现(源码+数据库+文档)
鲜花销售小程序目录 目录 基于微信小程序的鲜花销售系统设计与实现 一、前言 二、系统功能设计 三、系统实现 1、前台功能模块 2、后台功能模块 (1) 后台登录 (2) 管理员功能模块 用户管理 商家管理 鲜花信息管理 鲜花分类管理 管理员管理 系统管理 (3) 商家功…...

如何分析网站SEO数据,优化营销策略
如何分析网站SEO数据,优化营销策略 在当今数字化营销的时代,网站的SEO数据分析不仅是提升网站排名的关键,更是优化整体营销策略的重要手段。本文将详细探讨如何通过分析网站SEO数据来优化营销策略,助力企业在竞争激烈的市场中脱颖…...

零基础入门大模型开发:三周实战速成指南
看到同事靠大模型开发拿到高薪offer,你还在犹豫自己不是AI专业?作为一名普通后端开发,我曾经也认为大模型开发高不可攀——直到亲眼目睹同组Java同事仅用一个月就成功转型大模型应用开发,薪资涨幅40%。那一刻我才恍然大悟…...

东莞故意伤害罪律师在线咨询
在东莞遇到故意伤害罪相关法律问题,别慌!广东秦仪律师团队为您提供专业且贴心的在线咨询服务。我们拥有经验丰富的律师,他们不仅是广东省律师协会会员,还在法律领域深耕多年,有着扎实的法律知识和丰富的实战经验。曾在…...

Haskell编译器优化:wiwinwlh GHC内部机制详解
Haskell编译器优化:wiwinwlh GHC内部机制详解 【免费下载链接】wiwinwlh What I Wish I Knew When Learning Haskell 项目地址: https://gitcode.com/gh_mirrors/wi/wiwinwlh wiwinwlh项目(What I Wish I Knew When Learning Haskell)…...

WPS JS宏利用Fetch API实现网页数据抓取与Excel自动化处理
1. 为什么需要网页数据抓取与Excel自动化 在日常办公中,我们经常需要从各种网站获取数据并整理到Excel表格中。比如市场人员需要抓取竞品价格、财务人员需要获取汇率数据、运营人员需要统计社交媒体互动情况。传统做法是手动复制粘贴,不仅效率低下&#…...

图像去雾新突破:DEConv和CGA如何提升自动驾驶视觉系统性能
图像去雾新突破:DEConv和CGA如何提升自动驾驶视觉系统性能 清晨的浓雾中,一辆自动驾驶汽车缓缓驶过十字路口。车载摄像头捕捉到的画面本该模糊不清,但屏幕上却清晰地显示着行人、信号灯和障碍物——这背后是DEA-Net图像去雾技术创造的奇迹。在…...

零成本上手:在魔塔社区用免费GPU微调InternLM2.5-7B-Chat实战
1. 为什么选择魔塔社区进行大模型微调 第一次接触大模型微调的朋友们可能都有这样的困惑:动辄几十GB的模型参数,没有高端显卡怎么玩得转?这里就要给大家安利一个宝藏平台——阿里魔塔社区。我去年刚开始研究大模型时,也是被硬件门…...
可视化避坑与调参指南)
从.nii文件到发表级配图:一份超详细的fMRI脑区(ROI)可视化避坑与调参指南
从.nii文件到发表级配图:一份超详细的fMRI脑区(ROI)可视化避坑与调参指南 当你终于跑完最后一组统计分析,看着屏幕上那些代表显著脑区的彩色斑点时,可能已经迫不及待想把它们放进论文插图。但现实往往是——直接导出的…...

python twilio
# 关于Twilio与Python,一些实践后的思考 最近在项目中频繁使用Twilio来处理通信需求,发现不少开发者对这个工具集的理解还停留在“发短信的API”层面。实际上它的能力远不止于此,也并非简单地调用几个接口那么简单。 它究竟是什么 Twilio本…...

Qwen3.5-2B模型在Web开发中的创新应用:智能内容生成与审核
Qwen3.5-2B模型在Web开发中的创新应用:智能内容生成与审核 1. 引言:当Web开发遇上AI内容生成 想象一下这样的场景:用户上传了几张旅行照片,系统自动生成了一篇图文并茂的游记草稿;或者社区平台能够实时审核用户上传的…...