机器学习入门-----sklearn
机器学习基础了解
概念
机器学习是人工智能的一个实现途径
深度学习是机器学习的一个方法发展而来
定义:从数据中自动分析获得模型,并利用模型对特征数据【数据集:特征值+目标值构成】进行预测
算法
数据集的目标值是类别的话叫做分类问题;目标值是连续的数值的话叫做回归问题;统称监督学习;
另一类是无监督学习,这一类的数据集没有目标值,典型:聚类;
做什么
可以进行传统预测、图像识别、自然语言处理
传统预测
店铺销量预测、量化投资、广告推荐、企业客户分类、sql语言安全检测分类
图像识别
街道交通标志检测、人脸识别
自然语言处理
文本分类、情感分析、自动聊天、文本检测、翻译、写报纸、简单的新闻报告等
机器学习开发流程
数据收集、数据清洗(过滤、缺失处理、异常处理)、特征工程、数据建模 、模型评估
数据清洗是指处理数据中的错误、不完整或不准确的部分,以确保数据的质量和准确性。数据清洗通常涉及处理缺失值、异常值、重复值和错误值等。
特征工程是指根据数据的特性和业务需求,对原始数据进行转换、组合和提取,以提取出对建模和分析有用的特征。特征工程通常涉及对原始数据进行标准化、归一化、离散化、特征选择、特征组合等处理。
因此,数据清洗主要关注数据的准确性和完整性,而特征工程主要关注如何从原始数据中提取出对建模和分析有用的特征。两者都是数据预处理的重要环节,对于最终的数据分析和建模结果都有着重要的影响。
特征工程
定义:特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程
数据集
Kaggle网址:https://www.kaggle.com/
UCI网址:https://archive.ics.uci.edu/
scikit-learn:https://scikit-learn.org/stable/index.html
scikit-learn
Classification 分类; Regression 回归; Clustering 聚类;
Dimensionality reduction降维; Model selection 模型选择 ;Preprocessing 特征工程;
安装步骤:1.安装相关库【numpy+mkl和scipy】:步骤为下载相关库安装包,打开下载文件夹,shift+鼠标打开‘在此处打开Powershell窗口,使用pip install 名字安装;2.win+R输入cmd,进入cmd命令框;使用命令pip install -U scikit-learn安装 具体见笔记;
验证一下,打开cmd命令框,查看版本pip list;
数据集使用
特征提取:load(获取小规模数据集)、fetch(获取大规模数据集)
返回Bunch数据类型
数据集划分
使用:sklearn.model_selection.train_test_split
训练数据:用于训练,构建模型
测试数据:模型检验使用,用于评估模型是否有效,一般20%-30%
特征工程步骤
特征提取【特征值化】:
使用:sklearn.feature_extraction
将任意数据(如文本图像)转换为可用于机器学习的数字特征,目的是为了计算机能够更好的理解数据,如字典特征提取【特征离散化】、文本特征提取、图像特征提取【深度学习】
字典特征抽取【将特征当中存在的类别信息做one-hot编码处理】
应用场景:
1)数据集中类别特征比较多时,可以先将数据集特征转化为字典类型,然后使用sklearn.feature_extraction.DictVectorizer类转换【调用fit_transform(数据集)方法,默认是系数矩阵;用get_feature_names()方法返回类别名称】;2)数据集本身就是字典类型
one-hot编码:One-hot编码是一种将分类变量转换为二进制向量的编码方法。在这种编码中,每个分类变量的取值被表示为一个长度为n的二进制向量,其中n是分类变量的取值个数。在这个向量中,只有对应分类变量取值的索引位置上的值为1,其他位置的值都为0。这种编码方法可以使分类变量在机器学习算法中更容易处理和分析。
文本特征抽取
应用场景:
1)统计每个样本特征词出现的个数,用sklearn.feature_extraction.text.CountVectorizer类进行转换【调用fit_transform(文本)方法】;
2)统计一个字或者一个词对一个文件集或一个语料库中其中一份文件的重要程度,即统计在某一类类别文章出现次数很多,但其他类别文章当中出现较少的关键词,用sklearn.feature_extraction.text.TfidfTransformer类进行转换【调用fit_transform(文本)方法】,即tf-idf【term frequency词频,inverse document frequency逆向文档频率】方法;
扩展:
jieba可以用来中文分词
安装jieba库方法如下
使用命令pip install jieba
安装成功

特征预处理
The sklearn.preprocessing package provides several common utility functions and transformer classes to change raw feature vectors into a representation that is more suitable for the downstream estimators.
解释:通过一些转换函数将特征数据转换为更加适合算法模型的特征数据过程
数值型数据的无量纲化:
为什么要进行归一化和标准化:
特征的单位或者大小相差较大,或者某特征的方差要比其他特征要大出几个数量级, 容易影响(支配)目标结果,使得一些算法无法学习到其他目标;所以为了使不同规格数据转换为同一规格要使用无量纲化(归一化和标准化)
比较:
对于归一化来说,如果出现异常点,会影响最大值和最小值,结果会发生变化
对于标准化来说,如果出现异常点,由于具有一定的数据量,少量的异常点对于平均值的影响不大,从而方差【标准差代表数据的集中程度】影响较小
1)归一化
定义:对原始数据进行变换把数据映射到(默认【0,1】)之间 公式:
使用场景:因为最值是变化的且容易受异常点影响,所以这种方法鲁棒性【健壮性】较差,只适合传统精确小数据场景
使用:sklearn.preprocessing.MinMaxScaler
调用sklearn.preprocessing.minmax_scale(X, feature_range=(0, 1)【最小最大值放缩】,先读取数据,然后实例化对象【调用fit_transform()方法即可】,如下
数据,文件名:dating.txt
milage,Liters,Consumtime,target
40920,8.326976,0.953952,3
14488,7.153469,1.673904,2
26052,1.441871,0.805124,1
75136,13.147394,0.428964,1
38344,1.669788,0.134296,1
代码
import pandas as pd
from sklearn.preprocessing import MinMaxScalerdef minman_demo():"""归一化:return:"""# 1.获取数据data = pd.read_csv("dating.txt")data = data.iloc[:,:3] # 每行都要,前3列print("data:\n", data)# 2.实例化转换器类transfer = MinMaxScaler()# 3.调用转换器类data_new = transfer.fit相关文章:

机器学习入门-----sklearn
机器学习基础了解 概念 机器学习是人工智能的一个实现途径 深度学习是机器学习的一个方法发展而来 定义:从数据中自动分析获得模型,并利用模型对特征数据【数据集:特征值+目标值构成】进行预测 算法 数据集的目标值是类别的话叫做分类问题;目标值是连续的数值的话叫做回…...
双非本科准备秋招(15.3)—— 力扣二叉树
今天学了二叉树结点表示法,建树代码如下。 public class TreeNode {public int val;public TreeNode left;public TreeNode right;public TreeNode(int val) {this.val val;}public TreeNode(int val, TreeNode left, TreeNode right) {this.val val;this.left …...
20240203在WIN10下使用GTX1080配置stable-diffusion-webui.git不支持float16精度出错的处理
20240203在WIN10下使用GTX1080配置stable-diffusion-webui.git不支持float16精度出错的处理 2024/2/3 21:23 缘起:最近学习stable-diffusion-webui.git,在Ubuntu20.04.6下配置SD成功。 不搞精简版本:Miniconda了。直接上Anacoda! …...

京东微前端框架MicroApp简介
一、MicroApp 1.1 MicroApp简介 MicroApp是由京东前端团队推出的一款微前端框架,它从组件化的思维,基于类WebComponent进行微前端的渲染,旨在降低上手难度、提升工作效率。MicroApp无关技术栈,也不和业务绑定,可以用于任何前端框架。 官网链接:https://micro-zoe.gith…...
SpringBoot 使用定时任务(SpringTask)
Spring3.0以后自带的task,可以将它看成一个轻量级的Quartz,而且使用起来比Quartz简单许多。 使用步骤: 1.导入坐标 在spring-boot-starter-web坐标中,就包含了SpringTask,所以一般的Web项目都包含了。 <depende…...
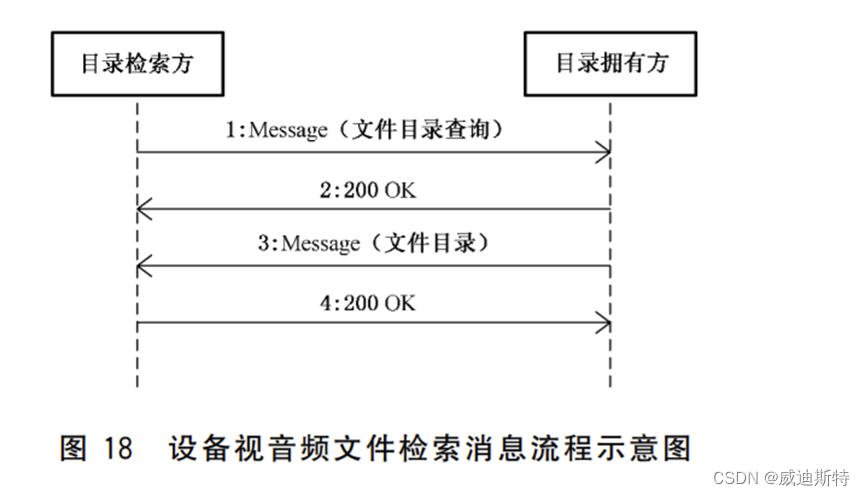
国标GB/T 28181详解:设备视音频文件检索消息流程
目 录 一、设备视音频文件检索 二、设备视音频文件检索的基本要求 三、命令流程 1、流程图 2、流程描述 四、协议接口 五、产品说明 六、设备视音频文件检索的作用 七、参考 在国标GBT28181中,定义了设备视音频文件检索消息的流程,主…...

openssl自签名CA根证书、服务端和客户端证书生成并模拟单向/双向证书验证
1. 生成根证书 1.1 生成CA证书私钥 openssl genrsa -aes256 -out ca.key 2048 1.2 取消密钥的密码保护 openssl rsa -in ca.key -out ca.key 1.3 生成根证书签发申请文件(csr文件) openssl req -new -sha256 -key ca.key -out ca.csr -subj "/CCN/STFJ/LXM/ONONE/OU…...

NIO Selector简介
1.Selector和Channel关系 Selector一般称为选择器,也叫多路复用器,NIO的核心组件,用于检查一个或多个Channel的状态是否处于可读、可写的状态。 2.可选择通道 (1)不是所有的channel都能被selector复用,…...
2023-12蓝桥杯STEMA考试 C++ 中高级试卷解析
蓝桥杯STEMA考试 C++ 中高级试卷(12月) 一、选择题 第一题 定义字符串 string a = "Hello C++",下列选项可以获取到字符 C 的是(B)。 A、a[7] B、a[6] C、a[5] D、a[4] 第二题 下列选项中数值与其它项不同的是( C)。 A、 B、 C、 D、 第三题 定义变量 int i =…...
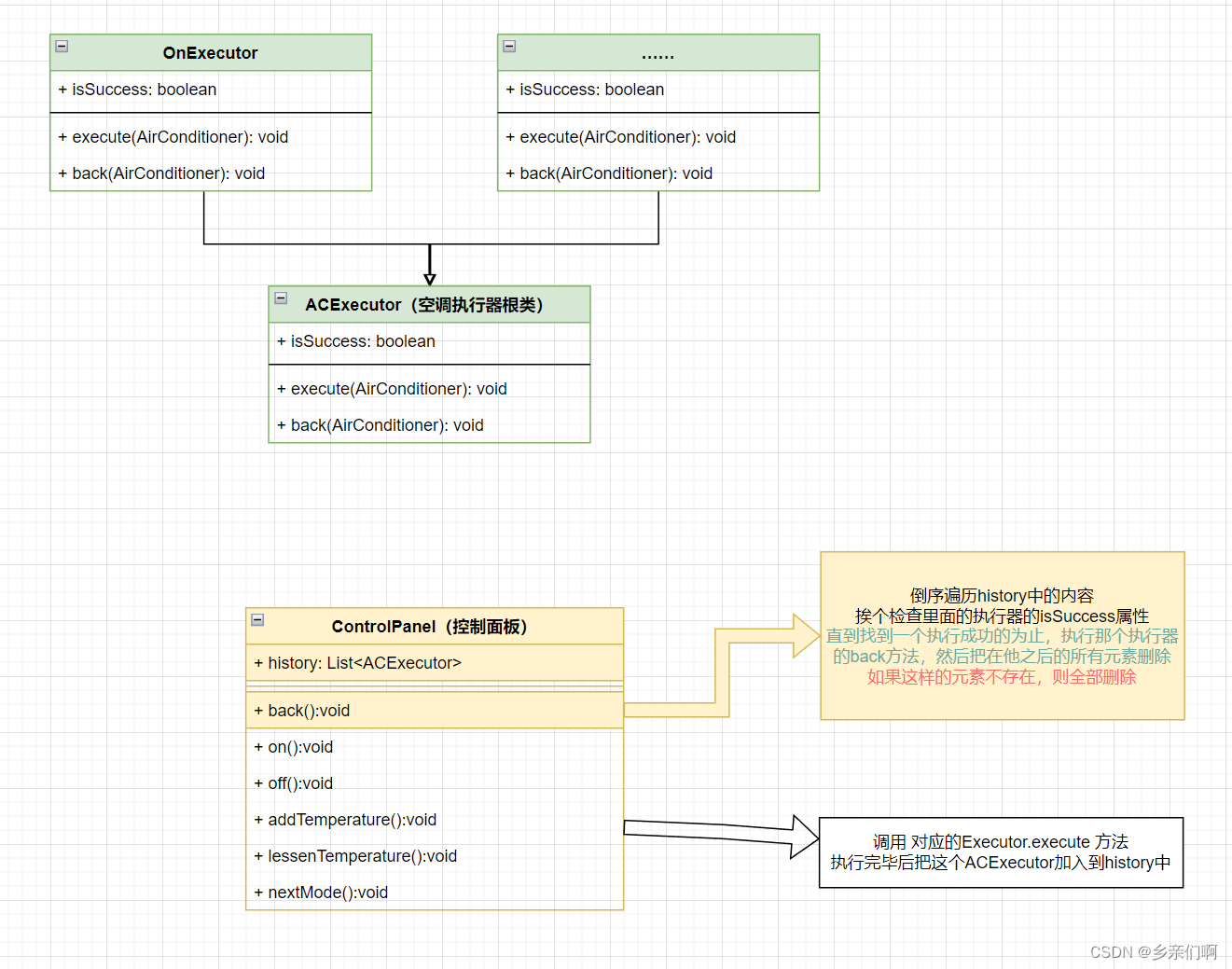
设计模式——2_1 命令(Command)
文章目录 定义图纸一个例子:空调和他的遥控器只有控制面板的空调遥控器可以撤销的操作 碎碎念命令和Runnable命令和事务 定义 把请求封装成一个对象,从而使你可以用不同的请求对客户进行参数化,对请求排队或记录请求日志,以及支持…...

HP数组面试题
PHP数组面试题 问题: 如何创建一个空数组和一个带有初始值的数组? 答案: 创建空数组:可以使用array()函数或空数组语法[]来创建一个空数组,例如$arr array();或$arr [];。创建带有初始值的数组:可以在创建…...
机器学习5-线性回归之损失函数
在线性回归中,我们通常使用最小二乘法(Ordinary Least Squares, OLS)来求解损失函数。线性回归的目标是找到一条直线,使得预测值与实际值的平方差最小化。 假设有数据集 其中 是输入特征, 是对应的输出。 线性回归的…...
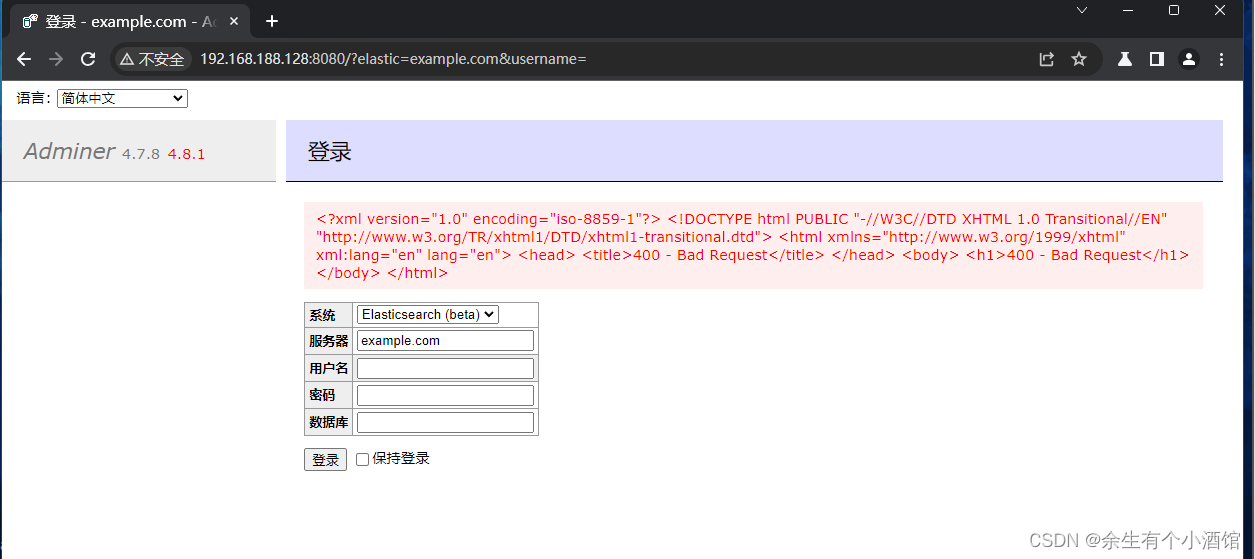
vulhub中Adminer ElasticSearch 和 ClickHouse 错误页面SSRF漏洞复现(CVE-2021-21311)
Adminer是一个PHP编写的开源数据库管理工具,支持MySQL、MariaDB、PostgreSQL、SQLite、MS SQL、Oracle、Elasticsearch、MongoDB等数据库。 在其4.0.0到4.7.9版本之间,连接 ElasticSearch 和 ClickHouse 数据库时存在一处服务端请求伪造漏洞(…...
浅谈Zookeeper及windows下详细安装步骤
1. Zookeeper介绍 1.1 分布式系统面临的问题 分布式系统是一个硬件或软件组件分布在不同的网络计算机上,彼此之间仅仅通过消息传递进行通信和协调的系统。 面临的问题:系统每个节点之间信息同步及共享 以一个小团队为例,面临的问题 通过网络进行信息…...

vite, vue3, vue-router, vuex, ES6学习日记
学习使用vitevue3的所遇问题总结(2024年2月1日) 组件中使用<script>标签忘记加 setup 这会导致Navbar 没有暴露出来,导致使用不了,出现以下报错 这是因为,如果不用setup,就得使用 export default…...

25考研|660/880/1000/1800全年带刷计划
作为一个参加过两次研究生考试的老学姐,我觉得考研数学的难度完全取决于你自己 我自己就是一个很好的例子 21年数学题目是公认的简单,那一年考130的很多,但是我那一年只考了87分。但是22年又都说是有史以来最难的一年,和20年的难度…...

Mybatis基础教程及使用细节
本篇主要对Mybatis基础使用进行总结,包括Mybatis的基础操作,使用注解进行增删改查的练习;详细介绍xml映射文件配置过程并且使用xml映射文件进行动态sql语句进行条件查询;为了简化java开发提高效率,介绍一下依赖&#x…...

10 分钟在K8s 中部署轻量级日志系统 Loki
转载至我的博客 https://www.infrastack.cn ,公众号:架构成长指南 Loki 是什么? Loki是由Grafana Labs开源的一个水平可扩展、高可用性,多租户的日志聚合系统的日志聚合系统。它的设计初衷是为了解决在大规模分布式系统中&#x…...
图像处理python基础
array 读取图片 tensor 模型预测 一般过程:读取数据np->tensor->model->result->np->画图 shape确保图像输入输出尺寸正确 读取图片 将在GPU上运行的tensor类型转变成在CPU上运行的np类型 三类计算机视觉任务的输入: 分类࿱…...
基于WordPress开发微信小程序2:决定开发一个wordpress主题
上一篇:基于WordPress开发微信小程序1:搭建Wordpress-CSDN博客 很快发现一个问题,如果使用别人的主题模板,多多少少存在麻烦,所以一咬牙,决定自己开发一个主题模板,并且开源在gitee上ÿ…...

NASA Earthdata保姆级教程:手把手教你用矩形框批量下载MODIS和VIIRS遥感数据
NASA Earthdata零基础实战:从注册到批量下载MODIS/VIIRS遥感数据的完整指南 第一次接触NASA Earthdata网站时,面对满屏的专业术语和复杂操作界面,大多数科研新手都会感到手足无措。作为全球最大的对地观测数据平台之一,Earthdata…...

新手友好:借助快马平台从零复刻w777.7cc经典小游戏
作为一个刚接触编程的新手,最近在InsCode(快马)平台尝试复刻w777.7cc经典小游戏时,发现整个过程比想象中简单许多。这种翻牌匹配类游戏规则明确、交互直观,特别适合用来理解前端三件套(HTML/CSS/JavaScript)的协作逻辑…...
)
电源工程师必看:平均电流模式BUCK双环控制详解(从传递函数到Psim仿真)
电源工程师必看:平均电流模式BUCK双环控制详解(从传递函数到Psim仿真) 在电力电子领域,BUCK变换器的控制策略一直是工程师们关注的重点。作为一名刚入行的电源工程师,我曾被各种控制模式搞得晕头转向——电压模式、峰值…...

从零到精通:Vue3.0中使用vuedraggable实现完美拖拽功能的5个关键技巧
从零到精通:Vue3.0中使用vuedraggable实现完美拖拽功能的5个关键技巧 在当今前端开发领域,交互体验的重要性日益凸显,而拖拽功能作为提升用户操作直观性的核心手段,已经成为现代Web应用的标配。Vue3.0凭借其出色的响应式系统和组合…...

3分钟快速上手:Win11Debloat - 让你的Windows 11系统更纯净高效
3分钟快速上手:Win11Debloat - 让你的Windows 11系统更纯净高效 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutt…...

如何在Windows中快速读取Linux分区?Ext2Read完整教程指南
如何在Windows中快速读取Linux分区?Ext2Read完整教程指南 【免费下载链接】ext2read A Windows Application to read and copy Ext2/Ext3/Ext4 (With LVM) Partitions from Windows. 项目地址: https://gitcode.com/gh_mirrors/ex/ext2read 你是否曾经遇到过…...

告别金融数据获取难题:mootdx打造一站式通达信数据解决方案
告别金融数据获取难题:mootdx打造一站式通达信数据解决方案 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 在金融数据分析和量化交易领域,获取高质量、实时的市场数据一直…...

保姆级教程:用Python解析大疆无人机照片EXIF,实现正射影像像素坐标定位
大疆无人机正射影像像素级地理定位实战指南 从航拍到测绘:解锁影像元数据的空间密码 当大疆无人机的快门按下瞬间,传感器记录的远不止是可见光信息。每一张正射影像都像被精心封装的时间胶囊,内部藏着完整的空间坐标、飞行姿态和相机参数。这…...

过河卒算法备案:我们不便宜,但我们值这个价!
在算法备案行业竞争愈演愈烈的当下,价格战愈加白热化,材料造假、模板套用、盲目承诺等行为屡见不鲜。这种“表面合规”看似便宜,实则暗藏风险。一旦遇到监管抽查,轻则整改重新备案,重则受罚,企业蒙受巨大损…...

从销售报表分析到供应链数据优化,SpreadJS 透视表插件全场景应用指南
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...