XGB-3: 模型IO
在XGBoost 1.0.0中,引入了对使用JSON保存/加载XGBoost模型和相关超参数的支持,旨在用一个可以轻松重用的开放格式取代旧的二进制内部格式。后来在XGBoost 1.6.0中,还添加了对通用二进制JSON的额外支持,作为更高效的模型IO的优化。它们具有相同的文档结构,但具有不同的表示形式,但都统称为JSON格式。本教程旨在分享一些关于XGBoost中使用的JSON序列化方法的基本见解。除非明确说明,以下各节假定正在使用2个输出格式之一,可以通过在保存/加载模型时提供带有.json(或二进制JSON的.ubj)文件扩展名的文件名来启用这两种格式:booster.save_model('model.json')。
在开始之前,需要说明的是,XGBoost是一个以树模型为重点的梯度提升库,这意味着在XGBoost内部有两个明显的部分:
- 由树组成的模型
- 用于构建模型的超参数和配置
如果是专注于深度学习领域,那么应该清楚由固定张量操作的权重组成的神经网络结构与用于训练它们的优化器(例如RMSprop)之间存在差异。
因此,当调用 booster.save_model(在R中是 xgb.save)时,XGBoost会保存树、一些模型参数(例如在训练树中的输入列数)以及目标函数,这些组合在一起代表了XGBoost中的“模型”概念。至于为什么将目标函数保存为模型的一部分,原因是目标函数控制全局偏差的转换(在XGBoost中称为base_score)。用户可以与他人共享此模型,用于预测、评估或使用不同的超参数集继续训练等。
有些情况下,需要保存的不仅仅是模型本身。例如,在分布式训练中,XGBoost执行检查点操作。或者由于某些原因,分布式计算框架决定将模型从一个工作节点复制到另一个工作节点,并在那里继续训练。在这种情况下,序列化输出需要包含足够的信息,以便在不需要用户再次提供任何参数的情况下继续以前的训练。将这种情景视为内存快照( memory snapshot或基于内存的序列化方法),并将其与普通的模型IO操作区分开来。目前,内存快照用于以下情况:
- Python:使用内置的pickle模块对
Booster对象进行pickle - R:使用内置函数
saveRDS或save对xgb.Booster对象进行持久化 - JVM:使用内置函数
saveModel对Booster对象进行序列化
注意:
旧的二进制格式不能区分模型和原始内存序列化格式的差异,它是一切的混合体。JVM包有其自己的基于内存的序列化方法。
为了启用模型 IO 的 JSON 格式支持(仅保存树和目标),请在文件名中使用 .json 或 .ubj 作为文件扩展名,后者是通用二进制 JSON 的扩展名。
- Python
bst.save_model('model_file_name.json')
- R
xgb.save(bst, 'model_file_name.json')
- Scala
val format = "json" // or val format = "ubj"
model.write.option("format", format).save("model_directory_path")
注意:
仅从由 XGBoost 生成的 JSON 文件加载模型。尝试加载由外部来源生成的 JSON 文件可能导致未定义的行为和崩溃。
关于模型和内存快照的向后兼容性说明
保证模型的向后兼容性,但不保证内存快照的向后兼容性。
模型(树和目标)使用稳定的表示,因此在较早版本的 XGBoost 中生成的模型可以在较新版本的 XGBoost 中访问。如果希望将模型存储或存档以供长期存储,请使用 save_model(Python)和 xgb.save(R)。
另一方面,内存快照(序列化)捕获了 XGBoost 内部的许多内容,其格式不稳定且可能经常更改。因此,内存快照仅适用于检查点,可以持久保存训练配置的完整快照,以便可以从可能的故障中强大地恢复并恢复训练过程。加载由较早版本的 XGBoost 生成的内存快照可能会导致错误或未定义的行为。如果使用 pickle.dump(Python)或 saveRDS(R)持久保存模型,则该模型可能无法在较新版本的 XGBoost 中访问。
自定义目标和度量标准
XGBoost支持用户提供的自定义目标和度量标准函数作为扩展。这些函数不会保存在模型文件中,因为它们是与语言相关的特性。在Python中,用户可以使用pickle将这些函数包含在保存的二进制文件中。其中一个缺点是,pickle输出不是稳定的序列化格式,在不同的Python版本和XGBoost版本上都无法使用,更不用说在不同的语言环境中了。解决此限制的另一种方法是在加载模型后再次提供这些函数。如果定制的函数很有用,请考虑创建一个PR(Pull Request)在XGBoost内部实现它,这样就可以在不同的语言绑定中使用定制的函数。
加载来自不同版本XGBoost的pickled文件
如前所述,pickle模型既不具备可移植性,也不稳定,但在某些情况下,pickled模型是有价值的。将其在将来恢复的一种方法是使用特定版本的Python和XGBoost将其加载回来,然后通过调用save_model导出模型。
可以使用类似的过程来恢复保存在旧RDS文件中的模型。在R中,可以使用remotes包安装旧版本的XGBoost:
library(remotes)
remotes::install_version("xgboost", "0.90.0.1") # 安装版本0.90.0.1
安装所需的版本后,可以使用readRDS加载RDS文件并恢复xgb.Booster对象。然后,调用xgb.save以使用稳定表示导出模型,就能够在最新版本的XGBoost中使用该模型。
- Python
import xgboost as xgbbst = xgb.Booster({'nthread': 4})
bst.load_model('model_file_name.json') # load xgb modelpreds = bst.predict(xgb.DMatrix(X_test)) # predict if x_test is not DMatrix format
print(preds)
保存和加载内部参数配置
XGBoost的C API、Python API和R API支持直接将内部配置保存和加载为JSON字符串。在Python包中:
bst = xgboost.train(...)
config = bst.save_config()
print(config)
或在R中:
config <- xgb.config(bst)
print(config)
将打印出类似以下的内容(由于太长,以下内容不是实际输出,仅用于演示):
{"Learner": {"generic_parameter": {"device": "cuda:0","gpu_page_size": "0","n_jobs": "0","random_state": "0","seed": "0","seed_per_iteration": "0"},"gradient_booster": {"gbtree_train_param": {"num_parallel_tree": "1","process_type": "default","tree_method": "hist","updater": "grow_gpu_hist","updater_seq": "grow_gpu_hist"},"name": "gbtree","updater": {"grow_gpu_hist": {"gpu_hist_train_param": {"debug_synchronize": "0",},"train_param": {"alpha": "0","cache_opt": "1","colsample_bylevel": "1","colsample_bynode": "1","colsample_bytree": "1","default_direction": "learn",..."subsample": "1"}}}},"learner_train_param": {"booster": "gbtree","disable_default_eval_metric": "0","objective": "reg:squarederror"},"metrics": [],"objective": {"name": "reg:squarederror","reg_loss_param": {"scale_pos_weight": "1"}}},"version": [1, 0, 0]
}
可以将其加载回由相同版本的XGBoost生成的模型,方法是:
bst.load_config(config)
保存模型和转储模型之间的区别
XGBoost在Booster对象中有一个名为dump_model的函数,它以可读的格式(如txt、json或dot(graphviz))导出模型。它的主要用途是进行模型解释或可视化,不应该加载回XGBoost。JSON版本具有模式Schema 。
保存模型(Save Model): 通过save_model函数,XGBoost将整个模型以二进制格式保存到文件中。这包括模型的树结构、超参数和目标函数等。保存的模型文件可以用于在不同的XGBoost版本之间共享、加载和继续训练。
- Python
booster.save_model('model.bin')
- R
xgb.save(booster, 'model.bin')
转储模型(Dump Model): 通过dump_model函数,XGBoost将模型导出为可读的文本、JSON或Graphviz DOT格式,以便进行模型解释、可视化或分析。这是为了方便用户查看模型的结构和特性,而不是用于加载回XGBoost进行进一步的训练或预测。
- Python
booster.dump_model('model.txt')
- R
xgb.dump(booster, 'model.txt')
Json Schema
JSON格式的另一个重要特点是有一个详细记录的模式(schema),基于这个模式,用户可以轻松地重用XGBoost输出的模型。以下是输出模型的JSON模式(不是序列化,如上所述将不是稳定的)。有关解析XGBoost树模型的示例,请参见/demo/json-model。请注意“dart” booster 中使用的“weight_drop”字段。XGBoost不直接对树叶进行缩放,而是将权重保存为一个单独的数组。
{"$schema": "http://json-schema.org/draft-07/schema#","definitions": {"gbtree": {"type": "object","properties": {"name": {"const": "gbtree"},"model": {"type": "object","properties": {"gbtree_model_param": {"$ref": "#/definitions/gbtree_model_param"},"trees": {"type": "array","items": {"type": "object","properties": {"tree_param": {"$ref": "#/definitions/tree_param"},"id": {"type": "integer"},"loss_changes": {"type": "array","items": {"type": "number"}},"sum_hessian": {"type": "array","items": {"type": "number"}},"base_weights": {"type": "array","items": {"type": "number"}},"left_children": {"type": "array","items": {"type": "integer"}},"right_children": {"type": "array","items": {"type": "integer"}},"parents": {"type": "array","items": {"type": "integer"}},"split_indices": {"type": "array","items": {"type": "integer"}},"split_conditions": {"type": "array","items": {"type": "number"}},"split_type": {"type": "array","items": {"type": "integer"}},"default_left": {"type": "array","items": {"type": "integer"}},"categories": {"type": "array","items": {"type": "integer"}},"categories_nodes": {"type": "array","items": {"type": "integer"}},"categories_segments": {"type": "array","items": {"type": "integer"}},"categories_sizes": {"type": "array","items": {"type": "integer"}}},"required": ["tree_param","loss_changes","sum_hessian","base_weights","left_children","right_children","parents","split_indices","split_conditions","default_left","categories","categories_nodes","categories_segments","categories_sizes"]}},"tree_info": {"type": "array","items": {"type": "integer"}}},"required": ["gbtree_model_param","trees","tree_info"]}},"required": ["name","model"]},"gbtree_model_param": {"type": "object","properties": {"num_trees": {"type": "string"},"num_parallel_tree": {"type": "string"}},"required": ["num_trees","num_parallel_tree"]},"tree_param": {"type": "object","properties": {"num_nodes": {"type": "string"},"size_leaf_vector": {"type": "string"},"num_feature": {"type": "string"}},"required": ["num_nodes","num_feature","size_leaf_vector"]},"reg_loss_param": {"type": "object","properties": {"scale_pos_weight": {"type": "string"}}},"pseudo_huber_param": {"type": "object","properties": {"huber_slope": {"type": "string"}}},"aft_loss_param": {"type": "object","properties": {"aft_loss_distribution": {"type": "string"},"aft_loss_distribution_scale": {"type": "string"}}},"softmax_multiclass_param": {"type": "object","properties": {"num_class": { "type": "string" }}},"lambda_rank_param": {"type": "object","properties": {"num_pairsample": { "type": "string" },"fix_list_weight": { "type": "string" }}},"lambdarank_param": {"type": "object","properties": {"lambdarank_num_pair_per_sample": { "type": "string" },"lambdarank_pair_method": { "type": "string" },"lambdarank_unbiased": {"type": "string" },"lambdarank_bias_norm": {"type": "string" },"ndcg_exp_gain": {"type": "string"}}}},"type": "object","properties": {"version": {"type": "array","items": [{"type": "number","minimum": 1},{"type": "number","minimum": 0},{"type": "number","minimum": 0}],"minItems": 3,"maxItems": 3},"learner": {"type": "object","properties": {"feature_names": {"type": "array","items": {"type": "string"}},"feature_types": {"type": "array","items": {"type": "string"}},"gradient_booster": {"oneOf": [{"$ref": "#/definitions/gbtree"},{"type": "object","properties": {"name": { "const": "gblinear" },"model": {"type": "object","properties": {"weights": {"type": "array","items": {"type": "number"}}}}}},{"type": "object","properties": {"name": { "const": "dart" },"gbtree": {"$ref": "#/definitions/gbtree"},"weight_drop": {"type": "array","items": {"type": "number"}}},"required": ["name","gbtree","weight_drop"]}]},"objective": {"oneOf": [{"type": "object","properties": {"name": { "const": "reg:squarederror" },"reg_loss_param": { "$ref": "#/definitions/reg_loss_param"}},"required": ["name","reg_loss_param"]},{"type": "object","properties": {"name": { "const": "reg:pseudohubererror" },"reg_loss_param": { "$ref": "#/definitions/reg_loss_param"}},"required": ["name","reg_loss_param"]},{"type": "object","properties": {"name": { "const": "reg:squaredlogerror" },"reg_loss_param": { "$ref": "#/definitions/reg_loss_param"}},"required": ["name","reg_loss_param"]},{"type": "object","properties": {"name": { "const": "reg:linear" },"reg_loss_param": { "$ref": "#/definitions/reg_loss_param"}},"required": ["name","reg_loss_param"]},{"type": "object","properties": {"name": { "const": "reg:logistic" },"reg_loss_param": { "$ref": "#/definitions/reg_loss_param"}},"required": ["name","reg_loss_param"]},{"type": "object","properties": {"name": { "const": "binary:logistic" },"reg_loss_param": { "$ref": "#/definitions/reg_loss_param"}},"required": ["name","reg_loss_param"]},{"type": "object","properties": {"name": { "const": "binary:logitraw" },"reg_loss_param": { "$ref": "#/definitions/reg_loss_param"}},"required": ["name","reg_loss_param"]},{"type": "object","properties": {"name": { "const": "count:poisson" },"poisson_regression_param": {"type": "object","properties": {"max_delta_step": { "type": "string" }}}},"required": ["name","poisson_regression_param"]},{"type": "object","properties": {"name": { "const": "reg:tweedie" },"tweedie_regression_param": {"type": "object","properties": {"tweedie_variance_power": { "type": "string" }}}},"required": ["name","tweedie_regression_param"]},{"properties": {"name": {"const": "reg:absoluteerror"}},"type": "object"},{"properties": {"name": {"const": "reg:quantileerror"},"quantile_loss_param": {"type": "object","properties": {"quantle_alpha": {"type": "array"}}}},"type": "object"},{"type": "object","properties": {"name": { "const": "survival:cox" }},"required": [ "name" ]},{"type": "object","properties": {"name": { "const": "reg:gamma" }},"required": [ "name" ]},{"type": "object","properties": {"name": { "const": "multi:softprob" },"softmax_multiclass_param": { "$ref": "#/definitions/softmax_multiclass_param"}},"required": ["name","softmax_multiclass_param"]},{"type": "object","properties": {"name": { "const": "multi:softmax" },"softmax_multiclass_param": { "$ref": "#/definitions/softmax_multiclass_param"}},"required": ["name","softmax_multiclass_param"]},{"type": "object","properties": {"name": { "const": "rank:pairwise" },"lambda_rank_param": { "$ref": "#/definitions/lambdarank_param"}},"required": ["name","lambdarank_param"]},{"type": "object","properties": {"name": { "const": "rank:ndcg" },"lambda_rank_param": { "$ref": "#/definitions/lambdarank_param"}},"required": ["name","lambdarank_param"]},{"type": "object","properties": {"name": { "const": "rank:map" },"lambda_rank_param": { "$ref": "#/definitions/lambda_rank_param"}},"required": ["name","lambda_rank_param"]},{"type": "object","properties": {"name": {"const": "survival:aft"},"aft_loss_param": { "$ref": "#/definitions/aft_loss_param"}}},{"type": "object","properties": {"name": {"const": "binary:hinge"}}}]},"learner_model_param": {"type": "object","properties": {"base_score": { "type": "string" },"num_class": { "type": "string" },"num_feature": { "type": "string" },"num_target": { "type": "string" }}}},"required": ["gradient_booster","objective"]}},"required": ["version","learner"]
}
相关文章:

XGB-3: 模型IO
在XGBoost 1.0.0中,引入了对使用JSON保存/加载XGBoost模型和相关超参数的支持,旨在用一个可以轻松重用的开放格式取代旧的二进制内部格式。后来在XGBoost 1.6.0中,还添加了对通用二进制JSON的额外支持,作为更高效的模型IO的优化。…...

springboot(ssm船舶维保管理系统 船只报修管理系统Java系统
springboot(ssm船舶维保管理系统 船只报修管理系统Java系统 开发语言:Java 框架:springboot(可改ssm) vue JDK版本:JDK1.8(或11) 服务器:tomcat 数据库:mysql 5.7&a…...
机器学习本科课程 大作业 多元时间序列预测
1. 问题描述 1.1 阐述问题 对某电力部门的二氧化碳排放量进行回归预测,有如下要求 数据时间跨度从1973年1月到2021年12月,按月份记录。数据集包括“煤电”,“天然气”,“馏分燃料”等共9个指标的数据(其中早期的部分…...

[office] excel中weekday函数的使用方法 #学习方法#微信#媒体
excel中weekday函数的使用方法 在EXCEL中Weekday是一个日期函数,可以计算出特定日期所对应的星期数。下面给大家介绍下Weekday函数作用方法。 01、比如,我在A84单元格输入一个日期,2018/5/9;那么,我们利用weekday计算…...

PAT-Apat甲级题1007(python和c++实现)
PTA | 1007 Maximum Subsequence Sum 1007 Maximum Subsequence Sum 作者 CHEN, Yue 单位 浙江大学 Given a sequence of K integers { N1, N2, ..., NK }. A continuous subsequence is defined to be { Ni, Ni1, ..., Nj } where 1≤i≤j≤K. The Maximum Su…...

洛谷:P2957 [USACO09OCT] Barn Echoes G
题目描述 The cows enjoy mooing at the barn because their moos echo back, although sometimes not completely. Bessie, ever the excellent secretary, has been recording the exact wording of the moo as it goes out and returns. She is curious as to just how mu…...

flinksqlbug : AggregateFunction udf Could not extract a data type from
org.apache.flink.table.api.ValidationException: SQL validation failed. An error occurred in the type inference logic of function ‘default_catalog.default_database.CollectSetSort’. org.apache.flink.table.api.ValidationException: An error occurred in the t…...

Aigtek高压放大器用途是什么呢
高压放大器在电子领域中扮演着至关重要的角色,其主要作用是将低电压信号放大到更高的电压水平。这种类型的放大器广泛用于各种应用中,以下是高压放大器的用途以及其关键作用的详细介绍。 1、科学研究和实验室应用: 高压放大器在科学研究和实验…...
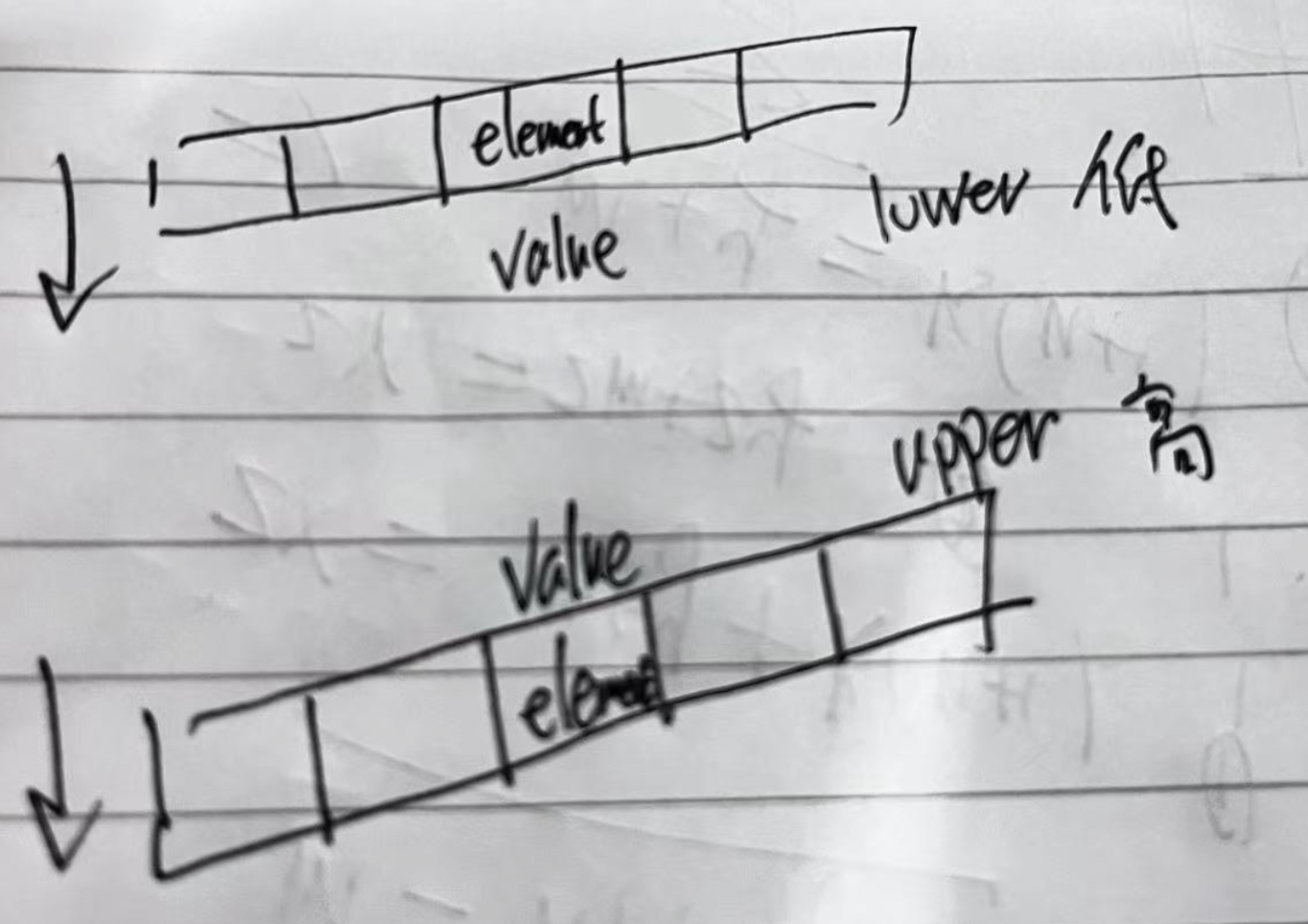
c++ STL less 的视角
c less 函数在不同的地方感觉所起的作用是不一样的, 这中间原因是 less 的视角不一样, 下面尝试给出解释下, 方便记忆 1、 左右视角 符合 排序sort less(value, element) less 表示一种 “符合关系“, 表示sort 后…...
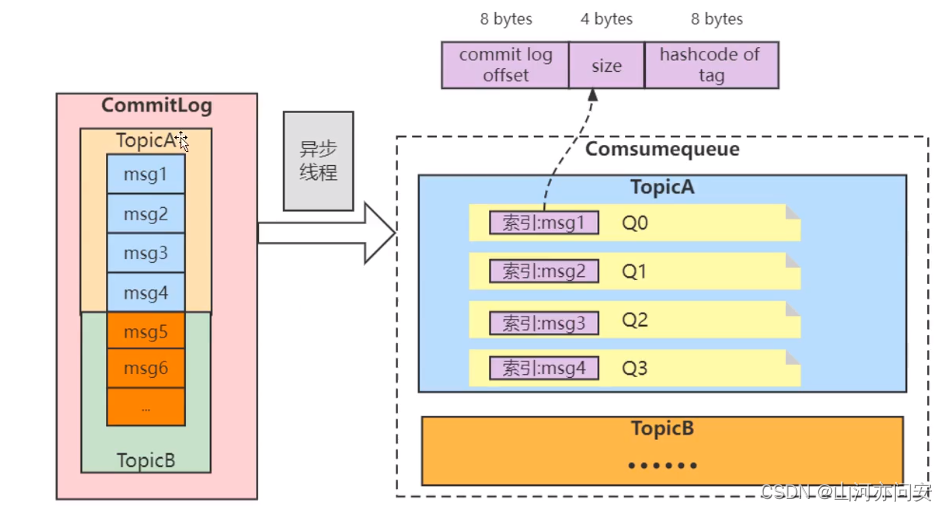
MQ面试题整理(持续更新)
1. MQ的优缺点 优点:解耦,异步,削峰 缺点: 系统可用性降低 系统引入的外部依赖越多,越容易挂掉。万一 MQ 挂了,MQ 一挂,整套系统崩 溃,你不就完了?系统复杂度提高 硬生…...

2401cmake,学习cmake2
步4:安装与测试 现在开始给项目添加安装规则和支持测试. 安装规则 安装规则非常简单:对MathFunctions,想安装库和头文件,对应用,想安装可执行文件和配置头. 所以在MathFunctions/CMakeLists.txt尾添加: install(TARGETS MathFunctions DESTINATION lib) install(FILES Mat…...

理解Jetpack Compose中的`remember`和`mutableStateOf`
理解Jetpack Compose中的remember和mutableStateOf 在现代Android开发中,Jetpack Compose已经成为构建原生UI的首选工具。它引入了一种声明式的编程模式,极大地简化了UI开发。在Compose的世界里,remember和mutableStateOf是两个非常关键的函…...

3D力导向树插件-3d-force-graph学习002
一、实现效果:节点文字同时展示 节点显示不同颜色节点盒label文字并存节点上添加点击事件 二、利用插件:CSS2DRenderer 提示:以下引入文件均可在安装完3d-force-graph的安装包里找到 三、关键代码 提示:模拟数据可按如下格式填…...
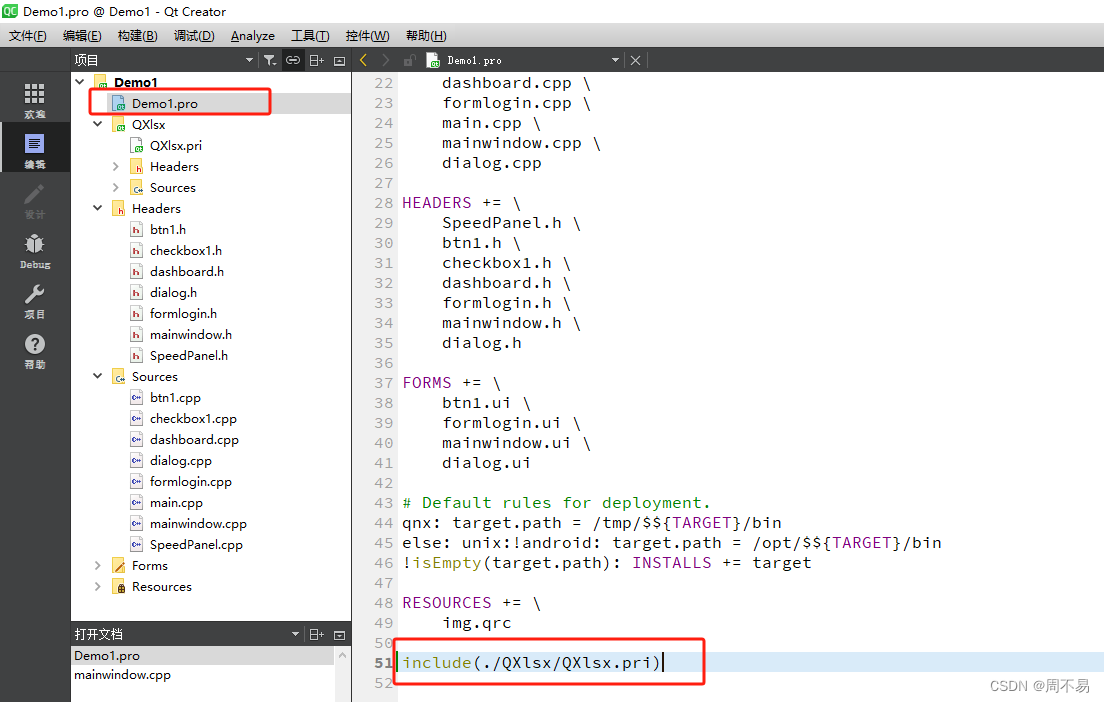
QXlsx Qt操作excel
QXlsx 是一个用于处理Excel文件的开源C库。它允许你在你的C应用程序中读取和写入Microsoft Excel文件(.xlsx格式)。该库支持多种操作,包括创建新的工作簿、读取和写入单元格数据、格式化单元格、以及其他与Excel文件相关的功能。 支持跨平台…...

Node.js 包管理工具
一、概念介绍 1.1 包是什么 『包』英文单词是 package ,代表了一组特定功能的源码集合 1.2 包管理工具 管理『包』的应用软件,可以对「包」进行 下载安装 , 更新 , 删除 , 上传 等操作。 借助包管理工具࿰…...
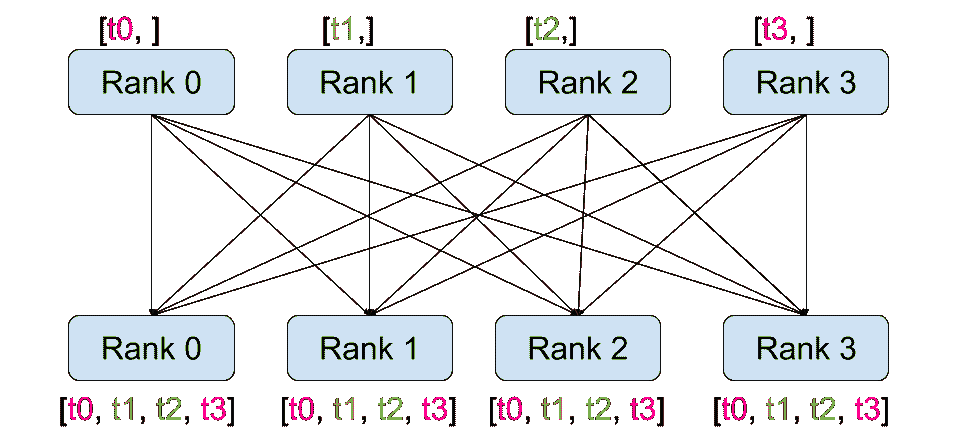
PyTorch 2.2 中文官方教程(十七)
(Beta)使用缩放点积注意力(SDPA)实现高性能 Transformer 原文:pytorch.org/tutorials/intermediate/scaled_dot_product_attention_tutorial.html 译者:飞龙 协议:CC BY-NC-SA 4.0 注意 点击这…...

Failed at the chromedriver@2.27.2 install script.
目录 【错误描述】Failed at the chromedriver2.27.2 install script. npm install报的错误 【解决方法】 删除node_modules文件夹npm install chromedriver --chromedriver_cdnurlhttp://cdn.npm.taobao.org/dist/chromedrivernpm install 【未解决】 下载该zip包运行这个&…...
OpenResty 安装
安装OpenResty 1.安装 首先你的Linux虚拟机必须联网 1)安装开发库 首先要安装OpenResty的依赖开发库,执行命令: yum install -y pcre-devel openssl-devel gcc --skip-broken2)安装OpenResty仓库 你可以在你的 CentOS 系统中…...
套路化编程 C# winform 自适应缩放布局
本例程实现基本的自适应缩放布局。 在本例程中你将会学习到如何通过鼠标改变界面比例(SplitContainer)、如何使用流布局(FlowLayoutPanel)排列控件,当然首先需要了解如何设置控件随窗口缩放。 目录 创建项目 编辑…...
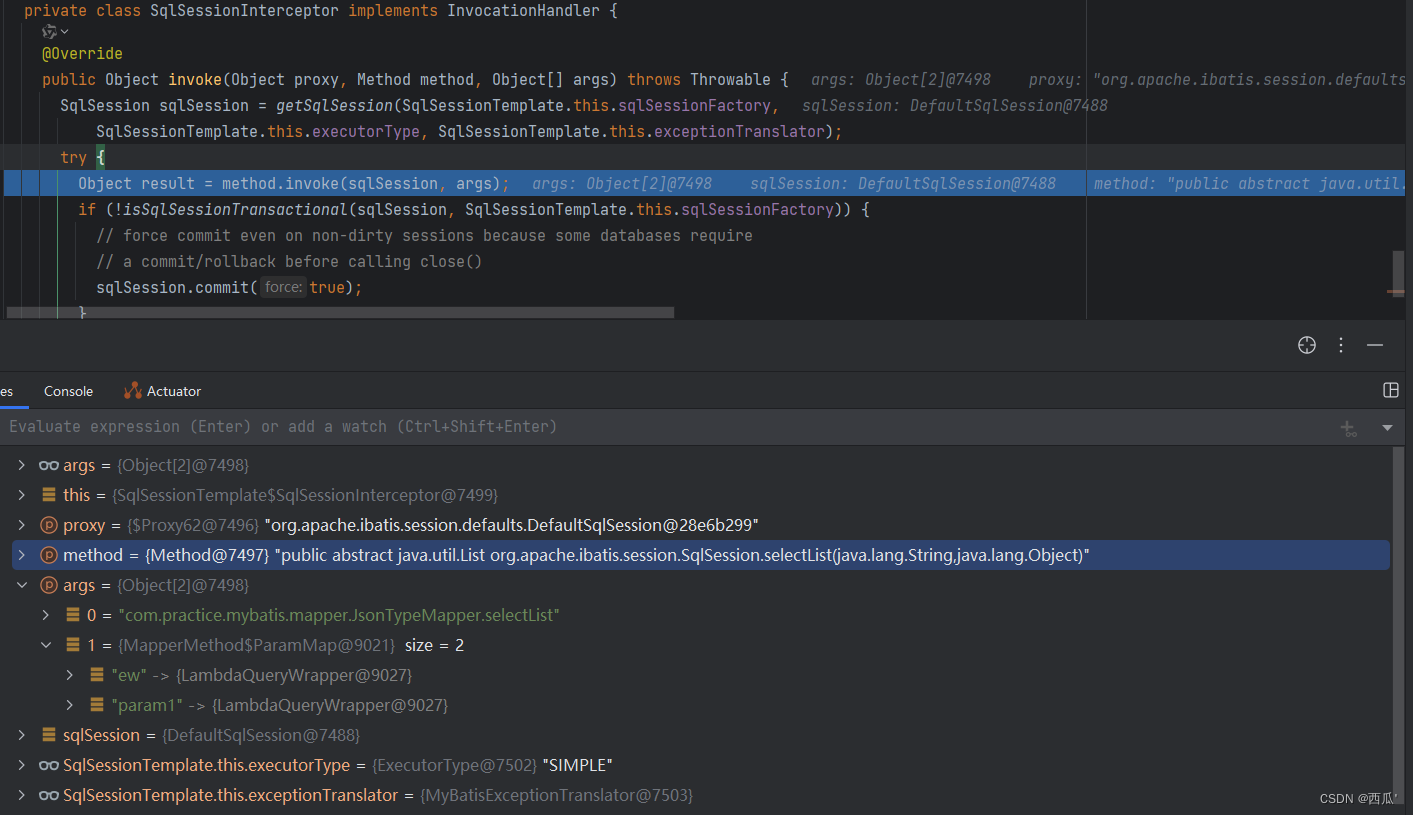
源码梳理(3)MybatisPlus启动流程
文章目录 1,MybatisPlus的使用示例2,BaseMapper方法的执行2,1 MybatisMapperProxy代理对象2.2 InvocationHandler接口(JDK动态代理)2.3 MapperMethodInvoker接口2.4 MybatisMapperMethod 3,SqlSession的执行流程3.1 Sq…...

【数据结构与算法】第23篇:树、森林与二叉树的转换
一、树的存储结构1.1 双亲表示法每个节点存储数据和父节点下标,适合找父节点的场景。c#define MAX_SIZE 100 typedef struct {int data;int parent; // 父节点下标 } PNode;typedef struct {PNode nodes[MAX_SIZE];int root; // 根节点下标int size; } PTree;缺…...

如何在不同的机器上运行多个OpenClaw实例?
想让不同机器上的 OpenClaw 一起协作,其实就是搭建一个跨机器的 “小龙虾通信网络”。实现方式分两种:简单直连(适合测试 / 小集群)和远程网关(适合生产 / 稳定协作)。下面给你一套直接能跑的完整方案。一、…...

基于Python的米家商城毕设源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在深入探讨基于Python技术的米家商城系统设计与实现。具体研究目的如下: 首先,通过对米家商城系统进行深入研究,旨在…...

东方电机RS485嵌入式协议库:多型号统一控制与工业可靠性设计
1. 项目概述OrientalCommon_asukiaaa 是一个专为东方电机(Oriental Motor)RS485通信设备设计的嵌入式通用接口库。该库不直接实现物理层驱动,而是聚焦于协议层抽象与控制逻辑封装,为上层应用提供统一、可移植、符合工业现场总线规…...

基于MMC的两端柔性直流输电系统设计仿真:包含电压平衡控制策略、最近电平调制策略、环流抑制及详...
基于MMC的两端柔性直流输电系统设计仿真 1、MMC-HVDC 电压平衡控制策略:为了实现桥臂子模块的电压动态平衡 在正常运行时,由于桥臂子模块投切存在不一致性,以及级联的子模块中的电容不断的在充电、放电或者闭锁状态切换 2、最近电平调制策略&…...
)
c++编程:说反话(1009-PAT乙级)
1009:说反话cin >> 读取字符串时不能读取空格string s; cin >> s; // 输入 "hello world" cout << s; // 输出 "hello"(空格后面的被丢弃)如何读取带空格的整行?getline()str…...

newTimer嵌入式定时器库:跨平台非阻塞延时与状态机设计
1. newTimer 定时器库深度解析:跨平台嵌入式精准延时与状态管理方案1.1 库定位与工程价值newTimer是一个轻量级、高度可移植的 C 定时器抽象库,专为资源受限的嵌入式微控制器设计。其核心价值不在于替代硬件定时器外设,而在于提供统一、语义清…...

[AI应用框架/Java] Spring AI 应用开发指南<>概述、快速入门
智能体时代的代码范式转移与 C# 的战略转型 传统的 C# 开发模式,即所谓的“工程导向型”开发,要求开发者创建一个复杂的项目结构,包括项目文件(.csproj)、解决方案文件(.sln)、属性设置以及依赖…...

高德地图JS API报错10009?手把手教你解决USERKEY_PLAT_NOMATCH问题
高德地图JS API报错10009?手把手教你解决USERKEY_PLAT_NOMATCH问题 当你在前端项目中集成高德地图JS API时,突然控制台抛出USERKEY_PLAT_NOMATCH错误(错误码10009),这意味着你的密钥与当前使用平台不匹配。这种问题看…...
)
从HCCDA题库看实战:GaussDB开发者必须掌握的10个核心操作(附实验截图指南)
从HCCDA题库看实战:GaussDB开发者必须掌握的10个核心操作(附实验截图指南) 在数据库技术的世界里,认证考试往往被视为理论知识的试金石,但真正考验开发者能力的,是如何将这些理论转化为实际生产力。GaussDB…...