机器学习超参数优化算法(贝叶斯优化)
文章目录
- 贝叶斯优化算法原理
- 贝叶斯优化的实现(三种方法均有代码实现)
- 基于Bayes_opt实现GP优化
- 基于HyperOpt实现TPE优化
- 基于Optuna实现多种贝叶斯优化
贝叶斯优化算法原理
在贝叶斯优化的数学过程当中,我们主要执行以下几个步骤:
-
1 定义需要估计的 f ( x ) f(x) f(x)以及 x x x的定义域
-
2 取出有限的n个 x x x上的值,求解出这些 x x x对应的 f ( x ) f(x) f(x)(求解观测值)
-
3 根据有限的观测值,对函数进行估计(该假设被称为贝叶斯优化中的先验知识),得出该估计 f ∗ f^* f∗上的目标值(最大值或最小值)
-
4 定义某种规则,以确定下一个需要计算的观测点
并持续在2-4步骤中进行循环,直到假设分布上的目标值达到我们的标准,或者所有计算资源被用完为止(例如,最多观测m次,或最多允许运行t分钟)。
以上流程又被称为序贯模型优化(SMBO),是最为经典的贝叶斯优化方法。在实际的运算过程当中,尤其是超参数优化的过程当中,有以下具体细节需要注意:
-
当贝叶斯优化不被用于HPO时,一般 f ( x ) f(x) f(x)可以是完全的黑盒函数(black box function,也译作黑箱函数,即只知道 x x x与 f ( x ) f(x) f(x)的对应关系,却丝毫不知道函数内部规律、同时也不能写出具体表达式的一类函数),因此贝叶斯优化也被认为是可以作用于黑盒函数估计的一类经典方法。但在HPO过程当中,需要定义的 f ( x ) f(x) f(x)一般是交叉验证的结果/损失函数的结果,而我们往往非常清楚损失函数的表达式,只是我们不了解损失函数内部的具体规律,因此HPO中的 f ( x ) f(x) f(x)不能算是严格意义上的黑盒函数。
-
在HPO中,自变量 x x x就是超参数空间。在上述二维图像表示中, x x x为一维的,但在实际进行优化时,超参数空间往往是高维且极度复杂的空间。
-
最初的观测值数量n、以及最终可以取到的最大观测数量m都是贝叶斯优化的超参数,最大观测数量m也决定了整个贝叶斯优化的迭代次数。
-
在第3步中,根据有限的观测值、对函数分布进行估计的工具被称为概率代理模型(Probability Surrogate model),毕竟在数学计算中我们并不能真的邀请数万人对我们的观测点进行连线。这些概率代理模型自带某些假设,他们可以根据廖廖数个观测点估计出目标函数的分布 f ∗ f^* f∗(包括 f ∗ f^* f∗上每个点的取值以及该点对应的置信度)。在实际使用时,概率代理模型往往是一些强大的算法,最常见的比如高斯过程、高斯混合模型等等。传统数学推导中往往使用高斯过程,但现在最普及的优化库中基本都默认使用基于高斯混合模型的TPE过程。
-
在第4步中用来确定下一个观测点的规则被称为采集函数(Aquisition Function),采集函数衡量观测点对拟合 f ∗ f^* f∗所产生的影响,并选取影响最大的点执行下一步观测,因此我们往往关注采集函数值最大的点。最常见的采集函数主要是概率增量PI(Probability of improvement,比如我们计算的频数)、期望增量(Expectation Improvement)、置信度上界(Upper Confidence Bound)、信息熵(Entropy)等等。上方gif图像当中展示了PI、UCB以及EI。其中大部分优化库中默认使用期望增量。
在HPO中使用贝叶斯优化时,我们常常会看见下面的图像,这张图像表现了贝叶斯优化的全部基本元素,我们的目标就是在采集函数指导下,让 f ∗ f^* f∗尽量接近 f ( x ) f(x) f(x)。

贝叶斯优化的实现(三种方法均有代码实现)
贝叶斯优化是当今黑盒函数估计领域最为先进和经典的方法,在同一套序贯模型下使用不同的代理模型以及采集函数、还可以发展出更多更先进的贝叶斯优化改进版算法,因此,贝叶斯优化的其算法本身就多如繁星,实现各种不同种类的贝叶斯优化的库也是琳琅满目,几乎任意一个专业用于超参数优化的工具库都会包含贝叶斯优化的内容。我们可以在以下页面找到大量可以实现贝叶斯优化方法的HPO库:https://www.automl.org/automl/hpo-packages/ ,其中大部分库都是由独立团队开发和维护,因此不同的库之间之间的优劣、性格、功能都有很大的差异。在课程中,我们将介绍如下三个可以实现贝叶斯优化的库:bayesian-optimization,hyperopt,optuna。
| HPO库 | 优劣评价 | 推荐指数 |
|---|---|---|
| bayes_opt | ✅实现基于高斯过程的贝叶斯优化 ✅当参数空间由大量连续型参数构成时 ⛔包含大量离散型参数时避免使用 ⛔算力/时间稀缺时避免使用 | ⭐⭐ |
| hyperopt | ✅实现基于TPE的贝叶斯优化 ✅支持各类提效工具 ✅进度条清晰,展示美观,较少怪异警告或报错 ✅可推广/拓展至深度学习领域 ⛔不支持基于高斯过程的贝叶斯优化 ⛔代码限制多、较为复杂,灵活性较差 | ⭐⭐⭐⭐ |
| optuna | ✅(可能需结合其他库)实现基于各类算法的贝叶斯优化 ✅代码最简洁,同时具备一定的灵活性 ✅可推广/拓展至深度学习领域 ⛔非关键性功能维护不佳,有怪异警告与报错 | ⭐⭐⭐⭐ |
- 导入库,确认使用数据(基于随机森林回归器进行优化)
#基本工具
import numpy as np
import pandas as pd
import time
import os #修改环境设置#算法/损失/评估指标等
import sklearn
from sklearn.ensemble import RandomForestRegressor as RFR
from sklearn.model_selection import KFold, cross_validate#优化器
from bayes_opt import BayesianOptimizationimport hyperopt
from hyperopt import hp, fmin, tpe, Trials, partial
from hyperopt.early_stop import no_progress_lossimport optuna
#导入波士顿房价数据
data = pd.read_csv(r"D:\Pythonwork\datasets\House Price\train_encode.csv",index_col=0)
#查看数据
data.head()
X = data.iloc[:,:-1]
y = data.iloc[:,-1]
基于Bayes_opt实现GP优化
- 1 定义目标函数
目标函数的值即 f ( x ) f(x) f(x)的值。贝叶斯优化会计算 f ( x ) f(x) f(x)在不同 x x x上的观测值,因此 f ( x ) f(x) f(x)的计算方式需要被明确。在HPO过程中,我们希望能够筛选出令模型泛化能力最大的参数组合,因此 f ( x ) f(x) f(x)应该是损失函数的交叉验证值或者某种评估指标的交叉验证值。需要注意的是,bayes_opt库存在三个影响目标函数定义的规则:
1 目标函数的输入必须是具体的超参数,而不能是整个超参数空间,更不能是数据、算法等超参数以外的元素,因此在定义目标函数时,我们需要让超参数作为目标函数的输入。
2 超参数的输入值只能是浮点数,不支持整数与字符串。因此当算法的实际参数需要输入字符串时,该参数不能使用bayes_opt进行调整,当算法的实际参数需要输入整数时,则需要在目标函数中规定参数的类型。
3 bayes_opt只支持寻找 f ( x ) f(x) f(x)的最大值,不支持寻找最小值。因此当我们定义的目标函数是某种损失时,目标函数的输出需要取负(即,如果使用RMSE,则应该让目标函数输出负RMSE,这样最大化负RMSE后,才是最小化真正的RMSE。)当我们定义的目标函数是准确率,或者auc等指标,则可以让目标函数的输出保持原样。
def bayesopt_objective(n_estimators,max_depth,max_features,min_impurity_decrease):#定义评估器#需要调整的超参数等于目标函数的输入,不需要调整的超参数则直接等于固定值#默认参数输入一定是浮点数,因此需要套上int函数处理成整数reg = RFR(n_estimators = int(n_estimators),max_depth = int(max_depth),max_features = int(max_features),min_impurity_decrease = min_impurity_decrease,random_state=83,verbose=False #可自行决定是否开启森林建树的verbose,n_jobs=-1)#定义损失的输出,5折交叉验证下的结果,输出负根均方误差(-RMSE)#注意,交叉验证需要使用数据,但我们不能让数据X,y成为目标函数的输入cv = KFold(n_splits=5,shuffle=True,random_state=83)validation_loss = cross_validate(reg,X,y,scoring="neg_root_mean_squared_error",cv=cv,verbose=False,n_jobs=-1,error_score='raise'#如果交叉验证中的算法执行报错,则告诉我们错误的理由)#交叉验证输出的评估指标是负根均方误差,因此本来就是负的损失#目标函数可直接输出该损失的均值return np.mean(validation_loss["test_score"])
- 2 定义参数空间
在任意超参数优化器中,优化器会将参数空格中的超参数组合作为备选组合,一组一组输入到算法中进行训练。在贝叶斯优化中,超参数组合会被输入我们定义好的目标函数 f ( x ) f(x) f(x)中。
在bayes_opt中,我们使用字典方式来定义参数空间,其中参数的名称为键,参数的取值范围为值。且任意参数的取值范围为双向闭区间,以下方的空间为例,在n_estimators的取值中,80与100都可以被取到。
param_grid_simple = {'n_estimators': (80,100), 'max_depth':(10,25), "max_features": (10,20), "min_impurity_decrease":(0,1)}
需要注意的是,bayes_opt只支持填写参数空间的上界与下界,不支持填写步长等参数,且bayes_opt会将所有参数都当作连续型超参进行处理,因此bayes_opt会直接取出闭区间中任意浮点数作为备选参数。例如,取92.28作为n_estimators的值。
这也是为什么在目标函数中,我们需要对整数型超参的取值都套上int函数。假设优化器取出92.28作为n_estimators的值,实际传入随机森林算法的会是int(92.28) = 92,如此我们可以保证算法运行过程中不会因参数类型不符而报错。也因为bayes_opt的这个性质,输入bayes_opt的参数空间天生会比其他贝叶斯优化库更大/更密,因此需要的迭代次数也更多
- 3 定义优化目标函数的具体流程
在有了目标函数与参数空间之后,我们就可以按bayes_opt的规则进行优化了。在任意贝叶斯优化算法的实践过程中,一定都有涉及到随机性的过程——例如,随机抽取点作为观测点,随机抽样部分观测点进行采集函数的计算等等。在大部分优化库当中,这种随机性是无法控制的,即便允许我们填写随机数种子,优化算法也不能固定下来。因此我们可以尝试填写随机数种子,但需要记住优化算法每次运行时一定都会不一样。
虽然,优化算法无法被复现,但是优化算法得出的最佳超参数的结果却是可以被复现的。只要优化完毕之后,可以从优化算法的实例化对象中取出最佳参数组合以及最佳分数,该最佳参数组合被输入到交叉验证中后,是一定可以复现其最佳分数的。如果没能复现最佳分数,则是交叉验证过程的随机数种子设置存在问题,或者优化算法的迭代流程存在问题。
def param_bayes_opt(init_points,n_iter):#定义优化器,先实例化优化器opt = BayesianOptimization(bayesopt_objective #需要优化的目标函数,param_grid_simple #备选参数空间,random_state=83 #随机数种子,虽然无法控制住)#使用优化器,记住bayes_opt只支持最大化opt.maximize(init_points = init_points #抽取多少个初始观测值, n_iter=n_iter #一共观测/迭代多少次)#优化完成,取出最佳参数与最佳分数params_best = opt.max["params"]score_best = opt.max["target"]#打印最佳参数与最佳分数print("\n","\n","best params: ", params_best,"\n","\n","best cvscore: ", score_best)#返回最佳参数与最佳分数return params_best, score_best
- 4 定义验证函数(非必须)
优化后的结果是可以复现的,即我们可以对优化算法给出的最优参数进行再验证,其中验证函数与目标函数高度相似,输入参数或超参数空间、输出最终的损失函数结果。在使用sklearn中自带的优化算法时,由于优化算法自己会执行分割数据、交叉验证的步骤,因此优化算法得出的最优分数往往与我们自身验证的分数不同(因为交叉验证时的数据分割不同)。然而在贝叶斯优化过程中,目标函数中的交叉验证即数据分割都是我们自己规定的,因此原则上来说,只要在目标函数中设置了随机数种子,贝叶斯优化给出的最佳分数一定与我们验证后的分数相同,所以当对优化过程的代码比较熟悉时,可以不用进行二次验证。
# 即带入最优参数查看结果
def bayes_opt_validation(params_best):reg = RFR(n_estimators = int(params_best["n_estimators"]) ,max_depth = int(params_best["max_depth"]),max_features = int(params_best["max_features"]),min_impurity_decrease = params_best["min_impurity_decrease"],random_state=83,verbose=False,n_jobs=-1)cv = KFold(n_splits=5,shuffle=True,random_state=83)validation_loss = cross_validate(reg,X,y,scoring="neg_root_mean_squared_error",cv=cv,verbose=False,n_jobs=-1)return np.mean(validation_loss["test_score"])
- 5 执行实际优化流程
start = time.time()
params_best, score_best = param_bayes_opt(20,280) #初始看20个观测值,后面迭代280次
print('It takes %s minutes' % ((time.time() -2 start)/60))
validation_score = bayes_opt_validation(params_best)
print("\n","\n","validation_score: ",validation_score)
可以查看最终结果

基于HyperOpt实现TPE优化
Hyperopt优化器是目前最为通用的贝叶斯优化器之一,Hyperopt中集成了包括随机搜索、模拟退火和TPE(Tree-structured Parzen Estimator Approach)等多种优化算法。相比于Bayes_opt,Hyperopt的是更先进、更现代、维护更好的优化器,也是我们最常用来实现TPE方法的优化器。在实际使用中,相比基于高斯过程的贝叶斯优化,基于高斯混合模型的TPE在大多数情况下以更高效率获得更优结果,该方法目前也被广泛应用于AutoML领域中。TPE算法原理可以参阅原论文Multiobjective tree-structured parzen estimator for computationally expensive optimization problems,在这里我们将重点介绍关于Hyperopt中使用TPE进行超参数搜索的过程。
- 1 定义目标函数
在定义目标函数 f ( x ) f(x) f(x)时,我们需要严格遵守需要使用的当下优化库的基本规则。与Bayes_opt一样,Hyperopt也有一些特定的规则会限制我们的定义方式,主要包括:
1 目标函数的输入必须是符合hyperopt规定的字典,不能是类似于sklearn的参数空间字典、不能是参数本身,更不能是数据、算法等超参数以外的元素。因此在自定义目标函数时,我们需要让超参数空间字典作为目标函数的输入。
2 Hyperopt只支持寻找 f ( x ) f(x) f(x)的最小值,不支持寻找最大值,因此当我们定义的目标函数是某种正面的评估指标时(如准确率,auc),我们需要对该评估指标取负。如果我们定义的目标函数是负损失,也需要对负损失取绝对值。当且仅当我们定义的目标函数是普通损失时,我们才不需要改变输出。
def hyperopt_objective(params):#定义评估器#需要搜索的参数需要从输入的字典中索引出来#不需要搜索的参数,可以是设置好的某个值#在需要整数的参数前调整参数类型reg = RFR(n_estimators = int(params["n_estimators"]),max_depth = int(params["max_depth"]),max_features = int(params["max_features"]),min_impurity_decrease = params["min_impurity_decrease"],random_state=83,verbose=False,n_jobs=-1)#交叉验证结果,输出负根均方误差(-RMSE)cv = KFold(n_splits=5,shuffle=True,random_state=83)validation_loss = cross_validate(reg,X,y,scoring="neg_root_mean_squared_error",cv=cv,verbose=False,n_jobs=-1,error_score='raise')#最终输出结果,由于只能取最小值,所以必须对(-RMSE)求绝对值#以求解最小RMSE所对应的参数组合return np.mean(abs(validation_loss["test_score"]))
- 2 定义参数空间
在任意超参数优化器中,优化器会将参数空格中的超参数组合作为备选组合,一组一组输入到算法中进行训练。在贝叶斯优化中,超参数组合会被输入我们定义好的目标函数 f ( x ) f(x) f(x)中。
在hyperopt中,我们使用特殊的字典形式来定义参数空间,其中键值对上的键可以任意设置,只要与目标函数中索引参数的键一致即可,键值对的值则是hyperopt独有的hp函数,包括了:
hp.quniform(“参数名称”, 下界, 上界, 步长) - 适用于均匀分布的浮点数
hp.uniform(“参数名称”,下界, 上界) - 适用于随机分布的浮点数
hp.randint(“参数名称”,上界) - 适用于[0,上界)的整数,区间为前闭后开
hp.choice(“参数名称”,[“字符串1”,“字符串2”,…]) - 适用于字符串类型,最优参数由索引表示
hp.choice(“参数名称”,[*range(下界,上界,步长)]) - 适用于整数型,最优参数由索引表示
hp.choice(“参数名称”,[整数1,整数2,整数3,…]) - 适用于整数型,最优参数由索引表示
hp.choice(“参数名称”,[“字符串1”,整数1,…]) - 适用于字符与整数混合,最优参数由索引表示
在hyperopt的说明当中,并未明确参数取值范围空间的开闭,根据实验,如无特殊说明,hp中的参数空间定义方法应当都为前闭后开区间。我们依然使用在随机森林上获得最高分的随机搜索的参数空间:
param_grid_simple = {'n_estimators': hp.quniform("n_estimators",80,100,1), 'max_depth': hp.quniform("max_depth",10,25,1), "max_features": hp.quniform("max_features",10,20,1), "min_impurity_decrease":hp.quniform("min_impurity_decrease",0,5,1)}
由于hp.choice最终会返回最优参数的索引,容易与数值型参数的具体值混淆,而hp.randint又只能够支持从0开始进行计数,因此我们常常会使用quniform获得均匀分布的浮点数来替代整数。对于需要取整数的参数值,如果采用quniform方式构筑参数空间,则需要在目标函数中使用int函数限定输入类型。例如,在范围[0,5]中取值时,可以取出[0.0, 1.0, 2.0, 3.0,…]这种均匀浮点数,在输入目标函数时,则必须确保参数值前存在int函数。当然,如果使用hp.choice则不会存在该问题。
- 3 定义优化目标函数的具体流程
有了目标函数和参数空间,接下来我们就可以进行优化了。在Hyperopt中,我们用于优化的基础功能叫做fmin,在fmin中,我们可以自定义使用的代理模型(参数algo),一般来说我们有tpe.suggest以及rand.suggest两种选项,前者指代TPE方法,后者指代随机网格搜索方法。我们还可以通过partial功能来修改算法涉及到的具体参数,包括模型具体使用了多少个初始观测值(参数n_start_jobs),以及在计算采集函数值时究竟考虑多少个样本(参数n_EI_candidates)。当然,我们也可以不填写这些参数,就使用默认的参数值。
除此之外,Hyperopt当中还有两个值得注意的功能,一个记录整个迭代过程的trials,另一个是提前停止参数early_stop_fn。其中,trials直译为“实验”或“测试”,表示我们不断尝试的每一种参数组合,这个参数中我们一般输入从hyperopt库中导入的方法Trials(),当优化完成之后,我们可以从保存好的trials中查看损失、参数等各种中间信息;而提前停止参数early_stop_fn中我们一般输入从hyperopt库导入的方法no_progress_loss(),这个方法中可以输入具体的数字n,表示当损失连续n次没有下降时,让算法提前停止。由于贝叶斯方法的随机性较高,当样本量不足时需要多次迭代才能够找到最优解,因此一般no_progress_loss()中的数值不会设置得太高。
def param_hyperopt(max_evals=100):#保存迭代过程trials = Trials()#设置提前停止early_stop_fn = no_progress_loss(100)#定义代理模型#algo = partial(tpe.suggest, n_startup_jobs=20, n_EI_candidates=50)params_best = fmin(hyperopt_objective #目标函数, space = param_grid_simple #参数空间, algo = tpe.suggest #代理模型你要哪个呢?#, algo = algo, max_evals = max_evals #允许的迭代次数, verbose=True, trials = trials, early_stop_fn = early_stop_fn)#打印最优参数,fmin会自动打印最佳分数print("\n","\n","best params: ", params_best,"\n")return params_best, trials
- 4 定义验证函数(非必要)
def hyperopt_validation(params): reg = RFR(n_estimators = int(params["n_estimators"]),max_depth = int(params["max_depth"]),max_features = int(params["max_features"]),min_impurity_decrease = params["min_impurity_decrease"],random_state=83,verbose=False,n_jobs=-1)cv = KFold(n_splits=5,shuffle=True,random_state=83)validation_loss = cross_validate(reg,X,y,scoring="neg_root_mean_squared_error",cv=cv,verbose=False,n_jobs=-1)return np.mean(abs(validation_loss["test_score"]))
- 5 执行实际优化流程
params_best, trials = param_hyperopt(300) #10%的空间大小
运行结果

#打印所有搜索相关的记录
trials.trials[0]
由于具有提前停止功能,因此基于TPE的hyperopt优化可能在我们设置的迭代次数被达到之前就停止,也因此hyperopt迭代到实际最优值所需的迭代次数可能更少。同时,TPE方法相比于高斯过程计算会更加迅速,因此在运行277次迭代的情况下,hyperopt只需要1分钟时间,而运行300次迭代的bayes_opt却需要2.11分钟,可见,即便运行同样的迭代次数,hyperopt也是更有优势的,这或许是因为hyperopt的参数空间更加稀疏、在整数型参数搜索上更高效。
不过HyperOpt的缺点也很明显,那就是代码精密度要求较高、灵活性较差,略微的改动就可能让代码疯狂报错难以跑通。同时,HyperOpt所支持的优化算法也不够多,如果我们专注地使用TPE方法,则掌握HyperOpt即可,如果我们希望拥有丰富的HPO手段,则可以更深入地接触Optuna库。
基于Optuna实现多种贝叶斯优化
Optuna是目前为止最为成熟、拓展性最强的超参数优化框架,与古旧的bayes_opt相比,Optuna明显是专门为机器学习和深度学习所设计。为了满足机器学习开发者的需求,Optuna拥有强大且固定的API,因此Optuna代码简单,编写高度模块化,是我们介绍的库中代码最为简练的库。Optuna的优势在于,它可以无缝衔接到PyTorch、Tensorflow等深度学习框架上,也可以与sklearn的优化库scikit-optimize结合使用,因此Optuna可以被用于各种各样的优化场景。
- 1 定义目标函数与参数空间
Optuna的目标函数相当特别。在其他优化库中,我们需要单独输入参数或参数空间,优化器会在具体优化过程中将参数空间一一放入我们的目标函数进行优化,但在Optuna中,我们并不需要将参数或参数空间输入目标函数,而是需要直接在目标函数中定义参数空间。特别的是,Optuna优化器会生成一个指代备选参数的变量trial,该变量无法被用户获取或打开,但该变量在优化器中生存,并被输入目标函数。在目标函数中,我们可以通过变量trail所携带的方法来构造参数空间,具体如下所示:
def optuna_objective(trial):#定义参数空间n_estimators = trial.suggest_int("n_estimators",80,100,1) #整数型,(参数名称,下界,上界,步长)max_depth = trial.suggest_int("max_depth",10,25,1)max_features = trial.suggest_int("max_features",10,20,1)#max_features = trial.suggest_categorical("max_features",["log2","sqrt","auto"]) #字符型min_impurity_decrease = trial.suggest_int("min_impurity_decrease",0,5,1)#min_impurity_decrease = trial.suggest_float("min_impurity_decrease",0,5,log=False) #浮点型#定义评估器#需要优化的参数由上述参数空间决定#不需要优化的参数则直接填写具体值reg = RFR(n_estimators = n_estimators,max_depth = max_depth,max_features = max_features,min_impurity_decrease = min_impurity_decrease,random_state=83,verbose=False,n_jobs=-1)#交叉验证过程,输出负均方根误差(-RMSE)#optuna同时支持最大化和最小化,因此如果输出-RMSE,则选择最大化#如果选择输出RMSE,则选择最小化cv = KFold(n_splits=5,shuffle=True,random_state=83)validation_loss = cross_validate(reg,X,y,scoring="neg_root_mean_squared_error",cv=cv #交叉验证模式,verbose=False #是否打印进程,n_jobs=-1 #线程数,error_score='raise')#最终输出RMSEreturn np.mean(abs(validation_loss["test_score"]))
- 2 定义优化目标函数的具体流程
在HyperOpt当中我们可以调整参数algo来自定义用于执行贝叶斯优化的具体算法,在Optuna中我们也可以。大部分备选的算法都集中在Optuna的模块sampler中,包括我们熟悉的TPE优化、随机网格搜索以及其他各类更加高级的贝叶斯过程,对于Optuna.sampler中调出的类,我们也可以直接输入参数来设置初始观测值的数量、以及每次计算采集函数时所考虑的观测值量。在Optuna库中并没有集成实现高斯过程的方法,但我们可以从scikit-optimize里面导入高斯过程来作为optuna中的algo设置,而具体的高斯过程相关的参数则可以通过如下方法进行设置:
def optimizer_optuna(n_trials, algo):#定义使用TPE或者GPif algo == "TPE":algo = optuna.samplers.TPESampler(n_startup_trials = 10, n_ei_candidates = 24)elif algo == "GP":from optuna.integration import SkoptSamplerimport skoptalgo = SkoptSampler(skopt_kwargs={'base_estimator':'GP', #选择高斯过程'n_initial_points':10, #初始观测点10个'acq_func':'EI'} #选择的采集函数为EI,期望增量)#实际优化过程,首先实例化优化器study = optuna.create_study(sampler = algo #要使用的具体算法, direction="minimize" #优化的方向,可以填写minimize或maximize)#开始优化,n_trials为允许的最大迭代次数#由于参数空间已经在目标函数中定义好,因此不需要输入参数空间study.optimize(optuna_objective #目标函数, n_trials=n_trials #最大迭代次数(包括最初的观测值的), show_progress_bar=True #要不要展示进度条呀?)#可直接从优化好的对象study中调用优化的结果#打印最佳参数与最佳损失值print("\n","\n","best params: ", study.best_trial.params,"\n","\n","best score: ", study.best_trial.values,"\n")return study.best_trial.params, study.best_trial.values
- 3 执行实际优化流程
best_params, best_score = optimizer_optuna(300,"TPE")

best_params, best_score = optimizer_optuna(300,"GP")

相关文章:
机器学习超参数优化算法(贝叶斯优化)
文章目录 贝叶斯优化算法原理贝叶斯优化的实现(三种方法均有代码实现)基于Bayes_opt实现GP优化基于HyperOpt实现TPE优化基于Optuna实现多种贝叶斯优化 贝叶斯优化算法原理 在贝叶斯优化的数学过程当中,我们主要执行以下几个步骤: …...
Sklearn、TensorFlow 与 Keras 机器学习实用指南第三版(六)
原文:Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow 译者:飞龙 协议:CC BY-NC-SA 4.0 第十四章:使用卷积神经网络进行深度计算机视觉 尽管 IBM 的 Deep Blue 超级计算机在 1996 年击败了国际象棋世界冠军…...

XGB-3: 模型IO
在XGBoost 1.0.0中,引入了对使用JSON保存/加载XGBoost模型和相关超参数的支持,旨在用一个可以轻松重用的开放格式取代旧的二进制内部格式。后来在XGBoost 1.6.0中,还添加了对通用二进制JSON的额外支持,作为更高效的模型IO的优化。…...

springboot(ssm船舶维保管理系统 船只报修管理系统Java系统
springboot(ssm船舶维保管理系统 船只报修管理系统Java系统 开发语言:Java 框架:springboot(可改ssm) vue JDK版本:JDK1.8(或11) 服务器:tomcat 数据库:mysql 5.7&a…...
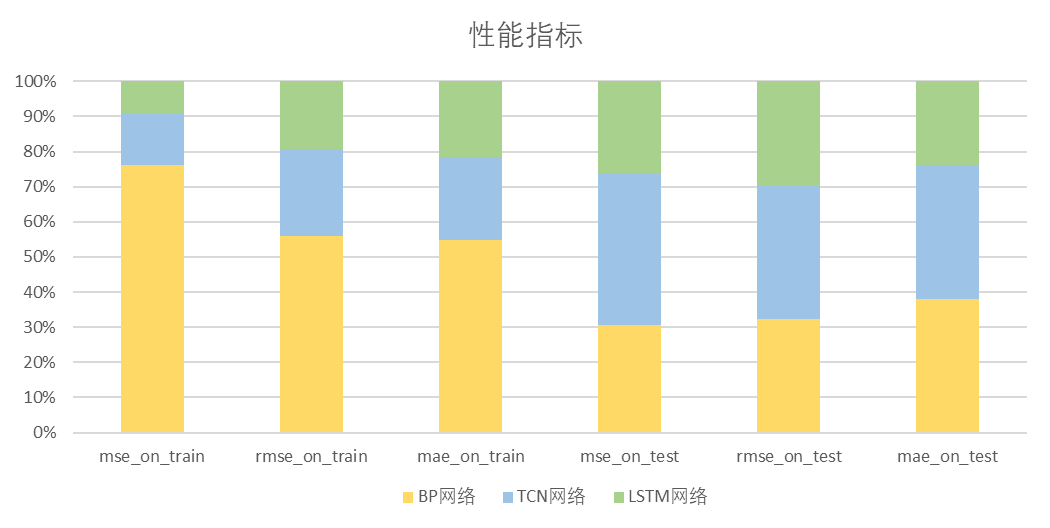
机器学习本科课程 大作业 多元时间序列预测
1. 问题描述 1.1 阐述问题 对某电力部门的二氧化碳排放量进行回归预测,有如下要求 数据时间跨度从1973年1月到2021年12月,按月份记录。数据集包括“煤电”,“天然气”,“馏分燃料”等共9个指标的数据(其中早期的部分…...

[office] excel中weekday函数的使用方法 #学习方法#微信#媒体
excel中weekday函数的使用方法 在EXCEL中Weekday是一个日期函数,可以计算出特定日期所对应的星期数。下面给大家介绍下Weekday函数作用方法。 01、比如,我在A84单元格输入一个日期,2018/5/9;那么,我们利用weekday计算…...

PAT-Apat甲级题1007(python和c++实现)
PTA | 1007 Maximum Subsequence Sum 1007 Maximum Subsequence Sum 作者 CHEN, Yue 单位 浙江大学 Given a sequence of K integers { N1, N2, ..., NK }. A continuous subsequence is defined to be { Ni, Ni1, ..., Nj } where 1≤i≤j≤K. The Maximum Su…...

洛谷:P2957 [USACO09OCT] Barn Echoes G
题目描述 The cows enjoy mooing at the barn because their moos echo back, although sometimes not completely. Bessie, ever the excellent secretary, has been recording the exact wording of the moo as it goes out and returns. She is curious as to just how mu…...

flinksqlbug : AggregateFunction udf Could not extract a data type from
org.apache.flink.table.api.ValidationException: SQL validation failed. An error occurred in the type inference logic of function ‘default_catalog.default_database.CollectSetSort’. org.apache.flink.table.api.ValidationException: An error occurred in the t…...

Aigtek高压放大器用途是什么呢
高压放大器在电子领域中扮演着至关重要的角色,其主要作用是将低电压信号放大到更高的电压水平。这种类型的放大器广泛用于各种应用中,以下是高压放大器的用途以及其关键作用的详细介绍。 1、科学研究和实验室应用: 高压放大器在科学研究和实验…...
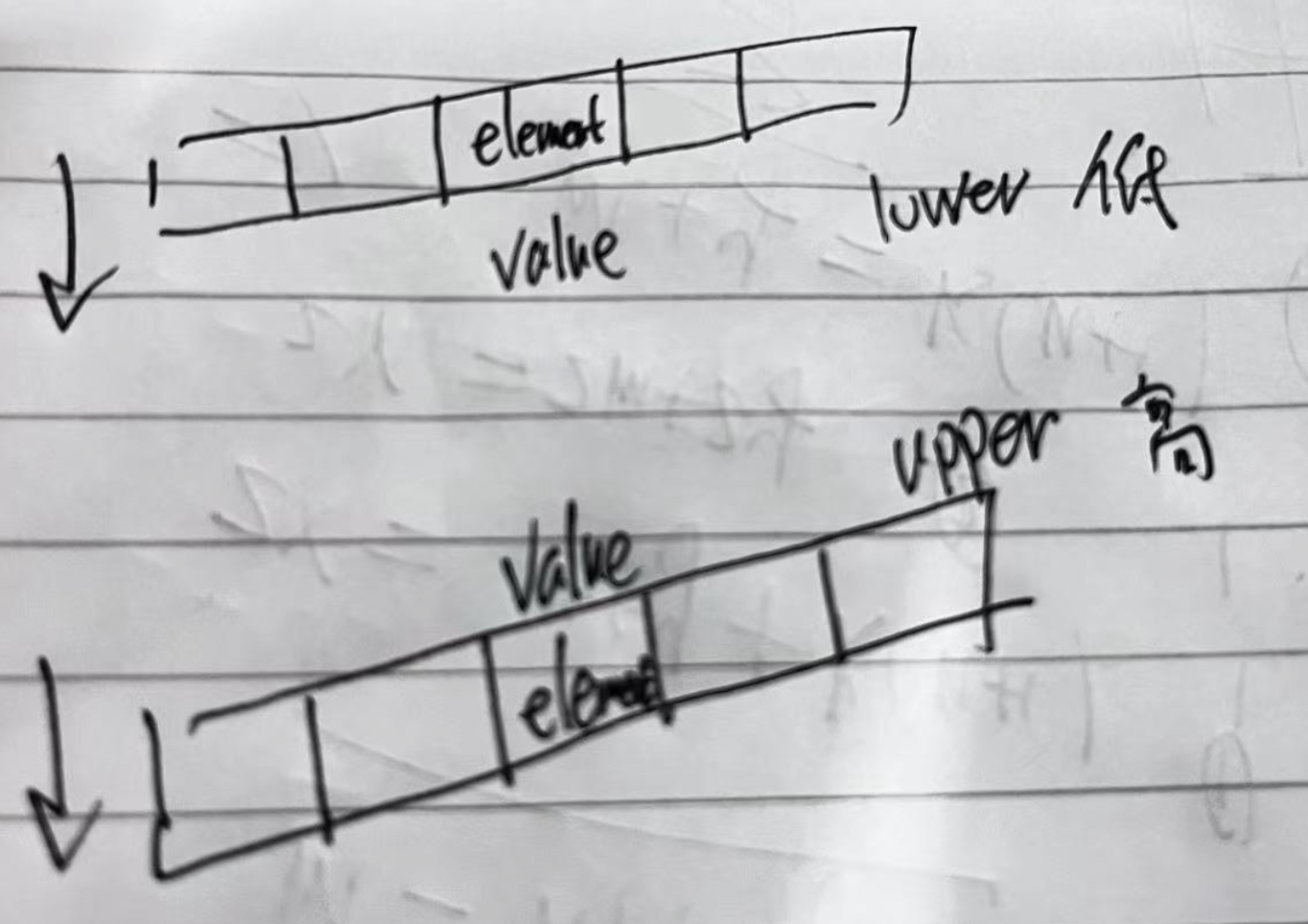
c++ STL less 的视角
c less 函数在不同的地方感觉所起的作用是不一样的, 这中间原因是 less 的视角不一样, 下面尝试给出解释下, 方便记忆 1、 左右视角 符合 排序sort less(value, element) less 表示一种 “符合关系“, 表示sort 后…...
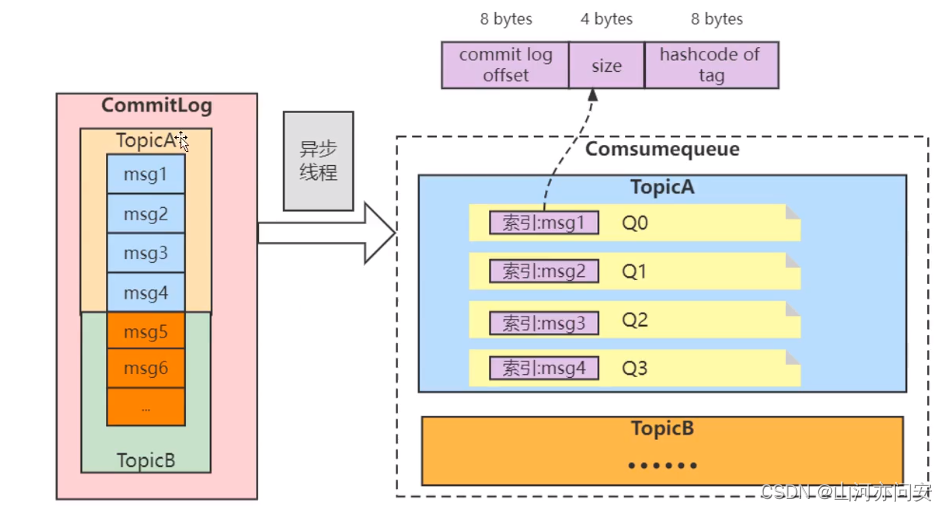
MQ面试题整理(持续更新)
1. MQ的优缺点 优点:解耦,异步,削峰 缺点: 系统可用性降低 系统引入的外部依赖越多,越容易挂掉。万一 MQ 挂了,MQ 一挂,整套系统崩 溃,你不就完了?系统复杂度提高 硬生…...

2401cmake,学习cmake2
步4:安装与测试 现在开始给项目添加安装规则和支持测试. 安装规则 安装规则非常简单:对MathFunctions,想安装库和头文件,对应用,想安装可执行文件和配置头. 所以在MathFunctions/CMakeLists.txt尾添加: install(TARGETS MathFunctions DESTINATION lib) install(FILES Mat…...

理解Jetpack Compose中的`remember`和`mutableStateOf`
理解Jetpack Compose中的remember和mutableStateOf 在现代Android开发中,Jetpack Compose已经成为构建原生UI的首选工具。它引入了一种声明式的编程模式,极大地简化了UI开发。在Compose的世界里,remember和mutableStateOf是两个非常关键的函…...

3D力导向树插件-3d-force-graph学习002
一、实现效果:节点文字同时展示 节点显示不同颜色节点盒label文字并存节点上添加点击事件 二、利用插件:CSS2DRenderer 提示:以下引入文件均可在安装完3d-force-graph的安装包里找到 三、关键代码 提示:模拟数据可按如下格式填…...
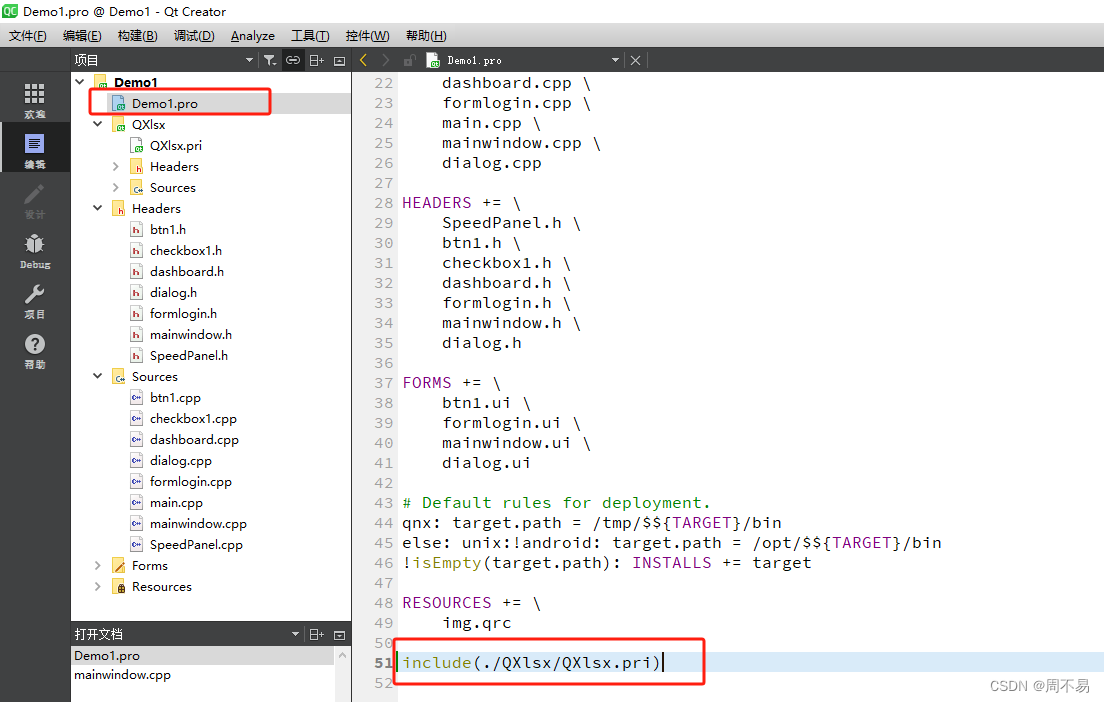
QXlsx Qt操作excel
QXlsx 是一个用于处理Excel文件的开源C库。它允许你在你的C应用程序中读取和写入Microsoft Excel文件(.xlsx格式)。该库支持多种操作,包括创建新的工作簿、读取和写入单元格数据、格式化单元格、以及其他与Excel文件相关的功能。 支持跨平台…...

Node.js 包管理工具
一、概念介绍 1.1 包是什么 『包』英文单词是 package ,代表了一组特定功能的源码集合 1.2 包管理工具 管理『包』的应用软件,可以对「包」进行 下载安装 , 更新 , 删除 , 上传 等操作。 借助包管理工具࿰…...
PyTorch 2.2 中文官方教程(十七)
(Beta)使用缩放点积注意力(SDPA)实现高性能 Transformer 原文:pytorch.org/tutorials/intermediate/scaled_dot_product_attention_tutorial.html 译者:飞龙 协议:CC BY-NC-SA 4.0 注意 点击这…...

Failed at the chromedriver@2.27.2 install script.
目录 【错误描述】Failed at the chromedriver2.27.2 install script. npm install报的错误 【解决方法】 删除node_modules文件夹npm install chromedriver --chromedriver_cdnurlhttp://cdn.npm.taobao.org/dist/chromedrivernpm install 【未解决】 下载该zip包运行这个&…...
OpenResty 安装
安装OpenResty 1.安装 首先你的Linux虚拟机必须联网 1)安装开发库 首先要安装OpenResty的依赖开发库,执行命令: yum install -y pcre-devel openssl-devel gcc --skip-broken2)安装OpenResty仓库 你可以在你的 CentOS 系统中…...

OpenClaw+百川2-13B:技术面试题库自动更新与练习
OpenClaw百川2-13B:技术面试题库自动更新与练习 1. 为什么需要自动化面试题库 去年准备跳槽时,我发现自己收藏的面试题文档已经两年没更新了。技术栈迭代太快,LeetCode题库每月新增上百道题,手动维护题库就像用勺子舀干海水。直…...

从PX4的FRD到Mavros的FLU:手把手教你正确配置`setpoint_raw/local`话题发布无人机目标点
从PX4的FRD到Mavros的FLU:无人机坐标系转换实战指南 当你在ROS环境下通过Mavros向PX4飞控发送位置指令时,是否遇到过无人机朝完全相反方向飞行的情况?这种"方向错乱"的根源往往在于坐标系理解的偏差。本文将彻底解开PX4与Mavros之间…...

Lux测试框架完整指南:如何编写高效的数据可视化测试用例
Lux测试框架完整指南:如何编写高效的数据可视化测试用例 【免费下载链接】lux Automatically visualize your pandas dataframe via a single print! 📊 💡 项目地址: https://gitcode.com/gh_mirrors/lux/lux Lux是一个强大的Python数…...

低成本验证创意:星图OpenClaw沙盒+Qwen3.5-9B试玩图片转代码
低成本验证创意:星图OpenClaw沙盒Qwen3.5-9B试玩图片转代码 1. 为什么需要沙盒环境验证创意 作为自由职业者,我经常遇到客户提出"把这张手绘草图变成网页原型"的需求。传统做法要么手动编写HTML/CSS(耗时),…...

单相光伏电池并网:扰动观测法实现最大功率输出与直流母线电压恒定策略
单相光伏电池并网 1.光伏采用扰动观测法实现最大功率输出 2.逆变器采用直流母线电压恒定策略 3.实现光伏的最大功率输出,直流母线电压维持在恒定值,总谐波畸变率满足并网条件光伏板在阳台上晒得发烫的时候,我最喜欢蹲在配电箱旁边观察电流表指…...

ArduinoAPI:mbed OS 上的轻量级 Arduino 兼容层
1. ArduinoAPI 库概述ArduinoAPI 是一个面向嵌入式开发者的轻量级兼容层库,其核心定位并非复刻 Arduino IDE 的完整生态,而是在 mbed OS 平台上提供一套语义兼容、接口简洁、可裁剪的 Arduino Core API 子集。该库不依赖 Arduino IDE 或 avr-gcc 工具链&…...

SPPF中的CSP结构解析
在YOLOv5/v8等目标检测模型中,SPPF 内的 CSP 结构特指 SPPFCSPC 模块或类似变体。它是一种将空间金字塔池化层(SPPF) 与跨阶段部分网络思想(CSPNet) 紧密结合的复合模块,旨在更高效地进行多尺度特征融合并提…...

【GitLab npm Registry 非标准端口安装问题解决方案】
GitLab npm Registry 非标准端口安装问题解决方案 问题类型: npm/pnpm 客户端与 GitLab npm Registry 集成 影响范围: 使用非标准端口的 GitLab npm Registry 解决时间: 2026-04-03 文档版本: v1.0 一、问题背景 1.1 业务场景 团队需要将内部组件库发布到私有 npm registry,选…...

LPS331AP SPI嵌入式驱动库:Mbed平台高精度气压温度传感器底层控制
1. LPS331AP_SPI 库概述LPS331AP_SPI 是一个专为 Mbed OS 平台设计的轻量级 SPI 驱动库,面向意法半导体(STMicroelectronics)推出的高精度数字气压/温度传感器 LPS331AP。该器件采用 MEMS 技术,集成压力传感单元与温度传感单元&am…...
)
基于单片机的心率及跌倒检测系统设计(有完整资料)
资料查找方式:特纳斯电子(电子校园网):搜索下面编号即可编号:T4192205M设计简介:本设计是基于单片机的心率及跌倒检测系统,主要实现以下功能:1、可通过心率模块检测当前的心率 2、可…...