Python 处理小样本数据的文档分类问题
在处理小样本数据的文档分类问题时,可以尝试使用迁移学习或者基于预训练模型的方法,如BERT、GPT等。然而,直接在这里编写一个完整的深度学习文档分类代码超出了这个平台的限制,但我可以为你提供一个基本的思路和简单示例,你可以根据这个思路进一步研究并实现。
# 导入必要的库
from transformers import BertTokenizer, BertForSequenceClassification
import torch
from torch.utils.data import Dataset, DataLoader# 假设你已经有了预处理的数据,每个样本是一个dict,包含'id','text'和'label'
class DocumentDataset(Dataset):def __init__(self, data, tokenizer, max_len):self.data = dataself.tokenizer = tokenizerself.max_len = max_lendef __len__(self):return len(self.data)def __getitem__(self, idx):text = self.data[idx]['text']label = self.data[idx]['label']encoding = self.tokenizer.encode_plus(text,add_special_tokens=True,max_length=self.max_len,padding='max_length',truncation=True,return_attention_mask=True,return_tensors='pt',)return {'input_ids': encoding['input_ids'].flatten(),'attention_mask': encoding['attention_mask'].flatten(),'labels': torch.tensor(label, dtype=torch.long)}# 初始化预训练模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=NUM_CLASSES) # NUM_CLASSES是你类别的数量# 假设你已经加载了小量数据到data变量中
dataset = DocumentDataset(data, tokenizer, max_len=128) # 调整max_len以适应你的需求
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE) # BATCH_SIZE是批次大小# 然后进行模型训练,这里仅展示训练循环的基本结构
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE) # 设置学习率for epoch in range(NUM_EPOCHS): # NUM_EPOCHS是训练轮数for batch in dataloader:input_ids = batch['input_ids'].to(device)attention_mask = batch['attention_mask'].to(device)labels = batch['labels'].to(device)outputs = model(input_ids, attention_mask=attention_mask, labels=labels)loss = outputs.lossoptimizer.zero_grad()loss.backward()optimizer.step()# 训练完成后,你可以用验证集或测试集评估模型性能# 注意:由于数据量较小,过拟合的风险较高,可能需要采取正则化、早停法等策略来优化模型。以上代码仅为示例,并未涵盖完整的工作流程,包括数据预处理、模型微调、模型评估与选择等步骤。在实际应用中,你还需要根据具体的数据格式和项目需求进行相应的调整。同时,对于小样本问题,也可以考虑采用数据增强、元学习等相关技术提高模型性能
相关文章:

Python 处理小样本数据的文档分类问题
在处理小样本数据的文档分类问题时,可以尝试使用迁移学习或者基于预训练模型的方法,如BERT、GPT等。然而,直接在这里编写一个完整的深度学习文档分类代码超出了这个平台的限制,但我可以为你提供一个基本的思路和简单示例ÿ…...

centos7安装oracle
1 安装虚拟机 设置4G内存,硬盘40G 2 配置网络环境 2.1配置主机名 # vi /etc/hostname 修改为 oracle2.2 配置IP地址 # vi /etc/sysconfig/network-scripts/ifcfg-ens33 修改 BOOTPROTO"static" ONBOOT"yes" IPADDR192.168.109.110 NETMAS…...
Web html
目录 1 前言2 HTML2.1 元素(Element)2.1.1 块级元素和内联(行级)元素2.1.2 空元素 2.2 html页面的文档结构2.3 常见标签使用2.3.1 注释2.3.2 标题2.3.3 段落2.3.4 列表2.3.5 超链接2.3.6 图片2.3.7 内联(行级)标签2.3.8 换行 2.4 属性2.4.1 布尔属性 2.5 实体引用2.6 空格2.7 D…...

Go语言学习踩坑记
go: go.mod file not found in current directory or any parent directory; see go help mod 解决 资源下载: 序号文件地址1 1、Go IDE liteidex38.3-win64-qt5.15.2.zip Release x38.3 visualfc/liteide GitHub2 2、Go语言的编译环境 go1.21.6.windows-amd64.m…...

Vue-easy-tree封装及使用
1.使用及安装 下载依赖 npm install wchbrad/vue-easy-tree引入俩种方案 1.在main.js中引入 import VueEasyTree from "wchbrad/vue-easy-tree"; import "wchbrad/vue-easy-tree/src/assets/index.scss" Vue.use(VueEasyTree)2.当前页面引入 import VueEa…...
opencv中使用cuda加速图像处理
opencv大多数只使用到了cpu的版本,实际上对于复杂的图像处理过程用cuda(特别是高分辨率的图像)可能会有加速效果。是否需要使用cuda需要思考: 1、opencv的cuda库是否提供了想要的算子。在CUDA-accelerated Computer Vision你可以…...

FPGA高端项目:IMX327 MIPI 视频解码 USB3.0 UVC 输出,提供FPGA开发板+2套工程源码+技术支持
目录 1、前言免责声明 2、相关方案推荐我这里已有的 MIPI 编解码方案 3、本 MIPI CSI-RX IP 介绍4、个人 FPGA高端图像处理开发板简介5、详细设计方案设计原理框图IMX327 及其配置MIPI CSI RX图像 ISP 处理图像缓存UVC 时序USB3.0输出架构 6、vivado工程详解FPGA逻辑设计 7、工…...

深入探索 MySQL 8 中的 JSON 类型:功能与应用
随着 NoSQL 数据库的兴起,JSON 作为一种轻量级的数据交换格式受到了广泛的关注。为了满足现代应用程序的需求,MySQL 8引入了原生的 JSON 数据类型,提供了一系列强大的 JSON 函数来处理和查询 JSON 数据。本文将深入探讨 MySQL 8 中JSON 类型的…...
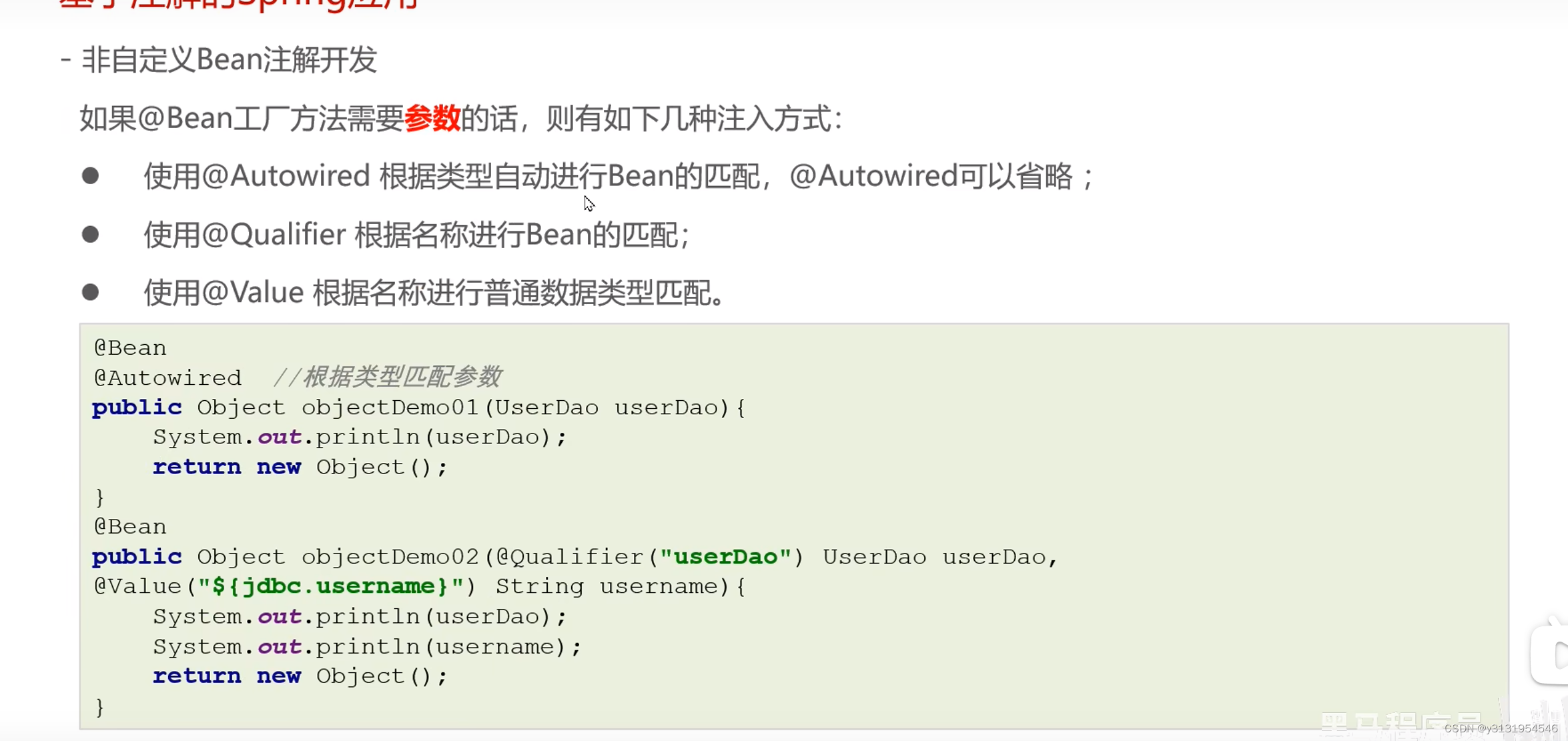
学习Spring的第十三天
非自定义bean注解开发 设置非自定义bean : 用bean去修饰一个方法 , 最后去返回 , spring就把返回的这个对象,放到Spring容器 一 :名字 : 如果bean配置了参数 , 名字就是参数名 , 如果没有 , 就是方法名字 二 : 如果方法产生对象时 , 需要注入数据 , 在方法参数设置即可 , …...

jss/css/html 相关的技术栈有哪些?
js 的技术组件有哪些?比如 jQuery vue 等 常见的JavaScript技术组件: jQuery: jQuery是一个快速、小巧且功能丰富的JavaScript库,用于简化DOM操作、事件处理、动画效果等任务。 React: React是由Facebook开发的用于构…...

机器学习超参数优化算法(贝叶斯优化)
文章目录 贝叶斯优化算法原理贝叶斯优化的实现(三种方法均有代码实现)基于Bayes_opt实现GP优化基于HyperOpt实现TPE优化基于Optuna实现多种贝叶斯优化 贝叶斯优化算法原理 在贝叶斯优化的数学过程当中,我们主要执行以下几个步骤: …...
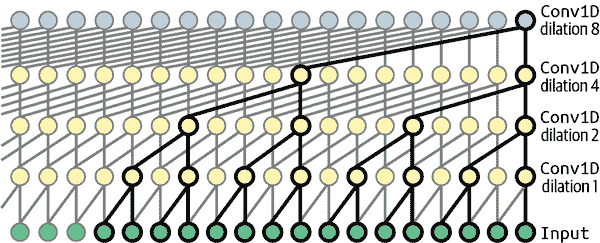
Sklearn、TensorFlow 与 Keras 机器学习实用指南第三版(六)
原文:Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow 译者:飞龙 协议:CC BY-NC-SA 4.0 第十四章:使用卷积神经网络进行深度计算机视觉 尽管 IBM 的 Deep Blue 超级计算机在 1996 年击败了国际象棋世界冠军…...

XGB-3: 模型IO
在XGBoost 1.0.0中,引入了对使用JSON保存/加载XGBoost模型和相关超参数的支持,旨在用一个可以轻松重用的开放格式取代旧的二进制内部格式。后来在XGBoost 1.6.0中,还添加了对通用二进制JSON的额外支持,作为更高效的模型IO的优化。…...

springboot(ssm船舶维保管理系统 船只报修管理系统Java系统
springboot(ssm船舶维保管理系统 船只报修管理系统Java系统 开发语言:Java 框架:springboot(可改ssm) vue JDK版本:JDK1.8(或11) 服务器:tomcat 数据库:mysql 5.7&a…...
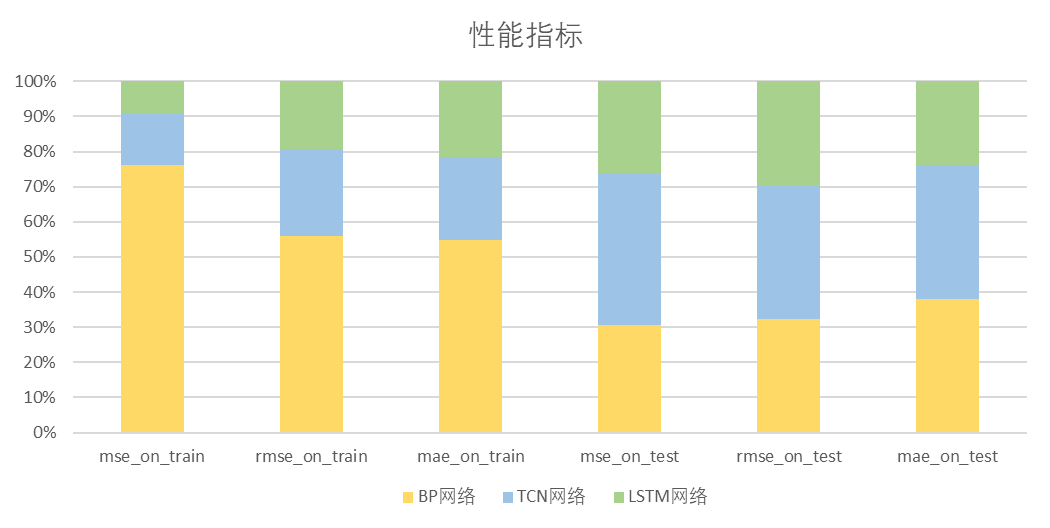
机器学习本科课程 大作业 多元时间序列预测
1. 问题描述 1.1 阐述问题 对某电力部门的二氧化碳排放量进行回归预测,有如下要求 数据时间跨度从1973年1月到2021年12月,按月份记录。数据集包括“煤电”,“天然气”,“馏分燃料”等共9个指标的数据(其中早期的部分…...

[office] excel中weekday函数的使用方法 #学习方法#微信#媒体
excel中weekday函数的使用方法 在EXCEL中Weekday是一个日期函数,可以计算出特定日期所对应的星期数。下面给大家介绍下Weekday函数作用方法。 01、比如,我在A84单元格输入一个日期,2018/5/9;那么,我们利用weekday计算…...

PAT-Apat甲级题1007(python和c++实现)
PTA | 1007 Maximum Subsequence Sum 1007 Maximum Subsequence Sum 作者 CHEN, Yue 单位 浙江大学 Given a sequence of K integers { N1, N2, ..., NK }. A continuous subsequence is defined to be { Ni, Ni1, ..., Nj } where 1≤i≤j≤K. The Maximum Su…...

洛谷:P2957 [USACO09OCT] Barn Echoes G
题目描述 The cows enjoy mooing at the barn because their moos echo back, although sometimes not completely. Bessie, ever the excellent secretary, has been recording the exact wording of the moo as it goes out and returns. She is curious as to just how mu…...

flinksqlbug : AggregateFunction udf Could not extract a data type from
org.apache.flink.table.api.ValidationException: SQL validation failed. An error occurred in the type inference logic of function ‘default_catalog.default_database.CollectSetSort’. org.apache.flink.table.api.ValidationException: An error occurred in the t…...

Aigtek高压放大器用途是什么呢
高压放大器在电子领域中扮演着至关重要的角色,其主要作用是将低电压信号放大到更高的电压水平。这种类型的放大器广泛用于各种应用中,以下是高压放大器的用途以及其关键作用的详细介绍。 1、科学研究和实验室应用: 高压放大器在科学研究和实验…...

RVC模型GitHub开源项目实战:从Fork到贡献代码
RVC模型GitHub开源项目实战:从Fork到贡献代码 想为热门的RVC(Retrieval-based Voice Conversion)项目贡献一份力量,却不知道从何下手?看着GitHub上那些活跃的Pull Request,是不是既羡慕又有点无从下手的感…...

手把手教你用NLI-DistilRoBERTa-Base:快速搭建自然语言推理服务
手把手教你用NLI-DistilRoBERTa-Base:快速搭建自然语言推理服务 1. 引言:什么是自然语言推理(NLI) 自然语言推理(Natural Language Inference)是NLP领域的一项重要任务,它需要判断两个句子之间的关系。想象一下,当你在阅读一段文…...

霜儿-汉服-造相Z-Turbo科研辅助:使用LaTeX撰写包含AI生成图像的学术论文
霜儿-汉服-造相Z-Turbo科研辅助:使用LaTeX撰写包含AI生成图像的学术论文 最近在帮一位研究传统服饰的朋友整理论文,遇到了一个挺有意思的问题。他们需要大量汉服的结构示意图和纹样分析图,但手绘耗时,找现成资料又很难完全匹配研…...
)
别再直接求逆了!用MATLAB的Cholesky分解高效求解对称正定矩阵的逆(附完整代码)
高效求解对称正定矩阵逆:MATLAB中Cholesky分解的工程实践指南 在工程计算领域,对称正定矩阵的逆矩阵求解是一个基础但至关重要的操作。从金融风险模型的协方差矩阵求逆,到机器学习中高斯过程回归的核矩阵运算,再到信号处理中的自适…...
)
农产投入线上管理|基于springboot + vue农产投入线上管理系统(源码+数据库+文档)
农产投入线上管理系统 目录 基于springboot vue农产投入线上管理系统 一、前言 二、系统功能演示 三、技术选型 四、其他项目参考 五、代码参考 六、测试参考 七、最新计算机毕设选题推荐 八、源码获取: 基于springboot vue农产投入线上管理系统 一、前…...

OpenClaw多模型切换:Qwen3.5-9B-AWQ-4bit与文本模型协同工作
OpenClaw多模型切换:Qwen3.5-9B-AWQ-4bit与文本模型协同工作 1. 为什么需要多模型协同 去年我在尝试用OpenClaw自动化处理工作文档时,发现一个尴尬的问题:当我需要同时处理图片和文本内容时,要么被迫用昂贵的多模态模型处理所有…...

OpenClaw技能开发指南:为SecGPT-14B定制专属安全检测模块
OpenClaw技能开发指南:为SecGPT-14B定制专属安全检测模块 1. 为什么需要为SecGPT-14B开发OpenClaw技能? 去年我在做安全审计时,经常需要手动将二进制文件上传到不同检测平台,再人工整理漏洞报告。这种重复劳动让我开始思考&…...

OpenClaw+千问3.5-9B:自动化周报生成与数据分析
OpenClaw千问3.5-9B:自动化周报生成与数据分析 1. 为什么需要自动化周报 每周五下午三点,我的日历总会准时弹出提醒:"该写周报了"。这个重复了三年多的机械动作,消耗了我大量本该用于创造性工作的时间。直到上个月&am…...

软考培训机构防套路手册:从师资甄别到合同陷阱的7个关键检查点
软考培训机构防套路手册:从师资甄别到合同陷阱的7个关键检查点 第一次报考软考的考生往往会被培训机构"包过""名师押题"的广告吸引,却不知道这个行业存在多少精心设计的消费陷阱。去年某考生花费6800元报名"保过班"&…...

【从零开始学Java | 第二十五篇】TreeSet
目录 前言 一、TreeSet的特点 二、TreeSet集合默认的规则 1.默认排序/自然排序 2.比较器排序 总结 前言 在 Java 的集合框架中,Set 接口代表了一个不允许存在重复元素的集合。我们最常用的通常是 HashSet,因为它提供了极高的查找和插入效率。但是&…...