四、机器学习基础概念介绍
四、机器学习基础概念介绍
- 1_机器学习基础概念
- 机器学习分类
- 1.1 有监督学习
- 1.2 无监督学习
- 2_有监督机器学习—常见评估方法
- 数据集的划分
- 2.1 留出法
- 2.2 校验验证法(重点方法)
- 简单交叉验证
- K折交叉验证(单独流出测试集)(常用方法/Sklearn的默认方法)
- k折交叉验证(不单独留出测试集)
- 留一法交叉验证
- Subject-wise交叉验证
- 2.3 bootstrap自助法
- 3_ 有监督机器学习—学习评价指标
- 3.1 准确率(Accuracy)
- 混淆矩阵
- 3.2 精确率(Precision)
- 3.3 召回率(Recall)
- 3.4 特异度(Specificity)
- 3.5 F1-值(F1-score)
- 3,6 ROC曲线
- 3.7 AUC面积
- 3.8 PR曲线
- 4_continue...后续更新
1_机器学习基础概念
机器学习一般可以分为训练和测试两个步骤。
训练:让模型学习数据的特点。
测试:让模型对新的数据进行预测,对比预测结果与实际结果之间的差异。
训练集:这批数据是供模型学习使用。
测试集:这批数据是供模型测试使用。
一般情况训练集和测试集是完全不相同的,训练集和测试集发生重叠是一个严重错误!
机器学习分类
1)按照学习方式
- 有监督学习:训练数据包含了数据本身及其对应的标签。每个训练数据都有一个明确的标识或结果。
- 无监督学习:训练数据只包含数据本身,不包含对应的标签。例如通过聚类算法对很多段EEG信号进行聚类分析。模型能够自主的学习到一些数据的特点。(通常缺乏先验知识,因此难以对数据进行标注或者标注成本太高)
- 半监督学习:部分训练数据有标签,部分训练数据没有标签。
- 强化学习:强化学习的标签可以不是一个明确的标识或结果。 一般是一个反馈或者奖励。
2)按照算法的原理
- 传统的机器学习(不包含任何人工神经网络结构,此文章的重点)
- 深度学习
1.1 有监督学习
监督学习一般解决两个问题:分类和回归
1) 分类和回归是做什么的
- 无论是分类还是回归,其本质都是对输入进行预测,都是有监督学习。
- 分类是根据输出得到一个分类的类别,而回归是根据输出得到一个具体的值。
2)分类和回归的区别
- 分类问题的输出的物体所属的类别,而回归问题的输出是物体的值。
- 分类问题的输出是离散值(0,1,2,3,…),回归问题输出的是连续值(36.7,36.8,…)
- eg:输入是一堆气象数据:
如果输出是具体的天气情况:雨天?晴天?阴天? —分类—
如果输出是具体的温度? —回归—
3)有监督学习有哪些
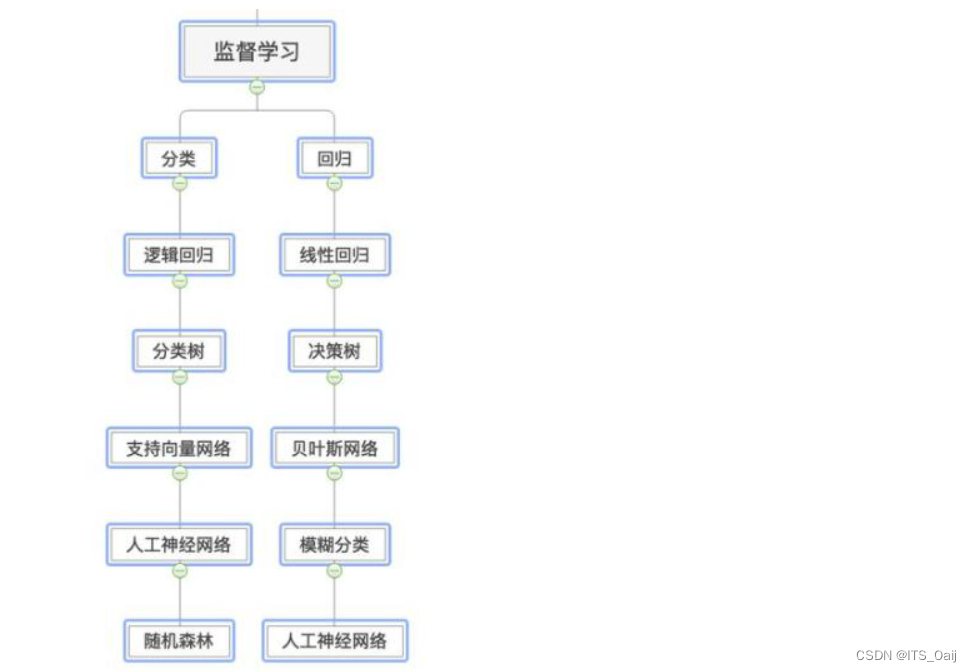
1.2 无监督学习
无监督学习一般解决两个问题:聚类和降维
1)聚类
- 在无监督学习中,数据不会带有任何标签。将这些无标签数据分成N个分开点集(称为簇)的算法,就被称为聚类算法。
- 常用聚类算法:K均值聚类和层次聚类
- 聚类和分类的区别:分类是有标签的,每个物体有其具体的明确的归属。而聚类是没有标签的,根据算法不同可能会得到不通过的结果。
2)降维
- 采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中。
- 降维是对数据本身处理,不需要标签。
- 常用降维算法:PCA、张量分解。
2_有监督机器学习—常见评估方法
常见的评估方法有:留出法、校验验证法和自助法
数据集的划分
- 第一种:训练集和测试集(不建议适用)
- 第二种:训练集、验证集和测试集(正确的数据集划分方法)
训练集——学生的课本;学生 根据课本里的内容来掌握知识。
验证集——作业,通过作业可以知道 不同学生学习情况、进步的速度快慢。
测试集——考试,考的题是平常都没有见过,考察学生举一反三的能力。
正确做法: 在训练集上训练模型,在验证集上评估模型(对模型进行参数调整),最后在测试集上测试模型。
2.1 留出法
- 将数据集D分割为两个互斥的集合:训练集S和测试集T。
- 其中训练集S还可以进一步划分为训练集S1和验证集V。
- 数据集划分完毕后,直接在训练集S上训练模型,在验证集S1上评估模型,在测试集T上测试模型即可。
一般情况下,会选择20%左右的数据作为测试集。
缺点:数据选择随机,结果的方差比较大
2.2 校验验证法(重点方法)
校验验证法:能充分利用数据集,但不适用于特别大的数据集
- 一般分为:简单交叉验证,留一法交叉验证和K折交叉验证
- 其中,K折交叉验证(单独流出测试集)(该方法为常用方法,Sklearn的默认方法)
简单交叉验证
- 将样本全部打乱,随机的将样本数据集分为互斥的两个部分:训练集和测试集。其中训练集还可以划分为训练集和验证集。
- 通过训练集训练模型,通过验证集选择模型参数,在测试集上评估模型的分类率。
- 接着重新把样本数据打乱,重新划分训练集和测试集。重复上述过程若干次,此时将会得到若千个分类率。
- 选择最大的分类率作为最终分类率。
等价于将留出法重复n次,通常用于模型预筛,可作为论文中探讨模型选择的一部分。
K折交叉验证(单独流出测试集)(常用方法/Sklearn的默认方法)
- 将样本全部打乱,随机从样本数据集划分出互斥的两部分:训练集和测试集。从训练集D分类K大小相似的互斥子集。
- 每次选用K-1个子集作为训练集,余下的那个子集作为验证集。这样就得到了K组训练/验证集,从而可以进行 K次训练和验证,可以返回K个模型。
- 在测试集上分别对K个模型进行测试得到分类率,最终K次测试中分类率的均值作为最终分类率。
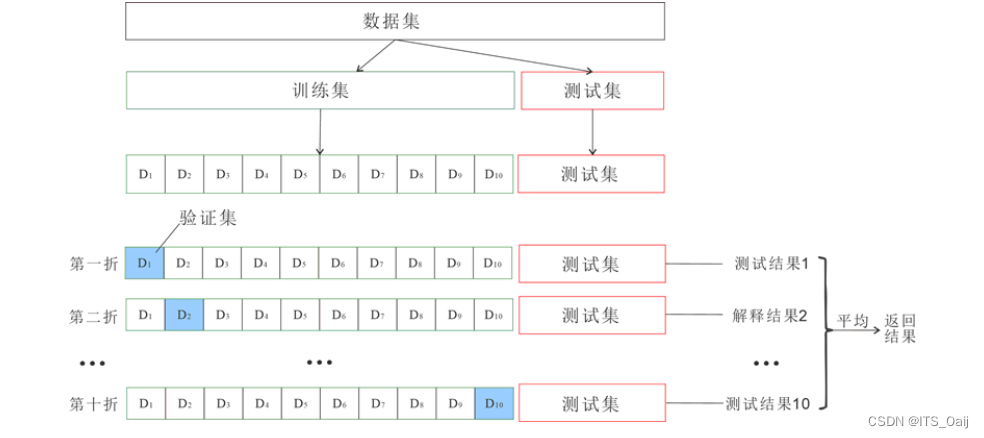 k为几就是几折交叉验证,通常五折/十折。
k为几就是几折交叉验证,通常五折/十折。
k折交叉验证(不单独留出测试集)

- 单独留出测试集的交叉验证会在进行交叉验证前单独留出测试集,后续所有的交叉验证都会最终在测试集上进行测试。
- 而不单独留出测试集的折交叉验证不会单独留出测试集,训练集、验证集和测试集将一会通过“交叉”产生。
- 数据量比较多,10折。10000个样本,
留一法交叉验证
- 当K折交叉验证中的K与样本个数N相等时,此时该验证方法被称为“留一法”。
- 理论上,留一法对数据的利用最为充分,其结果最接近实际的结果。如果样本数据比较大,会带来极大的计算量,因此留一法一般只适用于小样本量数据集。最终K个模型分类率的均值作为最终分类率。
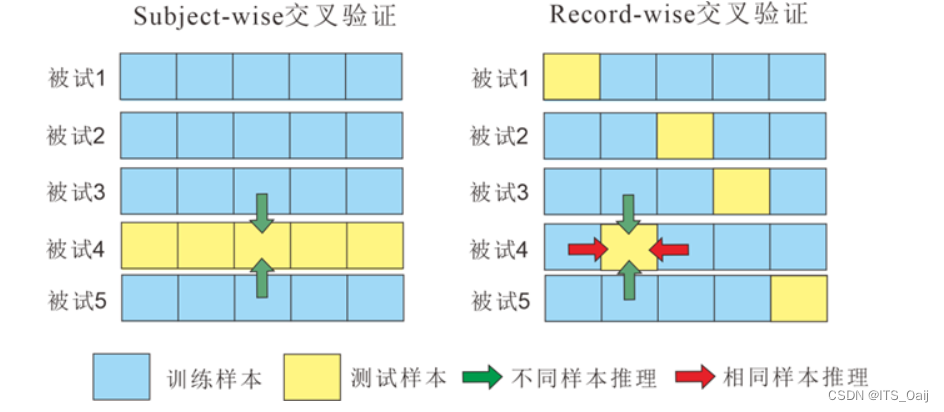
- 注意:在神经科学领域,一般使用留一被试法
- 留一被试法:将同一个被试的所有的样本视为一个特定的集合,每次选择一个被试的样本作为测试集,其他被试的样本作为训练集。
Subject-wise交叉验证

2.3 bootstrap自助法
3_ 有监督机器学习—学习评价指标
3.1 准确率(Accuracy)
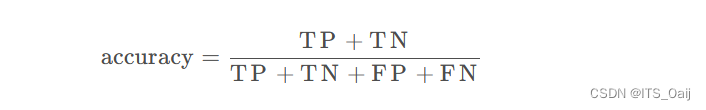
准确率能够清晰的判断我们模型的表现,但有一个严重的缺陷: 在正负样本不均衡的情况下,占比大的类别往往会成为影响 Accuracy 的最主要因素,此时的 Accuracy 并不能很好的反映模型的整体情况。
例如,一个测试集有正样本99个,负样本1个。模型把所有的样本都预测为正样本,那么模型的Accuracy为99%,看评价指标,模型的效果很好,但实际上模型没有任何预测能力。
混淆矩阵
TP = True Postive = 真阳性; FP = False Positive = 假阳性
FN = False Negative = 假阴性; TN = True Negative = 真阴性
比如我们一个模型对15个样本进行预测,然后结果如下。
真实值:0 1 1 0 1 1 0 0 1 0 1 0 1 0 0
预测值:1 1 1 1 1 0 0 0 0 0 1 1 1 0 1

3.2 精确率(Precision)
精度(precision, 或者PPV,,positive predictive value) = TP / (TP + FP)
在上面的例子中,精度=5/(5+4)= 0.556
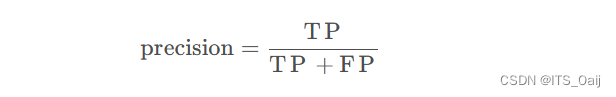
3.3 召回率(Recall)
·召回(recall,或者敏感度,sensitivity,真阳性率,TPR,True Positive Rate)= TP /(TP +FN)
在上面的例子中,召回=5/(5+2) = 0.714
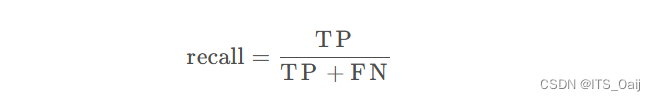
3.4 特异度(Specificity)
特异度(specificity,或者真阴性率,TNR,True Negative Rate) = TN / (TN + FP)
在上面的例子中,特异度 = 4 / (4+2) = 0.667
3.5 F1-值(F1-score)
F1-值(F1-score) = 2TP / (2TP+FP+FN)
精确率和召回率是一对矛盾的指标,因此需要放到一起综合考虑。F1-score是精确率和召回率的调和平均值。
相对于ACC的优势:能够同时表明模型对正负样本的预测能力
在上面的例子中,F1-值 = 25 / (25+4+2) = 0.625
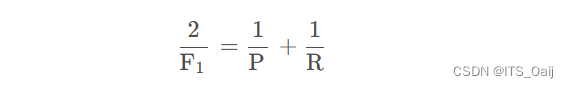
- 敏感度和特异度有何用?
特异度(specificity),TNR,即它反映筛检试验确定非病人的能力。
敏感度(sensitivity,召回率),TPR,即它反映筛检试验确定病人的能力。
敏感度高=漏诊率低,特异度高=误诊率低。
例如:核酸检测允许比较高的误诊率,但漏诊率低一定要很低。
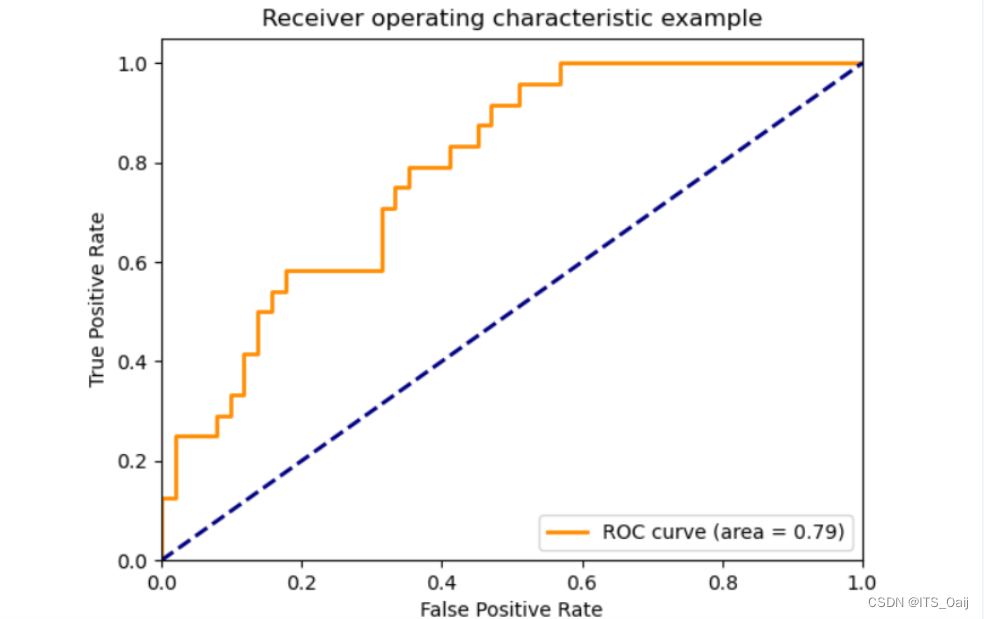
3,6 ROC曲线
ROC曲线(横轴:FPR;纵轴:TPR)该曲线越接近左上角越好
TPR = TP / (TP+FN); 真阳率
FPR = FP / (FP + TN); 伪阳率
3.7 AUC面积
AUC(ROC与坐标轴围成图像的面积)
AUC = 1,是完美分类器。
AUC = [0.85, 0.95], 效果很好
AUC = [0.7, 0.85], 效果一般
AUC = [0.5, 0.7],效果较低,但用于预测股票已经很不错了
AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
3.8 PR曲线
(仅供了解,横轴是recall,纵轴是precision,越接近右上角越好)
4_continue…后续更新
相关文章:
四、机器学习基础概念介绍
四、机器学习基础概念介绍 1_机器学习基础概念机器学习分类1.1 有监督学习1.2 无监督学习 2_有监督机器学习—常见评估方法数据集的划分2.1 留出法2.2 校验验证法(重点方法)简单交叉验证K折交叉验证(单独流出测试集)(常…...
)
Excel设置单元格下拉框(poi)
前言 年关在即,还在最后的迭代处理,还分了个其他同事的单,说是导出的Excel模版的2列要修改为下拉选项,过程很曲折,不说,以下其实就是一个笔记而已! 其实之前分享过阿里的EasyExcel设置单…...

api接口是什么意思,api接口该如何防护呢?
API接口:应用程序与服务之间的接口 什么是API接口 API是应用程序接口的缩写,指的是能够让不同的应用程序之间交换数据的一种方式。一个API接口就是应用程序与服务之间的接口,它定义了服务提供的功能和数据,以及应用程序如何访问这…...
PMP资料怎么学?PMP备考经验分享
PMP考试前大家大多都是提前备考个一两个月,但是有些朋友喜欢“不走寻常路”,并不打算去考PMP认证,想要单纯了解PMP,不管要不要考证,即使是仅仅学习了解一下我个人都非常支持,因为专业的基础的确能提高工作效…...
子句的含义)
partition by list(msn_id)子句的含义
在数据库查询中,特别是在使用SQL语言时,"PARTITION BY" 子句用于对结果集进行分区,以便可以对每个分区进行单独的聚合操作。这是在执行窗口函数(如 ROW_NUMBER(), RANK(), SUM(), AVG() 等)时特别有用的。 …...
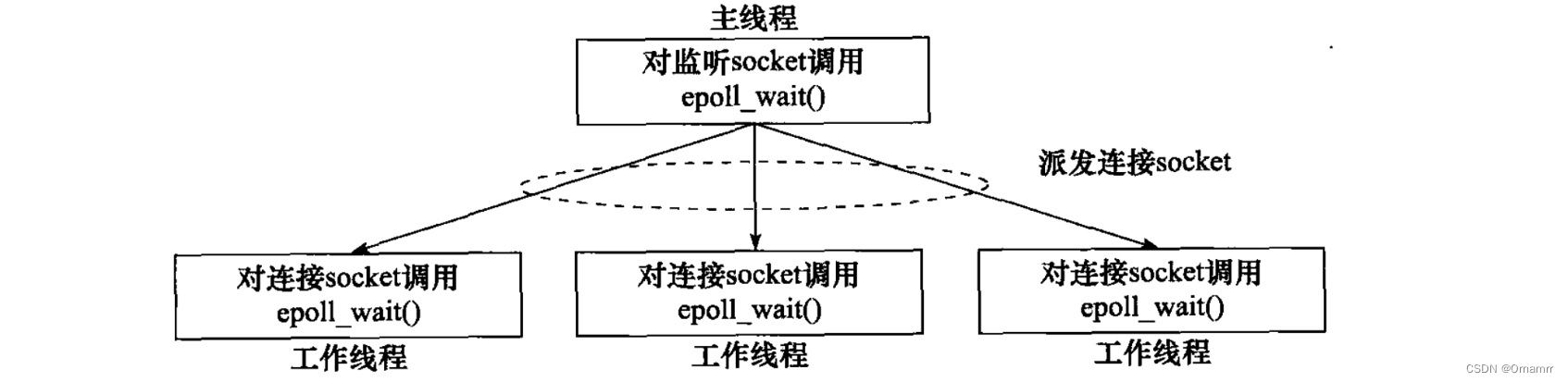
【C++】I/O多路转接详解(二)
在上一篇文章【C】I/O多路转接详解(一) 在出现EPOLL之后,随之而来的是两种事件处理模式的应运而生:Reator 和 Proactor,同步IO模型常用于Reactor模式,异步IO常用于Proactor. 目录 1. 服务器编程框架简介2. IO处理1. R…...
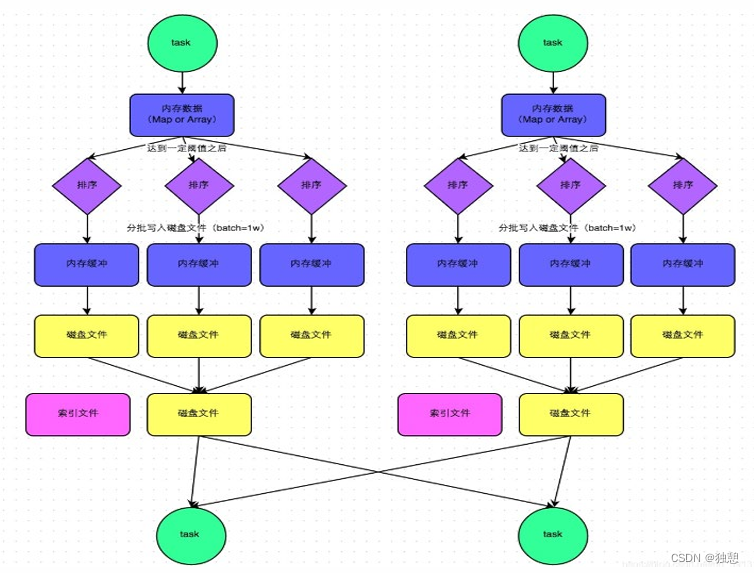
PySpark(三)RDD持久化、共享变量、Spark内核制度,Spark Shuffle
目录 RDD持久化 RDD 的数据是过程数据 RDD 缓存 RDD CheckPoint 共享变量 广播变量 累加器 Spark 内核调度 DAG DAG 的宽窄依赖和阶段划分 内存迭代计算 Spark是怎么做内存计算的? DAG的作用?Stage阶段划分的作用? Spark为什么比MapReduce快? Spar…...

详解MYSQL中的平均值组大小
文章目录 平均值组大小了解平均值组大小MySQL什么时候会使用平均值组大小平均值组大小对于索引选取的影响平均值组大小 了解平均值组大小 总数据量 / 值组 = 平均值组大小 值组是一组具有相同键前缀值的行,及所有相等的键为一个值组。总数据量为全表数据量MySQL什么时候会使…...
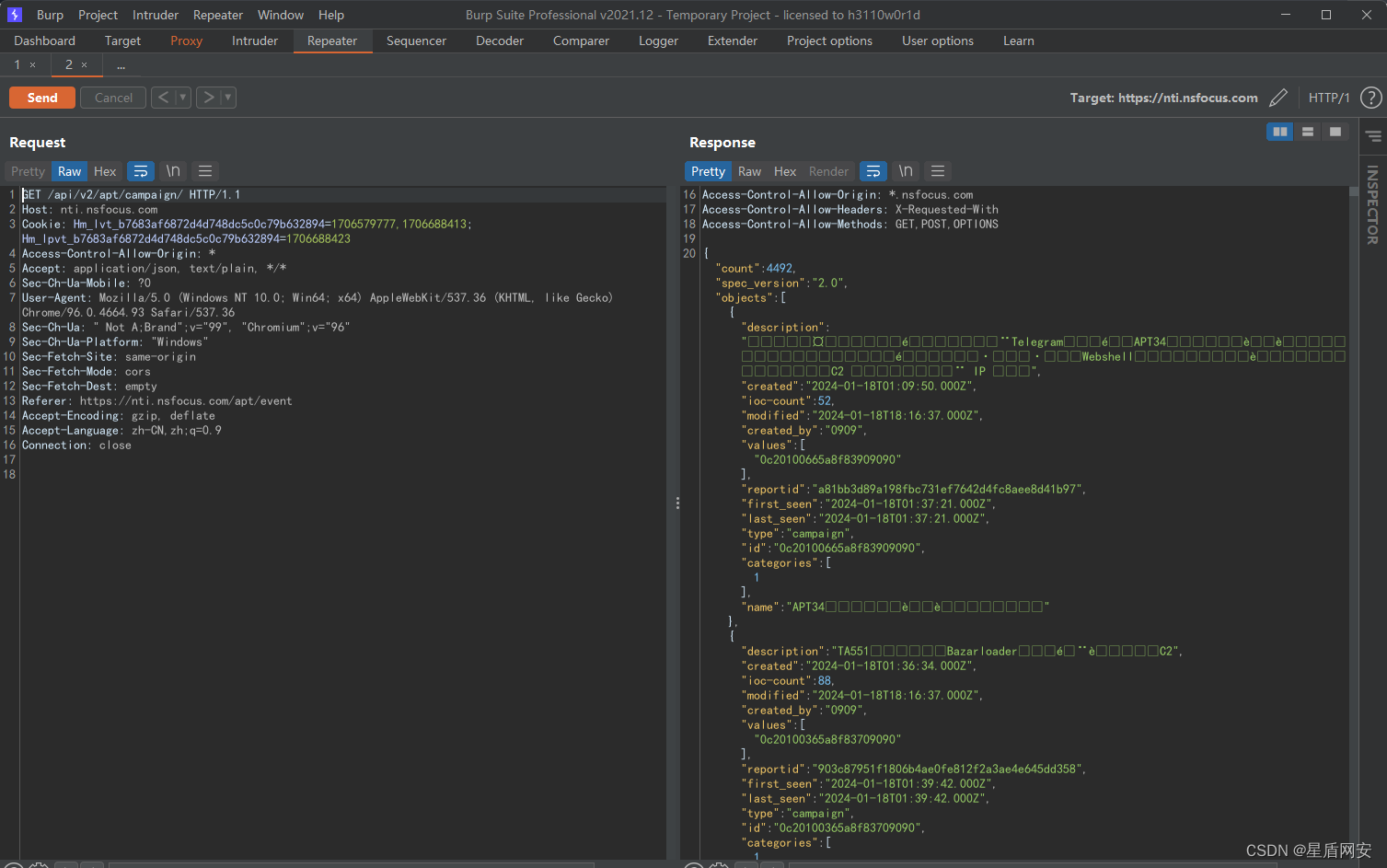
【爬虫专区】批量下载PDF (无反爬)
天命:只要没反爬,一切都简单 这次爬取的是绿盟的威胁情报的PDF 先看一下结构,很明显就是一个for循环渲染 burp抓包会发现第二次接口请求 接口请求一次就能获取到了所有的数据 然后一个循环批量下载数据即可,其实没啥难度的 imp…...
自动增长冲突)
PostgreSQL解决序列(自增id)自动增长冲突
背景 一般表的id主键我们都是设置为自增序列。 但是如果我们在插入一些数据的时候手动指定id,那么自增序列不会跟随我们手动设置的id增长。 就会出现下次不设置id的时候自增到我们手动指定的id导致主键冲突bug 举个例子 现在数据有 id123 现在我们手动插入数…...
1.0 Zookeeper 分布式配置服务教程
ZooKeeper 是 Apache 软件基金会的一个软件项目,它为大型分布式计算提供开源的分布式配置服务、同步服务和命名注册。 ZooKeeper 的架构通过冗余服务实现高可用性。 Zookeeper 的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高…...

(Flutter 常用插件整理
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 Flutter 常用插件整理 # Flutter 城市列表,联系人列表,索引&悬停 https://github.com/flutterchina/azlistviewazlistview: ^2.0.0# Dart 汉字转拼音 https://github.com/flutterchina/lpinyinlpinyin…...
vue2.0+使用md-edit编辑器
前言:小刘开发过程中,如果是博客项目一般是会用到富文本。众多富文本中,小刘选择了markdown,并记录分享了下来。 # 使用 npm npm i kangc/v-md-editor -Smain.js基本配置import VueMarkdownEditor from kangc/v-md-editor; import…...

Java设计模式大全:23种常见的设计模式详解(二)
本系列文章简介: 设计模式是在软件开发过程中,经过实践和总结得到的一套解决特定问题的可复用的模板。它是一种在特定情境中经过验证的经验和技巧的集合,可以帮助开发人员设计出高效、可维护、可扩展和可复用的软件系统。设计模式提供了一种在…...
【算法与数据结构】718、1143、1035、392、115、LeetCode最长重复子数组+最长公共子序列+不相交的线+判断子序列+不同的子序列
文章目录 一、718、最长重复子数组二、1143、最长公共子序列三、1035、不相交的线四、392、判断子序列五、115、不同的子序列六、完整代码 所有的LeetCode题解索引,可以看这篇文章——【算法和数据结构】LeetCode题解。 一、718、最长重复子数组 思路分析࿱…...

OCR文本纠错思路
文字错误类别:多字 少字 形近字 当前方案 文本纠错思路 简单: 一、构建自定义词典,提高分词正确率。不在词典中,也不是停用词,分成单字的数据极有可能是错字(少部分可能是新词)。错字与前后的…...

【java批量导出pdf】优化方案
问题情境: 项目中存在web页面点击一键导出,导出所有数据对应的pdf文件,由于有些pdf文件是实时生成的,之前最简答的写法for循环处理速度太慢,超过了nginx配置的最大响应时间了,且对用户交互体验上很不友好&…...
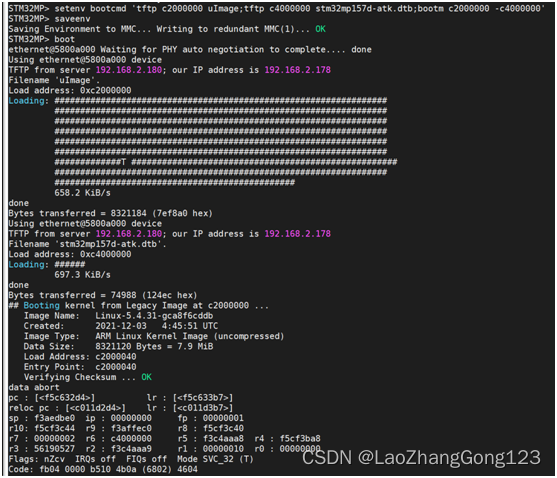
Linux第42步_移植ST公司uboot的第3步_uboot命令测试,搭建nfs服务器和tftp服务器
测试uboot命令,搭建nfs服务器和tftp服务器,是测试uboot非常关键的一步。跳过这一节,后面可能要踩坑。 一、输入“help回车”,查询uboot所支持的命令 二、输入“? bootz回车”,查询“bootz”怎么用 注意:和…...
)
C++枚举算法(3)
我家的门牌号 题目描述: 我家住在一条短胡同里,这条胡同的门牌号从1开始顺序编号。 若所有的门牌号之和减去我家门牌号的两倍,恰好等于n,求 我家的门牌号及总共有多少家。 数据保证有唯一解。 输入 一个正整数n。n < 100000。…...
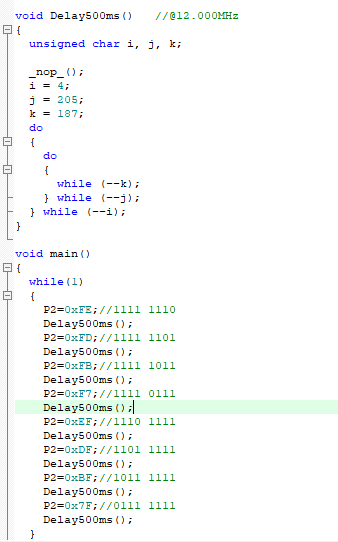
【51单片机】LED的三个基本项目(LED点亮&LED闪烁&LED流水灯)(3)
前言 大家好吖,欢迎来到 YY 滴单片机系列 ,热烈欢迎! 本章主要内容面向接触过单片机的老铁 主要内容含: 欢迎订阅 YY滴C专栏!更多干货持续更新!以下是传送门! YY的《C》专栏YY的《C11》专栏YY的…...

Qwen3-14B镜像实操:自定义Tokenizer适配垂直领域专业术语
Qwen3-14B镜像实操:自定义Tokenizer适配垂直领域专业术语 1. 镜像概述与核心优势 Qwen3-14B私有部署镜像是专为RTX 4090D 24GB显存环境优化的完整解决方案,开箱即用无需复杂配置。这个镜像最显著的特点是针对垂直领域专业术语进行了Tokenizer的深度优化…...

Qwen-Edit-2509多角度切换技术:如何用单张图片生成全视角内容?
Qwen-Edit-2509多角度切换技术:如何用单张图片生成全视角内容? 【免费下载链接】Qwen-Edit-2509-Multiple-angles 项目地址: https://ai.gitcode.com/hf_mirrors/dx8152/Qwen-Edit-2509-Multiple-angles 在视觉创作领域,你是否曾为拍…...

Windows驱动存储深度管理:从问题诊断到系统优化的完整解决方案
Windows驱动存储深度管理:从问题诊断到系统优化的完整解决方案 【免费下载链接】DriverStoreExplorer Driver Store Explorer [RAPR] 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 问题发现:驱动管理中的隐形痛点与风险 系…...

论文阅读 AIED 2024 Coding with AI: How Are Tools Like ChatGPT Being Used by Students in Foundational Pro
总目录 大模型相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328 Coding with AI: How Are Tools Like ChatGPT Being Used by Students in Foundational Programming Courses https://link.springer.com/chapter/10.1007/978-3-031-64299-9_20…...

如何突破Office功能限制?本地化激活方案全解析
如何突破Office功能限制?本地化激活方案全解析 【免费下载链接】ohook An universal Office "activation" hook with main focus of enabling full functionality of subscription editions 项目地址: https://gitcode.com/gh_mirrors/oh/ohook 当…...

探索GetQzonehistory:永久保存QQ空间记忆的数字时光机
探索GetQzonehistory:永久保存QQ空间记忆的数字时光机 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 在数字时代,我们的记忆分散在各个社交平台,而Q…...

攻克ComfyUI ControlNet Aux预处理难题:4个实用方案助你快速恢复功能
攻克ComfyUI ControlNet Aux预处理难题:4个实用方案助你快速恢复功能 【免费下载链接】comfyui_controlnet_aux ComfyUIs ControlNet Auxiliary Preprocessors 项目地址: https://gitcode.com/gh_mirrors/co/comfyui_controlnet_aux ComfyUI ControlNet Auxi…...

德意志飞机通过全球协作升级支线航空驾驶舱人机工学
2026年1月15日 —— 作为总部位于德国舍瑙的MAFELEC集团旗下成员,COMTRONIC GmbH近五十年来一直是航空航天领域人机界面(HMI)解决方案领域值得信赖的供应商。凭借在照明面板、定制键盘及先进光学技术方面的深厚积淀,COMTRONIC长期…...

python协同过滤算法的基于python二手物品交易网站系统
目录同行可拿货,招校园代理 ,本人源头供货商协同过滤算法在二手物品交易网站中的应用用户行为数据收集基于用户的协同过滤基于物品的协同过滤混合推荐策略冷启动问题处理实时推荐更新推荐结果评估代码实现示例系统功能整合性能优化项目技术支持源码获取详细视频演示 ࿱…...
)
别再看水刊了!智能故障诊断领域投稿,这20+个SCI期刊才是你的目标(附避坑指南)
智能故障诊断领域投稿指南:20高价值SCI期刊与避坑策略 对于从事智能故障诊断研究的学者而言,选择合适的SCI期刊投稿是研究成果获得认可的关键一步。本文将系统梳理该领域的优质期刊资源,帮助您避开常见陷阱,提高投稿成功率。 1. 智…...