AI助力农作物自动采摘,基于DETR(DEtection TRansformer)开发构建作物生产场景下番茄采摘检测计数分析系统
去年十一那会无意间刷到一个视频展示的就是德国机械收割机非常高效自动化地24小时不间断地在超广阔的土地上采摘各种作物,专家设计出来了很多用于采摘不同农作物的大型机械,看着非常震撼,但是我们国内农业的发展还是相对比较滞后的,小的时候拔草是一个人一列蹲在地里就在那埋头拔草,不知道什么时候才能走到地的尽头,小块的分散的土地太多基本上都是只能人工手工来取收割,大点的连片的土地可以用收割机来收割,不过收割机基本都是用来收割小麦的,最近几年好像老家也能看到用于收割玉米的机器了不过相对还是比较少的,玉米的收割我们基本上还是人工来收割的,不仅累效率还低遇上对玉米叶片过敏的就更要命了。。。。闲话就扯到这里了。
有时候经常在想我们的农业机械化自动化什么时候能再向前迈进一大步,回顾德国的工业机械,在视频展示的效果中,其实很关键的主要是两部分,一部分是机器视觉定位检测识别,另一部分是机械臂传动轴,两部分相互配合才能完成采摘工作,本文的主要想法是想要基于DETR开发构建用于番茄采摘场景下的目标检测系统,前文实践如下:
《AI助力农作物自动采摘,基于YOLOv7【tiny/l/x】不同系列参数模型开发构建作物生产场景下番茄采摘检测计数分析系统》
《AI助力农作物自动采摘,基于YOLOv8全系列【n/s/m/l/x】参数模型开发构建作物生产场景下番茄采摘检测计数分析系统》
《AI助力农作物自动采摘,基于YOLOv5全系列【n/s/m/l/x】参数模型开发构建作物生产场景下番茄采摘检测计数分析系统》
《AI助力农作物自动采摘,基于YOLOv3全系列【yolov3tiny/yolov3/yolov3spp】参数模型开发构建作物生产场景下番茄采摘检测计数分析系统》
首先看下实例效果:

DETR (DEtection TRansformer) 是一种基于Transformer架构的端到端目标检测模型。与传统的基于区域提议的目标检测方法(如Faster R-CNN)不同,DETR采用了全新的思路,将目标检测问题转化为一个序列到序列的问题,通过Transformer模型实现目标检测和目标分类的联合训练。
DETR的工作流程如下:
输入图像通过卷积神经网络(CNN)提取特征图。
特征图作为编码器输入,经过一系列的编码器层得到图像特征的表示。
目标检测问题被建模为一个序列到序列的转换任务,其中编码器的输出作为解码器的输入。
解码器使用自注意力机制(self-attention)对编码器的输出进行处理,以获取目标的位置和类别信息。
最终,DETR通过一个线性层和softmax函数对解码器的输出进行分类,并通过一个线性层预测目标框的坐标。
DETR的优点包括:
端到端训练:DETR模型能够直接从原始图像到目标检测结果进行端到端训练,避免了传统目标检测方法中复杂的区域提议生成和特征对齐的过程,简化了模型的设计和训练流程。
不受固定数量的目标限制:DETR可以处理变长的输入序列,因此不受固定数量目标的限制。这使得DETR能够同时检测图像中的多个目标,并且不需要设置预先确定的目标数量。
全局上下文信息:DETR通过Transformer的自注意力机制,能够捕捉到图像中不同位置的目标之间的关系,提供了更大范围的上下文信息。这有助于提高目标检测的准确性和鲁棒性。
然而,DETR也存在一些缺点:
计算复杂度高:由于DETR采用了Transformer模型,它在处理大尺寸图像时需要大量的计算资源,导致其训练和推理速度相对较慢。
对小目标的检测性能较差:DETR模型在处理小目标时容易出现性能下降的情况。这是因为Transformer模型在处理小尺寸目标时可能会丢失细节信息,导致难以准确地定位和分类小目标。
简单看下实例数据情况:
官方项目地址在这里,如下所示:
可以看到目前已经收获了超过1.2w的star量,还是很不错的了。
DETR整体数据流程示意图如下所示:

官方也提供了对应的预训练模型,可以自行使用:
本文选择的预训练官方权重是detr-r50-e632da11.pth,首先需要基于官方的预训练权重开发能够用于自己的 个性化数据集的权重,如下所示:
pretrained_weights = torch.load("./weights/detr-r50-e632da11.pth")
num_class = 1 + 1
pretrained_weights["model"]["class_embed.weight"].resize_(num_class+1,256)
pretrained_weights["model"]["class_embed.bias"].resize_(num_class+1)
torch.save(pretrained_weights,'./weights/detr_r50_%d.pth'%num_class)因为这里我的类别数量为1,所以num_class修改为:4+1,根据自己的实际情况修改即可。生成后如下所示:
终端执行:
python main.py --dataset_file "coco" --coco_path "/0000" --epoch 100 --lr=1e-4 --batch_size=2 --num_workers=0 --output_dir="outputs" --resume="weights/detr_r50_2.pth"即可启动训练,训练启动如下:

等待训练完成后,借助于评估模块对结果进行评估对比可视化:
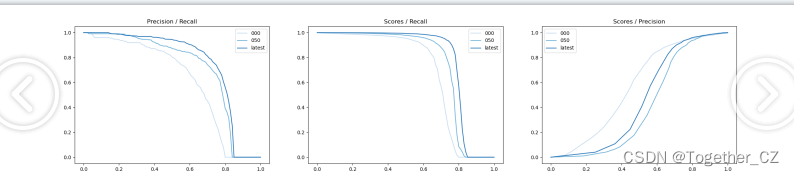
iter 000: mAP@50= 61.6, score=0.683, f1=0.694
iter 050: mAP@50= 71.7, score=0.747, f1=0.772
iter latest: mAP@50= 75.6, score=0.791, f1=0.797
iter 000: mAP@50= 61.6, score=0.683, f1=0.694
iter 050: mAP@50= 71.7, score=0.747, f1=0.772
iter latest: mAP@50= 75.6, score=0.791, f1=0.797接下来详细看下指标详情。
【Precision曲线】
精确率曲线(Precision-Recall Curve)是一种用于评估二分类模型在不同阈值下的精确率性能的可视化工具。它通过绘制不同阈值下的精确率和召回率之间的关系图来帮助我们了解模型在不同阈值下的表现。精确率(Precision)是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。
【Recall曲线】
召回率曲线(Recall Curve)是一种用于评估二分类模型在不同阈值下的召回率性能的可视化工具。它通过绘制不同阈值下的召回率和对应的精确率之间的关系图来帮助我们了解模型在不同阈值下的表现。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。召回率也被称为灵敏度(Sensitivity)或真正例率(True Positive Rate)。
【F1值曲线】
F1值曲线是一种用于评估二分类模型在不同阈值下的性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)、召回率(Recall)和F1分数的关系图来帮助我们理解模型的整体性能。
F1分数是精确率和召回率的调和平均值,它综合考虑了两者的性能指标。F1值曲线可以帮助我们确定在不同精确率和召回率之间找到一个平衡点,以选择最佳的阈值。
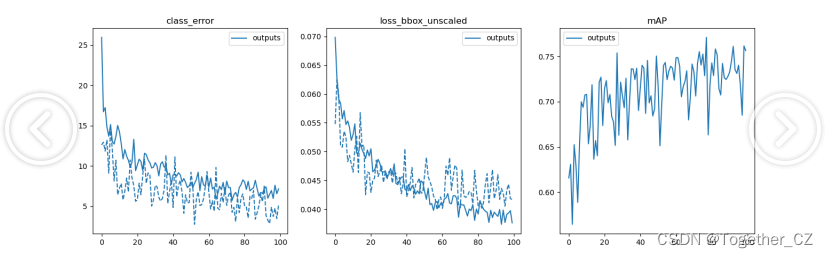
loss可视化如下所示:
感兴趣的话可以自行动手实践尝试下!
相关文章:
AI助力农作物自动采摘,基于DETR(DEtection TRansformer)开发构建作物生产场景下番茄采摘检测计数分析系统
去年十一那会无意间刷到一个视频展示的就是德国机械收割机非常高效自动化地24小时不间断地在超广阔的土地上采摘各种作物,专家设计出来了很多用于采摘不同农作物的大型机械,看着非常震撼,但是我们国内农业的发展还是相对比较滞后的࿰…...

C语言——字符串大小写互换
前言: 在C语言中,大小写字母相互转换是一个常见的操作。本文将详细介绍C语言中实现大小写字母相互转换的各种方法,并附上代码示例。 目录 一、使用tolower()和toupper()函数 二、使用位操作 三、使用字符串操作函数 一、使用tolower()和t…...

macOS的设置与常用软件(含IntelliJ IDEA 2023.3.2 Ultimate安装,SIP的关闭与开启)
目录 1 系统设置1.1 触控板1.2 键盘 2 软件篇2.1 [科学上网](https://justmysocks5.net/members/)2.1 [安装Chrome浏览器](https://www.google.cn/chrome/index.html)2.2 [安装utools](https://www.u.tools)2.3 [安装搜狗输入法](https://shurufa.sogou.com/)2.4 [安装snipaste…...
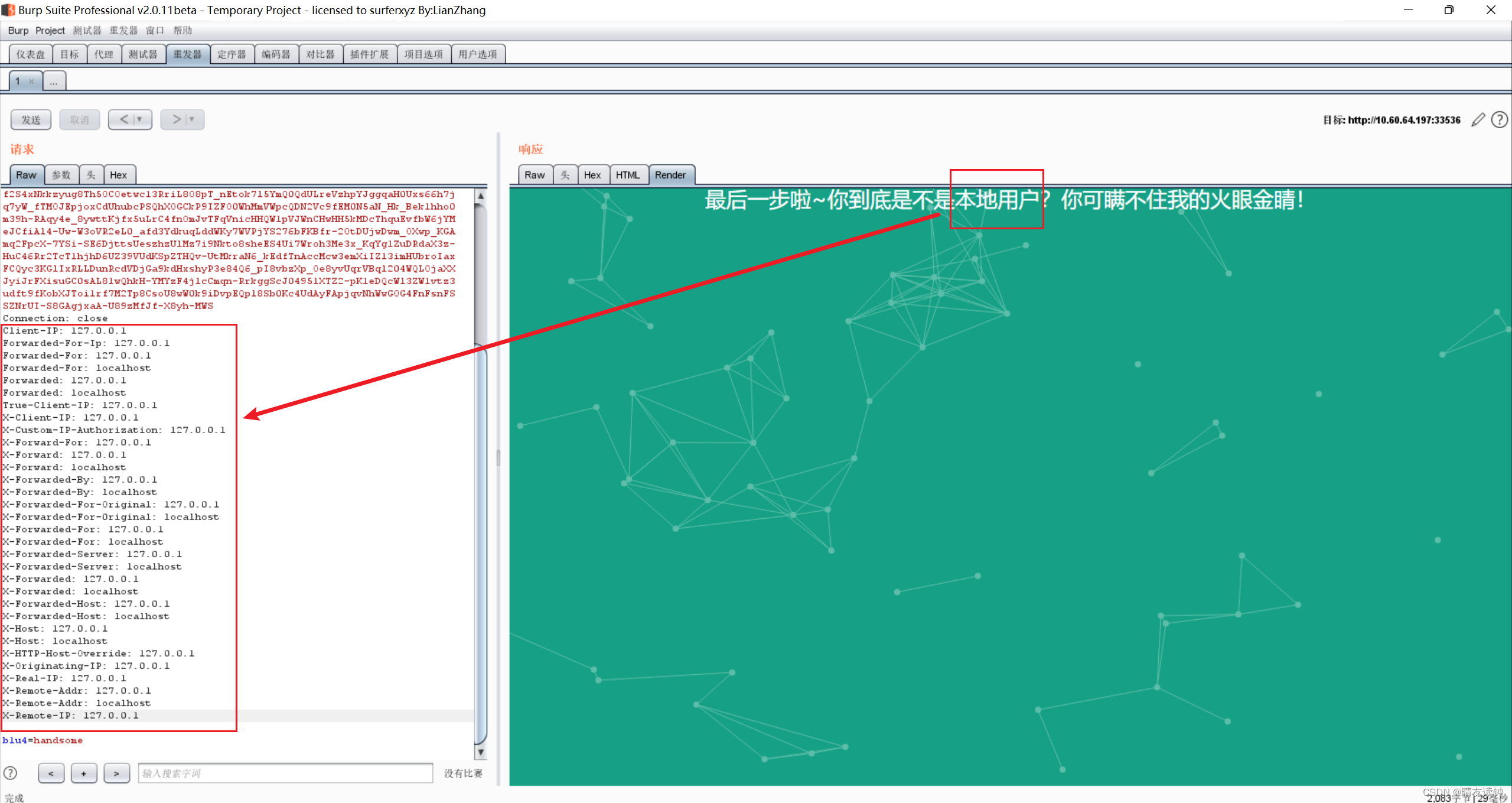
http伪造本地用户字段系列总结
本篇记录了http伪造本地用户的多条字段,便于快速解决题目 用法举例: 直接把伪造本地用户的多个字段复制到请求头中,光速解决部分字段被过滤的问题。 Client-IP: 127.0.0.1 Forwarded-For-Ip: 127.0.0.1 Forwarded-For: 127.0.0.1 Forwarded…...
Hadoop-IDEA开发平台搭建
1.安装下载Hadoop文件 1)hadoop-3.3.5 将下载的文件保存到英文路径下,名称一定要短。否则容易出问题; 2)解压下载下来的文件,配置环境变量 3)我的电脑-属性-高级设置-环境变量 4.详细配置文件如下&#…...

block任务块、rescue和always、loop循环、role角色概述、role角色应用、ansible-vault、sudo提权、特殊的主机清单变量
任务块 可以通过block关键字,将多个任务组合到一起可以将整个block任务组,一起控制是否要执行 # 如果webservers组中的主机系统发行版是Rocky,则安装并启动nginx[rootpubserver ansible]# vim block1.yml---- name: block taskshosts: webse…...
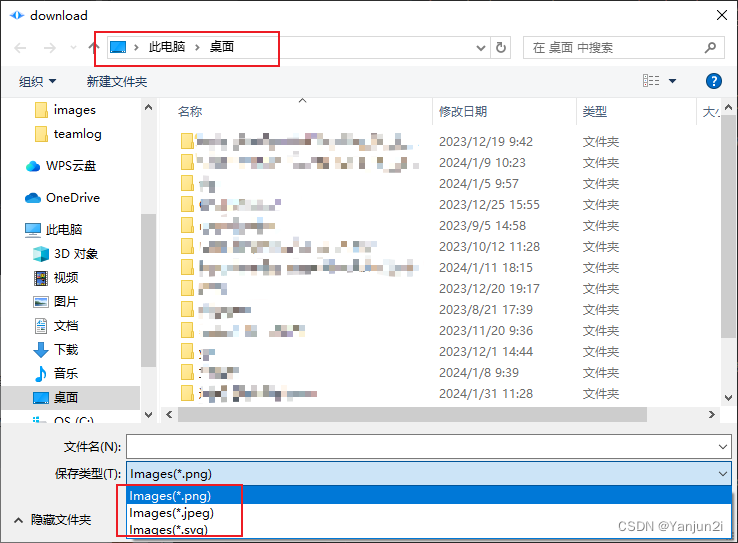
Qt:QFileDialog
目录 一、介绍 二、功能 三、具体事例 1、将某个界面保存为图片,后缀名可选PNG、JPEG、SVG等 一、介绍 QFileDialog提供了一个对话框,允许用户选择文件或者目录,也允许用户遍历文件系统,用以选择一个或多个文件或者目录。 QF…...

我的QQ编程学习群
欢迎大家加入我的QQ编程学习群。 群号:950365002 群里面有许多的大学生大佬,有编程上的疑惑可以随时问,也可以聊一些休闲的东西。 热烈欢迎大家加入!! 上限:150人。...

【C++】类与对象(四)——初始化列表|explicit关键字|static成员|友元|匿名对象
前言: 初始化列表,explicit关键字,static成员,友元,匿名对象 文章目录 一、构造函数的初始化列表1.1 构造函数体内赋值1.2 初始化列表 二、explicit关键字三、static成员四、友元4.1 友元函数4.2 友元类 五、内部类六、…...
ChatGPT高效提问—prompt常见用法
ChatGPT高效提问—prompt常见用法 1.1 角色扮演 prompt最为常见的用法是ChatGPT进行角色扮演。通常我们在和ChatGPT对话时,最常用的方式是一问一答,把ChatGPT当作一个单纯的“陪聊者”。而当我们通过prompt为ChatGPT赋予角色属性后,即使…...
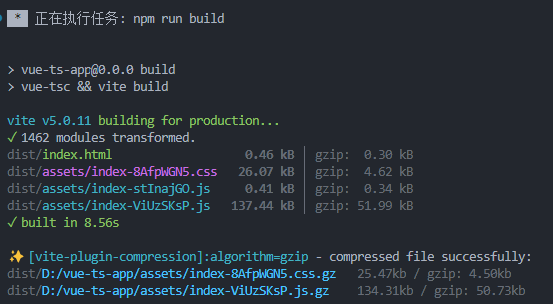
使用vite创建vue+ts项目,整合常用插件(scss、vue-router、pinia、axios等)和配置
一、检查node版本 指令:node -v 为什么要检查node版本? Vite 需要 Node.js 版本 18,20。然而,有些模板需要依赖更高的 Node 版本才能正常运行,当你的包管理器发出警告时,请注意升级你的 Node 版本。 二、创…...
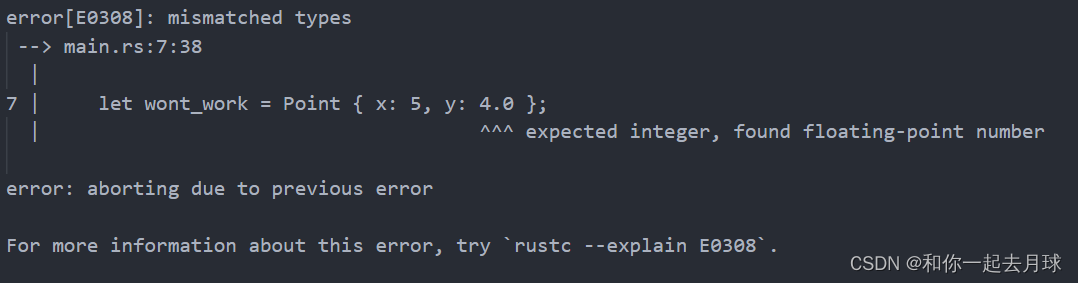
泛型、Trait 和生命周期(上)
目录 1、提取函数来减少重复 2、在函数定义中使用泛型 3、结构体定义中的泛型 4、枚举定义中的泛型 5、方法定义中的泛型 6、泛型代码的性能 每一门编程语言都有高效处理重复概念的工具。在 Rust 中其工具之一就是 泛型(generics)。泛型是具体类型…...

<网络安全>《18 数据安全交换系统》
1 概念 企业为了保护核心数据安全,都会采取一些措施,比如做网络隔离划分,分成了不同的安全级别网络,或者安全域,接下来就是需要建设跨网络、跨安全域的安全数据交换系统,将安全保障与数据交换功能有机整合…...
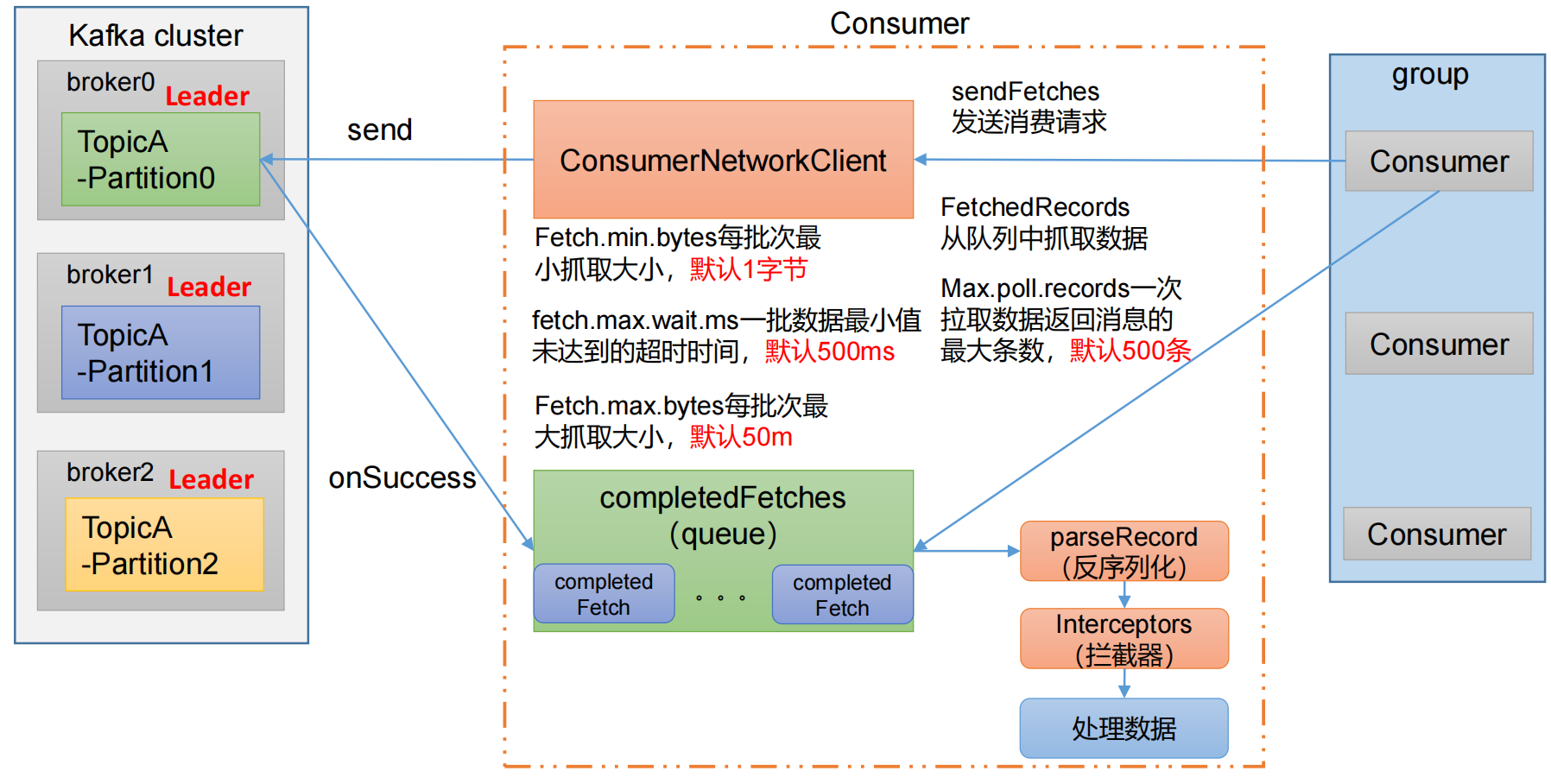
Kafka 生产调优
Kafka生产调优 文章目录 Kafka生产调优一、Kafka 硬件配置选择场景说明服务器台数选择磁盘选择内存选择CPU选择 二、Kafka Broker调优Broker 核心参数配置服役新节点/退役旧节点增加副本因子调整分区副本存储 三、Kafka 生产者调优生产者如何提高吞吐量数据可靠性数据去重数据乱…...
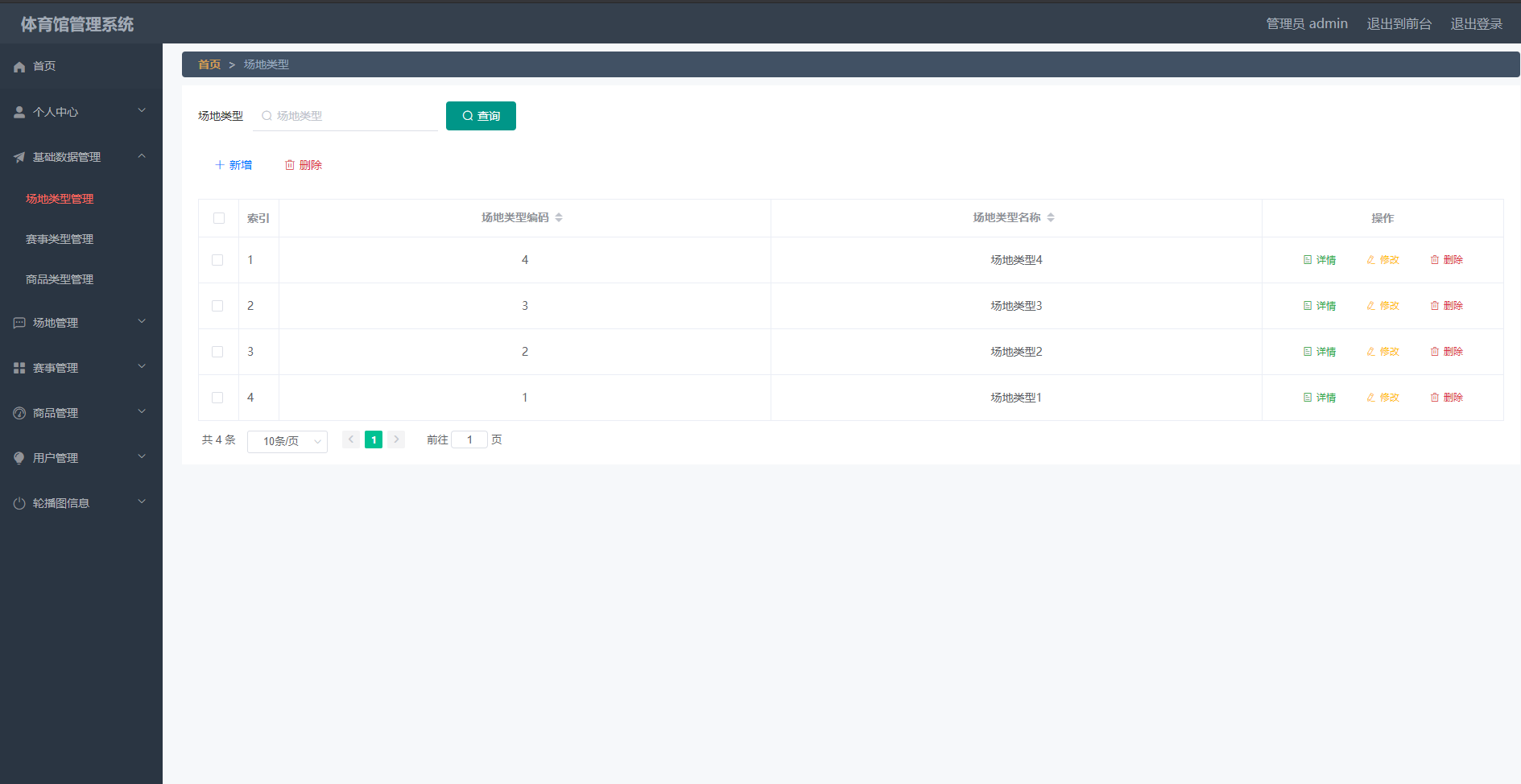
springboot162基于SpringBoot的体育馆管理系统的设计与实现
体育馆管理系统 摘 要 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存储,归纳,集中处理数据信息的管理方式。本体育馆管理系统就是在这样的大环境下诞生,其可以帮助管理者在短时间内处理完毕…...

Interpolator:在Android中方便使用一些常见的CubicBezier贝塞尔曲线动画效果
说明 方便在Android中使用Interpolator一些常见的CubicBezier贝塞尔曲线动画效果。 示意图如下 import android.view.animation.Interpolator import androidx.core.view.animation.PathInterpolatorCompat/*** 参考* android https://yisibl.github.io/cubic-bezier* 实现常…...
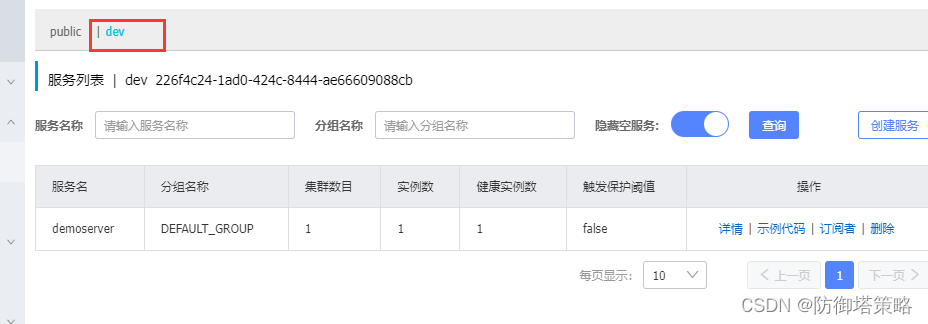
Nacos安装,服务注册,负载均衡配置,权重配置以及环境隔离
1. 安装 首先从官网下载 nacos 安装包,注意是下载 nacos-server Nacos官网 | Nacos 官方社区 | Nacos 下载 | Nacos 下载完毕后,解压找到文件夹bin,文本打开startup.cmd 修改配置如下 然后双击 startup.cmd 启动 nacos服务,默认…...

Vue3导出数据为txt文件
在Vue3中,可以通过使用Blob对象以及URL.createObjectURL()方法导出txt文档。 首先,你需要在Vue组件中创建一个方法来生成txt文档的内容。 //res.value.code 数据源 //type:格式设置 //form.name是下载文件的自定义名字 const downLoad ()&…...

Simulink中getConfigSet用法
目录 语法 说明 示例 获取配置集 getConfigSet的功能是从模型中获取配置集或配置引用。 语法 myConfigObj getConfigSet(model, configObjName) 说明 myConfigObj getConfigSet(model, configObjName) 返回关联到 model 并命名为 configObjName 的配置集或配置引用。 …...

【Algorithms 4】算法(第4版)学习笔记 05 - 2.2 归并排序
文章目录 前言参考目录学习笔记1:归并排序的简单演示1.1:基本思路1.2:归并排序的 demo 演示1.3:代码实现2:自顶向下的归并排序2.1:比较次数与访问次数的证明2.2:代码优化2.3:优化后代…...

告别繁琐!3步解锁教育资源获取新方式,效率提升10倍的高效工具
告别繁琐!3步解锁教育资源获取新方式,效率提升10倍的高效工具 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具 项目地址: https://gitcode.com/GitHub_Trending/tc/tchMaterial-parser 在数字化学习与教学资源管理…...

GPT-SoVITS应用场景解析:为视频配音、做有声书,简单又实用
GPT-SoVITS应用场景解析:为视频配音、做有声书,简单又实用 1. 引言:声音克隆技术带来的变革 想象一下,你正在制作一个短视频,需要为不同角色配音。传统方式要么自己录制(效果可能不专业)&…...

CCMusic跨平台部署指南:Windows/Linux/macOS全适配
CCMusic跨平台部署指南:Windows/Linux/macOS全适配 音乐风格识别从未如此简单——无论你用哪种电脑系统 1. 开篇:为什么需要跨平台部署方案 还在为音乐风格分类工具的安装头疼吗?不同的操作系统、不同的环境配置、复杂的依赖关系...这些麻烦…...

电容选型实战指南
电容选型这件事,比电阻要复杂得多。电阻选错了,大多数情况是“烧了”或“不准了”;电容选错了,可能直接导致系统复位、EMI超标、寿命骤减、甚至爆炸。电容是电路中最“敏感”的元件之一,它的选型需要在电气性能、温度特性、寿命、成本、体积之间反复权衡。 一、 选型前的四…...

本地部署 LookScanned:轻松将 PDF 转为逼真扫描件,结合内网穿透实现远程访问
前言 本文主要介绍了 LookScanned 这款工具的部署与使用方法。LookScanned 可将普通电子 PDF 转换为高度逼真的纸质扫描件效果,全程本地处理保障隐私,操作简单且无需打印扫描的物理步骤。 文中详细讲解了在极空间通过 Docker 部署 LookScanned 的流程&…...

PvZ Toolkit:植物大战僵尸游戏体验增强工具全解析
PvZ Toolkit:植物大战僵尸游戏体验增强工具全解析 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit 问题引入:植物大战僵尸玩家的共同痛点 在植物大战僵尸游戏过程中…...
)
别再只靠密码了!手把手教你用Gpg4win给邮件和文件加把‘数字锁’(附Kleopatra实战截图)
别再只靠密码了!手把手教你用Gpg4win给邮件和文件加把"数字锁" 你是否经常担心重要文件被他人窥探?或是害怕商务邮件在传输过程中遭人篡改?在这个数据泄露频发的时代,仅靠密码保护敏感信息已经远远不够。今天ÿ…...

Spring Boot 与 GraphQL 2.0 集成:构建现代化 API
Spring Boot 与 GraphQL 2.0 集成:构建现代化 API 引言 在现代 Web 开发中,API 设计变得越来越重要。传统的 RESTful API 在面对复杂的数据查询需求时,往往会面临过度获取或获取不足的问题。GraphQL 作为一种新型的 API 查询语言,…...

R数据可视化进阶|利用Scatterplot3d包打造交互式3D散点图
1. 为什么需要3D散点图可视化 在数据分析工作中,我们经常需要同时观察三个变量之间的关系。传统的2D散点图只能展示两个变量之间的相关性,当我们需要分析三个变量之间的复杂关系时,3D散点图就成为了必不可少的工具。比如在分析鸢尾花数据集时…...

Qt 串口编程实战:keySight 34401A 万用表数据采集与存储
1. 项目背景与硬件准备 keySight 34401A 数字万用表是实验室常见的六位半高精度测量设备,支持GPIB和RS-232两种通信接口。在实际工业测量场景中,RS-232串口连接因其布线简单、成本低廉的特点,成为许多开发者的首选方案。我最近接手的一个电池…...