CV | Medical-SAM-Adapter论文详解及项目实现
******************************* 👩⚕️ 医学影像相关直达👨⚕️*******************************
CV | SAM在医学影像上的模型调研【20240207更新版】-CSDN博客
CV | Segment Anything论文详解及代码实现
本文主要讲解Medical-SAM-Adapter论文及项目实现~
2023.12.29第七版_Medical SAM Adapter:Adapting Segment Anything Model for Medical Image Segmentation
论文地址:2304.12620.pdf (arxiv.org)
论文代码:KidsWithTokens/Medical-SAM-Adapter: Adapting Segment Anything Model for Medical Image Segmentation (github.com)
1.论文详解
摘要
Segment Anything Model (SAM) 在图像分割领域广受欢迎,因为它在各种分割任务中具有令人印象深刻的功能和基于提示的界面。然而,最近的研究和个别实验表明,由于缺乏医学特定知识,SAM在医学图像分割方面表现不佳。这就提出了一个问题,即如何增强SAM对医学图像的分割能力。在本文中,没有对SAM模型进行微调,而是提出了医疗SAM适配器(Med-SA),它使用一种轻巧而有效的适应技术将特定领域的医学知识整合到分割模型中。在Med-SA中,提出了空间深度转置(SD-Trans)来实现2D SAM与3D医学图像的适应,以及超提示适配器(HyP-Adpt)来实现快速条件适应。对不同图像模态的 17 个医学图像分割任务进行了综合评估实验。Med-SA 的性能优于几种最先进的 (SOTA) 医学图像分割方法,而仅更新了 2% 的参数。
方法
主要讲解方法部分
论文基于SAM,依旧使用图像编码器、提示编码器和mask解码器。
图像编码器:基于标准ViT被MAE训练,这里使用ViT_h/16变种,有14×14窗口的注意力和4个等间距的全局注意力。图像编码器的输出是对输入图像的16倍下采样嵌入。
提示编码器:可以是稀疏的点、框、文本或密集的mask;本文中只关注稀疏提示编码器,它将点和框表示为位置编码,并对每个提示类型进行学习嵌入。
mask解码器:是一个Transformer解码器,包括动态掩模预测头。
SAM 使用双向交叉注意,一个用于提示到图像的嵌入,另一个用于图像到提示的嵌入,在每个块中学习提示和图像嵌入之间的相互作用。在运行了两个块之后,SAM 上采样嵌入图像,MLP 将输出标记映射到一个动态线性分类器,从而预测给定图像的目标掩码。
Med-SA架构(Med-SA architecture)
为了对 SAM 架构进行微调以适应医学图像分割,本文没有完全调整所有参数,而是冻结了预先训练好的 SAM 参数,并在架构的特定位置插入了 Adapter 模块。
Adapter 是一个 bottleneck 结构,它依次包括:下投影、ReLU 激活和上投影。下投影使用简单的 MLP 层将给定的嵌入压缩到较小的维度;上投影使用另一个 MLP 层将压缩的嵌入扩展回其原始维度.

(在第一版里叫MSA,第七版里叫Med-SA)
2D Medical Image Adaption
在 SAM 编码器中,本文为每个 ViT 块部署了两个 Adapter。
修改标准 ViT block (a),得到 2D Medical Image Adaption (b)
- 将第一个 Adapter 放在多头注意力之后、残差连接之前
- 将第二个 Adapter 放在多头注意力之后 MLP 层的残差路径上
紧接着第二个 Adapter 之后,按照一定的比例系数对嵌入进行了缩放
引入缩放因子 s 是为了平衡与任务无关的特征和与任务有关的特征
Decoder Adaption
在 SAM 解码器中,本文为每个 ViT 块部署了Adapter,把这个叫做Hyper-Prompting Adapter
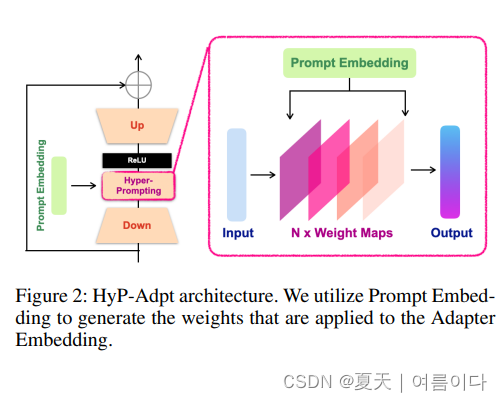
第一个 Adapter 部署在 prompt-to-image 嵌入的多头交叉注意之后,并添加了提示嵌入的残差
本文使用了另一种向下投影来压缩提示嵌入,并在 ReLU 激活之前将其添加到 Adapter 的嵌入上
有助于 Adapter 根据提示信息调整参数,使其更加灵活和通用于不同的模式和下游任务
第二个 Adapter 的部署方式与编码器完全相同,用于调整 MLP 增强嵌入
第三个 Adapter 部署在图像嵌入的残差连接之后,以提示交叉注意
另一个残差连接和层归一化在自适应后连接,以输出最终结果
SD-Trans
尽管 SAM 可以应用于病灶的每个切片以获得最终的分割,但是它没有考虑深度维中的相关性
本文提出了一种新的适配方法,其灵感来源于 image-to-video adaptation,具体架构如 (c)
在每个 block 中,本文将注意力操作分成两个分支:空间分支和深度分支
2.项目实现
2.0.环境设置
Python3.8+docker容器(Ubuntu)
git clone https://github.com/KidsWithTokens/Medical-SAM-Adaptercd Medical-SAM-Adapterwget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_b_01ec64.pth# 自定义req.txt,如本文A1
pip install -r req.txt因为我没有使用conda新建虚拟环境,自己新建了一个requestion.txt,如【A1】,按照作者要求是torch版本是1.12,我是1.14,并删掉了安装torch的命令。
2.1.数据集设置
官网:ISIC Challenge (isic-archive.com)
新建文件夹data/isic
#下载数据集
wget https://isic-challenge-data.s3.amazonaws.com/2016/ISBI2016_ISIC_Part1_Training_Data.zip#wget https://isic-challenge-data.s3.amazonaws.com/2016/ISBI2016_ISIC_Part1_Training_GroundTruth.zipwget https://isic-challenge-data.s3.amazonaws.com/2016/ISBI2016_ISIC_Part1_Test_Data.zip#wget https://isic-challenge-data.s3.amazonaws.com/2016/ISBI2016_ISIC_Part1_Test_GroundTruth.zip#下载csv文件
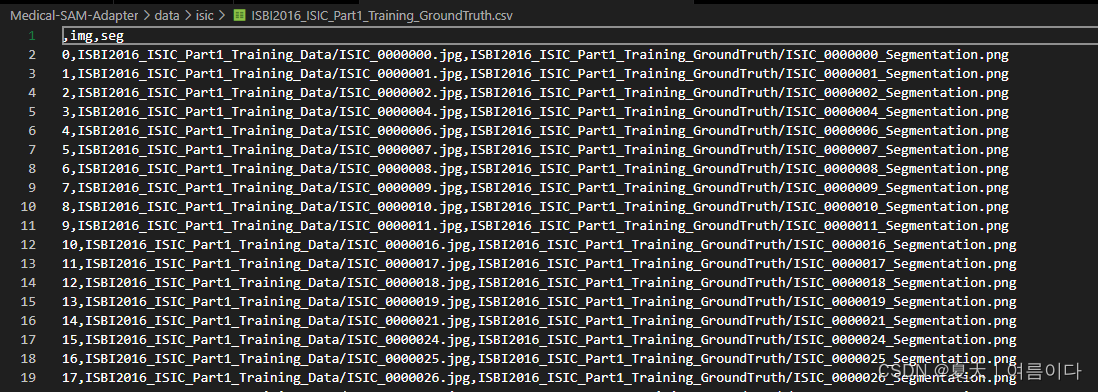
https://github.com/KidsWithTokens/MedSegDiff/blob/master/data/isic_csv/ISBI2016_ISIC_Part3B_Test_GroundTruth.csvhttps://github.com/KidsWithTokens/MedSegDiff/blob/master/data/isic_csv/ISBI2016_ISIC_Part3B_Training_GroundTruth.csv进入文件夹解压缩: unzip '*.zip'
格式如图
2.2.训练
训练数据集1:ISIC2016
python train.py -net sam -mod sam_adpt -exp_name msa_isic -sam_ckpt ./checkpoint/sam/sam_vit_b_01ec64.pth -image_size 1024 -b 32 -dataset isic -data_path ./data/isic一张单卡24GGPU的情况,batch size为2,17929MiB,如果现存较小,改小batch size或者image size.
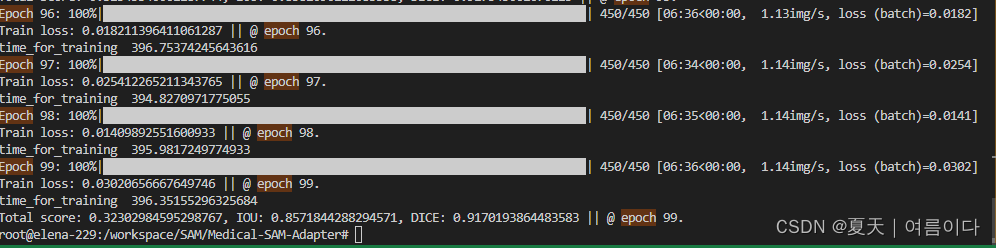
100个epoch时,IOU:0.85,DICE:0.91
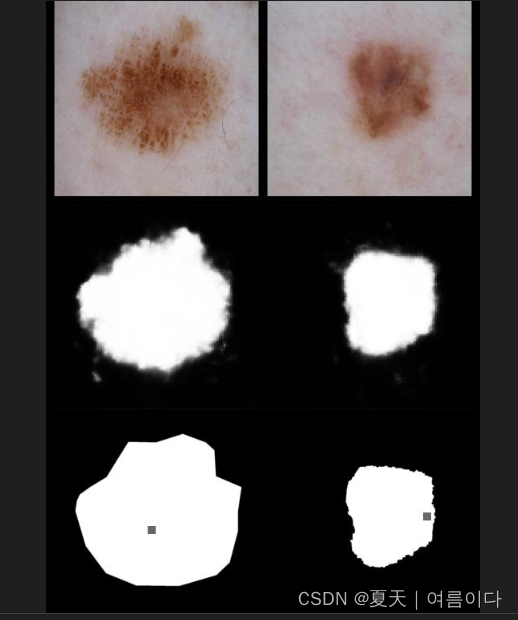
采样结果
训练数据集2
python train.py -net sam -mod sam_adpt -exp_name msa_kv
asir -sam_ckpt ./sam_vit_b_01ec64.pth -image_size 1024 -b 32 -dataset Kvasir-SEG -data_path /workspace/SAM
/datasets/Kvasir-SEG3.代码详解
3.1.论文的核心块adapter_block.py
位置:Medical-SAM-Adapter/models/ImageEncoder/vit/adapter_block.py
基于原本的transformer块添加窗口注意力和残差传播块,流程如下:
- 对输入张量
x进行归一化操作。 - 进行注意力计算,包括多头注意力机制和相对位置嵌入。
- 2D图像的情况使用 Space Adapter 处理注意力计算的输出。
- 如果数据是 3D ,则对输入进行额外的处理,并将其与 Space Adapter 处理后的结果相加。
- 对处理后的张量再次进行归一化操作。
- 将张量传递给 MLP 模块,并加上 MLP Adapter 处理后的结果的 scaled version。
- 将上述两项相加,并返回最终的输出张量。
3.2.
PS
【PS1】ValueError: num_samples should be a positive integer value, but got num_samples=0

csv文件问题
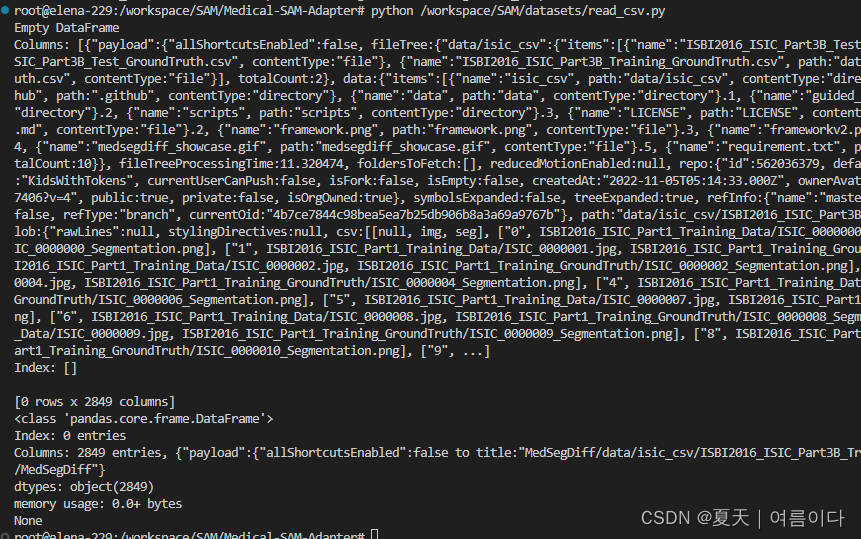
重新下载csv文件就可以啦,不能使用wget方式下载
【PS2】 TypeError: unsupported operand type(s) for %: 'int' and 'NoneType'
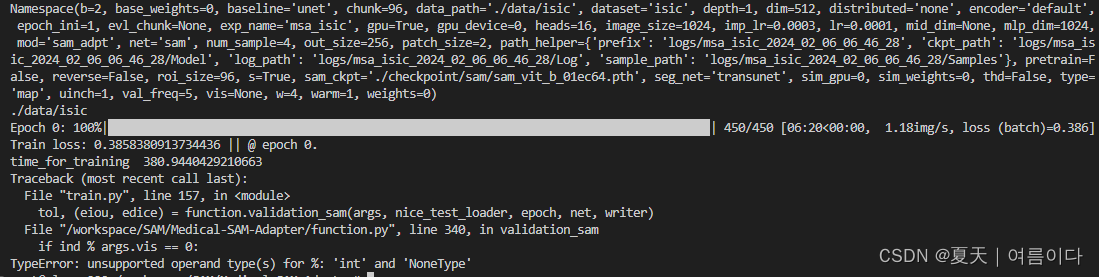
或者出现 ZeroDivisionError: integer division or modulo by zero错误时:
训练命令需要填写或修改vis自定义参数,默认是None,不能填写0,修改为1
扩展
【A1】pip 安装第三方库
aiosignal==1.2.0
alembic==1.10.4
appdirs==1.4.4
astor==0.8.1
asttokens==2.2.1
backcall==0.2.0
beautifulsoup4==4.12.2
blinker==1.6.2
cachetools==4.2.2
certifi==2022.12.7
charset-normalizer==2.0.4
click==8.1.3
cmaes==0.9.1
colorama==0.4.6
colorlog==6.7.0
contextlib2==21.6.0
coverage==6.5.0
coveralls==3.3.1
cucim==23.4.1
cycler==0.11.0
databricks-cli==0.17.7
docker==6.1.1
docopt==0.6.2
einops==0.6.1
entrypoints==0.4
exceptiongroup==1.1.1
executing==1.2.0
filelock==3.12.0
fire==0.5.0
flask==2.3.2
fonttools==4.25.0
future==0.18.3
gdown==4.7.1
gitdb==4.0.10
gitpython==3.1.31
google-auth==2.6.0
google-auth-oauthlib==0.4.4
greenlet==2.0.2
gunicorn==20.1.0
h5py==3.8.0
huggingface-hub==0.14.1
iniconfig==2.0.0
ipython
itk==5.3.0
itk-core==5.3.0
itk-filtering==5.3.0
itk-io==5.3.0
itk-numerics==5.3.0
itk-registration==5.3.0
itk-segmentation==5.3.0
itsdangerous==2.1.2
jedi==0.18.2
jinja2==3.1.2
json-tricks==3.16.1
jsonschema==4.17.3
kornia==0.4.1
lmdb==1.4.1
lucent==0.1.0
mako==1.2.4
mlflow==2.3.1
nibabel==5.1.0
ninja==1.11.1
nni==2.10
nptyping==2.5.0
opencv-python==4.7.0.72
openslide-python==1.1.2
optuna==3.1.1
partd==1.2.0
pluggy==1.0.0
pooch==1.4.0
prettytable==3.7.0
prompt-toolkit==3.0.38
psutil==5.9.5
pyarrow==11.0.0
pyasn1==0.4.8
pyasn1-modules==0.2.8
pydicom==2.3.1
pygments==2.15.1
pynrrd==1.0.0
pyqt5-sip==12.11.0
pyrsistent==0.19.3
pytest==7.3.1
pytest-mock==3.10.0
pythonwebhdfs==0.2.3
pytorch-ignite==0.4.10
querystring-parser==1.2.4
regex==2023.5.5
requests-oauthlib==1.3.0
responses==0.23.1
rsa==4.7.2
safetensors==0.4.1
schema==0.7.5
simplejson==3.19.1
smmap==5.0.0
soupsieve==2.4.1
scikit-image
sqlalchemy==2.0.12
sqlparse==0.4.4
tabulate==0.9.0
tensorboardx==2.2
termcolor==2.3.0
threadpoolctl==2.2.0
tifffile==2021.7.2
timm==0.9.12
tokenizers==0.12.1
tomli==2.0.1torch-lucent==0.1.8traitlets==5.9.0
transformers==4.21.3
typeguard==3.0.2
types-pyyaml==6.0.12.9
wcwidth==0.2.6
websocket-client==1.5.1
websockets==11.0.3
werkzeug==2.3.4相关文章:
CV | Medical-SAM-Adapter论文详解及项目实现
******************************* 👩⚕️ 医学影像相关直达👨⚕️******************************* CV | SAM在医学影像上的模型调研【20240207更新版】-CSDN博客 CV | Segment Anything论文详解及代码实现 本文主要讲解Medical-SAM-Adapter论文及项…...
C++初阶:容器(Containers)vector常用接口详解
介绍完了string类的相关内容后:C初阶:适合新手的手撕string类(模拟实现string类) 接下来进入新的篇章,容器vector介绍: 文章目录 1.vector的初步介绍2.vector的定义(constructor)3.v…...

flink写入es的参数解析
ElasticsearchSink内部使用BulkProcessor一次将一批动作(ActionRequest)发送到ES集群。在发送批量动作前,BulkProcessor先缓存,再刷新。缓存刷新的间隔,支持基于Action数量、基于Action大小、基于时间间隔3种策略。BulkProcessor支持在同一次…...

逆向工程:揭开科技神秘面纱的艺术
在当今这个科技飞速发展的时代,我们每天都在与各种电子产品、软件应用打交道。然而,你是否想过,这些看似复杂的高科技产品是如何被创造出来的?今天,我们就来探讨一下逆向工程这一神秘而又令人着迷的领域。 一、什么是…...
决策树的相关知识点
📕参考:ysu老师课件西瓜书 1.决策树的基本概念 【决策树】:决策树是一种描述对样本数据进行分类的树形结构模型,由节点和有向边组成。其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出ÿ…...
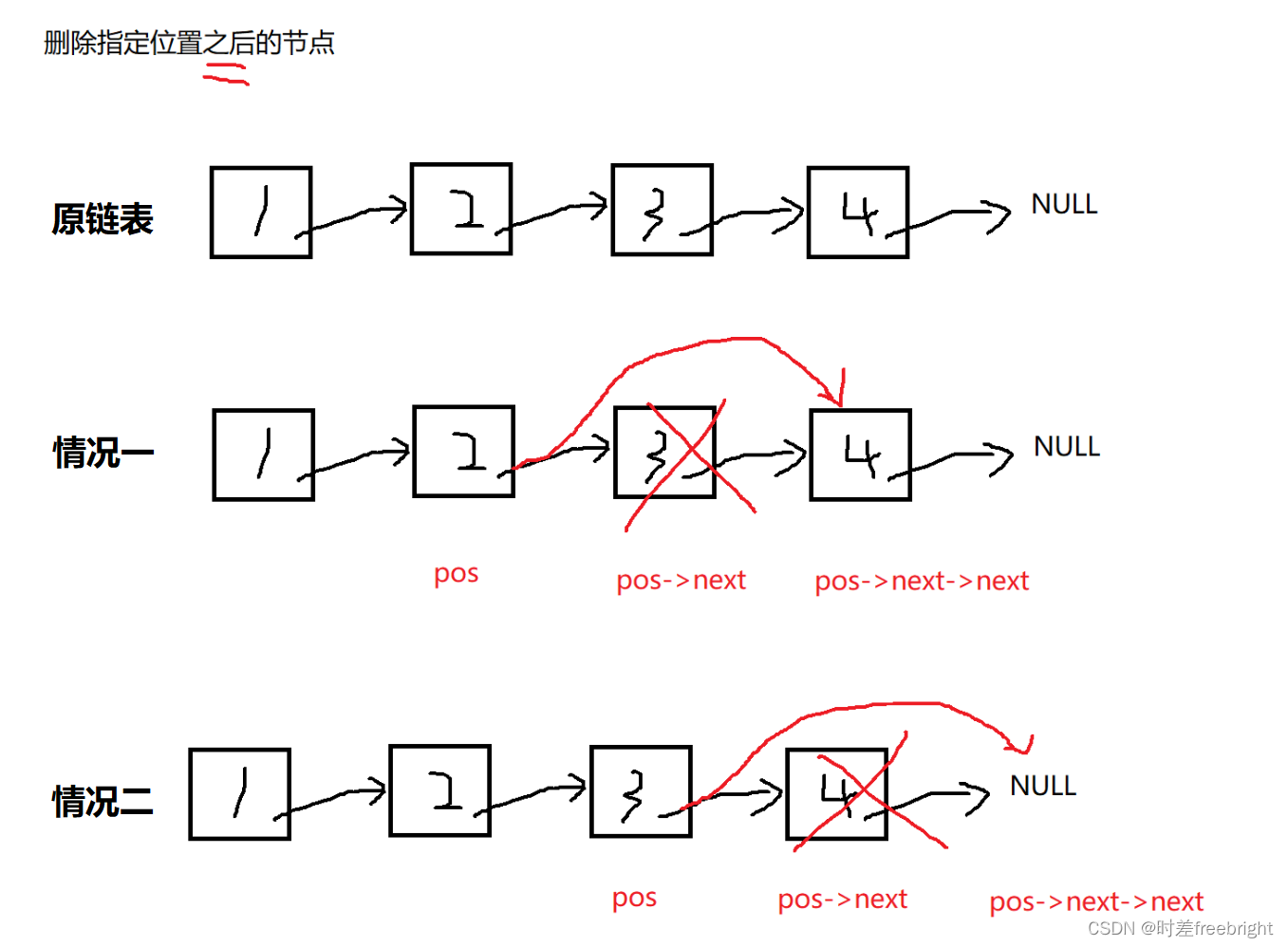
【数据结构】单向链表实现 超详细
目录 一. 单链表的实现 1.准备工作及其注意事项 1.1 先创建三个文件 1.2 注意事项:帮助高效记忆和理解 2.链表的基本功能接口 2.0 创建一个 链表 2.1 链表的打印 3.链表的创建新节点接口 4.链表的节点插入功能接口 4.1 尾插接口 4.2 头插接口 4.3 指定位…...

Opencc4j 开源中文繁简体使用介绍
Opencc4j Opencc4j 支持中文繁简体转换,考虑到词组级别。 Features 特点 严格区分「一简对多繁」和「一简对多异」。 完全兼容异体字,可以实现动态替换。 严格审校一简对多繁词条,原则为「能分则不合」。 词库和函数库完全分离,…...

vue 下载二进制文件
文章目录 概要技术细节 概要 vue 下载后端返回的二进制文件流 技术细节 import axios from "axios"; const baseUrl process.env.VUE_APP_BASE_API; //downLoadPdf("/pdf/download?pdfName" res .pdf, res); export function downLoadPdf(str, fil…...

数据结构之堆排序
对于几个元素的关键字序列{K1,K2,…,Kn},当且仅当满足下列关系时称其为堆,其中 2i 和2i1应不大于n。 { K i ≤ K 2 i 1 K i ≤ K 2 i 或 { K i ≥ K 2 i 1 K i ≥ K 2 i {\huge \{}^{K_i≤K_{2i}} _{K_i≤K_{2i1}} …...

鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之ScrollBar组件
鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之ScrollBar组件 一、操作环境 操作系统: Windows 10 专业版、IDE:DevEco Studio 3.1、SDK:HarmonyOS 3.1 二、ScrollBar组件 鸿蒙(HarmonyOS)滚动条组件ScrollBar&…...
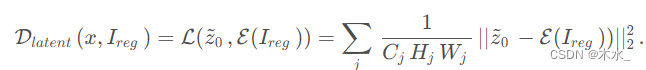
读论文:DiffBIR: Towards Blind Image Restoration with Generative Diffusion Prior
DiffBIR 发表于2023年的ICCV,是一种基于生成扩散先验的盲图像恢复模型。它通过两个阶段的处理来去除图像的退化,并细化图像的细节。DiffBIR 的优势在于提供高质量的图像恢复结果,并且具有灵活的参数设置,可以在保真度和质量之间进…...
基于微信小程序的新生报到系统的研究与实现,附源码
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝12w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇…...
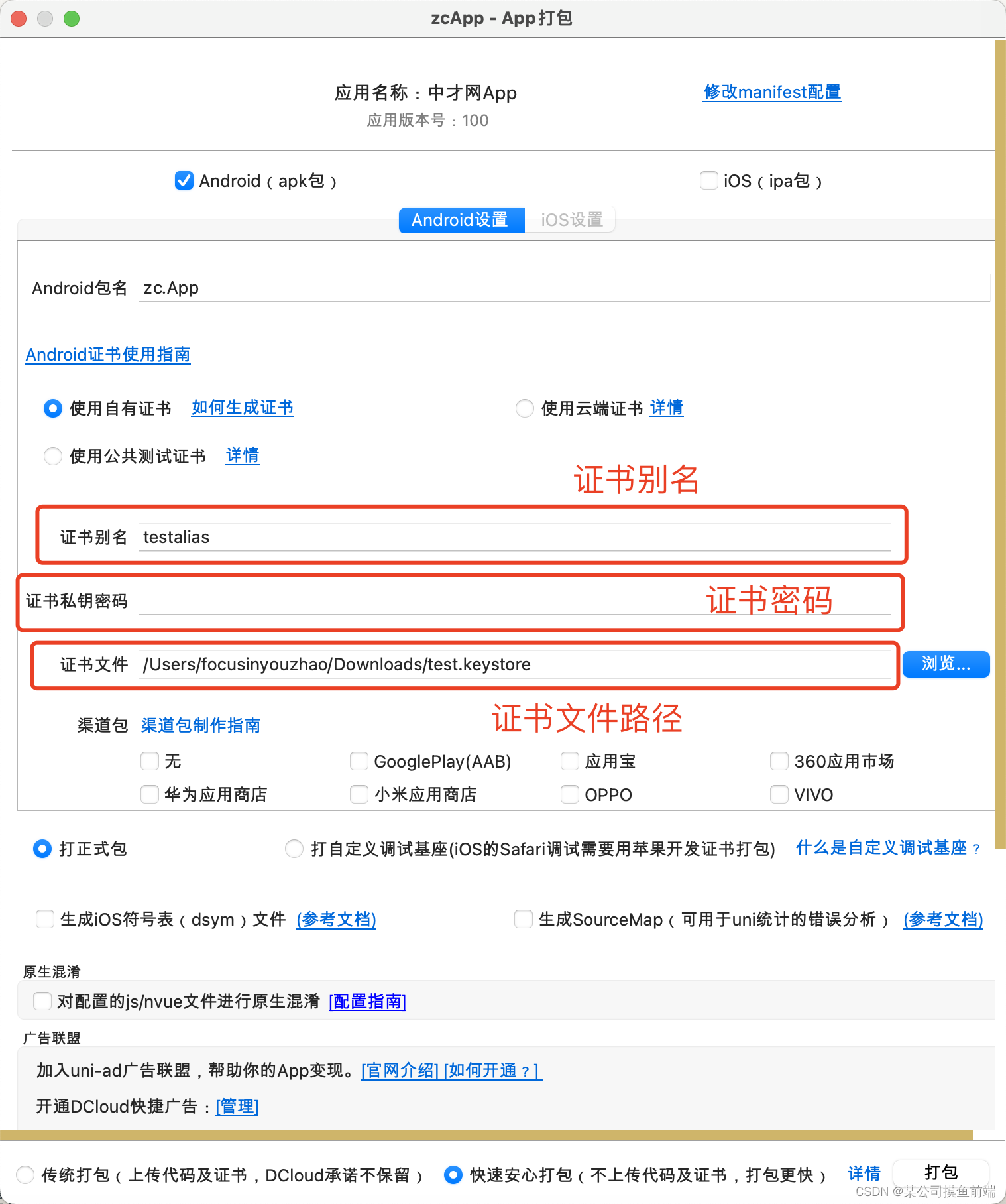
分享一下 uniapp 打包安卓apk
首先需要安装 Java 环境,这里就不做解释了 第二步:打开 mac 终端 / cmd 命令行工具 使用keytool -genkey命令生成证书 keytool -genkey -alias testalias -keyalg RSA -keysize 2048 -validity 36500 -keystore test.keystore *testalias 是证书别名&am…...
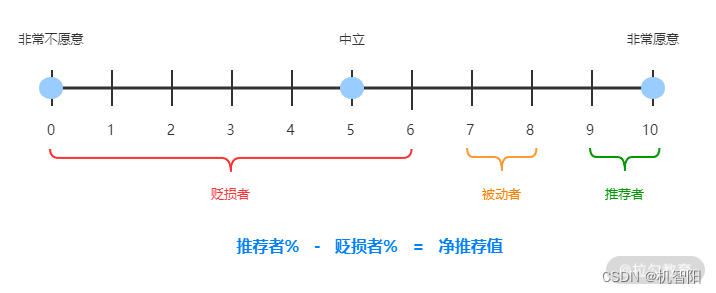
DevOps落地笔记-21|业务价值:软件发布的最终目的
上一课时介绍如何度量软件的内部质量和外部质量。在外部质量中,我们提到用户满意度是衡量软件外部质量的关键因素。“敏捷宣言”的第一条原则规定:“我们最重要的目标,是通过持续不断的及早交付有价值的软件使用户满意”。从这一点也可以看出…...

【动态规划】【前缀和】【数学】2338. 统计理想数组的数目
作者推荐 【动态规划】【前缀和】【C算法】LCP 57. 打地鼠 本文涉及知识点 动态规划汇总 C算法:前缀和、前缀乘积、前缀异或的原理、源码及测试用例 包括课程视频 LeetCode:2338. 统计理想数组的数目 给你两个整数 n 和 maxValue ,用于描述一个 理想…...

【已解决】onnx转换为rknn置信度大于1,图像出现乱框问题解决
前言 环境介绍: 1.编译环境 Ubuntu 18.04.5 LTS 2.RKNN版本 py3.8-rknn2-1.4.0 3.单板 迅为itop-3568开发板 一、现象 采用yolov5训练并将pt转换为onnx,再将onnx采用py3.8-rknn2-1.4.0推理转换为rknn出现置信度大于1,并且图像乱框问题…...
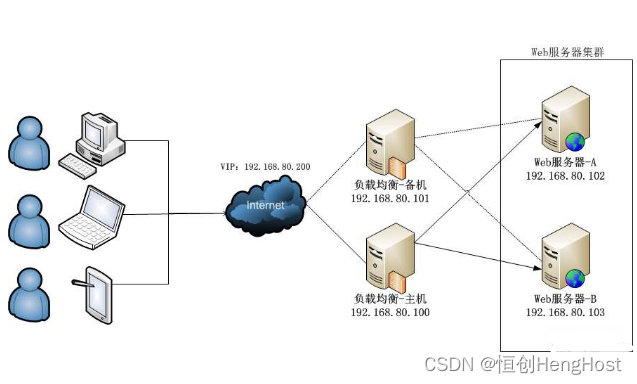
多路服务器技术如何处理大量并发请求?
在当今的互联网时代,随着用户数量的爆炸性增长和业务规模的扩大,多路服务器技术已成为处理大量并发请求的关键手段。多路服务器技术是一种并行处理技术,它可以通过多个服务器同时处理来自不同用户的请求,从而显著提高系统的整体性…...

SpringBoot - 不加 @EnableCaching 标签也一样可以在 Redis 中存储缓存?
网上文章都是说需要在 Application 上加 EnableCaching 注解才能让缓存使用 Redis,但是测试发现不用 EnableCaching 也可以使用 Redis,是网上文章有问题吗? 现在 Application 上用了 EnableAsync,SpringBootApplication࿰…...
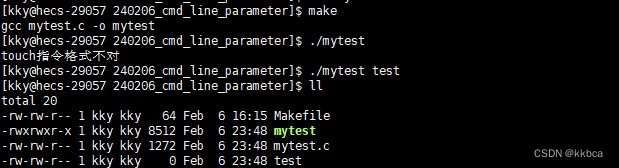
Linux------命令行参数
目录 前言 一、main函数的参数 二、命令行控制实现计算器 三、实现touch指令 前言 当我们在命令行输入 ls -al ,可以查看当前文件夹下所有文件的信息,还有其他的如rm,touch等指令,都可以帮我们完成相应的操作。 其实运行这些…...
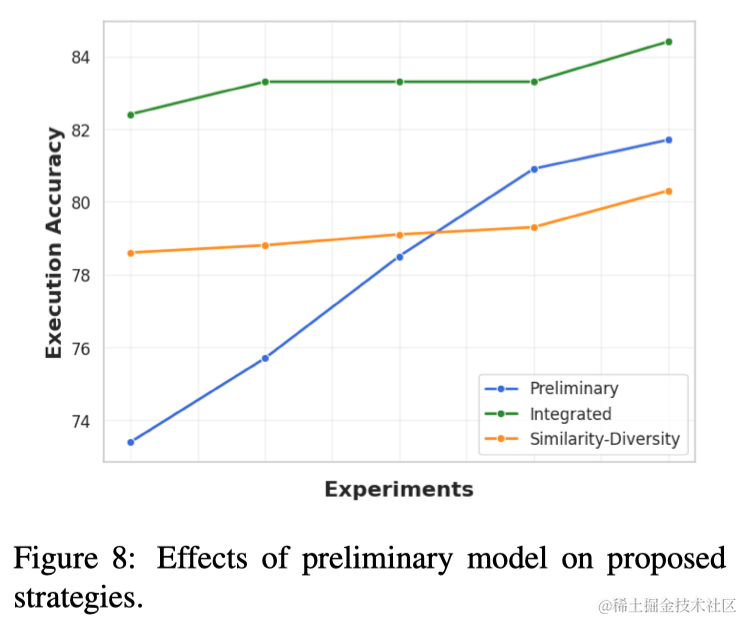
LLM少样本示例的上下文学习在Text-to-SQL任务中的探索
导语 本文探索了如何通过各种提示设计策略,来增强大型语言模型(LLMs)在Few-shot In-context Learning中的文本到SQL转换能力。通过使用示例SQL查询的句法结构来检索演示示例,并选择同时追求多样性和相似性的示例可以提高性能&…...

发音人「像真人」之外还要看什么:稳定性与一致性
🎯 发音人「像真人」之外还要看什么:稳定性与一致性在文字转语音领域,「像真人」往往是第一印象。然而,当您需要批量生成有声内容、长期使用同一音色时,真正决定体验的是稳定性与一致性。 顶伯文字转语音工具正是围绕这…...

2025终极指南:Cursor Free VIP破解工具如何帮你免费解锁AI编程助手所有功能
2025终极指南:Cursor Free VIP破解工具如何帮你免费解锁AI编程助手所有功能 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Yo…...

C++终端游戏开发:数据结构与算法在像素冒险世界中的应用
1. 项目概述:一个终端里的像素冒险世界如果你像我一样,对那种在命令行里跑起来的、充满复古像素感的游戏情有独钟,同时又对数据结构和算法如何驱动游戏逻辑感到好奇,那么autrin/Pokeman这个项目绝对值得你花时间研究。这不仅仅是一…...

CH32F103C8T6 vs STM32F103C8T6:程序下载生态深度对比与国产替代实战
CH32F103C8T6与STM32F103C8T6程序下载生态全维度对比与国产化迁移指南 在嵌入式开发领域,MCU的程序下载方式往往决定了开发效率的上限。当工程师从熟悉的STM32平台转向国产CH32时,最直接的"水土不服"往往就发生在烧录环节——同样的SWD接口为何…...

2026 年 5 月 CERT 发布 dnsmasq 六个严重安全漏洞,2.93 版本或一周左右发布
消息基本信息西蒙凯利在 2026 年 5 月 11 日,周一,协调世界时 17:18:25 发布消息,上一条消息(按线程)是[[Dnsmasq 讨论组] DHCP 请求中电路 ID 匹配问题],下一条消息(按线程)是[[Dns…...

UVa 215 Spreadsheet Calculator
题目分析 本题要求实现一个简单的电子表格计算器。电子表格是一个矩形网格,每个单元格包含一个整数或者一个表达式。表达式由整数常量、单元格引用以及 和 - 运算符组成,计算时遵循从左到右的结合顺序。 输入首先给出行数 rrr 和列数 ccc,其…...

改进人工势场多无人机三维航迹规划【附代码】
✨ 长期致力于航迹规划、多无人机、目标分配、人工势场算法、三维空间研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)多目标任务分配与人工势场基础&…...

智能语音转文字终极指南:如何用AsrTools轻松完成音频转字幕
智能语音转文字终极指南:如何用AsrTools轻松完成音频转字幕 【免费下载链接】AsrTools ✨ AsrTools: Smart Voice-to-Text Tool | Efficient Batch Processing | User-Friendly Interface | No GPU Required | Supports SRT/TXT Output | Turn your audio into accu…...
)
HC32F460_ADC驱动(二)
2 ADC工作的核心要素2.1 采样保持一般来说采样保持电路(S/H)是ADC转换的前端电路。由于模拟信号是时刻连续变化的,若转换过程中输入电压持续波动会导致转换结果失真。采样保持电路的核心作用是在ADC启动转换后保持输入信号不变,保…...

IGBT驱动技术革新:SCALE-iDriver磁隔离方案解析
1. IGBT驱动技术演进与SCALE-iDriver的突破在电力电子系统中,IGBT(绝缘栅双极型晶体管)作为核心功率开关器件,其驱动电路的性能直接决定了整个系统的效率和可靠性。传统IGBT驱动方案主要面临三大技术瓶颈:首先是隔离技…...