【课程作业_01】国科大2023模式识别与机器学习实践作业
国科大2023模式识别与机器学习实践作业
作业内容
从四类方法中选三类方法,从选定的每类方法中
,各选一种具体的方法,从给定的数据集中选一
个数据集(MNIST,CIFAR-10,电信用户流失数据集 )对这三种方法进行测试比较。
- 第一类方法:: 线性方法:线性SVM、 Logistic Regression
- 第二类方法: 非线性方法:Kernel SVM, 决策树
- 第三类方法: 集成学习:Bagging, Boosting
- 第四类方法: 神经元网络:自选结构
选择数据集
- MNIST
方法
线性SVM
方法介绍
支持向量机(SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器。SVM的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,或者求解其对偶问题。

SVM学习的基本想法是求解能够正确划分训练数据集并且几何间隔最大的分离超平面。如上图所示, w ⋅ x + b = 0 w \cdot x+b=0 w⋅x+b=0即为分离超平面,对于线性可分的数据集来说,这样的超平面有无穷多个(即感知机),但是几何间隔最大的分离超平面却是唯一的。
实验结果
对于每一个参数设置,做了三次实验,得到的模型准确率分别是ACC_1,ACC_2,ACC_3,平均值是ACC_M。
正则参数是正则项前面的系数。
| 正则参数 | 迭代次数 | ACC_1 | ACC_2 | ACC_3 | ACC_m |
|---|---|---|---|---|---|
| 10 | 1000 | 86.37% | 87.57% | 87.15% | 87.03% |
| 10 | 2000 | 86.9% | 88.45% | 86.4% | 87.25% |
| 50 | 1000 | 87.61% | 86.17% | 87.77% | 87.18% |
| 50 | 2000 | 86.97% | 88.02% | 88.1% | 87.7% |
| 100 | 1000 | 85.67% | 86.99% | 86.58% | 86.41% |
| 100 | 2000 | 86.94% | 86.29% | 86.84% | 86.69% |
结果分析
从结果可以看出,迭代次数一定时,一定范围内,随着正则参数的增大,模型预测的准确率会上升,但是超过一定范围,模型性能会下降,可能是正则参数过大导致模型欠拟合了。
当正则参数一定时,随着迭代次数的增大,模型的性能会逐渐变好。
决策树
方法介绍
决策树是一种典型的分类方法,首先对数据进行处理,利用归纳算法生成可读的规则和决策树,然后使用决策对新数据进行分析。具体来说,它是一种树形结构,其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果,本质是一颗由多个判断节点组成的树。
构建决策树的基本步骤为:
- 开始将所有记录看作一个节点
- 遍历每个变量的每一种分割方式,找到最好的分割点
- 分割成两个节点N1和N2
- 对N1和N2分别继续执行2-3步,直到每个节点不能再分。
实验结果
对于每一个参数设置,做了三次实验,得到的模型准确率分别是ACC_1,ACC_2,ACC_3,平均值是ACC_M。
| 分割类型 | 损失函数 | ACC_1 | ACC_2 | ACC_3 | ACC_M |
|---|---|---|---|---|---|
| best | gini | 87.61% | 87.87% | 88.03% | 87.84% |
| best | entropy | 88.54% | 88.40% | 88.38% | 88.44% |
| best | log_loss | 88.62% | 88.34% | 88.42% | 88.46% |
| random | gini | 86.61% | 87.09% | 87.01% | 86.90% |
| random | entropy | 87.55% | 87.82% | 88.20% | 87.86% |
| random | log_loss | 87.87% | 87.79% | 88.09% | 87.92% |
结果分析
从结果可以看出,当对节点分割时,选取最好的进行分割比随机分割的性能要好,因为可以获得的信息增益最好,而随机选取没有保障。
使用entropy和log_loss的性能比gini要好,而gini代表基尼系数,entropy代表信息增益,因此选择跟信息增益有关的损失更能提高决策树的性能。
神经元网络,使用简单的卷积神经网络
方法介绍
卷积神经网络(CNN),是一种专门用来处理具有类似网格结构的数据的神经网络。卷积网络是指那些至少在网络的一层中使用卷积运算来替代一般的矩阵乘法运算的神经网络。
卷积神经网络的基本结构由以下几个部分组成:输入层(input layer),卷积层(convolution layer),池化层(pooling layer),激活函数层和全连接层(full-connection layer)。
- 卷积层:对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器filter)做内积(逐个元素相乘再求和)的操作就是所谓的卷积操作
- 池化层:池化操作将输入矩阵某一位置相邻区域的总体统计特征作为该位置的输出,主要有平均池化(Average Pooling)、最大池化(Max Pooling)等。简单来说池化就是在该区域上指定一个值来代表整个区域。
- 激活函数:激活函数(非线性激活函数,如果激活函数使用线性函数的话,那么它的输出还是一个线性函数。)但使用非线性激活函数可以得到非线性的输出值。
- 全连接层:在全连接层中,每个神经元都与前一层中的所有神经元相连,因此它的输入是一个向量,输出也是一个向量。它对提取的特征进行非线性组合以得到输出。全连接层本身不具有特征提取能力,而是使得目标特征图失去空间拓扑结构,被展开为向量。
实验结果
迭代次数为epoch=10,使用带动量的随机梯度下降(SGD)进行优化,损失函数是交叉熵损失。
使用的卷积神经网络含有两层(含有卷积层,池化层,ReLU激活函数和批归一化层)和一个全连接层,输出的特征维度为10,因为MINIST只有10类。
| 批处理大小 | 学习率 | ACC |
|---|---|---|
| 64 | 0.1 | 99.03% |
| 64 | 0.01 | 98.95% |
| 64 | 0.001 | 98.09% |
| 128 | 0.1 | 99.16% |
| 128 | 0.01 | 98.95% |
| 128 | 0.001 | 97.35% |
| 128 | 0.02 | 99.02% |
| 128 | 0.002 | 98.12% |
结果分析
从结果可以看出,当批处理大小相同时,学习率为0.1时性能最好,之后随着学习率的减小模型的性能逐渐降低。
当学习率一致时,大多数情况下,批处理大小增加模型的性能也会更好,但有些情况不是,如学习率等于0.001时,此时需要将学习率扩大2倍(跟批处理大小增加的倍数一致),模型的性能才会比之前更好。
代码
线性SVM和决策树
# -*- encoding: utf-8 -*-
"""
File machine_learning_methods.py
Created on 2024/1/20 18:55
Copyright (c) 2024/1/20
@author:
"""
from sklearn.model_selection import train_test_split
from sklearn import svm
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from load_minist import load_minist_dataif __name__ == '__main__':minist_path = "./datasets/mnist-original.mat"method_type = "linear_svm"X_data, Y_data = load_minist_data(minist_path)# 数据规范化scaler = StandardScaler()X = scaler.fit_transform(X_data)# 分割得到训练和测试数据集X_train, X_test, Y_train, Y_test = train_test_split(X_data, Y_data, test_size=10000, random_state=42)print(f"Train data size:{X_train.shape}")print(f"Test data size:{X_test.shape}")if method_type == "linear_svm":print("Start training Linear SVM...")# 构建linear svm C表示正则项的权重l_svm = svm.LinearSVC(C = 10, max_iter=2000)l_svm.fit(X_train, Y_train)print("Training over!")print("The function is:")print(f"w:{l_svm.coef_}")print(f"b:{l_svm.intercept_}")print("Start testing...")# 打印模型的精确度print(f"{l_svm.score(X_test, Y_test) * 100}%")elif method_type == "kernel_svm":print("Start training Kernel SVM...")# 构建linear svm C表示正则项的权重k_svm = svm.SVC(C=100, max_iter=1000)k_svm.fit(X_train, Y_train)print("Training over!")print("Start testing...")# 打印模型的精确度print(f"{k_svm.score(X_test, Y_test) * 100}%")elif method_type == "decision_tree":print("Start training Decision Tree...")# 构建决策树d_tree = DecisionTreeClassifier(criterion = "gini", splitter = "best")d_tree.fit(X_train, Y_train)print("Training over!")print("Start testing...")# 打印模型的精确度print(f"{d_tree.score(X_test, Y_test) * 100}%")
卷积神经网络
# -*- encoding: utf-8 -*-
"""
File neural_net.py
Created on 2024/1/20 18:55
Copyright (c) 2024/1/20
@author:
"""
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms# 设计模型
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.block1 = nn.Sequential(nn.Conv2d(in_channels=1, out_channels=10, kernel_size=5),nn.MaxPool2d(kernel_size=2),nn.ReLU(True),nn.BatchNorm2d(10),)self.block2 = nn.Sequential(nn.Conv2d(in_channels=10, out_channels=20, kernel_size=5),nn.MaxPool2d(kernel_size=2),nn.ReLU(True),nn.BatchNorm2d(20),)# 输出10个类别self.fc = nn.Sequential(nn.Flatten(),nn.Linear(in_features=320, out_features=10))def forward(self, x):# x: B C=10 H=12 W=12x = self.block1(x)x = self.block2(x)x = self.fc(x)return xdef construct_data_loader(batch_size):# 数据的归一化transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])# 训练集train_dataset = datasets.MNIST(root='./datasets', train=True, transform=transform, download=True)train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)# 测试集test_dataset = datasets.MNIST(root='./datasets', train=False, transform=transform, download=True)test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)return train_loader, test_loaderdef train_model(train_loader):for (images, target) in train_loader:# images shape: B C=1 H Woutputs = model(images)loss = criterion(outputs, target)optimizer.zero_grad()loss.backward()optimizer.step()def test_model(test_loader):correct, total = 0, 0with torch.no_grad():for (images, target) in test_loader:outputs = model(images)_, predicted = torch.max(outputs.data, dim=1)total += target.size(0)correct += (predicted == target).sum().item()print('[%d / %d]: %.2f %% ' % (i + 1, epoch, 100 * correct / total))if __name__ == '__main__':# 定义超参数# 批处理大小batch_size = 128# 学习率lr = 0.002# 动量momentum = 0.5# 训练的epoch数epoch = 10# 构建模型model = Net()# 损失函数和优化器criterion = nn.CrossEntropyLoss()optimizer = torch.optim.SGD(model.parameters(), lr=lr, momentum=momentum)train_loader, test_loader = construct_data_loader(batch_size)for i in range(epoch):# 训练train_model(train_loader)# 测试test_model(test_loader)
参考资料
基于决策树模型和支持向量机模型的手写数字识别_手写数字识别决策树-CSDN博客
ResNet18实现——MNIST手写数字识别(突破0.995)_mnist resnet-CSDN博客
相关文章:
【课程作业_01】国科大2023模式识别与机器学习实践作业
国科大2023模式识别与机器学习实践作业 作业内容 从四类方法中选三类方法,从选定的每类方法中 ,各选一种具体的方法,从给定的数据集中选一 个数据集(MNIST,CIFAR-10,电信用户流失数据集 )对这…...

LeetCode374. Guess Number Higher or Lower——二分查找
文章目录 一、题目二、题解 一、题目 We are playing the Guess Game. The game is as follows: I pick a number from 1 to n. You have to guess which number I picked. Every time you guess wrong, I will tell you whether the number I picked is higher or lower th…...
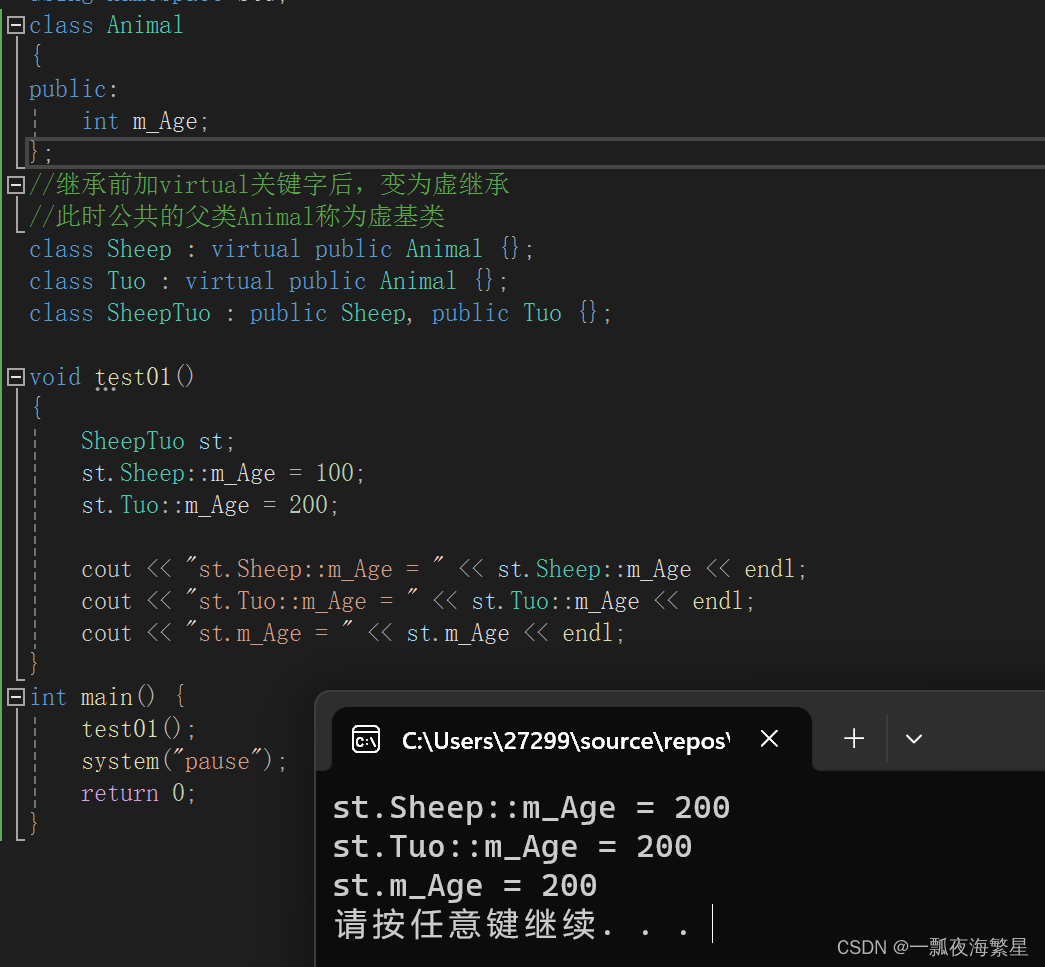
继承
1.继承的作用 有些类与类之间存在特殊关系,下级别的成员除了拥有上一级别的共性,还有自己的特性。 这个时候我们就可以考虑利用继承技术,减少重复代码。 总结: 继承的好处:可以减少重复的代码 class A : public B;…...

北斗卫星在物联网时代的应用探索
北斗卫星在物联网时代的应用探索 在当今数字化时代,物联网的应用已经深入到人们的生活中的方方面面,让我们的生活更加智能便捷。而北斗卫星系统作为我国自主研发的卫星导航系统,正为物联网的发展提供了强有力的支撑和保障。本文将全面介绍北…...

SQL注入 - 利用报错函数 floor 带回回显
环境准备:构建完善的安全渗透测试环境:推荐工具、资源和下载链接_渗透测试靶机下载-CSDN博客 一、原理 利用COUNT(), FLOOR(), RAND(), 和 GROUP BY来生成主键重复错误 函数解释 count(): 这个函数用于计算满足某一条件下的行数,是SQL中的一个聚合函数,常用于统计查询结…...
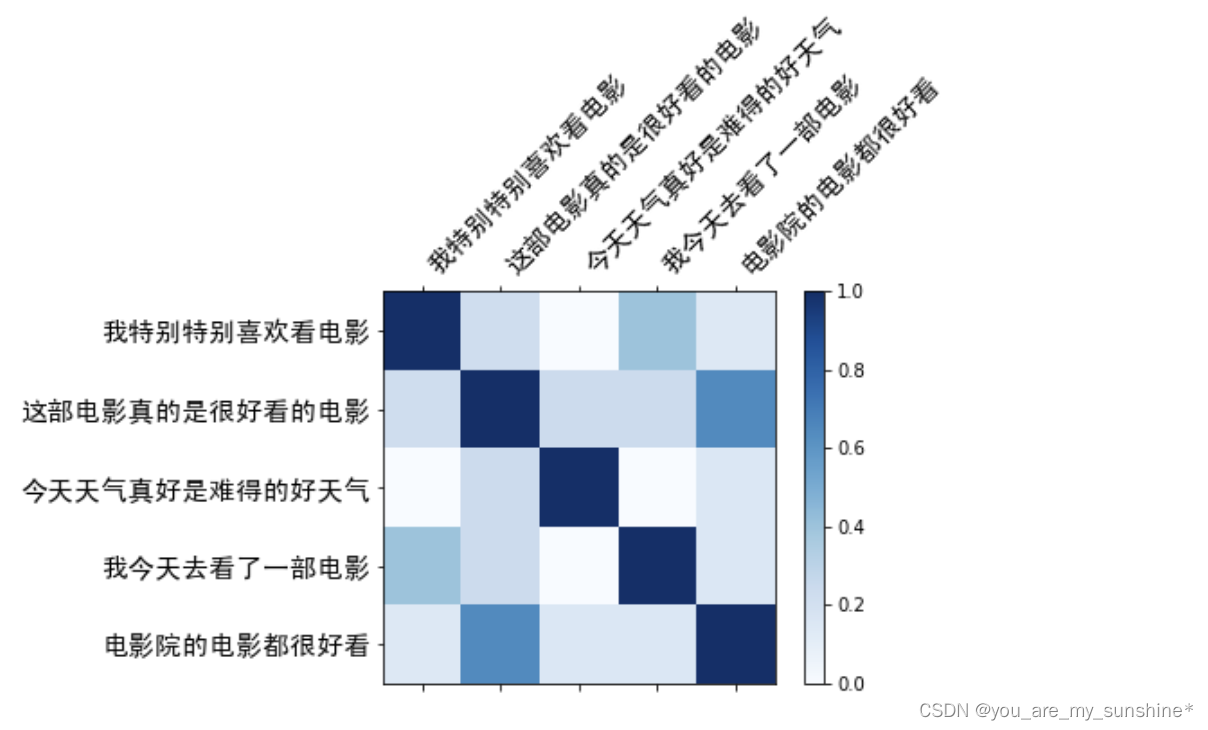
NLP_Bag-Of-Words(词袋模型)
文章目录 词袋模型用词袋模型计算文本相似度1.构建实验语料库2.给句子分词3.创建词汇表4.生成词袋表示5.计算余弦相似度6.可视化余弦相似度 词袋模型小结 词袋模型 词袋模型是一种简单的文本表示方法,也是自然语言处理的一个经典模型。它将文本中的词看作一个个独立…...
C语言rand随机数知识解析和猜数字小游戏
rand随机数 rand C语言中提供了一个可以随机生成一个随机数的函数:rand() 函数原型: int rand(void);rand函数返回的值的区间是:0~RAND_MAX(32767)之间。大部分编译器都是32767。 #include<stdlib.h> int ma…...

django中的缓存功能
一:介绍 Django中的缓存功能是一个重要的性能优化手段,它可以将某些耗时的操作(如数据库查询、复杂的计算等)的结果存储起来,以便在后续的请求中直接使用这些缓存的结果,而不是重新执行耗时的操作。Django…...
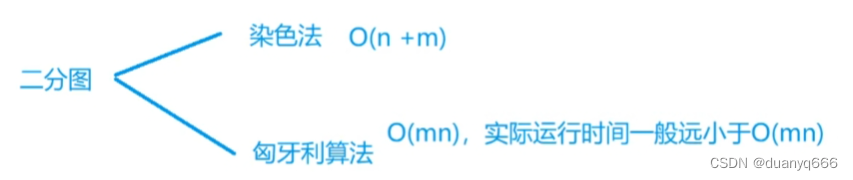
三、搜索与图论
DFS 排列数字 #include<iostream> using namespace std; const int N 10; int a[N], b[N]; int n;void dfs(int u){if(u > n){for(int i 1; i < n; i)cout<<a[i]<<" ";cout<<endl;return;}for(int i 1; i < n; i){if(!b[i]){b[…...
【翻译】Processing安卓模式的安装使用及打包发布(内含中文版截图)
原文链接在下面的每一章的最前面。 原文有三篇,译者不知道贴哪篇了,这篇干脆标了原创。。 译者声明:本文原文来自于GNU协议支持下的项目,具备开源二改授权,可翻译后公开。 文章目录 Install(安装࿰…...

MATLAB图像处理——边缘检测及图像分割算法
1.检测图像中的线段 clear clc Iimread(1.jpg);%读入图像 Irgb2gray(I); %转换为灰度图像 h1[-1, -1. -1; 2, 2, 2; -1, -1, -1]; %模板 h2[-1, -1, 2; -1, 2, -1; 2, -1, -1]; h3[-1, 2, -1; -1, 2, -1; -1, 2, -1]; h4[2, -1, -1; -1, 2, -1; -1, -1, 2]; J1imfilter(I, h1)…...

探索设计模式:原型模式深入解析
探索设计模式:原型模式深入解析 设计模式是软件开发中用于解决常见问题的标准解决方案。它们不仅能提高代码的可维护性和可复用性,还能让其他开发者更容易理解你的设计决策。今天,我们将聚焦于创建型模式之一的原型模式(Prototyp…...

IAR报错解决:Fatal Error[Pe1696]: cannot open source file “zcl_ha.h“
报错信息 Fatal Error[Pe1696]: cannot open source file "zcl_ha.h" K:\Z-Stack 3.0.2\Projects\zstack\Practice\SampleSwitch\Source\zcl_samplesw_data.c 51 意思是找不到zcl_ha.h文件 找不到的理由可能是我把例程复制了一份到别的文件目录下,少复制…...
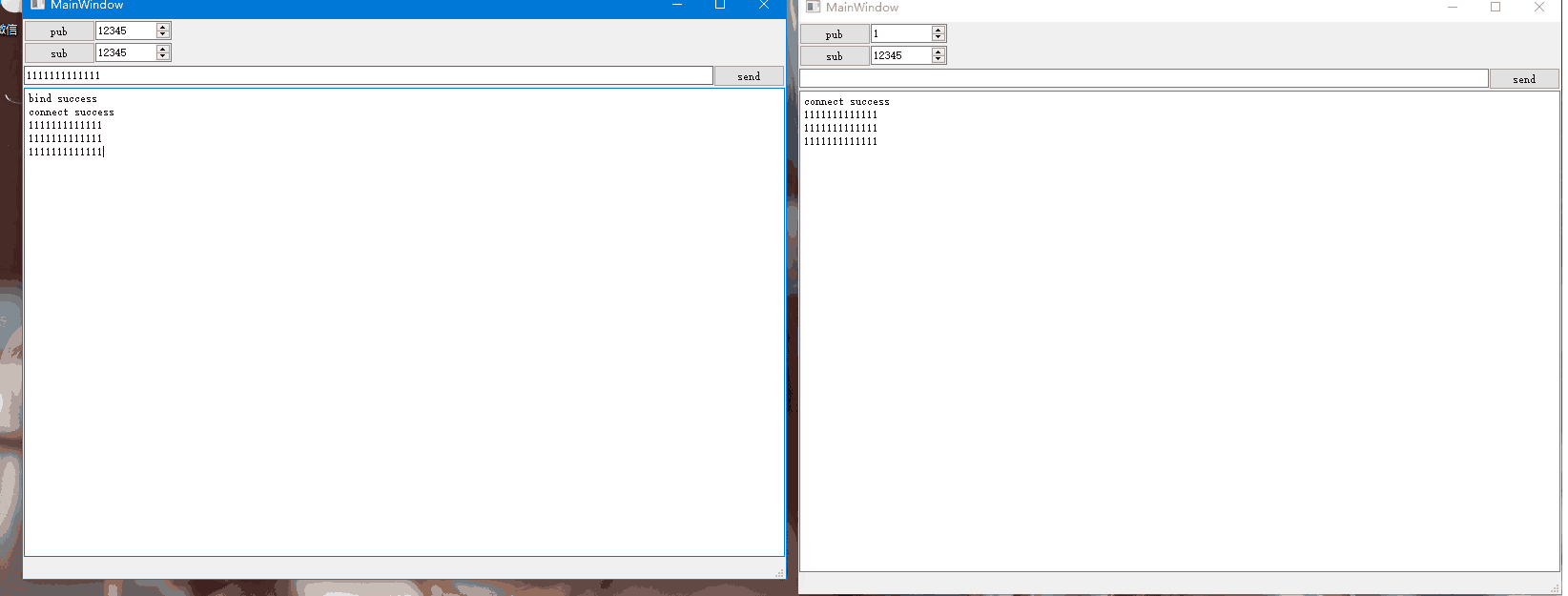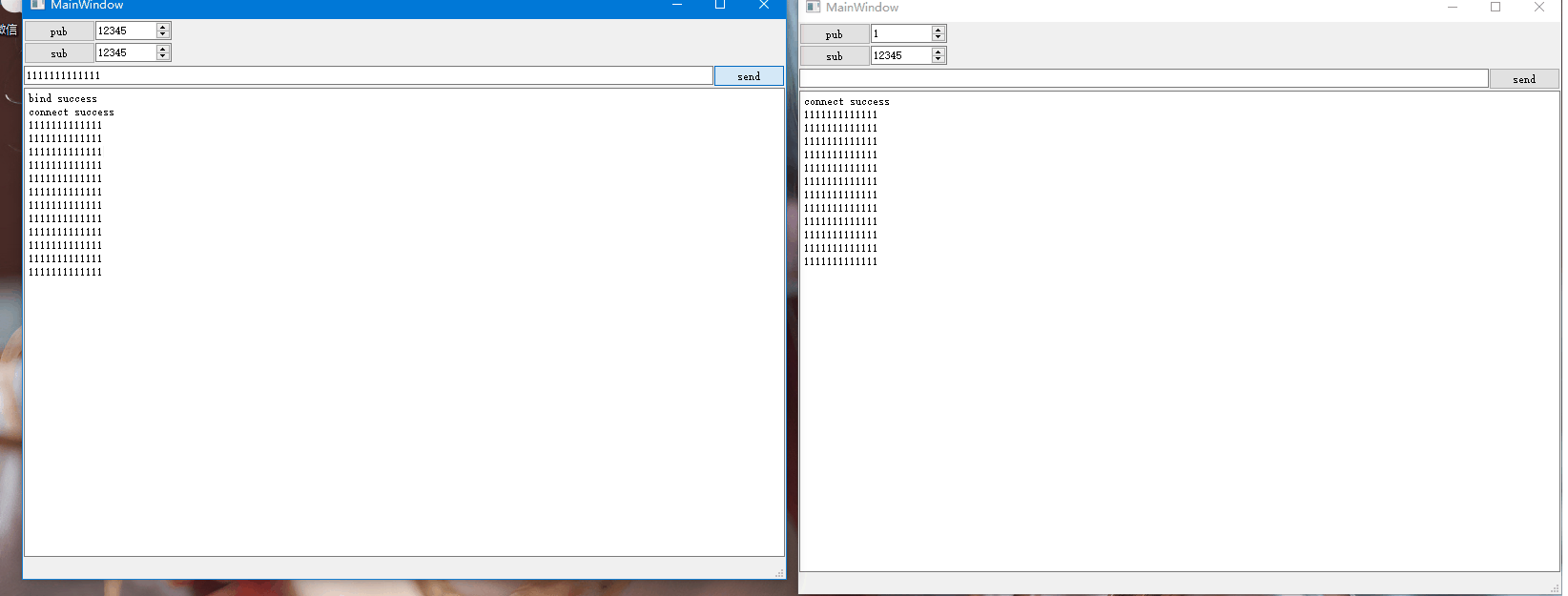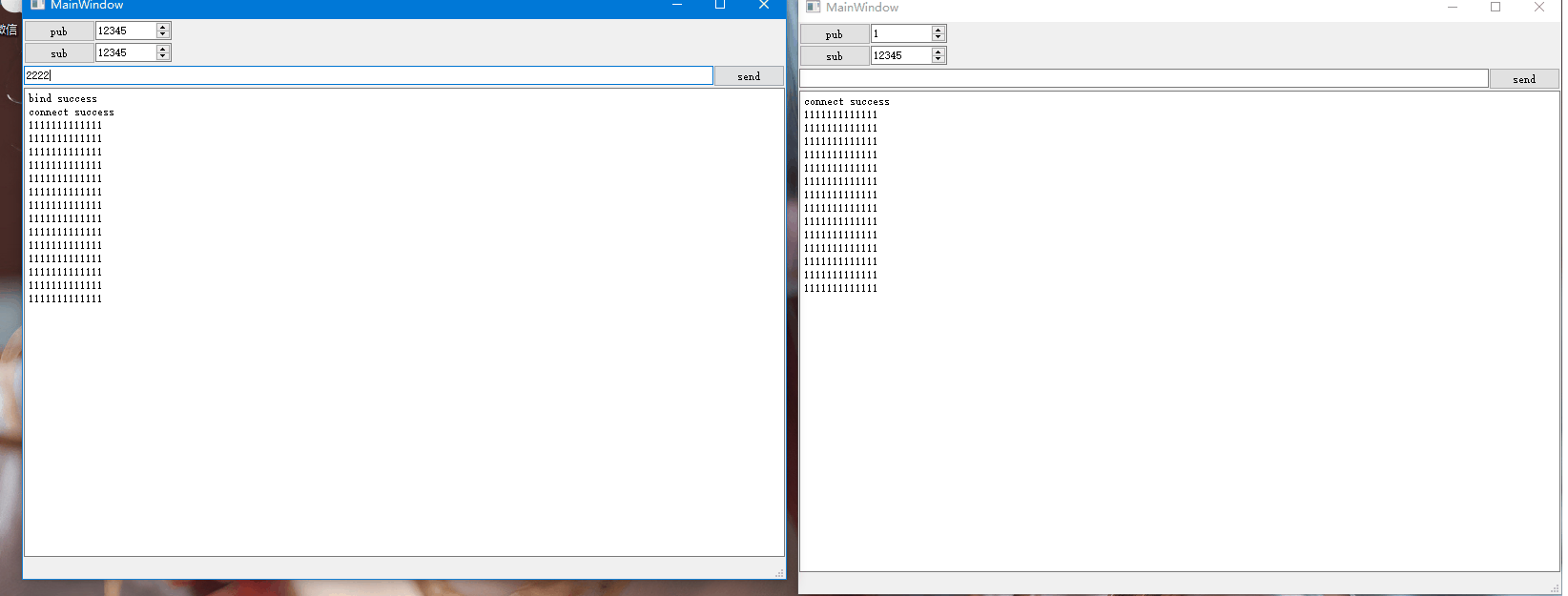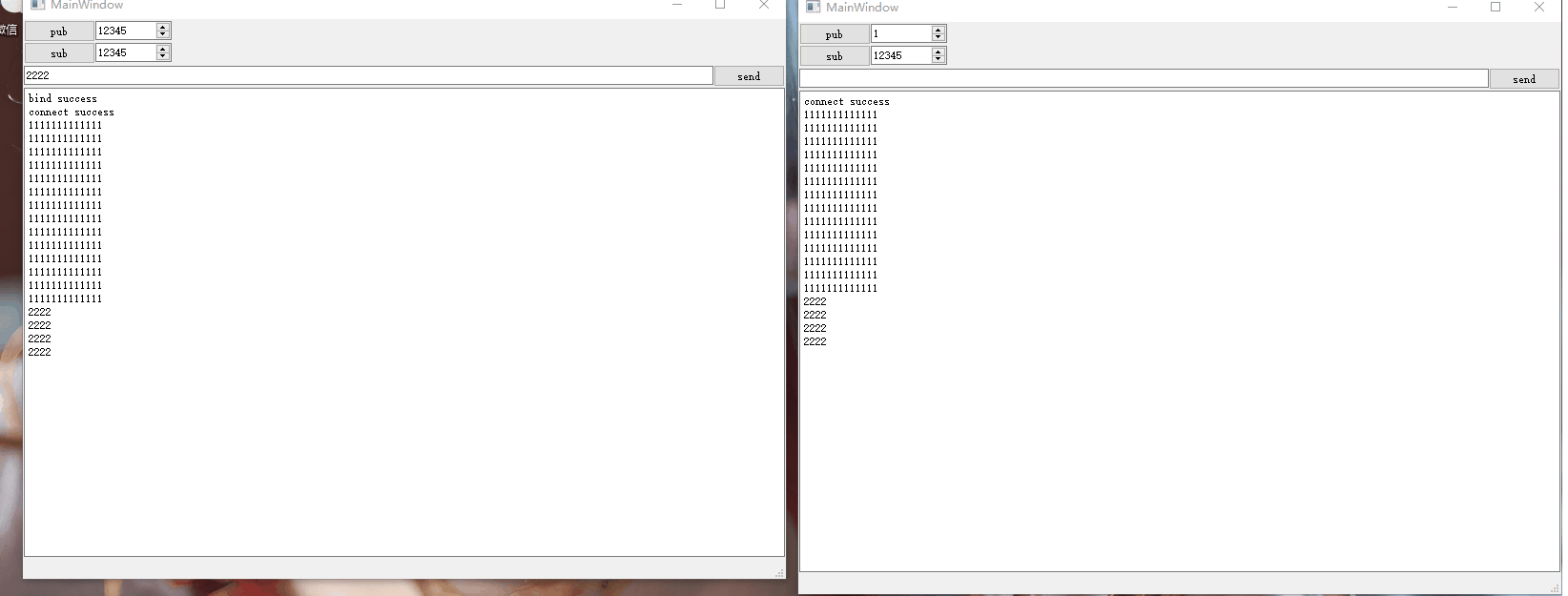
Qt网络编程-ZMQ的使用
不同主机或者相同主机中不同进程之间可以借助网络通信相互进行数据交互,网络通信实现了进程之间的通信。比如两个进程之间需要借助UDP进行单播通信,则双方需要知道对方的IP和端口,假设两者不在同一主机中,如下示意图: …...

如何清理Docker占用的磁盘空间?
在Docker中,随着时间的推移,占用的磁盘空间可能会不断增加。为了保持系统的稳定性和性能,定期清理Docker占用的磁盘空间非常重要。下面将介绍一些清理Docker磁盘空间的方法。 一、清理无用的容器 有时候,我们可能会运行一些临时…...

从零开始学HCIA之NAT基本工作原理
1、NAT设计之初的目的是解决IP地址不足的问题,慢慢地其作用发展到隐藏内部地址、实现服务器负载均衡、完成端口地址转换等功能。 2、NAT完成将IP报文报头中的IP地址转换为另一个IP地址的过程,主要用于实现内部网络访问外部网络的功能。 3、NAT功能一般…...

Day40- 动态规划part08
一、单词拆分 题目一:139. 单词拆分 139. 单词拆分 给你一个字符串 s 和一个字符串列表 wordDict 作为字典。如果可以利用字典中出现的一个或多个单词拼接出 s 则返回 true。 注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以…...

论文笔记:相似感知的多模态假新闻检测
整理了RecSys2020 Progressive Layered Extraction : A Novel Multi-Task Learning Model for Personalized Recommendations)论文的阅读笔记 背景模型实验 论文地址:SAFE 背景 在此之前,对利用新闻文章中文本信息和视觉信息之间的关系(相似…...

5G技术对物联网的影响
随着数字化转型的加速,5G技术作为通信领域的一次重大革新,正在对物联网(IoT)产生深远的影响。对于刚入行的朋友们来说,理解5G技术及其对物联网应用的意义,是把握行业发展趋势的关键。 让我们简单了解什么是…...
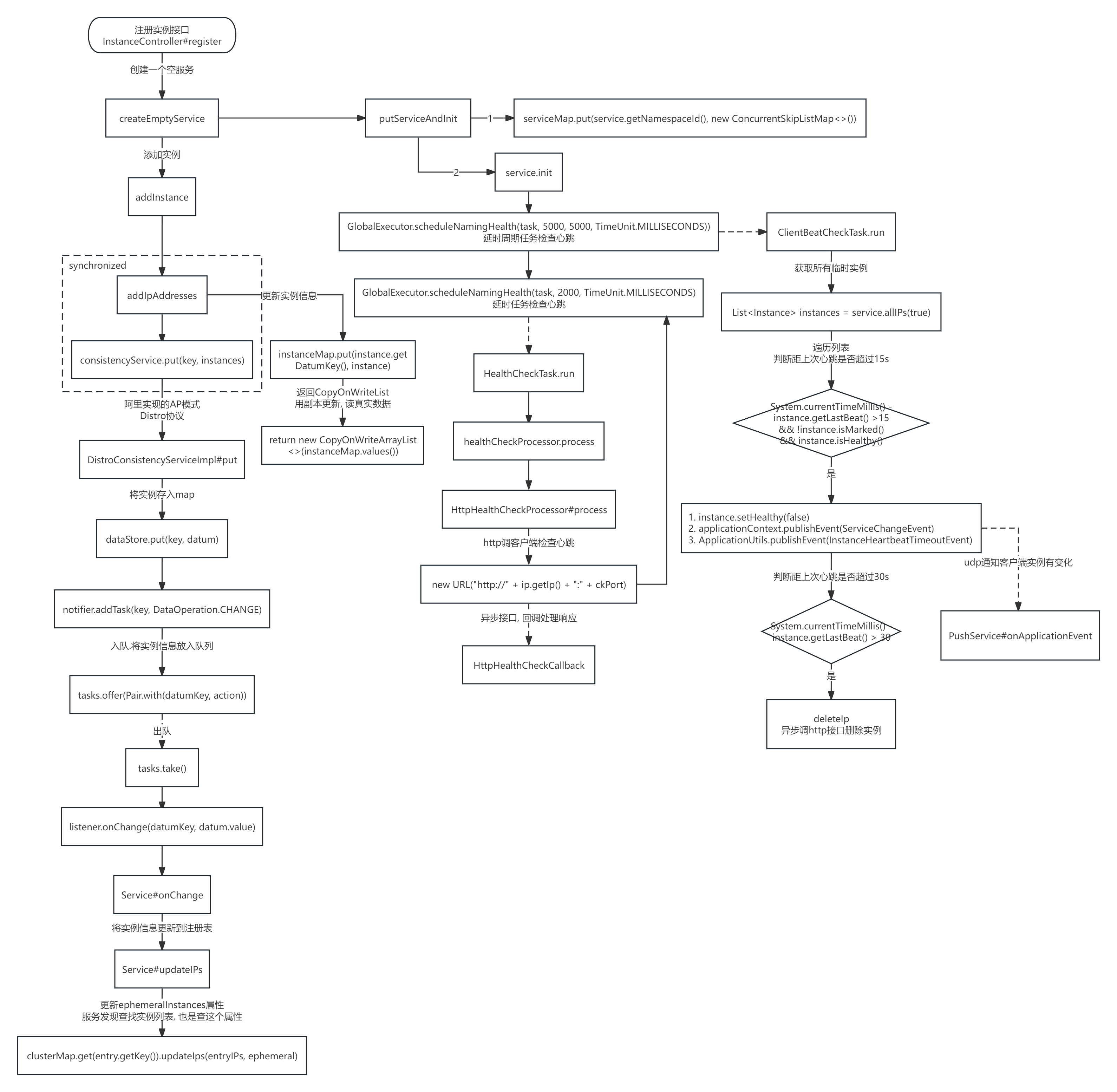
Nacos1.X源码解读(待完善)
目录 下载源码 注册服务 客户端注册流程 注册接口API 服务端处理注册请求 设计亮点 服务端流程图 下载源码 1. 克隆git地址到本地 # 下载nacos源码 git clone https://github.com/alibaba/nacos.git 2. 切换分支到1.4.7, maven编译(3.5.1) 3. 找到启动类com.alibaba.na…...

别再替换同义词!2026实测论文降AIGC工具:一次降至10%以下的排版保护指南
自从央视公开探讨初稿写作的AI味儿现象:据相关数据显示,近六成师生习惯使用生成式辅助,其中近三成学生将其用于核心初稿的撰写,各高校针对AIGC的审查便日益严格。 正是因为这种大背景,四月一到,定稿通知刚…...

基于开源项目构建智能音箱自定义电台技能:从原理到部署实践
1. 项目概述:一个为智能音箱打造的“龙虾电台”技能最近在折腾智能家居和语音助手,发现一个挺有意思的开源项目,叫“lobster-radio-skill”。光看名字,你可能会有点摸不着头脑:“龙虾电台”?这跟智能音箱有…...

毫秒算网的光通信技术——从“东数西算“到“毫秒用算“
引言:从"算力在哪"到"算力怎么到" 2021年启动的"东数西算"工程回答了一个根本问题:算力应该布局在哪里。通过在西部建设8大枢纽、10大集群,国家将算力基础设施与绿色能源禀赋深度耦合,开启了算力地…...

半小时搞定C#开发
前言 此篇发出的原因有两点 致敬C#开篇 - 孤独战士,一篇包含雄心壮志的开篇,便无疾而终,时隔这么多年回关,内心莫名欣慰,感谢曾经的自己,就像文章标题所说,做一个无谓的孤独战士。笔者看到现在…...

在Windows上安装APK的终极指南:5步掌握APK Installer工具
在Windows上安装APK的终极指南:5步掌握APK Installer工具 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想在Windows电脑上直接安装Android应用…...

WinForm用户控件调试踩坑记:从‘无法试运行’到完美模块测试的完整流程
WinForm用户控件调试实战:从模块移植到精准测试的完整指南 引言:为什么需要独立的控件测试环境? 在WinForm开发中,用户控件(UserControl)的复用与调试一直是让开发者头疼的问题。当你在主项目中直接测试一个复杂控件时,…...

瑞芯微-I2S | 音频驱动调试实战:从寄存器分析到音频环路测试
1. 瑞芯微I2S音频驱动调试全景指南 第一次接触瑞芯微平台的音频驱动调试时,我被各种专业术语和复杂的寄存器配置搞得晕头转向。经过多个项目的实战积累,我发现只要掌握正确的调试方法,音频驱动问题都能迎刃而解。本文将带你从底层寄存器分析开…...

挑战 100ms 延迟极限:深度拆解 dograh,构建企业级开源 WebRTC 实时语音智能体平台
发布日期: 2026-05-18标签: #VoiceAgent #WebRTC #语音智能体 #dograh #大模型 #实时音视频一、 引言在 2026 年,随着大模型多模态能力的爆发,传统的“打字输入、文字输出”交互模式正迅速向“纯语音实时对讲”演进。然而…...
)
Unity3D LineRenderer 从入门到精通:手把手教你绘制炫酷动态轨迹(附完整C#脚本)
Unity3D LineRenderer 动态轨迹绘制实战指南 在游戏开发中,动态轨迹效果是提升视觉体验的重要元素之一。无论是魔法技能的飞行路径、赛车游戏的轮胎痕迹,还是数据可视化中的动态连线,流畅且富有表现力的线条渲染都能显著增强场景的沉浸感。Un…...

量子错误校正与机器学习中的辅助比特影响研究
1. 量子错误校正与量子机器学习的基础概念量子计算的核心挑战之一是量子态的脆弱性。与环境相互作用导致的退相干效应会迅速破坏量子信息,这使得量子错误校正(QEC)成为实现实用量子计算的关键技术。在传统量子计算中,QEC通过冗余编…...