DolphinScheduler-3.2.0 集群搭建
目录
一、基础环境准备
1.1 组件下载地址
1.2 前置准备工作
二、 DolphinScheduler集群部署
2.1 解压安装包
2.2 配置数据库
2.3 准备 DolphinScheduler 启动环境
2.3.1 配置用户免密及权限
2.3.2 配置机器 SSH 免密登陆
2.3.3 启动 zookeeper集群
2.3.4 修改install_env.sh 文件
2.3.5 修改dolphinscheduler_env.sh 文件
2.3.6 初始化数据库
2.3.7 修改application.yaml文件
2.3.8 启动 DolphinScheduler
2.3.9 登录 DolphinScheduler
2.3.10 DolphinScheduler概览页
一、基础环境准备
1.1 组件下载地址
DolphinScheduler-3.2.0官网下载地址:
https://dolphinscheduler.apache.org/zh-cn/download/3.2.0![]() https://dolphinscheduler.apache.org/zh-cn/download/3.2.0
https://dolphinscheduler.apache.org/zh-cn/download/3.2.0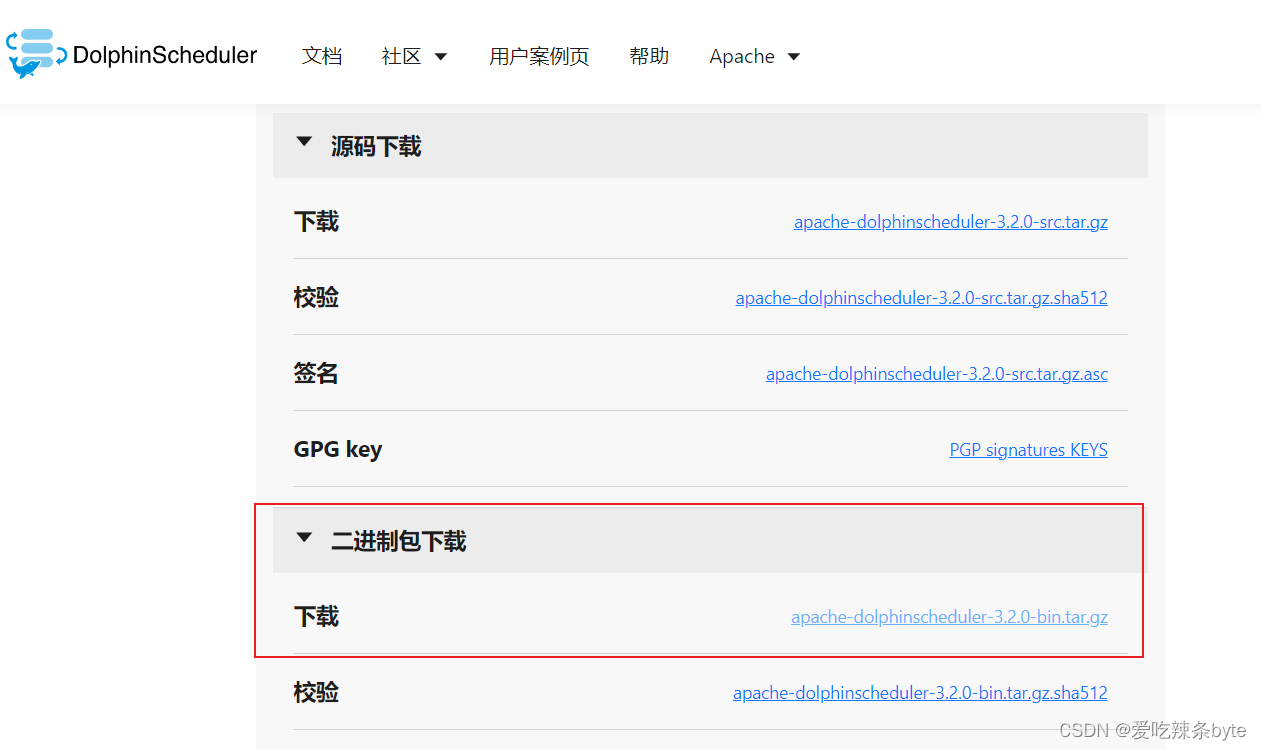
官网安装文档:https://dolphinscheduler.apache.org/zh-cn/docs/3.2.0/guide/installation/pseudo-cluster![]() https://dolphinscheduler.apache.org/zh-cn/docs/3.2.0/guide/installation/pseudo-cluster
https://dolphinscheduler.apache.org/zh-cn/docs/3.2.0/guide/installation/pseudo-cluster
1.2 前置准备工作
- JDK:下载JDK (1.8+),安装并配置
JAVA_HOME环境变量,并将其下的bin目录追加到PATH环境变量中。
[root@bigdata102 logs]# vim /etc/profile.d/my_env.sh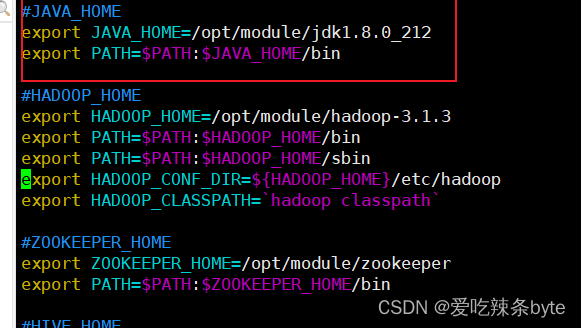
- 数据库:PostgreSQL (8.2.15+) 或者 MySQL (5.7+),两者任选其一即可,如 MySQL 则需要 JDBC Driver 8.0.16 及以上的版本。(这块后面会详细介绍)
[root@bigdata102 ~]$ mysql -h 192.168.10.102 -u root -P3306 -p
#密码123456
- 注册中心:ZooKeeper (3.8.0+)
ps:集群zk版本用的是3.5.7暂时没出问题
二、 DolphinScheduler集群部署
部署规划:
| 组件名称 | bigdata102 | bigdata103 | bigdata104 |
| DolphinScheduler3.2.0 | MasterServer | ||
| WorkerServer | WorkerServer | WorkerServer | |
| AlertServer | |||
| ApiApplicationServer | |||
| Zookeeper-3.5.7 | zk | zk | zk |
| Mysql-5.7.16 | mysql | ||
| mysql-connector-j-8.3.0.jar | mysql-connector-j-8.3.0.jar | mysql-connector-j-8.3.0.jar |
ps: 为了书写方便,下文中的DolphinScheduler 直接简称为ds
2.1 解压安装包
将ds安装包上传到bigdata102节点的/opt/software目录下,并直接解压到当前目录(ps:此处的解压目录不是最终的安装目录)
[root@bigdata102 software]# tar -zxvf apache-dolphinscheduler-3.2.0-bin.tar.gz2.2 配置数据库
ds元数据存储在关系型数据库中,故需创建相应的数据库和用户。
mysql -h 192.168.10.102 -u root -P3306 -p
//创建数据库
mysql> CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
//创建用户
//修改 {user} 和 {password} 为你希望的用户名和密码
mysql> CREATE USER '{user}'@'%' IDENTIFIED BY '{password}';
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO '{user}'@'%';
mysql> CREATE USER '{user}'@'localhost' IDENTIFIED BY '{password}';
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO '{user}'@'localhost';
mysql> FLUSH PRIVILEGES;
若出现以下错误信息,表明新建用户的密码过于简单。
ERROR 1819 (HY000): Your password does not satisfy the current policy requirements
可提高密码复杂度或者执行以下命令降低MySQL密码强度级别。
mysql> set global validate_password_policy=0;
mysql> set global validate_password_length=4;
赋予用户相应权限
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'%';
mysql> flush privileges;
ps:非常关键的一步:
如果使用 MySQL作为ds的元数据库,还需要将mysql-connector-java 驱动 ( 8.0.16 及以上的版本) 移动到ds的每个模块的 libs 目录下,其中包括 api-server/libs , alert-server/libs , master-server/libs ,worker-server/libs, tools/libs
本集群中:是将 mysql-connector-j-8.3.0.jar 移动到上述五个libs目录下

2.3 准备 DolphinScheduler 启动环境
2.3.1 配置用户免密及权限
创建部署用户,并且一定要配置 sudo 免密。以创建 dolphinscheduler 用户为例。
# 创建用户需使用 root 登录
useradd dolphinscheduler# 添加密码
echo "dolphinscheduler" | passwd --stdin dolphinscheduler# 配置 sudo 免密
sed -i '$adolphinscheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL' /etc/sudoers
sed -i 's/Defaults requirett/#Defaults requirett/g' /etc/sudoers# 修改目录权限,使得部署用户对二进制包解压后的 apache-dolphinscheduler-*-bin 目录有操作权限
chown -R dolphinscheduler:dolphinscheduler apache-dolphinscheduler-*-bin
chmod -R 755 apache-dolphinscheduler-*-bin2.3.2 配置机器 SSH 免密登陆
由于ds是集群部署模式,安装的时候,由单节点向其他节点发送资源,各节点间需要能 SSH 免密登陆。
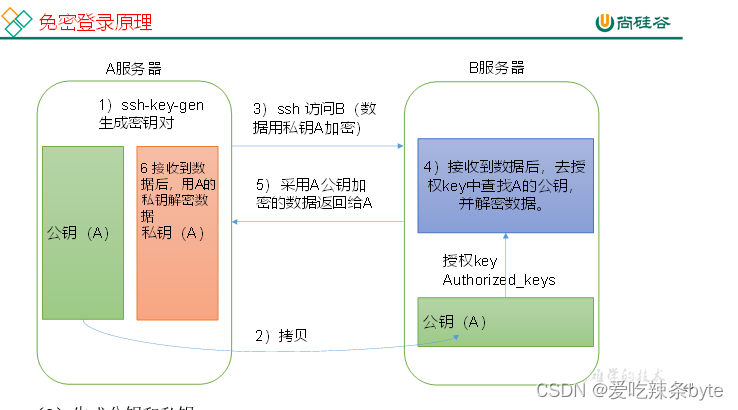
免密登陆配置过程:
- 生成公钥和私钥
[dolphinscheduler@bigdata102 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
- 将公钥拷贝到要免密登录的目标机器上
[dolphinscheduler@bigdata102 .ssh]$ ssh-copy-id bigdata102
[dolphinscheduler@bigdata102 .ssh]$ ssh-copy-id bigdata103
[dolphinscheduler@bigdata102 .ssh]$ ssh-copy-id bigdata104
免密配置完成后,用命令 ssh localhost 判断是否成功,如果不需要输入密码就能ssh登陆,则证明配置成功。

2.3.3 启动 zookeeper集群
不赘述,zk集群部署流程请自行百度。
2.3.4 修改install_env.sh 文件
vim bin/env/install_env.sh
# Example for hostnames: ips="ds1,ds2,ds3,ds4,ds5", Example for IPs: ips="192.168.8.1,192.168.8.2,192.168.8.3,192.168.8.4,192.168.8.5"
ips=${ips:-"bigdata102,bigdata103,bigdata104"}# Port of SSH protocol, default value is 22. For now we only support same port in all `ips` machine
# modify it if you use different ssh port
sshPort=${sshPort:-"22"}# A comma separated list of machine hostname or IP would be installed Master server, it
# must be a subset of configuration `ips`.
# Example for hostnames: masters="ds1,ds2", Example for IPs: masters="192.168.8.1,192.168.8.2"
masters=${masters:-"bigdata102"}# A comma separated list of machine <hostname>:<workerGroup> or <IP>:<workerGroup>.All hostname or IP must be a
# subset of configuration `ips`, And workerGroup have default value as `default`, but we recommend you declare behind the hosts
# Example for hostnames: workers="ds1:default,ds2:default,ds3:default", Example for IPs: workers="192.168.8.1:default,192.168.8.2:default,192.168.8.3:default"
workers=${workers:-"bigdata102:default,bigdata103:default,bigdata104:default"}# A comma separated list of machine hostname or IP would be installed Alert server, it
# must be a subset of configuration `ips`.
# Example for hostname: alertServer="ds3", Example for IP: alertServer="192.168.8.3"
alertServer=${alertServer:-"bigdata102"}# A comma separated list of machine hostname or IP would be installed API server, it
# must be a subset of configuration `ips`.
# Example for hostname: apiServers="ds1", Example for IP: apiServers="192.168.8.1"
apiServers=${apiServers:-"bigdata102"}# The directory to install DolphinScheduler for all machine we config above. It will automatically be created by `install.sh` script if not exists.
# Do not set this configuration same as the current path (pwd). Do not add quotes to it if you using related path.
installPath=${installPath:-"/opt/module/dolphinscheduler"}# The user to deploy DolphinScheduler for all machine we config above. For now user must create by yourself before running `install.sh`
# script. The user needs to have sudo privileges and permissions to operate hdfs. If hdfs is enabled than the root directory needs
# to be created by this user
deployUser=${deployUser:-"dolphinscheduler"}# The root of zookeeper, for now DolphinScheduler default registry server is zookeeper.
# It will delete ${zkRoot} in the zookeeper when you run install.sh, so please keep it same as registry.zookeeper.namespace in yml files.
# Similarly, if you want to modify the value, please modify registry.zookeeper.namespace in yml files as well.
zkRoot=${zkRoot:-"/dolphinscheduler"}2.3.5 修改dolphinscheduler_env.sh 文件
# applicationId auto collection related configuration, the following configurations are unnecessary if setting appId.collect=log
#export HADOOP_CLASSPATH=`hadoop classpath`:${DOLPHINSCHEDULER_HOME}/tools/libs/*
#export SPARK_DIST_CLASSPATH=$HADOOP_CLASSPATH:$SPARK_DIST_CLASS_PATH
#export HADOOP_CLIENT_OPTS="-javaagent:${DOLPHINSCHEDULER_HOME}/tools/libs/aspectjweaver-1.9.7.jar":$HADOOP_CLIENT_OPTS
#export SPARK_SUBMIT_OPTS="-javaagent:${DOLPHINSCHEDULER_HOME}/tools/libs/aspectjweaver-1.9.7.jar":$SPARK_SUBMIT_OPTS
#export FLINK_ENV_JAVA_OPTS="-javaagent:${DOLPHINSCHEDULER_HOME}/tools/libs/aspectjweaver-1.9.7.jar":$FLINK_ENV_JAVA_OPTS
# JAVA_HOME, will use it to start DolphinScheduler server
export JAVA_HOME=${JAVA_HOME:-/opt/module/jdk1.8.0_212}# Database related configuration, set database type, username and password# Tasks related configurations, need to change the configuration if you use the related tasks.
export HADOOP_HOME=${HADOOP_HOME:-/opt/module/hadoop-3.1.3}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-/opt/module/hadoop-3.1.3/etc/hadoop}
export SPARK_HOME=${SPARK_HOME:-/opt/module/spark}
#export SPARK_HOME1=${SPARK_HOME1:-/opt/soft/spark1}
#export SPARK_HOME2=${SPARK_HOME2:-/opt/soft/spark2}
#export PYTHON_HOME=${PYTHON_HOME:-/opt/soft/python}
export JAVA_HOME=${JAVA_HOME:-/opt/module/jdk1.8.0_212}
export HIVE_HOME=${HIVE_HOME:-/opt/module/hive}
#export FLINK_HOME=${FLINK_HOME:-/opt/soft/flink}
#export DATAX_HOME=${DATAX_HOME:-/opt/datax/datax}export PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$SPARK_HOME2/bin:$PYTHON_HOME/bin:$JAVA_HOME/bin:$HIVE_HOME/bin:$FLINK_HOME/bin:$DATAX_HOME/bin:$PATHexport SPRING_JACKSON_TIME_ZONE=${SPRING_JACKSON_TIME_ZONE:-UTC}
# Database related configuration, set database type, username and password
export DATABASE=${DATABASE:-mysql}
export SPRING_PROFILES_ACTIVE=${DATABASE}
# export SPRING_DATASOURCE_DRIVER_CLASS_NAME=com.mysql.jdbc.Driver
export SPRING_DATASOURCE_URL="jdbc:mysql://192.168.10.102:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&useSSL=false"
export SPRING_DATASOURCE_USERNAME="root"
export SPRING_DATASOURCE_PASSWORD="123456"
export SPRING_CACHE_TYPE=${SPRING_CACHE_TYPE:-none}export MASTER_FETCH_COMMAND_NUM=${MASTER_FETCH_COMMAND_NUM:-10}export REGISTRY_TYPE=${REGISTRY_TYPE:-zookeeper}
export REGISTRY_ZOOKEEPER_CONNECT_STRING=${REGISTRY_ZOOKEEPER_CONNECT_STRING:-bigdata102:2181,bigdata103:2181,bigdata104:2181}
export REGISTRY_ZOOKEEPER_BLOCK_UNTIL_CONNECTED=${REGISTRY_ZOOKEEPER_BLOCK_UNTIL_CONNECTED:30s}
ps: 这里有个坑:SPRING_DATASOURCE_URL参数最开始配置为:
export SPRING_DATASOURCE_URL="jdbc:mysql://192.168.10.102:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8"
在【2.3.6 初始化数据库】的时候,程序报Unsupported record version Unknown-0.0
排查后发现是:jdbc连接开启了ssl协议,所以我在上述 SPRING_DATASOURCE_URL参数的最后面,添加了&useSSL=false,此bug解决了。
2.3.6 初始化数据库
经过上述步骤,已经为 ds创建了元数据数据库,通过Shell脚本一键初始化数据库(自动建表)

2.3.7 修改application.yaml文件
需要修改以下5个文件:
master-server/conf/application.yaml
api-server/conf/application.yaml
worker-server/conf/application.yaml
alert-server/conf/application.yaml
tools/conf/application.yaml
每个文件修改的部分相同,如截图:主要是参数driver-class-name 和 参数url
datasource:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://192.168.10.102:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&useSSL=falseusername: rootpassword: 123456hikari:connection-test-query: select 1minimum-idle: 5auto-commit: truevalidation-timeout: 3000pool-name: DolphinSchedulermaximum-pool-size: 50connection-timeout: 30000idle-timeout: 600000leak-detection-threshold: 0initialization-fail-timeout: 1spring:config:activate:on-profile: mysqldatasource:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://192.168.10.102:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&useSSL=falseusername: rootpassword: 123456quartz:properties:org.quartz.jobStore.driverDelegateClass: org.quartz.impl.jdbcjobstore.StdJDBCDelegate
2.3.8 启动 DolphinScheduler
注意使用上面创建的部署用户dolphinscheduler 运行以下命令完成部署,部署后的运行日志位于logs 文件。

以master-server为例,日志存放在下列目录:

ps: 第一次部署可能出现 sh: bin/dolphinscheduler-daemon.sh: No such file or directory相关信息,此为非重要信息直接忽略即可
2.3.9 登录 DolphinScheduler
浏览器访问地址 http://localhost:12345/dolphinscheduler/ui 即可登录系统 UI。默认的用户名和密码是 admin/dolphinscheduler123
ps:这里的localhost的ip地址是api-server所在节点的地址(bin/env/install_env.sh 配置文件中指定的)


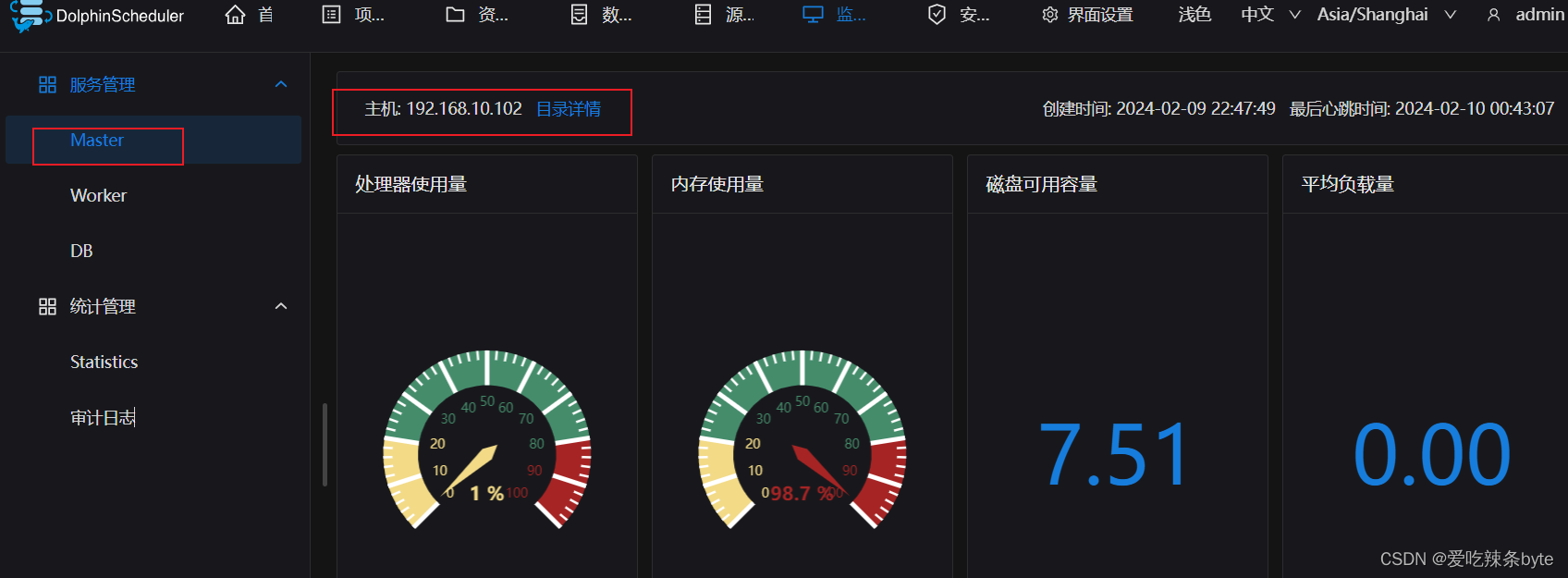
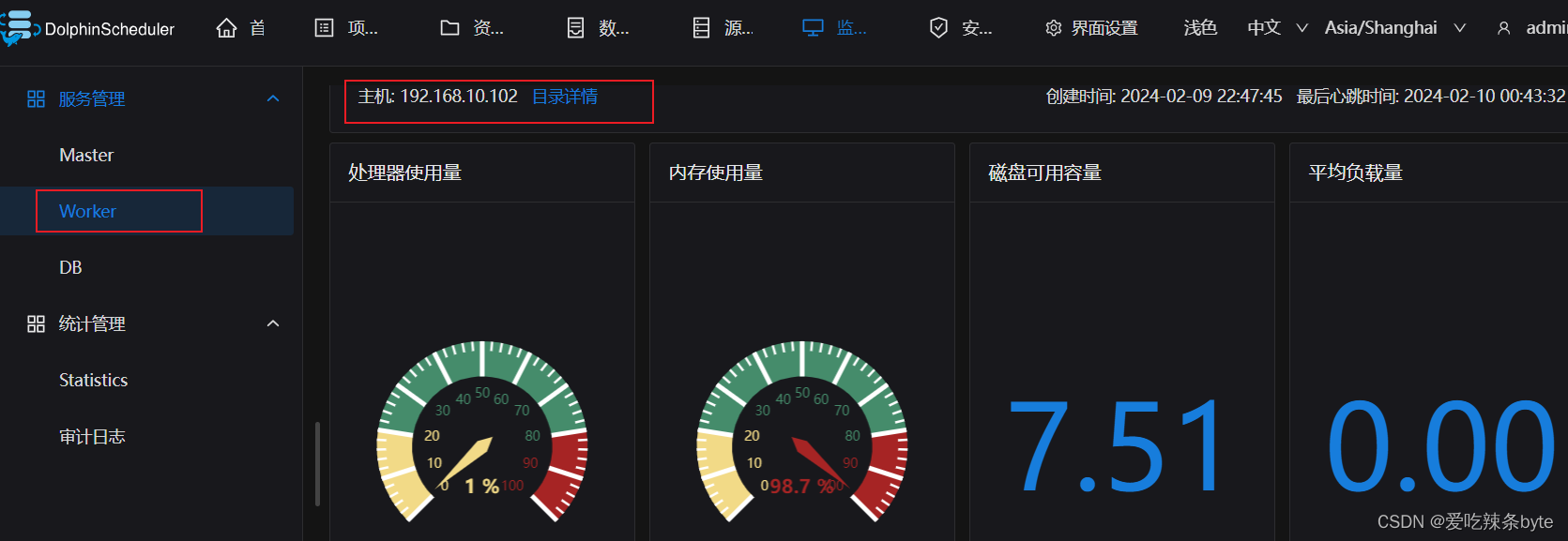
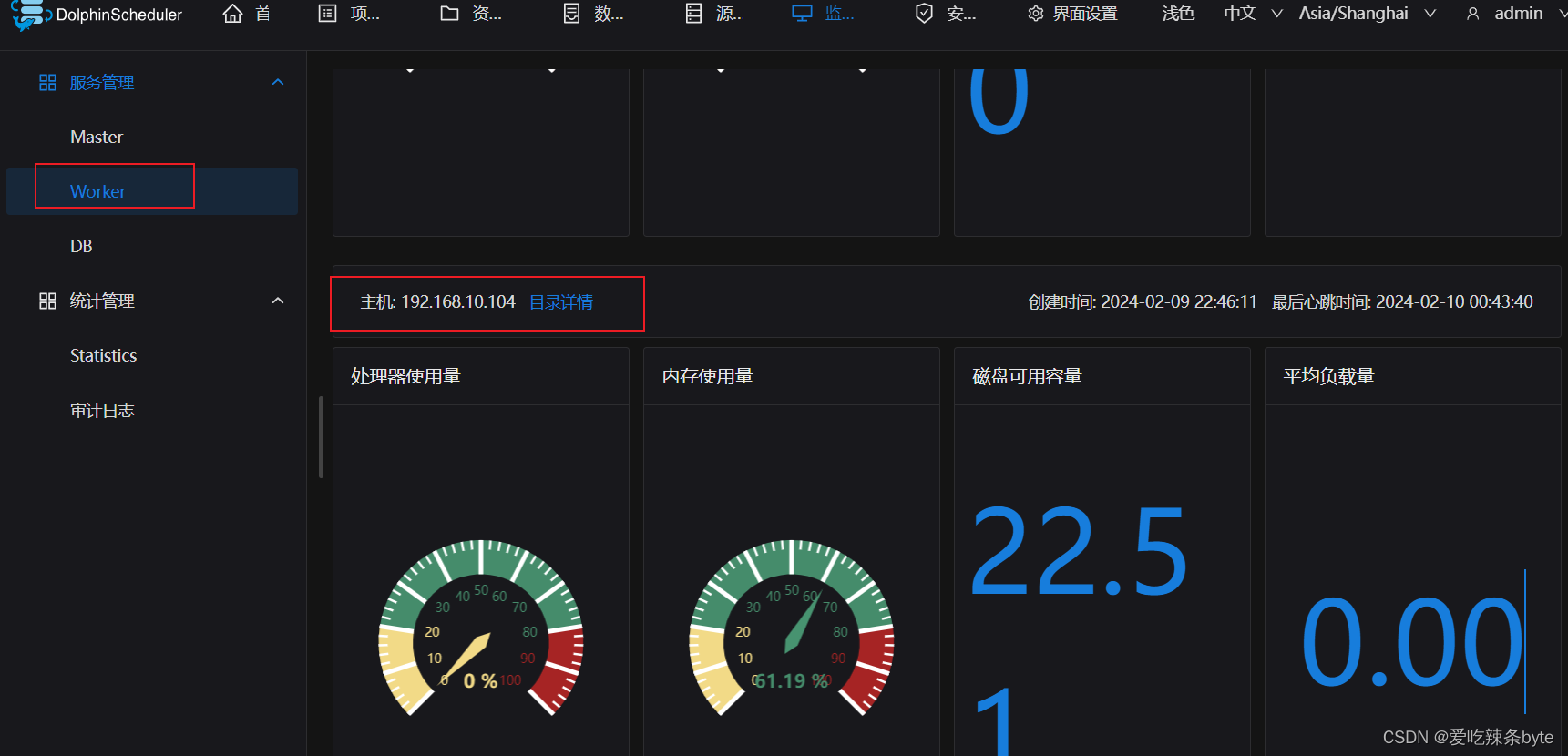
2.3.10 DolphinScheduler概览页
http://192.168.10.102:12345/dolphinscheduler/ui/home
用户/密码:admin/dolphinscheduler123

参考文档:
DolphinScheduler-3.2.0生产集群高可用搭建_dophinscheduler3.2.0 使用说明-CSDN博客
相关文章:
DolphinScheduler-3.2.0 集群搭建
目录 一、基础环境准备 1.1 组件下载地址 1.2 前置准备工作 二、 DolphinScheduler集群部署 2.1 解压安装包 2.2 配置数据库 2.3 准备 DolphinScheduler 启动环境 2.3.1 配置用户免密及权限 2.3.2 配置机器 SSH 免密登陆 2.3.3 启动 zookeeper集群 2.3.4 修改instal…...

07:Kubectl 命令详解|K8S资源对象管理|K8S集群管理(重难点)
Kubectl 命令详解|K8S资源对象管理|K8S集群管理 kubectl管理命令kubectl get 查询资源常用的排错命令kubectl run 创建容器 POD原理pod的生命周期 k8s资源对象管理资源文件使用资源文件管理对象Pod资源文件deploy资源文件 集群调度的规则扩容与缩减集群更…...
【设计模式】springboot3项目整合模板方法深入理解设计模式之模板方法(Template Method)
🎉🎉欢迎光临🎉🎉 🏅我是苏泽,一位对技术充满热情的探索者和分享者。🚀🚀 🌟特别推荐给大家我的最新专栏《Spring 狂野之旅:底层原理高级进阶》 🚀…...
Windows搭建docker+k8s
安装Docker Desktop 从官网下载,然后直接安装即可,过程很简单,一直Next就行。 有一点需要注意就是要看好对应的版本,因为后边涉及到版本的问题。 https://www.docker.com/products/docker-desktop 安装完成,双击图…...

年假作业10
一、选择题 BBDBACCCAD 二、填空题 1,4,13,40 3715 358 5 2 6 1 5 4 8 2 0 2 三、编程题 1、 #include <iostream> #include<array> #include <limits> using namespace std; int main() {array<int,10> score;array<int,10>::iterat…...

[ai笔记4] 将AI工具场景化,应用于生活和工作
欢迎来到文思源想的AI空间,这是技术老兵重学ai以及成长思考的第4篇分享内容! 转眼已经到了大年初三,但是拜年的任务还只完成了一半,准备的大部头的书,现在也就看了两本,还好AI笔记通过每天早起坚持了下来。…...

【生产实测可用】Redis修改集群弱口令
起因 漏扫redis连接发现弱口令需要修改 先连上去看看是空口令还是弱口令 redis-cli -p 6379 -h a.b.c.d info sentinel找到启动服务器的配置文件 cp -av /app/redis-7001/redis.conf /app/redis-7001/redis.conf.bak20240207 echo "requirepass 口令" >>/a…...

备战蓝桥杯---图论基础理论
图的存储: 1.邻接矩阵: 我们用map[i][j]表示i--->j的边权 2.用vector数组(在搜索专题的游戏一题中应用过) 3.用邻接表: 下面是用链表实现的基本功能的代码: #include<bits/stdc.h> using nam…...

[office] excel2003进行可视性加密的方法 #媒体#其他#知识分享
excel2003进行可视性加密的方法 Excel如何对重要文件进行可视性的加密处理呢?下面是小编带来的关于excel2003进行可视性加密的方法,希望阅读过后对你有所启发! excel2003进行可视性加密的方法: 可视性加密步骤1:打开你要加密的excel2003文档…...

算法沉淀——分治算法(leetcode真题剖析)
算法沉淀——分治算法 快排思想01.颜色分类02.排序数组03.数组中的第K个最大元素04.库存管理 III 归并思想01.排序数组02.交易逆序对的总数03.计算右侧小于当前元素的个数04.翻转对 分治算法是一种解决问题的算法范式,其核心思想是将一个大问题分解成若干个小问题&a…...

Qt 进程守护程序
Qt 进程守护程序 简单粗暴的监控,方法可整合到其他代码。 一、windows环境下 1、进程查询函数 processCount函数用于查询系统所有运行的进程中该进程运行的数量,比如启动了5个A进程,该函数查询返回的结果就为5。 windows下使用了API接口查询…...
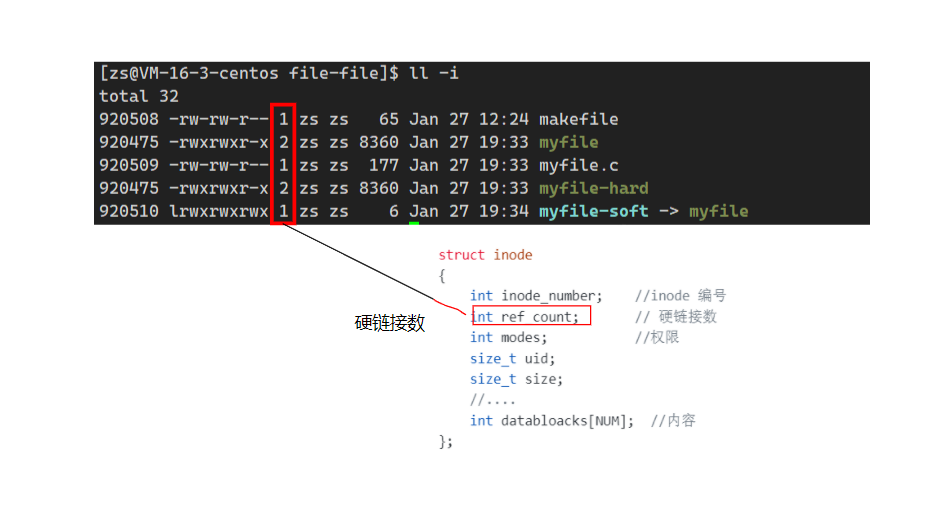
Linux_文件系统
假定外部存储设备为磁盘,文件如果没有被使用,那么它静静躺在磁盘上,如果它被使用,则文件将被加载进内存中。故此,可以将文件分为内存文件和磁盘文件。 内存文件 磁盘文件 软、硬链接 一.内存文件 1.1 c语言的文件接口 …...
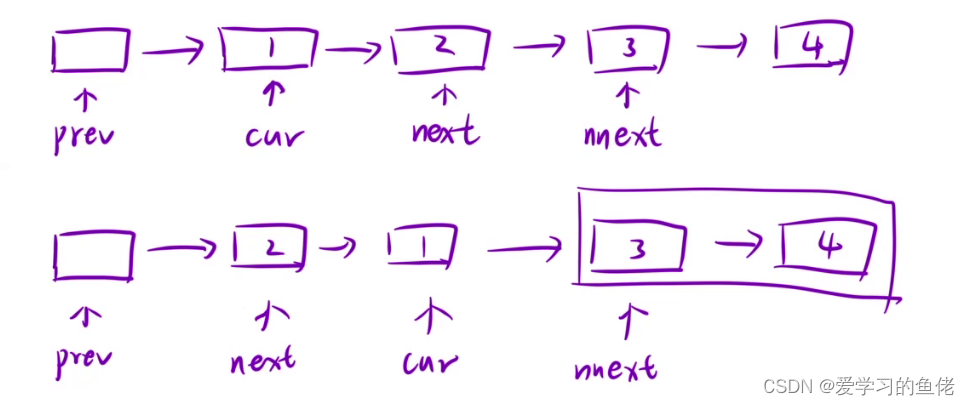
算法沉淀——链表(leetcode真题剖析)
算法沉淀——链表 01.两数相加02.两两交换链表中的节点03.重排链表04.合并 K 个升序链表05.K个一组翻转链表 链表常用技巧 1、画图->直观形象、便于理解 2、引入虚拟"头节点" 3、要学会定义辅助节点(比如双向链表的节点插入) 4、快慢双指针…...

Flink从入门到实践(一):Flink入门、Flink部署
文章目录 系列文章索引一、快速上手1、导包2、求词频demo(1)要读取的数据(2)demo1:批处理(离线处理)(3)demo2 - lambda优化:批处理(离线处理&…...

python分离字符串 2022年12月青少年电子学会等级考试 中小学生python编程等级考试二级真题答案解析
目录 python分离字符串 一、题目要求 1、编程实现 2、输入输出 二、算法分析 三、程序代码 四、程序说明 五、运行结果 六、考点分析 七、 推荐资料 1、蓝桥杯比赛 2、考级资料 3、其它资料 python分离字符串 2022年12月 python编程等级考试级编程题 一、题目要…...
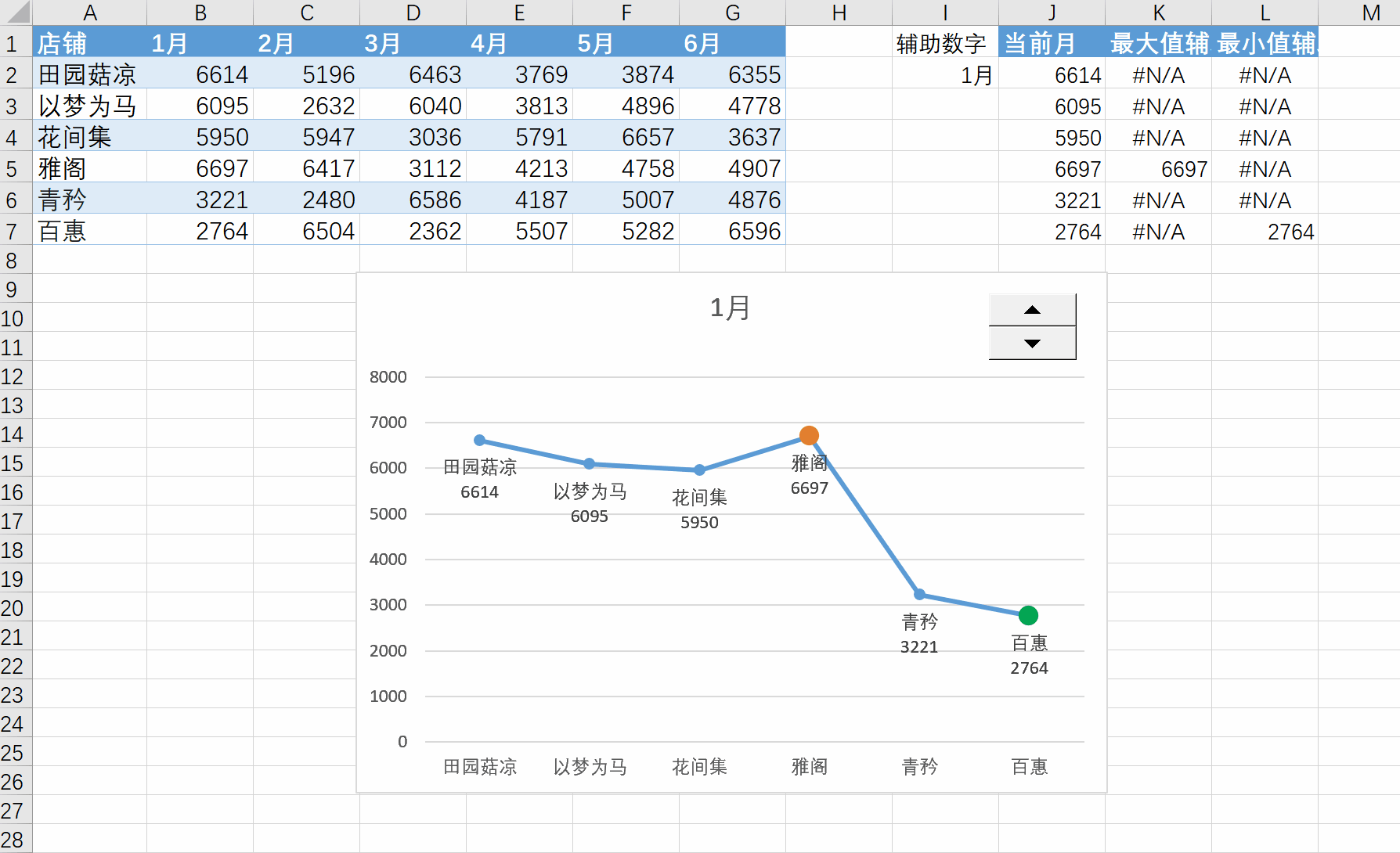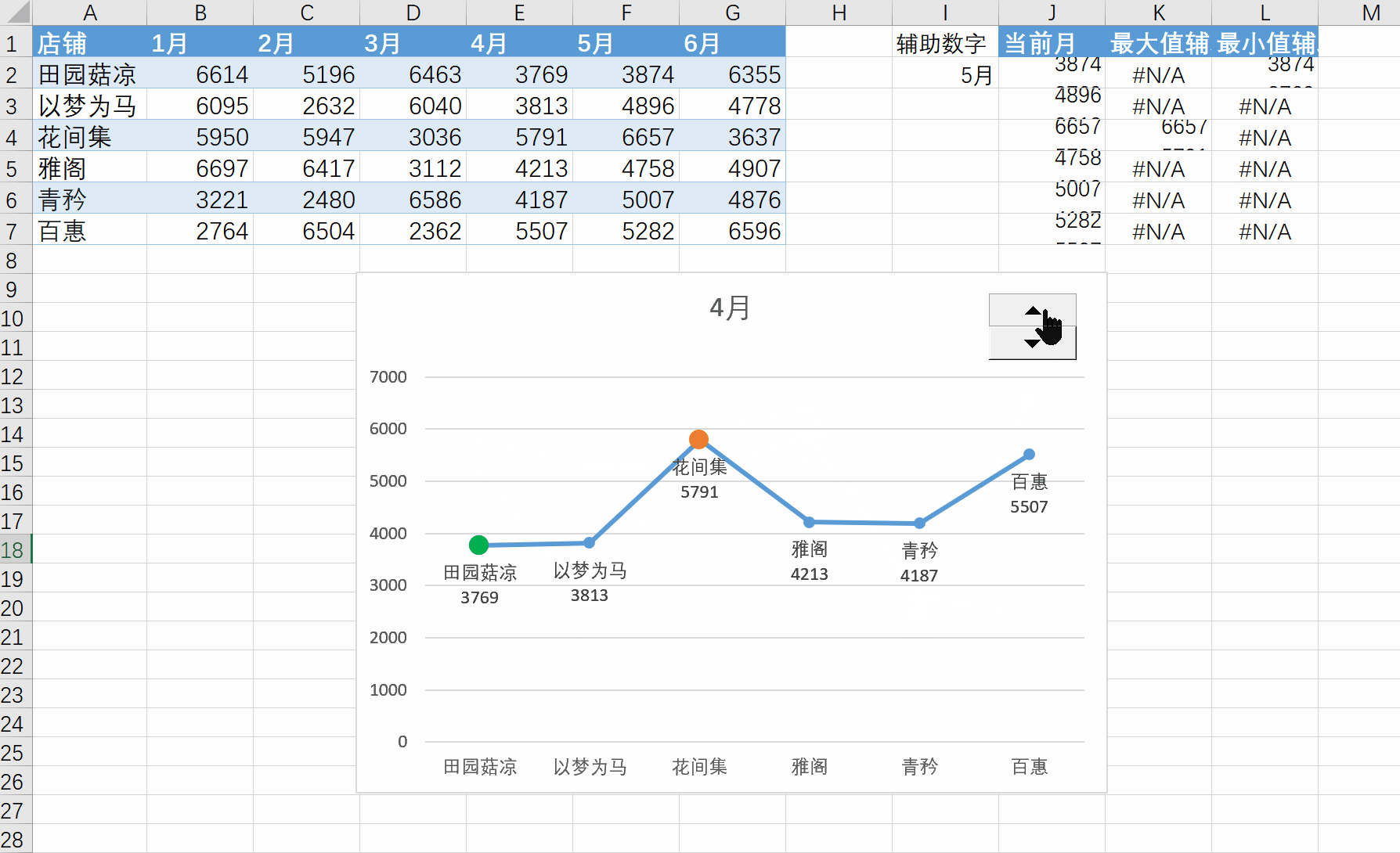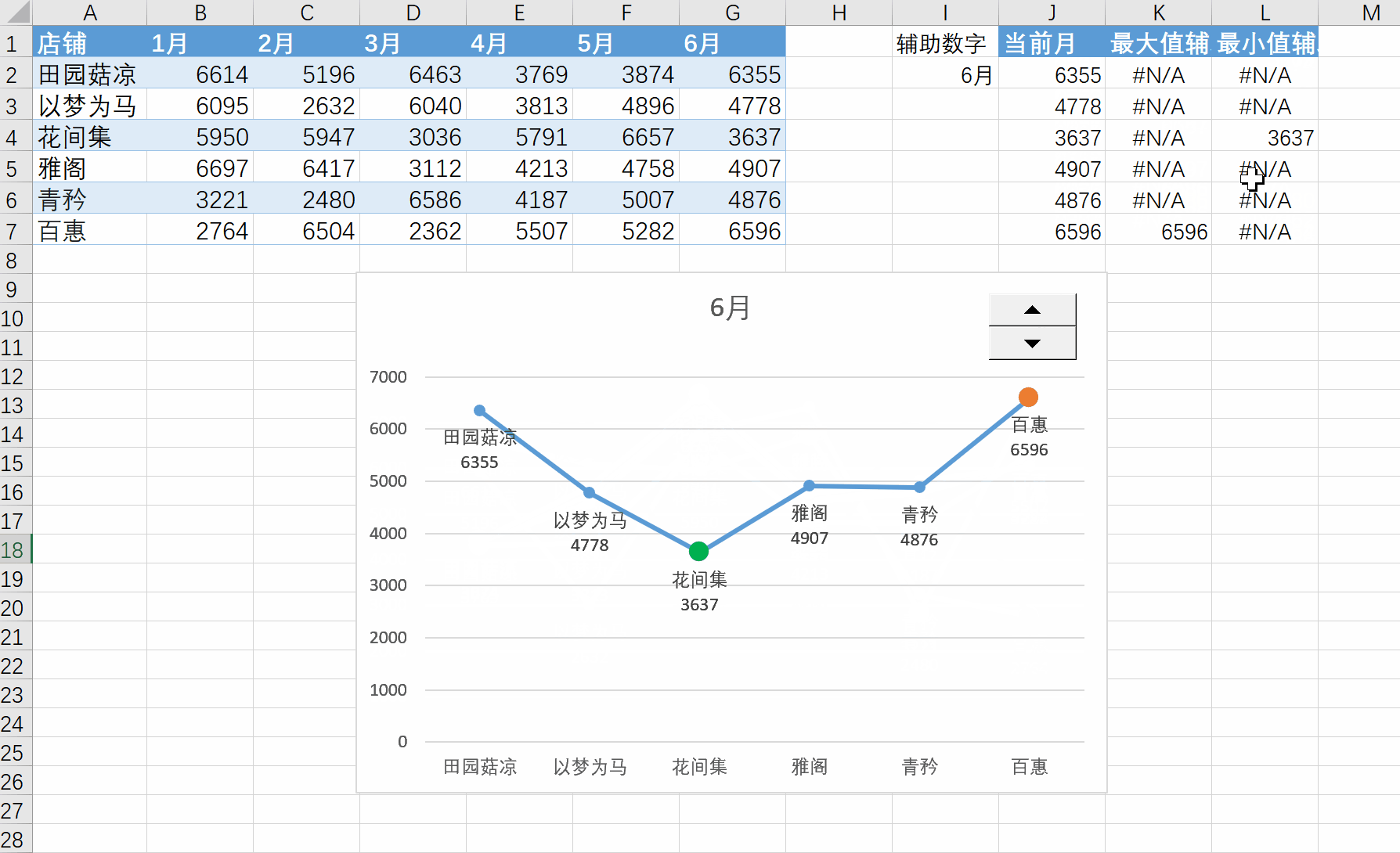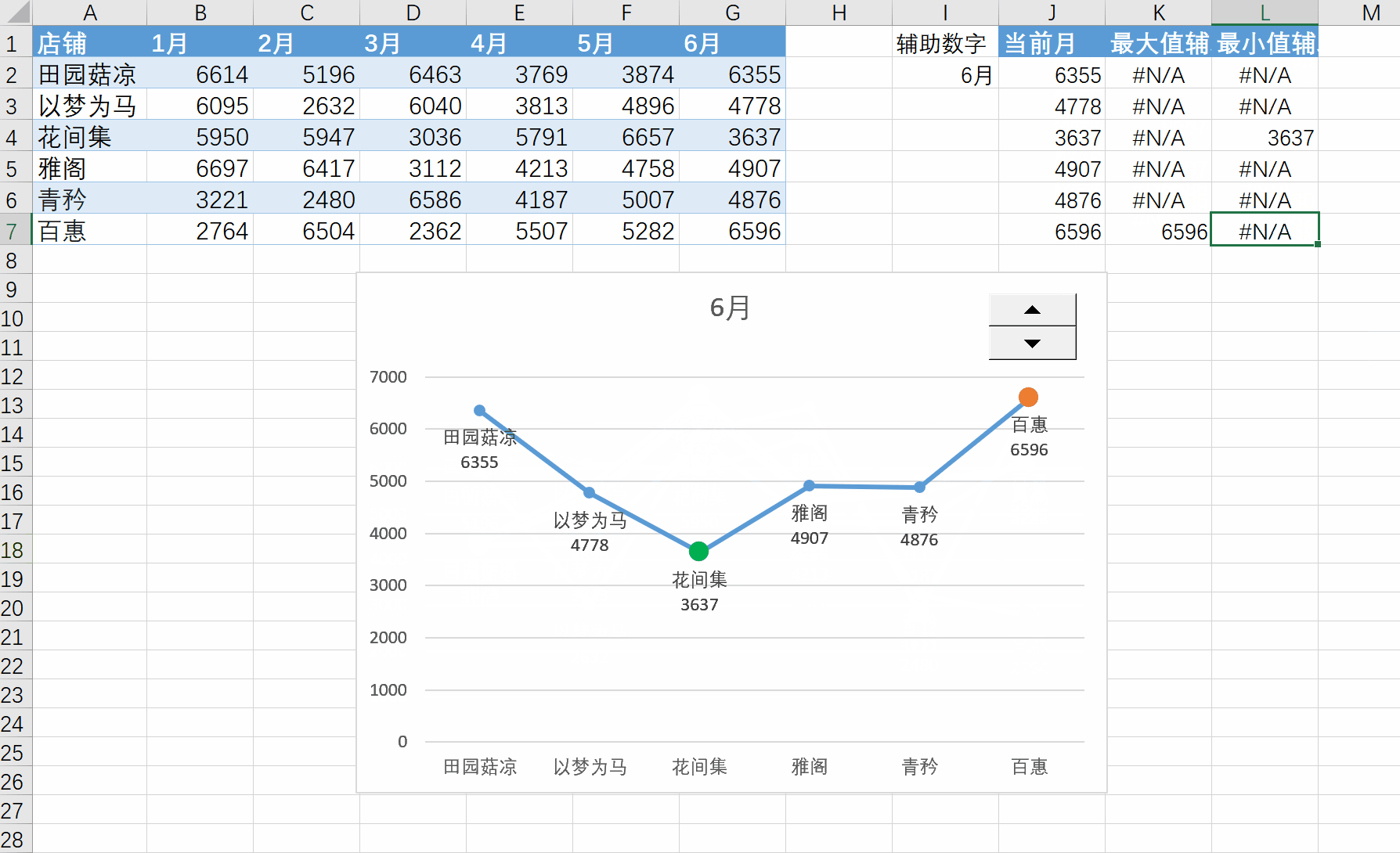
Excel练习:折线图突出最大最小值
Excel练习:折线图突出最大最小值 要点:NA值在折现图中不会被绘制,看似一条线,实际是三条线。换成0值和""都不行。 查看所有已分享Excel文件-阿里云 学习的这个视频:Excel折线图,…...

鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之MenuItem组件
鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之MenuItem组件 一、操作环境 操作系统: Windows 10 专业版、IDE:DevEco Studio 3.1、SDK:HarmonyOS 3.1 二、MenuItem组件 用来展示菜单Menu中具体的item菜单项。 子组件 无。 接口 Men…...

Mockito测试框架中的方法详解
这里写目录标题 第一章、模拟对象1.1)①mock()方法:1.2)②spy()方法: 第二章、模拟对象行为2.1)模拟方法调用①when()方法 2.2)模拟返回值②thenReturn(要返回的值)③doReturn() 2.3)模拟并替换…...

Atcoder ABC339 A - TLD
TLD 时间限制:2s 内存限制:1024MB 【原题地址】 所有图片源自Atcoder,题目译文源自脚本Atcoder Better! 点击此处跳转至原题 【问题描述】 【输入格式】 【输出格式】 【样例1】 【样例输入1】 atcoder.jp【样例输出1】 jp【样例说明…...

企业级DevOps实战
第1章 Zookeeper服务及MQ服务 Zookeeper(动物管理员)是一个开源的分布式协调服务,目前由Apache进行维护。 MQ概念 MQ(消息队列)是一种应用程序之间的通信方法,应用程序通过读写出入队列的消息࿰…...

N_m3u8DL-RE终极指南:如何高效下载加密流媒体视频
N_m3u8DL-RE终极指南:如何高效下载加密流媒体视频 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE 还…...

不只是驱动问题!深挖华硕飞行堡垒风扇控制逻辑:ATK、热键服务与系统电源管理的三角关系
华硕飞行堡垒风扇控制逻辑深度解析:ATK、热键服务与系统电源管理的协同机制 当你的华硕飞行堡垒笔记本按下FNF5组合键却毫无反应时,多数教程会告诉你"重装驱动就能解决"。但作为技术爱好者,我们更关心的是:为什么驱动安…...

终极指南:3步实现Switch手柄在Windows PC上的完美XInput兼容
终极指南:3步实现Switch手柄在Windows PC上的完美XInput兼容 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcod…...

3步掌握StreamCap:开源直播录制工具的终极使用指南
3步掌握StreamCap:开源直播录制工具的终极使用指南 【免费下载链接】StreamCap Multi-Platform Live Stream Automatic Recording Tool | 多平台直播流自动录制客户端 基于FFmpeg 支持监控/定时/转码 项目地址: https://gitcode.com/gh_mirrors/st/StreamCap …...

紧急停止与异常停机:天勤策略里的断线保护与人工兜底
前言 网络闪断、进程被 kill、策略异常未捕获,都可能让持仓暴露在无人管理状态。天勤文档里有紧急停止相关能力(见 advanced/emergency_stop.rst),我把它和自建「停机即平仓/撤单」脚本配合使用。下面写工程清单,不替代…...

团队项目空间、角色继承链、资产水印策略——Midjourney新功能三大硬核模块详解,错过将丧失企业级部署资格
更多请点击: https://codechina.net 第一章:团队项目空间、角色继承链、资产水印策略——Midjourney新功能三大硬核模块详解,错过将丧失企业级部署资格 Midjourney v6.3 企业版正式引入三大底层架构级能力:团队项目空间ÿ…...
)
从Simulink模型到S32K3xx芯片:手把手教你玩转NXP官方MBD工具包(v1.4实战)
从Simulink模型到S32K3xx芯片:手把手教你玩转NXP官方MBD工具包(v1.4实战) 在汽车电子开发领域,时间就是竞争力。当传统手写代码遇上复杂的汽车MCU外设配置,工程师们常常陷入寄存器手册的海洋。而基于模型的设计&#x…...

告别‘偏科’模型:用CAST双流架构搞定视频动作识别,兼顾时空理解
时空双流协同:CAST架构如何重塑视频动作识别的平衡之道 视频动作识别正面临一个关键瓶颈——现有模型往往在时空理解上"偏科"。就像人类大脑需要左右半球协同工作才能完整理解世界一样,理想的视频理解模型也需要同时具备敏锐的空间感知和精准的…...

HTML5语义化与现代Web标准
HTML5语义化与现代Web标准 1. 技术分析 1.1 HTML5概述 HTML5是现代Web的基础: HTML5特性语义化标签: header, footer, article多媒体支持: video, audio表单增强: date, email, number离线存储: localStorage, sessionStorage核心改进:语义化文档结构原生多媒体支持…...

COMTool图表插件使用教程:实时数据可视化与曲线绘制完整指南
COMTool图表插件使用教程:实时数据可视化与曲线绘制完整指南 【免费下载链接】COMTool Cross platform communicate assistant(Serial/network/terminal tool)( 跨平台 串口调试助手 网络调试助手 终端工具 linux windows mac Raspberry Pi )…...