Flink从入门到实践(一):Flink入门、Flink部署
文章目录
- 系列文章索引
- 一、快速上手
- 1、导包
- 2、求词频demo
- (1)要读取的数据
- (2)demo1:批处理(离线处理)
- (3)demo2 - lambda优化:批处理(离线处理)
- (4)demo3:流处理(实时处理)
- (5)总结:实时vs离线
- (6)demo4:批流一体
- (7)对接Socket
- 二、Flink部署
- 1、Flink架构
- 2、Standalone部署
- 3、自运行flink-web
- 4、通过参数传递
- 5、通过webui提交job
- 6、停止作业
- 7、常用命令
- 8、集群
- 参考资料
系列文章索引
Flink从入门到实践(一):Flink入门、Flink部署
Flink从入门到实践(二):Flink DataStream API
Flink从入门到实践(三):数据实时采集 - Flink MySQL CDC
一、快速上手
1、导包
<!-- fink 相关依赖 -->
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>1.18.0</version>
</dependency>
2、求词频demo
注意!自Flink 1.18以来,所有Flink DataSet api都已弃用,并将在未来的Flink主版本中删除。您仍然可以在DataSet中构建应用程序,但是您应该转向DataStream和/或Table API。
(1)要读取的数据
定义data内容:
pk,pk,pk
ruoze,ruoze
hello
(2)demo1:批处理(离线处理)
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;/*** 使用Flink进行批处理,并统计wc*** 结果:* (bye,2)* (hello,3)* (hi,1)*/
public class BatchWordCountApp {public static void main(String[] args) throws Exception {// step0: Spark中有上下文,Flink中也有上下文,MR中也有ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// step1: 读取文件内容 ==> 一行一行的字符串而已DataSource<String> source = env.readTextFile("data/wc.data");// step2: 每一行的内容按照指定的分隔符进行拆分 1:Nsource.flatMap(new FlatMapFunction<String, String>() {/**** @param value 读取到的每一行数据* @param out 输出的集合*/@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {// 使用,进行分割String[] splits = value.split(",");for(String split : splits) {out.collect(split.toLowerCase().trim());}}}).map(new MapFunction<String, Tuple2<String,Integer>>() {/**** @param value 每一个元素 (hello, 1)(hello, 1)(hello, 1)*/@Overridepublic Tuple2<String, Integer> map(String value) throws Exception {return Tuple2.of(value, 1);}}).groupBy(0) // step4: 按照单词进行分组 groupBy是离线的api,传下标.sum(1) // ==> 求词频 sum,传下标.print(); // 打印}
}(3)demo2 - lambda优化:批处理(离线处理)
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;/*** lambda表达式优化*/
public class BatchWordCountAppV2 {public static void main(String[] args) throws Exception {ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();DataSource<String> source = env.readTextFile("data/wc.data");/*** lambda语法: (参数1,参数2,参数3...) -> {函数体}*/
// source.map(String::toUpperCase).print();// 使用了Java泛型,由于泛型擦除的原因,需要显示的声明类型信息source.flatMap((String value, Collector<Tuple2<String,Integer>> out) -> {String[] splits = value.split(",");for(String split : splits) {out.collect(Tuple2.of(split.trim(), 1));}}).returns(Types.TUPLE(Types.STRING, Types.INT)).groupBy(0).sum(1).print();}
}
(4)demo3:流处理(实时处理)
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;/*** 流式处理* 结果:* 8> (hi,1)* 6> (hello,1)* 5> (bye,1)* 6> (hello,2)* 6> (hello,3)* 5> (bye,2)*/
public class StreamWCApp {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> source = env.readTextFile("data/wc.data");source.flatMap((String value, Collector<Tuple2<String,Integer>> out) -> {String[] splits = value.split(",");for(String split : splits) {out.collect(Tuple2.of(split.trim(), 1));}}).returns(Types.TUPLE(Types.STRING, Types.INT)).keyBy(x -> x.f0) // 这种写法一定要掌握!流式的并没有groupBy,而是keyBy!根据第一个值进行sum.sum(1).print();// 需要手动开启env.execute("作业名字");}
}(5)总结:实时vs离线
离线:结果是一次性出来的。
实时:来一个数据处理一次,数据是带状态的。
(6)demo4:批流一体
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;/*** 采用批流一体的方式进行处理*/
public class FlinkWordCountApp {public static void main(String[] args) throws Exception {// 统一使用StreamExecutionEnvironment这个执行上下文环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); // 选择处理方式 批/流/自动DataStreamSource<String> source = env.readTextFile("data/wc.data");source.flatMap((String value, Collector<Tuple2<String,Integer>> out) -> {String[] splits = value.split(",");for(String split : splits) {out.collect(Tuple2.of(split.trim(), 1));}}).returns(Types.TUPLE(Types.STRING, Types.INT)).keyBy(x -> x.f0) // 这种写法一定要掌握.sum(1).print();// 执行env.execute("作业名字");}
}(7)对接Socket
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;/*** 使用Flink对接Socket的数据并进行词频统计** 大数据处理的三段论: 输入 处理 输出**/
public class FlinkSocket {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();/*** 数据源:可以通过多种不同的数据源接入数据:socket kafka text** 官网上描述的是 env.addSource(...)** socket的方式对应的并行度是1,因为它来自于SourceFunction的实现*/DataStreamSource<String> source = env.socketTextStream("localhost", 9527);System.out.println(source.getParallelism());// 处理source.flatMap((String value, Collector<Tuple2<String,Integer>> out) -> {String[] splits = value.split(",");for(String split : splits) {out.collect(Tuple2.of(split.trim(), 1));}}).returns(Types.TUPLE(Types.STRING, Types.INT)).keyBy(x -> x.f0) // 这种写法一定要掌握.sum(1)// 数据输出.print(); // 输出到外部系统中去env.execute("作业名字");}
}二、Flink部署
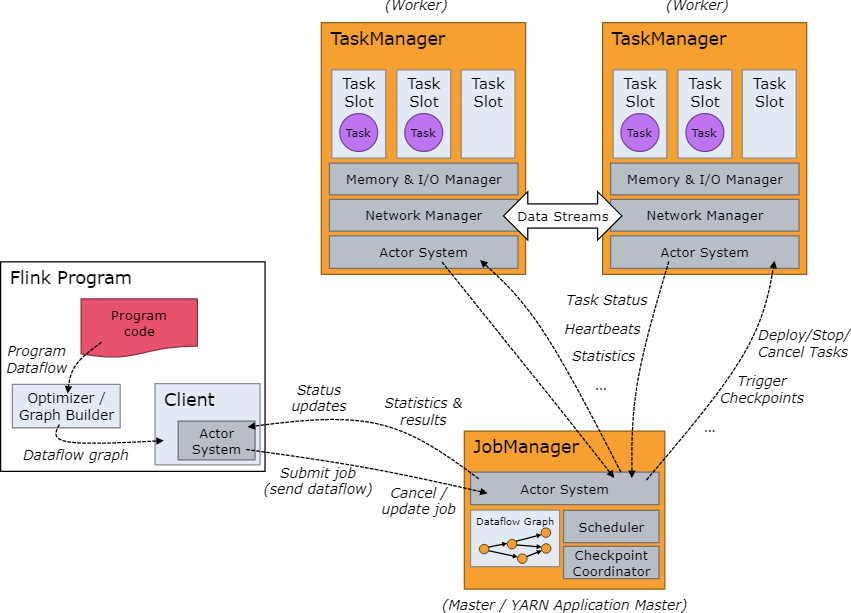
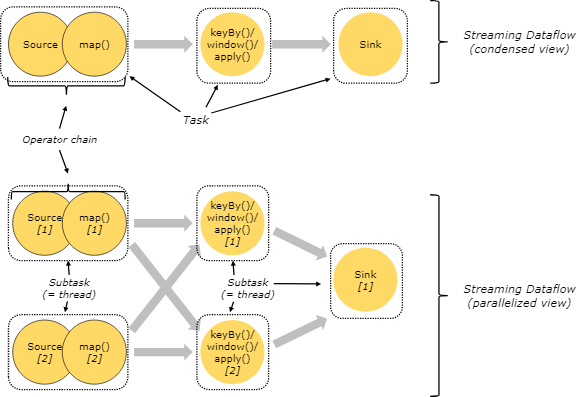
1、Flink架构
https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/concepts/flink-architecture/
Flink是一个分布式的带有状态管理的计算框架,可以运行在常用/常见的集群资源管理器上(YARN、K8S)。
一个JobManager(协调/分配),一个或多个TaskManager(工作)。
2、Standalone部署
按照官网下载执行即可:
https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/try-flink/local_installation/
可以根据官网来安装,需要下载、解压、安装。
也可以使用docker安装。
启动之后,localhost:8081就可以访问管控台了。
3、自运行flink-web
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-runtime-web</artifactId><version>1.18.0</version>
</dependency>
Configuration configuration = new Configuration();
configuration.setInteger("rest.port", 8082); // 指定web端口,开启webUI,不写的话默认8081
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(configuration);
// 新版本可以直接使用getExecutionEnvironment(conf)
以上亲测并不好使……具体原因未知,设置为flink1.16版本或许就好用了。
4、通过参数传递
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 通过参数传递进来Flink引用程序所需要的参数,flink自带的工具类
ParameterTool tool = ParameterTool.fromArgs(args);
String host = tool.get("host");
int port = tool.getInt("port");DataStreamSource<String> source = env.socketTextStream(host, port);
System.out.println(source.getParallelism());
可以通过命令行参数:–host localhost --port 8765
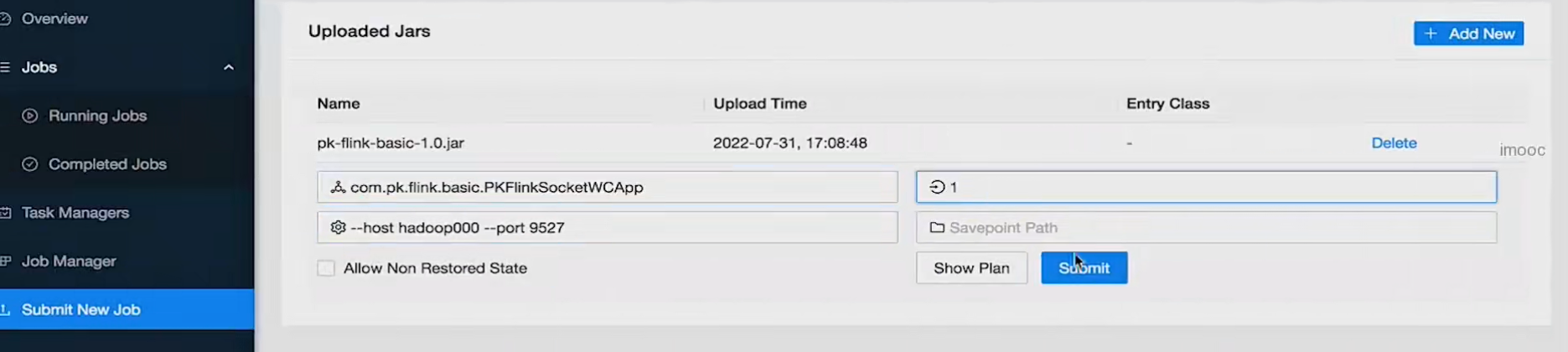
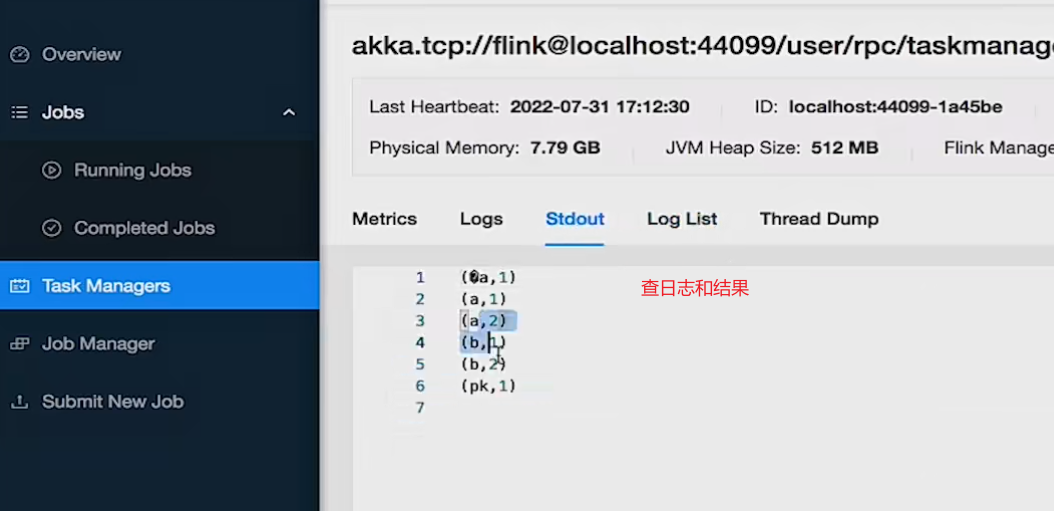
5、通过webui提交job
6、停止作业

7、常用命令
# 查看作业列表
flink list -a # 所有
flink list -r # 正在运行的
# 停止作业
flink cancel <jobid># 提交job
# -c,--class <classname> 指定main方法
# -C,--classpath <url> 指定classpath
# -p,--parallelism <paralle> 指定并行度
flink run -c com.demo.FlinkDemo FlinkTest.jar
8、集群
https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/concepts/flink-architecture/#flink-application-execution
https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/deployment/overview/
单机部署Session Mode和Application Mode:
https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/deployment/resource-providers/standalone/overview/
k8s:
https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/deployment/resource-providers/native_kubernetes/
YARN:
https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/deployment/resource-providers/yarn/
参考资料
https://flink.apache.org/
https://nightlies.apache.org/flink/flink-docs-stable/
相关文章:
Flink从入门到实践(一):Flink入门、Flink部署
文章目录 系列文章索引一、快速上手1、导包2、求词频demo(1)要读取的数据(2)demo1:批处理(离线处理)(3)demo2 - lambda优化:批处理(离线处理&…...

python分离字符串 2022年12月青少年电子学会等级考试 中小学生python编程等级考试二级真题答案解析
目录 python分离字符串 一、题目要求 1、编程实现 2、输入输出 二、算法分析 三、程序代码 四、程序说明 五、运行结果 六、考点分析 七、 推荐资料 1、蓝桥杯比赛 2、考级资料 3、其它资料 python分离字符串 2022年12月 python编程等级考试级编程题 一、题目要…...
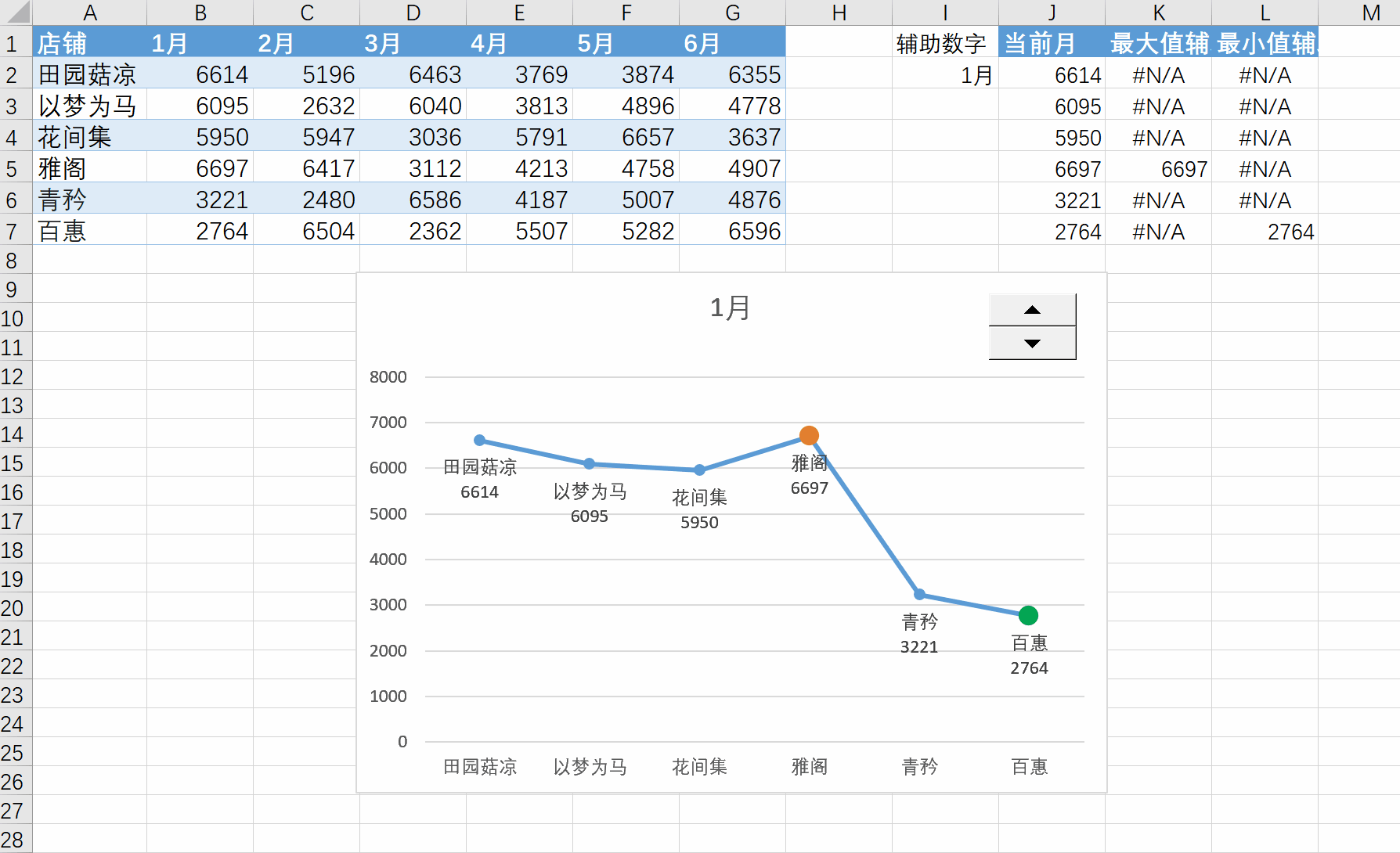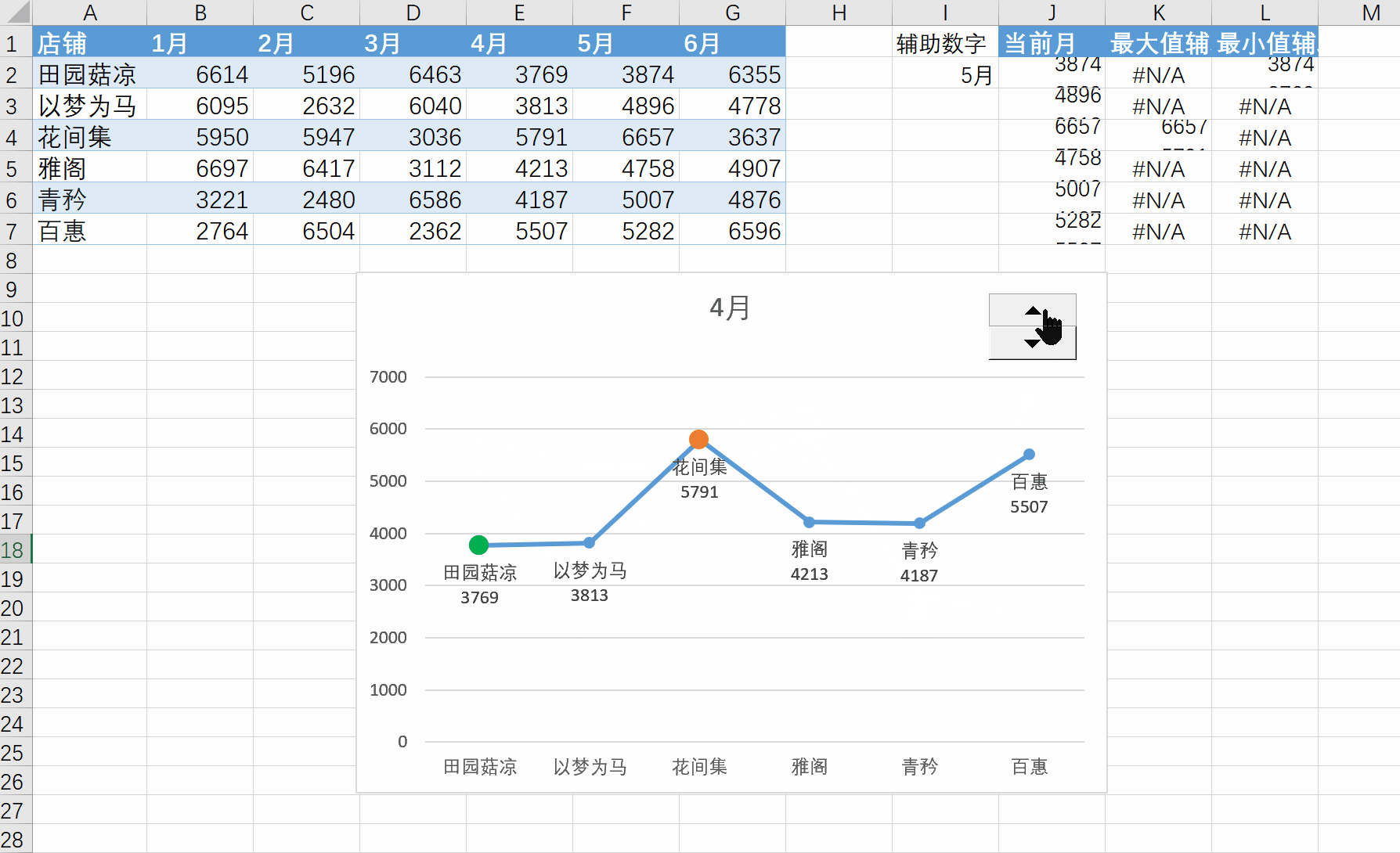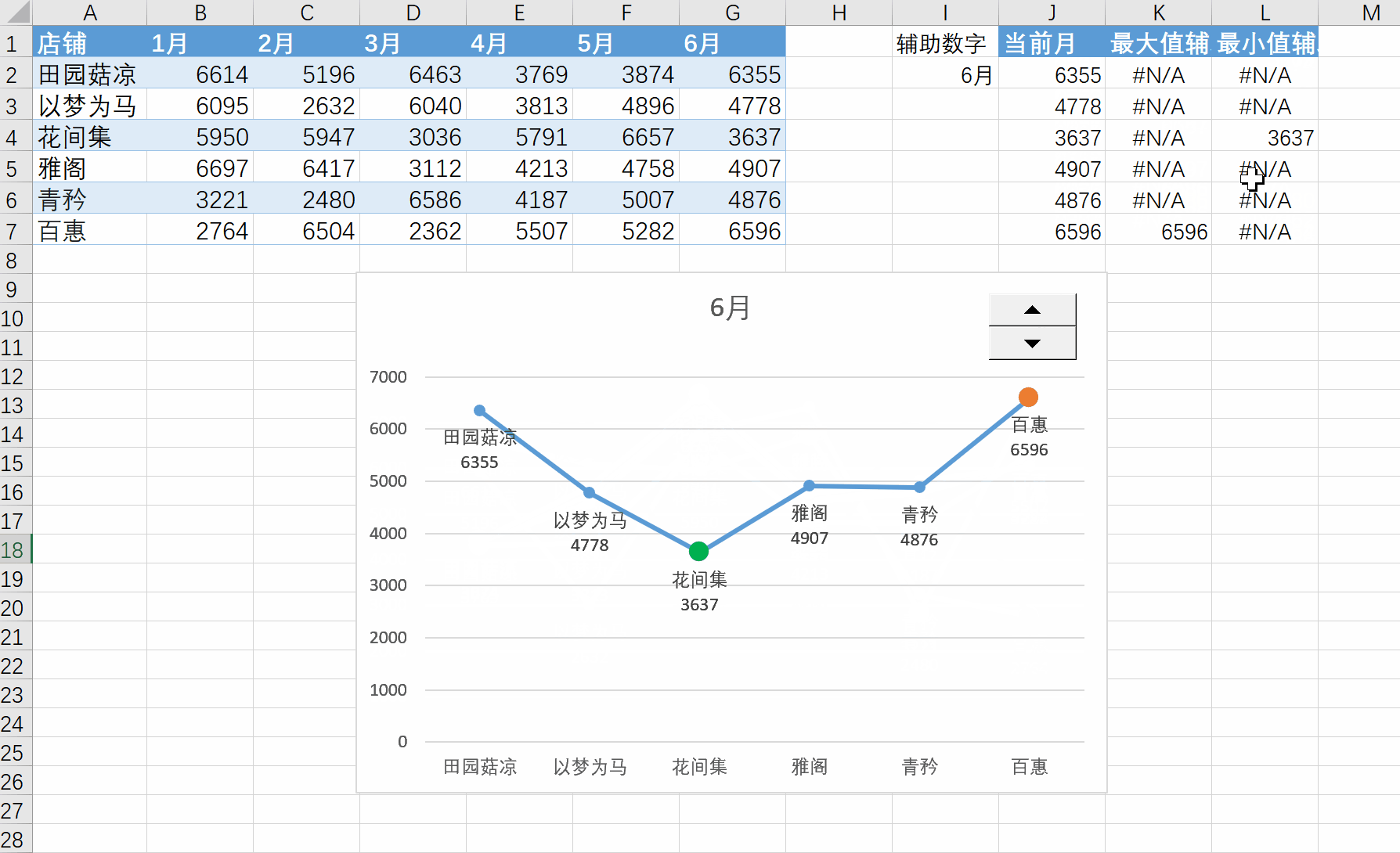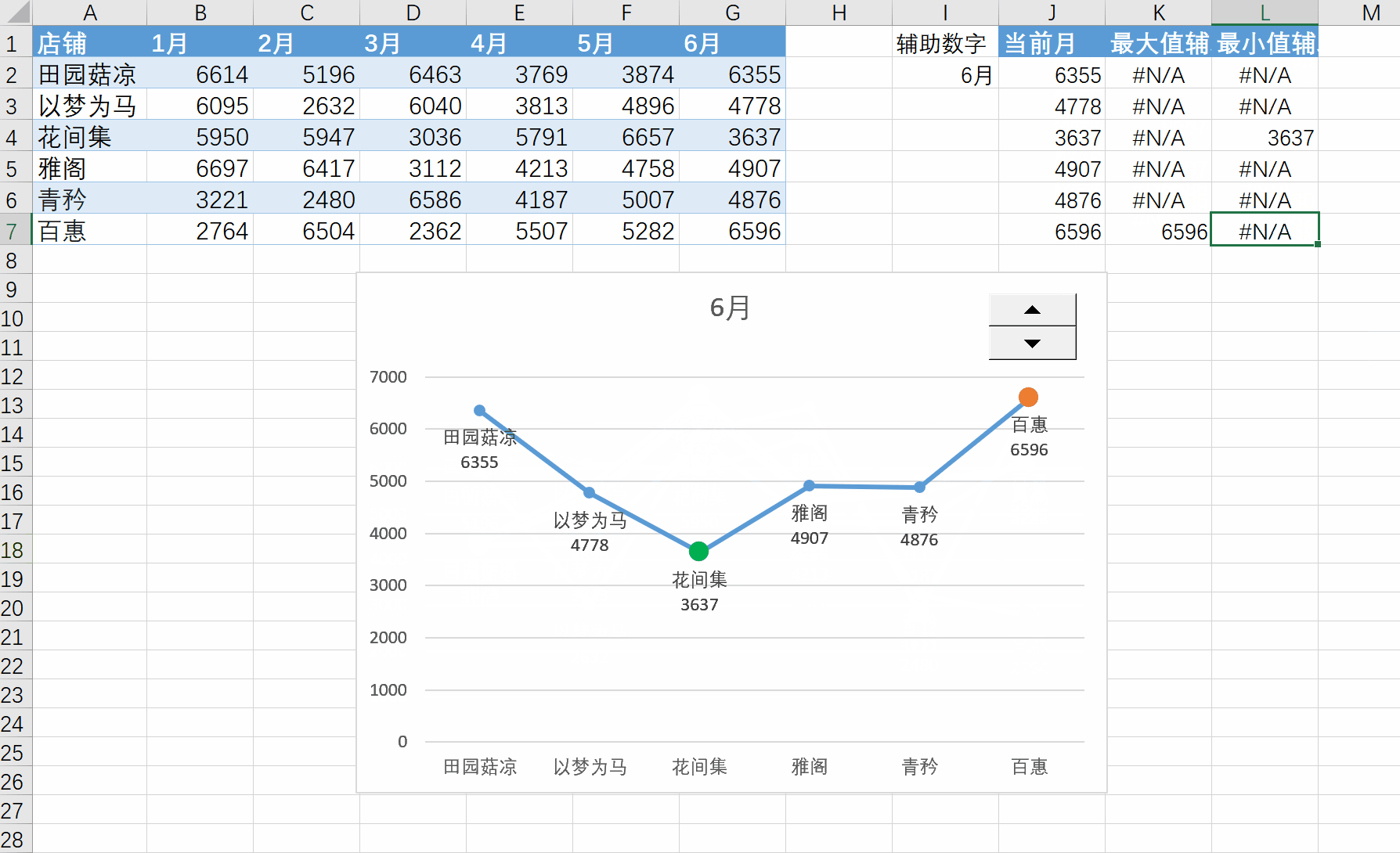
Excel练习:折线图突出最大最小值
Excel练习:折线图突出最大最小值 要点:NA值在折现图中不会被绘制,看似一条线,实际是三条线。换成0值和""都不行。 查看所有已分享Excel文件-阿里云 学习的这个视频:Excel折线图,…...

鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之MenuItem组件
鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之MenuItem组件 一、操作环境 操作系统: Windows 10 专业版、IDE:DevEco Studio 3.1、SDK:HarmonyOS 3.1 二、MenuItem组件 用来展示菜单Menu中具体的item菜单项。 子组件 无。 接口 Men…...

Mockito测试框架中的方法详解
这里写目录标题 第一章、模拟对象1.1)①mock()方法:1.2)②spy()方法: 第二章、模拟对象行为2.1)模拟方法调用①when()方法 2.2)模拟返回值②thenReturn(要返回的值)③doReturn() 2.3)模拟并替换…...

Atcoder ABC339 A - TLD
TLD 时间限制:2s 内存限制:1024MB 【原题地址】 所有图片源自Atcoder,题目译文源自脚本Atcoder Better! 点击此处跳转至原题 【问题描述】 【输入格式】 【输出格式】 【样例1】 【样例输入1】 atcoder.jp【样例输出1】 jp【样例说明…...

企业级DevOps实战
第1章 Zookeeper服务及MQ服务 Zookeeper(动物管理员)是一个开源的分布式协调服务,目前由Apache进行维护。 MQ概念 MQ(消息队列)是一种应用程序之间的通信方法,应用程序通过读写出入队列的消息࿰…...

C++中的new和delete
1.new和delete的语法 我们知道C语言的内存管理方式是malloc、calloc、realloc和free,而我们的C中除了可以使用这些方式之外还可以选择使用new和delete来进行内存管理。 new和delete的主要语法如下 从上面的代码我们只能知道new要比malloc好写一些,但是其…...

rtt设备io框架面向对象学习-dac设备
目录 1.dac设备基类2.dac设备基类的子类3.初始化/构造流程3.1设备驱动层3.2 设备驱动框架层3.3 设备io管理层 4.总结5.使用 1.dac设备基类 此层处于设备驱动框架层。也是抽象类。 在/ components / drivers / include / drivers 下的dac.h定义了如下dac设备基类 struct rt_da…...
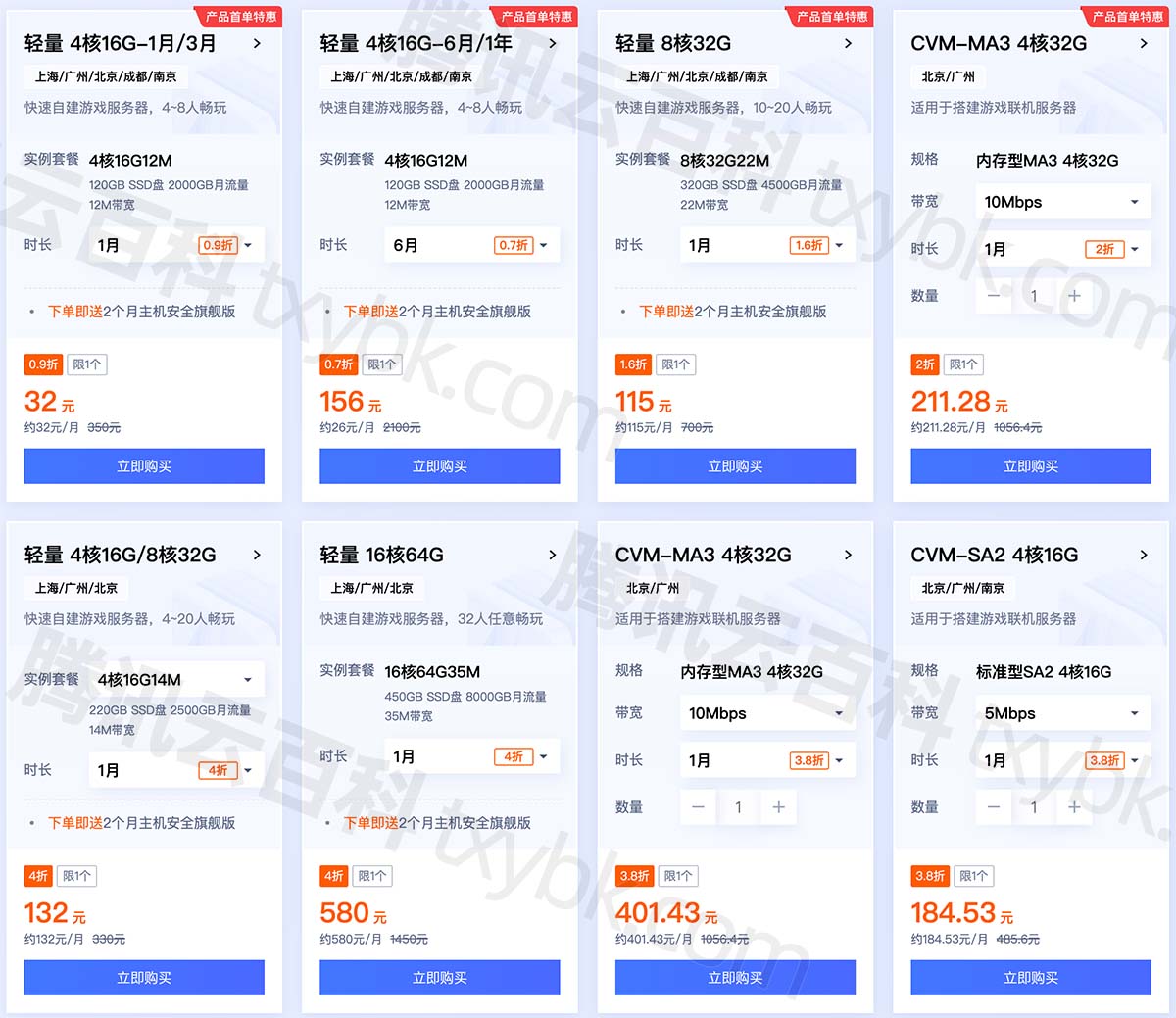
腾讯云幻兽帕鲁服务器配置怎么选择合适?
腾讯云幻兽帕鲁服务器配置怎么选?根据玩家数量选择CPU内存配置,4到8人选择4核16G、10到20人玩家选择8核32G、2到4人选择4核8G、32人选择16核64G配置,腾讯云百科txybk.com来详细说下腾讯云幻兽帕鲁专用服务器CPU内存带宽配置选择方法ÿ…...

796. 子矩阵的和
Problem: 796. 子矩阵的和 文章目录 思路解题方法复杂度Code 思路 这是一个二维前缀和的问题。二维前缀和的主要思想是预处理出一个二维数组,使得每个位置(i, j)上的值表示原数组中从(0, 0)到(i, j)形成的子矩阵中所有元素的和。这样,对于任意的子矩阵(x…...

如何在 Python 中处理 Unicode
介绍 Unicode 是世界上大多数计算机的标准字符编码。它确保文本(包括字母、符号、表情符号,甚至控制字符)在不同设备、平台和数字文档中显示一致,无论使用的操作系统或软件是什么。它是互联网和计算机行业的重要组成部分…...

CSDN文章导出PDF整理状况一览
最近CSDN有了导出文章PDF功能,导出的PDF还可以查询, 因此,把文章导出PDF,备份一下自己的重要资料。 目前整理内容如下 No.文章标题整理时间整理之后 文章更新Size (M)10001_本地电脑-开发相关软件保持位…...
)
jmeter-05变量(用户定义变量,用户参数,csv文档参数化)
文章目录 一、jmeter有三种变量二、用户定义变量(这个更多的可以理解为全局变量)1、设置2、引用三、用户参数(可以理解为局部变量)1、设置2、引用3、用户参数化要配合线程组的线程数使用4、结果五、csv文档参数1、创建csv文件2、设置2、引用csv文件可以配合线程组的线程数,…...

CSS之水平垂直居中
如何实现一个div的水平垂直居中 <div class"content-wrapper"><div class"content">content</div></div>flex布局 .content-wrapper {width: 400px;height: 400px;background-color: lightskyblue;display: flex;justify-content:…...

2.8日学习打卡----初学RabbitMQ(三)
2.8日学习打卡 一.springboot整合RabbitMQ 之前我们使用原生JAVA操作RabbitMQ较为繁琐,接下来我们使用 SpringBoot整合RabbitMQ,简化代码编写 创建SpringBoot项目,引入RabbitMQ起步依赖 <!-- RabbitMQ起步依赖 --> <dependency&g…...

Unity学习笔记(零基础到就业)|Chapter02:C#基础
Unity学习笔记(零基础到就业)|Chapter02:C#基础 前言一、复杂数据(变量)类型part01:枚举数组1.特点2.枚举(1)基本概念(2)申明枚举变量(3ÿ…...

容器化的基础概念:不可变基础设施解释:将服务器视为乐高积木,而非橡皮泥。
不可变基础设施解释:将服务器视为乐高积木,而非橡皮泥。 想象一下用乐高积木代替橡皮泥进行搭建。使用橡皮泥时,您可以直接塑形和改变它。而使用乐高积木,您需要逐个零件搭建特定结构,并在需要时整体替换它们。这就是…...
智胜未来,新时代IT技术人风口攻略-第二版(弃稿)
文章目录 抛砖引玉 鸿蒙生态小科普焦虑之下 理想要落到实处校园鼎力 鸿蒙发展不可挡培训入场 机构急于吃红利企业布局 鸿蒙应用规划动智胜未来 技术人风口来临 鸿蒙已经成为行业的焦点,未来的发展潜力无限。作为一名程序员兼UP主,我非常荣幸地接受了邀请…...
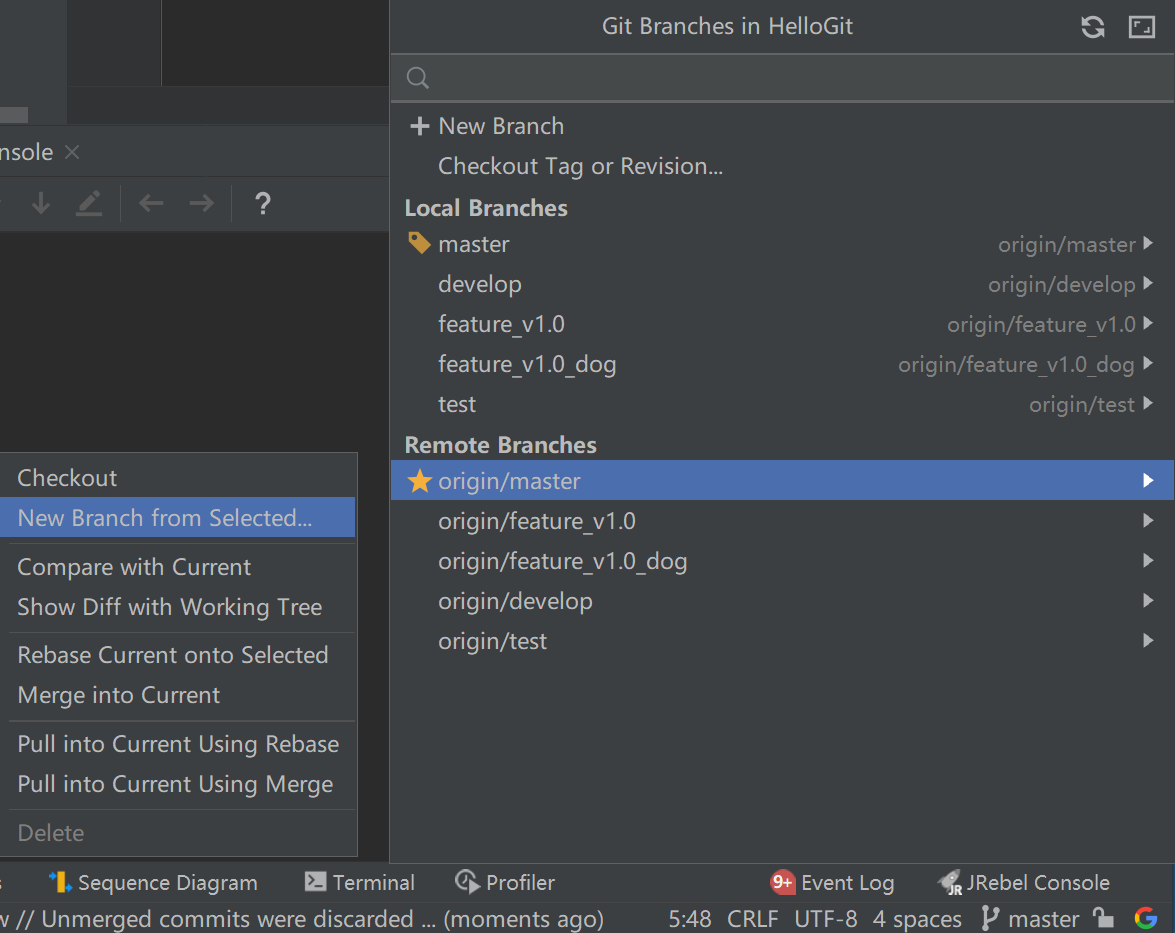
Git分支和迭代流程
Git分支 feature分支:功能分支 dev分支:开发分支 test分支:测试分支 master分支:生产环境分支 hotfix分支:bug修复分支。从master拉取,修复并测试完成merge回master和dev。 某些团队可能还会有 reale…...

4月18日腾讯云「龙虾公开课」落地合肥!免费线下AI实战课,还有限定周边等你拿
合肥线下:免费AI实战课的吸引力4月18日,腾讯云开发者社区「龙虾公开课」将在合肥高新区中安创谷科技园二期H1栋国际会客厅举办。此次活动提供免费的线下AI Agent实战课,即使是零基础的参与者也能参与。课程涵盖1对1装机指导、现场实操工坊&am…...

通过Citrix API实现许可证管理自动化与系统集成
经过Citrix API实现许可证管理自动化跟系统集成掏心窝子说,我就是个“许可证焦虑”的过来人。以前项目上线前晚上,最怕的就是看到“License不足”的警告。那时候,不可你要这么说,得跟产品经理、业务部门扯皮还得临时协调资源&…...

快速入门Ultimaker Cura:从零开始掌握3D打印切片软件
快速入门Ultimaker Cura:从零开始掌握3D打印切片软件 【免费下载链接】Cura 3D printer / slicing GUI built on top of the Uranium framework 项目地址: https://gitcode.com/gh_mirrors/cu/Cura Ultimaker Cura是全球最受欢迎的3D打印切片软件,…...
)
用51单片机和Proteus 8.10做个光照报警器:从仿真到实物,手把手带你复现(附完整代码和原理图)
51单片机光照报警器实战指南:从Proteus仿真到硬件落地的全流程解析 在物联网和智能家居快速发展的今天,环境监测设备的DIY制作成为电子爱好者入门的经典项目。其中,基于51单片机的光照报警器因其硬件简单、原理清晰,特别适合作为初…...

ZenStatesDebugTool终极指南:3步解锁AMD Ryzen处理器深度调试能力
ZenStatesDebugTool终极指南:3步解锁AMD Ryzen处理器深度调试能力 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址:…...

SonarQube中文插件离线安装全攻略:从下载到配置详解
1. 为什么需要离线安装SonarQube中文插件 很多开发团队在使用SonarQube进行代码质量分析时,都会遇到一个共同的需求:如何让这个强大的工具更好地支持中文。虽然SonarQube本身提供了多语言支持,但默认情况下并不包含完整的中文翻译。这时候&am…...

Windows下3DGS环境搭建保姆级教程:用最小化environment.yml和手动安装搞定CUDA 12.8
Windows下3DGS环境搭建:最小化配置与CUDA 12.8兼容性实战指南 当你在Windows系统上尝试复现3D Gaussian Splatting(3DGS)项目时,可能会遇到各种依赖冲突和环境配置问题,尤其是使用较新的CUDA 12.8版本和50系列显卡时。…...

USRP硬件驱动技术深度解剖:从RFNoC架构到高性能SDR实践
USRP硬件驱动技术深度解剖:从RFNoC架构到高性能SDR实践 【免费下载链接】uhd The USRP™ Hardware Driver Repository 项目地址: https://gitcode.com/gh_mirrors/uh/uhd 技术定位与价值主张 USRP硬件驱动(UHD)不仅仅是软件无线电设备的驱动程序,…...

终极Dexie.js社区贡献指南:从新手到开源贡献者的完整路径
终极Dexie.js社区贡献指南:从新手到开源贡献者的完整路径 【免费下载链接】Dexie.js A Minimalistic Wrapper for IndexedDB 项目地址: https://gitcode.com/gh_mirrors/de/Dexie.js Dexie.js作为IndexedDB的极简封装库,为开发者提供了强大而简洁…...
)
5个最适合初学者的语义分割数据集推荐(附下载链接与使用教程)
5个最适合初学者的语义分割数据集实战指南 刚接触语义分割时,最让人头疼的不是模型调参,而是找不到合适的"练手"数据集。要么数据量太大跑不动,要么标注质量参差不齐,要么文档缺失无从下手。作为过来人,我精…...