Python学习之路-初识爬虫:requests
Python学习之路-初识爬虫:requests
requests的作用
作用:发送网络请求,返回响应数据
中文文档 : http://docs.python-requests.org/zh_CN/latest/index.html
为什么学requests而不是urllib
- requests的底层实现就是urllib
- requests在python2 和python3中通用,方法完全一样
- requests简单易用
- Requests能够自动帮助我们解压(gzip压缩的等)网页内容
response.text 和response.content的区别
response.text- 类型:str
- 解码类型: 根据HTTP 头部对响应的编码作出有根据的推测,推测的文本编码
- 如何修改编码方式:
response.encoding=”gbk”
response.content- 类型:bytes
- 解码类型: 没有指定
- 如何修改编码方式:
response.content.deocde(“utf8”)
获取网页源码的通用方式:
response.content.decode()response.content.decode("GBK")response.text
以上三种方法从前往后尝试,能够100%的解决所有网页解码的问题
所以:更推荐使用response.content.deocde()的方式获取响应的html页面
发送带header的请求
思考
对比浏览器上百度首页的网页源码和代码中的百度首页的源码,有什么不同?
代码中的百度首页的源码非常少,为什么?
为什么请求需要带上header?
模拟浏览器,欺骗服务器,获取和浏览器一致的内容
header的形式
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
用法
requests.get(url,headers=headers)
发送带参数的请求
什么叫做请求参数
错误的列1: http://www.webkaka.com/tutorial/server/2015/021013/
正确的例2:https://www.baidu.com/s?wd=python&c=b
参数的形式
kw = {'wd':'长城'}
用法
requests.get(url,params=kw)
关于参数的注意点
在url地址中,很多参数是没有用的,比如百度搜索的url地址,其中参数只有一个字段有用,其他的都可以删除
对应的,在后续的爬虫中,越到很多参数的url地址,都可以尝试删除参数
requests模块发送POST请求
哪些地方我们会用到POST请求:
- 登录注册( POST 比 GET 更安全)
- 需要传输大文本内容的时候( POST 请求对数据长度没有要求)
所以同样的,我们的爬虫也需要在这两个地方回去模拟浏览器发送post请求
使用requests模块发送post请求
- 用法:
response = requests.post("http://www.baidu.com/", data = data,headers=headers) - data 的形式:字典
使用代理
为什么要使用代理
- 让服务器以为不是同一个客户端在请求
- 防止我们的真实地址被泄露,防止被追究
理解正向代理和反向代理的区别
正向代理:对于浏览器知道服务器的真实地址,例如VPN 反向代理:浏览器不知道服务器的真实地址,例如nginx
代理的使用
- 用法:
requests.get("http://www.baidu.com", proxies = proxies) - proxies的形式:字典
- 例如:
proxies = { "http": "http://12.34.56.79:9527", "https": "https://12.34.56.79:9527", }
代理IP的分类
根据代理服务器端的配置,向目标地址发送请求时,REMOTE_ADDR, HTTP_VIA,HTTP_X_FORWARDED_FOR三个变量不同而可以分为下面四类:
-
透明代理(Transparent Proxy)
REMOTE_ADDR = Proxy IPHTTP_VIA = Proxy IPHTTP_X_FORWARDED_FOR = Your IP透明代理虽然可以直接“隐藏”你的IP地址,但是还是可以从HTTP_X_FORWARDED_FOR来查到你是谁。
-
匿名代理(Anonymous Proxy)
REMOTE_ADDR = proxy IPHTTP_VIA = proxy IPHTTP_X_FORWARDED_FOR = proxy IP匿名代理比透明代理进步了一点:别人只能知道你用了代理,无法知道你是谁。
-
混淆代理(Distorting Proxies)
REMOTE_ADDR = Proxy IPHTTP_VIA = Proxy IPHTTP_X_FORWARDED_FOR = Random IP address如上,与匿名代理相同,如果使用了混淆代理,别人还是能知道你在用代理,但是会得到一个假的IP地址,伪装的更逼真
-
高匿代理(Elite proxy或High Anonymity Proxy)
REMOTE_ADDR = Proxy IPHTTP_VIA = not determinedHTTP_X_FORWARDED_FOR = not determined可以看出来,高匿代理让别人根本无法发现你是在用代理,所以是最好的选择。
从使用的协议:代理ip可以分为http代理,https代理,socket代理等,使用的时候需要根据抓取网站的协议来选择
代理IP使用的注意点
-
反反爬
使用代理ip是非常必要的一种
反反爬的方式,但是即使使用了代理ip,对方服务器任然会有很多的方式来检测我们是否是一个爬虫比如:
-
一段时间内,检测IP访问的频率,访问太多频繁会屏蔽
-
检查Cookie,User-Agent,Referer等header参数,若没有则屏蔽
-
服务方购买所有代理提供商,加入到反爬虫数据库里,若检测是代理则屏蔽
所以更好的方式是购买质量更高的代理,或者自己搭建代理服务器,组装自己的
代理IP池,同时在使用的时候使用随机的方式进行选择使用,不要每次都用一个代理ip,没事没有任何效果的
-
-
代理ip池的更新
购买的代理ip很多时候大部分(超过60%)可能都没办法使用,这个时候就需要通过程序去检测哪些可用,把不能用的删除掉。对应的实现方式在我们学习了
超时参数的使用之后大家会了解
使用requests处理cookie相关的请求
回顾cookie和session的区别
- cookie数据存放在客户的浏览器上,session数据放在服务器上。
- cookie不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗。
- session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能。
- 单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
爬虫中为什么要使用cookie
- 带上cookie的好处
- 能够访问登录后的页面
- 正常的浏览器在请求服务器的时候肯定会带上cookie(第一次请求某个地址除外),所以对方服务器有可能会通过是否携带cookie来判断我们是否是一个爬虫,对应的能够起到一定的反爬的效果
- 带上cookie的坏处
- 一套cookie往往对应的是一个用户的信息,请求太频繁有更大的可能性被对方识别为爬虫
- 那么上面的问题如何解决 ?使用多个账号
requests处理cookie相关的请求之session
-
requests 提供了一个叫做session类,来实现客户端和服务端的
会话保持 -
会话保持有两个内涵:
- 保存cookie
- 实现和服务端的长连接
-
使用方法
session = requests.session()response = session.get(url,headers)session实例在请求了一个网站后,对方服务器设置在本地的cookie会保存在session中,下一次再使用session请求对方服务器的时候,会带上前一次的cookie
-
动手:
动手尝试使用session来登录人人网:
http://www.renren.com/PLogin.do(先不考虑这个url地址从何而来),请求体的格式:{"email":"username", "password":"password"}
requests处理cookie相关的请求之cookie放在headers中
了解headers中cookie
- headers中的cookie:
- 使用分号(;)隔开
- 分号两边的类似a=b形式的表示一条cookie
- a=b中,a表示键(name),b表示值(value)
- 在headers中仅仅使用了cookie的name和value
cookie的具体组成的字段
由于headers中对cookie仅仅使用它的name和value,所以在代码中我们仅仅需要cookie的name和value即可
在headers中使用cookie
headers = {
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
"Cookie":" Pycharm-26c2d973=dbb9b300-2483-478f-9f5a-16ca4580177e; Hm_lvt_98b9d8c2fd6608d564bf2ac2ae642948=1512607763; Pycharm-26c2d974=f645329f-338e-486c-82c2-29e2a0205c74; _xsrf=2|d1a3d8ea|c5b07851cbce048bd5453846445de19d|1522379036"}requests.get(url,headers=headers)
cookie有过期时间,所以直接复制浏览器中的cookie可能意味着下一程序继续运行的时候需要替换代码中的cookie,对应的我们也可以通过一个程序专门来获取cookie供其他程序使用;当然也有很多网站的cookie过期时间很长,这种情况下,直接复制cookie来使用更加简单
requests处理cookie相关的请求之使用cookies参数
- cookies的形式:字典
cookies = {"cookie的name":"cookie的value"}
- 使用方法:
requests.get(url,headers=headers,cookies=cookie_dict}
requests模块获取cookie
requests.utils.dict_from_cookiejar:把cookiejar对象转化为字典
import requestsurl = "http://www.baidu.com"
response = requests.get(url)
print(type(response.cookies))cookies = requests.utils.dict_from_cookiejar(response.cookies)
print(cookies)
输出为:
<class 'requests.cookies.RequestsCookieJar'>
{'BDORZ': '27315'}
在前面的requests的session类中,我们不需要处理cookie的任何细节,如果有需要,我们可以使用上述方法来解决
requests处理证书错误
经常我们在网上冲浪时,经常能够看到ssl的证书不安全
那么如果在代码中请求会怎么样呢?
import requestsurl = "https://www.12306.cn/mormhweb/"
response = requests.get(url)
返回
ssl.CertificateError ...
为了在代码中能够正常的请求,我们修改添加一个参数
import requestsurl = "https://www.12306.cn/mormhweb/"
response = requests.get(url,verify=False)
超时参数的使用
在平时网上冲浪的过程中,我们经常会遇到网络波动,这个时候,一个请求等了很久可能任然没有结果
对应的,在爬虫中,一个请求很久没有结果,就会让整个项目的效率变得非常低,这个时候我们就需要对请求进行强制要求,让他必须在特定的时间内返回结果,否则就报错
使用方法如下:
response = requests.get(url,timeout=3)
通过添加timeout参数,能够保证在3秒钟内返回响应,否则会报错
这个方法还能够拿来检测代理ip的质量,如果一个代理ip在很长时间没有响应,那么添加超时之后也会报错,对应的这个ip就可以从代理ip池中删除
retrying模块的使用
上述方法能够加快我们整体的请求速度,但是在正常的网页浏览过成功,如果发生速度很慢的情况,我们会做的选择是刷新页面,那么在代码中,我们是否也可以刷新请求呢?
对应的,retrying模块就可以帮助我们解决
- retrying模块的地址:https://pypi.org/project/retrying/
- retrying 模块的使用
- 使用retrying模块提供的retry模块
- 通过装饰器的方式使用,让被装饰的函数反复执行
- retry中可以传入参数
stop_max_attempt_number,让函数报错后继续重新执行,达到最大执行次数的上限,如果每次都报错,整个函数报错,如果中间有一个成功,程序继续往后执行
所以我们可以结合前面的知识点和retrying模块,把我们需要反复使用的请求方法做一个简单的封装,在后续任何其他地方需要使用的时候,调用该方法就行
代码参考
# parse.py
import requests
from retrying import retryheaders = {}@retry(stop_max_attempt_number=3) #最大重试3次,3次全部报错,才会报错
def _parse_url(url)response = requests.get(url, headers=headers, timeout=3) #超时的时候回报错并重试assert response.status_code == 200 #状态码不是200,也会报错并充实return responsedef parse_url(url)try: #进行异常捕获response = _parse_url(url)except Exception as e:print(e)response = Nonereturn response
为什么需要新建隐身窗口
在打开隐身窗口的时候,第一次请求某个网站是没有携带cookie的,和代码请求一个网站一样,不携带cookie。这样就能够尽可能的理解代码请求某个网站的结果;除非数据是通过js加载出来的,不然爬虫请求到的数据和浏览器请求的数据大部分时候都是相同的
chrome中network的更多功能
Perserve log
默认情况下,页面发生跳转之后,之前的请求url地址等信息都会消失,勾选perserve log后之前的请求都会被保留
filter过滤
在url地址很多的时候,可以在filter中输入部分url地址,对所有的url地址起到一定的过滤效果,具体位置在上面第二幅图中的2的位置
观察特定种类的请求
在上面第二幅图中的3的位置,有很多选项,默认是选择的all,即会观察到所有种类的请求
很多时候处于自己的目的可以选择all右边的其他选项,比如常见的选项:
- XHR:大部分情况表示ajax请求
- JS:js请求
- CSS:css请求
但是很多时候我们并不能保证我们需要的请求是什么类型,特别是我们不清楚一个请求是否为ajax请求的时候,直接选择all,从前往后观察即可,其中js,css,图片等不去观察即可
不要被浏览器中的一堆请求吓到了,这些请求中除了js,css,图片的请求外,其他的请求并没有多少个
相关文章:

Python学习之路-初识爬虫:requests
Python学习之路-初识爬虫:requests requests的作用 作用:发送网络请求,返回响应数据 中文文档 : http://docs.python-requests.org/zh_CN/latest/index.html 为什么学requests而不是urllib requests的底层实现就是urllibrequests在pytho…...

Linux 常用的命令
① 基本命令 uname -m 显示机器的处理器架构uname -r 显示正在使用的内核版本dmidecode -q 显示硬件系统部件(SMBIOS / DMI) hdparm -i /dev/hda 罗列一个磁盘的架构特性hdparm -tT /dev/sda 在磁盘上执行测试性读取操作系统信息arch 显示机器的处理器架构uname -m 显示机器的处…...
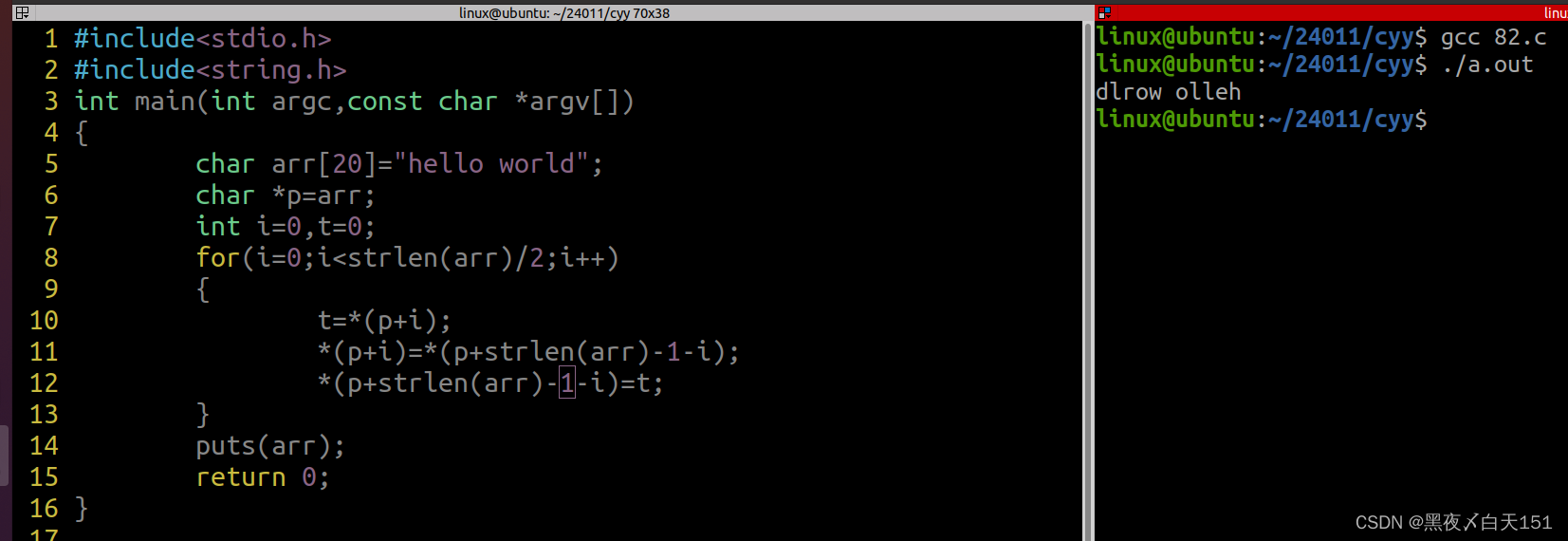
假期作业 10
1.整理磁盘操作的完整流程,如何接入虚拟机,是否成功识别,对磁盘分区工具的使用,格式化,挂载以及取消挂载 U盘接入虚拟机 在虚拟机--->可移动设备--->找到U盘---->连接 检测U盘是否被虚拟机识别 ls /dev/s…...
)
【洛谷 P3367】【模板】并查集 题解(并查集+路径压缩)
【模板】并查集 题目描述 如题,现在有一个并查集,你需要完成合并和查询操作。 输入格式 第一行包含两个整数 N , M N,M N,M ,表示共有 N N N 个元素和 M M M 个操作。 接下来 M M M 行,每行包含三个整数 Z i , X i , Y i Z_i,X_i,Y…...
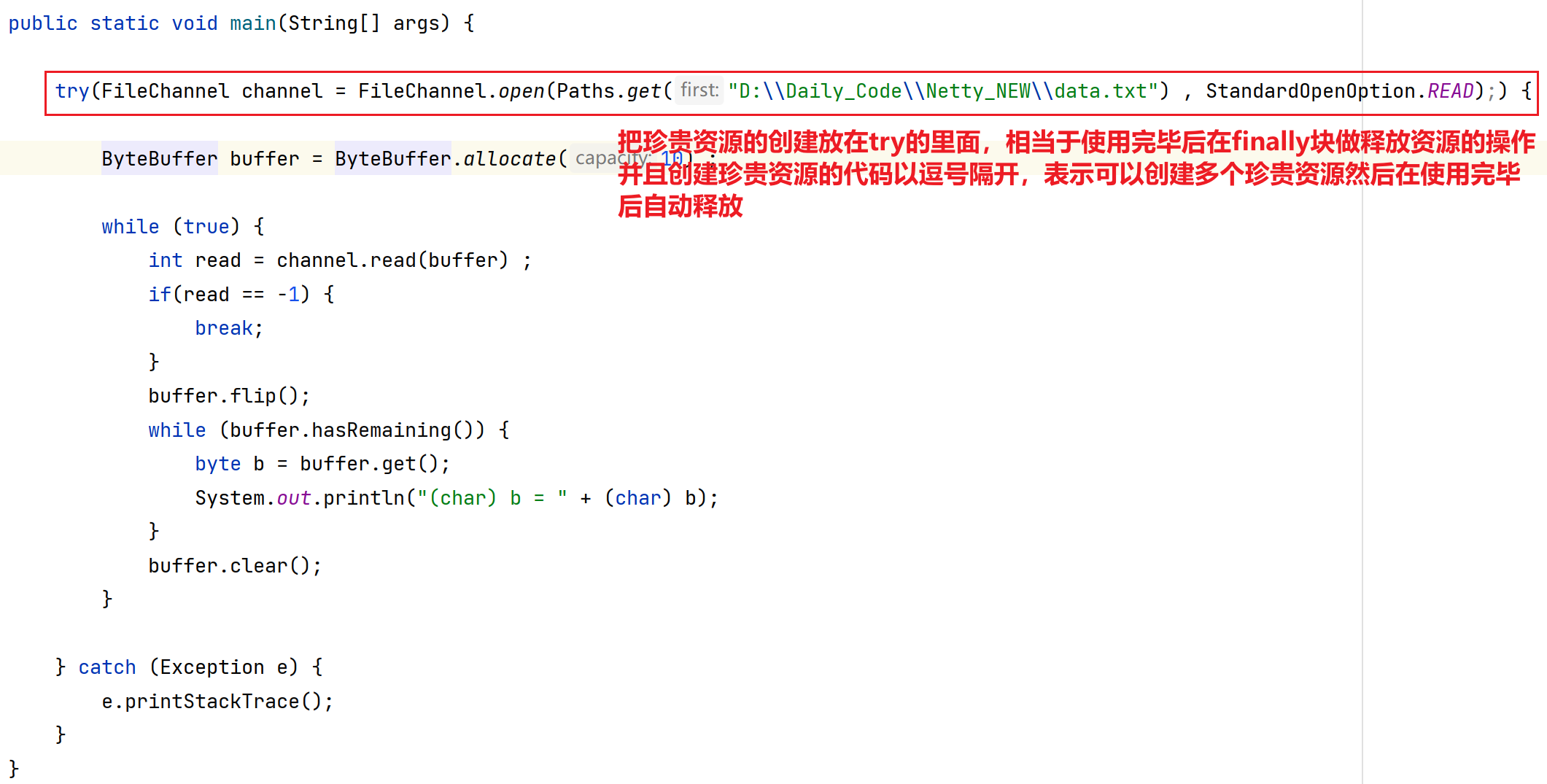
Netty应用(一) 之 NIO概念 基本编程
目录 第一章 概念引入 1.分布式概念引入 第二章 Netty基础 - NIO 1.引言 1.1 什么是Netty? 1.2 为什么要学习Netty? 2.NIO编程 2.1 传统网络通信中开发方式及问题(BIO) 2.1.1 多线程版网络编程 2.1.2 线程池版的网络编程…...
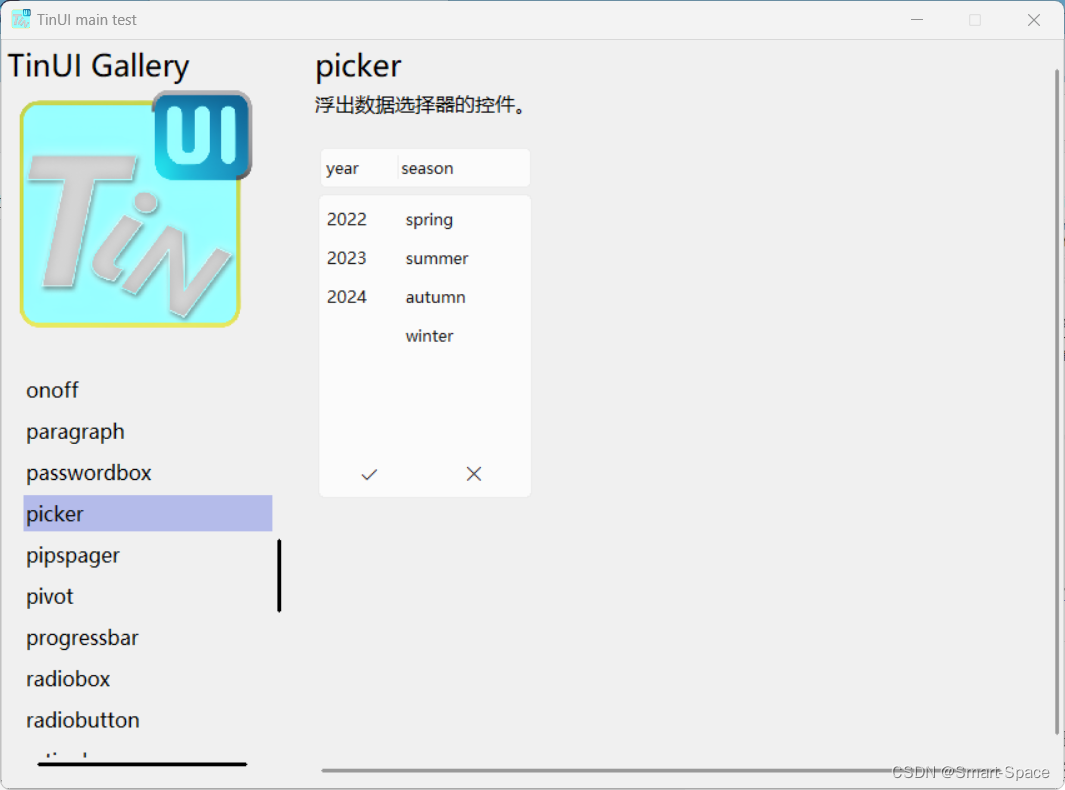
tkinter-TinUI-xml实战(10)展示画廊
tkinter-TinUI-xml实战(10)展示画廊 引言声明文件结构核心代码主界面统一展示控件控件展示界面单一展示已有展示多类展示 最终效果在这里插入图片描述  ………… 结语 引言…...
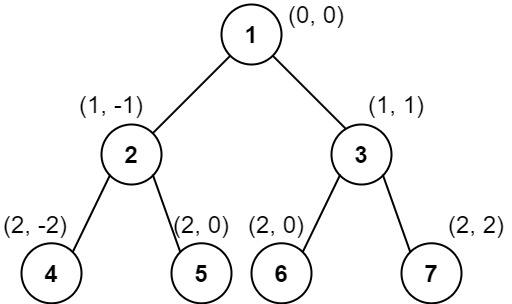
LeetCode二叉树的垂序遍历
题目描述 给你二叉树的根结点 root ,请你设计算法计算二叉树的 垂序遍历 序列。 对位于 (row, col) 的每个结点而言,其左右子结点分别位于 (row 1, col - 1) 和 (row 1, col 1) 。树的根结点位于 (0, 0) 。 二叉树的 垂序遍历 从最左边的列开始直到…...
 函数用法)
[linux c]linux do_div() 函数用法
linux do_div() 函数用法 do_div() 是一个 Linux 内核中的宏,用于执行 64 位整数的除法操作,并将结果存储在给定的变量中,同时将余数存储在另一个变量中。这个宏通常用于内核编程中,特别是在处理大整数和性能敏感的场合。 函数原…...

Python学习之路-爬虫提高:常见的反爬手段和解决思路
Python学习之路-爬虫提高:常见的反爬手段和解决思路 常见的反爬手段和解决思路 明确反反爬的主要思路 反反爬的主要思路就是:尽可能的去模拟浏览器,浏览器在如何操作,代码中就如何去实现。浏览器先请求了地址url1,保留了cookie…...

python_numpy库_ndarray的聚合操作、矩阵操作等
一、ndarray的聚合操作 1、求和np.sum() import numpy as np n np.arange(10) print(n) s np.sum(n) print(s) n np.random.randint(0,10,size(3,5)) print(n) s1 np.sum(n) print(s1) #全部数加起来 s2 np.sum(n,axis0) print(s2) #表示每一列的多行求和 …...
python-自动化篇-终极工具-用GUI自动控制键盘和鼠标-pyautogui
文章目录 用GUI自动控制键盘和鼠标pyautogui 模块鼠标屏幕位置——移动地图——pyautogui.size鼠标位置——自身定位——pyautogui.position()移动鼠标——pyautogui.moveTo拖动鼠标滚动鼠标 键盘按下键盘释放键盘 开始与结束通过注销关闭所有程序 用GUI自动控制键盘和鼠标 在…...
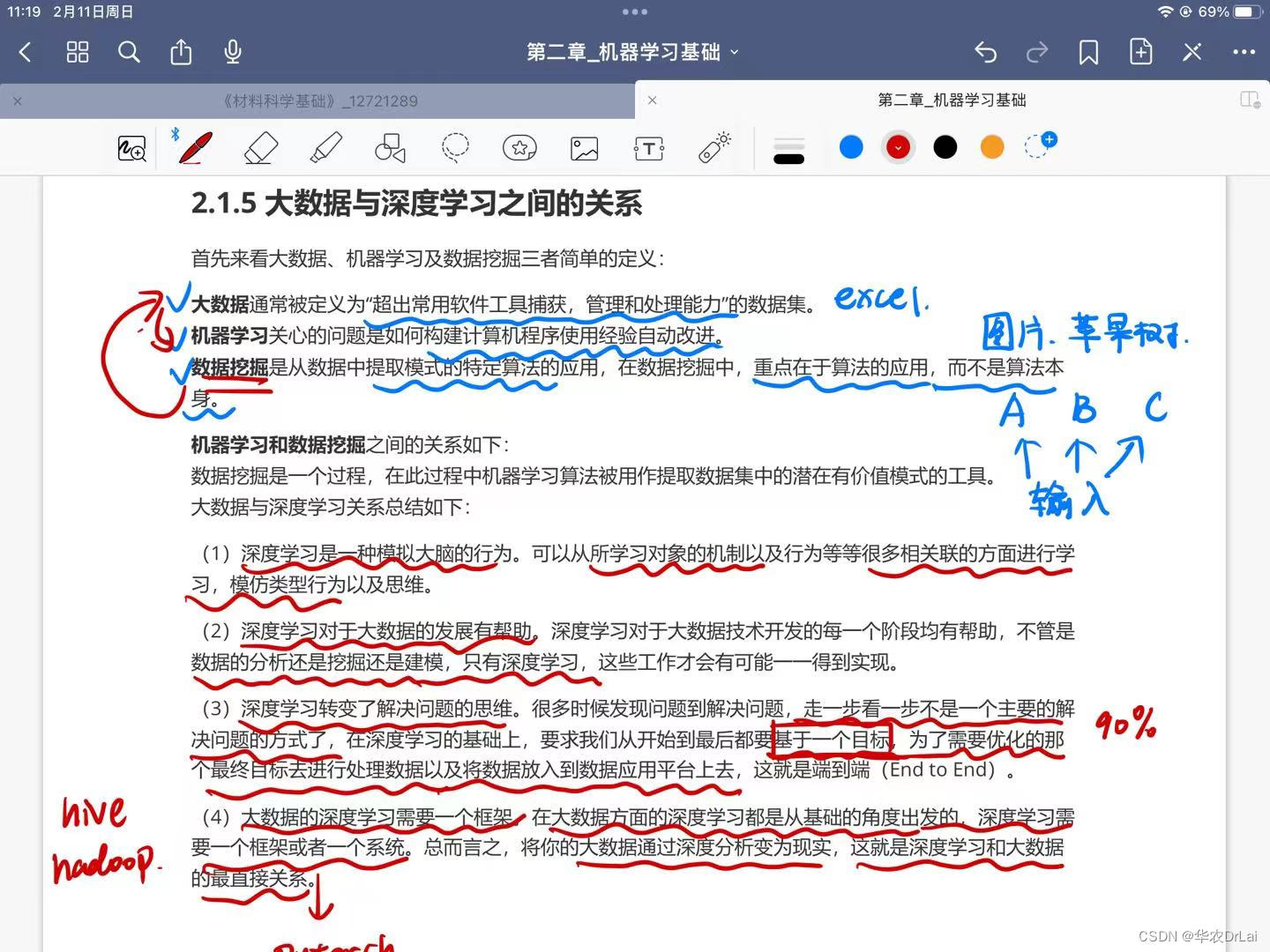
面试:大数据和深度学习之间的关系是什么?
大数据与深度学习之间存在着紧密的相互关系,它们在当今技术发展中相辅相成。 大数据的定义与特点:大数据指的是规模(数据量)、多样性(数据类型)和速度(数据生成及处理速度)都超出了传统数据处理软件和硬件能力范围的数据集。它具有四个主要特点,通常被称…...

航芯ACM32G103开发板评测 08 ADC Timer外设测试
航芯ACM32G103开发板评测 08 ADC Timer外设测试 1. 软硬件平台 ACM32G103 Board开发板MDK-ARM Keil 2. 定时器Timer 在一般的MCU芯片中,定时器这个外设资源是非常重要的,一般可以分为SysTick定时器(系统滴答定时器)、常规定时…...

【Linux学习】生产者-消费者模型
目录 22.1 什么是生产者-消费者模型 22.2 为什么要用生产者-消费者模型? 22.3 生产者-消费者模型的特点 22.4 BlockingQueue实现生产者-消费者模型 22.4.1 实现阻塞队列BlockQueue 1) 添加一个容器来存放数据 2)加入判断Blocking Queue情况的成员函数 3)实现push和pop方法 4)完…...
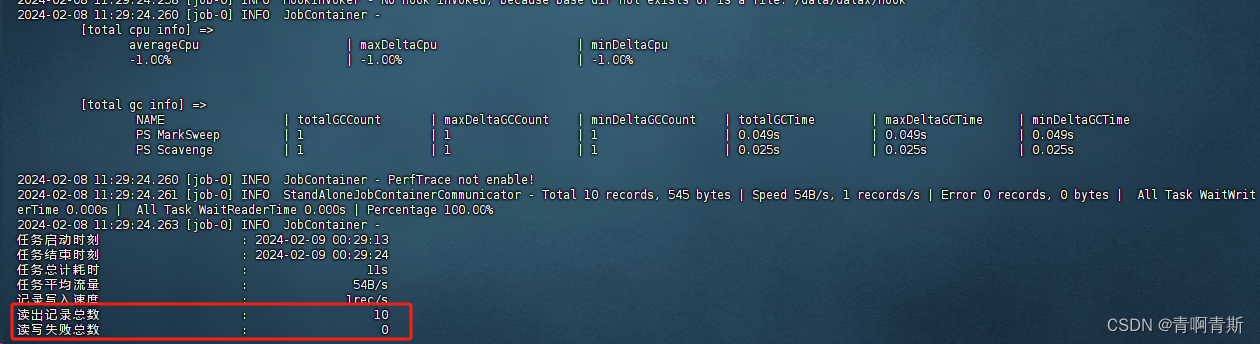
三、案例 - MySQL数据迁移至ClickHouse
MySQL数据迁移至ClickHouse 一、生成测试数据表和数据1.在MySQL创建数据表和数据2.在ClickHouse创建数据表 二、生成模板文件1.模板文件内容2.模板文件参数详解2.1 全局设置2.2 数据读取(Reader)2.3 数据写入(Writer)2.4 性能设置…...

[WinForm开源]概率计算器 - Genshin Impact(V1.0)
创作目的:为方便旅行者估算自己拥有的纠缠之缘能否达到自己的目的,作者使用C#开发了一款小型软件供旅行者参考使用。 创作说明:此软件所涉及到的一切概率与规则完全按照游戏《原神》(V4.4.0)内公示的概率与规则(包括保底机制&…...
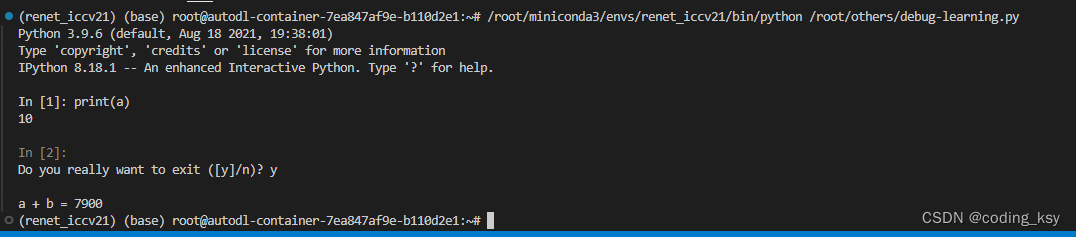
vscode 代码调试from IPython import embed
一、讲解 这种代码调试方法非常的好用。 from IPython import embed上面的代码片段是用于Python中嵌入一个交互式IPython shell的方法。这可以在任何Python脚本或程序中实现,允许在执行到该点时暂停程序,并提供一个交互式环境,以便于检查、…...
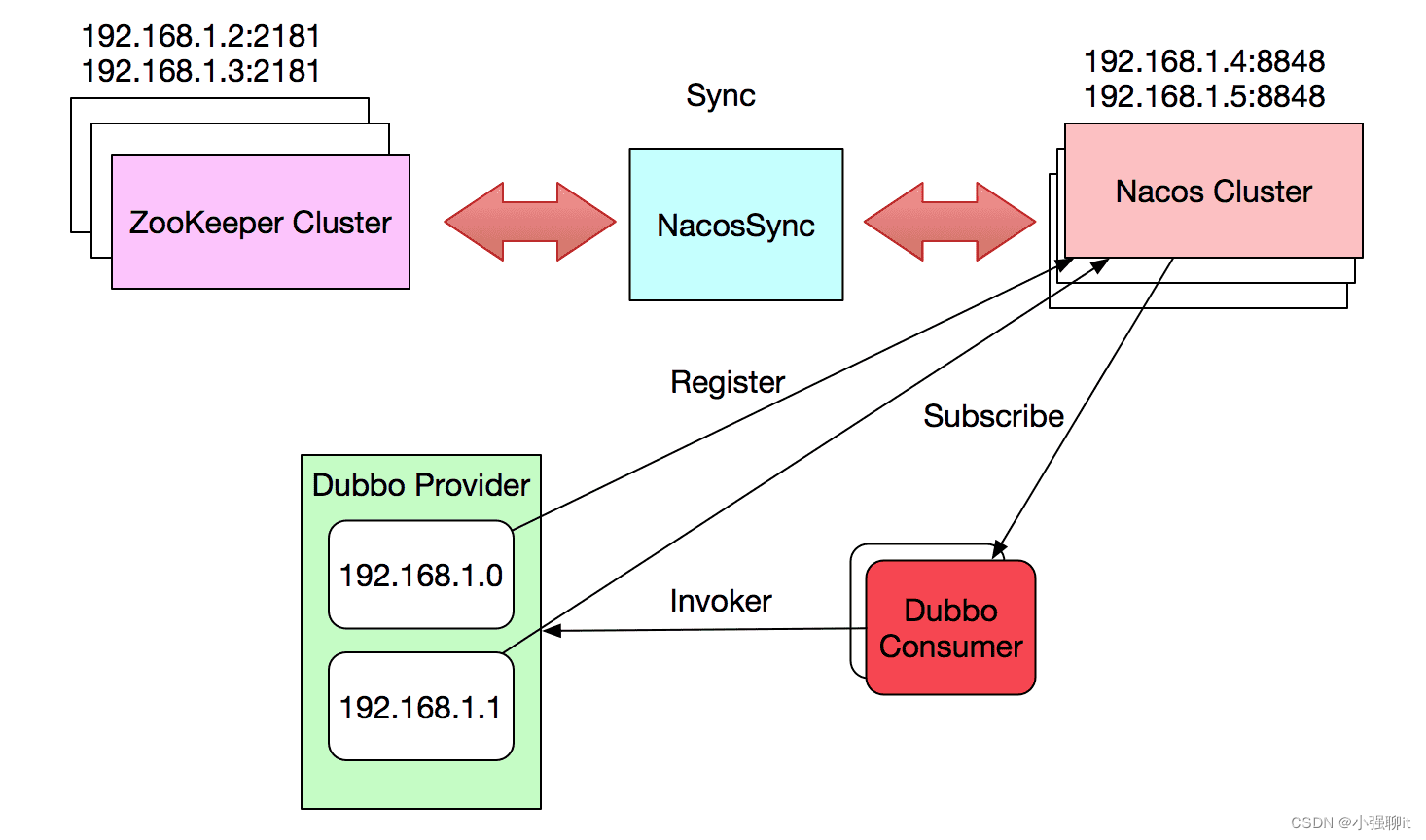
双活工作关于nacos注册中心的数据迁移
最近在做一个双活的项目,在纠结一个注册中心是在双活机房都准备一个,那主机房的数据如果传过去呢,查了一些资料,最终在官网查到了一个NacosSync 的组件,主要用来做数据传输的,并且支持在线替换注册中心的&a…...
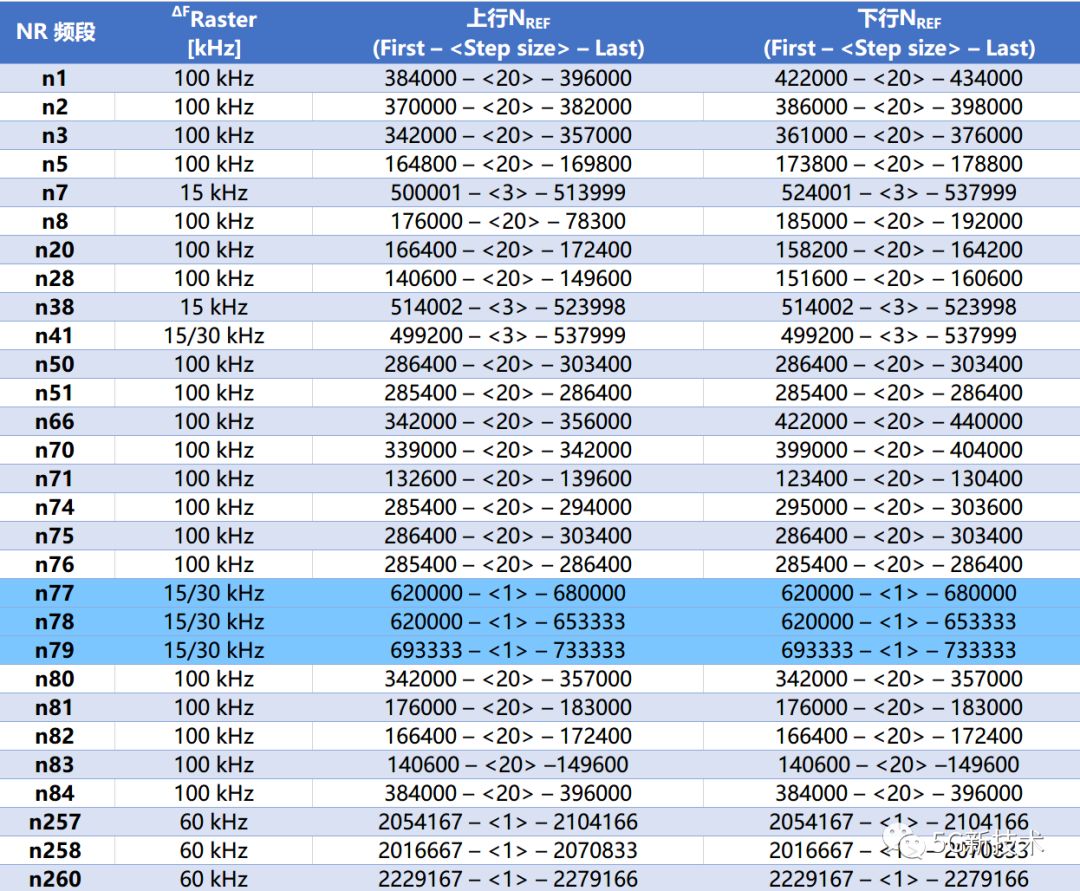
5G NR 信道号计算
一、5G NR的频段 增加带宽是增加容量和传输速率最直接的方法,目前5G最大带宽将会达到400MHz,考虑到目前频率占用情况,5G将不得不使用高频进行通信。 3GPP协议定义了从Sub6G(FR1)到毫米波(FR2)的5G目标频谱。 其中FR1是5G的核心频段࿰…...
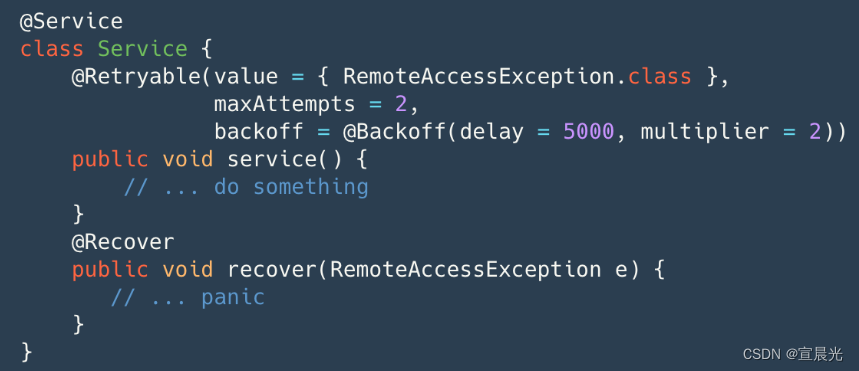
01-Spring实现重试和降级机制
主要用于在模块调用中,出现失败、异常情况下,仍需要进行重复调用。并且在最终调用失败时,可以采用降级措施,返回一般结果。 1、重试机制 我们采用spring 提供的retry 插件,其原理采用aop机制,所以需要额外…...

北光恒电:安捷伦6812B/6813B电源不开机、输出不正常故障排查
安捷伦6812B/6813B电源作为高精度交流电源/功率分析仪,广泛应用于电源测试、UPS测试、航空电子ATE等场景,凭借稳定性能成为实验室和生产线上的核心设备。长期使用或操作不当,不开机、输出不正常等故障频发,影响测试效率。常见故障…...

开关电源功率因数校正:从谐波失真到PFC电路设计实践
1. 项目概述:从“相移”到“失真”,理解开关整流器的功率因数挑战在通信、数据中心乃至我们日常使用的各类开关电源适配器中,高频开关整流器是电能转换的核心。作为一名电源工程师,我经常被问到:“为什么我们设备的输入…...

谷歌外链怎么发?靠1种图文形式自动吸引外链
写外链一直是SEO里最耗体力的活。很多公司招了三个实习生,每天坐在电脑前发几百封开发信,回复率往往不到0.5%。到了2026年,谷歌的算法已经能识别出绝大多数带有“交换”性质的人为链接。现在的行情是,想要稳住排名,得让…...

除了连接模拟器,AppInventor开发者还应该知道的3个‘坑’:录音、短信模块与API调用限制
避开AppInventor开发中的三大隐形陷阱:录音、短信与API调用实战指南 当你成功连接AppInventor模拟器,准备大展拳脚开发应用时,可能会突然发现某些功能"神秘失效"——录音按钮点击无反应、短信发送模块形同虚设、API调用慢如蜗牛。这…...

Java 数组
Java 数组详细教程数组是 Java 中一种基本且重要的数据结构,用于存储固定大小的同类型元素的集合。所有元素在内存中是连续存储的,可以通过索引(下标)快速访问。1. 数组的基本概念元素: 数组中存储的每一个数据项。长度…...

7天掌握FontForge:免费开源字体编辑器的完整使用指南
7天掌握FontForge:免费开源字体编辑器的完整使用指南 【免费下载链接】fontforge Free (libre) font editor for Windows, Mac OS X and GNULinux 项目地址: https://gitcode.com/gh_mirrors/fo/fontforge 你是否曾梦想设计属于自己的字体?无论是…...

用NE555和立创EDA做个会‘叮咚’的门铃:从原理图到PCB打板的完整DIY记录
从零打造NE555叮咚门铃:立创EDA全流程实战指南 当电子爱好者第一次尝试将电路图转化为实物时,往往会面临软件操作、元件选型和生产对接的多重挑战。本文将以经典NE555叮咚门铃为例,手把手演示如何用立创EDA完成从原理图设计到PCB打板的完整流…...

别再只盯着硬盘了!Windows内存取证入门:用ProcDump和Strings快速分析可疑进程的Dump文件
Windows内存取证实战:5分钟快速定位可疑进程的蛛丝马迹 当服务器突然卡顿、某个进程CPU占用率飙升时,大多数运维人员的第一反应是打开任务管理器结束进程。但真正的威胁往往隐藏在表象之下——那些看似正常的svchost.exe可能正在悄悄执行恶意代码。本文…...
)
51单片机定时器生成PWM波控制电机转速,从原理到代码调试全流程(基于STC89C52)
51单片机定时器生成PWM波控制电机转速:从寄存器配置到闭环调速实战 在嵌入式控制领域,PWM(脉冲宽度调制)技术如同精准的"电子油门",通过调节脉冲占空比实现对电机转速的精细控制。STC89C52RC这颗经典的51内核…...
)
保姆级教程:在Ubuntu上把YOLOv5的ONNX模型转成RV1126能用的RKNN模型(附完整代码)
从ONNX到RKNN:YOLOv5模型在RV1126平台的完整转换指南 当清晨的第一缕阳光透过窗帘缝隙洒在键盘上,我正盯着终端里那个顽固的ONNX模型发愁——它已经在我的Ubuntu工作站上运行了整整一夜,却依然没能成功转换为RV1126开发板可用的RKNN格式。这…...