java8-用流收集数据-6

本章内容
口用co1lectors类创建和使用收集器
口将数据流归约为一个值
口汇总:归约的特殊情况
数据分组和分区口
口 开发自己的自定义收集器
我们在前一章中学到,流可以用类似于数据库的操作帮助你处理集合。你可以把Java8的流看作花哨又懒惰的数据集迭代器。它们支持两种类型的操作:中间操作(如fi1ter或map)和终端操作(如count、findrirst、forEach和reduce)。中间操作可以链接起来,将一个流转换为另一个流。这些操作不会消耗流,其目的是建立一个流水线。与此相反,终端操作会消耗流,以产生一个最终结果,例如返回流中的最大元素。它们通常可以通过优化流水线来缩短计算时间。
我们已经在第4章和第5章中用过co11ect终端操作了,当时主要是用来把stream中所有的元素结合成一个List。在本章中,你会发现co1lect是一个归约操作,就像reduce一样可以接受各种做法作为参数,将流中的元素累积成一个汇总结果。具体的做法是通过定义新的Co1lector接口来定义的,因此区分collection、collector和co1lect是很重要的。下面是一些查询的例子,看看你用collect和收集器能够做什么。口对一个交易列表按货币分组,获得该货币的所有交易额总和(返回一个Map<currency,Integer>)口将交易列表分成两组:贵的和不贵的(返回一个Map<Boolean,List<Transaction>>)。口创建多级分组,比如按城市对交易分组,然后进一步按照贵或不贵分组(返回一个Map<Boolean,List<Transaction>>激动吗?很好,我们先来看一个利用收集器的例子。想象一下,你有一个由Transaction构成的List,并且想按照名义货币进行分组。在没有Lambda的Java里,哪怕像这种简单的用例实现起来都很啰嗦,就像下面这样。

6.1 收集器简介
前一个例子清楚地展示了函数式编程相对于指令式编程的一个主要优势:你只需指出希望的结果--“做什么”,而不用操心执行的步骤--“如何做”。在上一个例子里,传递给collect方法的参数是co1lector接口的一个实现,也就是给stream中元素做汇总的方法。上一章里的toList只是说“按顺序给每个元素生成一个列表”;在本例中,groupingBy说的是“生成一个Map,它的键是(货币)桶,值则是桶中那些元素的列表”。
要是做多级分组,指令式和函数式之间的区别就会更加明显:由于需要好多层嵌套循环和条件,指令式代码很快就变得更难阅读、更难维护、更难修改。相比之下,函数式版本只要再加上一个收集器就可以轻松地增强功能了,你会在6.3节中看到它。
6.1.1 收集器用作高级归约
刚刚的结论又引出了优秀的函数式API设计的另一个好处:更易复合和重用。收集器非常有用,因为用它可以简洁而灵活地定义co1lect用来生成结果集合的标准。更具体地说,对流调用co1lect方法将对流中的元素触发一个归约操作(由co1lector来参数化)。图6-1所示的归约操作所做的工作和代码清单6-1中的指令式代码一样。它遍历流中的每个元素,并让collector进行处理。

一般来说,collector会对元素应用一个转换函数(很多时候是不体现任何效果的恒等转换,例如toList),并将结果累积在一个数据结构中,从而产生这一过程的最终输出。例如,在前面所示的交易分组的例子中,转换函数提取了每笔交易的货币,随后使用货币作为键,将交易本身
累积在生成的Map中。如货币的例子中所示,collector接口中方法的实现决定了如何对流执行归约操作。我们会在6.5节和6.6节研究如何创建自定义收集器。但co1lectors实用类提供了很多静态工厂方法,可以方便地创建常见收集器的实例,只要拿来用就可以了。最直接和最常用的收集器是toList静态方法,它会把流中所有的元素收集到一个ist中:
List<Transaction>transactions=transactiongtream.collect(Collectors.toList())6.1.2 预定义收集器
在本章剩下的部分中,我们主要探讨预定义收集器的功能,也就是那些可以从co1lectors类提供的工厂方法(例如groupingBy)创建的收集器。它们主要提供了三大功能:
口将流元素归约和汇总为一个值
口 元素分组
口 元素分区
我们先来看看可以进行归约和汇总的收集器。它们在很多场合下都很方便,比如前面例子中提到的求一系列交易的总交易额。
然后你将看到如何对流中的元素进行分组,同时把前一个例子推广到多层次分组,或把不同
的收集器结合起来,对每个子组进行进一步归约操作。我们还将谈到分组的特殊情况“分区”即使用谓词(返回一个布尔值的单参数函数)作为分组函数。
6.4节末有一张表,总结了本章中探讨的所有预定义收集器。在6.5节你将了解更多有关co1lector接口的内容。在6.6节中你会学到如何创建自己的自定义收集器,用于co1lectors类的工厂方法无效的情况。
6.2 归约和汇总
为了说明从Collectors工厂类中能创建出多少种收集器实例,我们重用一下前一章的例包含一张佳看列表的菜单!
就像你刚刚看到的,在需要将流项目重组成集合时,一般会使用收集器( stream方法co1lect的参数)。再宽泛一点来说,但凡要把流中所有的项目合并成一个结果时就可以用。这个结果可以是任何类型,可以复杂如代表一棵树的多级映射,或是简单如一个整数--也许代表了菜单的热量总和。这两种结果类型我们都会讨论:6.2.2节讨论单个整数,6.3.1节讨论多级分组。我们先来举一个简单的例子,利用counting工厂方法返回的收集器,数一数菜单里有多少种菜:
long howManyDishes = menu.stream().collect (Collectors .counting());这还可以写得更为直接:
long howManyDishes =menu.stream().count()counting收集器在和其他收集器联合使用的时候特别有用,后面会谈到这一点。在本章后面的部分,我们假定你已导人了co1lectors类的所有静态工厂方法:
import static java.util.stream.Collectors.*;这样你就可以写counting()而用不着写collectors.counting()之类的了。让我们来继续探讨简单的预定义收集器,看看如何找到流中的最大值和最小值。
6.2.1 查找流中的最大值和最小值
假设你想要找出菜单中热量最高的菜。你可以使用两个收集器,Collectors.maxBy和Collectors.minBy,来计算流中的最大或最小值。这两个收集器接收一个comparator参数来比较流中的元素。你可以创建一个comparator来根据所含热量对菜看进行比较,并把它传递给Collectors .maxBy:
Comparator<Dish>dishCaloriesComparator=Comparator.comparingInt(Dish::getCalories):
Optiona1l<Dish>mostCalorieDish=menu.stream()
.collect(maxBy(dishCaloriesComparator));你可能在想optional<Dish>是怎么回事。要回答这个问题,我们需要问“要是menu为空怎么办”。那就没有要返回的菜了!Java8引|人了optiona1,它是一个容器,可以包含也可以不包含值。这里它完美地代表了可能也可能不返回菜看的情况。我们在第5章讲findAny方法的时候简要提到过它。现在不用担心,我们专门用第10章来研究optional<T>及其操作。另一个常见的返回单个值的归约操作是对流中对象的一个数值字段求和。或者你可能想要求平均数。这种操作被称为汇总操作。让我们来看看如何使用收集器来表达汇总操作。

6.2.3 连接字符串
joining工厂方法返回的收集器会把对流中每一个对象应用tostring方法得到的所有字符串连接成一个字符串。这意味着你把菜单中所有菜看的名称连接起来,如下所示:
String shortMenu = menu.stream().map(Dish::getName).collect (joining());请注意,joining在内部使用了stringBuilder来把生成的字符串逐个追加起来。此外还要注意,如果Dish类有一个tostring方法来返回菜看的名称,那你无需用提取每一道菜名称的函数来对原流做映射就能够得到相同的结果:
String shortMenu =menu.stream().collect(joining());
二者均可产生以下字符串:
porkbeefchickenfrench friesriceseason fruitpizzaprawnssalmon
但该字符串的可读性并不好。幸好,joining工厂方法有一个重载版本可以接受元素之间的分界符,这样你就可以得到一个逗号分隔的菜看名称列表:
String shortMenu = menu.stream().map(Dish::getName) .collect (joining(","));正如我们预期的那样,它会生成:
pork,beef,chicken,french fries,rice,season fruit,pizza,prawns, salmon
到目前为止,我们已经探讨了各种将流归约到一个值的收集器。在下一节中,我们会展示为什么所有这种形式的归约过程,其实都是co1lectors.reducing工厂方法提供的更广义归约收集器的特殊情况。
6.2.4 广义的归约汇总
事实上,我们已经讨论的所有收集器,都是一个可以用reducing工厂方法定义的归约过程的特殊情况而已。co11ectors.reducing工厂方法是所有这些特殊情况的一般化。可以说,先前讨论的案例仅仅是为了方便程序员而已。(但是,请记得方便程序员和可读性是头等大事!)例如,可以用reducing方法创建的收集器来计算你菜单的总热量,如下所示:
int totalCalories =menu.stream().collect(reducing(0,Dish::getCalories,(i,j)->i +j))它需要三个参数。
口第一个参数是归约操作的起始值,也是流中没有元素时的返回值,所以很显然对于数值和而言0是一个合适的值。
口第二个参数就是你在6.2.2节中使用的函数,将菜看转换成一个表示其所含热量的int。
口第三个参数是一个Binaryoperator,将两个项目累积成一个同类型的值。这里它就是对两个int求和。同样,你可以使用下面这样单参数形式的reducing来找到热量最高的菜,如下所示:
Optional<Dish>mostCalorieDish =
menu.stream().collect(reducing((d1,d2)->dl.getCalories()>d2.getCalories()?d1 :d2));你可以把单参数reducing工厂方法创建的收集器看作三参数方法的特殊情况,它把流中的第一个项目作为起点,把恒等函数(即一个函数仅仅是返回其输入参数)作为一个转换函数。这也意味着,要是把单参数reducing收集器传递给空流的co1lect方法,收集器就没有起点;正如我们在6.2.1节中所解释的,它将因此而返回一个optional<pish>对象。
收集与归约
在上一章和本章中讨论了很多有关归约的内容。你可能想知道,stream接口的collect和reduce方法有何不同,因为两种方法通常会获得相同的结果。例如,你可以像下面这样使用reduce方法来实现toListCollector所做的工作:
Stream<Integer>stream=Arrays.asList(l,2,3,4,5,6).stream();List<Integer>numbersstream.reduce(
new rrayList<Integer>()
(List<Integer>l,Integer e)->{1 .add(e);
return li
}
(List<Integer>1l,List<Integer>12)->{
11.addд11(12);
return 11;});
这个解决方案有两个问题:一个语义问题和一个实际问题。语义问题在于,reduce方法旨在把两个值结合起来生成一个新值,它是一个不可变的归约。与此相反,collect方法的设计就是要改变容器,从而累积要输出的结果。这意味着,上面的代码片段是在滥用reduce方法,因为它在原地改变了作为累加器的List。你在下一章中会更详细地看到,以错误的语义使用reduce方法还会造成一个实际问题:这个归约过程不能并行工作,因为由多个线程并发修改同一个数据结构可能会破坏List本身。在这种情况下,如果你想要线程安全,就需要每次分配一个新的List,而对象分配又会影响性能。这就是co1lect方法特别适合表达可变容器上的归约的原因,更关键的是它适合并行操作,本章后面会谈到这一点。
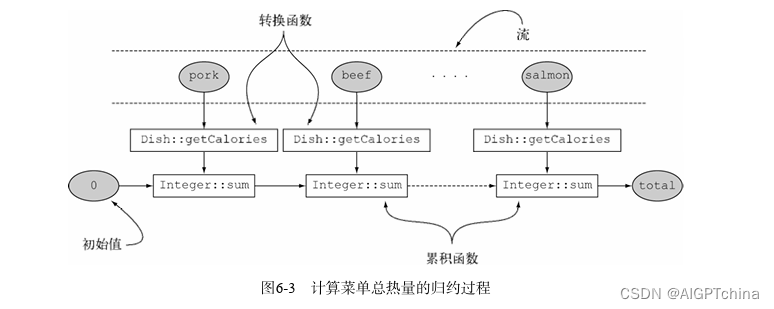
1.收集框架的灵活性:以不同的方法执行同样的操作你还可以进一步简化前面使用reducing收集器的求和例子--引用Integer类的sum方法,而不用去写一个表达同一操作的Lammbda表达式。这会得到以下程序:
int totalCalories =menu.stream().collect(reducing(0,4-- 初始值Dish::getCalories,◁-转换函数Integer::sum))i4- 累积函数
从逻辑上说,归约操作的工作原理如图6-3所示:利用累积函数,把一个初始化为起始值的累加器,和把转换函数应用到流中每个元素上得到的结果不断迭代合并起来。



6.3 分组
一个常见的数据库操作是根据一个或多个属性对集合中的项目进行分组。就像前面讲到按货币对交易进行分组的例子一样,如果用指令式风格来实现的话,这个操作可能会很麻烦、啰嗦而且容易出错。但是,如果用Java8所推崇的函数式风格来重写的话,就很容易转化为一个非常容易看懂的语句。我们来看看这个功能的第二个例子:假设你要把菜单中的菜按照类型进行分类,有肉的放一组,有鱼的放一组,其他的都放另一组。用collectors.groupingBy工厂方法返回的收集器就可以轻松地完成这项任务,如下所示:
Map<Dish.Type,List<Dish>>dishesByType =
menu.stream().collect(groupingBy(Dish::getType));其结果是下面的Map:
(FISH=lprawns,salmon],0THER=[french fries,rice,season fruit,pizza],MEAT=[pork,beef,chickenl}
这里,你给groupingBy方法传递了一个Function(以方法引用的形式),它提取了流中每:道Dish的Dish.ype。我们把这个Function叫作分类函数,因为它用来把流中的元素分成不同的组。如图6-4所示,分组操作的结果是一个ap,把分组函数返回的值作为映射的键,把流中所有具有这个分类值的项目的列表作为对应的映射值。在菜单分类的例子中,键就是菜的类型,

但是,分类函数不一定像方法引用那样可用,因为你想用以分类的条件可能比简单的属性访问器要复杂。例如,你可能想把热量不到400卡路里的菜划分为“低热量”(diet),热量400到700卡路里的菜划为“普通”(normal),高于700卡路里的划为“高热量”(fat)。由于pish类的作者没有把这个操作写成一个方法,你无法使用方法引用,但你可以把这个逻辑写成Lambda表达式:
public enum CaloricLevel(DIET,NORMAL,FAT
Map<CaloricLevel,List<Dish>> dishesByCaloricLevel = menu.stream().collect (groupingBy(dish>if (dish.getCalories()<= 400)return CaloricLevel.DIET;else if (dish.getCalories()<= 700)return
CaloricLeve1.NORMAL:
else returnaricevel.FT:现在,你已经看到了如何对菜单中的菜看按照类型和热量进行分组,但要是想同时按照这两个标准分类怎么办呢?分组的强大之处就在于它可以有效地组合。让我们来看看怎么做。
6.4 分区
分区是分组的特殊情况:由一个谓词(返回一个布尔值的函数)作为分类函数,它称分区函数。分区函数返回一个布尔值,这意味着得到的分组Map的键类型是Boolean,于是它最多可以分为两组--true是一组,false是一组。例如,如果你是素食者或是请了一位素食的朋友来共进晚餐,可能会想要把菜单按照素食和非素食分开:
分区函数
Map<Boolean,List<Dish>> partitionedMenumenu.stream().collect(partitioningBy(Dish::isVegetarian));这会返回下面的Map:
false=lpork,beef,chicken,prawns,salmon]true=lfrench fries,rice,season fruit,pizza]}那么通过Map中键为true的值,就可以找出所有的素食菜看了
List<Dish> vegetarianDishes = partitionedMenu.get(true);
请注意,用同样的分区谓词,对菜单ist创建的流作筛选,然后把结果收集到另外一个List中也可以获得相同的结果:
List<Dish> vegetarianDishes=
menu.stream().filter(Dish::isVegetarian).collect (toList());
相关文章:
java8-用流收集数据-6
本章内容口用co1lectors类创建和使用收集器 口将数据流归约为一个值 口汇总:归约的特殊情况 数据分组和分区口 口 开发自己的自定义收集器 我们在前一章中学到,流可以用类似于数据库的操作帮助你处理集合。你可以把Java8的流看作花哨又懒惰的数据集迭代器。它们…...

[前端开发] JavaScript基础知识 [上]
下篇:JavaScript基础知识 [下] JavaScript基础知识 [上] 引言语句、标识符和变量JavaScript引入注释与输出数据类型运算符条件语句与循环语句 引言 JavaScript是一种广泛应用于网页开发的脚本语言,具有重要的前端开发和部分后端开发的应用。通过JavaSc…...
初识Qt | 从安装到编写Hello World程序
文章目录 1.前端开发简单分类2.Qt的简单介绍3.Qt的安装和环境配置4.创建简单的Qt项目 1.前端开发简单分类 前端开发,这里是一个广义的概念,不单指网页开发,它的常见分类 网页开发:前端开发的主要领域,使用HTML、CSS …...
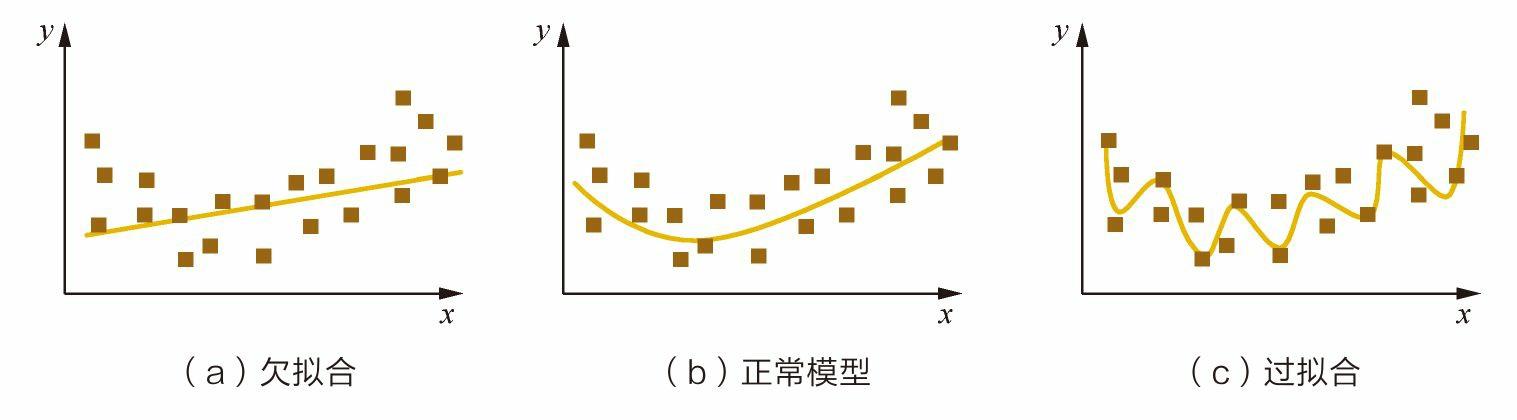
机器学习:过拟合和欠拟合的介绍与解决方法
过拟合和欠拟合的表现和解决方法。 其实除了欠拟合和过拟合,还有一种是适度拟合,适度拟合就是我们模型训练想要达到的状态,不过适度拟合这个词平时真的好少见。 过拟合 过拟合的表现 模型在训练集上的表现非常好,但是在测试集…...

变分自编码器(VAE)PyTorch Lightning 实现
✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。 🍎个人主页:小嗷犬的个人主页 🍊个人网站:小嗷犬的技术小站 🥭个人信条:为天地立心&…...

设备驱动开发_1
可加载模块如何工作的 主要内容 描述可加载模块优势使用模块命令效率使用和定义模块密钥和模块工作1 描述可加载模块优势 开发周期优势: 静态模块在/boot下的vmlinuz中,需要配置、编译、重启。 开发周期长。 LKM 不需要重启。 开发周期优于静态模块。 2 使用模块命令效率…...
知识点精要解析)
C语言位域(Bit Fields)知识点精要解析
在C语言中,位域(Bit Field)是一种独特的数据结构特性,它允许程序员在结构体(struct)中定义成员变量,并精确指定其占用的位数。通过使用位域,我们可以更高效地利用存储空间࿰…...

离散数学——图论(笔记及思维导图)
离散数学——图论(笔记及思维导图) 目录 大纲 内容 参考 大纲 内容 参考 笔记来自【电子科大】离散数学 王丽杰...
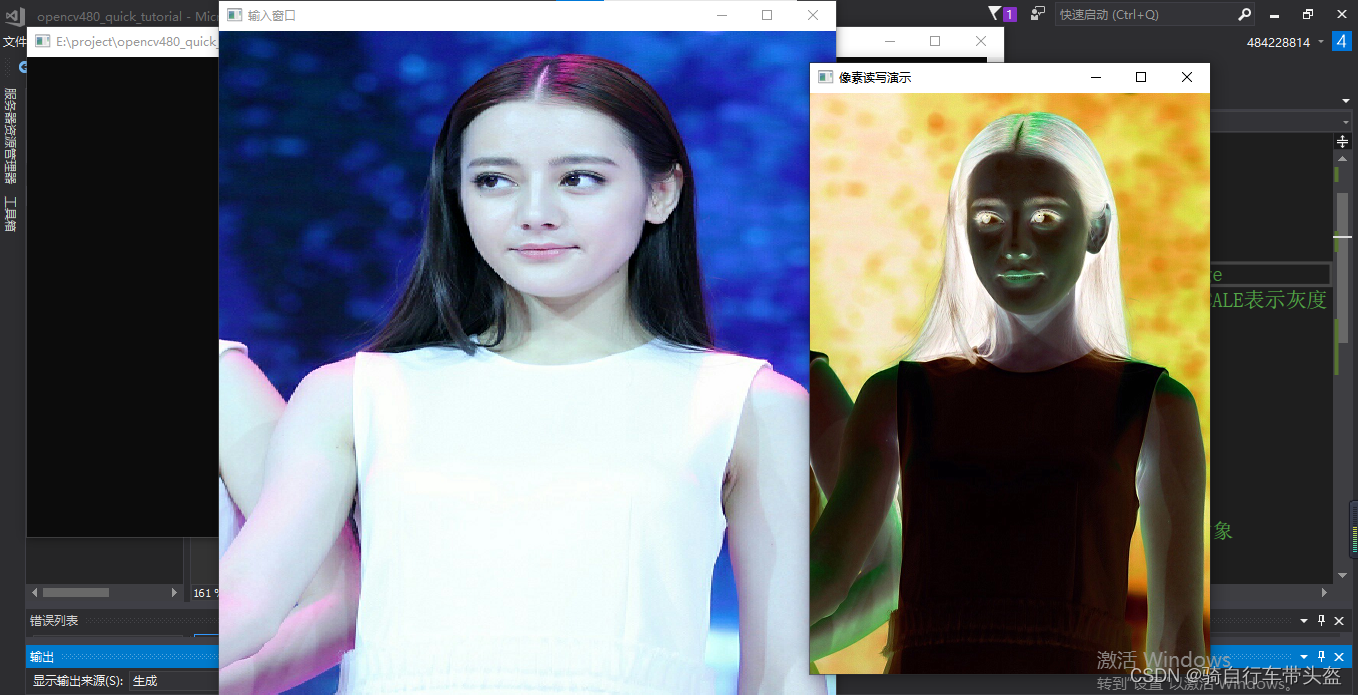
opencv图像像素的读写操作
void QuickDemo::pixel_visit_demo(Mat & image) {int w image.cols;//宽度int h image.rows;//高度int dims image.channels();//通道数 图像为灰度dims等于一 图像为彩色时dims等于三 for (int row 0; row < h; row) {for (int col 0; col < w; col) {if…...

Java学习第十四节之冒泡排序
冒泡排序 package array;import java.util.Arrays;//冒泡排序 //1.比较数组中,两个相邻的元素,如果第一个数比第二个数大,我们就交换他们的位置 //2.每一次比较,都会产生出一个最大,或者最小的数字 //3.下一轮则可以少…...

第1章 计算机网络体系结构-1.1计算机网络概述
1.1.1计算机网络概念 计算机网络是将一个分散的,具有独立功能的计算机系统通过通信设备与路线连接起来,由功能完善的软件实现资源共享和信息传递的系统。(计算机网络就是一些互连的,自治的计算机系统的集合) 1.1.2计算机网络的组成 从不同角…...

蓝桥杯:C++排序
排序 排序和排列是算法题目常见的基本算法。几乎每次蓝桥杯软件类大赛都有题目会用到排序或排列。常见的排序算法如下。 第(3)种排序算法不是基于比较的,而是对数值按位划分,按照以空间换取时间的思路来排序。看起来它们的复杂度更好,但实际…...
数据结构-堆
1.容器 容器用于容纳元素集合,并对元素集合进行管理和维护. 传统意义上的管理和维护就是:增,删,改,查. 我们分析每种类型容器时,主要分析其增,删,改ÿ…...

奔跑吧小恐龙(Java)
前言 Google浏览器内含了一个小彩蛋当没有网络连接时,浏览器会弹出一个小恐龙,当我们点击它时游戏就会开始进行,大家也可以玩一下试试,网址:恐龙快跑 - 霸王龙游戏. (ur1.fun) 今天我们也可以用Java来简单的实现一下这…...

Ubuntu 1804 And Above Coredump Settings
查看 coredump 是否开启 # 查询, 0 未开启, unlimited 开启 xiaoUbuntu:/var/core$ ulimit -c 0# 开启 xiaoUbuntu:/var/core$ ulimit -c unlimited查看 coredump 保存路径 默认情况下,Ubuntu 使用 apport 服务处理 coredump 文件ÿ…...

docker 2:安装
docker 2:安装 ubuntu 安装 docker sudo apt install docker.io 把当前用户放进 docker 用户组,避免每次运行 docker 命都要使用 sudo 或者 root 权限。 sudo usermod -aG docker $USERid $USER 看到用户已加入 docker 组 …...
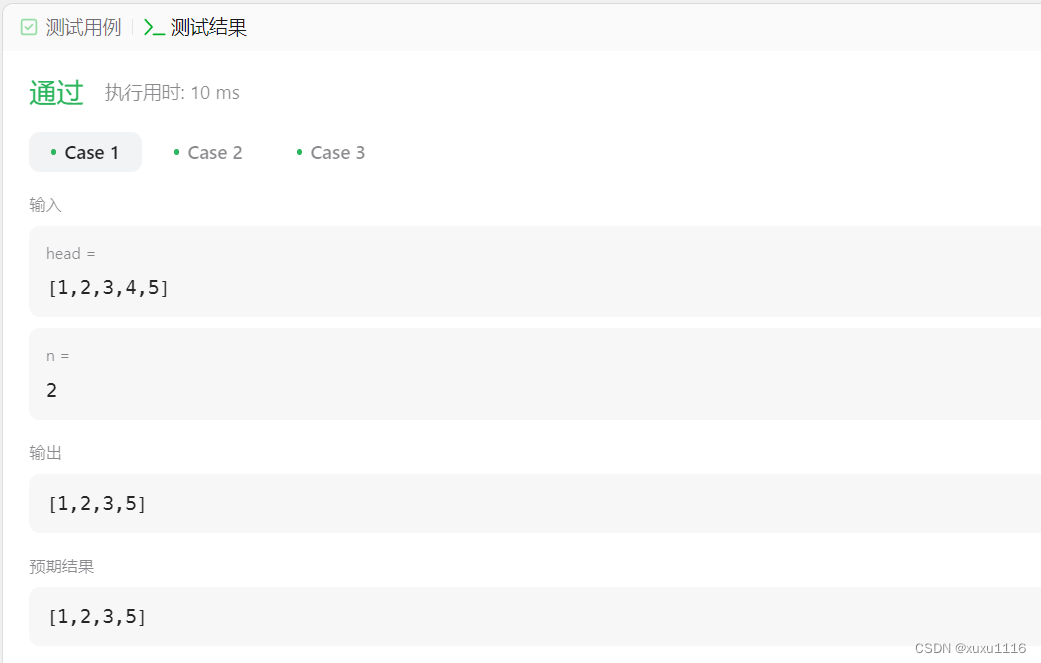
LeetCode Python - 19.删除链表的倒数第N个结点
目录 题目答案运行结果 题目 给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。 示例 1: 输入:head [1,2,3,4,5], n 2 输出:[1,2,3,5] 示例 2: 输入:head [1], n 1 输出&a…...
Spring Boot 笔记 005 环境搭建
1.1 创建数据库和表(略) 2.1 创建Maven工程 2.2 补齐resource文件夹和application.yml文件 2.3 porn.xml中引入web,mybatis,mysql等依赖 2.3.1 引入springboot parent 2.3.2 删除junit 依赖--不能删,删了会报错 2.3.3 引入spring web依赖…...
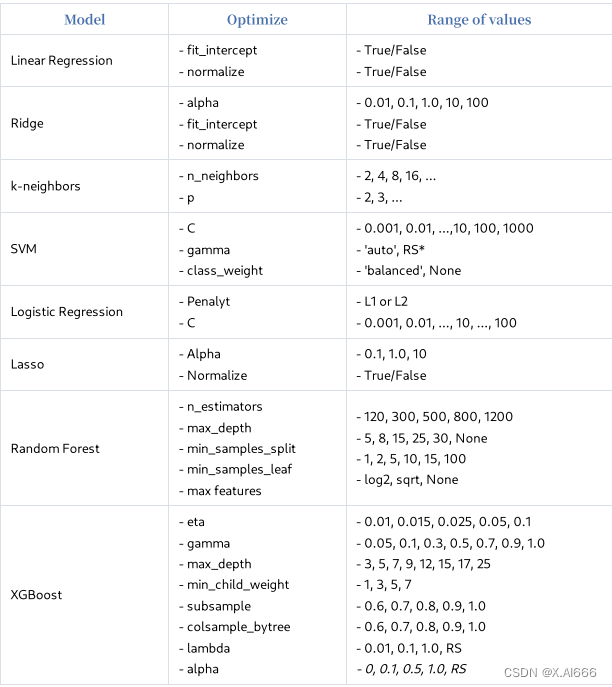
【解决(几乎)任何机器学习问题】:超参数优化篇(超详细)
这篇文章相当长,您可以添加至收藏夹,以便在后续有空时候悠闲地阅读。 有了优秀的模型,就有了优化超参数以获得最佳得分模型的难题。那么,什么是超参数优化呢?假设您的机器学习项⽬有⼀个简单的流程。有⼀个数据集&…...

面试计算机网络框架八股文十问十答第七期
面试计算机网络框架八股文十问十答第七期 作者:程序员小白条,个人博客 相信看了本文后,对你的面试是有一定帮助的!关注专栏后就能收到持续更新! ⭐点赞⭐收藏⭐不迷路!⭐ 1)UDP协议为什么不可…...

蚂蚁百灵 Ring-2.6-1T 开源解析:万亿级思考模型如何实现「按需推理」
引言 2026年5月,蚂蚁百灵团队正式开源了其旗舰级思考模型 Ring-2.6-1T,这是一款拥有万亿参数的推理模型,在 AIME 2026 数学竞赛基准测试中取得了 95.83分 的惊人成绩,一跃成为国产开源 Agent 模型的新里程碑。更值得关注的是,该模型首次引入了 可调节的 Reasoning Effort…...

别再手动改参数了!用Fluent 2023R1的Parametric模块,5分钟搞定N个工况的批量仿真
Fluent 2023R1参数化模块实战:从单点仿真到智能设计空间探索 在计算流体动力学(CFD)领域,工程师们常常需要面对一个现实困境:如何高效完成数十种工况的参数扫描?传统手动修改边界条件的方式不仅耗时费力&am…...

【工具实战】告别网页操作:利用Alist+Rclone打造无缝云盘本地化体验
1. 为什么需要云盘本地化? 每次想从网盘下载文件都要打开浏览器、登录账号、找到文件、点击下载,这一套流程走下来至少得花两三分钟。更别提上传大文件时网页端动不动就卡死,或是遇到网络波动导致传输中断的糟心体验。我去年整理家庭照片时就…...

ESJsonFormat-Xcode与MJExtension完美结合:构建高效iOS数据模型
ESJsonFormat-Xcode与MJExtension完美结合:构建高效iOS数据模型 【免费下载链接】ESJsonFormat-Xcode 将JSON格式化输出为模型的属性 项目地址: https://gitcode.com/gh_mirrors/es/ESJsonFormat-Xcode ESJsonFormat-Xcode是一款专为iOS开发者打造的JSON转模…...

5 分钟快速上手 hoist-non-react-statics:提升组件静态属性的完整教程
5 分钟快速上手 hoist-non-react-statics:提升组件静态属性的完整教程 【免费下载链接】hoist-non-react-statics Copies non-react specific statics from a child component to a parent component 项目地址: https://gitcode.com/gh_mirrors/ho/hoist-non-reac…...
)
What Are You Talking About(HDU- P1075)
伊格纳修斯真是走了狗屎运,昨天居然遇到了火星人!可惜他完全听不懂火星人的语言。临走时,火星人给了他一本火星历史书和一本词典。现在伊格纳修斯想把这本历史书翻译成英语,你能帮帮他吗?输入本题只有一组测试数据&…...

白盒测试覆盖题
先贴完整逻辑代码java运行if (温度 < 高温值 && 温度 > 低温值) {显示正常温度; // 分支1 } else {if (温度 > 高温值) {高温报警; // 分支2} else {低温报警; // 分支3}蜂鸣警报; // 分支4 }先定义 3 个条件A:温度<高温值B&am…...

告别无声直播!OBS实时字幕插件终极指南:5分钟让直播无障碍
告别无声直播!OBS实时字幕插件终极指南:5分钟让直播无障碍 【免费下载链接】OBS-captions-plugin Closed Captioning OBS plugin using Google Speech Recognition 项目地址: https://gitcode.com/gh_mirrors/ob/OBS-captions-plugin 还在为直播观…...

Cyber Engine Tweaks终极指南:3步解锁赛博朋克2077的完整定制体验
Cyber Engine Tweaks终极指南:3步解锁赛博朋克2077的完整定制体验 【免费下载链接】CyberEngineTweaks Cyberpunk 2077 tweaks, hacks and scripting framework 项目地址: https://gitcode.com/gh_mirrors/cy/CyberEngineTweaks 你是否想让《赛博朋克2077》运…...

2026年公司文化专题片拍摄公司排行榜:行业深度解析
引言随着企业对品牌传播和文化建设的重视程度不断提升,公司文化专题片成为展示企业形象、传递核心价值观的重要手段。越来越多的企业开始关注如何通过高质量的专题片来提升品牌形象和企业文化影响力。本文将深入分析2026年公司文化专题片拍摄行业的趋势,…...