基于AI Agent探讨:安全领域下的AI应用范式
先说观点:关于AI应用,通常都会聊准召。但在安全等模糊标准的场景下,事实上不存在准召的定义。因此,AI的目标应该是尽可能的“像人”。而想要评价有多“像人”,就先需要将人的工作数字化。而AI Agent是能够将数字化、自动化、智能化这几个转变过程相对顺畅衔接起来的一种框架。
0、为什么GPT让大家感到兴奋
单纯从能力上看,针对特定的任务,GPT是不如各种已有能力的:
-
执行加减乘除、排序、去重等任务,GPT远不如各种脚本和工具来得靠谱。当任务相对简单时,还能够应付,一旦复杂度增加,GPT就会出现各种异常,比如:大数计算、长文本任务等。
-
强监督任务,即使复杂度极高,比如下围棋,AlphaGo早就通过深度学习能力打败了人类,单纯GPT肯定是比敌AlphaGo的。尽管AlphaGo取得了如此高的成就,但带来了反响并没有GPT热烈。

在细分领域能力并不强的情况下,为什么GPT带来如此大的跨圈影响?ChatGPT功不可没,他呈现的“对话”这一交互形式,大幅度降低了AI的体验门槛,拉近了人与AI的距离。而能够支撑“对话”这种交互模式,其实也代表了GPT的一些能力特性:
-
更宽松的输入和输出兼容:过往的AI通常都会要求特定格式的输入和输出,比如输入一堆特征,输出一个0和1的结果。而GPT的生成式能力,让输入输出可以变得十分随意。
-
具备较强的通识:ChatGPT选用的“大力出奇迹”方式,增大参数量和训练集,也使得自身具备了足够多的知识储备,能够zero-shot应对大部分问答场景。
因此,以GPT为代表的大模型,相当于一个“宽而浅”的智能体。承担简单任务时,其灵活性会大幅度提升工作效率,但如果承担复杂工作,则往往不会给到有效的反馈。
1、AI Agent简介
那怎么提升LLM的能力深度呢?
最直接的方法是提供更多专项领域内的数据进行训练or微调,但成本会相对较高,也未必会取得正向效果,新的知识输入可能会导致模型遗忘已有的关键知识。
在Prompt中提供更多的上下文数据,是更直接的思路。
-
比如GPT不知道新发生的事情,那就拼接一个搜索插件,在提问的时候,把查询的最新内容放到Prompt中,这样GPT就能将其作为参考来回答问题。
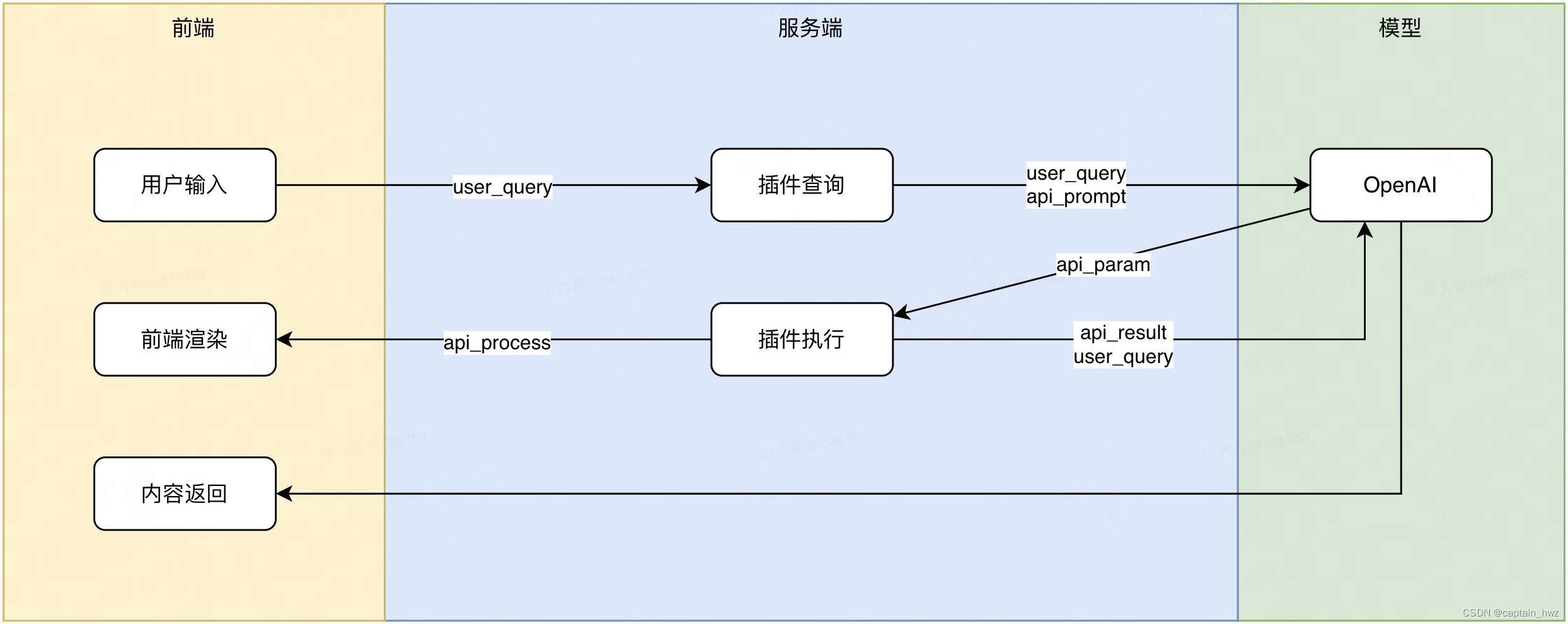
- 比如GPT不知道一些领域内的知识,那就提供一个知识库,在提问的时候,先在知识库中检索相关的知识放到Prompt中,这样GPT就能够将知识库作为参考来回复。
这种通过外部力量增强模型能力的做法,就属于AI Agent的简单形态。
AI Agent的学术定义如下:
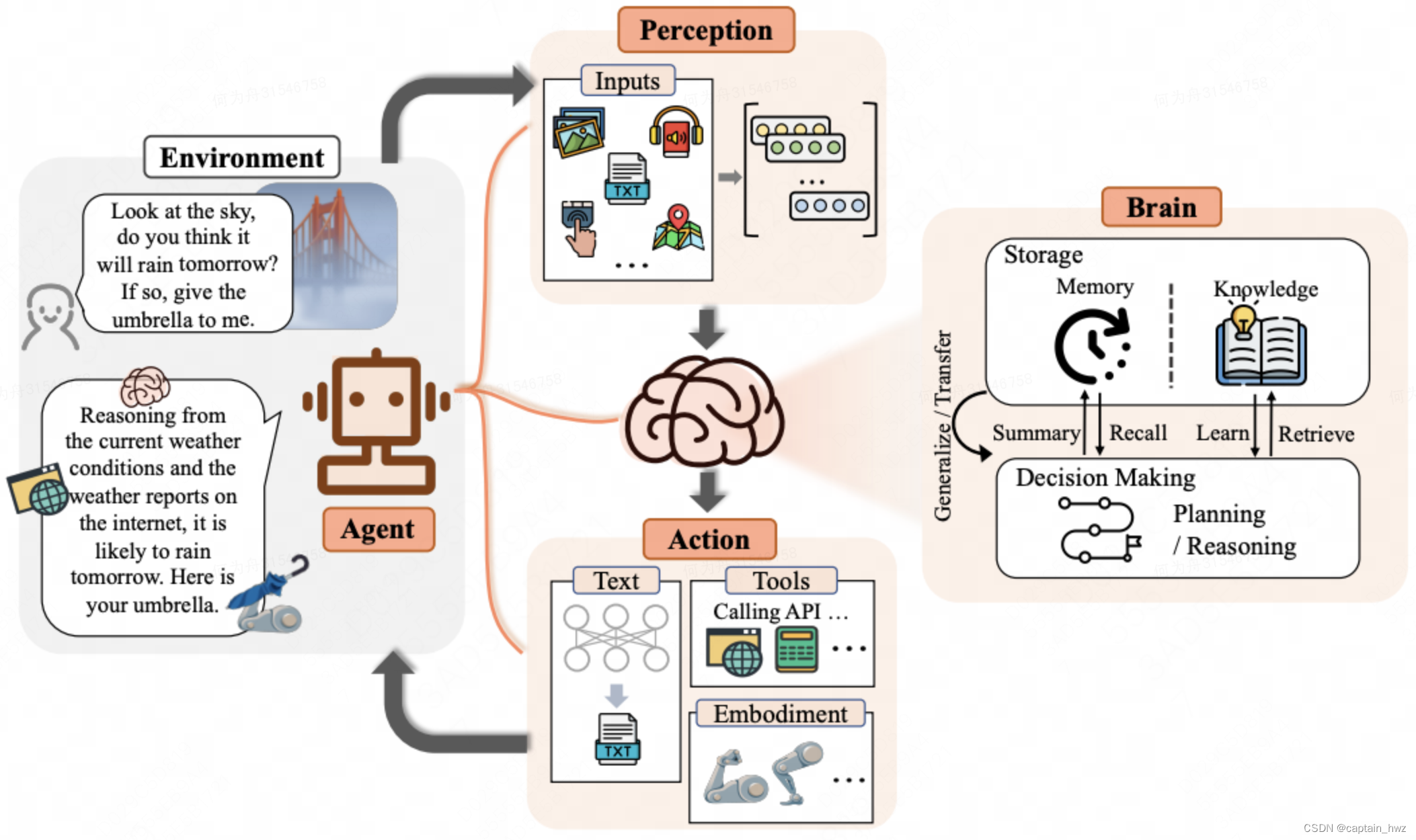
Xi, Zhiheng, et al. "The rise and potential of large language model based agents: A survey." arXiv preprint arXiv:2309.07864 (2023).
AI Agent由大脑(Brain)、感知(Perception)、行动(Action)三个部分组成。作为控制器,大脑模块承担记忆、思考和决策等基本任务;感知模块负责感知和处理来自外部环境的多模态信息;行动模块负责使用工具执行任务并影响周围环境。Agent的内部信息通路是Perception->Brain->Action构成的一个循环:接受到某个任务后,大脑先做出规划,然后根据当前阶段决策需要做出哪些动作;感知到这些动作的反馈后,结合历史记忆,做出下一步决策。
Agent和playbook的概念其实很接近,或者跟进一步说,“有限状态机”本身就是一种Agent的体现。而这其中的主要差别在于,AI Agent不倾向提前定义好明确的SOP,而是让AI根据已知的情况自主判断,做出决策和下一步动作。

那为什么LLM给Agent带来了新的活力呢?因为定义过程其实是一件很难的事情:购物的时候如何挑选合适的商品、下棋的时候如何决策下一步、投资的时候选取有潜力的目标,等等。随着事件类型和特征的丰富程度增加,人来决策的直觉性越来越强,将其抽象为一个代码实现的过程也更加困难。而LLM的通识性和逻辑性,恰好能规避掉这个过程。
从另一方面来说,当前阶段的LLM不擅长完成复杂任务,但大量研究发现其具备CoT能力:通过将复杂任务进行拆解,逐步完成,能够大幅提升最终的成功率。而Agent则是一个CoT的合适载体。
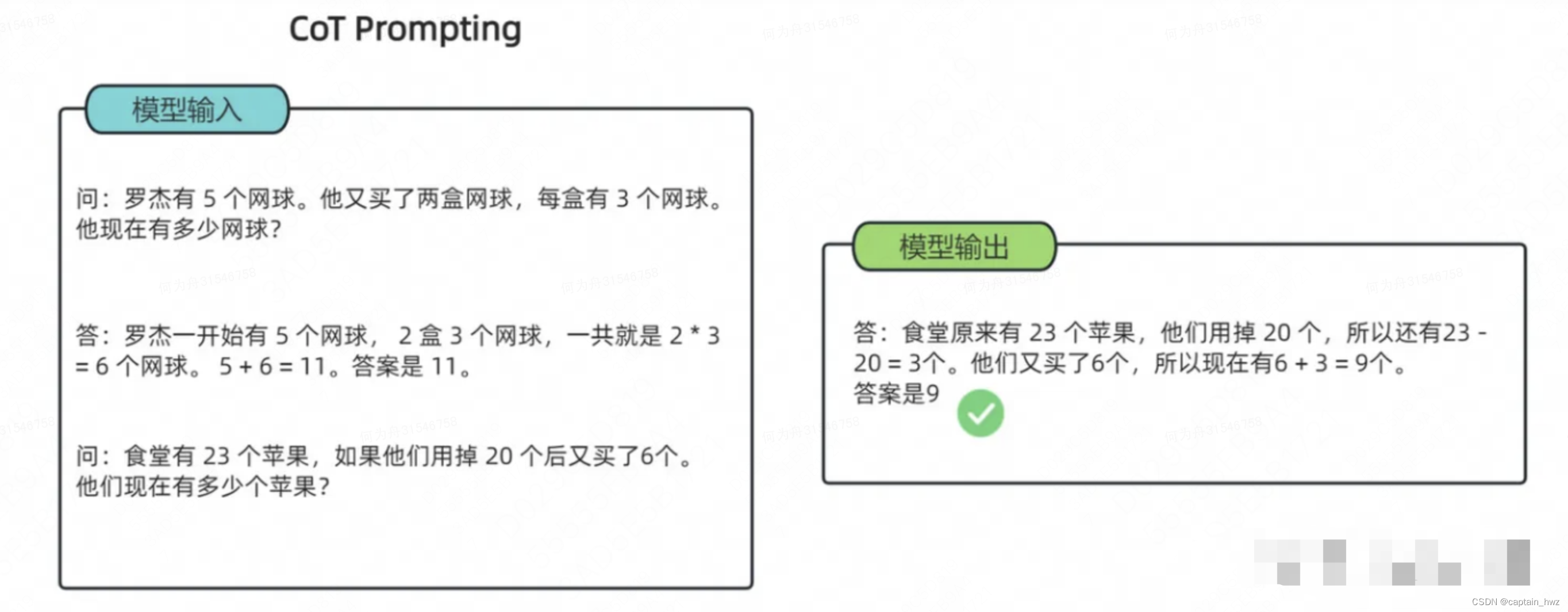
因此,LLM和Agent起到了相互促进的作用。
2、安全领域下的算法应用
安全的特点是对bad case极度敏感。所以安全更讲究逻辑,不讲究概率。
比如特斯拉发生一起事故,如果只是讲概率,特斯拉已经安全行驶百万公里,事故率低于0.0001%,而你就是不幸被小概率命中的那波人。尽管都是客观公正的事实,但数字过于冰冷,并无法说服人们的赢得信任。所有要做的其实是还原事故过程,让人们认为特斯拉作为汽车厂商该做的都做了,才有可能平息质疑。
而过去算法的应用本质上都属于概率学的呈现(比如推荐你大概率会感兴趣的商品),因此很难在安全场景下得到大规模的使用,仅在部分风险可接受的场景下呈现出了积极的发展态势。如人脸识别支付,哪怕识别错了,用其他人的账户完成了支付,厂商仅需要进行对应损失的赔付即可,从整体概率上是可接受的。

在ChatGPT刚火热的时候,我一度认为Copilot是解决这一困境的方法:算法不再做决策,只是提供建议,最终还是由人来做决策。但使用一段时间后,能够明显感觉到直接讲GPT作为Copilot能提供的帮助是有限的:
-
面对简单的场景,写段脚本、写个复杂SQL等,GPT能够较好的执行结果,能够有效替代大量搜索引擎工作。
-
面对复杂的决策场景,GPT通常只能接收到有限的信息,也缺乏历史经验的输入,几乎给不到有效的建议。
这让我想起了《萨利机长》中,机长在处理应急事件时的过程:在飞机因为鸟类撞击导致引擎失灵,副机长立即拿出了QRH(Quick Reference Handbook),找到对应章节,开始按照上面的操作步骤开始处理。在副机长执行了十几项动作后(据说大约有三页,但连第一页都没过完),机长一边check,一边做出了决策:降落哈德逊河 —— 一个完全超脱手册的判断,副机长一脸震惊。

这其实反映了安全行业特别有意思的一个现象:无论如何完备标准化处置能力,最终都还是会依靠人来完成最终决策。
而AI Agent能够在安全领域有什么帮助?它能将一个复杂任务拆分,既有利于观测过程,也有利于明确处理任务。
3、基于Agent的AI应用范式
首先,需要定义一下应用AI的目标。我认为是:尽可能模拟安全专家的决策过程,而不是追求更高的准召率。
安全本身就缺乏明确的定义,一起事件是入侵还是误报,最终还是需要交由人来决策。当安全专家穷尽各种方法也无法做出正确判断时,无法想象AI能够做出更准确的判断。因此,准召只能是AI应用的一个参照性指标,我们最终希望评判的还是,AI有多像人。
这个过程大体会分为几步:
1)所有动作的API化
Agent的重要特性之一就是能够于环境交互,具备灵活的输入输出能力,即感知(Perception)和行动(Action)部分。而将安全专家的各类操作API化,将是落地Agent的过程中工作量最大的一环。大概会需要经过一次内部的头脑风暴,把可能需要进行的操作给盘点出来。
以审查一次Web安全告警为例,可能会需要:
-
查询来源IP的归属,判断是否恶意;
-
查询当前业务的属性,是否安全相关;
-
查询内部组织架构,判断IP和业务之间的相关性;
-
查询该业务的过往请求,判断是否正常操作;
-
查询该IP的后续请求,判断是否有进一步异常动作;
-
查询告警规则,判断是否符合规则预期;
-
进行尝试性封禁,判断攻击是否被阻断;
-
获取近期客诉,判断是否存在误伤;
-
……
这其中任何一环都可能是影响最终决策的关键信息输入,因此必须保障AI Agent具备主动查询并获取相应信息的能力。
2)过往记录初步形成知识库
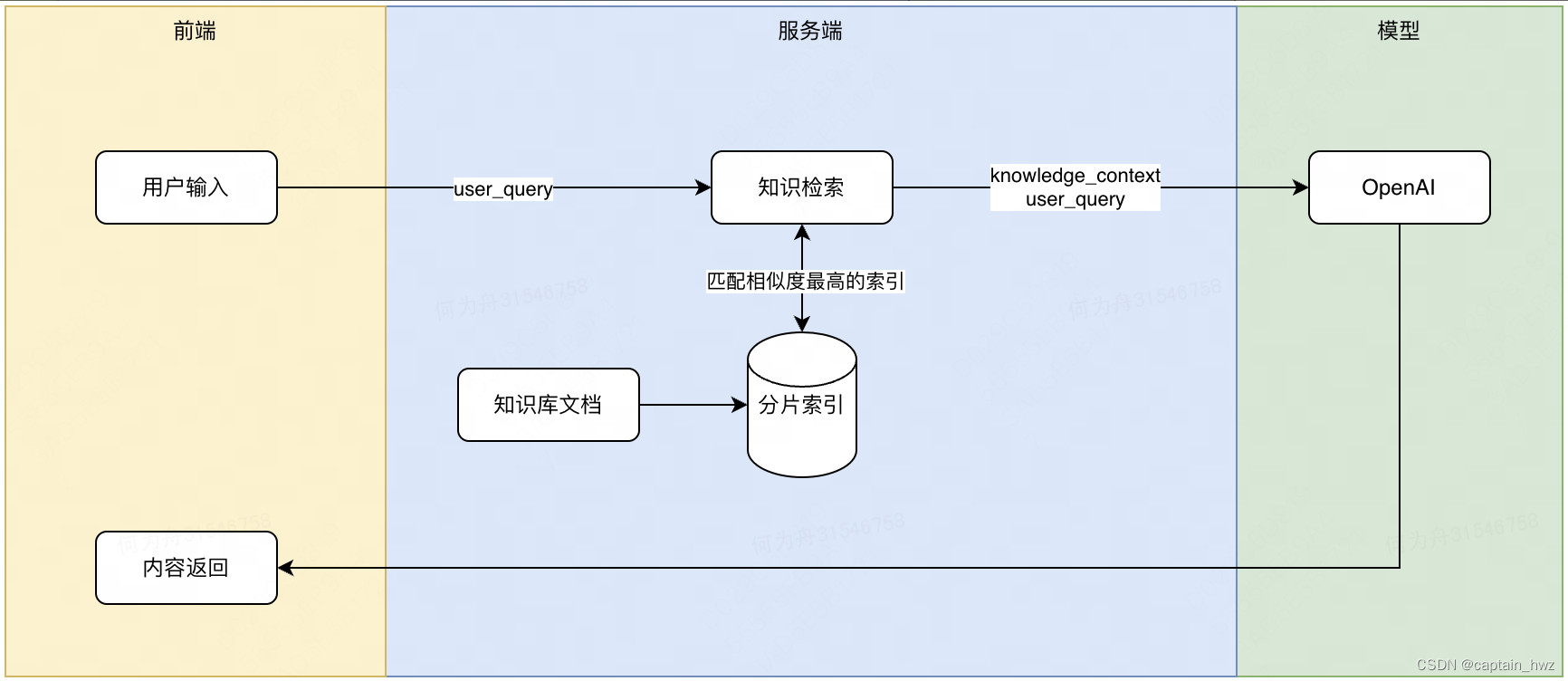
团队内部经过长期运营沉淀下来的经验是十分宝贵的,摒弃这部分数据从0开始使用Agent就过于浪费了。因此,第二步是想办法将过去的零散知识汇总起来,变成Agent可以快速学习和参考的知识库。相对价值比较高的内容包括:已有的SOP、处理记录/复盘报告、数据查询报表、接口文档和案例等。
知识库的检索能力会决定AI Agent的能力上限。
知识库的官方称呼为RAG(Retrieval-Augmented Generation),比较经典的RAG实现为LangChain-Chatchat。大致原理如下:
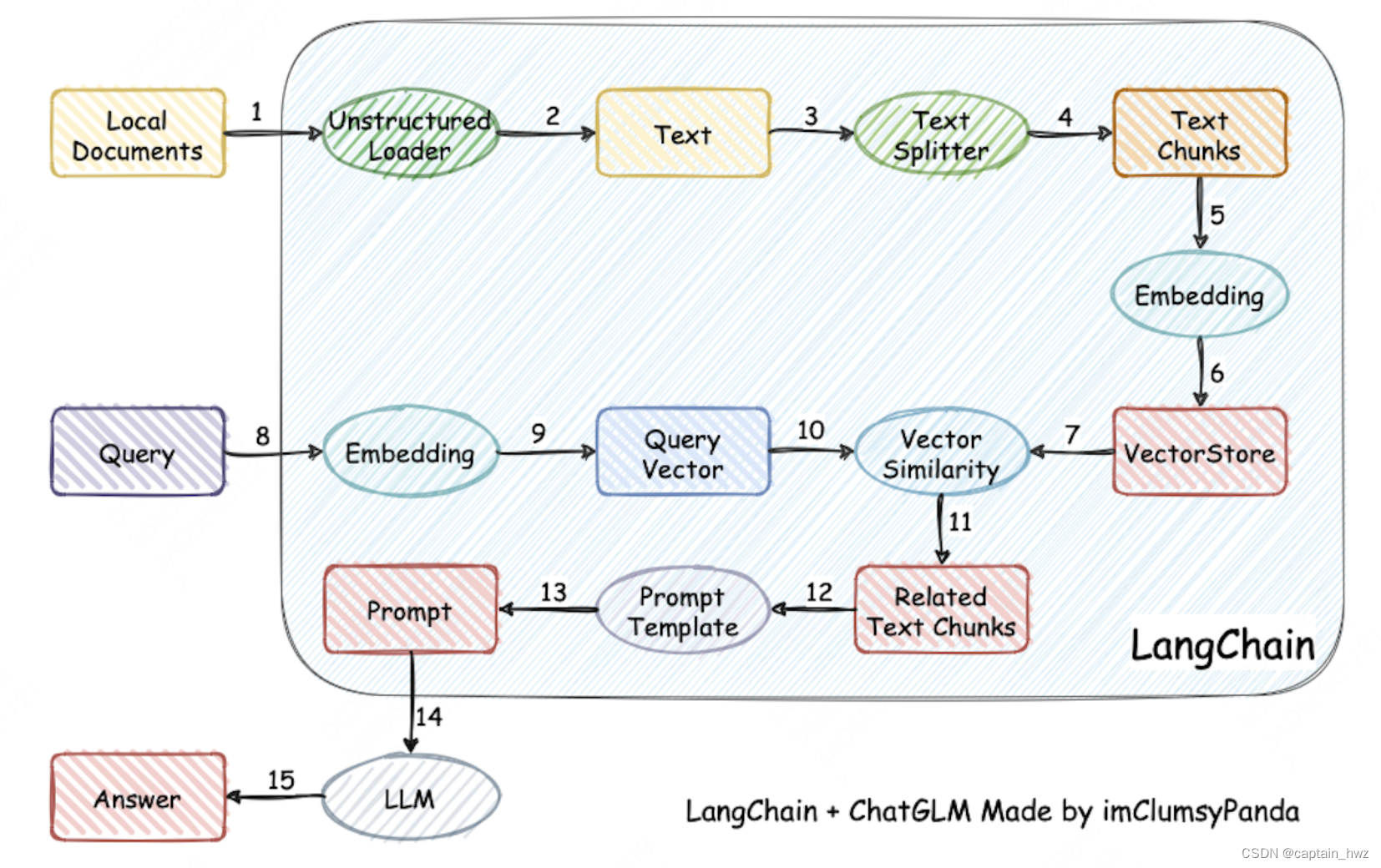
更理想的RAG,应当能够根据人类的思维模式来进行分类检索。比如当你接到一项任务的时候,大致会尝试在脑海中检索两部分内容:相关的理论基础、相关的过往案例。基于这两部分内容,再结合通识逻辑进行推理,通常能够做出正确的决策来。
3)指导性的运营平台
AI Agent一定需要人工交互,才能够获得反馈,持续迭代自身。
总体来说,AI Agent的运算过程仍然是黑盒的,因此需要设定一些节点,让AI Agent主动跳出循环,等待安全专家的反馈,包括:规划设定、关键控制流、最终结果。在观看其他行业的AI Agent应用分享时,下图所示的人和AI的合作分工,我认为是比较符合预期的:
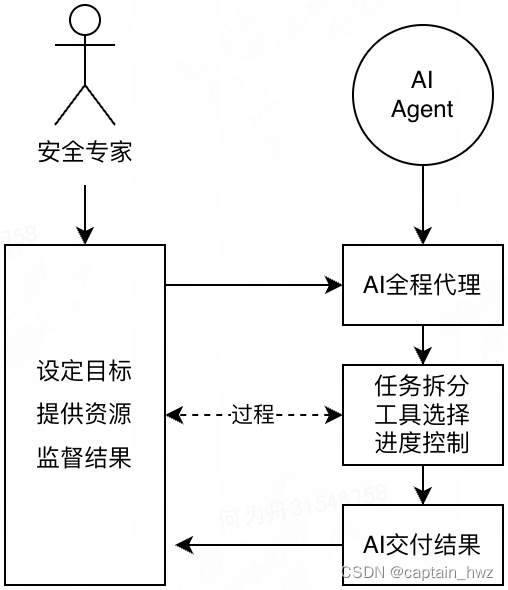
这个过程中,降低交互成本是需要核心考虑的因素。基于ChatGPT的成功,对话几乎是必然的一种形态。
4)可修正的处理记录
最后,需要让AI Agent对每次任务的处理过程进行摘要记录,并且人工对其中的偏差进行修正,形成一个完整的案例报告。
这个案例报告会被录入到知识库中,当AI Agent下次处理相似的任务时,会被检索出来,使得AI Agent会按照相似的逻辑进行处理。
总结来说,完整的AI Agent大致会长这样:
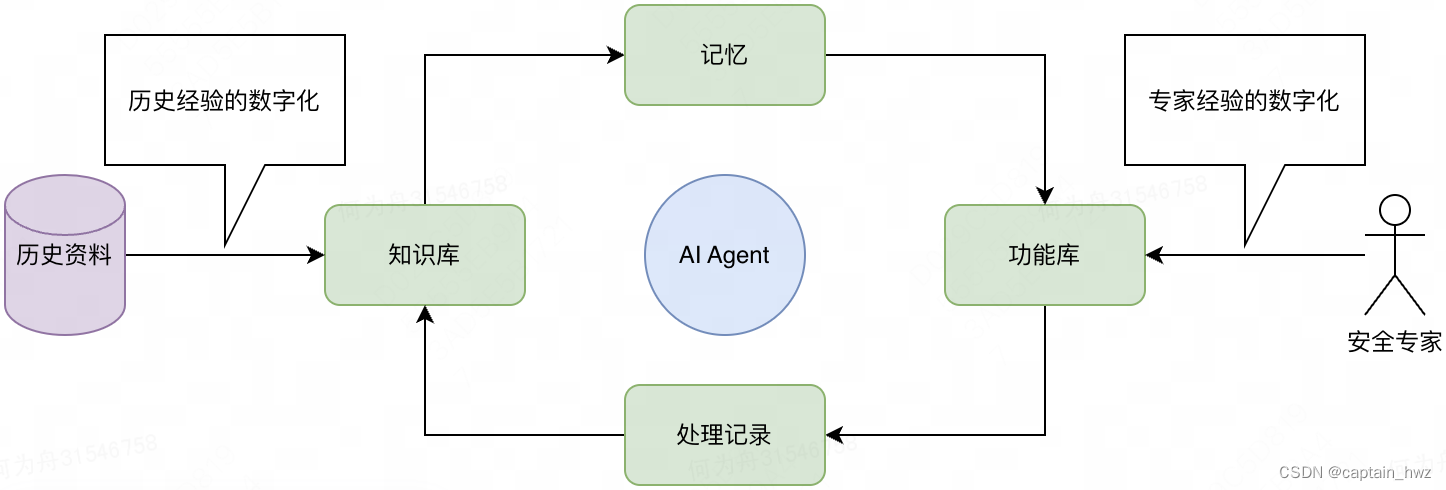
有了以上这些框架之后,AI Agent的雏形就基本具备了:1)能够在安全专家的指导下,完成特定的任务处理;2)能够将日常处理过程记录下来。
这个阶段,AI Agent的表现可能并不如预期,但随着记忆的不断积累,以及持续优化记忆检索的模式(如处理任务时,将匹配度最高、最成功的历史处理记录捞出来),AI Agent就可以进入持续学习领域知识,持续提升自身能力的正向循环。
4、Agent的正向意义
对Agent的正向意义再做一轮强调。
AI的目标是:尽可能模拟安全专家的决策过程,而不是追求更高的准召率。因此,不应当期望Agent落地之后,能够带来额外的能力增益。由于历史经验的不足,Agent甚至对提效的帮助也不会特别显著。
这个过程中,最大的意义,其实是促进日常工作的数字化。而只有数字化的程度足够高,才能够形成有效的经验积累,带动整个团队提升。
在没有Agent之前,大家其实也都在往这个方向努力。比如:
-
投简历时,公司提供了极细致的简历模版(学历、年龄、工作经历、奖项等),让求职者填写各种标准字段;
-
面试时,公司将能力考核项一项项列出来(专业能力、沟通能力、综合潜力等),要求面试官填写;
-
事件复盘时,公司提供了用于刨根究底的复盘模版(事件发生时间、响应时间、止损时间、恢复时间等);
-
……
但不得不承认的是,人工填写这些表单,是一件极其annoying的工作。因此,人性使然下,大家总是会耍各种小聪明,来降低这部分工作负担。最终往往导致,貌似有一个非常全面的机制,但执行质量却差强人意。
而AI Agent的出现,可以通过“对话”等形式,大幅度降低这部分工作的精力成本。个人认为,这才是AI Agent的最大意义。
5、结语
AI的发展大体是一个从简单白盒到复杂黑盒的过程,比如:从传统机器学习到深度学习、从RNN的标准Encoder-Decoder模式到GPT直接Decoder-only引领潮流。降低AI的应用和理解门槛,本身也是AI发展的重要趋势之一。
AI Agent似乎是让决策过程再次变得白盒。但细细品味,AI Agent实际上是将AI应用拔高了一个层面:过去只处理单个任务,现在要处理复杂作业,因此需要CoT的支撑。
大胆猜测,未来会出现一个通用的AI Agent(GPTs已经接近这个状态),大幅度降低AI Agent的落地门槛。随之而来,会出现多个Agent的协作机制:一个Agent扮演高阶决策者,其他Agent扮演不同的职能角色,进一步提升AI处理任务的复杂性。
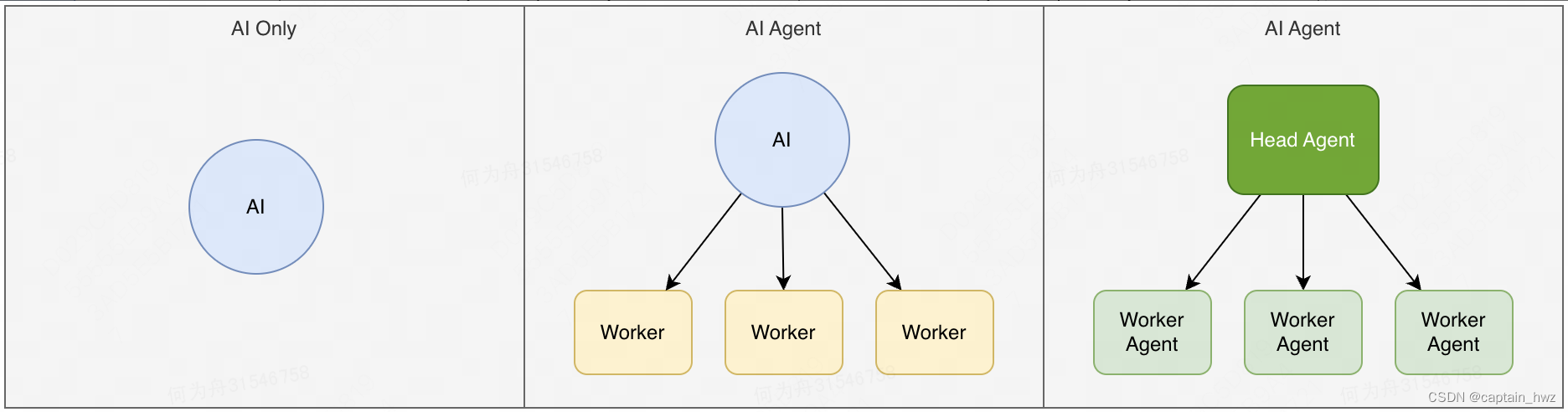
就仿佛是一个公司的发展历程:单兵作战 -> 小团队作战 -> 多级管理团队。
相关文章:
基于AI Agent探讨:安全领域下的AI应用范式
先说观点:关于AI应用,通常都会聊准召。但在安全等模糊标准的场景下,事实上不存在准召的定义。因此,AI的目标应该是尽可能的“像人”。而想要评价有多“像人”,就先需要将人的工作数字化。而AI Agent是能够将数字化、自…...
Stable Diffusion 模型下载:ToonYou(平涂卡通)
本文收录于《AI绘画从入门到精通》专栏,专栏总目录:点这里。 文章目录 模型介绍生成案例案例一案例二案例三案例四案例五案例六案例七案例八案例九案例十...
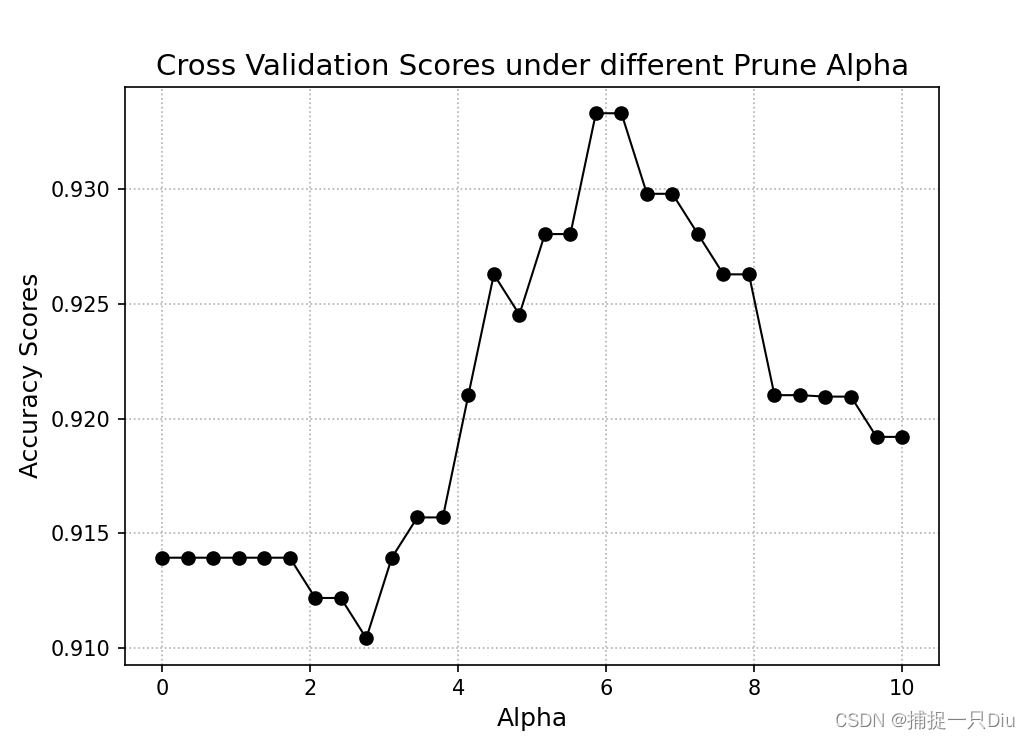
机器学习:分类决策树(Python)
一、各种熵的计算 entropy_utils.py import numpy as np # 数值计算 import math # 标量数据的计算class EntropyUtils:"""决策树中各种熵的计算,包括信息熵、信息增益、信息增益率、基尼指数。统一要求:按照信息增益最大、信息增益率…...

红队打靶练习:HACK ME PLEASE: 1
信息收集 1、arp ┌──(root㉿ru)-[~/kali] └─# arp-scan -l Interface: eth0, type: EN10MB, MAC: 00:0c:29:69:c7:bf, IPv4: 192.168.61.128 Starting arp-scan 1.10.0 with 256 hosts (https://github.com/royhills/arp-scan) 192.168.61.2 00:50:56:f0:df:20 …...
《VulnHub》GoldenEye:1
title: 《VulnHub》GoldenEye:1 date: 2024-02-16 14:53:49 updated: 2024-02-16 15:08:49 categories: WriteUp:Cyber-Range excerpt: 主机发现、目标信息扫描、源码 js 文件泄露敏感信息、hydra 爆破邮件服务(pop3)、邮件泄露敏…...
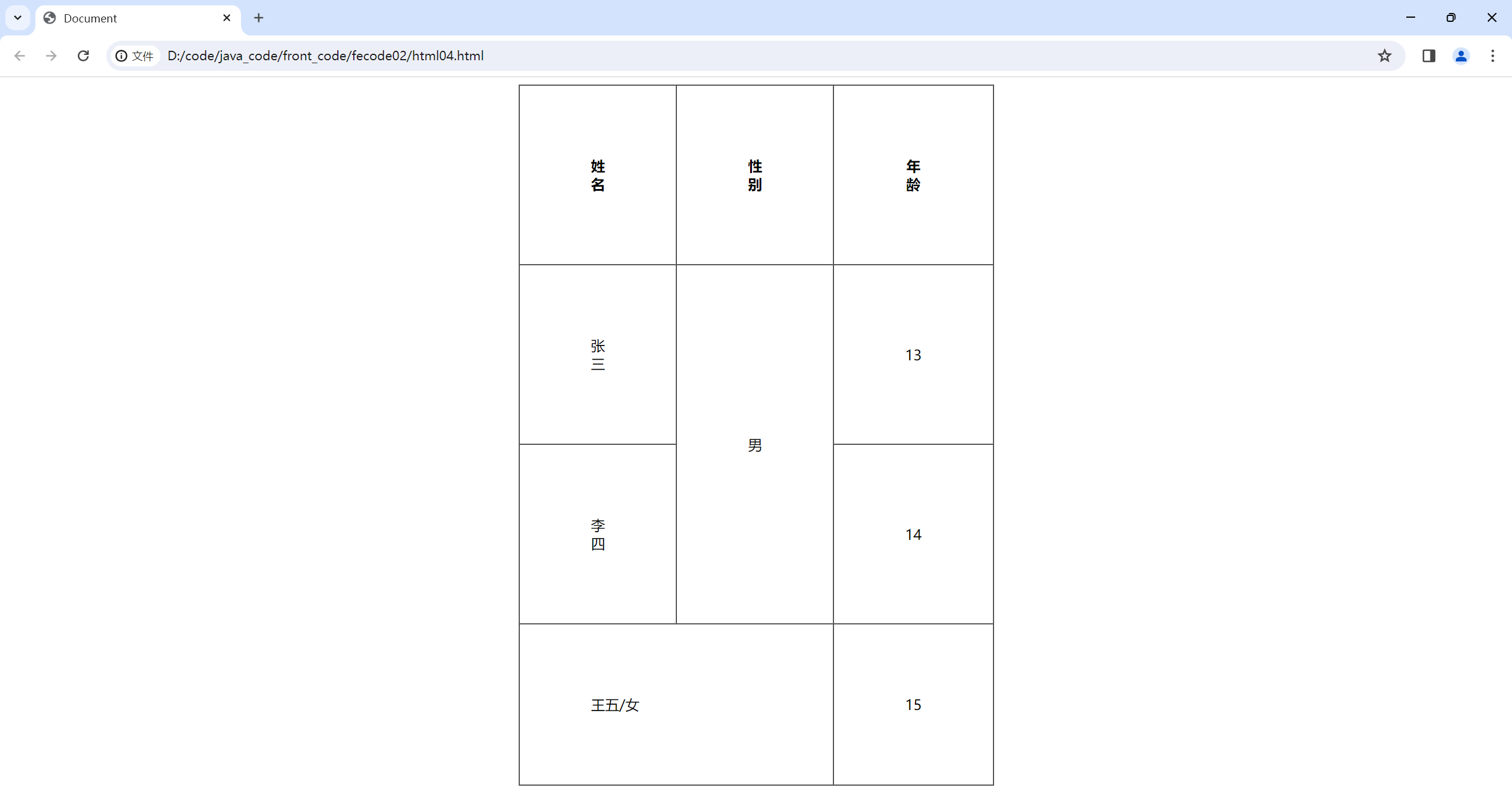
html的表格标签
html的表格标签 table标签:表示整个表格tr:表示表格的一行td:表示一个单元格th:表示表头单元格.会居中加粗thead:表格的头部区域 (注意和th区分,范围是比th要大的).tbody:表格得到主体区域. table包含tr , tr包含td或者th. 表格标签有一些属性,可以用于设置大小边…...
2022省赛真题:展开你的扇子)
蓝桥杯(Web大学组)2022省赛真题:展开你的扇子
思路: transform-origin: center bottom;使盒子旋转时,以底部的中心为坐标原点(题目已给出) 对每个盒子使用transform: rotate();实现旋转 笔记: 设置悬浮旋转时, #box div:hover #item6{ } 为什…...
复习基础知识1
局部变量 写程序时,程序员经常会用到局部变量 汇编中寄存器、栈,可写区段、堆,函数的局部变量该存在哪里呢? 注意:局部变量有易失性 一旦函数返回,则所有局部变量会失效。 考虑到这种特性,人们…...

java8-用流收集数据-6
本章内容口用co1lectors类创建和使用收集器 口将数据流归约为一个值 口汇总:归约的特殊情况 数据分组和分区口 口 开发自己的自定义收集器 我们在前一章中学到,流可以用类似于数据库的操作帮助你处理集合。你可以把Java8的流看作花哨又懒惰的数据集迭代器。它们…...

[前端开发] JavaScript基础知识 [上]
下篇:JavaScript基础知识 [下] JavaScript基础知识 [上] 引言语句、标识符和变量JavaScript引入注释与输出数据类型运算符条件语句与循环语句 引言 JavaScript是一种广泛应用于网页开发的脚本语言,具有重要的前端开发和部分后端开发的应用。通过JavaSc…...
初识Qt | 从安装到编写Hello World程序
文章目录 1.前端开发简单分类2.Qt的简单介绍3.Qt的安装和环境配置4.创建简单的Qt项目 1.前端开发简单分类 前端开发,这里是一个广义的概念,不单指网页开发,它的常见分类 网页开发:前端开发的主要领域,使用HTML、CSS …...
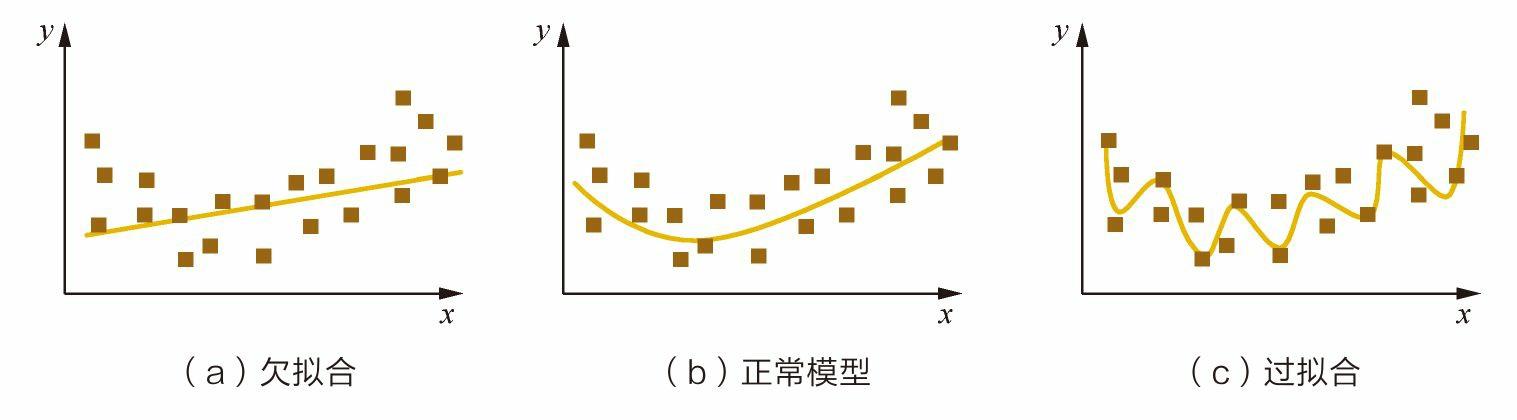
机器学习:过拟合和欠拟合的介绍与解决方法
过拟合和欠拟合的表现和解决方法。 其实除了欠拟合和过拟合,还有一种是适度拟合,适度拟合就是我们模型训练想要达到的状态,不过适度拟合这个词平时真的好少见。 过拟合 过拟合的表现 模型在训练集上的表现非常好,但是在测试集…...

变分自编码器(VAE)PyTorch Lightning 实现
✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。 🍎个人主页:小嗷犬的个人主页 🍊个人网站:小嗷犬的技术小站 🥭个人信条:为天地立心&…...

设备驱动开发_1
可加载模块如何工作的 主要内容 描述可加载模块优势使用模块命令效率使用和定义模块密钥和模块工作1 描述可加载模块优势 开发周期优势: 静态模块在/boot下的vmlinuz中,需要配置、编译、重启。 开发周期长。 LKM 不需要重启。 开发周期优于静态模块。 2 使用模块命令效率…...
知识点精要解析)
C语言位域(Bit Fields)知识点精要解析
在C语言中,位域(Bit Field)是一种独特的数据结构特性,它允许程序员在结构体(struct)中定义成员变量,并精确指定其占用的位数。通过使用位域,我们可以更高效地利用存储空间࿰…...

离散数学——图论(笔记及思维导图)
离散数学——图论(笔记及思维导图) 目录 大纲 内容 参考 大纲 内容 参考 笔记来自【电子科大】离散数学 王丽杰...
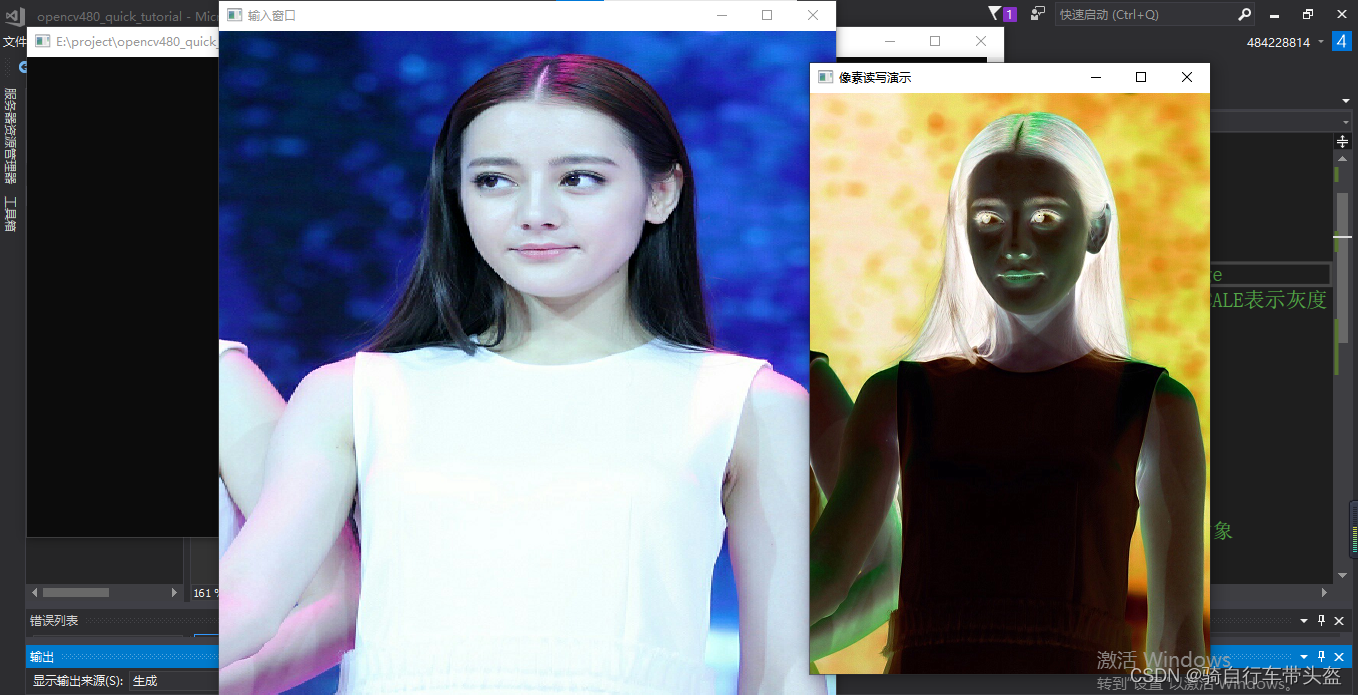
opencv图像像素的读写操作
void QuickDemo::pixel_visit_demo(Mat & image) {int w image.cols;//宽度int h image.rows;//高度int dims image.channels();//通道数 图像为灰度dims等于一 图像为彩色时dims等于三 for (int row 0; row < h; row) {for (int col 0; col < w; col) {if…...

Java学习第十四节之冒泡排序
冒泡排序 package array;import java.util.Arrays;//冒泡排序 //1.比较数组中,两个相邻的元素,如果第一个数比第二个数大,我们就交换他们的位置 //2.每一次比较,都会产生出一个最大,或者最小的数字 //3.下一轮则可以少…...

第1章 计算机网络体系结构-1.1计算机网络概述
1.1.1计算机网络概念 计算机网络是将一个分散的,具有独立功能的计算机系统通过通信设备与路线连接起来,由功能完善的软件实现资源共享和信息传递的系统。(计算机网络就是一些互连的,自治的计算机系统的集合) 1.1.2计算机网络的组成 从不同角…...

蓝桥杯:C++排序
排序 排序和排列是算法题目常见的基本算法。几乎每次蓝桥杯软件类大赛都有题目会用到排序或排列。常见的排序算法如下。 第(3)种排序算法不是基于比较的,而是对数值按位划分,按照以空间换取时间的思路来排序。看起来它们的复杂度更好,但实际…...

从特征稀缺到精准定位:基于HS-FPN与可变形注意力的白细胞检测新范式
1. 白细胞检测的现状与挑战 在医学影像分析领域,白细胞检测一直是个让人头疼的问题。想象一下,医生需要从密密麻麻的血细胞图像中找出白细胞,就像在沙滩上找特定形状的贝壳一样困难。传统方法主要依赖医生手动操作显微镜,不仅效率…...

STM32驱动WS2812灯珠颜色错乱?可能是你的GRB顺序和位序搞反了!
STM32驱动WS2812灯珠颜色错乱?GRB顺序与位序的深度解析 当你第一次用STM32成功点亮WS2812灯珠时,那种成就感难以言表。但紧接着,你可能遇到了一个令人困惑的问题:明明在代码里设置了纯红色(255, 0, 0)&…...

DeepSeek总结的CloudNativePG 与 Crunchy PGO:一个诚实且带有主观见解的比较
来源:https://www.gabrielebartolini.it/articles/2026/05/cloudnativepg-and-crunchy-pgo-an-honest-opinionated-comparison/ CloudNativePG 与 Crunchy PGO:一个诚实且带有主观见解的比较 作者: Gabriele Bartolini 日期: 2026年5月18日 目录 Crunchy…...
)
洛谷P7071 ‘优秀的拆分’背后:如何用对拍程序验证你的C++代码正确性(附Win10批处理脚本)
洛谷P7071 优秀的拆分背后:如何用对拍程序验证你的C代码正确性(附Win10批处理脚本) 在编程竞赛中,写出能通过样例的代码只是第一步。真正考验选手的是代码在各种边界条件下的稳定性。很多选手都有这样的经历:提交代码后…...

生物 --- 免疫力
1、免疫的概念免疫是人体的一种生理功能。识别“自己”和“非己”。破坏和排斥进入人体内的抗原物质,如病原体。指机体识别和清除外来入侵抗原及体内突变或衰老细胞,并维持自身内环境稳定的生理功能。2、免疫系统的构成免疫系统主要由免疫器官、免疫细胞…...

峡谷焕新:用R3nzSkin解锁英雄联盟个性化游戏体验
峡谷焕新:用R3nzSkin解锁英雄联盟个性化游戏体验 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 在英雄联盟的召唤师峡谷中,每一…...
)
JavaFX程序打包exe的两种实战方案对比:exe4j vs jlink+launch4j(含体积优化技巧)
JavaFX程序打包exe的两种实战方案对比:exe4j vs jlinklaunch4j(含体积优化技巧) 对于JavaFX开发者而言,将精心开发的程序打包成可执行的exe文件是产品交付的关键一步。面对市面上多种打包工具和方案,如何选择最适合自己…...

基板式PCB与嵌入式芯片:下一代电子系统集成的核心技术解析
1. 项目概述:从一块“板子”看透一个产业干了十几年硬件,从画第一块51单片机的板子,到如今参与定义复杂的系统级封装,我越来越觉得,PCB(印制电路板)和芯片的关系,早已不是简单的“承…...

OPS-C可插拔电脑主机:模块化设计如何革新部署与运维
1. 项目概述:为什么我们需要OPS-C这样的可插拔电脑主机?如果你负责过学校机房、企业会议室或者数字标牌网络的维护,一定对传统电脑主机的部署和运维深有体会。每次设备升级或故障排查,都得钻到桌子底下,面对一堆缠绕的…...

解锁Godot游戏宝库:PCK文件解包实战指南
解锁Godot游戏宝库:PCK文件解包实战指南 【免费下载链接】godot-unpacker godot .pck unpacker 项目地址: https://gitcode.com/gh_mirrors/go/godot-unpacker 你是否曾经好奇过Godot游戏中的精美画面和动人音效是如何封装的?那些神秘的PCK文件就…...