2.13日学习打卡----初学RocketMQ(四)
2.13日学习打卡
目录:
- 2.13日学习打卡
- 一.RocketMQ之Java Class
- DefaultMQProducer类
- DefaultMQPushConsumer类
- Message类
- MessageExt类
- 二.RocketMQ 消费幂
- 消费过程幂等
- 消费速度慢的处理方式
- 三.RocketMQ 集群服务
- 集群特点
- 单master模式
- 多master模式
- 多master多Slave模式-异步复制
- 多Master多Slave模式-同步双写
- 四.RocketMQ消息消费
- 集群消费
- 广播消费
- 消息消费时的权衡
一.RocketMQ之Java Class
DefaultMQProducer类
概述
DefaultMQProducer类是应用发送消息使用的基类,封装一些通用的方法方便开发者在更多场景中使用。属于线程安全类,在配置并启动后可在多个线程间共享此对象。
其可以通过无参构造方法快速创建一个生产者,通过getter/setter方法,调整发送者的参数。主要负责消息的发送,支持同步/异步/oneway的发送方式,这些发送方式均支持批量发送。
方法
| 属性 | 内容 |
|---|---|
| DefaultMQProducerImpl defaultMQProducerImpl; | 生产者内部默认实现类 |
| String producerGroup; | Producer组名, 默认值为DEFAULT_PRODUCER。多个Producer如果属于一个应用,发送同样的消息,则应该将它们归为同一组。 |
| String createTopicKey; | 自动创建测试的topic名称, 默认值为TBW102;在发送消息时,自动创建服务器不存在的topic,需要指定Key。broker必须开启isAutoCreateTopicEnable |
| int defaultTopicQueueNums; | 创建默认topic的queue数量。默认4 |
| int sendMsgTimeout; | 发送消息超时时间,默认值10000,单位毫秒 |
| int compressMsgBodyOverHowmuch; | 消息体压缩阈值,默认为4k(Consumer收到消息会自动解压缩) |
| int retryTimesWhenSendFailed; | 同步模式,返回发送消息失败前内部重试发送的最大次数。可能导致消息重复。默认2 |
| int retryTimesWhenSendAsyncFailed; | 异步模式,返回发送消息失败前内部重试发送的最大次数。可能导致消息重复。默认2 |
| boolean retryAnotherBrokerWhenNotStoreOK; | 声明发送失败时,下次是否投递给其他Broker,默认false |
| int maxMessageSize; | 最大消息大小。默认4M; 客户端限制的消息大小,超过报错,同时服务端也会限制 |
| TraceDispatcher traceDispatcher | 消息追踪器,定义了异步传输数据接口。使用rcpHook来追踪消息 |
DefaultMQPushConsumer类
概述
DefaultMQPushConsumer类是rocketmq客户端消费者的实现,从名字上已经可以看出其消息获取方式为broker往消费端推送数据,其内部实现了流控,消费位置上报等等。DefaultMQPushConsumer是Push消费模式下的默认配置。
方法
| 字段 | 内容 |
|---|---|
| DefaultMQPushConsumerImpl defaultMQPushConsumerImpl; | 消费者实现类,所有的功能都委托给DefaultMQPushConsumerImpl来实现 |
| String consumerGroup; | 消费者组名,必须设置,参数默认值是:DEFAULT_CONSUMER (需要注意的是,多个消费者如果具有同样的组名,那么这些消费者必须只消费同一个topic) |
| MessageModel messageModel; | 消费的方式,支持以下两种 1、集群消费 2、广播消费。BROADCASTING 广播模式,即所有的消费者可以消费同样的消息CLUSTERING 集群模式,即所有的消费者平均来消费一组消息 |
| ConsumeFromWhere consumeFromWhere; | 消费者从那个位置消费,分别为:CONSUME_FROM_LAST_OFFSET:第一次启动从队列最后位置消费,后续再启动接着上次消费的进度开始消费 ;CONSUME_FROM_FIRST_OFFSET:第一次启动从队列初始位置消费,后续再启动接着上次消费的进度开始消费;CONSUME_FROM_TIMESTAMP:第一次启动从指定时间点位置消费,后续再启动接着上次消费的进度开始消费(以上所说的第一次启动是指从来没有消费过的消费者,如果该消费者消费过,那么会在broker端记录该消费者的消费位置,如果该消费者挂了再启动,那么自动从上次消费的进度开始) |
| AllocateMessageQueueStrategy allocateMessageQueueStrategy; | 消息分配策略,用于集群模式下,消息平均分配给所有客户端;默认实现为AllocateMessageQueueAveragely |
| Map<String, String> subscription; | topic对应的订阅tag |
| MessageListener messageListener; | 消息监听器 ,处理消息的业务就在监听里面。目前支持的监听模式包括:MessageListenerConcurrently,对应的处理逻辑类是MessageListener messageListener ;ConsumeMessageConcurrentlyService MessageListenerOrderly 对应的处理逻辑类是ConsumeMessageOrderlyService;两者使用不同的ACK机制。RocketMQ提供了ack机制,以保证消息能够被正常消费。发送者为了保证消息肯定消费成功,只有使用方明确表示消费成功,RocketMQ才会认为消息消费成功。中途断电,抛出异常等都不会认为成功——即都会重新投递。上面两个不同的监听模式使用的ACK机制是不一样的。 |
| OffsetStore offsetStore; | offset存储实现,分为本地存储或远程存储 。集群消费:从远程Broker获取。广播消费:从本地文件获取。 |
DefaultMQPushConsumer类
重要字段int consumeThreadMin = 20 线程池自动调整int consumeThreadMax = 64 线程池自动调整long adjustThreadPoolNumsThreshold = 100000 int consumeConcurrentlyMaxSpan = 2000单队列并行消费最大跨度,用于流控 int pullThresholdForQueue = 1000一个queue最大消费的消息个数,用于流控 long pullInterval = 0 检查拉取消息的间隔时间,由于是长轮询,所以为 0,但是如果应用为了流控,也可以设置大于 0 的值,单位毫秒,取值范围: [0, 65535]consumeMessageBatchMaxSize = 1 并发消费时,一次消费消息的数量,默认为1,假如修改为50,此时若有100条消息,那么会创建两个线程,每个线程分配50条消息。换句话说,批量消费最大消息条数,取值范围: [1, 1024]。默认是1pullBatchSize = 32 消费者去broker拉取消息时,一次拉取多少条。取值范围: [1, 1024]。默认是32 。可选配置boolean postSubscriptionWhenPull = false boolean unitMode = false 重要方法subscribe(String topic, String subExpression) 订阅某个topic,subExpression传*为订阅该topic所有消息 registerMessageListener(MessageListenerConcurrently messageListener) 注册消息回调,如果需要顺序消费,需要注册MessageListenerOrderly的实现 start 启动消息消费 Message类
含义Producer发送的消息定义为Message类位置org.apache.rocketmq.common.message字段定义如图字段详解topicMessage都有Topic这一属性,Producer发送指定Topic的消息,Consumer订阅Topic下的消息。通过Topic字段,Producer会获取消息投递的路由信息,决定发送给哪个Broker。flag网络通信层标记。bodyProducer要发送的实际消息内容,以字节数组形式进行存储。Message消息有一定大小限制。transactionIdRocketMQ 4.3.0引入的事务消息相关的事务编号。properties该字段为一个HashMap,存储了Message其余各项参数,比如tag、key等关键的消息属性。RocketMQ预定义了一组内置属性,除了内置属性之外,还可以设置任意自定义属性。当然属性的数量也是有限的,消息序列化之后的大小不能超过预设的最大消息大小。系统内置属性定义于org.apache.rocketmq.common.message.MessageConst (如图)对于一些关键属性,Message类提供了一组set接口来进行设置,class Message {public void setTags(String tags) {...}public void setKeys(Collection<String> keys) {...}public void setDelayTimeLevel(int level) {...}public void setWaitStoreMsgOK(boolean waitStoreMsgOK) {...}public void setBuyerId(String buyerId) {...}}这几个set接口对应的作用分别为为,属性 接口 用途MessageConst.PROPERTY_TAGS setTags 在消费消息时可以通过tag进行消息过滤判定MessageConst.PROPERTY_KEYS setKeys 可以设置业务相关标识,用于消费处理判定,或消息追踪查询MessageConst.PROPERTY_DELAY_TIME_LEVEL setDelayTimeLevel 消息延迟处理级别,不同级别对应不同延迟时间MessageConst.PROPERTY_WAIT_STORE_MSG_OK setWaitStoreMsgOK 在同步刷盘情况下是否需要等待数据落地才认为消息发送成功`MessageConst.PROPERTY_BUYER_ID setBuyerId 没有在代码中找到使用的地方,所以暂不明白其用处 这几个字段为什么用属性定义,而不是单独用一个字段进行表示?方便之处可能在于消息数据存盘结构早早定义,一些后期添加上的字段功能为了适应之前的存储结构,以属性形式存储在一个动态字段更为方便,自然兼容。MessageExt类
含义对于发送方来说,上述Message的定义以足够。但对于RocketMQ的整个处理流程来说,还需要更多的字段信息用以记录一些必要内容,比如消息的id、创建时间、存储时间等等。在同package下可以找到与之相关的其余类定义。首先就是MessageExt,字段字段 用途queueId 记录MessageQueue编号,消息会被发送到Topic下的MessageQueuestoreSize 记录消息在Broker存盘大小queueOffset 记录在ConsumeQueue中的偏移sysFlag 记录一些系统标志的开关状态,MessageSysFlag中定义了系统标识bornTimestamp 消息创建时间,在Producer发送消息时设置storeHost 记录存储该消息的Broker地址msgId 消息IdcommitLogOffset 记录在Broker中存储便宜bodyCRC 消息内容CRC校验值reconsumeTimes 消息重试消费次数preparedTransactionOffset 事务详细相关字段 注意Message还有一个名为MessageConst.PROPERTY_UNIQ_CLIENT_MESSAGE_ID_KEYIDX的属性,在消息发送时由Producer生成创建。上面的msgId则是消息在Broker端进行存储时通过MessageDecoder.createMessageId方法生成的,其构成为(如图)这个MsgId是在Broker生成的,Producer在发送消息时没有该信息,Consumer在消费消息时则能获取到该值。RocketMQ也提供了相关命令,命令 实现类 描述queryMsgById QueryMsgByIdSubCommand 根据MsgId查询消息 二.RocketMQ 消费幂

消费过程幂等
RocketMQ无法避免消息重复(Exactly-Once),所以如果业务对消费重复非常敏感,务必要在业务层面进行去重处理。可以借助关系数据库进行去重。首先需要确定消息的唯一键,可以是msgId,也可以是消息内容中的唯一标识字段,例如订单Id等。在消费之前判断唯一键是否在关系数据库中存在。如果不存在则插入,并消费,否则跳过。(实际过程要考虑原子性问题,判断是否存在可以尝试插入,如果报主键冲突,则插入失败,直接跳过)msgId一定是全局唯一标识符,但是实际使用中,可能会存在相同的消息有两个不同msgId的情况(消费者主动重发、因客户端重投机制导致的重复等),这种情况就需要使业务字段进行重复消费。
消费速度慢的处理方式
提高消费并行度
绝大部分消息消费行为都属于 IO 密集型,即可能是操作数据库,或者调用 RPC,这类消费行为的消费速度在于后端数据库或者外系统的吞吐量,通过增加消费并行度,可以提高总的消费吞吐量,但是并行度增加到一定程度,反而会下降。所以,应用必须要设置合理的并行度。 如下有几种修改消费并行度的方法:
同一个 ConsumerGroup 下,通过增加 Consumer 实例数量来提高并行度(需要注意的是超过订阅队列数的 Consumer 实例无效)。可以通过加机器,或者在已有机器启动多个进程的方式。
提高单个 Consumer 的消费并行线程,通过修改参数 consumeThreadMin、consumeThreadMax实现。
批量方式消费
批量方式消费可以很大程度上提高消费吞吐量,例如订单扣款类应用,一次处理一个订单耗时 1 s,一次处理 10 个订单可能也只耗时 2 s,这样即可大幅度提高消费的吞吐量,通过设置 consumer的 consumeMessageBatchMaxSize 参数值,默认是 1,即一次只消费一条消息,例如设置为 N,那么每次消费的消息数小于等于 N。
跳过非重要消息
发生消息堆积时,如果消费速度一直追不上发送速度,如果业务对数据要求不高的话,可以选择丢弃不重要的消息。例如,当某个队列的消息数堆积到100000条以上,则尝试丢弃部分或全部消息,这样就可以快速追上发送消息的速度。示例代码如下:
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,ConsumeConcurrentlyContext context) {//队列偏移量long offset = msgs.get(0).getQueueOffset();//最大偏移量String maxOffset = msgs.get(0).getProperty(Message.PROPERTY_MAX_OFFSET);long diff = Long.parseLong(maxOffset) - offset;if (diff > 100000) {// TODO 消息堆积情况的特殊处理return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;}// TODO 正常消费过程return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;}
优化每条消息消费过程
举例如下,原来某条消息的消费过程如图中左侧的流程,优化后变成右侧
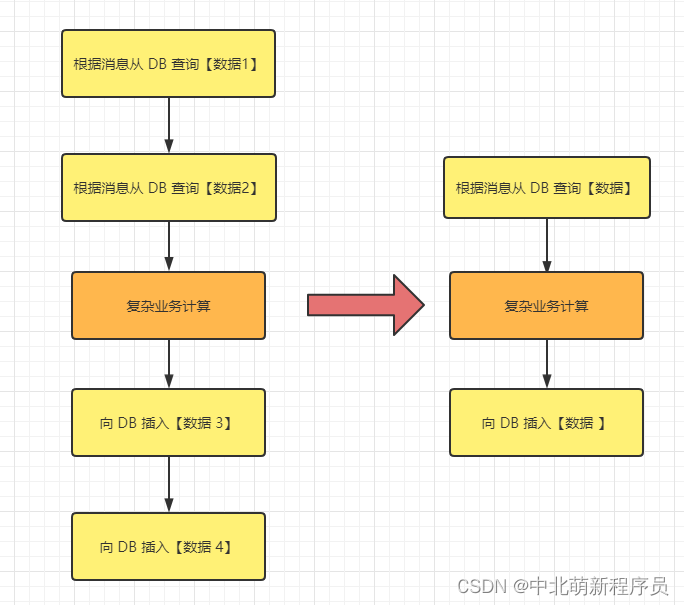
这条消息的消费过程中有4次与 DB的 交互,如果按照每次 5ms 计算,那么总共耗时 20ms,假设业务计算耗时 5ms,那么总过耗时 25ms,所以如果能把 4 次 DB 交互优化为 2 次,那么总耗时就可以优化到 15ms,即总体性能提高了 40%。所以应用如果对时延敏感的话,可以把DB部署在SSD硬盘,相比于SCSI磁盘,前者的RT会小很多。
消费打印日志
如果消息量较少,建议在消费入口方法打印消息,消费耗时等,方便后续排查问题
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,ConsumeConcurrentlyContext context) {log.info("RECEIVE_MSG_BEGIN: " + msgs.toString());// TODO 正常消费过程return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;}
如果能打印每条消息消费耗时,那么在排查消费慢等线上问题时,会更方便。
三.RocketMQ 集群服务

集群特点
NameServer是一个几乎无状态节点,可集群部署,节点之间无任何信息同步。Broker部署相对复杂,Broker分为Master与Slave,一个Master可以对应多个Slave,但是一个Slave只能对应一个Master,Master与Slave的对应关系通过指定相同的BrokerName,不同的BrokerId来定义,BrokerId为0表示Master,非0表示Slave。Master也可以部署多个。 每个Broker与NameServer集群中的所有节点建立长连接,定时注册Topic信息到所有 NameServer。
Producer与NameServer集群中的其中一个节点(随机选择)建立长连接,定期从NameServer取Topic路由信息,并向提供Topic服务的Master建立长连接,且定时向Master发送心跳。Producer完全无状态,可集群部署。
Consumer与NameServer集群中的其中一个节点(随机选择)建立长连接,定期从 NameServer取Topic路由信息,并向提供Topic服务的Master、Slave建立长连接,且定时向Master、Slave发送心跳。Consumer既可以从Master订阅消息,也可以从Slave订阅消息,订阅规则由Broker配置决定。
单master模式
这种方式风险较大,一旦Broker重启或者宕机时,会导致整个服务不可用。不建议线上环境使用,可以用于本地测试。
启动 NameServer
### 首先启动Name Server
$ nohup sh mqnamesrv &
### 验证Name Server 是否启动成功
$ tail -f ~/logs/rocketmqlogs/namesrv.log
The Name Server boot success...
启动 Broker
### 启动Broker
$ nohup sh bin/mqbroker -n localhost:9876 &### 验证Broker是否启动成功,例如Broker的IP为:192.168.1.2,且名称为broker-a
$ tail -f ~/logs/rocketmqlogs/broker.log
The broker[broker-a, 192.169.1.2:10911] boot success...多master模式
一个集群无Slave,全是Master,例如2个Master或者3个Master,这种模式的优缺点如下:
优点:配置简单,单个Master宕机或重启维护对应用无影响,在磁盘配置为RAID10时,即使机器宕机不可恢复情况下,由于RAID10磁盘非常可靠,消息也不会丢(异步刷盘丢失少量消息,同步刷盘一条不丢),性能最高;
缺点:单台机器宕机期间,这台机器上未被消费的消息在机器恢复之前不可订阅,消息实时性会受到影响。
启动NameServer
NameServer需要先于Broker启动,且如果在生产环境使用,为了保证高可用,建议一般规模的集群启动3个NameServer,各节点的启动命令相同,如下:
### 首先启动Name Server$ nohup sh mqnamesrv &### 验证Name Server 是否启动成功$ tail -f ~/logs/rocketmqlogs/namesrv.logThe Name Server boot success...
启动Broker集群
### 在机器A,启动第一个Master,例如NameServer的IP为:192.168.1.1$ nohup sh mqbroker -n 192.168.1.1:9876 -c$ROCKETMQ_HOME/conf/2m-noslave/broker-a.properties &### 在机器B,启动第二个Master,例如NameServer的IP为:192.168.1.1$ nohup sh mqbroker -n 192.168.1.1:9876 -c$ROCKETMQ_HOME/conf/2m-noslave/broker-b.properties &...
多master多Slave模式-异步复制
每个Master配置一个Slave,有多对Master-Slave,HA采用异步复制方式,主备有短暂消息延迟(毫秒级),这种模式的优缺点如下:
优点:即使磁盘损坏,消息丢失的非常少,且消息实时性不会受影响,同时Master宕机后,消费者仍然可以从Slave消费,而且此过程对应用透明,不需要人工干预,性能同多Master模式几乎一样
缺点:Master宕机,磁盘损坏情况下会丢失少量消息。
启动NameServer
### 首先启动Name Server
$ nohup sh mqnamesrv &
### 验证Name Server 是否启动成功
$ tail -f ~/logs/rocketmqlogs/namesrv.log
The Name Server boot success...
启动Broker集群
### 在机器A,启动第一个Master,例如NameServer的IP
为:192.168.1.1
$ nohup sh mqbroker -n 192.168.1.1:9876 -c
$ROCKETMQ_HOME/conf/2m-2s-async/broker-a.properties &
### 在机器B,启动第二个Master,例如NameServer的IP
为:192.168.1.1
$ nohup sh mqbroker -n 192.168.1.1:9876 -c
$ROCKETMQ_HOME/conf/2m-2s-async/broker-b.properties &
### 在机器C,启动第一个Slave,例如NameServer的IP
为:192.168.1.1
$ nohup sh mqbroker -n 192.168.1.1:9876 -c
$ROCKETMQ_HOME/conf/2m-2s-async/broker-a-s.properties &
### 在机器D,启动第二个Slave,例如NameServer的IP
为:192.168.1.1
$ nohup sh mqbroker -n 192.168.1.1:9876 -c
$ROCKETMQ_HOME/conf/2m-2s-async/broker-b-s.properties &
多Master多Slave模式-同步双写
每个Master配置一个Slave,有多对Master-Slave,HA采用同步双写方式,即只有主备都写成功,才向应用返回成功,这种模式的优缺点如下:
优点:数据与服务都无单点故障,Master宕机情况下,消息无延迟,服务可用性与数据可用性都非常高;
缺点:性能比异步复制模式略低(大约低10%左右),发送单个消息的RT会略高,且目前版本在主节点宕机后,备机不能自动切换为主机。
启动NameServer
### 首先启动Name Server$ nohup sh mqnamesrv &### 验证Name Server 是否启动成功$ tail -f ~/logs/rocketmqlogs/namesrv.logThe Name Server boot success...
启动Broker集群
### 在机器A,启动第一个Master,例如NameServer的IP
为:192.168.1.1$ nohup sh mqbroker -n 192.168.1.1:9876 -c
$ROCKETMQ_HOME/conf/2m-2s-sync/broker-a.properties &### 在机器B,启动第二个Master,例如NameServer的IP
为:192.168.1.1$ nohup sh mqbroker -n 192.168.1.1:9876 -c
$ROCKETMQ_HOME/conf/2m-2s-sync/broker-b.properties &### 在机器C,启动第一个Slave,例如NameServer的IP
为:192.168.1.1$ nohup sh mqbroker -n 192.168.1.1:9876 -c
$ROCKETMQ_HOME/conf/2m-2s-sync/broker-a-s.properties &### 在机器D,启动第二个Slave,例如NameServer的IP
为:192.168.1.1$ nohup sh mqbroker -n 192.168.1.1:9876 -c
$ROCKETMQ_HOME/conf/2m-2s-sync/broker-b-s.properties &
以上Broker与Slave配对是通过指定相同的BrokerName参数来配对,Master的BrokerId必须是0,Slave的BrokerId必须是大于0的数。另外一个Master下面可以挂载多个Slave,同一Master下的多个Slave通过指定不同的BrokerId来区分。$ROCKETMQ_HOME指的RocketMQ安装目录,需要用户自己设置此环境变量
四.RocketMQ消息消费
集群消费
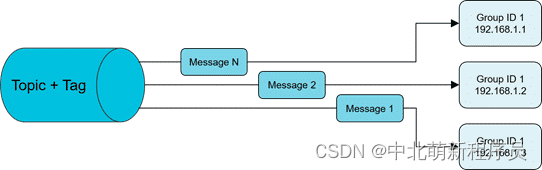
消费者的一种消费模式。一个Consumer Group中的各个Consumer实例分摊去消费消息,即一条消息只会投递到一个Consumer Group下面的一个实例。
实际上,每个Consumer是平均分摊Message Queue的去做拉取消费。例如某个Topic有3条Q,其中一个Consumer Group有3个实例(可能是3个进程,或者3台机器),那么每个实例只消费其中的1条Q。
而由Producer发送消息的时候是轮询所有的Q,所以消息会平均散落在不同的Q上,可以认为Q上的消息是平均的。那么实例也就平均地消费消息了。
这种模式下,消费进度(Consumer Offset)的存储会持久化到Broker。
import org.apache.rocketmq.client.consumer.DefaultMQPushConsumer;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyStatus;
import org.apache.rocketmq.client.consumer.listener.MessageListenerConcurrently;
import org.apache.rocketmq.client.exception.MQClientException;
import org.apache.rocketmq.common.protocol.heartbeat.MessageModel;import static com.morris.rocketmq.util.Contant.CONSUMER_GROUP;
import static com.morris.rocketmq.util.Contant.NAME_SERVER_ADDRESS;/*** 集群消费消息(默认)* ClusterConsumer 类,用于从 RocketMQ 集群消费消息*/
public class ClusterConsumer {public static void main(String[] args) throws InterruptedException, MQClientException {// 使用指定的消费者组名来实例化 DefaultMQPushConsumer。DefaultMQPushConsumer consumer = new DefaultMQPushConsumer(CONSUMER_GROUP);// 指定 NameServer 地址。consumer.setNamesrvAddr(NAME_SERVER_ADDRESS);consumer.setMessageModel(MessageModel.CLUSTERING); // 设置消息模式为集群消费模式(默认)。// 订阅一个或多个要消费的主题。consumer.subscribe("TopicTest", "*");// 注册回调函数,以便在从代理获取的消息到达时执行。consumer.registerMessageListener((MessageListenerConcurrently) (msgs, context) -> {System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; // 标记消息已成功消费。});// 启动消费者实例。consumer.start();System.out.printf("Consumer Started.%n");}
}- CONSUMER_GROUP 和 NAME_SERVER_ADDRESS 是从 Contant 类中获取的常量,用于指定消费者组和 NameServer 地址。
- MessageModel.CLUSTERING 设置消费模式为集群消费模式,默认情况下 RocketMQ 使用集群消费模式。
- consumer.subscribe(“TopicTest”, ““) 订阅了名为 “TopicTest” 的主题,”” 表示消费该主题下的所有消息。
- consumer.registerMessageListener(…) 注册了一个消息监听器,用于接收从代理获取的消息,并处理这些消息。
- consumer.start() 启动了消费者实例,开始消费消息。
广播消费

消费者的一种消费模式。消息将对一个Consumer Group下的各个Consumer实例都投递一遍。即即使这些Consumer属于同一个Consumer Group,消息也会被Consumer Group 中的每个Consumer都消费一次。
实际上,是一个消费组下的每个消费者实例都获取到了topic下面的每个Message Queue去拉取消费。所以消息会投递到每个消费者实例。
这种模式下,消费进度(Consumer Offset)会存储持久化到实例本地。
import org.apache.rocketmq.client.consumer.DefaultMQPushConsumer;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyStatus;
import org.apache.rocketmq.client.consumer.listener.MessageListenerConcurrently;
import org.apache.rocketmq.client.exception.MQClientException;
import org.apache.rocketmq.common.protocol.heartbeat.MessageModel;import static com.morris.rocketmq.util.Contant.CONSUMER_GROUP;
import static com.morris.rocketmq.util.Contant.NAME_SERVER_ADDRESS;/*** 广播消费消息(默认)* BroadcastingConsumer 类,用于从 RocketMQ 广播消费消息*/
public class BroadcastingConsumer {public static void main(String[] args) throws InterruptedException, MQClientException {// 使用指定的消费者组名来实例化 DefaultMQPushConsumer。DefaultMQPushConsumer consumer = new DefaultMQPushConsumer(CONSUMER_GROUP);// 指定 NameServer 地址。consumer.setNamesrvAddr(NAME_SERVER_ADDRESS);consumer.setMessageModel(MessageModel.BROADCASTING); // 设置消息模式为广播消费模式(默认)。// 订阅一个或多个要消费的主题。consumer.subscribe("TopicTest", "*");// 注册回调函数,以便在从代理获取的消息到达时执行。consumer.registerMessageListener((MessageListenerConcurrently) (msgs, context) -> {System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; // 标记消息已成功消费。});// 启动消费者实例。consumer.start();System.out.printf("Consumer Started.%n");}
}- CONSUMER_GROUP 和 NAME_SERVER_ADDRESS 是从 Contant 类中获取的常量,用于指定消费者组和 NameServer 地址。
- MessageModel.BROADCASTING 设置消费模式为广播消费模式,默认情况下 RocketMQ 使用广播消费模式。
- consumer.subscribe(“TopicTest”, ““) 订阅了名为 “TopicTest” 的主题,”” 表示消费该主题下的所有消息。
- consumer.registerMessageListener(…) 注册了一个消息监听器,用于接收从代理获取的消息,并处理这些消息。
- consumer.start() 启动了消费者实例,开始消费消息。
这种模式下消费者只能收到启动后发送MQ中的消息。
消息消费时的权衡
集群模式:
- 消费端集群化部署,每条消息只需要被处理一次。
- 由于消费进度在服务端维护,可靠性更高。
- 集群消费模式下,每一条消息都只会被分发到一台机器上处理。如果需要被集群下的每一台机器都处理,请使用广播模式。
- 集群消费模式下,不保证每一次失败重投的消息路由到同一台机器上,因此处理消息时不应该做任何确定性假设。
广播模式:
- 广播消费模式下不支持顺序消息。
- 广播消费模式下不支持重置消费位点。
- 每条消息都需要被相同逻辑的多台机器处理。
- 消费进度在客户端维护,出现重复的概率稍大于集群模式。
广播模式下,消息队列RocketMQ保证每条消息至少被每台客户端消费一次,但是并不会对消费失败的消息进行失败重投,因此业务方需要关注消费失败的情况。
广播模式下,客户端每一次重启都会从最新消息消费。客户端在被停止期间发送至服务端的消息将会被自动跳过,请谨慎选择。
广播模式下,每条消息都会被大量的客户端重复处理,因此推荐尽可能使用集群模式。
目前仅Java客户端支持广播模式。广播模式下服务端不维护消费进度,所以消息队列RocketMQ控制台不支持消息堆积查询、消息堆积报警和订阅关系查询功能。
如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,大家的支持就是我坚持下去的动力!
相关文章:
2.13日学习打卡----初学RocketMQ(四)
2.13日学习打卡 目录: 2.13日学习打卡一.RocketMQ之Java ClassDefaultMQProducer类DefaultMQPushConsumer类Message类MessageExt类 二.RocketMQ 消费幂消费过程幂等消费速度慢的处理方式 三.RocketMQ 集群服务集群特点单master模式多master模式多master多Slave模式-…...
ZigBee学习——BDB
✨本博客参考了善学坊的教程,并总结了在实现过程中遇到的问题。 善学坊官网 文章目录 一、BDB简介二、BDB Commissioning Modes2.1 Network Steering2.2 Network Formation2.3 Finding and Binding(F & B)2.4 Touchlink 三、BDB Commissi…...
使用Docker快速部署MySQL
部署MySQL 使用Docker安装,仅仅需要一步即可,在命令行输入下面的命令 docker run -d \--name mysql \-p 3306:3306 \-e TZAsia/Shanghai \-e MYSQL_ROOT_PASSWORD123456 \mysql MySQL安装完毕!通过任意客户端工具即可连接到MySQL. 当我们执…...

力扣热题100_滑动窗口_3_无重复字符的最长子串
文章目录 题目链接解题思路解题代码 题目链接 3. 无重复字符的最长子串 给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。 示例 1: 输入: s “abcabcbb” 输出: 3 解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。 示…...
RM电控工程讲义
HAL_CAN_RxFifo0MsgPendingCallback(CAN_HandleTypeDef *hcan) 是一个回调函数,通常在STM32的HAL库中用于处理CAN(Controller Area Network)接收FIFO 0中的消息。当CAN接口在FIFO 0中有待处理的消息时,这个函数会被调用。 HAL库C…...
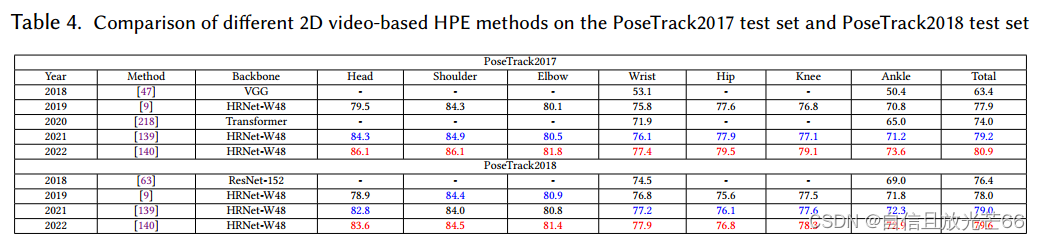
论文阅读:《Deep Learning-Based Human Pose Estimation: A Survey》——Part 1:2D HPE
目录 人体姿态识别概述 论文框架 HPE分类 人体建模模型 二维单人姿态估计 回归方法 目前发展 优化 基于热图的方法 基于CNN的几个网络 利用身体结构信息提供构建HPE网络 视频序列中的人体姿态估计 2D多人姿态识别 方法 自上而下 自下而上 2D HPE 总结 数据集…...

C语言——oj刷题——杨氏矩阵
目录 1. 理解杨氏矩形的特点 2. 实现杨氏矩形查找算法 3. 编写示例代码 当我们谈到杨氏矩形时,我们指的是一种在二维数组中查找目标元素的高效算法。它是由杨氏(Yan Shi)教授提出的,因此得名为杨氏矩形。 杨氏矩形问题的场景是…...

C++ 50道面试题
1. static关键字 1.全局static变量 存储位置:静态存储区,在程序运行期间一直存在 初始化: 未手动初始化的变量自动初始化为0 作用域: 从定义之处开始,到文件结束,仅能在本文件中使用 2.局部static变量…...

寒假学习记录14:JS字符串
目录 查找字符串中的特定元素 String.indexOf() (返回索引值) 截取字符串的一部分 .substring() (不影响原数组)(不允许负值) 截取字符串的一部分 .slice() (不影响原数…...

【数学建模】【2024年】【第40届】【MCM/ICM】【C题 网球运动中的“动量”】【解题思路】
一、题目 (一) 赛题原文 2024 MCM Problem C: Momentum in Tennis In the 2023 Wimbledon Gentlemen’s final, 20-year-old Spanish rising star Carlos Alcaraz defeated 36-year-old Novak Djokovic. The loss was Djokovic’s first at Wimbledon…...
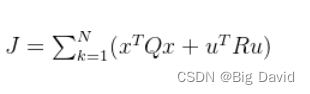
无人驾驶LQR控制算法 c++ 实现
参考博客: (1)LQR的理解与运用 第一期——理解篇 (2)线性二次型调节器(LQR)原理详解 (3)LQR控制基本原理(包括Riccati方程具体推导过程) (4)【基础…...
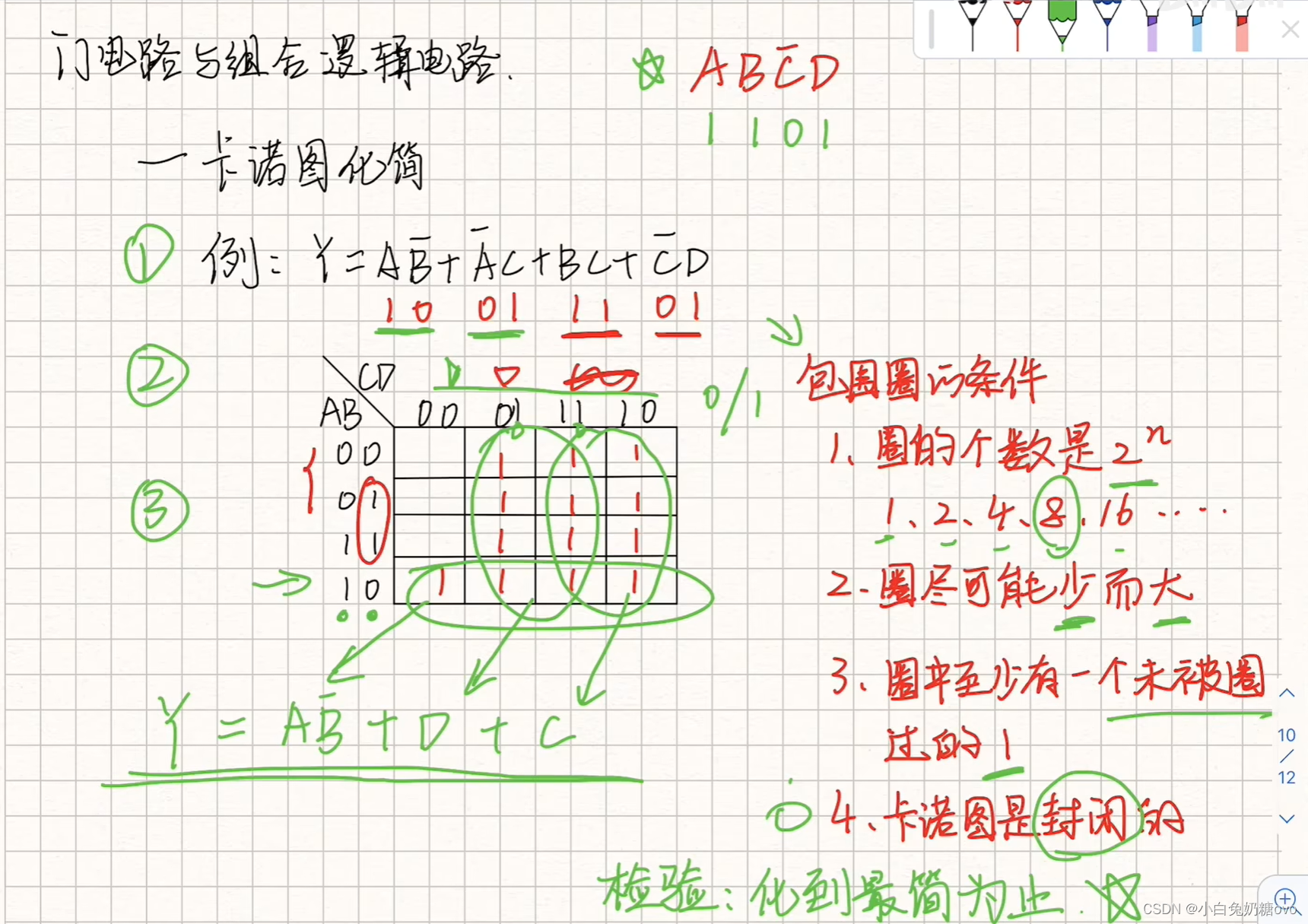
Karnaugh map (卡诺图)
【Leetcode】 289. Game of Life According to Wikipedia’s article: “The Game of Life, also known simply as Life, is a cellular automaton devised by the British mathematician John Horton Conway in 1970.” The board is made up of an m x n grid of cells, wh…...

C# CAD 框选pdf输出
在C#中进行AutoCAD二次开发时,实现框选(窗口选择)实体并输出这些实体到PDF文件通常涉及以下步骤: public ObjectIdCollection GetSelectedEntities() {using (var acTrans HostApplicationServices.WorkingDatabase.Transaction…...

【Linux】 Linux 小项目—— 进度条
进度条 基础知识1 \r && \n2 行缓冲区3 函数介绍 进度条实现版本 1代码实现运行效果 版本2 Thanks♪(・ω・)ノ谢谢阅读!!!下一篇文章见!!! 基础知识 1 \r &&a…...
Sora和Pika,RunwayMl,Stable Video对比!网友:Sora真王者,其他都是弟
大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,所以创建了“AI信息Gap”这个公众号,专注于分享AI全维度知识…...

Go内存优化与垃圾收集
Go提供了自动化的内存管理机制,但在某些情况下需要更精细的微调从而避免发生OOM错误。本文介绍了如何通过微调GOGC和GOMEMLIMIT在性能和内存效率之间取得平衡,并尽量避免OOM的产生。原文: Memory Optimization and Garbage Collector Management in Go 本…...

【Spring】Bean 的生命周期
一、Bean 的生命周期 Spring 其实就是一个管理 Bean 对象的工厂,它负责对象的创建,对象的销毁等 所谓的生命周期就是:对象从创建开始到最终销毁的整个过程 什么时候创建 Bean 对象?创建 Bean 对象的前后会调用什么方法…...
云计算基础-存储基础
存储概念 什么是存储: 存储就是根据不同的应用程序环境,通过采取合理、安全、有效的方式将数据保存到某些介质上,并能保证有效的访问,存储的本质是记录信息的载体。 存储的特性: 数据临时或长期驻留的物理介质需要保…...
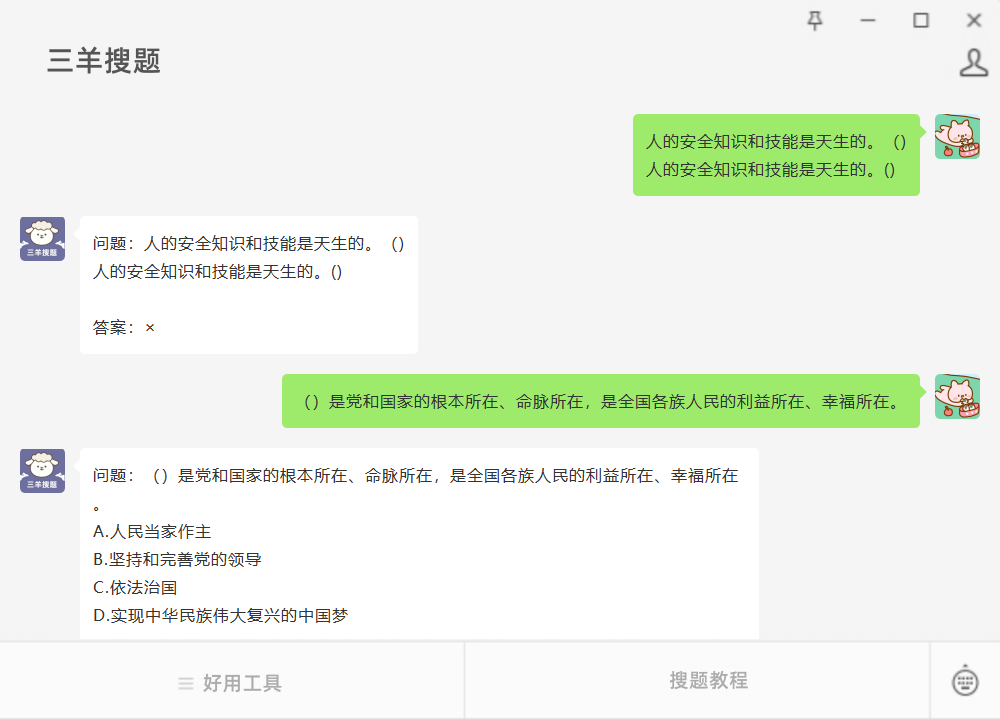
问题:人的安全知识和技能是天生的。() #媒体#知识分享#学习方法
问题:人的安全知识和技能是天生的。() 人的安全知识和技能是天生的。() 参考答案如图所示 问题:()是党和国家的根本所在、命脉所在,是全国各族人民的利益所在、幸福所在。 A.人民当家作主 B.坚持和完善…...
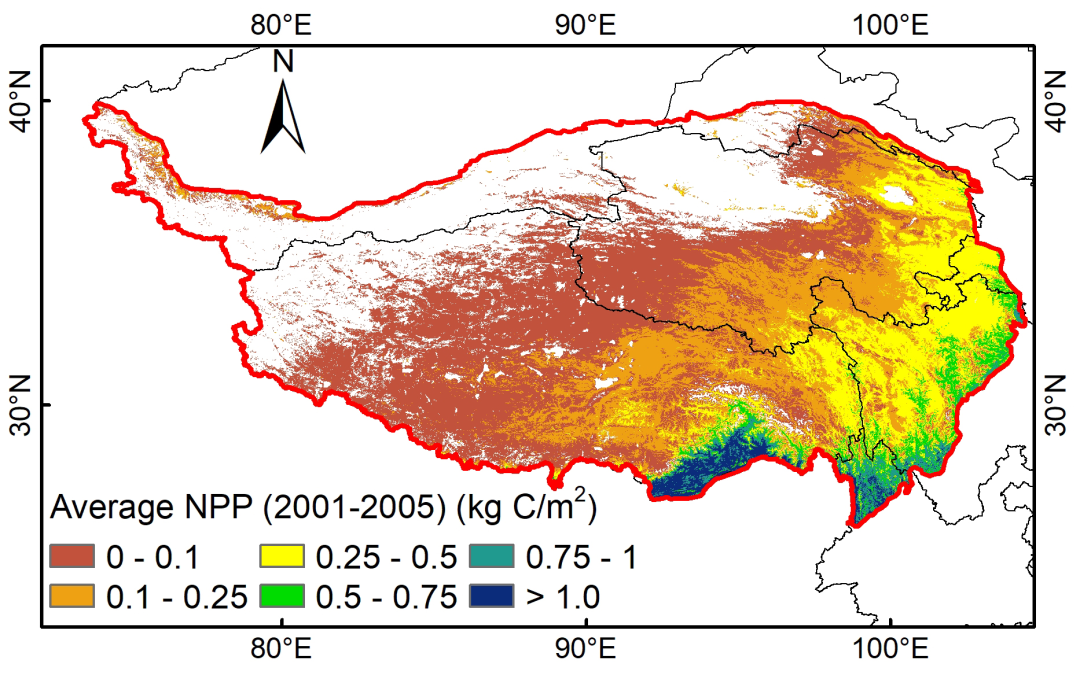
【数据分享】2001~2020年青藏高原植被净初级生产力数据集
各位同学们好,今天和大伙儿分享的是2001~2020年青藏高原植被净初级生产力数据集。如果大家有下载处理数据等方面的问题,您可以私信或评论。 朱军涛. (2022). 青藏高原植被净初级生产力数据集(2001-2020). 国家青藏高原数据中心. …...

如何高效构建视频数据集:video2frame终极实战指南
如何高效构建视频数据集:video2frame终极实战指南 【免费下载链接】video2frame Yet another easy-to-use tool to extract frames from videos, for deep learning and computer vision. 项目地址: https://gitcode.com/gh_mirrors/vi/video2frame 在计算机…...

3步轻松掌握:163MusicLyrics歌词下载完全指南
3步轻松掌握:163MusicLyrics歌词下载完全指南 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 还在为找不到高质量的LRC歌词而烦恼吗?163MusicLyri…...

【人生底稿 28】新疆出差终章:几番波折终汇报,尽兴踏归津门路
三日游玩尽数落幕,忙碌工作正式回归。轻松的闲暇时光悄然收尾,紧绷的工作状态再次上线。整趟新疆之行,在起伏辗转中迎来最终收尾。一、深夜复盘材料,彻夜待汇报游玩结束回到酒店,我没有松懈休息,静下心重新…...

Applite:macOS软件管理的最佳图形化方案,告别繁琐命令行
Applite:macOS软件管理的最佳图形化方案,告别繁琐命令行 【免费下载链接】Applite User-friendly GUI macOS application for Homebrew Casks 项目地址: https://gitcode.com/gh_mirrors/ap/Applite 还在为macOS软件安装更新而烦恼吗?…...

Shell脚本加固实战:用shellguard提升脚本健壮性与安全性
1. 项目概述:一个为Shell脚本穿上“防弹衣”的守护者 在运维开发、自动化部署乃至日常的系统管理工作中,Shell脚本是我们最忠实、最高效的伙伴。从简单的日志清理到复杂的CI/CD流水线,Shell脚本无处不在。然而,脚本的安全性、健壮…...

如何为深信服超融合平台上的应用快速接入大模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何为深信服超融合平台上的应用快速接入大模型能力 对于在深信服超融合平台上部署业务应用的企业开发团队而言,集成智…...

模拟WiFi反向散射技术:无电池物联网通信新突破
1. 项目概述:模拟WiFi反向散射技术的革新突破在物联网设备爆炸式增长的今天,电池续航已成为制约大规模部署的关键瓶颈。传统传感器节点即使采用低功耗设计,其电池寿命也鲜有超过3-5年。而Leggiero提出的模拟WiFi反向散射技术,则开…...

大语言模型长上下文建模:从注意力优化到Mamba架构的工程实践
1. 项目概述:为什么长上下文建模是LLM的“圣杯”?如果你在过去一年里深度使用过任何主流的大语言模型,无论是ChatGPT、Claude还是开源的Llama、Qwen,一个共同的痛点一定让你印象深刻:“它好像不记得我们之前聊了什么”…...

5分钟终极指南:在Blender中完美导入Rhino 3dm文件的完整教程
5分钟终极指南:在Blender中完美导入Rhino 3dm文件的完整教程 【免费下载链接】import_3dm Blender importer script for Rhinoceros 3D files 项目地址: https://gitcode.com/gh_mirrors/im/import_3dm 你是否正在寻找一种简单、快速且免费的方法,…...

基于MCP协议构建个人AI工作流:模块化套件配置与隐私优先实践
1. 项目概述:一个为个人工作流注入AI智能的MCP套件 最近在折腾AI Agent和自动化工作流的朋友,应该都绕不开一个词: MCP 。全称是Model Context Protocol,你可以把它理解成AI模型(比如Claude、ChatGPT)和外…...