yolov8源码解读Detect层
yolov8源码解读Detect层
- Detect层解读
- 网络各层解读及detect层后的处理
关于网络的backbone,head,以及detect层后处理,可以参考文章结尾博主的文章。
Detect层解读
先贴一下全部代码,下面一一解读。
class Detect(nn.Module):"""YOLOv8 Detect head for detection models."""dynamic = False # force grid reconstructionexport = False # export modeshape = Noneanchors = torch.empty(0) # initstrides = torch.empty(0) # initdef __init__(self, nc=80, ch=()):"""Initializes the YOLOv8 detection layer with specified number of classes and channels."""super().__init__()self.nc = nc # number of classesself.nl = len(ch) # number of detection layersself.reg_max = 16 # DFL channels (ch[0] // 16 to scale 4/8/12/16/20 for n/s/m/l/x)self.no = nc + self.reg_max * 4 # number of outputs per anchorself.stride = torch.zeros(self.nl) # strides computed during buildc2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], min(self.nc, 100)) # channelsself.cv2 = nn.ModuleList(nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch)self.cv3 = nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch)self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()def forward(self, x):"""Concatenates and returns predicted bounding boxes and class probabilities."""shape = x[0].shape # BCHW# print(">>>>", x[0].shape)# print(">>>>", x[1].shape)# print(">>>>", x[2].shape)for i in range(self.nl):x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)if self.training:return xelif self.dynamic or self.shape != shape:self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))self.shape = shapex_cat = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2)if self.export and self.format in ('saved_model', 'pb', 'tflite', 'edgetpu', 'tfjs'): # avoid TF FlexSplitV opsbox = x_cat[:, :self.reg_max * 4]cls = x_cat[:, self.reg_max * 4:]else:box, cls = x_cat.split((self.reg_max * 4, self.nc), 1)dbox = dist2bbox(self.dfl(box), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.stridesif self.export and self.format in ('tflite', 'edgetpu'):# Normalize xywh with image size to mitigate quantization error of TFLite integer models as done in YOLOv5:# https://github.com/ultralytics/yolov5/blob/0c8de3fca4a702f8ff5c435e67f378d1fce70243/models/tf.py#L307-L309# See this PR for details: https://github.com/ultralytics/ultralytics/pull/1695img_h = shape[2] * self.stride[0]img_w = shape[3] * self.stride[0]img_size = torch.tensor([img_w, img_h, img_w, img_h], device=dbox.device).reshape(1, 4, 1)dbox /= img_size# print(cls.shape)y = torch.cat((dbox, cls.sigmoid()), 1)# print(y.shape)return y if self.export else (y, x)
dynamic = False #这个属性指示网格(通常是特征图上的锚框网格)是否需要动态地重建export = False #这个属性用于指示模型是否处于导出模式。shape = None # 用于存储输入图像或特征图的尺寸。anchors = torch.empty(0) # 创建了一个空的PyTorch张量strides = torch.empty(0)
步长(strides)是卷积神经网络中特征图相对于输入图像的缩小比例。
例如,如果步长是32,那么一个32x32像素的区域在特征图上就对应一个单元。
和anchors一样,这里的torch.empty(0)表示步长尚未初始化。
def __init__(self, nc=80, ch=()):"""Initializes the YOLOv8 detection layer with specified number of classes and channels."""super().__init__()self.nc = nc # number of classesself.nl = len(ch) # number of detection layersself.reg_max = 16 # DFL channels (ch[0] // 16 to scale 4/8/12/16/20 for n/s/m/l/x)self.no = nc + self.reg_max * 4 # number of outputs per anchorself.stride = torch.zeros(self.nl) # strides computed during buildc2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], min(self.nc, 100)) # channelsself.cv2 = nn.ModuleList(nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch)self.cv3 = nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch)self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()
nc:类别数
nl:检测层的数量,目标检测中为3。
ch:传入的图片通道尺寸,在yolov8n,图片大小为640*640时。这里的ch为(256,128,64)
no:两个卷积再拼接后输出通道数,为4×reg_max+nc
c2,c3:计算卷积层的通道数。
cv2,cv3:定义的卷积操作,以输出有关类别和选框的特征图。
dfl:通过将分布式的概率分布转化为单一的预测值
class DFL(nn.Module):def __init__(self, c1=16):"""Initialize a convolutional layer with a given number of input channels."""super().__init__()self.conv = nn.Conv2d(c1, 1, 1, bias=False).requires_grad_(False)x = torch.arange(c1, dtype=torch.float)self.conv.weight.data[:] = nn.Parameter(x.view(1, c1, 1, 1))self.c1 = c1def forward(self, x):"""Applies a transformer layer on input tensor 'x' and returns a tensor."""b, c, a = x.shape # batch, channels, anchorsreturn self.conv(x.view(b, 4, self.c1, a).transpose(2, 1).softmax(1)).view(b, 4, a)
self.conv:创建了一个输入通道为16,输出为1,没有偏置项,不需要进行梯度更新的卷积层。
这样的权重设置实际上模拟了一个积分过程,将卷积操作变成了加权求和的形式。
x:1到15的整数。
self.conv.weight.data[:] = nn.Parameter(x.view(1, c1, 1, 1)):
这里使用nn.Parameter将重塑后的张量设置为模型的参数,并且参数不会被更新。
假设前向传播中,x的形状为(1, 64, 8400),下面解释下forword中的变化。
1,x.view(b, 4, self.c1, a): 这个操作是对x的形状进行重塑。self.c1是16(因为输入通道数是64,即4*self.c1),那么a是8400(代表了所有锚点的数量)。b是批次大小,这里为1。所以x.view(b, 4, self.c1, a)将x从(1, 64, 8400)重塑为(1, 4, 16, 8400)。在这个形状中,我们得到了每个锚点的每个坐标轴(x, y, 宽度, 高度)上的16个预测值(可能代表某种概率分布)。
2,transpose(2, 1): 这个操作交换第二维和第三维。在应用transpose之后,张量的形状变为(1, 16, 4, 8400)。这样做的目的是让每组概率分布的16个预测值连续地排列在一起,为后面的softmax运算做准备。
3,softmax(1): softmax函数应用于第一维(现在是16个预测值的这一维)。softmax确保了这16个值之和为1,转换为一个有效的概率分布,表示每个预测值的可能性。
4,self.conv(…): 这个操作将配置好的卷积层应用在进行了softmax操作的张量上。由于卷积层的权重已被设置为从0到15的整数,并且不更新权重(不进行梯度下降优化),这个步骤实际上是在计算期望值。卷积层将每个离散的概率值乘以其相应的索引(也就是权重),然后对结果进行求和,得到该坐标的预测值。
5,view(b, 4, a): 最后一步是将张量的形状从卷积操作后的(1, 1, 4, 8400)转换回(1, 4, 8400)。这样确保了最终的输出张量与每个坐标轴的预测值(x, y, 宽度, 高度)和所有锚点的数量对齐。
总的来说,dfl层就是对预测的坐标求加权期望值。将(1,64,8400)先变为(1,16,4,8400),然后对这16个通道求加权期望,变为(1,4,8400)即这8400个锚点中的每一个锚点,x,y,width,hight的加权平均值。
接下来是前向传播的过程。打印传入的x形状,发现通道数是64,128,256。

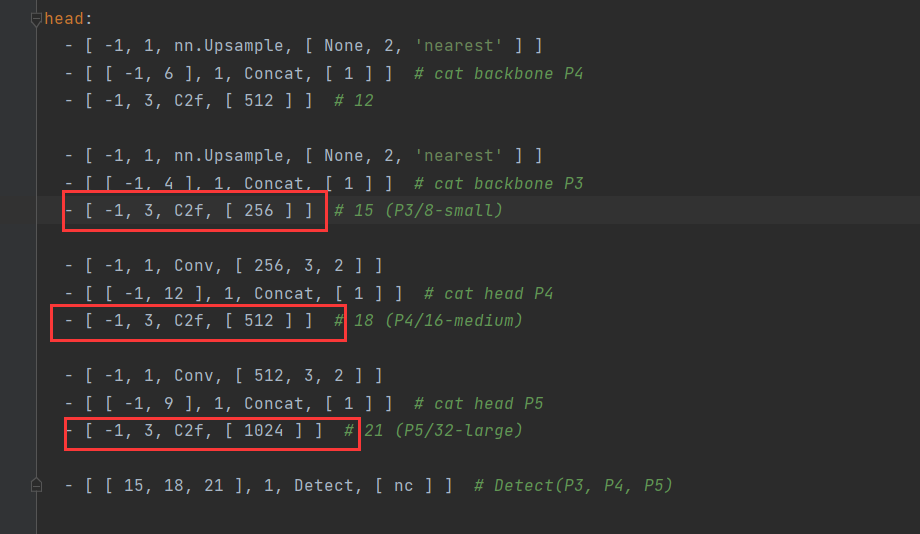
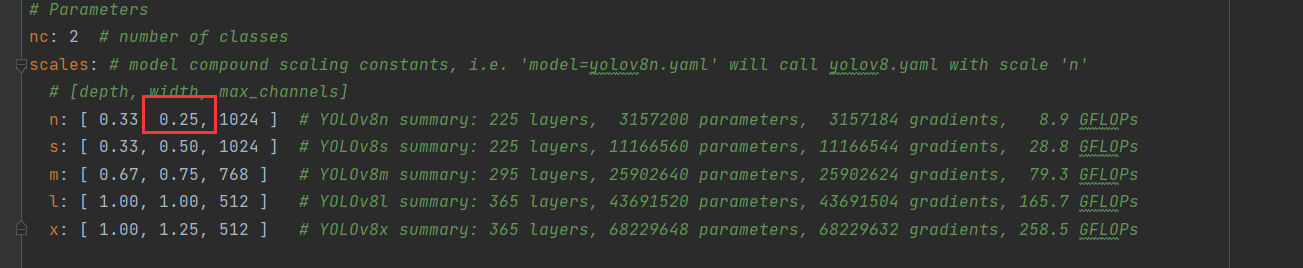
原因:Detect层接受15,18,21层的输入。原本通道数是1024,512,256。但是yolov8n还需要乘0.25。
经过cv2,通道数变为64,经过cv3通道数变为nc,我这里nc为2(二分类)。在经过cat拼接,在通道维度上拼接,所以x[i]的通道数变为66。
如果处于训练模式,就直接返回x。
否则执行下面的代码,将特征图列表x(1×66×40×40,1×66×80×80,1×66×20×20)传递给make_anchors()函数。make_anchors函数用于生成锚点(anchors),它通常用在目标检测网络中。每个锚点代表了特征图上的一个点,可以用来预测相对于该点的边界框。strides是这些特征图相对于原始图像的下采样步长。简单来说,生成了8400个锚点(40×40+80×80+20×20),变量为anchors,形状为1×2×8400)。同时生成了8400个步长,变量为strides,形状为1×8400。参数0.5表示每个锚点处于每个像素块的中央。
if self.training:return xelif self.dynamic or self.shape != shape:self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))self.shape = shape
将xi按照2维度进行拼接,xi分别为1×66×40×40,1×66×80×80,1×66×20×20。拼接后的x_cat为1×66×8400
x_cat = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2)
这段代码就是把x_cat进行拆分。box形状为1×64×8400,包含每个边界框的回归参数。cls形状为1×2×8400,会包含类别预测,2是因为我这里类别为2。
if self.export and self.format in ('saved_model', 'pb', 'tflite', 'edgetpu', 'tfjs'): # avoid TF FlexSplitV opsbox = x_cat[:, :self.reg_max * 4]cls = x_cat[:, self.reg_max * 4:]else:box, cls = x_cat.split((self.reg_max * 4, self.nc), 1)
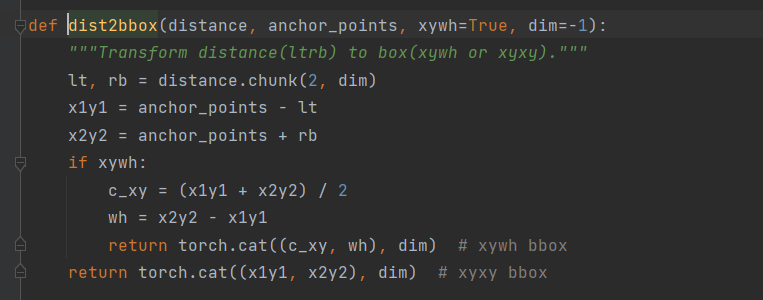
dfl层就是对预测的坐标求加权期望值。将(1,64,8400)先变为(1,16,4,8400),然后对这16个通道求加权期望,变为(1,4,8400)即这8400个锚点中的每一个锚点,x1,y1,x2,y2的加权平均值。dist2bbox()函数的作用是将锚点x1,y1,x2,y2转换为x,y,width,hight的形式。最后在乘以步长,还原到原图的大小比例。
dbox = dist2bbox(self.dfl(box), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.strides
此代码片段的作用是在模型导出为 Tensorflow Lite (tflite) 或 Edge TPU 兼容格式时,对预测框 (dbox) 进行归一化处理。
if self.export and self.format in ('tflite', 'edgetpu'):# Normalize xywh with image size to mitigate quantization error of TFLite integer models as done in YOLOv5:# https://github.com/ultralytics/yolov5/blob/0c8de3fca4a702f8ff5c435e67f378d1fce70243/models/tf.py#L307-L309# See this PR for details: https://github.com/ultralytics/ultralytics/pull/1695img_h = shape[2] * self.stride[0]img_w = shape[3] * self.stride[0]img_size = torch.tensor([img_w, img_h, img_w, img_h], device=dbox.device).reshape(1, 4, 1)dbox /= img_size
此时y的形状为1×66×8400。代表有8400个锚点,每个锚点包含坐标框的x,y,width,hight,以及类别得分信息。
y = torch.cat((dbox, cls.sigmoid()), 1)
返回值,至此detect层结束。完整的预测,后续还需要进行一些处理。如进行非极大抑制,对这8400个锚点进行筛选
return y if self.export else (y, x)
另外,最后的bias_init()函数用于初始化一个目标检测模型中的Detect层的偏置。确保在训练开始时偏置值是基于合理假设的。这种方法的目标是为模型提供一个好的起点,并有助于加速训练过程中的收敛。
def bias_init(self):"""Initialize Detect() biases, WARNING: requires stride availability."""m = self # self.model[-1] # Detect() module# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1# ncf = math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # nominal class frequencyfor a, b, s in zip(m.cv2, m.cv3, m.stride): # froma[-1].bias.data[:] = 1.0 # boxb[-1].bias.data[:m.nc] = math.log(5 / m.nc / (640 / s) ** 2) # cls (.01 objects, 80 classes, 640 img)
网络各层解读及detect层后的处理
关于backbone,head层,以及detect层参考下面博主的文章,讲的非常好。
链接: Yolov 8源码超详细逐行解读+ 网络结构细讲(自我用的小白笔记)
链接: 最细致讲解yolov8模型推理完整代码–(前处理,后处理)
相关文章:
yolov8源码解读Detect层
yolov8源码解读Detect层 Detect层解读网络各层解读及detect层后的处理 关于网络的backbone,head,以及detect层后处理,可以参考文章结尾博主的文章。 Detect层解读 先贴一下全部代码,下面一一解读。 class Detect(nn.Module):"""YOLOv8 …...
(AtCoder Beginner Contest 341)(A - D)
比赛地址 : Tasks - Toyota Programming Contest 2024#2(AtCoder Beginner Contest 341) A . Print 341 模拟就好了 , 先放一个 1 , 然后放 n 个 01 ; #include<bits/stdc.h> #define IOS ios::sync_with_stdio(0);cin.tie(0);cout…...

python Flask与微信小程序 统计管理
common/models/stat/StatDailyMember.py DROP TABLE IF EXISTS stat_daily_member;CREATE TABLE stat_daily_member (id int(11) unsigned NOT NULL AUTO_INCREMENT,date date NOT NULL COMMENT 日期,member_id int(11) NOT NULL DEFAULT 0 COMMENT 会员id,total_shared_count …...

光伏企业助力乡村振兴
光伏是一种利用太阳能生产电能的发电技术,属于可再生能源。近年来我国的光伏企业发展迅速,已经称霸全球,同时也为乡村振兴贡献了力量。 一、光伏企业助力乡村 1.推动农业发展 光伏发电和农业种植、畜牧、渔业、水产等有机结合,…...

root MUSIC 算法补充说明
root MUSIC 算法补充说明 多项式求根root MUSIC 算法原理如何从 2 M − 2 2M-2 2M−2 个根中确定 K K K 个根从复数域上观察 2 M − 2 2M-2 2M−2 个根的分布 这篇笔记是上一篇关于 root MUSIC 笔记的补充。 多项式求根 要理解 root MUSIC 算法,需要理解多项式求…...

关于Django的中间件使用说明。
目录 1.中间件2. 为什么要中间件?3. 具体使用中间件3.1 中间件所在的位置:在django的settings.py里面的MIDDLEWARE。3.2 中间件的创建3.3 中间件的使用 4. 展示成果 1.中间件 中间件的大概解释:在浏览器在请求服务器的时候,首先要…...

Chapter 8 - 15. Congestion Management in TCP Storage Networks
User Actions After learning the states of queue utilization, the following are the actions that admins and operators can take while using TCP transport for storage traffic. 了解了队列利用率的状态后,管理员和操作员在使用 TCP 传输存储流量时可以采取以下措施。…...

前端技巧之svg精灵图svg-sprite-loader
首先说明精灵图的必要性,其可以让我们只需要向服务器请求一次图片资源,就能加载很多图片,即能够减轻http请求造成的服务器压力。 然后这里要说明的是这个插件是webpack上面的,所以在vue2中比较好用,如果在vue3中&…...

IO线程-day2
1> 使用fread和fwrite完成两个文件的拷贝 程序: #define MAXSIZE 1024 #include<myhead.h>int main(int argc, char const *argv[]) {FILE *srcfpNULL;FILE *destfpNULL;if(!(srcfpfopen("pm.bmp","r")))PRINT_ERR("");if…...
Spring Boot 笔记 024 登录页面
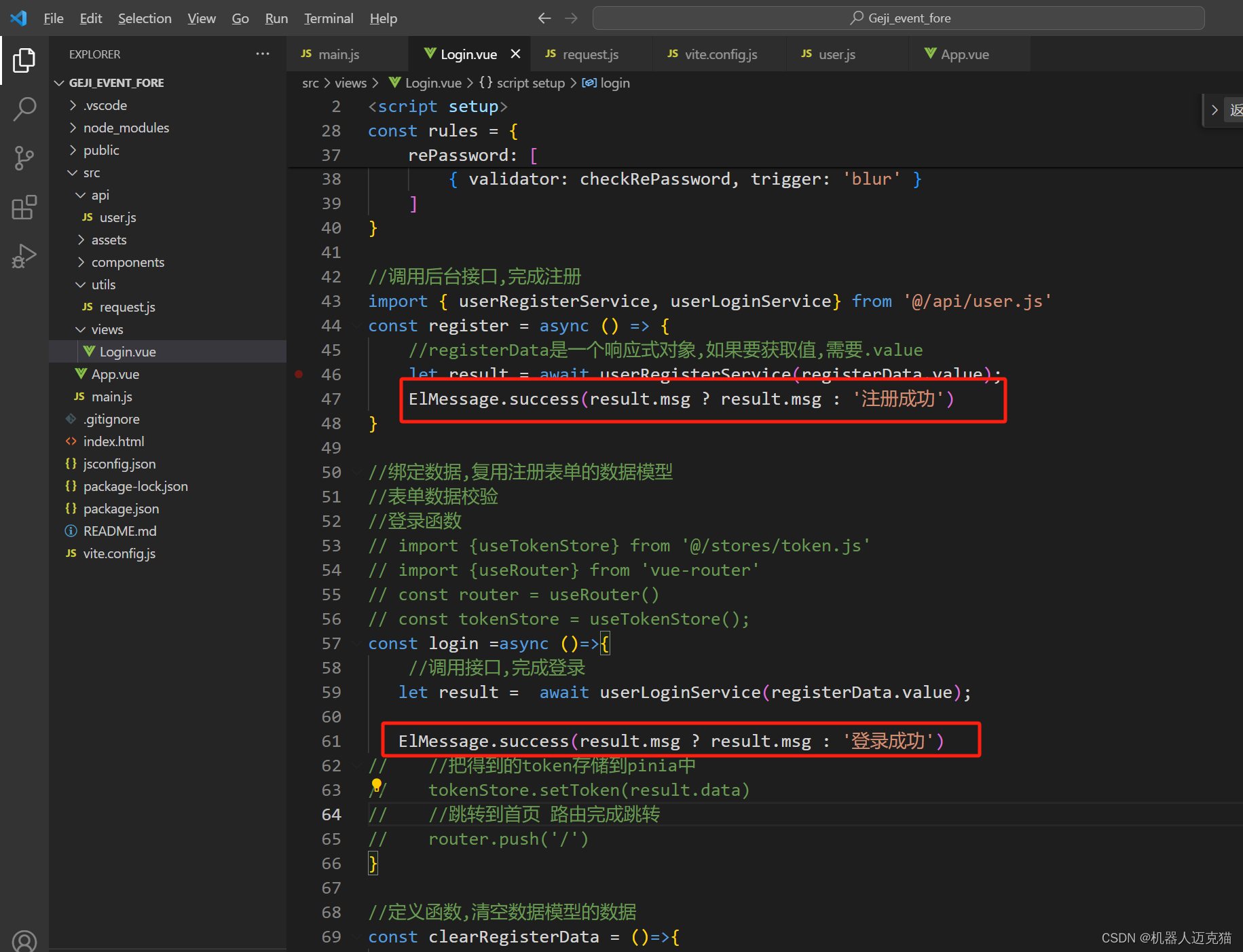
1.1 登录接口 //导入request.js请求工具 import request from /utils/request.js//提供调用注册接口的函数 export const userRegisterService (registerData)>{//借助于UrlSearchParams完成传递const params new URLSearchParams()for(let key in registerData){params.a…...

09_Java集合
一、Java集合框架概述 一方面, 面向对象语言对事物的体现都是以对象的形式,为了方便对多个对象的操作,就要对对象进行存储。另一方面,使用Array存储对象方面具有一些弊端,而Java 集合就像一种容器,可以动态…...

HCIA-HarmonyOS设备开发认证V2.0-3.2.轻量系统内核基础-软件定时器
目录 一、软件定时器基本概念二、软件定时器运行机制三、软件定时器状态四、软件定时器模式五、软件定时器开发流程六、软件定时器使用说明七、软件定时器接口八、代码分析(待续...)坚持就有收获 一、软件定时器基本概念 软件定时器,是基于系…...
考研证件照可以自己用手机拍吗?考研证件照p过可以通过审核吗?考研证件照有什么要求
一、考研证件照可以自己用手机拍吗 现在的智能手机相机技术先进,大多都配备了高像素摄像头,使得自拍照片的质量有了大幅提升。相较于传统的证件照拍摄,使用手机自拍考研证件照理论上是可行的。然而,考研证件照需要满足一定的规定…...
win10 环境下Python 3.8按装fastapi paddlepaddle 进行图片文字识别1
###按装 用conda 创建python 3.8的环境,可参看本人python下的其它文章。 在pycharm开发环境下按装相关的模块: pip install -i https://pypi.tuna.tsinghua.edu.cn/simple fastapi pip install -i https://pypi.tuna.tsinghua.edu.cn/simple "uvi…...

json字符串的处理
json字符串的处理 【1】解析json字符串(1)如果json格式字符串 ,最外层 是 中括号,表示数组,就使用方法(2)如果json格式字符串,最外层是 大括号,表示对象,就是…...

Java基础String常见的编程练习
1.对字符串数组进行排序 package javalianxi;import java.util.Arrays; import java.util.Comparator;public class Test1 {public static void main(String[] args) {String[] array { "cd", "CD", "bc", "AB", "ab", &q…...
| 491.递增子序列 46.全排列 47.全排列 II)
代码随想录算法训练营(回溯5)| 491.递增子序列 46.全排列 47.全排列 II
491.递增子序列 本题和大家刚做过的 90.子集II 非常像,但又很不一样,很容易掉坑里。 题目链接/文章讲解 视频讲解 46.全排列 本题重点感受一下,排列问题 与 组合问题,组合总和,子集问题的区别。 为什么排列问题不用…...

专业140+总分420+南京信息工程大学811信号与系统考研经验南信大电子信息与通信工程,真题,大纲,参考书
今年顺利被南信大电子信息录取,初试420,专业811信号与系统140(Jenny老师辅导班上140很多,真是大佬云集),今年应该是南信大电子信息最卷的一年,复试线比往年提高了很多,录取平均分380…...

一元函数微分学【高数笔记】
1. 什么是微分?什么是微商? 2. 什么是函数的微分? 3. 在函数的微分中,有什么样的关系? 4. 一元函数的微分运用在什么题型中? 5. 什么是一元函数?...
(16)Hive——企业调优经验
前言 本篇文章主要整理hive-3.1.2版本的企业调优经验,有误请指出~ 一、性能评估和优化 1.1 Explain查询计划 使用explain命令可以分析查询计划,查看计划中的资源消耗情况,定位潜在的性能问题,并进行相应的优化。 explain执行计划…...

机器学习能耗评估工具对比:芯片传感器与估算模型实战解析
1. 项目概述与背景在AI模型规模日益膨胀、训练成本水涨船高的今天,我们除了关注模型的准确率和F1值,是否也该关心一下它“吃”了多少电?这不仅仅是电费账单的问题,更关乎我们能否在追求技术前沿的同时,践行环境责任。作…...

Betaflight 2025.12:从飞行控制器到飞行艺术家——开源飞控系统的架构演进与实践
Betaflight 2025.12:从飞行控制器到飞行艺术家——开源飞控系统的架构演进与实践 【免费下载链接】betaflight Open Source Flight Controller Firmware 项目地址: https://gitcode.com/gh_mirrors/be/betaflight 在无人机技术快速发展的今天,飞行…...

因果推断中倾向得分校准:提升双稳健机器学习估计精度的关键
1. 项目概述:当因果推断遇上“不准”的机器学习在观察性研究中做因果推断,就像在迷雾中寻找一条真实的路径。我们手头有大量的数据(协变量X)、处理状态(D,比如是否参加了某个培训项目)和结果&am…...

终极指南:用Whisky在Mac上免费运行Windows游戏与软件的完整方案
终极指南:用Whisky在Mac上免费运行Windows游戏与软件的完整方案 【免费下载链接】Whisky A modern Wine wrapper for macOS built with SwiftUI 项目地址: https://gitcode.com/gh_mirrors/wh/Whisky 还在为Mac无法运行Windows专属软件而烦恼吗?W…...

Frida CLR绑定:.NET动态插桩与运行时可观测性实战
1. 这不是“给.NET加个Hook”,而是让CLR自己开口说话很多人第一次听说“Frida CLR绑定”,下意识反应是:“哦,又一个在.NET程序里打补丁的工具?”——这理解偏差得有点远。它根本不是在应用层API上做拦截,也…...

如何快速掌握XELFViewer:Linux二进制文件分析的终极指南
如何快速掌握XELFViewer:Linux二进制文件分析的终极指南 【免费下载链接】XELFViewer ELF file viewer/editor for Windows, Linux and MacOS. 项目地址: https://gitcode.com/gh_mirrors/xe/XELFViewer 你是否曾面对复杂的Linux可执行文件感到无从下手&…...

RDP Wrapper:免费解锁Windows家庭版多用户远程桌面功能
RDP Wrapper:免费解锁Windows家庭版多用户远程桌面功能 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap RDP Wrapper Library是一个创新的开源项目,专为Windows家庭版和基础版用户提供完整的…...

联想刃7000K BIOS高级配置优化指南:解锁隐藏参数设置与性能调优
联想刃7000K BIOS高级配置优化指南:解锁隐藏参数设置与性能调优 【免费下载链接】Lenovo-7000k-Unlock-BIOS Lenovo联想刃7000k2021-3060版解锁BIOS隐藏选项并提升为Admin权限 项目地址: https://gitcode.com/gh_mirrors/le/Lenovo-7000k-Unlock-BIOS 本文详…...

在Node.js服务中集成Taotoken实现统一的大模型API调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js服务中集成Taotoken实现统一的大模型API调用 对于需要在产品中集成AI能力的中小团队而言,直接管理多个大模型…...

如何彻底解决QQ音乐加密格式的播放限制?
如何彻底解决QQ音乐加密格式的播放限制? 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 还在为下载的QQ音乐文件无法在其他设备上播放而烦恼吗?你是…...