RabbitMQ保证消息的可靠性
1. 问题引入
消息从发送,到消费者接收,会经理多个过程:

其中的每一步都可能导致消息丢失,常见的丢失原因包括:
- 发送时丢失:
- 生产者发送的消息未送达exchange
- 消息到达exchange后未到达queue
- MQ宕机,queue将消息丢失
- consumer接收到消息后未消费就宕机
针对这些问题,RabbitMQ分别给出了解决方案:
- 生产者确认机制
- mq持久化
- 消费者确认机制
- 失败重试机制
2. 生产者消息确认
RabbitMQ提供了publisher confirm机制来避免消息发送到MQ过程中丢失。这种机制必须给每个消息指定一个唯一ID。消息发送到MQ以后,会返回一个结果给发送者,表示消息是否处理成功。
返回结果有两种方式:
- publisher-confirm,发送者确认
- 消息成功投递到交换机,返回ack
- 消息未投递到交换机,返回nack
- publisher-return,发送者回执
- 消息投递到交换机了,但是没有路由到队列。返回ACK,及路由失败原因。

- 消息投递到交换机了,但是没有路由到队列。返回ACK,及路由失败原因。
注意:

2.1 修改配置
首先,修改publisher服务中的application.yml文件,添加下面的内容:
spring:rabbitmq:publisher-confirm-type: correlatedpublisher-returns: truetemplate:mandatory: true说明:
publish-confirm-type:开启publisher-confirm,这里支持两种类型:simple:同步等待confirm结果,直到超时correlated:异步回调,定义ConfirmCallback,MQ返回结果时会回调这个ConfirmCallback
publish-returns:开启publish-return功能,同样是基于callback机制,不过是定义ReturnCallbacktemplate.mandatory:定义消息路由失败时的策略。true,则调用ReturnCallback;false:则直接丢弃消息
2.2 定义Return回调
每个RabbitTemplate只能配置一个ReturnCallback,因此需要在项目加载时配置:
修改publisher服务,添加一个:
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.BeansException;
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
import org.springframework.context.annotation.Configuration;@Slf4j
@Configuration
public class CommonConfig implements ApplicationContextAware {@Overridepublic void setApplicationContext(ApplicationContext applicationContext) throws BeansException {// 获取RabbitTemplateRabbitTemplate rabbitTemplate = applicationContext.getBean(RabbitTemplate.class);// 设置ReturnCallbackrabbitTemplate.setReturnCallback((message, replyCode, replyText, exchange, routingKey) -> {// 投递失败,记录日志log.info("消息发送失败,应答码{},原因{},交换机{},路由键{},消息{}",replyCode, replyText, exchange, routingKey, message.toString());// 如果有业务需要,可以重发消息});}
}
2.3 定义ConfirmCallback
ConfirmCallback可以在发送消息时指定,因为每个业务处理confirm成功或失败的逻辑不一定相同。
在publisher服务的测试类中,定义一个单元测试方法:
public void testSendMessage2SimpleQueue() throws InterruptedException {// 1.消息体String message = "hello, spring amqp!";// 2.全局唯一的消息ID,需要封装到CorrelationData中CorrelationData correlationData = new CorrelationData(UUID.randomUUID().toString());// 3.添加callbackcorrelationData.getFuture().addCallback(result -> {if(result.isAck()){// 3.1.ack,消息成功log.debug("消息发送成功, ID:{}", correlationData.getId());}else{// 3.2.nack,消息失败log.error("消息发送失败, ID:{}, 原因{}",correlationData.getId(), result.getReason());}},ex -> log.error("消息发送异常, ID:{}, 原因{}",correlationData.getId(),ex.getMessage()));// 4.发送消息rabbitTemplate.convertAndSend("task.direct", "task", message, correlationData);// 休眠一会儿,等待ack回执Thread.sleep(2000);
}
3. 消息持久化
生产者确认可以确保消息投递到RabbitMQ的队列中,但是消息发送到RabbitMQ以后,如果突然宕机,也可能导致消息丢失。
要想确保消息在RabbitMQ中安全保存,必须开启消息持久化机制。
- 交换机持久化
- 队列持久化
- 消息持久化
3.1 交换机持久化
RabbitMQ中交换机默认是非持久化的,mq重启后就丢失。
SpringAMQP中可以通过代码指定交换机持久化:
@Bean
public DirectExchange simpleExchange(){// 三个参数:交换机名称、是否持久化、当没有queue与其绑定时是否自动删除return new DirectExchange("simple.direct", true, false);
}
事实上,默认情况下,由SpringAMQP声明的交换机都是持久化的。
可以在RabbitMQ控制台看到持久化的交换机都会带上D的标示:

3.2 队列持久化
RabbitMQ中队列默认是非持久化的,mq重启后就丢失。
SpringAMQP中可以通过代码指定交换机持久化:
@Bean
public Queue simpleQueue(){// 使用QueueBuilder构建队列,durable就是持久化的return QueueBuilder.durable("simple.queue").build();
}
事实上,默认情况下,由SpringAMQP声明的队列都是持久化的。
可以在RabbitMQ控制台看到持久化的队列都会带上D的标示:

3.3 消息持久化
利用SpringAMQP发送消息时,可以设置消息的属性(MessageProperties),指定delivery-mode:
- 1:非持久化
- 2:持久化
用Java代码指定:

默认情况下,SpringAMQP发出的任何消息都是持久化的,不用特意指定。
4. 消费者消息确认
RabbitMQ是阅后即焚机制,RabbitMQ确认消息被消费者消费后会立刻删除。
而RabbitMQ是通过消费者回执来确认消费者是否成功处理消息的:消费者获取消息后,应该向RabbitMQ发送ACK回执,表明自己已经处理消息。
设想这样的场景:
- 1)RabbitMQ投递消息给消费者
- 2)消费者获取消息后,返回ACK给RabbitMQ
- 3)RabbitMQ删除消息
- 4)消费者宕机,消息尚未处理
这样,消息就丢失了。因此消费者返回ACK的时机非常重要。
而SpringAMQP则允许配置三种确认模式:
•manual:手动ack,需要在业务代码结束后,调用api发送ack。
•auto:自动ack,由spring监测listener代码是否出现异常,没有异常则返回ack;抛出异常则返回nack
•none:关闭ack,MQ假定消费者获取消息后会成功处理,因此消息投递后立即被删除
由此可知:
- none模式下,消息投递是不可靠的,可能丢失
- auto模式类似事务机制,出现异常时返回nack,消息回滚到mq;没有异常,返回ack
- manual:自己根据业务情况,判断什么时候该ack
一般,我们都是使用默认的auto即可。
4.1 none模式
修改consumer服务的application.yml文件,添加下面内容:
spring:rabbitmq:listener:simple:acknowledge-mode: none # 关闭ack
修改consumer服务的SpringRabbitListener类中的方法,模拟一个消息处理异常:
@RabbitListener(queues = "simple.queue")
public void listenSimpleQueue(String msg) {log.info("消费者接收到simple.queue的消息:【{}】", msg);// 模拟异常System.out.println(1 / 0);log.debug("消息处理完成!");
}
测试可以发现,当消息处理抛异常时,消息依然被RabbitMQ删除了。
4.2 auto模式
再次把确认机制修改为auto:
spring:rabbitmq:listener:simple:acknowledge-mode: auto # 关闭ack
在异常位置打断点,再次发送消息,程序卡在断点时,可以发现此时消息状态为unack(未确定状态):

抛出异常后,因为Spring会自动返回nack,所以消息恢复至Ready状态,并且没有被RabbitMQ删除:

5. 消费失败重试机制
当消费者出现异常后,消息会不断requeue(重入队)到队列,再重新发送给消费者,然后再次异常,再次requeue,无限循环,导致mq的消息处理飙升,带来不必要的压力:

怎么办呢?
5.1 本地重试
我们可以利用Spring的retry机制,在消费者出现异常时利用本地重试,而不是无限制的requeue到mq队列。
修改consumer服务的application.yml文件,添加内容:
spring:rabbitmq:listener:simple:retry:enabled: true # 开启消费者失败重试initial-interval: 1000 # 初识的失败等待时长为1秒multiplier: 1 # 失败的等待时长倍数,下次等待时长 = multiplier * last-intervalmax-attempts: 3 # 最大重试次数stateless: true # true无状态;false有状态。如果业务中包含事务,这里改为false
重启consumer服务,重复之前的测试。可以发现:
- 在重试3次后,SpringAMQP会抛出异常AmqpRejectAndDontRequeueException,说明本地重试触发了
- 查看RabbitMQ控制台,发现消息被删除了,说明最后SpringAMQP返回的是ack,mq删除消息了
结论:
- 开启本地重试时,消息处理过程中抛出异常,不会requeue到队列,而是在消费者本地重试
- 重试达到最大次数后,Spring会返回ack,消息会被丢弃
5.2 失败策略
在之前的测试中,达到最大重试次数后,消息会被丢弃,这是由Spring内部机制决定的。
在开启重试模式后,重试次数耗尽,如果消息依然失败,则需要有MessageRecovery接口来处理,它包含三种不同的实现:
-
RejectAndDontRequeueRecoverer:重试耗尽后,直接reject,丢弃消息。默认就是这种方式
-
ImmediateRequeueMessageRecoverer:重试耗尽后,返回nack,消息重新入队
-
RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机
比较优雅的一种处理方案是RepublishMessageRecoverer,失败后将消息投递到一个指定的,专门存放异常消息的队列,后续由人工集中处理。
1)在consumer服务中定义处理失败消息的交换机和队列
@Bean
public DirectExchange errorMessageExchange(){return new DirectExchange("error.direct");
}
@Bean
public Queue errorQueue(){return new Queue("error.queue", true);
}
@Bean
public Binding errorBinding(Queue errorQueue, DirectExchange errorMessageExchange){return BindingBuilder.bind(errorQueue).to(errorMessageExchange).with("error");
}
2)定义一个RepublishMessageRecoverer,关联队列和交换机
@Bean
public MessageRecoverer republishMessageRecoverer(RabbitTemplate rabbitTemplate){return new RepublishMessageRecoverer(rabbitTemplate, "error.direct", "error");
}
完整代码:
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.DirectExchange;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.amqp.rabbit.retry.MessageRecoverer;
import org.springframework.amqp.rabbit.retry.RepublishMessageRecoverer;
import org.springframework.context.annotation.Bean;@Configuration
public class ErrorMessageConfig {@Beanpublic DirectExchange errorMessageExchange(){return new DirectExchange("error.direct");}@Beanpublic Queue errorQueue(){return new Queue("error.queue", true);}@Beanpublic Binding errorBinding(Queue errorQueue, DirectExchange errorMessageExchange){return BindingBuilder.bind(errorQueue).to(errorMessageExchange).with("error");}@Beanpublic MessageRecoverer republishMessageRecoverer(RabbitTemplate rabbitTemplate){return new RepublishMessageRecoverer(rabbitTemplate, "error.direct", "error");}
}
6. 总结
如何确保RabbitMQ消息的可靠性?
- 开启生产者确认机制,确保生产者的消息能到达队列
- 开启持久化功能,确保消息未消费前在队列中不会丢失
- 开启消费者确认机制为auto,由spring确认消息处理成功后完成ack
- 开启消费者失败重试机制,并设置MessageRecoverer,多次重试失败后将消息投递到异常交换机,交由人工处理
相关文章:
RabbitMQ保证消息的可靠性
1. 问题引入 消息从发送,到消费者接收,会经理多个过程: 其中的每一步都可能导致消息丢失,常见的丢失原因包括: 发送时丢失: 生产者发送的消息未送达exchange消息到达exchange后未到达queue MQ宕机&…...

【工作实践-02】实验室移动端—跳转页面及交互
一、跳转页面不关闭当前页,与uniapp头部导航栏的返回按钮效果相似 uni.navigateBack({delta: 1}) 二、返回页面并刷新 1. 返回上一页时重新获取列表(调用上一页面获取列表方法) let pages getCurrentPages(); // 当前页面let beforePage pages[pages.length - 2…...

HTTP 请求 400错误
问题 HTTP 请求 400错误 详细问题 客户端发送请求 public static UserInfo updateUserInfo(UserInfo userInfo) {// 创建 OkHttpClient 对象OkHttpClient client new OkHttpClient();// 创建请求体MediaType JSON MediaType.parse("application/json; charsetutf-8&…...

C语言---指针进阶
1.字符指针 int main() {char str1[] "hello world";char str2[] "hello world";const char* str3 "hello world.";const char* str4 "hello world.";if (str3 str4){//常量字符串在内存里面是无法修改的,所以没必要…...

QT-通信编码格式问题
这里写目录标题 一、项目场景1.QT客户端与服务端通信时,转化步骤如下:2.原数据示例3.转化后数据 二、问题描述1.采用Soap协议2.采用HTTP协议 三、原因分析四、解决方案 一、项目场景 1.QT客户端与服务端通信时,转化步骤如下: 1&…...

一文了解Web3.0真实社交先驱ERA
Web2时代,少数科技巨头垄断了全球近60亿人口的网络社交数据,并用之为自己牟利,用户无法掌控个人数据,打破该局面逐渐成为共识,于是,不少人看到了Web3社交赛道蕴含的巨大机遇,标榜着去中心化和抗…...
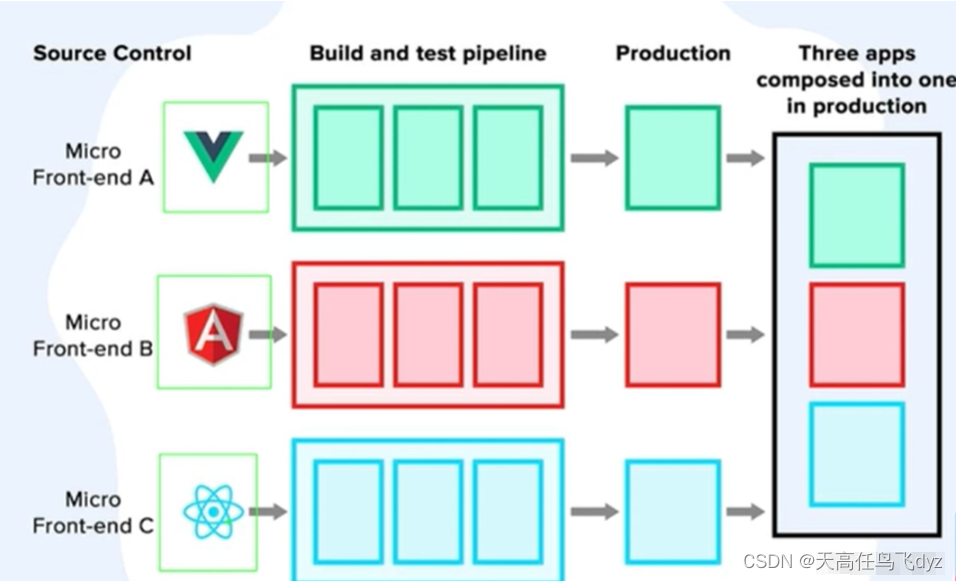
微前端(qiankun)vue3+vite
目录 一、什么是微前端 二、主应用接入 qiankun 1.按照qiankun插件 2.注册微应用引用 3.挂载容器 三、微应用接入 qiankun 1.vite.config.ts 2.main.ts ps:手动加载微应用方式 ps:为什么不用 iframe 一、什么是微前端 微前端是一种多个团队通过独…...
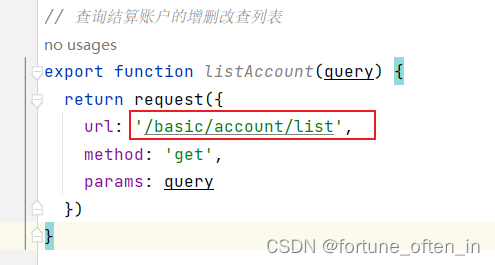
根据Ruoyi做二开
Ruoyi二开 前言菜单代码生成新建微服务网关添加微服务的路由 vue页面和对应的js文件js中方法的url和controller中方法的url总结 前言 之前写过一篇文章,若依微服务版本搭建,超详细,就介绍了怎么搭建若依微服务版本,我们使用若依就…...
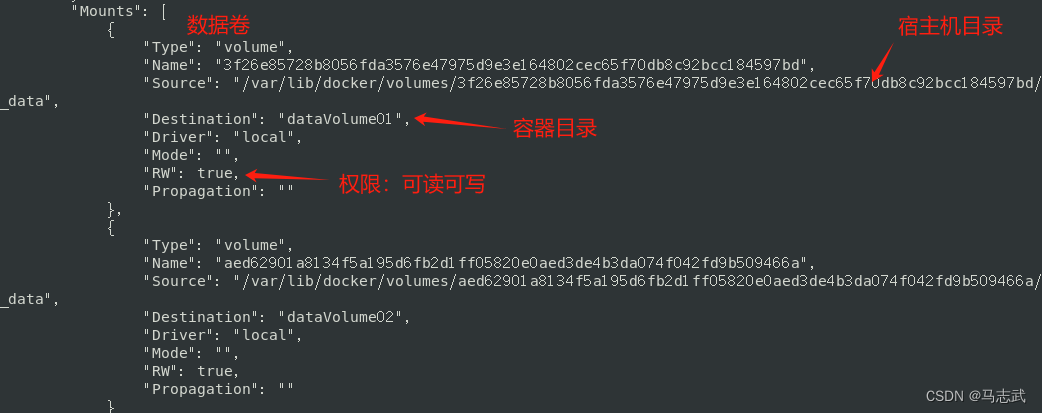
DockerFile的应用
DockerFile的应用 一、介绍1 构建的三步骤2 构建的过程 二、常用命令三、DockerFile案例1 创建DockerFile文件2 使用DockerFile文件构建镜像3 启动容器并验证 四 DockerFile添加数据卷 一、介绍 DockerFile是用来构建Docker镜像的构建文件,是由一系列命令和参数构成…...
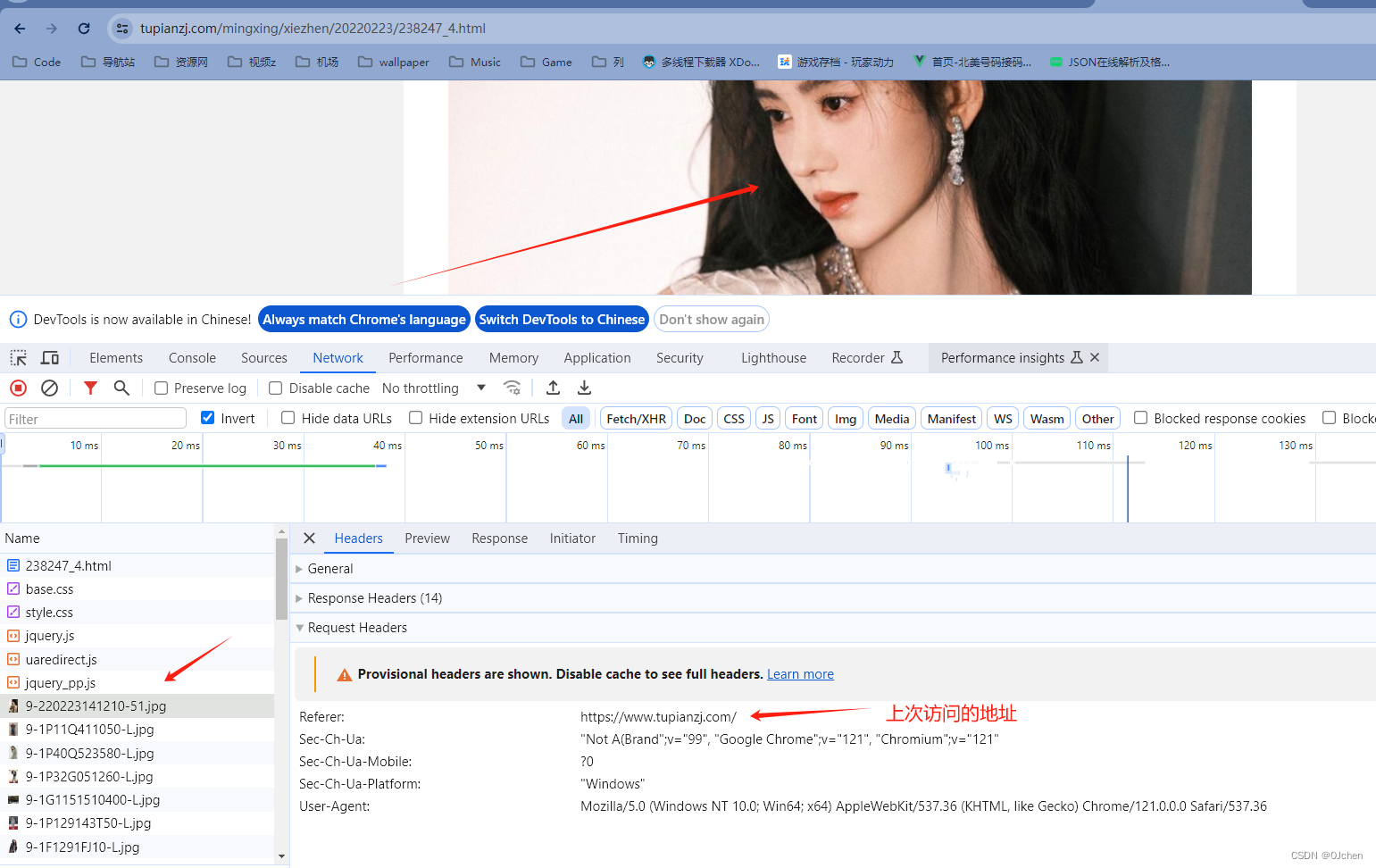
爬虫入门一
文章目录 一、什么是爬虫?二、爬虫基本流程三、requests模块介绍四、requests模块发送Get请求五、Get请求携带参数六、携带请求头七、发送post请求八、携带cookie方式一:放在请求头中方式二:放在cookie参数中 九、post请求携带参数十、模拟登…...

2024-02-16 web3-区块链-keypass记录
摘要: 2024-02-16 web3-区块链-keypass记录 文档: Introduction - Keypass Docs What is KEYPASS? - Keypass Docs What is KEYPASS? KeyPass Wallet is a new smart contract wallet that provides a secure and customizable registration…...

使用 JMimeMagic 在 Java 中识别文件类型
在 Java 中,我们可以使用 JMimeMagic 库来识别文件类型,尤其是在需要准确区分文件类型时。下面是一个简单的使用 JMimeMagic 的示例代码。 添加依赖 首先,在你的项目中添加 JMimeMagic 依赖。你可以在 Maven 项目中的 pom.xml 文件中加入以…...
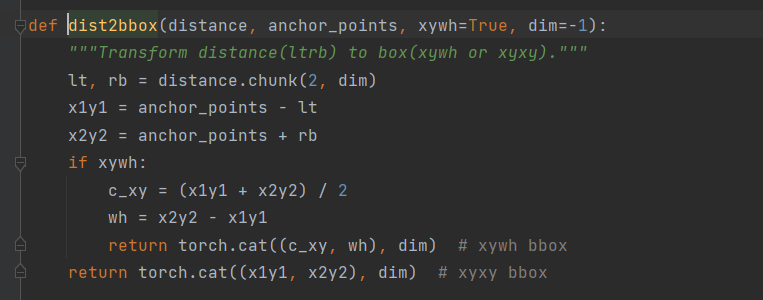
yolov8源码解读Detect层
yolov8源码解读Detect层 Detect层解读网络各层解读及detect层后的处理 关于网络的backbone,head,以及detect层后处理,可以参考文章结尾博主的文章。 Detect层解读 先贴一下全部代码,下面一一解读。 class Detect(nn.Module):"""YOLOv8 …...
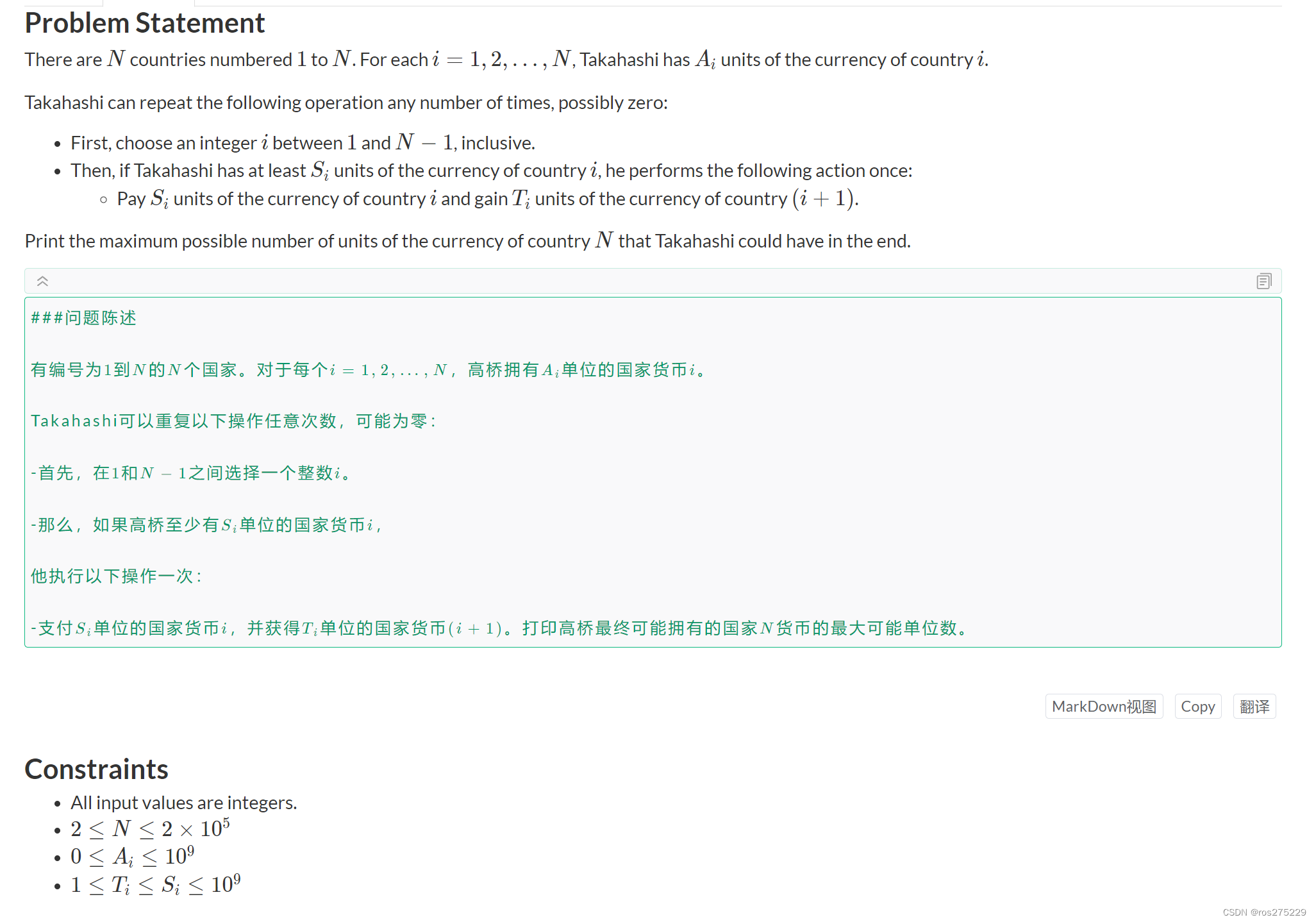
(AtCoder Beginner Contest 341)(A - D)
比赛地址 : Tasks - Toyota Programming Contest 2024#2(AtCoder Beginner Contest 341) A . Print 341 模拟就好了 , 先放一个 1 , 然后放 n 个 01 ; #include<bits/stdc.h> #define IOS ios::sync_with_stdio(0);cin.tie(0);cout…...

python Flask与微信小程序 统计管理
common/models/stat/StatDailyMember.py DROP TABLE IF EXISTS stat_daily_member;CREATE TABLE stat_daily_member (id int(11) unsigned NOT NULL AUTO_INCREMENT,date date NOT NULL COMMENT 日期,member_id int(11) NOT NULL DEFAULT 0 COMMENT 会员id,total_shared_count …...

光伏企业助力乡村振兴
光伏是一种利用太阳能生产电能的发电技术,属于可再生能源。近年来我国的光伏企业发展迅速,已经称霸全球,同时也为乡村振兴贡献了力量。 一、光伏企业助力乡村 1.推动农业发展 光伏发电和农业种植、畜牧、渔业、水产等有机结合,…...

root MUSIC 算法补充说明
root MUSIC 算法补充说明 多项式求根root MUSIC 算法原理如何从 2 M − 2 2M-2 2M−2 个根中确定 K K K 个根从复数域上观察 2 M − 2 2M-2 2M−2 个根的分布 这篇笔记是上一篇关于 root MUSIC 笔记的补充。 多项式求根 要理解 root MUSIC 算法,需要理解多项式求…...

关于Django的中间件使用说明。
目录 1.中间件2. 为什么要中间件?3. 具体使用中间件3.1 中间件所在的位置:在django的settings.py里面的MIDDLEWARE。3.2 中间件的创建3.3 中间件的使用 4. 展示成果 1.中间件 中间件的大概解释:在浏览器在请求服务器的时候,首先要…...

Chapter 8 - 15. Congestion Management in TCP Storage Networks
User Actions After learning the states of queue utilization, the following are the actions that admins and operators can take while using TCP transport for storage traffic. 了解了队列利用率的状态后,管理员和操作员在使用 TCP 传输存储流量时可以采取以下措施。…...

前端技巧之svg精灵图svg-sprite-loader
首先说明精灵图的必要性,其可以让我们只需要向服务器请求一次图片资源,就能加载很多图片,即能够减轻http请求造成的服务器压力。 然后这里要说明的是这个插件是webpack上面的,所以在vue2中比较好用,如果在vue3中&…...

3大技术突破:html-to-docx如何解决HTML转Word格式失真难题
3大技术突破:html-to-docx如何解决HTML转Word格式失真难题 【免费下载链接】html-to-docx HTML to DOCX converter 项目地址: https://gitcode.com/gh_mirrors/ht/html-to-docx html-to-docx是一款专为解决HTML到Word文档转换领域格式失真问题而设计的开源工…...

FlashMLA:把 KV Cache 压缩到原来的八分之一
标准 MHA 的 KV Cache 是推理显存的第一大户。LLaMA-7B,32 层,每层 32 头,HeadDim128,SeqLen128K——KV Cache 吃 40GB。MLA(Multi-head Latent Attention)用低秩分解把 KV 映射到一个远小于 HeadDim 的潜在…...

BOM 物料清单科普
BOM Bill of Materials 物料清单科普PLM、ERP、MES、SAP、数字孪生中的 BOM 全链路应用目录 前言 从"天天对 BOM"的经典场景切入,抛出核心问题一、BOM 的本质 还原 BOM 的真实定义,破除"BOM 物料清单"的误解二、全景图谱 完整 BOM …...

如何高效实现设备指纹保护:专业硬件伪装实战指南
如何高效实现设备指纹保护:专业硬件伪装实战指南 【免费下载链接】EASY-HWID-SPOOFER 基于内核模式的硬件信息欺骗工具 项目地址: https://gitcode.com/gh_mirrors/ea/EASY-HWID-SPOOFER EASY-HWID-SPOOFER是一款基于内核模式的硬件信息修改工具,…...

韭菜盒子:在VSCode中打造你的专属投资工作台,让代码与行情无缝融合
韭菜盒子:在VSCode中打造你的专属投资工作台,让代码与行情无缝融合 【免费下载链接】leek-fund :chart_with_upwards_trend: 韭菜盒子VSCode插件,可以看股票、基金、期货等实时数据。 LeekFund turns your VS Code and Cursor into a real-ti…...

揭秘AI教材写作技巧!低查重AI工具助力,3天完成50万字教材!
教材创作中AI工具的应用与优势 在教材编写的过程中,确保原创性与合规性的平衡是一个至关重要的问题。一方面,借鉴已有教材的优秀内容时,创作者往往会担心查重率超标;另一方面,自主进行原创知识点的阐释,又…...

ChatGPT企业版安全合规全解析:如何在72小时内完成GDPR/等保2.0双认证接入?
更多请点击: https://intelliparadigm.com 第一章:ChatGPT企业版核心架构与合规定位 ChatGPT企业版并非简单叠加访问权限的SaaS服务,而是基于隔离部署、数据主权保障与策略可编程性构建的合规优先架构。其底层采用多租户物理隔离的专用基础设…...

YCB数据集入门指南:从下载到3D模型可视化,手把手教你用Blender和Python搞定
YCB数据集实战指南:从零掌握3D模型处理全流程在机器人抓取、计算机视觉和增强现实领域,YCB数据集已成为行业标准之一。这个包含日常物品高精度3D模型的资源库,为算法开发提供了可靠的测试基准。但对于刚接触的研究者来说,从数据下…...
)
健身党福音:用YOLOv7+Python做个食物卡路里识别App(附完整源码和数据集)
从零打造智能饮食助手:YOLOv7与Python的卡路里识别实践每次站在自助餐厅琳琅满目的食物前,健身爱好者们都会面临一个灵魂拷问:这盘食物的热量到底有多少?传统的手动查询不仅效率低下,还经常因为分量估算不准导致热量计…...

机器学习均质化:用数据各向同性化破解砌体结构宏观建模难题
1. 项目概述:当砌体结构遇上机器学习均质化在土木工程和计算力学领域,我们常常面临一个经典难题:如何高效且准确地预测像砖砌体这类复杂复合材料的宏观力学行为?砌体由砖块和砂浆层交替组成,其微观结构是非均匀且各向异…...