浅谈业务场景中缓存的使用
浅谈缓存
- 一、背景
- 二、缓存分类
- 1.本地缓存
- 2.分布式缓存
- 三、缓存读写模式
- 1.读请求
- 2.写请求
- 四、缓存穿透
- 1.缓存空对象
- 2.请求校验
- 3.请求来源限制
- 4.布隆过滤器
- 五、缓存击穿
- 1.改变过期时间
- 2.串行访问数据库
- 六、缓存雪崩
- 1.避免集中过期
- 2.提前更新缓存
- 七、缓存与数据库一致性
- 1.设置缓存过期时间
- 2.更新缓存/更新数据库
- 2.1 先更新数据库再更新缓存
- 2.2 先更新缓存再更新数据库
- 3.先删除缓存再更新数据库
- 3.1 两个操作事务性操作情况如下:
- 3.2 数据一致性问题
- 4.先更新数据库再删除缓存
- 4.1 两个操作事务性操作情况如下:
- 4.2 补偿机制
- 4.3 数据一致性问题
- 5.延时双删
- 5.1 延时双删操作流程:
- 5.2 延迟双删优化
- 总结
一、背景
互联网相关业务相对于传统场景普遍存在高并发高流量的情况,因此在实际业务场景中,都会通过在业务和存储中间添加缓存层来减轻数据库的压力。使用缓存主要是为了提升响应速度和并发量,并减轻数据库的访问压力。在实际使用过程中需要解决缓存穿透、缓存击穿和缓存雪崩的发生,并且需要考虑缓存与数据库数据一致性问题。
二、缓存分类
缓存根据保存的位置不同分为本地缓存和分布式缓存。本地缓存就是保存在服务所在机器上,占用jvm内存空间;分布式缓存就是保存在独立的服务上如Redis集群上。
1.本地缓存
将一些只读基础数据进行本地缓存减轻数据库访问压力加快程序访问速度。这类数据特点变更不频繁,对缓存与数据库中数据不一致容忍度较高。服务启动时进行本地缓存加载,可以采用定时刷新缓存或者监听消息的方式重新加载缓存来保证本地缓存数据的实时性。
- 缺点:占用本地内存,数据量受限;每个服务都需要保存,副本较多;服务启动时需要加载,可能导致启动时间较长;
- 优点:本地缓存访问速度更快,独立缓存不互相影响
2.分布式缓存
将非只读数据保存在分布式缓存集群中可以提高服务的灵活度,提升响应速度提高并发量,这些数据基本都是程序运行过程中加载到缓存并在一段时间后会从缓存卸载。
- 缺点:需要部署额外缓存集群;需要提供多副本防止单点故障;业务集群共用,缓存污染容易导致整个业务不可用;
- 优点:不占用本地内存,数据量不受限制;与业务集群结偶,缓存保存在缓存集群中;服务运行过程中加载和卸载,不影响服务启动耗时;
三、缓存读写模式
经典的缓存+数据库读取 Cache Aside Pattern模型。
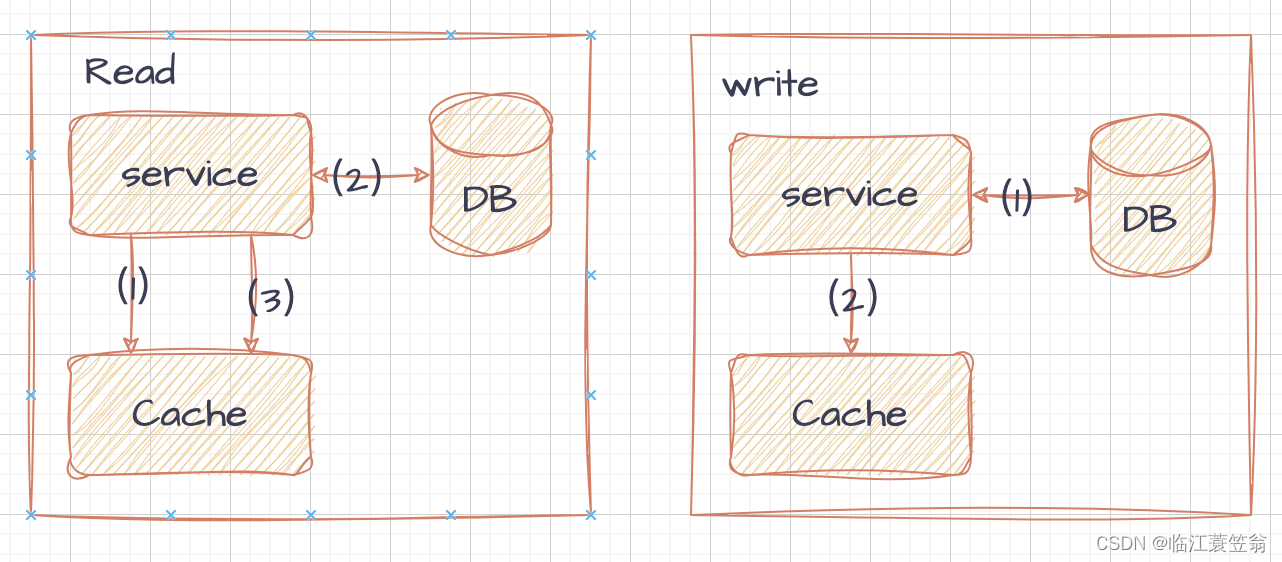
1.读请求
- 读的时候先从缓存读取
- 如果缓存中不存在,则需要从数据库中读取
- 数据取出后需要写入到缓存中
2.写请求
- 更新时需要先更新数据库
- 然后删除缓存
四、缓存穿透
缓存穿透是指查询了一个在数据库和缓存中都不存在的数据。由经典 Cache Aside Pattern模型可知,所有请求都会进行数据库查询,如果请求非常多会给数据库造成访问压力乃至奔溃。造成这种场景有可能是误删除数据或者恶意攻击导致的。
为了防止此问题,基本都是采用空间换时间,也就是对访问请求进行一定拦截和过滤。
1.缓存空对象
当查询数据库无结果时,将空对象保存到缓存中并设置一个过期时间。当在缓存过期时间内,相同的请求在缓存中都可以查询到结果而不会访问到数据库。过期时间内数据库即使新增了数据也不会加载到缓存,因此需要合理设置过期时间长度。
2.请求校验
对于请求进行数据合法性校验,将不合法校验直接拦截,不进行缓存和数据库的查询操作。
3.请求来源限制
可以通过设置黑白名单,对请求来源进行限制,保证没有恶意攻击行为和非法请求。
4.布隆过滤器
将数据库中数据保存到布隆过滤器中,当请求过来先经过布隆过滤器,如果不存在直接拒绝,如果存在则继续查询。
五、缓存击穿
缓存击穿是查询的数据在缓存中不存在,但是数据库中存在。当缓存中key过期,而此时有大量并发请求此key会导致数据库压力剧增。可以通过限制同时查询数据库的请求或者缓存的过期时间避免此问题。
1.改变过期时间
设置热点数据永不过期
2.串行访问数据库
缓存击穿是大量并发请求同时进行数据库查询导致的。可以在进行对应数据库查询之前进行加锁操作。
2.1 当查询key时,首先查询缓存,如果没有。需要先获取分布式锁才能进入数据库查询然后将查询结果保存到缓存,然后解锁。
2.2 如果发现查询锁被占用,则说明有线程正在获取。所以等待锁接触后可以直接访问缓存而不必进行数据库查询操作。
六、缓存雪崩
缓存雪崩是指缓存中大批量key同时过期,而此时又是流量高峰导致后端数据库压力暴增,甚至会导致数据库挂掉。缓存击穿是指单个key过期,缓存雪崩是指大量key同时过期。
1.避免集中过期
将缓存中的数据缓存时间在原有的失效时间基础上加一个随机值,这样可以避免集体失效引发雪崩。
2.提前更新缓存
可以在缓存中数据过期前,主动更新缓存中的数据,防止数据到达TTL。
七、缓存与数据库一致性
由于缓存和数据库是两个数据源,如果想要保证两个数据源的强一致性需要对读写操作进行加锁处理和事务处理,但是加锁之后会影响整个系统的响应速度,基本不会采用此方式进行处理。在实际场景中,在强一致性和系统性能上采取一个妥协,基本上都是要求缓存和数据库在短时间内一致即可,也就是最终一致性而不要求强一致性。
1.设置缓存过期时间
此方案针对数据要求一致性比较低或者读多写少的业务场景。读时缓存如果没有数据,从数据库读取后写入缓存并设置过期时间。写时直接写入数据库,不操作缓存。
2.更新缓存/更新数据库
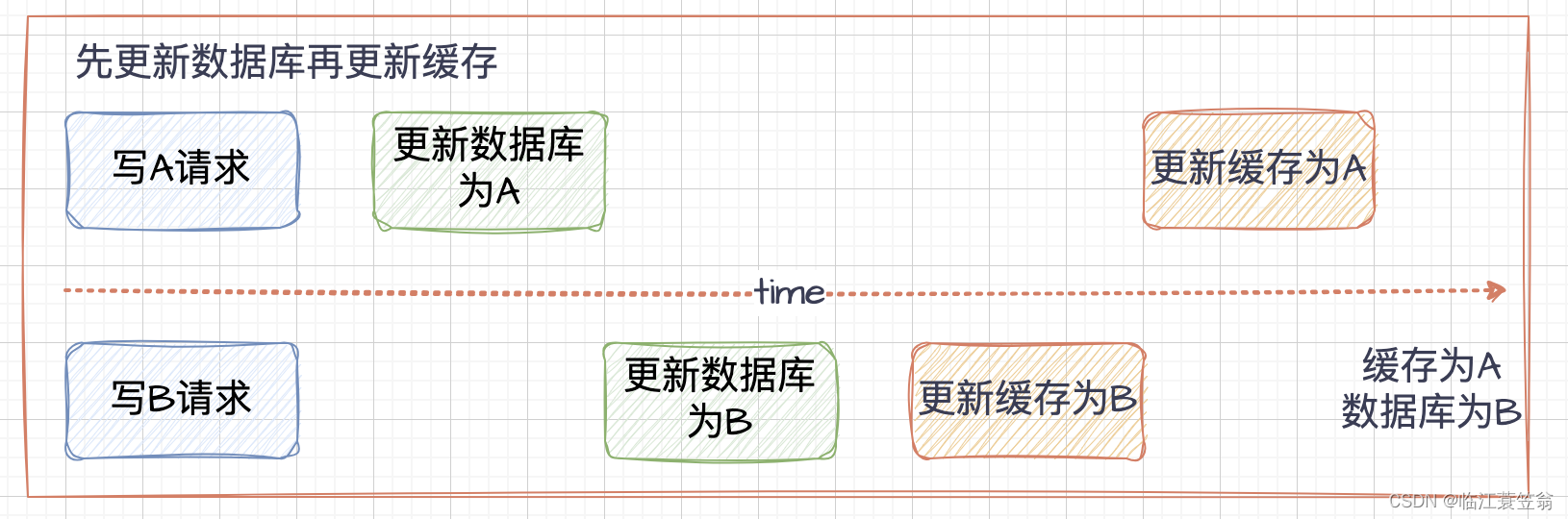
由于更新数据库和更新缓存有可能有一定的延迟和间隔。在并发写请求的情况下,不论先更新缓存后更新数据库,还是先更新数据库后更新缓存,都可能存在数据库和缓存数据不一致的情况。由于数据库和缓存都更新成功都有很大概率出现数据不一致的情况,所以不讨论其中一个失败的情况。
2.1 先更新数据库再更新缓存
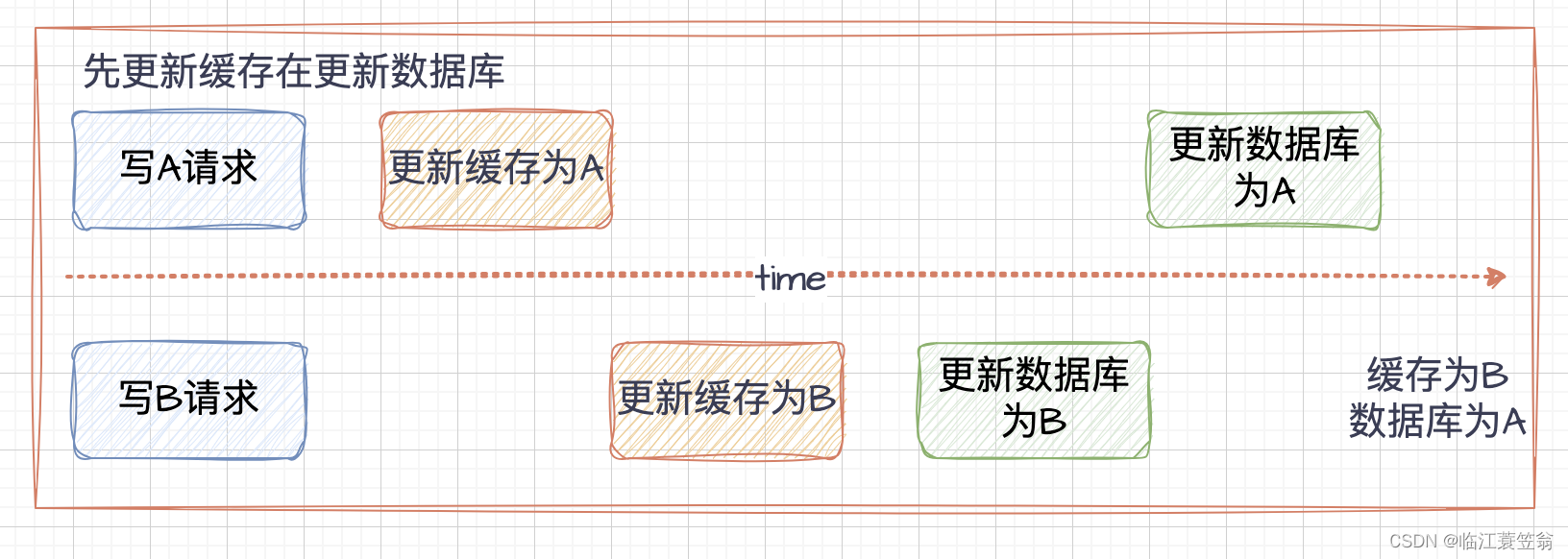
2.2 先更新缓存再更新数据库
3.先删除缓存再更新数据库
3.1 两个操作事务性操作情况如下:
1) 删除缓存成功,更新数据库成功
2 )删除缓存失败,程序异常,不会进行更新数据库操作
3 )删除缓存成功,更新数据库失败,由于数据库还是旧数据,缓存中为空,数据不会不一致
3.2 数据一致性问题
在删除缓存和更新数据库操作之间的读请求,会从数据库读取旧数据然后写入到缓存中导致数据不一致。
4.先更新数据库再删除缓存
4.1 两个操作事务性操作情况如下:
1) 更新数据库成功,删除缓存成功
2 )更新数据库失败,程序异常,不会进行删除缓存操作
3 )更新数据库成功,删除缓存失败,由于数据库是新数据,缓存是旧数据,数据出现不一致
4.2 补偿机制
- 删除失败重试,如果删除缓存失败,需要把此信息发送到消息队列,进行异步删除
- 监听数据库变更,建立一个服务监听binlog变化,然后删除缓存。
4.3 数据一致性问题
出现数据不一致的条件是否苛刻,基本不会出现
5.延时双删
先更新数据库再删除缓存已经很好的解决了缓存和数据库一致性问题。但是现在的数据库基本都是进行了主从配置,也就是主库负责数据写入,从库负责数据读取。这样在数据同步到从库之前,可能读取从库旧数据然后写入缓存导致数据不一致。
5.1 延时双删操作流程:
1) 先删除缓存,可以加快缓存与数据库数据同步速度(高并发时可能数据库不断有值写入)
2 )更新数据库
3 )延迟一段时间(大于主从同步时间)删除缓存(等待新数据同步到从库)
5.2 延迟双删优化
延迟双删数据库与缓存至少需要等待数据同步到从库才会数据一致。可以在更新数据库之后,将key进行标记,然后立刻删除缓存。当读数据时,如果缓存中没有数据,需要看key是否进行了标记,如果标记了需要从主库读取数据人然后保存到缓存,并删除此标记。
此方案相当于牺牲了主库的一部分性能,来尽可能保证数据一致性。
总结
缓存是提高系统响应和吞吐量的一个方法,但是使用过程中需要解决缓存穿透、缓存击穿、缓存雪崩等问题,并且需要考虑缓存和数据库的数据一致性问题。如果考虑到程序的可靠性,建议程序对缓存是弱依赖,也就是即使缓存系统完全不可用,也可以保证程序在响应速度和吞吐量降低的情况下,运行的正确性和数据的完整性。
相关文章:
浅谈业务场景中缓存的使用
浅谈缓存 一、背景二、缓存分类1.本地缓存2.分布式缓存 三、缓存读写模式1.读请求2.写请求 四、缓存穿透1.缓存空对象2.请求校验3.请求来源限制4.布隆过滤器 五、缓存击穿1.改变过期时间2.串行访问数据库 六、缓存雪崩1.避免集中过期2.提前更新缓存 七、缓存与数据库一致性1.设…...

Itext生成pdf文件,html转pdf时中文一直显示不出来
之前使用freemark模板渲染ftl页面,转出的pdf中,css2有些样式好像不支持,比较常用的居中样式都没有效果,text-align:center 改造成使用html页面来转pdf,css2的样式可以生效,itext是不支持css3的弹性布局的ITextRenderer pdfRendere…...

题目 1138: C语言训练-求矩阵的两对角线上的元素之和
问题描述: 求矩阵的两对角线上的元素之和 样例输入: 3 1 2 3 4 5 6 7 8 9 样例输出: 25 问题分析: 因为奇数阶矩阵的主对角线和副对角线上的元素有重复,偶数阶矩阵的主对角线和副对角线上的元素无重复&#x…...
第6讲自定义icon实现
自定义icon实现 component下新建SvgIcon目录,再新建index.vue 定义svg-icon组件 <template><svg class"svg-icon" aria-hidden"true"><use :xlink:href"iconName"></use></svg> </template>&…...

花费200元,我用全志H616和雪糕棒手搓了一台可UI交互的视觉循迹小车
常见的视觉循迹小车都具备有路径识别、轨迹跟踪、转向避障、自主决策等基本功能,如果不采用红外避障的方案,那么想要完全满足以上这些功能,摄像头、电机、传感器这类关键部件缺一不可,由此一来小车成本也就难以控制了。 但如果&a…...

AUTOSAR OS TASK
什么是TASK? 我们在裸机中跑代码,程序永远只能单活动流水执行,当程序需要等待的时候,CPU就一直在waiting状态,无法高效的利用CPU,这个时候就引入了并发运行需求。一个系统能同时执行多个不同活动的系统叫做并发系统。其中这个系统中的每个并发执行的活动都由TASK(任务)…...
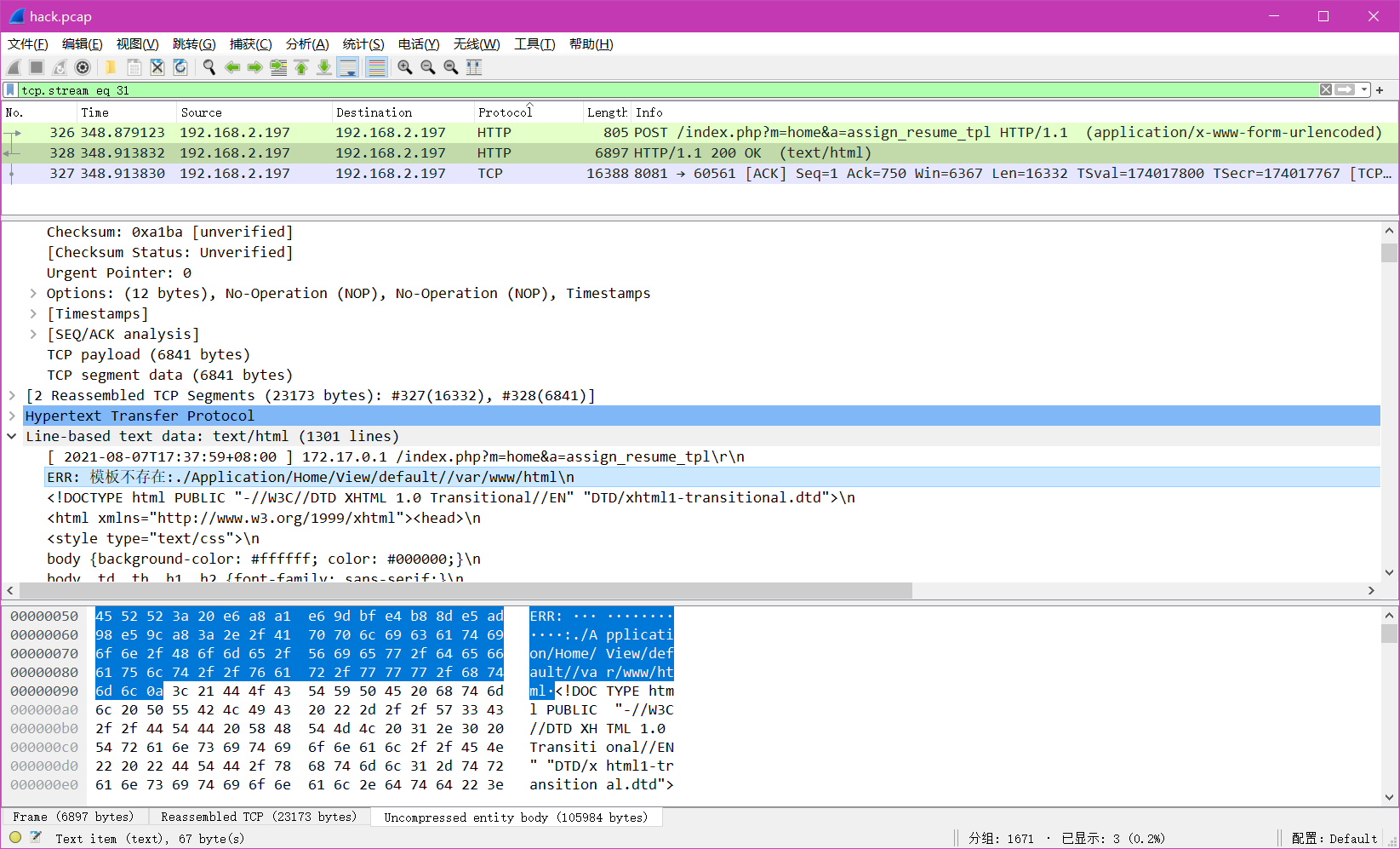
陇剑杯 2021刷题记录
题目位置:https://www.nssctf.cn/上有 陇剑杯 2021 1. 签到题题目描述分析答案小结 2. jwt问1析1答案小结 问2析2答案小结 问3析3答案 问4析4答案 问5析5答案 问6析6答案 3. webshell问1析1答案 问2析2答案 问3析3答案 1. 签到题 题目描述 此时正在进行的可能是_…...
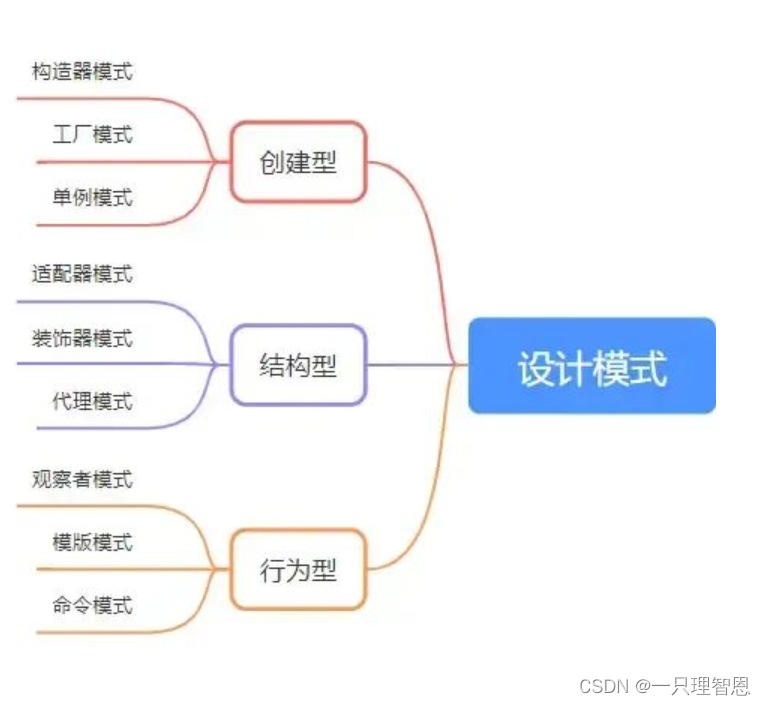
前端常见的设计模式
说到设计模式,大家想到的就是六大原则,23种模式。这么多模式,并非都要记住,但作为前端开发,对于前端出现率高的设计模式还是有必要了解并掌握的,浅浅掌握9种模式后,整理了这份文章。 六大原则&…...
OpenAI视频生成模型Sora的全面解析:从ViViT、扩散Transformer到NaViT、VideoPoet
前言 真没想到,距离视频生成上一轮的集中爆发(详见《Sora之前的视频生成发展史:从Gen2、Emu Video到PixelDance、SVD、Pika 1.0》)才过去三个月,没想OpenAI一出手,该领域又直接变天了 自打2.16日OpenAI发布sora以来(其开发团队包…...

3个密码学相关的问题
一、离散对数问题(Discrete Logarithm Problem, DLP) 问题描述:给定 有限阿贝尓群 G中的2个元素a和b,找出最小的正整数x满足:b a ^^ x (或者证明这样的x不存在)。 二、阶数问题(O…...

5G网络eMBB、uRLLC、mMTC
ITU(国际电信联盟)于2015年9月正式定义了5G的三大应用场景:eMBB(增强型移动宽带)、uRLLC(低时延高可靠通信)、mMTC(海量物联网通信)。 eMBB是4G MBB(移动宽带…...
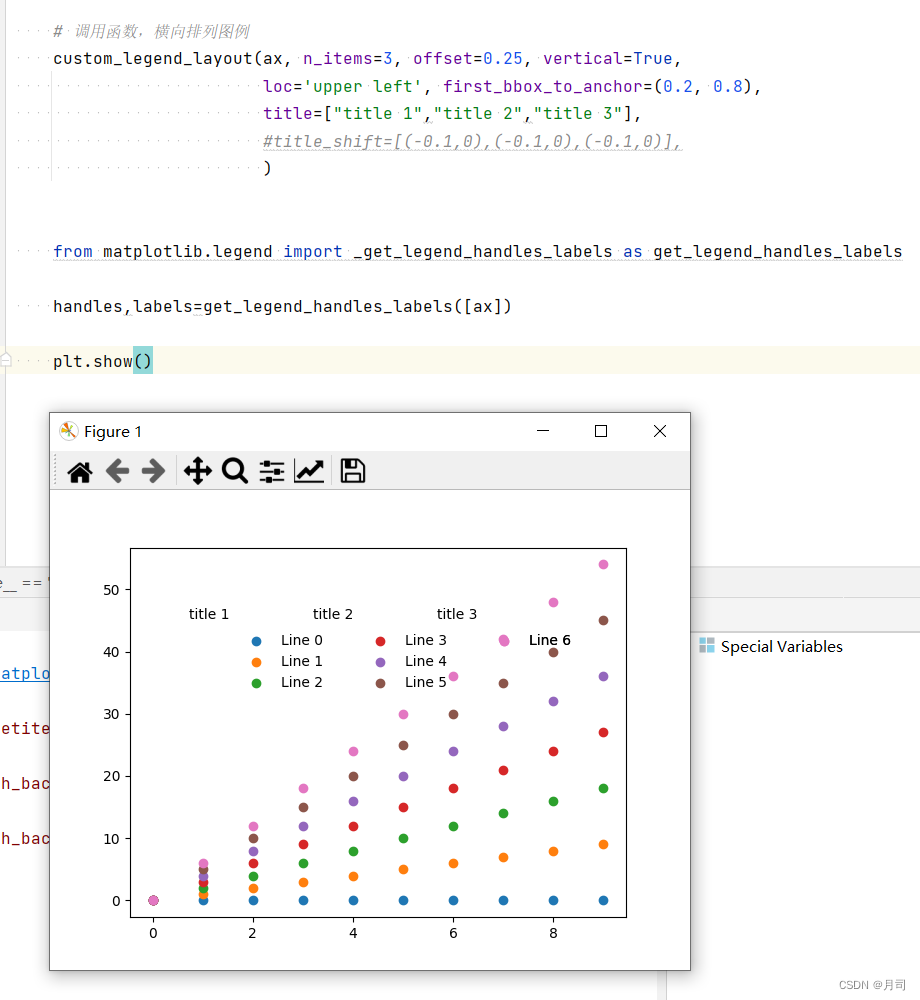
matplotlib图例使用案例1.1:在不同行或列的图例上添加title
我们将图例进行行显示或者列显示后,只能想继续赋予不同行或者列不同的title来进行分类。比较简单的方式,就是通过ax.annotate方法添加标签,这样方法复用率比较低,每次使用都要微调ax.annotate的显示位置。比较方便的方法是在案例1…...

nginx 日志改为json格式
nginx 日志改为json格式 场景描述效果变更旧样式新样式 场景描述 正常使用nginx时,使用默认的日志输出格式,对于后续日志接入其他第三方日志收集、清洗环节,因分隔符问题可能不是很友好。 xxxx - - [19/Feb/2024:11:16:48 0800] "GET …...
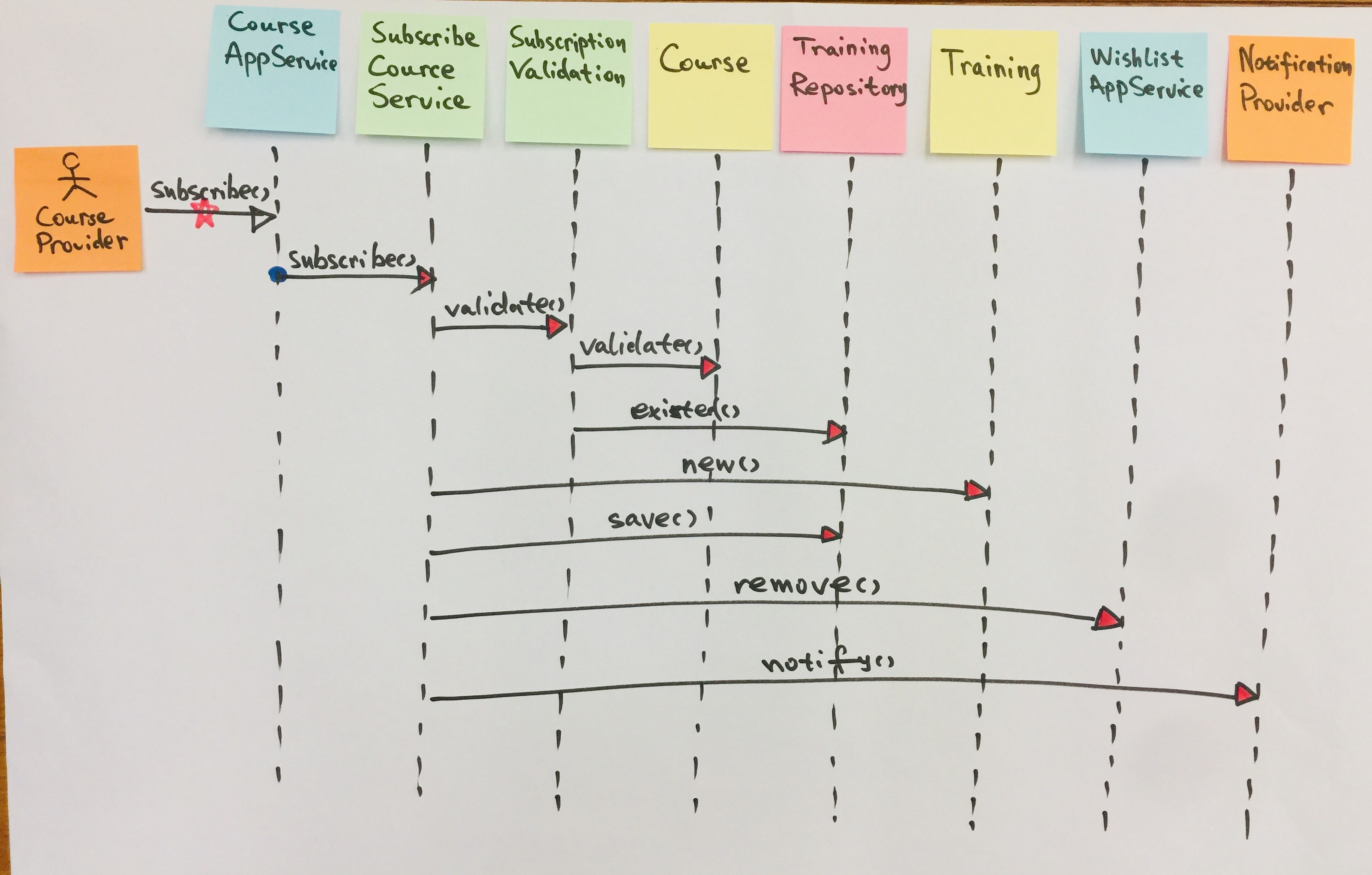
【DDD】学习笔记-应用服务
Eric Evans 为运用领域驱动设计的系统架构划定了层次,在领域层和展现层之间引入了应用层(Application Layer):“应用层要尽量简单,不包含业务规则或者知识,而只为下一层(指领域层)中…...
【医学大模型】MEDDM LLM-Executable CGT 结构化医学知识: 将临床指导树结构化,便于LLM理解和应用
MEDDM LLM-Executable CGT 结构化医学知识: 将临床指导树结构化,便于LLM理解和应用 提出背景对比传统医学大模型流程步骤临床指导树流程图识别临床决策支持系统 总结解决方案设计数据收集与处理系统实施临床决策支持 提出背景 论文:https://arxiv.org/p…...

YOLOV8改进系列指南
基于Ultralytics的YOLOV8改进项目.(69.9) 为了感谢各位对V8项目的支持,本项目的赠品是yolov5-PAGCP通道剪枝算法.具体使用教程 专栏改进汇总 二次创新系列 ultralytics/cfg/models/v8/yolov8-RevCol.yaml 使用(ICLR2023)Reversible Column Networks对yolov8主干进行重设计,里…...

FlinkSql一个简单的测试程序
FlinkSql一个简单的测试程序 以下是一个简单的 Flink SQL 示例,展示了如何使用 Flink Table API 和 Flink SQL 进行基本的数据流处理。 定义数据实体 CC : - CC 类表示数据流中的元素,包含两个字段: character (字符&a…...

二、ActiveMQ安装
ActiveMQ安装 一、相关环境二、安装Java8三、下载安装包四、启动五、其他命令六、开放端口七、后台管理 一、相关环境 环境:Centos7.9安装ActiveMQ版本:5.15.9JDK8 二、安装Java8 安装教程:https://qingsi.blog.csdn.net/article/details/…...

通俗易懂的L0范数和L1范数及其Python实现
定义 L0 范数(L0-Norm) L0 范数并不是真正意义上的一个范数,因为它不满足范数的三角不等式性质,但它在数学优化和信号处理等领域有着实际的应用。L0 范数指的是向量中非零元素的个数。它通常用来度量向量的稀疏性。数学上表示为…...

如何在30天内使用python制作一个卡牌游戏
如何在30天内使用python制作一个卡牌游戏 第1-5天:规划和设计第6-10天:搭建游戏框架第11-20天:核心游戏机制开发第21-25天:游戏界面和用户体验第26-30天:测试和发布附加建议游戏类型游戏规则设计界面设计技术选型第6-…...

独立开发者如何利用 Taotoken 的 Token Plan 套餐以更优成本启动 AI 项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用 Taotoken 的 Token Plan 套餐以更优成本启动 AI 项目 对于独立开发者或小型工作室而言,在项目启动…...

STM32H743音频实战:用CubeMX和I2S驱动WM8978,从寄存器配置到代码移植避坑
STM32H743音频实战:CubeMX与I2S驱动WM8978的深度避坑指南 第一次在STM32H743上调试WM8978音频编解码器时,我盯着示波器上杂乱无章的I2S信号波形发呆了半小时。耳机里偶尔传来的爆裂声仿佛在嘲笑我的无知——这场景想必很多嵌入式音频开发者都不陌生。本文…...

面试官问我SQL怎么调优,我直接甩出这套Explain对比法
面试官问我SQL怎么调优,我直接甩出这套Explain对比法 线上系统突然变慢,用户投诉纷至沓来,运维群里消息炸了锅。排查半天,发现罪魁祸首竟然是一条不起眼的SQL语句。这条SQL在测试环境跑得飞快,一到生产环境就像老牛拉破车。相信很多开发者都遇到过这种场景——SQL写的时候…...

五轴龙门机床厂家推荐,五轴龙门机床哪家好?
五轴龙门机床厂家推荐,五轴龙门机床哪家好?五轴龙门机床性能参数与场景适配分析。五轴龙门机床是高端装备制造的核心加工设备,广泛应用于航空航天、新能源、重工装备等领域。本文基于海天精工、纽威数控、环球工业机械、济南二机床四款主流国…...

基于RK3399核心板的智能PCR仪开发:从嵌入式系统到高精度温控
1. 项目概述:当PCR仪遇上高性能核心板在分子生物学实验室里,PCR仪(聚合酶链式反应仪)是当之无愧的“C位”设备。从基础的病原体检测、基因分型,到前沿的基因编辑、高通量测序文库构建,几乎每一个实验环节都…...

如何在现代显示器上完美重温经典游戏?终极宽屏修复工具包指南
如何在现代显示器上完美重温经典游戏?终极宽屏修复工具包指南 【免费下载链接】WidescreenFixesPack Plugins to make or improve widescreen resolutions support in games, add more features and fix bugs. 项目地址: https://gitcode.com/gh_mirrors/wi/Wides…...

SpringBoot-Scan:面向红队的SpringBoot资产指纹与测绘工作流
1. 这不是又一个“SpringBoot漏洞扫描器”教程,而是一份真实红队队员的资产测绘工作流你有没有遇到过这样的情况:手头刚拿到一个目标域名,技术栈标注着“SpringBoot 2.7.x”,但连它到底跑在哪个端口、是否启用了Actuator、有没有暴…...

Wifite2 终极指南:快速掌握无线网络安全审计工具
Wifite2 终极指南:快速掌握无线网络安全审计工具 【免费下载链接】wifite2 Rewrite of the popular wireless network auditor, "wifite" 项目地址: https://gitcode.com/gh_mirrors/wi/wifite2 Wifite2 是一款功能强大的无线网络安全审计工具&…...

Path of Building完全汉化版PoeCharm:流放之路角色构建终极指南
Path of Building完全汉化版PoeCharm:流放之路角色构建终极指南 【免费下载链接】PoeCharm Path of Building Chinese version 项目地址: https://gitcode.com/gh_mirrors/po/PoeCharm 如果你是一名《流放之路》的玩家,是否曾经因为Path of Build…...

精密峰值检测电路:双运放架构原理、设计与工程实践
1. 项目概述:从“是什么”到“为什么用它”在电子设计和信号处理领域,我们常常需要知道一个信号在特定时间段内的“最高点”或“最低点”。比如,你想知道麦克风采集到的声音信号最大有多响,或者一个振动传感器感受到的冲击力峰值是…...