机器学习基础(一)理解机器学习的本质
导读:在本文中,将深入探索机器学习的根本原理,包括基本概念、分类及如何通过构建预测模型来应用这些理论。
目录
机器学习
机器学习概念
相关概念
机器学习根本:模型
数据的语言:特征与标签
训练与测试:模型评估
机器学习的分类
监督学习:有指导的学习过程
非监督学习:自我探索的过程
强化学习:通过试错学习
构建与分析鸢尾花数据模型
鸢尾花数据集简介
加载数据集
创建和训练模型
进行预测与评估模型
机器学习
机器学习概念
机器学习是人工智能的一个分支,是一门开发算法和统计模型的科学,计算机系统使用这些算法和模型,在没有明确指令的情况下,依靠既有模式和推理来执行任务。在机器学习中,算法使用统计技术来使计算机能够“学习”数据,并基于这些数据做出预测或决策,而不是依靠严格的硬编码指令。机器学习这个领域的起源可以追溯到20世纪50年代,当时科学家们开始探索如何使计算机模拟人类学习过程。
在机器学习探索和尝试的历史中,有几个关键时刻值得一提。例如,20世纪80年代的神经网络的复兴,以及2006年深度学习概念的提出,这些都极大推动了机器学习的发展。如今,随着计算能力的飞速提升和大数据的普及,机器学习开始快速发展,成为现代技术不可或缺的一部分,从智能手机应用到复杂的股市分析系统,机器学习无处不在,它正在塑造我们的生活方式和工作方式。
机器学习之所以重要,是因为它为处理大量数据、发现模式、做出预测和决策提供了一种高效的方法。在医疗、金融、教育、零售等众多行业中,机器学习的应用都在带来革命性的变化,比如,医疗领域中的机器学习可以帮助诊断疾病、预测疾病进展,金融领域中则可以用于风险评估和欺诈检测。
随着我们深入本章的学习,读者不仅将在理论上理解探讨机器学习,也将通过实战案例和代码示例来加深理解,这些实战案例将覆盖从数据准备、模型构建到优化和模型评估的整个流程。我们会提供完整的程序代码,以及对这些代码的详细解释,确保即使是AI领域的新手也能跟上学习的步伐。
相关概念
要深入理解机器学习,首先需要掌握几个核心概念。这些概念是机器学习理论的基石,对于理解如何构建和应用机器学习模型至关重要。
机器学习根本:模型
在机器学习中,模型是指从数据中学习的算法。可以将其视为一种根据输入数据(特征)来做出预测或决策的系统。模型的训练过程涉及使用已知的数据集来调整其内部参数,使其能够准确地预测未见过的数据。

模型训练的基本步骤包括:
- 选择模型:根据问题的性质选择适当的机器学习算法。
- 训练数据:提供包含特征(解释变量)和标签(目标变量)的数据集。
- 学习过程:算法通过分析训练数据来学习模式和关系。
- 评估与调整:使用独立的测试集评估模型的性能,并根据需要进行调整。
数据的语言:特征与标签
在机器学习中,我们通常将数据分为两类:特征和标签。特征是输入数据,是模型用来进行预测的信息。例如,房价预测模型的数据集结构应该是:
| 特征 | 类型 | 描述 |
| id | 整数 | 房屋唯一标识符 |
| longitude | 浮点数 | 房屋地理位置的经度 |
| latitude | 浮点数 | 房屋地理位置的纬度 |
| housing_median_age | 整数 | 房屋的中位年龄 |
| total_rooms | 整数 | 房屋内的房间总数 |
| total_bedrooms | 整数 | 房屋内的卧室总数 |
| population | 整数 | 房屋所在区域的人口总数 |
| households | 整数 | 房屋所在区域的家庭总数 |
| median_income | 浮点数 | 区域内家庭的收入中位数 |
| ocean_proximity | 文本 | 房屋靠近海洋的位置 |
| median_house_value | 浮点数 | 房屋的中位价值(标签) |
特征可能包括房屋的面积、房间数量、地理位置等信息,标签则是开发者想要预测的结果,在此类中表示房屋的售价。
训练与测试:模型评估
为了验证模型的有效性,我们需要将数据分为训练集和测试集。训练集用于构建和优化模型,而测试集则用于评估模型的性能。这种划分帮助我们理解模型对新数据的泛化能力,即其在实际应用中的表现。
在这个过程中,需要特别关注两个常见问题:过拟合和欠拟合。过拟合发生在模型过于复杂,过度学习训练数据的细节和噪声,而不足以泛化到新数据的情况,它对训练数据中的特定特征过度敏感,包括一些不规则和随机的误差,过拟合的模型在训练数据上表现得非常好,但是在新的、未见过的数据上表现不佳。相反,欠拟合则是模型过于简单,不能充分学习数据中的模式,可能是由于模型过于简单(例如,参数太少或模型结构不够复杂)或者训练数据中的特征不足以捕捉到决定输出的关键因素,欠拟合的模型不但在训练数据上表现不佳,而且在新数据上同样表现有所欠缺。
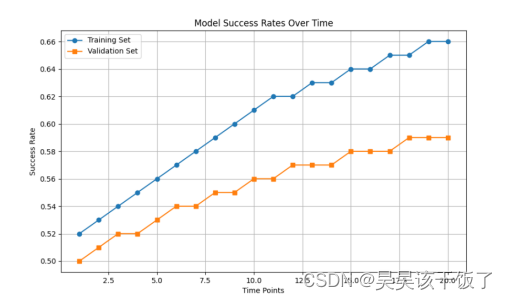
在欠拟合情况下,即使随着时间的增加训练次数增多,训练集和测试集的成功率提升都非常有限,说明模型未能充分学习数据中的模式。训练集和测试集的成功率曲线都比较平坦,且测试集的成功率通常低于训练集,尽管训练时间延长,训练集和验证集的成功率仍然只是缓慢提高,欠拟合成功率折线图如图:
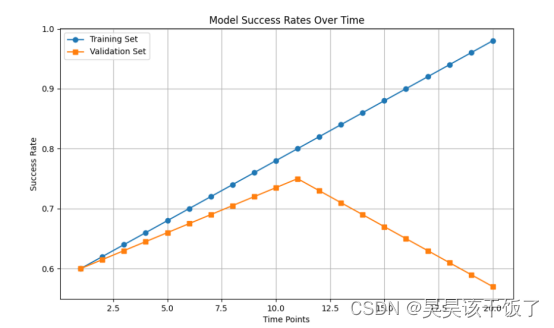
对于过拟合情况,通常为训练集成功率随时间显著提高而测试集成功率先提高后下降或停滞不前,反映出模型对训练数据过度拟合而泛化能力差。这种情况下,训练集和测试集之间的准确率会有明显差距,表明模型对未见数据的预测性能不佳,过拟合成功率折线图如图:
在一个正常拟合的情况下,训练集和验证集的准确率都会随着时间的推移而提高,并且两者之间的差距不会太大,这表明模型既学习了数据中的足够信息,又保持了良好的泛化能力。正常拟合成功率折线图如图:

机器学习的分类
机器学习的方法多种多样,不同的方法适用于不同类型的问题,主要的机器学习方法可以分为3类:监督学习、非监督学习和强化学习。理解这些分类方法的使用场景有助于读者选择正确的方法来解决特定的问题。
监督学习:有指导的学习过程
监督学习是最常见的机器学习类型之一。在监督学习方法下,我们提供给模型的训练数据既包括特征也包括相应的标签。模型的任务是学习如何将特征映射到标签,从而能够对新的、未标记的数据做出预测。常见的监督学习任务包括分类(预测离散标签)和回归(预测连续标签)。例如,根据患者的临床数据来预测是否患有特定疾病(分类),或者预测房屋的售价(回归)。
非监督学习:自我探索的过程
与监督学习不同,非监督学习的训练数据不包含任何标签。非监督学习的目标是让模型自己探索数据并找出其中的结构。常见的非监督学习任务包括聚类和降维。一个典型的例子是市场细分,其中模型会根据客户的购买行为将其分为不同的群体。
- 聚类:发现数据中的自然群体
- 降维:减少数据的复杂性,同时保留重要信息
强化学习:通过试错学习
强化学习与监督学习和非监督学习有所不同,在强化学习模式下,智能体通过与环境交互从而进行学习。也就是说强化学习不是从标记好的数据集中学习,而是根据事物行为的结果来学习。这个结果通常以奖励的形式给出。强化学习在游戏(如国际象棋和围棋)、机器人导航以及在线推荐系统中得到了广泛的应用。
构建与分析鸢尾花数据模型
首次使用scikit-learn库,需要先进行安装。scikit-learn,也称为sklearn,是Python中最流行的机器学习库之一,它提供了广泛的工具和算法来处理常见的机器学习任务。安装sklearn库时,可以在命令行或终端中,输入以下命令:pip install scikit-learn。
鸢尾花数据集简介
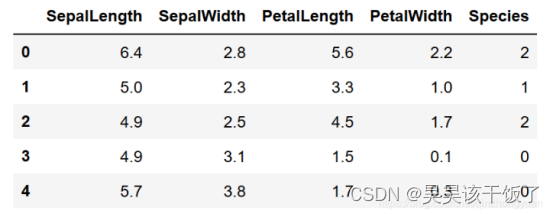
鸢尾花数据集是机器学习中最著名的数据集之一,包含150个样本,每个样本有4个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度),用于预测鸢尾花的种类(共有三种:Setosa、Versicolour、Virginica)。
加载数据集
from sklearn.datasets import load_irisiris = load_iris()x, y = iris.data, iris.target创建和训练模型
接下来,我们将使用一个简单的分类算法,即决策树来训练模型。决策树是直观运用概率分析的一种图解法,是一个基于分支的树模型,其中,每个内部结点表示在一个属性上的测试,每个分支代表一个属性输出,而每一个树叶结点代表类或类分布,树的最顶层是根结点。在这里,我们首先导入DecisionTreeClassifier,然后创建一个决策树分类器的实例,并使用鸢尾花数据对其进行训练:
from sklearn.tree import DecisionTreeClassifiermodel = DecisionTreeClassifier()model.fit(X, y)进行预测与评估模型
模型一旦训练完成,就可以用来进行数据预测,同时,也可以用来评估模型的性能。在实际应用中,一般会将数据分为独立的训练集和测试集,本例为了简化运算,是在同一数据集上进行的训练和测试,对数据集中的每个样本进行分类预测.
#进行预测predictions = model.predict(X)#评估模型from sklearn.metrics import accuracy_score#这会输出模型在整个数据集上的准确率print(accuracy_score(y, predictions))下一节我们将详细讲解监督学习和非监督学习,以及一个实战案例:预测房价
机器学习基础(二)监督与非监督学习-CSDN博客更深入地探讨监督学习和非监督学习的知识,重点关注它们的理论基础、常用算法及实际应用场景。https://blog.csdn.net/qq_52213943/article/details/136163917?spm=1001.2014.3001.5501
-----------------
以上,欢迎点赞收藏、评论区交流
相关文章:
机器学习基础(一)理解机器学习的本质
导读:在本文中,将深入探索机器学习的根本原理,包括基本概念、分类及如何通过构建预测模型来应用这些理论。 目录 机器学习 机器学习概念 相关概念 机器学习根本:模型 数据的语言:特征与标签 训练与测试…...

Eclipse - Makefile generation
Eclipse - Makefile generation References right mouse click on the project -> Properties -> C/C Build -> Generate Makefiles automatically 默认会在 Debug 目录下创建 Makefile 文件。 References [1] Yongqiang Cheng, https://yongqiang.blog.csdn.net/...

Sora:新一代实时音视频通信框架
一、Sora简介 Sora是一个开源的实时音视频通信框架,旨在提供高效、稳定、可扩展的音视频通信解决方案。它基于WebRTC技术,支持跨平台、跨浏览器的实时音视频通信,并且具备低延迟、高并发、易集成等特点。 --点击进入Sora(一定要科学哦&#x…...

龟兔赛跑算法
一、题目 给定一个长度为 n1 的数组nums,数组中所有的数均在 1∼n1 的范围内,其中 n≥1。 请找出数组中任意一个重复的数。 样例 给定 nums [2, 3, 5, 4, 3, 2, 6, 7]。返回 2 或 3。 二、解析 解决这个问题的一种有效方法是使用快慢指针…...
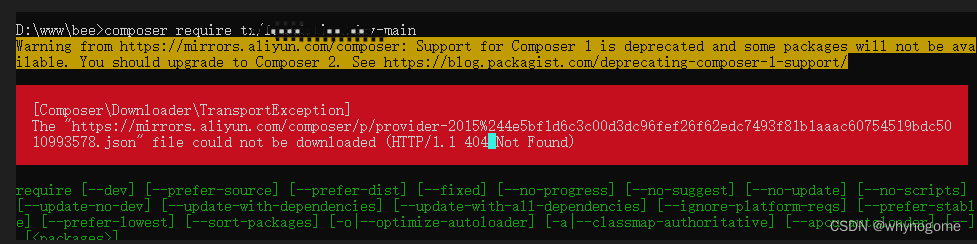
Yii2项目使用composer异常记录
问题描述 在yii2项目中,使用require命令安装依赖时,出现如下错误提示 该提示意思是:composer运行时,执行了yiisoft/yii2-composer目录下的插件,但是该插件使用的API版本是1.0,但是当前的cmposer版本提供的…...

【蓝桥杯 2021】图像模糊
图像模糊 题目描述 小蓝有一张黑白图像,由 nm 个像素组成,其中从上到下共 n 行,每行从左到右 m 列。每个像素由一个 0 到 255 之间的灰度值表示。 现在,小蓝准备对图像进行模糊操作,操作的方法为: 对于…...

【leetcode】贪心算法介绍
详细且全面地分析贪心算法常用的解题套路、数据结构和代码逻辑如下: 找最值型: 每一步选择都是局部最优解,最后得到的结果就是全局最优解。常用于找零钱问题、区间覆盖问题等。一般情况下,可以通过排序将数据进行处理,…...
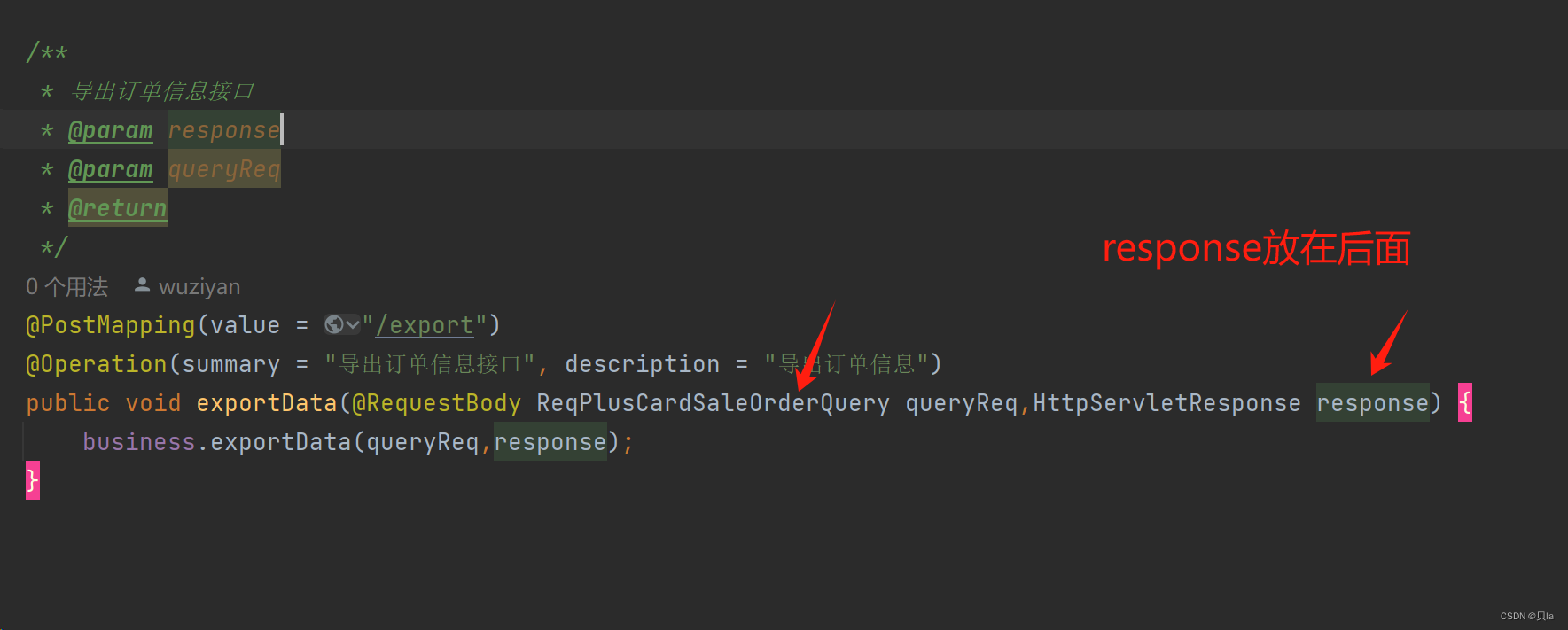
com.alibaba.fastjson.JSONException: toJSON error的原因
问题: 导出接口报错,显示json格式化异常 发现问题: 第一个参数为HttpResponse,转换成json的时候报错 修改方法: 1.调换两个参数的位置 2.在aop判断里边 把ServletAPI过滤掉 Before("excudeWebController()")pub…...
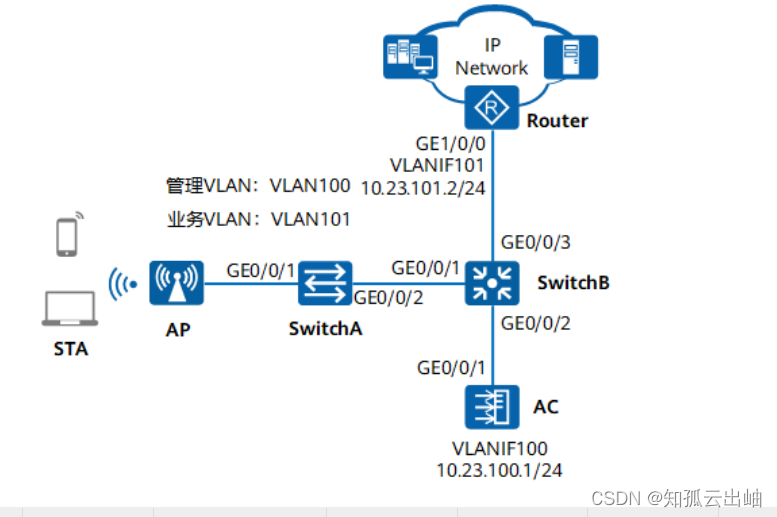
华为配置旁挂二层组网直接转发示例
配置旁挂二层组网直接转发示例 组网图形 图1 配置旁挂二层组网直接转发示例组网图 业务需求组网需求数据规划配置思路配置注意事项操作步骤配置文件扩展阅读 业务需求 企业用户通过WLAN接入网络,以满足移动办公的最基本需求。且在覆盖区域内移动发生漫游时ÿ…...

OLMo 以促进语言模型科学之名 —— OLMo Accelerating the Science of Language Models —— 全文翻译
OLMo: Accelerating the Science of Language Models OLMo 以促进语言模型科学之名 摘要 语言模型在自然语言处理的研究中和商业产品中已经变得无所不在。因为其商业上的重要性激增,所以,其中最强大的模型已经闭源,控制在专有接口之中&#…...

单例模式双端检测详解
正确写出doublecheck的单例模式_double check单例模式-CSDN博客...

秦PLUS荣耀版7.98万元起震撼上市,拉开“电比油低”大幕
2月19日,秦PLUS荣耀版正式上市,五大颠覆、三大焕新刷新A轿体验新高度。DM-i版本5款车型,官方指导价7.98万元——12.58万元;EV版本5款车型,官方指导价10.98万元——13.98万元。正式开启“电比油低”新时代。 电比油低&a…...

学习总结19
# 奶牛的耳语 ## 题目描述 在你的养牛场,所有的奶牛都养在一排呈直线的牛栏中。一共有 n 头奶牛,其中第 i 头牛在直线上所处的位置可以用一个整数坐标 pi(0< pi < 10^8) 来表示。在无聊的日子里,奶牛们常常在自己的牛栏里与其它奶牛交…...
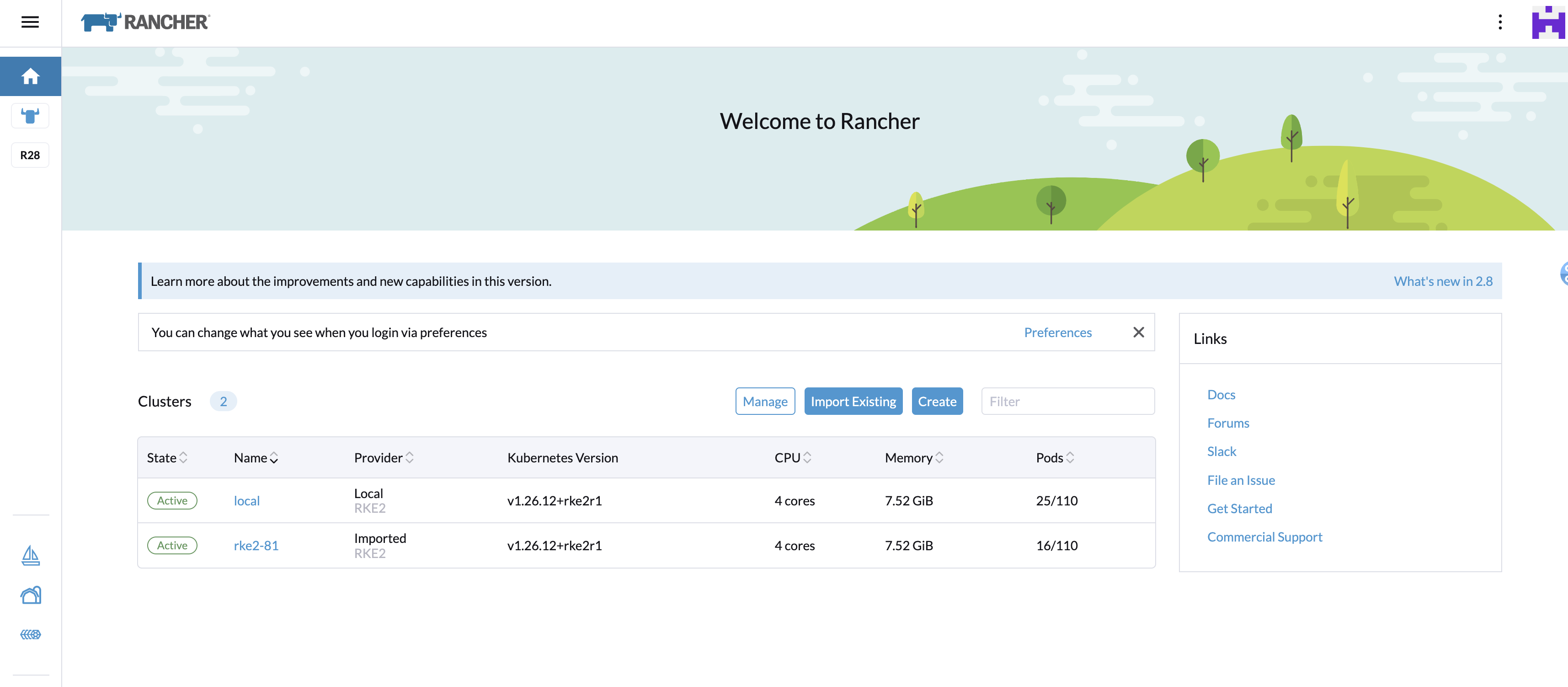
rancher v2.8.1 如何成功注册已有 k8s 集群
需要加入的集群为rke2部署的双节点集群 $ kubectl get node NAME STATUS ROLES AGE VERSION rke-master01 Ready control-plane,etcd,master,worker 94d v1.26.8rke2r1 rke-master02 Ready control-plane,etcd,mast…...

Vue中$root的使用方法
查看本专栏目录 关于作者 还是大剑师兰特:曾是美国某知名大学计算机专业研究生,现为航空航海领域高级前端工程师;CSDN知名博主,GIS领域优质创作者,深耕openlayers、leaflet、mapbox、cesium,canvas&#x…...

redis 异步队列
//produceMessage.ts 模拟生产者 import Redis from ioredis; const redis new Redis(); // 生产者:将消息推送到队列 async function produceMessage(queueName:string, message:string) {try {await redis.rpush(queueName, message);console.log(Produced messa…...

SpringBoot + Nacos 实现动态化线程池
1.背景 在后台开发中,会经常用到线程池技术,对于线程池核心参数的配置很大程度上依靠经验。然而,由于系统运行过程中存在的不确定性,我们很难一劳永逸地规划一个合理的线程池参数。 在对线程池配置参数进行调整时,一…...

《Docker极简教程》--Dockerfile--Dockerfile的基本语法
Dockerfile是一种文本文件,用于定义Docker镜像的内容和构建步骤。它包含一系列指令,每个指令代表一个构建步骤,从基础镜像开始,逐步构建出最终的镜像。通过Dockerfile,用户可以精确地描述应用程序运行环境的配置、依赖…...

css中, grid-auto-rows: 怎样简写在grid:中
grid-auto-rows:100px; grid-template-columns:1fr 1fr; 👆可以写成👇 grid:auto-flow 100px / 1fr 1fr;在CSS Grid布局中,grid-auto-rows 属性用于指定自动生成的网格容器的行的大小。如果你想要将 grid-auto-rows 的值简写在 grid 属性中&a…...
|Day53(动态规划))
@ 代码随想录算法训练营第8周(C语言)|Day53(动态规划)
代码随想录算法训练营第8周(C语言)|Day53(动态规划) Day50、动态规划(包含题目 ● 123.买卖股票的最佳时机III ● 188.买卖股票的最佳时机IV ) 123.买卖股票的最佳时机III 题目描述 给定一个数组 price…...

D2DX技术深度解析:如何为经典暗黑破坏神2注入现代图形渲染能力
D2DX技术深度解析:如何为经典暗黑破坏神2注入现代图形渲染能力 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx D…...

5分钟掌握跨平台资源下载:res-downloader视频号批量下载终极指南
5分钟掌握跨平台资源下载:res-downloader视频号批量下载终极指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader …...

Q-Learning原理与工程实践:从试错记账到智能决策
1. 这不是数学课,是教你怎么让机器“试错成长”——Q-Learning到底在干啥?你有没有带过小孩学骑自行车?一开始扶着后座,他歪歪扭扭往前冲,撞到草坪、蹭到墙边、甚至直接摔进灌木丛——但每次摔倒后,他都会下…...

Java读取Word图片坐标位置的方法
Word文档中图片坐标怎么获取于实际开发期间,我们时常得去处理Word文档里的图片,像是把图片提取出来,对排版予以调整,亦或是进行自动化校验。然而,好多人在获取图片的坐标位置之际卡住了,这事是由于Word的图…...

量子Krylov子空间算法与经典阴影技术解析
1. 量子Krylov子空间算法原理与实现量子Krylov子空间算法是当前NISQ(含噪声中等规模量子)时代最具前景的量子-经典混合算法之一。其核心思想是通过构造一组Krylov基矢{|ψₖ⟩} {|ψ₀⟩, H|ψ₀⟩, H|ψ₀⟩,..., H^(d-1)|ψ₀⟩},将高维希…...
)
DeepSeek微服务拆分实战:从单体到弹性集群的7步标准化迁移手册(含流量染色+灰度发布Checklist)
更多请点击: https://codechina.net 第一章:DeepSeek微服务架构演进的底层逻辑与决策框架 微服务架构并非技术堆砌的结果,而是业务复杂度、组织演进节奏与工程效能诉求三者动态博弈下的系统性解法。DeepSeek 在模型训练平台、推理网关、数据…...

2026年哪个开源商城,更适合长期维护?——真正决定商城系统寿命的,从来不是“功能多少”,而是“复杂业务长期是否还能稳定演进”
很多企业第一次选开源商城系统时。 通常都会特别关注: 功能全不全插件多不多页面好不好看上线速度快不快 因为在很多人认知里: 功能越多 → 系统越成熟 于是很多企业前期选型时。 都会优先选择: 功能最多的插件最全的营销玩法最丰富的…...

Windows 11终极优化指南:Win11Debloat一键提升51%系统性能
Windows 11终极优化指南:Win11Debloat一键提升51%系统性能 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter an…...

Cortex-M0+与M3/M4的SWD调试接口整合方案
1. Cortex-M0与Cortex-M3/M4的SWD调试接口整合挑战在嵌入式系统设计中,经常需要将不同性能等级的ARM Cortex-M系列处理器组合使用。比如将低功耗的Cortex-M0与高性能的Cortex-M3/M4搭配,形成主从处理器架构。这种组合在物联网终端、工业控制器等场景非常…...

【设计模式 13】命令:覆水能收
这一课讲命令模式。什么在变:决策需要记录、排队、撤销。怎么挡:把决策封装成命令对象,可执行可回滚。林衍那次决策失误,后来集团内部管它叫"黑色十月"。 起因是赵闯带回来一条消息:一家新晋竞争对手拿到了十…...