第五篇【传奇开心果系列】Python文本和语音相互转换库技术点案例示例:详细解读pyttsx3的`preprocess_text`函数文本预处理。
传奇开心果短博文系列
- 系列短博文目录
- Python文本和语音相互转换库技术点案例示例系列
- 短博文目录
- 前言
- 一、pyttsx3的`preprocess_text`函数文本预处理基本用法示例代码
- 二、实现更复杂的文本预处理逻辑示例代码
- 三、去除停用词、词干提取示例代码
- 四、词形还原、拼写纠正示例代码
- 五、实体识别、去除HTML标签示例代码
- 六、去除URL链接、处理缩写词示例代码
- 七、处理特定的符号、处理特定的文本模式示例代码
- 八、归纳总结
系列短博文目录
Python文本和语音相互转换库技术点案例示例系列
短博文目录
前言

 pyttsx3在文本转换语音之前,首先要开展系列步骤的文本预处理工作。
pyttsx3在文本转换语音之前,首先要开展系列步骤的文本预处理工作。
这些预处理步骤可以在使用pyttsx3之前应用于文本,以提高转换结果的质量和可读性。预处理后的文本更干净、准确,可以更好地用于语音转换。pyttsx3主要使用preprocess_text函数开展文本预处理。
一、pyttsx3的preprocess_text函数文本预处理基本用法示例代码
 下面是一个使用
下面是一个使用pyttsx3库进行文本预处理基本用法的示例代码:
import pyttsx3def preprocess_text(text):# 移除文本中的特殊字符processed_text = ''.join(e for e in text if e.isalnum() or e.isspace())# 将文本转换为小写processed_text = processed_text.lower()return processed_text# 创建一个TTS引擎
engine = pyttsx3.init()# 设置预处理文本
text = "Hello, World! This is a text-to-speech example."# 预处理文本
processed_text = preprocess_text(text)# 使用TTS引擎朗读预处理后的文本
engine.say(processed_text)
engine.runAndWait()
在上面的示例代码中,preprocess_text函数用于对文本进行预处理。它首先移除文本中的特殊字符,然后将文本转换为小写。这样可以确保文本在朗读之前被正确处理。
然后,我们使用pyttsx3.init()方法初始化一个TTS引擎。接下来,我们设置要朗读的文本,并将其传递给preprocess_text函数进行预处理。最后,使用engine.say()方法将预处理后的文本传递给TTS引擎进行朗读,然后使用engine.runAndWait()方法等待朗读完成。
你可以根据自己的需求修改preprocess_text函数,以实现更复杂的文本预处理逻辑。
二、实现更复杂的文本预处理逻辑示例代码


下面是一个修改后的preprocess_text函数,实现了更复杂的文本预处理逻辑:
import redef preprocess_text(text):# 移除文本中的特殊字符和标点符号processed_text = re.sub(r'[^\w\s]', '', text)# 将文本转换为小写processed_text = processed_text.lower()# 移除多余的空格processed_text = re.sub(r'\s+', ' ', processed_text)return processed_text
在这个修改后的函数中,我们使用了re模块的正则表达式功能。首先,我们使用re.sub()函数和正则表达式[^\w\s]来移除文本中的特殊字符和标点符号。这个正则表达式表示匹配除了字母、数字、下划线和空格之外的任何字符。然后,我们将文本转换为小写,并使用re.sub()函数和正则表达式\s+来移除多余的空格,将连续的多个空格替换为一个空格。
这样,预处理后的文本将只包含小写字母、数字、下划线和单个空格,没有特殊字符和多余的空格。你可以根据自己的需求进一步修改这个函数,添加其他的预处理步骤,例如去除停用词、词干提取等。
三、去除停用词、词干提取示例代码

 当涉及到去除停用词和词干提取时,可以使用一些自然语言处理库,如
当涉及到去除停用词和词干提取时,可以使用一些自然语言处理库,如nltk(Natural Language Toolkit)来实现。下面是一个修改后的preprocess_text函数,包括去除停用词和词干提取的示例代码:
import re
import nltk
from nltk.corpus import stopwords
from nltk.stem import PorterStemmerdef preprocess_text(text):# 移除文本中的特殊字符和标点符号processed_text = re.sub(r'[^\w\s]', '', text)# 将文本转换为小写processed_text = processed_text.lower()# 移除多余的空格processed_text = re.sub(r'\s+', ' ', processed_text)# 去除停用词stop_words = set(stopwords.words('english'))processed_text = ' '.join(word for word in processed_text.split() if word not in stop_words)# 词干提取stemmer = PorterStemmer()processed_text = ' '.join(stemmer.stem(word) for word in processed_text.split())return processed_text
在这个修改后的函数中,我们首先导入了nltk库,并从nltk.corpus模块导入了停用词和从nltk.stem模块导入了词干提取器PorterStemmer。
然后,在preprocess_text函数中,我们创建了一个停用词集合stop_words,使用set(stopwords.words('english'))加载英文停用词。接下来,我们使用列表推导式和条件判断语句,将不在停用词集合中的单词保留下来,形成一个经过去除停用词的文本。
最后,我们创建了一个词干提取器stemmer,使用PorterStemmer()初始化。然后,使用列表推导式和词干提取器将文本中的每个单词提取出词干,并重新组合成一个经过词干提取的文本。
这样,预处理后的文本将不包含停用词,并且每个单词都被提取为其词干形式。你可以根据自己的需求进一步修改这个函数,添加其他的预处理步骤,如词形还原、拼写纠正等。
四、词形还原、拼写纠正示例代码

 要进行词形还原和拼写纠正,我们可以使用
要进行词形还原和拼写纠正,我们可以使用nltk库中的WordNetLemmatizer和spell模块。下面是一个修改后的preprocess_text函数,包括词形还原和拼写纠正的示例代码:
import re
import nltk
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import word_tokenize
from nltk import pos_tag
from nltk import download
from spellchecker import SpellCheckerdef preprocess_text(text):# 移除文本中的特殊字符和标点符号processed_text = re.sub(r'[^\w\s]', '', text)# 将文本转换为小写processed_text = processed_text.lower()# 移除多余的空格processed_text = re.sub(r'\s+', ' ', processed_text)# 去除停用词stop_words = set(stopwords.words('english'))processed_text = ' '.join(word for word in processed_text.split() if word not in stop_words)# 词形还原download('averaged_perceptron_tagger')download('wordnet')lemmatizer = WordNetLemmatizer()tokens = word_tokenize(processed_text)tagged_tokens = pos_tag(tokens)processed_text = ' '.join(lemmatizer.lemmatize(word, tag) for word, tag in tagged_tokens)# 拼写纠正spell = SpellChecker()processed_text = ' '.join(spell.correction(word) for word in processed_text.split())return processed_text
在这个修改后的函数中,我们首先导入了nltk库的WordNetLemmatizer、word_tokenize、pos_tag模块,以及spellchecker库的SpellChecker模块。
然后,在preprocess_text函数中,我们下载了nltk库的averaged_perceptron_tagger和wordnet资源,用于词形还原。
接下来,我们创建了一个词形还原器lemmatizer,使用WordNetLemmatizer()初始化。然后,我们使用word_tokenize函数将文本分词为单词列表,使用pos_tag函数为每个单词标记词性,然后使用列表推导式和词形还原器将每个单词还原为其原始形式,最后重新组合成一个经过词形还原的文本。
最后,我们创建了一个拼写纠正器spell,使用SpellChecker()初始化。然后,使用列表推导式和拼写纠正器对文本中的每个单词进行拼写纠正,并重新组合成一个经过拼写纠正的文本。
这样,预处理后的文本将进行词形还原和拼写纠正,以提高文本的质量和准确性。你可以根据自己的需求进一步修改这个函数,添加其他的预处理步骤,如实体识别、去除HTML标签等。
五、实体识别、去除HTML标签示例代码
 要进行实体识别和去除HTML标签,我们可以使用
要进行实体识别和去除HTML标签,我们可以使用nltk库中的ne_chunk和BeautifulSoup模块。下面是一个修改后的preprocess_text函数,包括实体识别和去除HTML标签的示例代码:
import re
import nltk
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import word_tokenize
from nltk import pos_tag
from nltk import ne_chunk
from nltk import download
from spellchecker import SpellChecker
from bs4 import BeautifulSoupdef preprocess_text(text):# 去除HTML标签processed_text = BeautifulSoup(text, "html.parser").get_text()# 移除文本中的特殊字符和标点符号processed_text = re.sub(r'[^\w\s]', '', processed_text)# 将文本转换为小写processed_text = processed_text.lower()# 移除多余的空格processed_text = re.sub(r'\s+', ' ', processed_text)# 去除停用词stop_words = set(stopwords.words('english'))processed_text = ' '.join(word for word in processed_text.split() if word not in stop_words)# 词形还原download('averaged_perceptron_tagger')download('wordnet')lemmatizer = WordNetLemmatizer()tokens = word_tokenize(processed_text)tagged_tokens = pos_tag(tokens)processed_text = ' '.join(lemmatizer.lemmatize(word, tag) for word, tag in tagged_tokens)# 拼写纠正spell = SpellChecker()processed_text = ' '.join(spell.correction(word) for word in processed_text.split())# 实体识别tagged_tokens = pos_tag(word_tokenize(processed_text))processed_text = ' '.join(chunk.label() if hasattr(chunk, 'label') else chunk[0] for chunk in ne_chunk(tagged_tokens))return processed_text
在这个修改后的函数中,我们首先导入了nltk库的ne_chunk模块,以及BeautifulSoup模块来处理HTML标签。
然后,在preprocess_text函数中,我们使用BeautifulSoup模块的BeautifulSoup(text, "html.parser").get_text()方法去除文本中的HTML标签。
接下来,我们继续之前的步骤,包括移除特殊字符和标点符号、转换为小写、移除多余的空格、去除停用词、词形还原和拼写纠正。
最后,我们使用pos_tag函数将文本中的单词标记词性,然后使用ne_chunk函数进行实体识别。我们使用列表推导式和条件判断语句,将识别出的实体标签保留下来,形成一个经过实体识别的文本。
这样,预处理后的文本将进行实体识别和去除HTML标签,以进一步提高文本的质量和准确性。你可以根据自己的需求进一步修改这个函数,添加其他的预处理步骤,如去除URL链接、处理缩写词等。
六、去除URL链接、处理缩写词示例代码
 要去除URL链接和处理缩写词,我们可以使用正则表达式来匹配和替换文本中的URL链接,以及使用一个缩写词词典来进行缩写词的替换。下面是一个修改后的
要去除URL链接和处理缩写词,我们可以使用正则表达式来匹配和替换文本中的URL链接,以及使用一个缩写词词典来进行缩写词的替换。下面是一个修改后的preprocess_text函数,包括去除URL链接和处理缩写词的示例代码:
import re
import nltk
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import word_tokenize
from nltk import pos_tag
from nltk import ne_chunk
from nltk import download
from spellchecker import SpellChecker
from bs4 import BeautifulSoupdef preprocess_text(text):# 去除HTML标签processed_text = BeautifulSoup(text, "html.parser").get_text()# 去除URL链接processed_text = re.sub(r'http\S+|www.\S+', '', processed_text)# 移除文本中的特殊字符和标点符号processed_text = re.sub(r'[^\w\s]', '', processed_text)# 将文本转换为小写processed_text = processed_text.lower()# 移除多余的空格processed_text = re.sub(r'\s+', ' ', processed_text)# 去除停用词stop_words = set(stopwords.words('english'))processed_text = ' '.join(word for word in processed_text.split() if word not in stop_words)# 处理缩写词abbreviations = {"can't": "cannot","won't": "will not","it's": "it is",# 添加其他缩写词和对应的替换}processed_text = ' '.join(abbreviations.get(word, word) for word in processed_text.split())# 词形还原download('averaged_perceptron_tagger')download('wordnet')lemmatizer = WordNetLemmatizer()tokens = word_tokenize(processed_text)tagged_tokens = pos_tag(tokens)processed_text = ' '.join(lemmatizer.lemmatize(word, tag) for word, tag in tagged_tokens)# 拼写纠正spell = SpellChecker()processed_text = ' '.join(spell.correction(word) for word in processed_text.split())# 实体识别tagged_tokens = pos_tag(word_tokenize(processed_text))processed_text = ' '.join(chunk.label() if hasattr(chunk, 'label') else chunk[0] for chunk in ne_chunk(tagged_tokens))return processed_text
在这个修改后的函数中,我们首先导入了re模块,用于处理正则表达式匹配和替换。
然后,在preprocess_text函数中,我们使用re.sub函数和正则表达式r'http\S+|www.\S+'来匹配和替换文本中的URL链接。这样,我们可以将URL链接从文本中去除。
接下来,我们继续之前的步骤,包括去除HTML标签、移除特殊字符和标点符号、转换为小写、移除多余的空格、去除停用词、处理缩写词、词形还原和拼写纠正。
在处理缩写词时,我们创建了一个缩写词词典abbreviations,其中包含了一些常见的缩写词和对应的替换。你可以根据需要添加其他的缩写词和替换到这个词典中。
最后,我们使用pos_tag函数将文本中的单词标记词性,然后使用ne_chunk函数进行实体识别。我们使用列表推导式和条件判断语句,将识别出的实体标签保留下来,形成一个经过实体识别的文本。
这样,预处理后的文本将去除URL链接、处理缩写词,并进行其他的预处理步骤,以进一步提高文本的质量和准确性。你可以根据自己的需求进一步修改这个函数,添加其他的预处理步骤,如处理特定的符号、处理特定的文本模式等。
七、处理特定的符号、处理特定的文本模式示例代码
 根据你的需求,你可以进一步修改
根据你的需求,你可以进一步修改preprocess_text函数,添加其他的预处理步骤,如处理特定的符号、处理特定的文本模式等。下面是一个示例代码,包括处理特定符号和处理特定文本模式的预处理步骤:
import re
import nltk
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import word_tokenize
from nltk import pos_tag
from nltk import ne_chunk
from nltk import download
from spellchecker import SpellChecker
from bs4 import BeautifulSoupdef preprocess_text(text):# 去除HTML标签processed_text = BeautifulSoup(text, "html.parser").get_text()# 去除URL链接processed_text = re.sub(r'http\S+|www.\S+', '', processed_text)# 移除文本中的特殊字符和标点符号processed_text = re.sub(r'[^\w\s]', '', processed_text)# 处理特定符号processed_text = re.sub(r'\$', ' dollar ', processed_text)processed_text = re.sub(r'%', ' percent ', processed_text)# 将文本转换为小写processed_text = processed_text.lower()# 移除多余的空格processed_text = re.sub(r'\s+', ' ', processed_text)# 去除停用词stop_words = set(stopwords.words('english'))processed_text = ' '.join(word for word in processed_text.split() if word not in stop_words)# 处理缩写词abbreviations = {"can't": "cannot","won't": "will not","it's": "it is",# 添加其他缩写词和对应的替换}processed_text = ' '.join(abbreviations.get(word, word) for word in processed_text.split())# 词形还原download('averaged_perceptron_tagger')download('wordnet')lemmatizer = WordNetLemmatizer()tokens = word_tokenize(processed_text)tagged_tokens = pos_tag(tokens)processed_text = ' '.join(lemmatizer.lemmatize(word, tag) for word, tag in tagged_tokens)# 拼写纠正spell = SpellChecker()processed_text = ' '.join(spell.correction(word) for word in processed_text.split())# 实体识别tagged_tokens = pos_tag(word_tokenize(processed_text))
processed_text = ' '.join(chunk.label() if hasattr(chunk, 'label') else chunk[0] for chunk in ne_chunk(tagged_tokens))# 处理特定文本模式# 示例:将日期格式统一为YYYY-MM-DDprocessed_text = re.sub(r'\b(\d{1,2})[/-](\d{1,2})[/-](\d{2,4})\b', r'\3-\1-\2', processed_text)# 示例:将电话号码格式统一为xxx-xxx-xxxxprocessed_text = re.sub(r'\b(\d{3})[ -]?(\d{3})[ -]?(\d{4})\b', r'\1-\2-\3', processed_text)return processed_text
在这个示例代码中,我们添加了两个处理特定文本模式的预处理步骤:
-
将日期格式统一为YYYY-MM-DD:使用正则表达式
\b(\d{1,2})[/-](\d{1,2})[/-](\d{2,4})\b匹配日期格式,并使用替换模式\3-\1-\2将日期格式统一为YYYY-MM-DD。 -
将电话号码格式统一为xxx-xxx-xxxx:使用正则表达式
\b(\d{3})[ -]?(\d{3})[ -]?(\d{4})\b匹配电话号码格式,并使用替换模式\1-\2-\3将电话号码格式统一为xxx-xxx-xxxx。
八、归纳总结
 下面是对
下面是对pyttsx3中的preprocess_text函数进行归纳总结的知识点:
-
HTML标签去除:使用
BeautifulSoup库去除文本中的HTML标签,以确保纯文本的输入。 -
URL链接去除:使用正则表达式
re.sub函数去除文本中的URL链接。 -
特殊字符和标点符号去除:使用正则表达式
re.sub函数去除文本中的特殊字符和标点符号。 -
特定符号处理:使用正则表达式
re.sub函数或字符串替换操作,处理特定的符号,如将$符号替换为单词dollar,将%符号替换为单词percent,将@符号替换为单词at等。 -
文本转换为小写:使用
str.lower方法将文本转换为小写,以统一大小写格式。 -
多余空格移除:使用正则表达式
re.sub函数去除文本中的多余空格。 -
停用词去除:使用NLTK库的
stopwords模块获取停用词列表,将文本中的停用词去除。 -
缩写词处理:定义一个包含缩写词和对应替换的字典,将文本中的缩写词替换为对应的全写形式。
-
词形还原:使用NLTK库的
WordNetLemmatizer词形还原器,对文本中的单词进行词形还原处理。 -
拼写纠正:使用
spellchecker库的SpellChecker类,对文本中的拼写错误进行纠正。 -
实体识别:使用NLTK库的
ne_chunk函数对文本中的实体进行识别,例如人名、地名等。 -
特定文本模式处理:使用正则表达式
re.sub函数,处理特定的文本模式,例如统一日期格式、电话号码格式等。
 这些预处理步骤可以根据需要进行选择和修改,以适应特定的应用场景和文本数据。预处理后的文本更干净、准确,可以更好地用于后续的语音转换。
这些预处理步骤可以根据需要进行选择和修改,以适应特定的应用场景和文本数据。预处理后的文本更干净、准确,可以更好地用于后续的语音转换。
相关文章:
第五篇【传奇开心果系列】Python文本和语音相互转换库技术点案例示例:详细解读pyttsx3的`preprocess_text`函数文本预处理。
传奇开心果短博文系列 系列短博文目录Python文本和语音相互转换库技术点案例示例系列 短博文目录前言一、pyttsx3的preprocess_text函数文本预处理基本用法示例代码二、实现更复杂的文本预处理逻辑示例代码三、去除停用词、词干提取示例代码四、词形还原、拼写纠正示例代码五、…...

logback实践
1:日志区分环境 2:debug info warn error日志文件不一样 3: 文件滚动日志 4:启动可带参数 --spring.profiles.activedev --log.levelinfo 5:可从配置文件中获取上下文参数 logback-spring.xml 放在 classpath 下面 <configuration scan"false" scanPer…...

深入理解java虚拟机---自动内存管理
2.2 运行时数据区域 Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域。这些区域有各自的用途,以及创建和销毁的时间,有的区域随着虚拟机进程的启动而一直存在,有些区域则是依赖用户线程的启动和结束而建立和销…...
)
粉笔规范词积累(文化发展)
活态保护/活态传承 基本释义 是在文化遗产生成发展的环境当中进行保护和传承,在人民群众生产生活过程中进行传承与发展。 应用场景 当资料中出现“让文化遗产不仅‘活’在历史中,更‘活’在人们的生产生活中”等类似表述,可概括为“活态保…...
如何在Ubuntu部署Emlog,并将本地博客发布至公网可远程访问
文章目录 前言1. 网站搭建1.1 Emolog网页下载和安装1.2 网页测试1.3 cpolar的安装和注册 2. 本地网页发布2.1 Cpolar临时数据隧道2.2.Cpolar稳定隧道(云端设置)2.3.Cpolar稳定隧道(本地设置) 3. 公网访问测试总结 前言 博客作为使…...

Axios
Axios简介 axios框架全称(ajax – I/O – system): 基于promise用于浏览器和node.js的http客户端,因此可以使用Promise API 一、axios是干啥的 说到axios我们就不得不说下Ajax。在旧浏览器页面在向服务器请求数据时࿰…...

数据仓库选型建议
1 数仓分层 1.1 数仓分层的意义 **数据复用,减少重复开发:**规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。数据的逐层加工原则,下层包含了上层数据加工所需要的全量数据,这样的加工方…...

每日一题——LeetCode1470.重新排列数组
方法一 把数组的前n项看做一个数组,后n项看做一个数组,两个数组循环先后往res里push元素 var shuffle function(nums, n) {let res[]for(let i0;i<n;i){res.push(nums[i])res.push(nums[in])}return res }; 消耗时间和内存情况: 方法二…...
网络安全--网鼎杯2018漏洞复现(二次注入)
一、环境:在线测试平台 BUUCTF在线评测 (buuoj.cn) 二、进入界面先尝试万能账号 1or11# 换格式 hais1bux1 11or11# 三、万能的不行那我们就得想注册了,去register.php去看看 注册个账号 发现用户名回显,猜测考点为用户名处二次注入&…...
CSS篇--transform
CSS篇–transform 使用transform属性实现元素的位移、旋转、缩放等效果 位移 // 语法 transform:translate(水平移动距离,垂直移动距离) translate() 如果只给一个值,表示x轴方法移动距离 单独设置某个方向的移动距离:translateX() transla…...
阿里云国际-在阿里云服务器上快速搭建幻兽帕鲁多人服务器
幻兽帕鲁是最近流行的新型生存游戏。该游戏一夜之间变得极为流行,同时在线玩家数量达到了200万。然而,幻兽帕鲁的服务器难以应对大量玩家的压力。为解决这一问题,幻兽帕鲁允许玩家建立专用服务器,其提供以下优势: &am…...

vite 快速搭建 Vue3.0项目
一、初始化项目 npm create vite-app <project name>二、进入项目目录 cd ……三、安装依赖 npm install四、启动项目 npm run dev五、配置项目 安装 typescript npm add typescript -D初始化 tsconfig.json //执行命令 初始化 tsconfig.json npx tsc --init …...

深入理解Python爬虫的Response对象
源码分享 https://docs.qq.com/sheet/DUHNQdlRUVUp5Vll2?tabBB08J2 在构建Python爬虫时,理解HTTP响应(Response)是至关重要的。本篇博客将详细介绍如何使用Python的Requests库来处理HTTP响应,并通过详细的代码案例指导你如何提取…...

centos7下docker的安装
背景 总结下docker的一些知识 docker安装(有网络版) 参考文章我以前试过这个帖子,建议安装高版本的docker,(20以上的,不然可能会有一些问题) ## 1、安装依赖 [rootiZo7e61fz42ik0Z ~]#yum i…...

Excel SUMPRODUCT函数用法(乘积求和,分组排序)
SUMPRODUCT函数是Excel中功能比较强大的一个函数,可以实现sum,count等函数的功能,也可以实现一些基础函数无法直接实现的功能,常用来进行分类汇总,分组排序等 SUMPRODUCT 函数基础 SUMPRODUCT函数先计算多个数组的元素之间的乘积…...

C#上位机与三菱PLC的通信08---开发自己的通讯库(A-1E版)
1、A-1E报文回顾 具体细节请看: C#上位机与三菱PLC的通信03--MC协议之A-1E报文解析 C#上位机与三菱PLC的通信04--MC协议之A-1E报文测试 2、为何要开发自己的通讯库 前面使用了第3方的通讯库实现了与三菱PLC的通讯,实现了数据的读写,对于通…...

ABAQUS应用04——集中质量的添加方法
文章目录 0. 背景1. 集中质量的编辑2. 约束的设置3. 总结 0. 背景 混塔ABAQUS模型中,机头、法兰等集中质量的设置是模型建立过程中的一部分,需要研究集中质量的添加。 1. 集中质量的编辑 集中质量本身的编辑没什么难度,我已经用Python代码…...
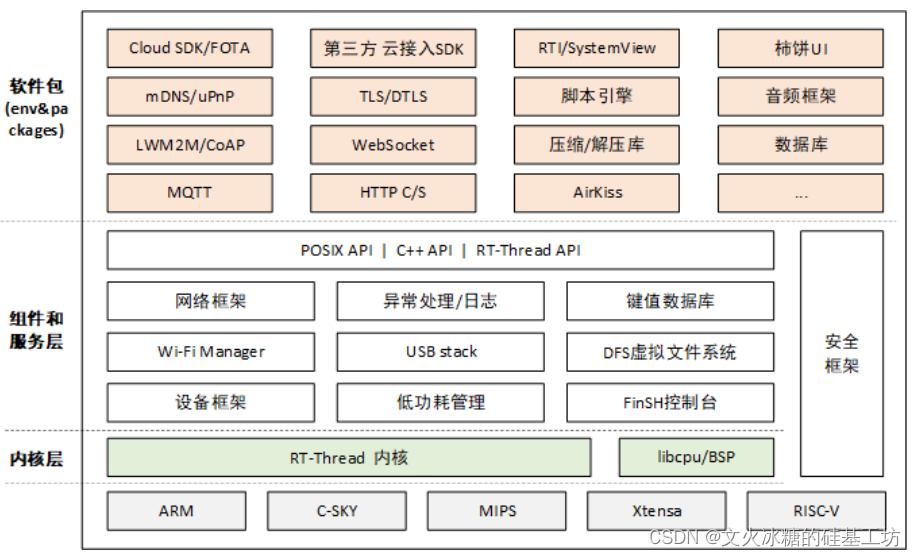
[嵌入式系统-24]:RT-Thread -11- 内核组件编程接口 - 网络组件 - TCP/UDP Socket编程
目录 一、RT-Thread网络组件 1.1 概述 1.2 RT-Thread支持的网络协议栈 1.3 RT-Thread如何选择不同的网络协议栈 二、Socket编程 2.1 概述 2.2 UDP socket编程 2.3 TCP socket编程 2.4 TCP socket收发数据 一、RT-Thread网络组件 1.1 概述 RT-Thread 是一个开源的嵌入…...
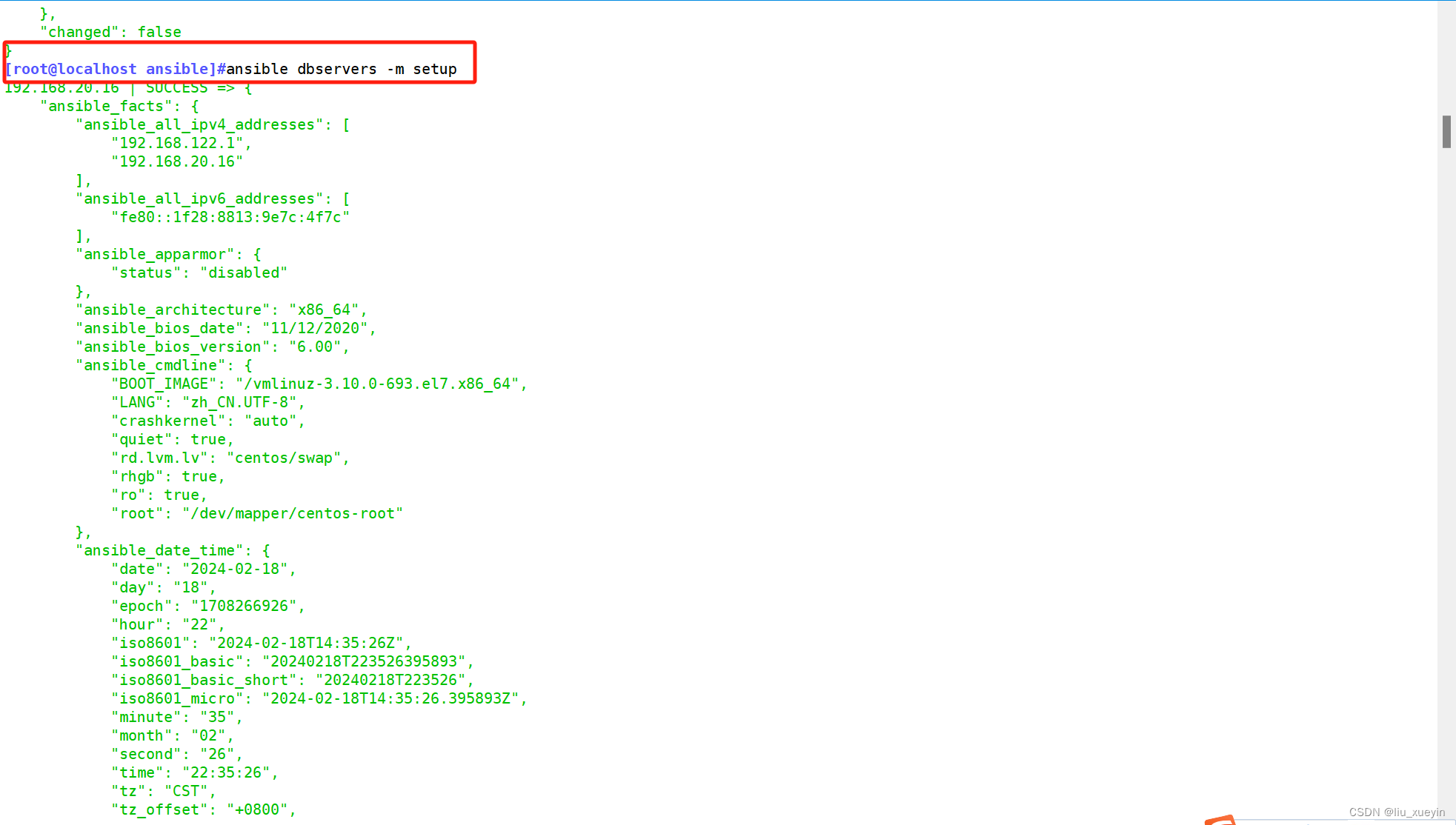
【ansible】认识ansible,了解常用的模块
目录 一、ansible是什么? 二、ansible的特点? 三、ansible与其他运维工具的对比 四、ansible的环境部署 第一步:配置主机清单 第二步:完成密钥对免密登录 五、ansible基于命令行完成常用的模块学习 模块1:comma…...
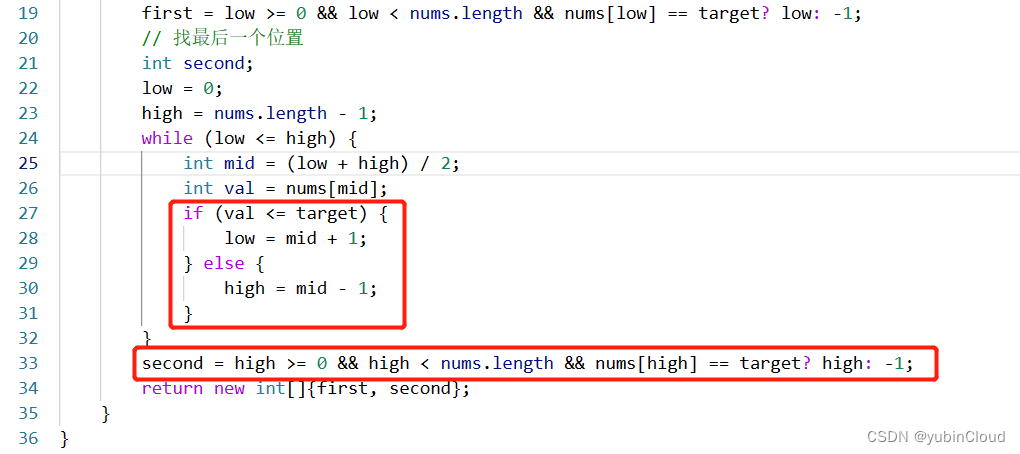
【LeetCode】升级打怪之路 Day 01:二分法
今日题目: 704. 二分查找35. 搜索插入位置34. 在排序数组中查找元素的第一个和最后一个位置 目录 今日总结Problem 1: 二分法LeetCode 704. 二分查找 【easy】LeetCode 35. 搜索插入位置 ⭐⭐⭐⭐⭐LeetCode 34. 在排序数组中查找元素的第一个和最后一个位置 【medi…...
终极Emu模型架构解析:深入理解370亿参数的多模态Transformer
终极Emu模型架构解析:深入理解370亿参数的多模态Transformer 【免费下载链接】Emu Emu Series: Generative Multimodal Models from BAAI 项目地址: https://gitcode.com/gh_mirrors/emu/Emu Emu是由BAAI开发的革命性多模态生成模型系列,通过融合…...

YOLOv11公共场所人群年龄目标检测数据集-280张-pedestrian-1_5
YOLOv11公共场所人群年龄目标检测数据集 📊 数据集基本信息 目标类别: [‘adult’, ‘child’, ‘elder’]中文类别:[‘成人’, ‘儿童’, ‘老人’]训练集:196 张验证集:56 张测试集:28 张总计:…...

RT-Trace升级:集成GDB Server与一键烧录,打造嵌入式开发调试平台
1. 项目概述:嵌入式开发的“瑞士军刀”再进化如果你是一名嵌入式开发者,最近可能被一个词刷屏了——RT-Trace。这已经不是它第一次带来惊喜了。最初,它以非侵入式的实时追踪和性能分析能力,在RT-Thread社区里掀起了一阵热潮&#…...

EASY-HWID-SPOOFER:Windows硬件指纹保护终极方案
EASY-HWID-SPOOFER:Windows硬件指纹保护终极方案 【免费下载链接】EASY-HWID-SPOOFER 基于内核模式的硬件信息欺骗工具 项目地址: https://gitcode.com/gh_mirrors/ea/EASY-HWID-SPOOFER 在数字时代,您的电脑硬件信息正在被悄无声息地追踪。无论是…...
】)
【项目实训(个人8)】
继续进行法律文书智能摘要系统的开发,新增了几个功能,并优化了用户体验概述本次开发为法律文书智能摘要系统新增了两项核心功能。其一是摘要版本管理,支持同一文档的多版本摘要生成、存储、对比和回滚。用户在生成摘要时,系统自动…...
)
别再只会画矩形了!用Leaflet+L.geoJSON搞定复杂行政区遮罩(含飞地处理)
突破Leaflet遮罩技术瓶颈:复杂行政区与飞地处理的终极方案 当我们面对真实世界中的行政区划数据时,理想化的矩形遮罩显得力不从心。中国行政区划的复杂性——飞地、嵌套洞、不规则边界——要求开发者掌握更高级的地图遮罩技术。本文将带您深入Leaflet的L…...

在Node.js项目中集成Taotoken实现稳定的大模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js项目中集成Taotoken实现稳定的大模型调用 对于需要在产品中集成AI能力的中小型团队而言,开发过程常常伴随着一…...
)
毕业设计 深度学习的人体跌倒检测与识别(源码+论文)
文章目录 0 前言1 项目运行效果2 相关技术原理2.1卷积神经网络2.2 YOLO简介2.3 YOLOv5s 模型算法流程和原理2.4 数据集处理数据标注简介数据保存 2.5 模型训练 4 最后 0 前言 🔥这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创…...

初创团队如何利用Taotoken的Token Plan实现AI成本精细化管理
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何利用Taotoken的Token Plan实现AI成本精细化管理 对于初创团队和独立开发者而言,在拥抱大模型能力的同时&a…...

以灵活测试方案打造共享实验室,强化槟城IC设计生态系统
益莱储(Electro Rent) InvestPenang|IC 设计验证与特性表征共享实验室马来西亚槟城正积极推进其成为亚洲领先的半导体枢纽。在 InvestPenang 主导的「Penang Silicon Design 5KM(PSD5KM)」计划下,全新的 I…...