ElasticSearch聚合操作
目录
ElasticSearch聚合操作
基本语法
聚合的分类
后续示例数据
Metric Aggregation
Bucket Aggregation
ES聚合分析不精准原因分析
提高聚合精确度
ElasticSearch聚合操作
Elasticsearch除搜索以外,提供了针对ES 数据进行统计分析的功能。聚合(aggregations)可以让我们极其方便的实现对数据的统计、分析、运算。例如:
什么品牌的手机最受欢迎?
这些手机的平均价格、最高价格、最低价格?
这些手机每月的销售情况如何?
基本语法
聚合查询的语法结构与其他查询相似,通常包含以下部分:
查询条件:指定需要聚合的文档,可以使用标准的 Elasticsearch 查询语法,如 term、match、range 等等。
聚合函数:指定要执行的聚合操作,如 sum、avg、min、max、terms、date_histogram 等等。每个聚合命令都会生成一个聚合结果。
聚合嵌套:聚合命令可以嵌套,以便更细粒度地分析数据。
GET <index_name>/_search
{"aggs": {"<aggs_name>": { // 聚合名称需要自己定义"<agg_type>": {"field": "<field_name>"}}}
}aggs_name:聚合函数的名称
agg_type:聚合种类,比如是桶聚合(terms)或者是指标聚合(avg、sum、min、max等)
field_name:字段名称或者叫域名。
聚合的分类
Metric Aggregation:—些数学运算,可以对文档字段进行统计分析,类比Mysql中的 min(), max(), sum() 操作。
SELECT MIN(price), MAX(price) FROM products
#Metric聚合的DSL类比实现:
{"aggs":{"avg_price":{"avg":{"field":"price"}}}
}Bucket Aggregation: 一些满足特定条件的文档的集合放置到一个桶里,每一个桶关联一个key,类比Mysql中的group by操作。
SELECT size COUNT(*) FROM products GROUP BY size
#bucket聚合的DSL类比实现:
{"aggs": {"by_size": {"terms": {"field": "size"}}
}后续示例数据
DELETE /employees
#创建索引库
PUT /employees
{"mappings": {"properties": {"age":{"type": "integer"},"gender":{"type": "keyword"},"job":{"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 50}}},"name":{"type": "keyword"},"salary":{"type": "integer"}}}
}PUT /employees/_bulk
{ "index" : { "_id" : "1" } }
{ "name" : "Emma","age":32,"job":"Product Manager","gender":"female","salary":35000 }
{ "index" : { "_id" : "2" } }
{ "name" : "Underwood","age":41,"job":"Dev Manager","gender":"male","salary": 50000}
{ "index" : { "_id" : "3" } }
{ "name" : "Tran","age":25,"job":"Web Designer","gender":"male","salary":18000 }
{ "index" : { "_id" : "4" } }
{ "name" : "Rivera","age":26,"job":"Web Designer","gender":"female","salary": 22000}
{ "index" : { "_id" : "5" } }
{ "name" : "Rose","age":25,"job":"QA","gender":"female","salary":18000 }
{ "index" : { "_id" : "6" } }
{ "name" : "Lucy","age":31,"job":"QA","gender":"female","salary": 25000}
{ "index" : { "_id" : "7" } }
{ "name" : "Byrd","age":27,"job":"QA","gender":"male","salary":20000 }
{ "index" : { "_id" : "8" } }
{ "name" : "Foster","age":27,"job":"Java Programmer","gender":"male","salary": 20000}
{ "index" : { "_id" : "9" } }
{ "name" : "Gregory","age":32,"job":"Java Programmer","gender":"male","salary":22000 }
{ "index" : { "_id" : "10" } }
{ "name" : "Bryant","age":20,"job":"Java Programmer","gender":"male","salary": 9000}
{ "index" : { "_id" : "11" } }
{ "name" : "Jenny","age":36,"job":"Java Programmer","gender":"female","salary":38000 }
{ "index" : { "_id" : "12" } }
{ "name" : "Mcdonald","age":31,"job":"Java Programmer","gender":"male","salary": 32000}
{ "index" : { "_id" : "13" } }
{ "name" : "Jonthna","age":30,"job":"Java Programmer","gender":"female","salary":30000 }
{ "index" : { "_id" : "14" } }
{ "name" : "Marshall","age":32,"job":"Javascript Programmer","gender":"male","salary": 25000}
{ "index" : { "_id" : "15" } }
{ "name" : "King","age":33,"job":"Java Programmer","gender":"male","salary":28000 }
{ "index" : { "_id" : "16" } }
{ "name" : "Mccarthy","age":21,"job":"Javascript Programmer","gender":"male","salary": 16000}
{ "index" : { "_id" : "17" } }
{ "name" : "Goodwin","age":25,"job":"Javascript Programmer","gender":"male","salary": 16000}
{ "index" : { "_id" : "18" } }
{ "name" : "Catherine","age":29,"job":"Javascript Programmer","gender":"female","salary": 20000}
{ "index" : { "_id" : "19" } }
{ "name" : "Boone","age":30,"job":"DBA","gender":"male","salary": 30000}
{ "index" : { "_id" : "20" } }
{ "name" : "Kathy","age":29,"job":"DBA","gender":"female","salary": 20000}Metric Aggregation
单值分析︰只输出一个分析结果(min, max, avg, sum等)
多值分析:输出多个分析结果(stats(统计), extended stats等)
查询员工的最低最高和平均工资
#多个 Metric 聚合,找到最低最高和平均工资
POST /employees/_search
{"size": 0, "aggs": {"max_salary": {"max": {"field": "salary"}},"min_salary": {"min": {"field": "salary"}},"avg_salary": {"avg": {"field": "salary"}}}
}对salary进行统计
# 一个聚合,输出多值
POST /employees/_search
{"size": 0,"aggs": {"stats_salary": {"stats": {"field":"salary"}}}
}cardinate对搜索结果去重
POST /employees/_search
{"size": 0,"aggs": {"cardinate": {"cardinality": {"field": "job.keyword"}}}
}Bucket Aggregation
按照一定的规则,将文档分配到不同的桶中,从而达到分类的目的。ES提供的一些常见的 Bucket Aggregation。
Terms,需要字段支持filedata,如果是keyword 默认支持fielddata,如果是text需要在Mapping 中开启fielddata,会按照分词后的结果进行分桶。
数字类型支持Range / Data Range、Histogram(直方图) / Date Histogram。
支持嵌套: 也就在桶里再做分桶。
获取job的分类信息
# 对keword 进行聚合
GET /employees/_search
{"size": 0,"aggs": {"jobs": {"terms": {"field":"job.keyword"}}}
}聚合可配置属性有:
field:指定聚合字段。
size:指定聚合结果数量。
order:指定聚合结果排序方式。
默认情况下,Bucket聚合会统计Bucket内的文档数量,记为_count,并且按照_count降序排序。我们可以指定order属性,自定义聚合的排序方式:
GET /employees/_search
{"size": 0,"aggs": {"jobs": {"terms": {"field":"job.keyword","size": 10,"order": {"_count": "desc" }}}}
}限定聚合范围
#只对salary在10000元以上的文档聚合
GET /employees/_search
{"query": {"range": {"salary": {"gte": 10000 }}}, "size": 0,"aggs": {"jobs": {"terms": {"field":"job.keyword","size": 10,"order": {"_count": "desc" }}}}
}ES聚合分析不精准原因分析
ElasticSearch在对海量数据进行聚合分析的时候会损失搜索的精准度来满足实时性的需求。
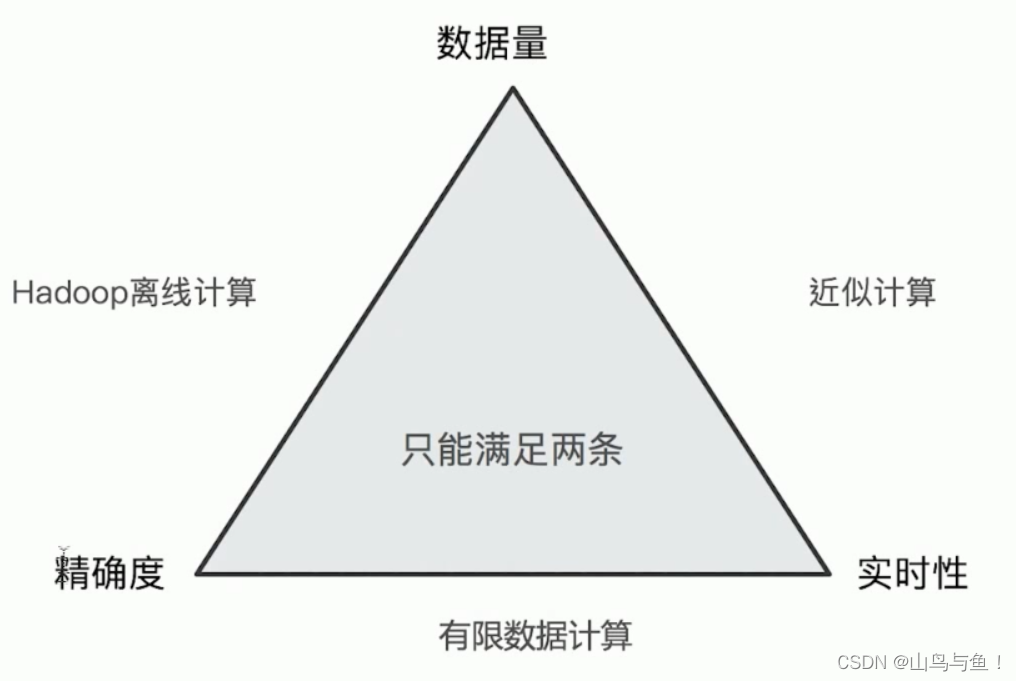
Terms聚合分析的执行流程:
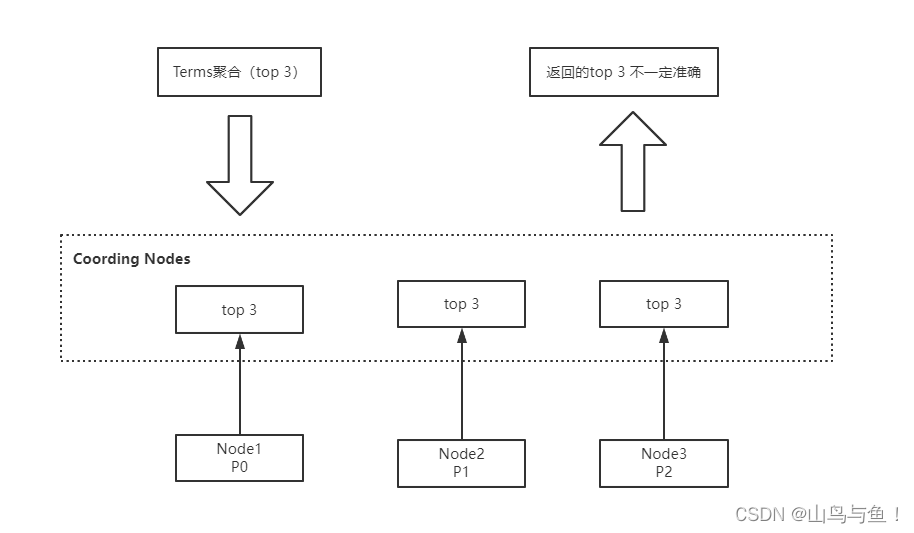
不精准的原因: 数据分散到多个分片,聚合是每个分片的取 Top X,导致结果不精准。ES 可以不每个分片Top X,而是全量聚合,但这会有很大的性能问题。
提高聚合精确度
方案1:设置主分片为1
注意7.x版本已经默认为1。
适用场景:数据量小的小集群规模业务场景。
方案2:调大 shard_size 值
设置 shard_size 为比较大的值,官方推荐:size*1.5+10。shard_size 值越大,结果越趋近于精准聚合结果值。此外,还可以通过show_term_doc_count_error参数显示最差情况下的错误值,用于辅助确定 shard_size 大小。
- size:是聚合结果的返回值,客户期望返回聚合排名前三,size值就是 3。
- shard_size: 每个分片上聚合的数据条数。shard_size 原则上要大于等于 size
适用场景:数据量大、分片数多的集群业务场景。
方案3:使用Clickhouse/ Spark 进行精准聚合
适用场景:数据量非常大、聚合精度要求高、响应速度快的业务场景。
相关文章:
ElasticSearch聚合操作
目录 ElasticSearch聚合操作 基本语法 聚合的分类 后续示例数据 Metric Aggregation Bucket Aggregation ES聚合分析不精准原因分析 提高聚合精确度 ElasticSearch聚合操作 Elasticsearch除搜索以外,提供了针对ES 数据进行统计分析的功能。聚合(aggregation…...

普中51单片机学习(定时器和计数器)
定时器和计数器 51单片机有两组定时器/计数器,因为既可以定时,又可以计数,故称之为定时器/计数器。定时器/计数器和单片机的CPU是相互独立的。定时器/计数器工作的过程是自动完成的,不需要CPU的参与。51单片机中的定时器/计数器是…...

having子句
目录 having子句 having和where的区别 Oracle从入门到总裁:https://blog.csdn.net/weixin_67859959/article/details/135209645 现在要求查询出每个职位的名称,职位的平均工资,但是要求显示平均工资高于 200 的职位 按照职位先进行分组,同…...

STM32H7 系列 MCU 内部 SRAM
通过参看《STM32H7 参考手册》“2.4 Embedded SRAM”章节知道 The STM32H743/53xx and STM32H750xB 内存特性: Up to 864 Kbytes of System SRAM 128 Kbytes of data TCM RAM 64 Kbytes of instruction TCM RAM 4 Kbytes of backup SRAM 1.1 TCM SRAM TCM : Tightly-Coupled …...

备战蓝桥杯---动态规划(应用2(一些十分巧妙的优化dp的手段))
好久不见,甚是想念,最近一直在看过河这道题(感觉最近脑子有点宕机QAQ),现在算是有点懂了,打算记录下这道又爱又恨的题。(如有错误欢迎大佬帮忙指出) 话不多说,直接看题&…...

从 git 分支中合并特定文件,而不是整个分支的内容
问题 在git 中,我们可以使用 git merge 命令,合并整个分支,覆盖当前分支的内容,但是有时候我们并不想这么做,而是想 merge 某个文件。那么下面提供两种办法。 方法一 使用 git checkout,从别的分支&#x…...
pycharm 远程运行报错 Failed to prepare environment
什么也没动的情况下,远程连接后运行是没问题的,突然在运行时就运行不了了,解决方案 清理缓存: 有时候 PyCharm 的内部缓存可能出现问题,可以尝试清除缓存(File > Invalidate Caches / Restart࿰…...

(十二)【Jmeter】线程(Threads(Users))之setUp 线程组
简述 操作路径如下: 作用:在正式测试开始前执行预加载或预热操作,为测试做准备。配置:设置预加载或预热操作的采样器、循环次数等参数。使用场景:确保在正式测试开始前应用程序已经达到稳定状态,减少测试结果的偏差。优点:提供预加载或预热操作,确保测试的准确性。缺…...

代码随想录算法训练营第二十五天|216.组合总和III,17.电话号码的字母组合
目录 216.组合总和II 17.电话号码的字母组合 216.组合总和II 如果把 组合问题理解了,本题就容易一些了。 题目链接/文章讲解:代码随想录 视频讲解:和组合问题有啥区别?回溯算法如何剪枝?| LeetCode:216.…...
c#创建安装windows服务
背景:最近在做设备数据对接采集时,遇到一些设备不是标准的Service-Client接口,导致采集的数据不够准确;比如设备如果中途开关机后,加工的数量就会从0开始重新计数,因此需要实时监控设备的数据,进行叠加处理;考略到工厂设备比较多,实时监听接口的数据为每秒3次,因此将…...

【JVM】打破双亲委派机制
📝个人主页:五敷有你 🔥系列专栏:JVM ⛺️稳中求进,晒太阳 打破双亲委派机制 打破双亲委派机制三种方法 自定义类加载器 ClassLoader包含了四个核心方法 //由类加载器子类实现,获取二进制数据调用…...

程序员要了解的AI基本知识
一.AI从业人员的三个层次 AI从业人员的层次是不同的,所以需要的知识面也是不同的。下面大致给出了3个层面。 1.学术研究者 他们的工作是从理论上诠释机器学习的各个方面,试图找出“这样设计模型/参数为什么效果更好”,并且为其他从业者提供…...
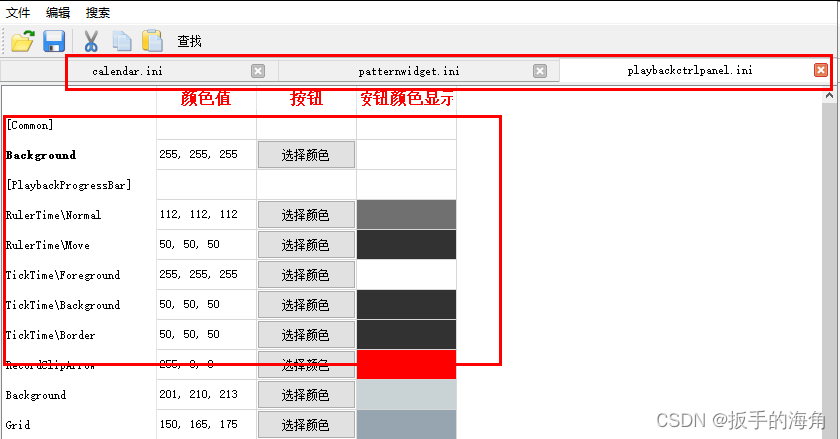
306_C++_QT_创建多个tag页面,使用QMdiArea容器控件,每个页面都是一个新的表格[或者其他]页面
程序目的是可以打开多个styles文件(int后缀文件),且是tag样式的(就是可以切多个页面出来,并且能够单独关闭);其中读取ini文件,将其插入到表格中的操作,也是比较复杂的,因为需要保持RGB字符串和前面的说明字符串对齐 ini文件举例: [MainMenu] Foreground\Selected=&…...

OpenCV笔记3:级联分类器实现人脸检测+绘制logo
OpenCV 人脸检测绘制logo 检测人脸绘制人脸区域绘制logo 寻找轮廓 二值图阈值 绘制轮廓 """ 绘制logo 1. 检测人脸区域如何检测到人脸眼睛、鼻子、嘴巴、眉毛、下巴等级联的过程OpenCV、Mediapipe、YOLOFace、DBFace等 2. 把logo粘贴在人脸上方 ""…...
)
python---Pixiv排行榜图片获取(2024.2.16)
1.提示: 使用需要安装各种import的包,都是很基础的包,直接安装即可。 自备梯子 。 切记把userid和cookie改为自己账号的参数! userid就是点击pixiv头像,网址后面一串数, cookie是打开排行榜后,…...
QT3作业
1 2. 使用手动连接,将登录框中的取消按钮使用qt4版本的连接到自定义的槽函数中,在自定义的槽函数中调用关闭函数,将登录按钮使用t5版本的连接到自定义的槽函数中,在槽函数中判断ui界面上输入的账号是否为"admin"&#…...

零基础,两个月,如何蓝桥杯备战?
本文约4000字,阅读时长8~12分钟。 首先说明,目前0算法基础,想在两个月后的蓝桥杯拿奖,有一定难度,但也不是完全没可能。在这么短的时间内选择正确的方法,做高性价比的事就尤为重要。 我是蓝桥云课省赛无忧…...
基于Java+小程序点餐系统设计与实现(源码+部署文档)
博主介绍: ✌至今服务客户已经1000、专注于Java技术领域、项目定制、技术答疑、开发工具、毕业项目实战 ✌ 🍅 文末获取源码联系 🍅 👇🏻 精彩专栏 推荐订阅 👇🏻 不然下次找不到 Java项目精品实…...

炫酷3D按钮
一.预览 该样式有一种3D变换的高级感,大家可以合理利用这些样式到自己的按钮上 二.代码 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice…...

世界顶级名校计算机专业学习使用教材汇总
🌈个人主页: Aileen_0v0 🔥热门专栏: 华为鸿蒙系统学习|计算机网络|数据结构与算法 💫个人格言:“没有罗马,那就自己创造罗马~” #mermaid-svg-IauYk2cGjEyljid0 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-siz…...

RV1126B嵌入式音频开发实战:从ALSA驱动到应用播放全解析
1. 项目概述:从一块核心板到声音的诞生 最近在折腾一块基于瑞芯微RV1126B芯片的EASY EAI Nano开发板,目标是让它“开口说话”——实现稳定的音频输出。这听起来像是一个基础功能,但对于嵌入式开发,尤其是涉及多媒体处理的边缘AI设…...

告别键盘鼠标切换烦恼:开源KVM软件Input Leap让你一套键鼠控制多台电脑
告别键盘鼠标切换烦恼:开源KVM软件Input Leap让你一套键鼠控制多台电脑 【免费下载链接】input-leap Open-source KVM software 项目地址: https://gitcode.com/gh_mirrors/in/input-leap 你是否经常在Windows、macOS和Linux多台电脑之间来回切换,…...

基于STM32MP25x构建工业级嵌入式Linux平台:Debian、XFCE、VNC与TSN集成实践
1. 项目概述:一个面向工业边缘的“全能”嵌入式Linux平台最近,我们团队基于STM32MP25x系列核心板,成功构建并发布了一套完整的Debian系统镜像。这个项目的目标非常明确:打造一个开箱即用、功能全面且高度适配工业边缘计算场景的嵌…...

自动化 Vue 3 转 React 编译工具 VuReact 连续迭代,全量编译速度提升 30%-40%
近期,自动化 Vue 3 转 React 编译工具 VuReact 完成 v1.8.0、v1.8.1、v1.8.3 连续迭代,围绕性能、稳定性、开发体验深度优化,降低 Vue 项目向 React 迁移门槛。更新聚焦三大方向本轮更新围绕性能、稳定性、开发体验三大方向进行深度优化。尤其…...

如何快速提高能力
人机协作,AI模型:Deepseek仅供参考如何快速提高能力在快节奏的现代社会中,每个人都渴望快速提升自己的能力,无论是职场竞争力、专业技能,还是通用素养。能力的提升并非一蹴而就,但遵循科学有效的方法&#…...

终极Visual C++运行库修复指南:如何一次性解决所有DLL缺失问题
终极Visual C运行库修复指南:如何一次性解决所有DLL缺失问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾因"找不到MSVCP140.dll&qu…...

Android Studio中文界面完整汉化指南:三步打造母语开发环境
Android Studio中文界面完整汉化指南:三步打造母语开发环境 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还在为And…...
ESP32 阿里云身份认证 超简版教程)
硬件入门 + 单片机基础(第16天)ESP32 阿里云身份认证 超简版教程
一、准备工作阿里云物联网平台创建产品 设备,拿到三元组ProductKeyDeviceNameDeviceSecretArduino 安装库:AliyunIoTSDK(阿里云官方 MQTT)WiFiPubSubClient二、直接可用代码(只需要改 4 处信息)#include &…...

电源BOM砍掉30%!这颗SiC PSR芯片让12W-200W设计更简单
摘要:传统反激电源设计中,光耦反馈网络、TL431基准源、补偿电路占据了大量BOM成本与PCB面积。芯茂微LP3798系列采用原边PSR架构内置/外推SiC功率管方案,无需光耦即可实现恒压恒流控制,全系满足7级能效,待机功耗<75m…...

K210+STM32F103C8T6低成本送药小车全流程:从硬件选型到代码调试避坑
K210STM32F103C8T6低成本送药小车全流程:从硬件选型到代码调试避坑 当电子竞赛遇上嵌入式开发,一个融合视觉识别与运动控制的送药小车项目,往往成为检验技术实力的试金石。本文将带你从零开始,用K210视觉模块与STM32F103C8T6主控芯…...