大数据构建知识图谱:从技术到实战的完整指南
文章目录
- 大数据构建知识图谱:从技术到实战的完整指南
- 一、概述
- 二、知识图谱的基础理论
- 定义与分类
- 核心组成
- 历史与发展
- 三、知识获取与预处理
- 数据源选择
- 数据清洗
- 实体识别
- 四、知识表示方法
- 知识表示模型
- RDF
- OWL
- 属性图模型
- 本体构建
- 关系提取与表示
- 五、知识图谱构建技术
- 图数据库选择
- Neo4j
- ArangoDB
- 构建流程
- 数据预处理
- 实体关系识别
- 图数据库存储
- 优化和索引
- 深度学习在构建中的应用
大数据构建知识图谱:从技术到实战的完整指南
本文深入探讨了知识图谱的构建全流程,涵盖了基础理论、数据获取与预处理、知识表示方法、知识图谱构建技术等关键环节。
一、概述
知识图谱,作为人工智能和语义网技术的重要组成部分,其核心在于将现实世界的对象和概念以及它们之间的多种关系以图形的方式组织起来。它不仅仅是一种数据结构,更是一种知识的表达和存储方式,能够为机器学习提供丰富、结构化的背景知识,从而提升算法的理解和推理能力。
在人工智能领域,知识图谱的重要性不言而喻。它提供了一种机器可读的知识表达方式,使计算机能够更好地理解和处理复杂的人类语言和现实世界的关系。通过构建知识图谱,人工智能系统可以更有效地进行知识的整合、推理和查询,从而在众多应用领域发挥重要作用。
具体到应用场景,知识图谱被广泛应用于搜索引擎优化、智能问答系统、推荐系统、自然语言处理等领域。例如,在搜索引擎中,通过知识图谱可以更精确地理解用户的查询意图和上下文,提供更相关和丰富的搜索结果。在智能问答系统中,知识图谱使得机器能够理解和回答更复杂的问题,实现更准确的信息检索和知识发现。
此外,知识图谱还在医疗健康、金融分析、风险管理等领域展现出巨大潜力。在医疗领域,利用知识图谱可以整合和分析大量的医疗数据,为疾病诊断和药物研发提供支持。在金融领域,则可以通过知识图谱对市场趋势、风险因素进行更深入的分析和预测。
总的来说,知识图谱作为连接数据、知识和智能的桥梁,其在人工智能的各个领域都扮演着至关重要的角色。随着技术的不断进步和应用领域的拓展,知识图谱将在智能化社会中发挥越来越重要的作用。
二、知识图谱的基础理论
定义与分类
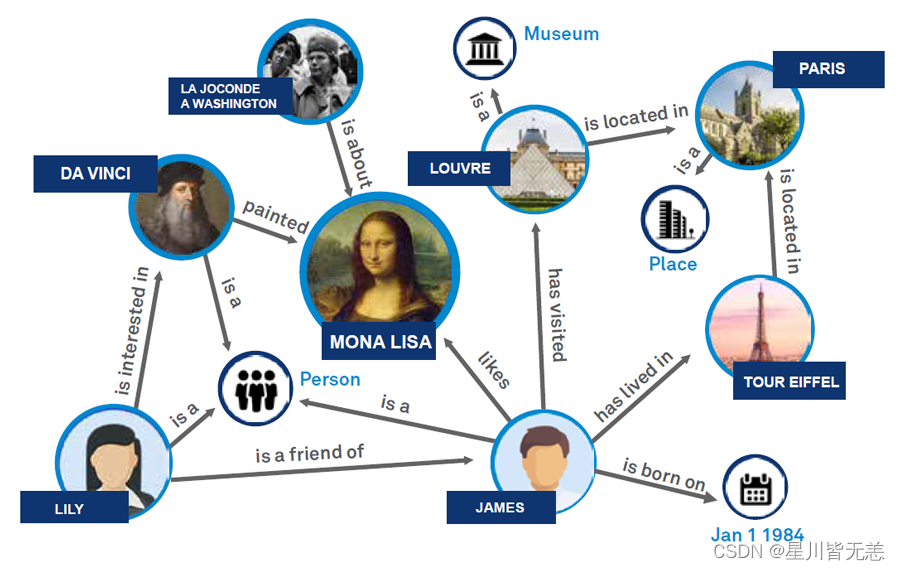
知识图谱是一种通过图形结构表达知识的方法,它通过节点(实体)和边(关系)来表示和存储现实世界中的各种对象及其相互联系。这些实体和关系构成了一个复杂的网络,使得知识的存储不再是孤立的,而是相互关联和支持的。
知识图谱根据其内容和应用领域可以分为多种类型。例如,通用知识图谱旨在覆盖广泛的领域知识,如Google的Knowledge Graph;而领域知识图谱则专注于特定领域,如医疗、金融等。此外,根据构建方法的不同,知识图谱还可以分为基于规则的、基于统计的和混合型知识图谱。
核心组成
知识图谱的核心组成元素包括实体、关系和属性。实体是知识图谱中的基本单位,代表现实世界中的对象,如人、地点、组织等。关系则描述了实体之间的各种联系,例如“属于”、“位于”等。属性是对实体的具体描述,如年龄、位置等。这些元素共同构成了知识图谱的骨架,使得知识的组织和检索变得更加高效和精确。
历史与发展
知识图谱的概念最早可以追溯到语义网和链接数据的概念。早期的语义网关注于如何使网络上的数据更加机器可读,而链接数据则强调了数据之间的关联。知识图谱的出现是对这些理念的进一步发展和实践应用,它通过更加高效的数据结构和技术,使得知识的表示、存储和检索更加高效和智能。
随着人工智能和大数据技术的发展,知识图谱在自然语言处理、机器学习等领域得到了广泛应用。例如,知识图谱在提升搜索引擎的智能化、优化推荐系统的准确性等方面发挥了重要作用。此外,随着技术的不断进步,知识图谱的构建和应用也在不断地演变和优化,包括利用深度学习技术进行知识提取和图谱构建,以及在更多领域的应用拓展。
三、知识获取与预处理

数据源选择
知识图谱构建的首要步骤是确定和获取数据源。数据源的选择直接影响知识图谱的质量和应用范围。通常,数据源可以分为两大类:公开数据集和私有数据。公开数据集,如Wikipedia、Freebase、DBpedia等,提供了丰富的通用知识,适用于构建通用知识图谱。而私有数据,如企业内部数据库、专业期刊等,则更适用于构建特定领域的知识图谱。
选择数据源时,应考虑数据的可靠性、相关性、完整性和更新频率。可靠性保证了数据的准确性,相关性和完整性直接影响知识图谱的应用价值,而更新频率则关系到知识图谱的时效性。在实践中,通常需要结合多个数据源,以获取更全面和深入的知识覆盖。
数据清洗
获取数据后,下一步是数据清洗。这一过程涉及从原始数据中移除错误、重复或不完整的信息。数据清洗的方法包括去噪声、数据规范化、缺失值处理等。去噪声是移除数据集中的错误和无关数据,例如,去除格式错误的记录或非相关领域的信息。数据规范化涉及将数据转换为一致的格式,如统一日期格式、货币单位等。对于缺失值,可以采用插值、预测或删除不完整记录的方法处理。
数据清洗不仅提高了数据的质量,还能增强后续处理的效率和准确性。因此,这一步骤在知识图谱构建中至关重要。
实体识别
实体识别是指从文本中识别出知识图谱中的实体,这是构建知识图谱的核心步骤之一。实体识别通常依赖于自然语言处理(NLP)技术,特别是命名实体识别(NER)。NER技术能够从非结构化的文本中识别出具有特定意义的片段,如人名、地名、机构名等。
实体识别的方法多种多样,包括基于规则的方法、统计模型以及近年来兴起的基于深度学习的方法。基于规则的方法依赖于预定义的规则来识别实体,适用于结构化程度较高的领域。统计模型,如隐马尔可夫模型(HMM)、条件随机场(CRF)等,通过学习样本数据中的统计特征来识别实体。而基于深度学习的方法,如使用长短时记忆网络(LSTM)或BERT等预训练模型,能够更有效地处理语言的复杂性和多样性,提高识别的准确率和鲁棒性。
实体识别不仅需要高准确性,还要考虑到速度和可扩展性,特别是在处理大规模数据集时。因此,选择合适的实体识别技术和优化算法是至关重要的。
四、知识表示方法
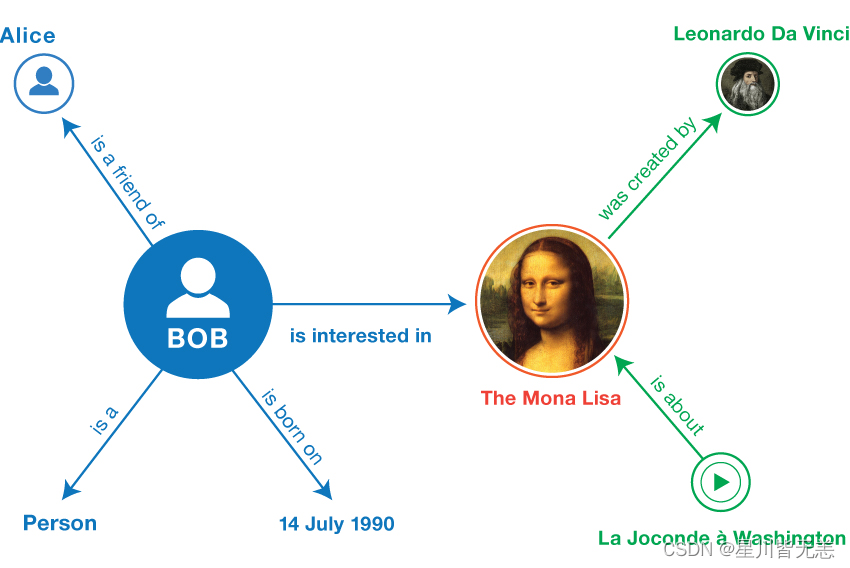
知识表示是知识图谱构建中的核心环节,它涉及将现实世界的复杂信息和关系转化为计算机可理解和处理的格式。有效的知识表示不仅有助于提高知识图谱的查询效率,还能加强知识的推理能力,是实现知识图谱功能的关键。
知识表示模型
知识表示的首要任务是选择合适的模型。当前主流的知识表示模型包括资源描述框架(RDF)、Web本体语言(OWL)和属性图模型。
RDF
RDF是一种将信息表示为“主体-谓词-宾语”三元组的模型,它使得知识的表示形式既灵活又标准化。在RDF中,每个实体和关系都被赋予一个唯一的URI(统一资源标识符),以确保其全球唯一性和可互操作性。RDF的优势在于其简单性和扩展性,但它在表达复杂关系和属性方面存在局限。
OWL
OWL是基于RDF的一种更为复杂和强大的知识表示语言。它支持更丰富的数据类型和关系,包括类、属性、个体等,并能表达复杂的逻辑关系,如等价类、属性限制等。OWL的优势在于其表达能力和逻辑推理能力,适用于构建复杂的领域知识图谱。
属性图模型
属性图模型通过图结构来表示知识,其中节点代表实体,边代表关系,节点和边都可以附带属性。这种模型直观且易于实现,适用于大规模的图数据处理。它在图数据库中得到了广泛应用,如Neo4j、ArangoDB等。
本体构建
本体是知识图谱中用来描述特定领域知识和概念的一组术语和定义。本体的构建是知识图谱构建的重要部分,它定义了知识图谱中的实体类别、属性和关系类型。
本体构建的关键在于准确地把握和表达领域知识。这通常需要领域专家的参与,以确保本体的准确性和全面性。在实际操作中,可以使用本体编辑工具如Protégé来创建和管理本体,同时结合NLP技术自动化提取和维护本体结构。
关系提取与表示
关系提取是指从原始数据中识别出实体之间的关系,并将其加入到知识图谱中。这一步骤通常依赖于文本分析和数据挖掘技术。关系提取的方法包括基于规则的方法、机器学习方法和深度学习方法。
关系的表示要考虑到其多样性和复杂性。在简单的情况下,关系可以被直接表示为实体之间的连接。但在复杂情况下,关系可能涉及多个实体和属性,甚至是关系的层次和类型。在这种情况下,需要更复杂的数据结构和算法来准确表示关系。
五、知识图谱构建技术
构建知识图谱是一个复杂的过程,涉及数据处理、知识提取、存储管理等多个阶段。本节将详细探讨知识图谱构建的关键技术,并提供具体的代码示例。
图数据库选择
选择合适的图数据库是构建知识图谱的首要步骤。图数据库专为处理图形数据而设计,提供高效的节点、边查询和存储能力。常见的图数据库有Neo4j、ArangoDB等。
Neo4j
Neo4j是一个高性能的NoSQL图形数据库,支持Cypher查询语言,适合于处理复杂的关系数据。它的优势在于强大的关系处理能力和良好的社区支持。
ArangoDB
ArangoDB是一个多模型数据库,支持文档、键值及图形数据。它在灵活性和扩展性方面表现出色,适用于多种类型的数据存储需求。
构建流程
构建知识图谱的过程大致可分为数据预处理、实体关系识别、图数据库存储和优化几个阶段。
数据预处理
数据预处理包括数据清洗、实体识别等步骤,目的是将原始数据转换为适合构建知识图谱的格式。
import pandas as pd# 示例:清洗和准备数据
def clean_data(data):# 数据清洗逻辑cleaned_data = data.dropna() # 去除空值return cleaned_data# 假设我们有一个原始数据集
raw_data = pd.read_csv('example_dataset.csv')
cleaned_data = clean_data(raw_data)
实体关系识别
实体关系识别是从清洗后的数据中提取实体和关系。这里以Python和PyTorch实现一个简单的命名实体识别模型为例。
import torch
import torch.nn as nn
import torch.optim as optim# 示例:定义一个简单的命名实体识别模型
class NERModel(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim):super(NERModel, self).__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim)self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)self.fc = nn.Linear(hidden_dim, vocab_size)def forward(self, x):embedded = self.embedding(x)lstm_out, _ = self.lstm(embedded)out = self.fc(lstm_out)return out# 初始化模型、损失函数和优化器
model = NERModel(vocab_size=1000, embedding_dim=64, hidden_dim=128)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
图数据库存储
将提取的实体和关系存储到图数据库中。以Neo4j为例,展示如何使用Cypher语言存储数据。
// 示例:使用Cypher语言在Neo4j中创建节点和关系
CREATE (p1:Person {name: 'Alice'})
CREATE (p2:Person {name: 'Bob'})
CREATE (p1)-[:KNOWS]->(p2)
优化和索引
为提高查询效率,可以在图数据库中创建索引。
// 示例:在Neo4j中为Person节点的name属性创建索引
CREATE INDEX ON :Person(name)
深度学习在构建中的应用
深度学习技术在知识图谱构建中主要用于实体识别、关系提取和知识融合。以下展示一个使用深度学习进行关系提取的示例。
# 示例:使用深度学习进行关系提取
class RelationExtractionModel(nn.Module):def __init__(self, input_dim, hidden_dim):super(RelationExtractionModel, self).__init__()self.lstm = nn.LSTM(input_dim, hidden_dim, batch_first=True)self.fc = nn.Linear(hidden_dim, 2) # 假设有两种关系类型def forward(self, x):lstm_out, _ = self.lstm(x)out = self.fc(lstm_out[:, -1, :])return out# 初始化模型、损失函数和优化器
relation_model = RelationExtractionModel(input_dim=300, hidden_dim=128)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(relation_model.parameters(), lr=0.001)
在这个模型中,我们使用LSTM网络从文本数据中提取特征,并通过全连接层预测实体间的关系类型。
相关文章:
大数据构建知识图谱:从技术到实战的完整指南
文章目录 大数据构建知识图谱:从技术到实战的完整指南一、概述二、知识图谱的基础理论定义与分类核心组成历史与发展 三、知识获取与预处理数据源选择数据清洗实体识别 四、知识表示方法知识表示模型RDFOWL属性图模型 本体构建关系提取与表示 五、知识图谱构建技术图…...
WebServer -- 定时器处理非活动连接(上)
目录 🍍函数指针 🌼基础知识 🐙整体概述 🎂基础API sigaction 结构体 sigaction() sigfillset() SIGALRM, SIGTERM 信号 alarm() socketpair() send() 📕信号通知流程 统一事件源 信号处理机制 &#x…...

微服务部署:金丝雀发布、蓝绿发布和滚动发布的对比
金丝雀发布、蓝绿发布和滚动发布的对比 金丝雀发布、蓝绿发布和滚动发布都是软件发布策略,它们都旨在降低发布风险并提高发布速度。但是,这三种策略在工作方式、优缺点等方面存在一些差异。 工作方式 金丝雀发布:将新版本软件逐步发布给用…...
)
轻松入门MySQL:优化复杂查询,使用临时表简化数据库查询流程(13)
在进销存管理系统中,复杂的数据查询是司空见惯的。这些查询往往需要处理大量的数据,并执行复杂的逻辑操作。然而,处理这些查询可能会变得非常耗时,并且难以维护。为了解决这个问题,我们可以利用临时表,这是…...

vmware的ubuntu虚拟机因空间满无法启动
正在虚拟机编译android源代码,没注意空间不足,结果回来发现了 Assuming drive cache: write through 的问题,经查是空间不足的原因 按照这个教程,清除出来部分空间,才能进去系统,并且对系统空间做下优化 …...
Unity数据持久化之PlayerPrefs
这里写目录标题 PlayerPrefs概述基本方法PlayerPrefs存储位置实践小项目反射知识补充数据管理类的创建反射存储数据----常用成员反射存储数据----List成员反射存储数据----Dictionary成员反射存储数据----自定义类成员反射读取数据----常用成员反射读取数据----List成员反射读取…...

uniapp微信公众号H5分享
如果项目文件node_modules中没有weixin-js-sdk文件,则直接使用本文章提供的; 如果不生效,则在template.h5.html中引入 <script src"https://res.wx.qq.com/open/js/jweixin-1.6.0.js"></script> 首先引入weixin-js-…...

深入理解指针(c语言)
目录 一、使用指针访问数组二、数组名的理解1、数组首元素的地址2、整个数组 三、一维数组传参的本质四、冒泡排序五、二级指针六、指针数组 一、使用指针访问数组 可以使用指针来访问数组元素。例如,可以声明一个指针变量并将其指向数组的第一个元素,然…...
高级语言期末2015级唐班B卷
1.编写函数,按照如下公式计算圆周率π的值(精确到1e-5) #include <stdio.h>double pai() {double last0;double flag1;int n1;while(flag-last>1e-5) {lastflag;flag*1.0*(2*n)*(2*n)/((2*n-1)*(2*n1));n;}return 2*last; }int main…...
开发一款招聘小程序需要具备哪些功能?
随着时代的发展,找工作的方式也在不断变得简单,去劳务市场、人才市场的方式早就已经过时了,现在大多数年轻人都是直接通过手机来找工作。图片 找工作类的平台不但能扩大企业的招聘渠道,还能节省招聘的成本,方便求职者进…...
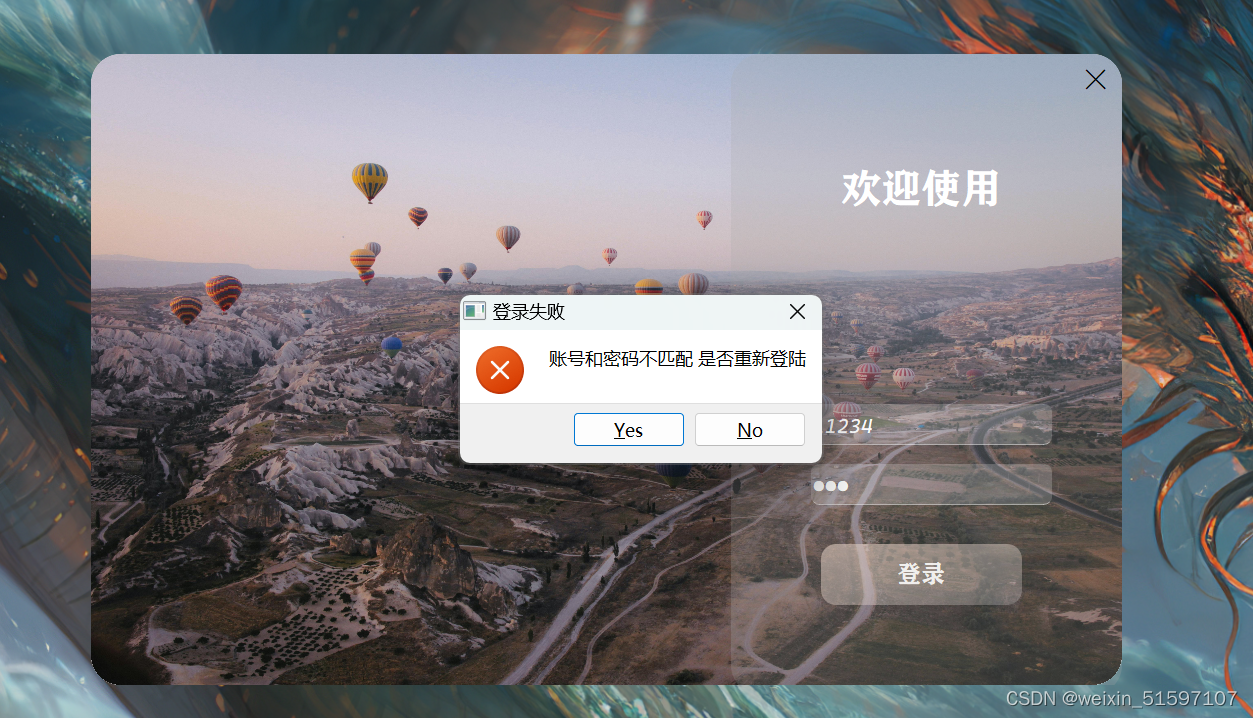
嵌入式学习-qt-Day3
嵌入式学习-qt-Day3 一、思维导图 二、作业 完善对话框,点击登录对话框,如果账号和密码匹配,则弹出信息对话框,给出提示”登录成功“,提供一个Ok按钮,用户点击Ok后,关闭登录界面,跳…...

零基础到高级:Android音视频开发技能路径规划
音视频开发趋势 Android音视频开发领域目前正处于一个高速发展的阶段,主要趋势如下: 超高清视频:4K视频亚毫米级显示清晰,更加逼真,为开发更加逼真的虚拟现实应用提供了基础。AI技术:自适应码率控制、视频…...

阿里云香港轻量应用服务器网络线路cn2?
阿里云香港轻量应用服务器是什么线路?不是cn2。 阿里云香港轻量服务器是cn2吗?香港轻量服务器不是cn2。阿腾云atengyun.com正好有一台阿里云轻量应用服务器,通过mtr traceroute测试了一下,最后一跳是202.97开头的ip,1…...

python中websockets与主线程传递参数
目录 一、子线程创建websockets服务端接收客户端数据 二、主线程内启动子线程接收并处理数据 一、子线程创建websockets服务端接收客户端数据并存入队列 发送的消息客户端与服务端统一,多种消息加入判断的标签 服务端:web_server.py import asynci…...

js谐音梗创意小游戏《望子成龙》
🌻 前言 龙年到来,祥瑞满天。愿您如龙般矫健,事业腾飞;如龙鳞闪耀,生活美满。祝您龙年大吉,万事如意! 龙年伊始,我给各位设计了一款原创的小游戏,话不多说,直…...

第十篇:node处理404和服务器错误
🎬 江城开朗的豌豆:个人主页 🔥 个人专栏 :《 VUE 》 《 javaScript 》 📝 个人网站 :《 江城开朗的豌豆🫛 》 ⛺️ 生活的理想,就是为了理想的生活 ! 目录</...

左右互博。
链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网 讨厌鬼在和小甜妹在玩石头游戏。 游戏一开始有 nnn 堆石子,第 iii 堆石子,有 aia_iai 个石子。两人轮流进行游戏。 轮到某个人时,这个人先选数量为 x(x&…...

android通过广播打印ram使用信息
在内存非常吃紧的情况下,android设备会开始kill部分非系统进程甚至系统进程来保证基本的系统运行。在这种情况下如何获取设备过去某段时间的ram使用情况至关重要。 通过开发者模式中的“内存”可以完美得知设备内存使用信息。 我们可以通过此途径,设计一…...

内存管理——线性内存,进程空间
低2G为进程空间 开始地址结束地址大小属性00xFFFFF1M保留0x1000000x102FFF栈不固定位置、大小0x1030000x143FFF堆不固定位置、大小0x400000主程序文件不固定位置、大小加载dll不固定位置、大小0x7ffdd000TIB位置,大小编译时固定0x7FFFE000系统与用户共享数据块位置…...

入门Python必读的流程控制语句
流程控制 if-else 语法: if 条件:语句else:语句 例子: a1 #使用方式一 if a>1:print(大于1) else:print(小于等于1) #使用方式二 print(大于1) if a>1 else print(小于等于1) 输出: >>小于等于1 >>小于等于1 if-elif-else 语法: if 条件:语句elif 条件:…...

Windows远程桌面终极解锁指南:如何免费开启多用户并发连接
Windows远程桌面终极解锁指南:如何免费开启多用户并发连接 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap 还在为Windows家庭版无法使用远程桌面而烦恼吗?RDP Wrapper Library这款开源工具能…...
—— 从漏检比例到多项式选择的工程权衡)
CRC校验码的检错性能(一)—— 从漏检比例到多项式选择的工程权衡
1. CRC校验码的检错性能基础 当你用手机发送一条消息,或者从硬盘读取文件时,数据在传输过程中可能会出错。这时候就需要一种"数据质检员"来检查错误,CRC校验码就是其中最常用的一种。它就像快递包裹上的防拆封条,能告诉…...
深度解析:如何让你的飞控代码轻松跑在不同芯片上?)
ArduPilot硬件抽象层(HAL)深度解析:如何让你的飞控代码轻松跑在不同芯片上?
ArduPilot硬件抽象层(HAL)深度解析:跨平台飞控开发实战指南 当开发者尝试将ArduPilot移植到一块全新的飞控板时,最常遇到的挑战莫过于如何让同一套控制算法在不同硬件架构上无缝运行。这正是硬件抽象层(HAL)设计的精妙之处——它如同一位技艺高超的翻译官…...

告别‘天书’!手把手教你用vdex2dex、odex2smali等工具,把Android应用的vdex/odex/cdex转成可读的dex文件
Android逆向工程实战:从vdex/odex/cdex到可读dex的完整指南 当你兴致勃勃地打开一个APK文件准备分析时,却发现里面只有vdex、odex或cdex文件,用JADX直接打开全是乱码——这种挫败感每个逆向工程师都经历过。本文将带你一步步破解这些"天…...

【图像增强】基于Grünwald–Letnikov和Riesz分数阶算子的四种分数阶PDE图像增强算法的MATLAB实现
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室👇 关注我领取海量matlab电子书和…...

Skill 不是 Prompt 模板,而是 Code Agent 的领域知识接口
很多人第一次把 Code Agent 接进老项目,都会经历一个落差: Demo 里它能十分钟写完一个 CRUD;一进真实业务系统,它开始犯一些“刚入职新人”才会犯的错。 它能看懂 Controller,却不知道这个字段为什么不能改ÿ…...

别再只盯着增益了!用Cadence仿真两级比较器,手把手教你搞定噪声、失调和延时
两级比较器Cadence仿真实战:从噪声分析到延时优化的全流程指南 在模拟IC设计领域,比较器作为信号链中的关键模块,其性能直接影响整个系统的精度与响应速度。传统教材往往聚焦于比较器的理论推导,却鲜少提供可落地的仿真验证方法。…...

MSP430单片机低功耗设计实战:从架构到代码的灵活性解析
1. 项目概述:为什么是MSP430?如果你在嵌入式领域摸爬滚打了一段时间,尤其是在对功耗极其敏感的应用场景里,比如智能穿戴、便携医疗设备、无线传感器网络或者那些需要电池供电数年的工业传感器,那么“MSP430”这个名字对…...
)
Perplexity估值从3B美元缩水至1.8B?华尔街分析师闭门会议纪要首度流出(含5条未公开预警红线)
更多请点击: https://intelliparadigm.com 第一章:Perplexity估值缩水事件全景速览 2024年第三季度,AI搜索初创公司Perplexity在完成新一轮融资后,其内部估值从2023年底的10亿美元迅速回调至约7.5亿美元,引发全球科技…...

避坑指南:STM32F4 HAL库驱动MPU6050,从GitHub标准库移植到DMA模式的完整记录
STM32F4 HAL库下MPU6050 DMA模式移植实战:从标准库到高效姿态采集 移植第三方传感器驱动是嵌入式开发中的高频操作。最近在平衡车项目中,需要将GitHub上一个基于标准库的MPU6050驱动移植到STM32CubeMX生成的HAL库环境,并升级为DMA传输模式。这…...