通俗易懂理解GhostNetV1轻量级神经网络模型
一、参考资料
原始论文:[1]
PyTorch代码链接:Efficient-AI-Backbones
MindSpore代码:ghostnet_d
解读模型压缩5:减少冗余特征的Ghost模块:华为Ghost网络系列解读
GhostNet论文解析:Ghost Module
CVPR 2020:华为GhostNet,超越谷歌MobileNet,已开源
二、术语解析
廉价的线性变换/线性运算:cheap linear operations;
线性变换的线性内核:linear kernels;
深度可分离卷积:Depthwise Separable Convolution,DSConv;
逐深度卷积:Depthwise Convolution,DWConv;
逐点卷积:Pointwise Convolution,PWConv;
Ghost特征图:Ghost feature maps;
三、相关介绍
1. 廉价的线性变换
“廉价”指的是计算量小,计算成本低。
cheap operation 其实就是 group convolution,group number = input channel number,相当于DWConv操作。
2. 标准卷积层
关于标准卷积的详细介绍,请参考博客:
关于CNN卷积神经网络与Conv2D标准卷积的重要概念
CNN卷积神经网络模型的参数量、计算量计算方法(概念版)

给定输入特征图 X ∈ R h × w × c X\in\mathbb{R}^{h\times w \times c} X∈Rh×w×c,卷积核 f ∈ R c × k × k × n f\in\mathbb{R}^{c\times k\times k\times n} f∈Rc×k×k×n,通过标准卷积操作,输出特征图为 Y ∈ R h ′ × w ′ × n Y\in\mathbb{R}^{h^{\prime}\times w^{\prime}\times n} Y∈Rh′×w′×n,标准卷积过程可以表示为:
Y = X ∗ f + b , ( 1 ) Y=X*f+b,\quad(1) Y=X∗f+b,(1)
其中, ∗ * ∗ 是卷积运算, b b b 是偏置项。
标准卷积的FLOPs计算量为: n ⋅ h ′ ⋅ w ′ ⋅ c ⋅ k ⋅ k n\cdot h^{\prime}\cdot w^{\prime}\cdot c\cdot k\cdot k n⋅h′⋅w′⋅c⋅k⋅k。
四、GhostNetV1相关介绍
GhostNetV1 又称为 C-GhostNet,是针对CPU优化的轻量级神经网络。
1. 摘要
该论文提供了一个全新的Ghost Module,旨在通过廉价操作生成更多的特征图。基于一组原始的特征图,作者应用一系列廉价的线性变换(cheap linear operations),以很小的代价生成许多能从原始特征发掘所需信息的Ghost特征图。该Ghost模块即插即用,通过堆叠Ghost Module得出 Ghost bottleneck,进而搭建轻量级神经网络——GhostNet。在ImageNet分类任务,GhostNet在相似计算量情况下Top-1正确率达75.7%,高于MobileNetV3的75.2%。
2. 引言
深度卷积神经网络通常引用由大量卷积组成的卷积神经网络,导致大量的计算成本。尽管最近的工作,例如MobileNet和ShuffleNet引入DSConv或混洗操作(shuffle),以使用较小的卷积核(浮点运算)来构建有效的CNN,其余 1×1 卷积层仍将占用大量内存和FLOPs。
在深度卷积神经网络中,中间层的输出特征图通常会包含丰富甚至冗余的特征图,其中一些特征图可以通过对另一些特征图基于某种简单的操作变换获取,比如仿射变换和小波变换这些低成本的线性运算。如下图所示,在ResNet-50中,将经过第一个残差块处理后的特征图拿出来,三个相似的特征图对用相同颜色的框注释。 在一个特征图对中,其中一个特征图可以通过廉价操作(用扳手表示)将另一个特征图变换而获得,可以认为其中一个特征图是另一个的“幻影(Ghost)”。因为,本文提出并非所有特征图都要用卷积操作来得到,Ghost特征图可以使用廉价的操作来生成。

3. Ghost Module(GM)
利用Ghost Module生成与普通卷积层相同数量的特征图,我们可以轻松地将Ghost Module替换卷积层,集成到现有设计好的神经网络结构中,以减少计算成本。
3.1 Ghost Module原理
Ghost Module分为三步:
- 通过
DWConv,生成 m = n s m=\frac {n}{s} m=sn 个本征特征图; - 通过廉价的线性变换,生成 n = m ⋅ s n=m \cdot s n=m⋅s 个Ghost特征图;
- 拼接本征特征图和Ghost特征图。

上图中, I d e n t i t y Identity Identity 表示恒等映射, Φ k \Phi_k Φk 表示廉价的线性变换。
Step1:生成m个本征特征图(intrinsic feature maps)
首先,给定输入特征图 X ∈ R h × w × c X\in\mathbb{R}^{h\times w \times c} X∈Rh×w×c,PWConv 卷积核 f ′ ∈ R c × k × k × m f^{\prime}\in\mathbb{R}^{c\times k\times k\times m} f′∈Rc×k×k×m 的尺寸为 1 × 1 1 \times 1 1×1 ,通过 PWConv 操作,生成 m m m个本征特征图 Y ∈ R h × w × m Y\in\mathbb{R}^{h\times w\times m} Y∈Rh×w×m。 m ≤ n m\leq n m≤n,输入特征图与输出特征图的高和宽一致。为简单起见,这里省略偏置项,该过程可以表示为:
Y ′ = X ∗ f ′ , ( 2 ) Y^{\prime}=X*f',\quad(2) Y′=X∗f′,(2)
Step2:生成n个Ghost特征图
然后,将本征特征图 Y ′ Y^{\prime} Y′ 每一个通道的特征图 y i ′ y^{\prime}_i yi′,通过一系列廉价的线性变换 Φ i , j \Phi_{i,j} Φi,j ,以生成 s s s个Ghost特征图 y i j y_{ij} yij,公式表达如下:
y i j = Φ i , j ( y i ′ ) , ∀ i = 1 , . . . , m , j = 1 , . . . , s , ( 3 ) y_{ij}=\Phi_{i,j}(y^{\prime}_i),\quad \forall i=1,...,m,\quad j=1,...,s,\quad(3) yij=Φi,j(yi′),∀i=1,...,m,j=1,...,s,(3)
其中, y i ′ y^{\prime}_i yi′ 是 Y ′ Y^{\prime} Y′ 中第 i i i个原始特征图,上述函数中的 Φ i , j \Phi_{i,j} Φi,j 是第 j j j个线性变换,用于生成第 j j j个Ghost特征图 y i j y_{ij} yij。也就是说, y i ′ y^{\prime}_i yi′ 可以具有一个或多个Ghost特征图 { y i j } j = 1 s \{y_{ij}\}_{j=1}^{s} {yij}j=1s。最后的 Φ i , s \Phi_{i,s} Φi,s 是用于保留本征特征图的恒等映射。通过廉价的线性变换,生成 n = m ⋅ s n=m \cdot s n=m⋅s个Ghost特征图 Y = [ y 11 , y 12 , ⋯ , y m s ] Y=[y_{11},y_{12},\cdots,y_{ms}] Y=[y11,y12,⋯,yms]。
s s s为超参数,用于生成 m = n s m = \frac{n}{s} m=sn 个本征特征图。
Step3:拼接特征图
最后,将第一步得到的本征特征图和第二步得到的Ghost特征图拼接(identity连接),得到最终结果OutPut。公式表达如下:
Y = Concat ( [ Y ′ , Y ′ ∗ Φ i , j ] ) , Y=\operatorname{Concat}([Y',Y'*\Phi_{i,j}]), Y=Concat([Y′,Y′∗Φi,j]),

上图中, w ′ = w , h ′ = h w^{\prime} = w, h^{\prime} = h w′=w,h′=h。
3.2 Ghost Module与DSConv
关于深度可分离卷积的详细介绍,请参考另一篇博客:深入浅出理解深度可分离卷积(Depthwise Separable Convolution)
DSConv由DWConv和PWConv构成,使用 DWConv 处理空间信息,使用 PWConv 处理不同channel之间的信息。相比之下,Ghost Module先使用标准卷积得到一些特征,再使用廉价线性变换得到另一些特征。
从另一个角度看,Ghost Module 是对本征特征图做增强/增广,和数据增广有点相似。
3.3 Φ i , j \Phi_{i,j} Φi,j 线性变换:DWConv
论文中使用的廉价的线性变换并不是常见的旋转、平移、仿射变换(affine transformation)和小波变换(wavelet transformation),而是用的DWConv。 因为卷积是当前硬件已经很好支持的高效运算,它可以涵盖许多广泛使用的线性运算,例如平滑、模糊等。此外,线性变换的 linear kernels 大小为 d × d d\times d d×d, d d d 不一致会导致计算单元(例如CPU和GPU)的计算效率降低。所以,论文中== d d d 取固定值(例如全3x3或全5x5),并利用 DWConv 来实现 Φ i , j \Phi_{i,j} Φi,j==,以构建高效的深度神经网络。
3.4 Ghost Module计算量与参数量
Ghost Module具有1个恒等映射(identity mapping)和 m ⋅ ( s − 1 ) = n s ⋅ ( s − 1 ) m\cdot(s-1)=\frac{n}{s}\cdot(s-1) m⋅(s−1)=sn⋅(s−1) 个线性变换。进行1个恒等映射,生成 m m m个本征特征图,进行 m ⋅ ( s − 1 ) m\cdot(s-1) m⋅(s−1) 个线性变换,生成 n n n个Ghost特征图。
解释说明:
n − m = m × s − m = m × ( s − 1 ) = n s ⋅ ( s − 1 ) n-m=m \times s - m = m \times (s-1) =\frac{n}{s}\cdot(s-1) n−m=m×s−m=m×(s−1)=sn⋅(s−1)
每个线性变换的 linear kernels 大小为 d × d d \times d d×d,其中 d d d 为超参数。
Ghost Module与标准卷积的计算量加速比为:
r s = n ⋅ h ′ ⋅ w ′ ⋅ c ⋅ k ⋅ k n s ⋅ h ′ ⋅ w ′ ⋅ c ⋅ k ⋅ k + ( s − 1 ) ⋅ n s ⋅ h ′ ⋅ w ′ ⋅ d ⋅ d = c ⋅ k ⋅ k 1 s ⋅ c ⋅ k ⋅ k + s − 1 s ⋅ d ⋅ d ≈ s ⋅ c s + c − 1 ≈ s . ( 4 ) \begin{gathered} r_{s} =\frac{n\cdot h^{\prime}\cdot w^{\prime}\cdot c\cdot k\cdot k}{\frac ns\cdot h^{\prime}\cdot w^{\prime}\cdot c\cdot k\cdot k+(s-1)\cdot\frac ns\cdot h^{\prime}\cdot w^{\prime}\cdot d\cdot d} \\ =\frac{c\cdot k\cdot k}{\frac1s\cdot c\cdot k\cdot k+\frac{s-1}s\cdot d\cdot d}\approx\frac{s\cdot c}{s+c-1}\approx s. \end{gathered}\quad (4) rs=sn⋅h′⋅w′⋅c⋅k⋅k+(s−1)⋅sn⋅h′⋅w′⋅d⋅dn⋅h′⋅w′⋅c⋅k⋅k=s1⋅c⋅k⋅k+ss−1⋅d⋅dc⋅k⋅k≈s+c−1s⋅c≈s.(4)
其中, d × d d \times d d×d 的幅度与 k × k k \times k k×k 和 s ≪ c s\ll c s≪c 相似。
Ghost Module与标准卷积的参数量压缩比为:
r c = n ⋅ c ⋅ k ⋅ k n s ⋅ c ⋅ k ⋅ k + ( s − 1 ) ⋅ n s ⋅ d ⋅ d ≈ s ⋅ c s + c − 1 ≈ s . ( 5 ) \begin{aligned}r_c&=\frac{n\cdot c\cdot k\cdot k}{\frac{n}{s}\cdot c\cdot k\cdot k+(s-1)\cdot\frac{n}{s}\cdot d\cdot d}\approx\frac{s\cdot c}{s+c-1}\approx s.\end{aligned} \quad (5) rc=sn⋅c⋅k⋅k+(s−1)⋅sn⋅d⋅dn⋅c⋅k⋅k≈s+c−1s⋅c≈s.(5)
3.5 Ghost Module消融实验
如上所述,Ghost Module有两个超参数:
- s s s用于生成 m = n s m=\frac {n}{s} m=sn 个本征特征图;
- 用于计算Ghost特征图的线性变换的
linear kernels尺寸 d × d d \times d d×d,即DWConv的卷积核。
作者测试了这两个超参数对模型精度的影响。首先,作者固定 s = 2 s=2 s=2,并在 { 1 , 3 , 5 , 7 } \{1, 3, 5, 7\} {1,3,5,7} 范围中调整 d d d,在CIFIAR-10数据集上测试结果如下表所示:

从上表中可以看出,当 d = 3 d=3 d=3 时,Ghost Module 的性能优于更小或更大的 Ghost Module。这是因为大小为 1 × 1 1 \times 1 1×1 的卷积核无法在特征图上引入空间信息,而较大的 linear kernels(例如 d = 5 d=5 d=5或 d = 7 d=7 d=7)会导致过拟合和更多计算量。因此,在以下实验中,作者采用 d = 3 d=3 d=3 来提高有效性和效率。
在研究了 linear kernels 大小的影响后,作者固定 d = 3 d=3 d=3,并在 { 2 , 3 , 4 , 5 } \{2, 3, 4, 5\} {2,3,4,5} 的范围内调整超参数 s s s。实际上, s s s 与计算成本直接相关,也即较大的 s s s导致较大的计算量加速比和参数量压缩比。实验结果如下表所示:

从上表中可以看出,当增加 s s s时,FLOPs显著减少,且准确率逐渐降低,这是预期内的结果。特别的,当 s = 2 s=2 s=2 时,也就是将VGG-16压缩 2 × 2 \times 2× 时,Ghost Module的性能甚至比原始模型更好,表明所提出的Ghost Module的优越性。
3.6 (PyTorch)代码实现
class GhostModule(nn.Module):def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):super(GhostModule, self).__init__()self.oup = oupinit_channels = math.ceil(oup / ratio)new_channels = init_channels*(ratio-1)self.primary_conv = nn.Sequential(nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False),nn.BatchNorm2d(init_channels),nn.ReLU(inplace=True) if relu else nn.Sequential(),)# Depthwiseconvself.cheap_operation = nn.Sequential(nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False),nn.BatchNorm2d(new_channels),nn.ReLU(inplace=True) if relu else nn.Sequential(),)def forward(self, x):x1 = self.primary_conv(x)x2 = self.cheap_operation(x1)out = torch.cat([x1,x2], dim=1)return out[:,:self.oup,:,:]
3.7 (Paddle)代码实现
# 复现恒等映射和线性变换的特征融合import paddle
from paddle.fluid.layers.nn import transpose
import paddle.nn as nn
import math
import paddle.nn.functional as Fclass DWConv3x3BNReLU(nn.Sequential):def __init__(self, in_channel, out_channel, stride, groups):super(DWConv3x3BNReLU, self).__init__(nn.Conv2D(in_channels=in_channel, out_channels=out_channel, kernel_size=3, stride=stride, padding=1, groups=groups, bias_attr=False),nn.BatchNorm2D(out_channel),nn.ReLU6(),)class GhostModule(nn.Layer):def __init__(self, in_channels, out_channels, s=2, kernel_size=1, stride=1, use_relu=True):super(GhostModule, self).__init__()intrinsic_channel = out_channels // sghost_channel = intrinsic_channel * (s - 1)self.primary_conv = nn.Sequential(nn.Conv2D(in_channels=in_channels, out_channels=intrinsic_channel, kernel_size=kernel_size, stride=stride, padding=(kernel_size-1)//2, bias_attr =False),nn.BatchNorm2D(intrinsic_channel),nn.ReLU() if use_relu else nn.Sequential())self.cheap_op = DWConv3x3BNReLU(in_channel=intrinsic_channel, out_channel=ghost_channel, stride=stride, groups=intrinsic_channel)def forward(self, x):x1 = self.primary_conv(x)x2 = self.cheap_op(x1)out = paddle.concat([x1, x2], axis=1)return out
4. Ghost bottleneck(G-bneck)
4.1 Ghost bottleneck结构
Ghost bottleneck与ResNet中的基本残差块(Basic Residual Block)结构相似,可以认为是将 Basic Residual Block 中的卷积操作用 Ghost Module 替换得到。
Ghost bottleneck主要由两个堆叠的Ghost Module组成。第一个Ghost Module用于增加通道数。第二个Ghost Module用于减少通道数,以与shortcut路径匹配。然后,使用shortcut连接这两个Ghost Module的输入和输出。这里借鉴了MobileNetV2,第二个Ghost Module之后不使用ReLU激活函数,其他层在每层之后都应用了批量归一化(BN)和ReLU非线性激活。作者设计了2种Ghost bottleneck。如下图所示,分别对应着 stride=1 和 stride=2 的情况。Ghost bottleNeck结构如下图所示:

左图中,stride=1,主干通路用两个 Ghost Module 串联组成,其中第一个Ghost Module扩大通道数,第二个Ghost Module将通道数降低到与输入通道数一致。
右图中,stride=2,与左图的不同之处在于,主干通路的两个 Ghost Module 之间加入了一个 stride=2 的 DWConv,可以将特征图大小降为输入特征图的 1 2 \frac {1}{2} 21,且跳跃连接通路也需要同样的降采样,以保证Add操作可以对齐。这个模块可以用来替换其他CNN中的下采样层(1/2)。
出于效率考虑,Ghost Module中的所有标准卷积都用PWConv代替。
4.2 (PyTorch)代码实现
class GhostBottleneck(nn.Module):def __init__(self, inp, hidden_dim, oup, kernel_size, stride, use_se):super(GhostBottleneck, self).__init__()assert stride in [1, 2]self.conv = nn.Sequential(# PointwiseConvGhostModule(inp, hidden_dim, kernel_size=1, relu=True),# DepthwiseConvdepthwise_conv(hidden_dim, hidden_dim, kernel_size, stride, relu=False) if stride==2 else nn.Sequential(),# Squeeze-and-ExciteSELayer(hidden_dim) if use_se else nn.Sequential(),# pw-linearGhostModule(hidden_dim, oup, kernel_size=1, relu=False),)if stride == 1 and inp == oup:self.shortcut = nn.Sequential()else:self.shortcut = nn.Sequential(# DepthwiseConvdepthwise_conv(inp, inp, 3, stride, relu=True),nn.Conv2d(inp, oup, 1, 1, 0, bias=False),nn.BatchNorm2d(oup),)def forward(self, x):return self.conv(x) + self.shortcut(x)
5. GhostNetV1
5.1 MobileNetV3结构
关于MobileNet网络模型的详细介绍,请参考另一篇博客:通俗易懂理解MobileNet网络模型

5.2 GhostNetV1结构
基于MobileNetV3网络结构的优势,作者使用 Ghost bottleneck 替换MobileNetV3中的bottleneck。基于Ghost bottleneck,作者提出GhostNet。
GhostNet主要由一堆Ghost bottleneck组成,其中Ghost bottleneck以Ghost Module为基础。第一层是具有16个卷积核的标准卷积层,然后是一系列Ghost bottleneck,通道逐渐增加。这些Ghost bottleneck根据其输入特征图的尺寸大小分为不同的阶段(stage)。除了每个阶段的最后一个Ghost bottleneck是stride = 2,其他所有Ghost bottleneck都以stride = 1。最后,利用全局平均池化和卷积层将特征图转换为1280维特征向量以进行最终分类。SE模块用在某些Ghost bottleneck中的残差层。与MobileNetV3相比,这里用ReLU换掉了Hard-swish激活函数。GhostNet 网络结构如下表所示。
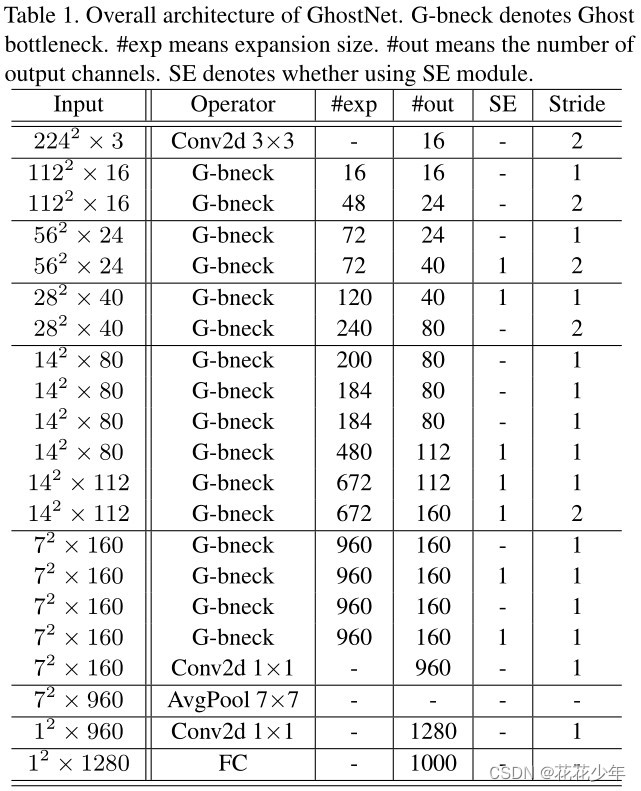
解释说明
-
#exp,表示expansion ratio,将输出通道数与输入通道数之比称为expansion ratio; -
#out,表示output channels; -
SE,表示是否使用SE模块; -
Stride,表示stride。
五、参考文献
[1] Han K, Wang Y, Tian Q, et al. Ghostnet: More features from cheap operations[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020: 1580-1589.
相关文章:
通俗易懂理解GhostNetV1轻量级神经网络模型
一、参考资料 原始论文:[1] PyTorch代码链接:Efficient-AI-Backbones MindSpore代码:ghostnet_d 解读模型压缩5:减少冗余特征的Ghost模块:华为Ghost网络系列解读 GhostNet论文解析:Ghost Module CVPR…...
P8630 [蓝桥杯 2015 国 B] 密文搜索
P8630 [蓝桥杯 2015 国 B] 密文搜索 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)https://www.luogu.com.cn/problem/P8630 题目分析 基本上是hash的板子,但实际上对于密码串,只要判断主串中任意连续的八个位置是否存在密码串即可;那么我们…...

Electron实战之环境搭建
工欲善其事必先利其器,在进行实战开发的时候,我们最终的步骤是搞好一个舒服的开发环境,目前支持 Vue 的 Electron 工程化工具主要有 electron-vue、Vue CLI Plugin Electron Builder、electron-vite。 接下来我们将分别介绍基于 Vue CLI Plu…...

【0259】inval.h/inval.c的理解
1. inval.h/inval.c inval.h、inval.c是缓存无效消息(invalidation message)调度程序定义。 2. inval.h/inval.c特性 inval.h/inval.c的实现是一个非常微妙的东西,所以需要注意: 当一个元组被更新或删除时,我们的标准可见性规则(standard visibility rules)认为只要我…...

力扣爆刷第77天--动态规划一网打尽打家劫舍问题
力扣爆刷第77天–动态规划一网打尽打家劫舍问题 文章目录 力扣爆刷第77天--动态规划一网打尽打家劫舍问题一、198.打家劫舍二、213.打家劫舍II三、337.打家劫舍 III 一、198.打家劫舍 题目链接:https://leetcode.cn/problems/house-robber/ 思路:小偷不…...

深入理解C语言(5):程序环境和预处理详解
文章主题:程序环境和预处理详解🌏所属专栏:深入理解C语言📔作者简介:更新有关深入理解C语言知识的博主一枚,记录分享自己对C语言的深入解读。😆个人主页:[₽]的个人主页🏄…...
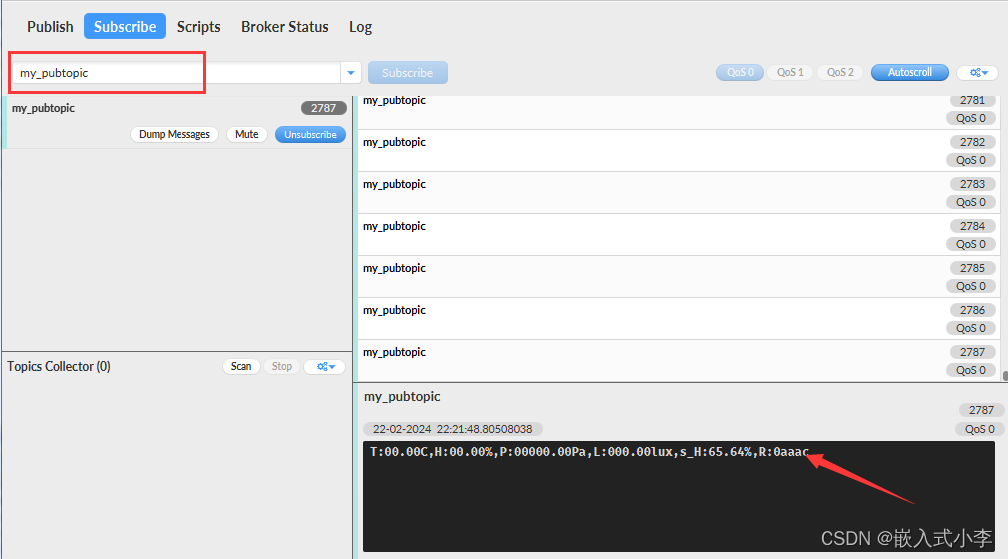
ESP8266智能家居(3)——单片机数据发送到mqtt服务器
1.主要思想 前期已学习如何用ESP8266连接WIFI,并发送数据到服务器。现在只需要在单片机与nodeMCU之间建立起串口通信,这样单片机就可以将传感器测到的数据:光照,温度,湿度等等传递给8266了,然后8266再对数据…...
—— 筑梦之路)
lvm逻辑卷创建raid阵列(不常用)—— 筑梦之路
RAID卷介绍 逻辑卷管理器(LVM)不仅仅可以将多个磁盘和分区聚合到一个逻辑卷中,以此提高单个分区的存储容量,还可以创建和管理独立磁盘的冗余阵列(RAID)卷,防止磁盘故障并提高性能。它支持常用的RAID级别,支持的RAID的级别有 0、1…...

LayUI发送Ajax请求
页面初始化操作 var processData null $(function () {initView();initTable();// test(); })function initView() {layui.use([laydate, form], function () {var laydate layui.laydate;laydate.render({elem: #applyDateTimeRange,type: datetime,range: true});}); }初始…...

平时积累的FPGA知识点(10)
平时在FPGA群聊等积累的FPGA知识点,第10期: 41 ZYNQ系列芯片的PL中使用PS端送过来的时钟,这些时钟名字是自动生成的吗? 解释:是的。PS端设置的是ps_clk,用report_clocks查出来的时钟名变成了clk_fpga_0&a…...
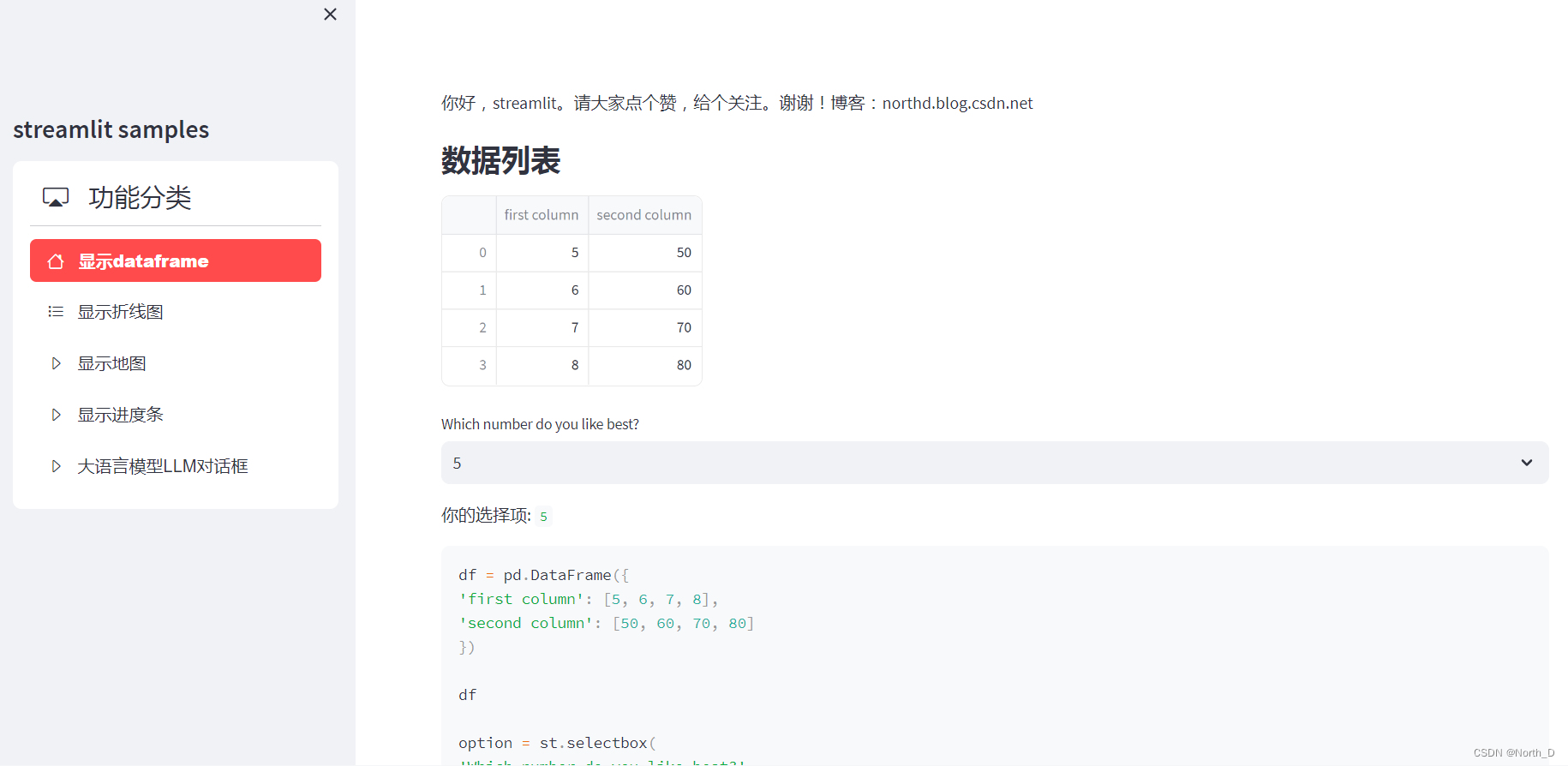
使用Streamlit构建纯LLM Chatbot WebUI傻瓜教程
文章目录 使用Streamlit构建纯LLM Chatbot WebUI傻瓜教程开发环境hello Streatelit显示DataFrame数据显示地图WebUI左右布局设置st.sidebar左侧布局st.columns右侧布局 大语言模型LLM Chatbot WebUI设置Chatbot页面布局showdataframe()显示dataframeshowLineChart()显示折线图s…...
电脑死机卡住怎么办 电脑卡住鼠标也点不动的解决方法
在我们使用电脑的过程中,可能由于电脑硬件或者软件的问题,偶尔会出现电脑卡住的情况,很多电脑小白都不知道电脑卡住了怎么办,鼠标也点不动,键盘也没用,一旦发生了这种情况,大家可以来参考一下小编分享的电脑死机卡住的解决方法。 电脑卡住鼠标也点不动的解决方法 方…...

RAG 语义分块实践
每日推荐一篇专注于解决实际问题的外文,精准翻译并深入解读其要点,助力读者培养实际问题解决和代码动手的能力。 原文标题:Semantic chunking in practice 原文地址:https://medium.com/@boudhayan-dev/semantic-chunking-in-practice-23a8bc33d56d 语义分块的实践 回顾 …...

12 Autosar_SWS_MemoryMapping.pdf解读
AUTOSAR中MemMap_autosar memmap-CSDN博客 1、Memory Map的作用 1.1 避免RAM的浪费:不同类型的变量,为了对齐造成的空间两份; 1.2 特殊RAM的用途:比如一些变量通过位掩码来获取,如果map到特定RAM可以通过编译器的位掩码…...

【Linux取经路】文件系统之缓冲区
文章目录 一、先看现象二、用户缓冲区的引入三、用户缓冲区的刷新策略四、为什么要有用户缓冲区五、现象解释六、结语 一、先看现象 #include <stdio.h> #include <string.h> #include <unistd.h>int main() {const char* fstr "Hello fwrite\n"…...
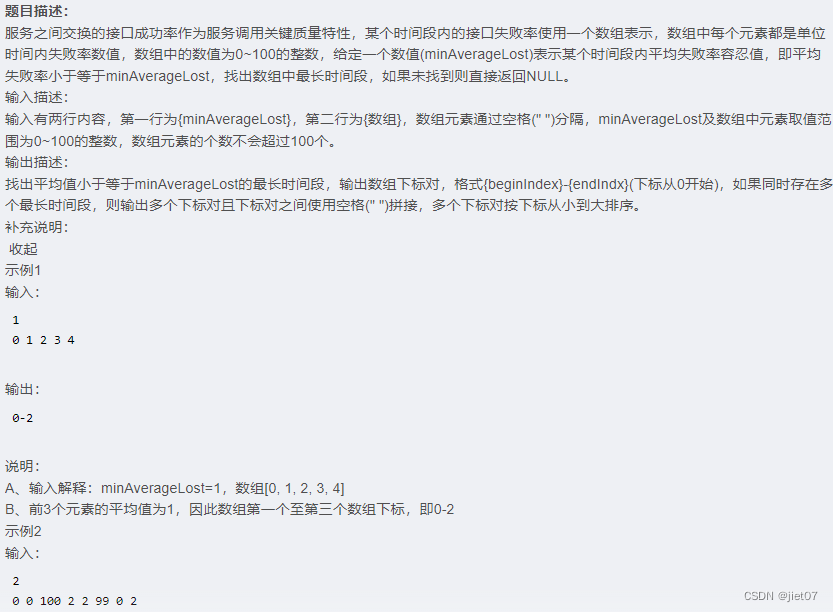
华为OD机试真题-查找接口成功率最优时间段-2023年OD统一考试(C卷)--Python3--开源
题目: 考察内容: for 时间窗口list(append, sum, sort) join 代码: """ 题目分析:最长时间段 且平均值小于等于minLost同时存在多个时间段,则输出多个,从大到小排序未找到返回 NULL 输入…...
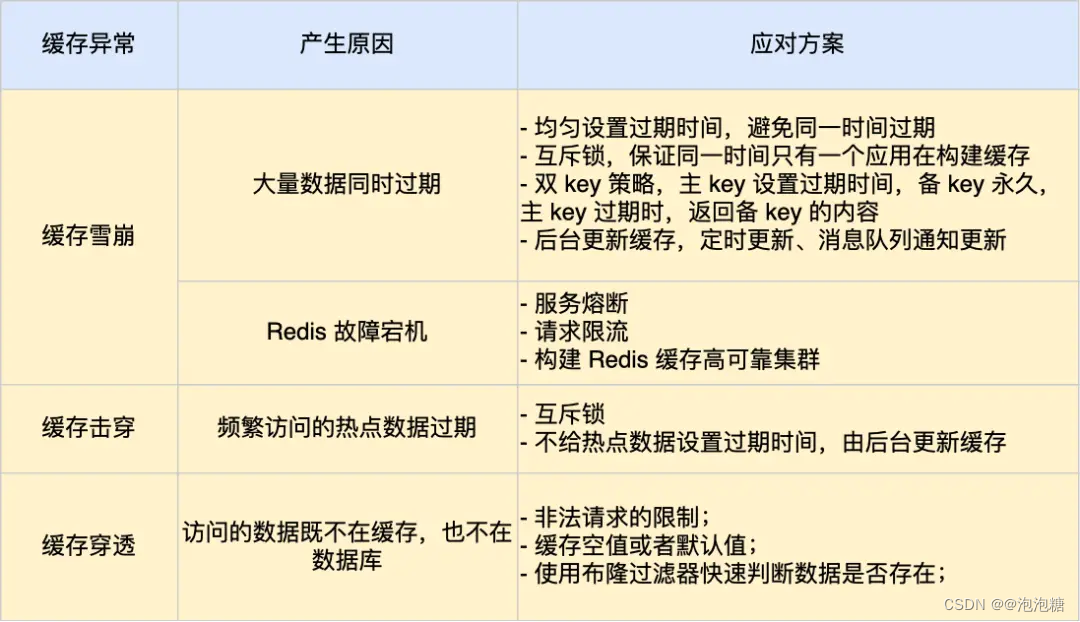
缓存篇—缓存雪崩、缓存击穿、缓存穿透
缓存异常会面临的三个问题:缓存雪崩、击穿和穿透。 其中,缓存雪崩和缓存击穿主要原因是数据不在缓存中,而导致大量请求访问了数据库,数据库压力骤增,容易引发一系列连锁反应,导致系统奔溃。不过࿰…...

Python实现视频转音频、音频转文本的最佳方法
文章目录 Python实现视频转音频和音频转文字视频转音频步骤 1:导入moviepy库步骤 2:选择视频文件步骤 3:创建VideoFileClip对象步骤 4:提取音频步骤 5:保存音频文件 音频转文字步骤 1:导入SpeechRecognitio…...

阿里云SSL免费证书到期自动申请部署程序
阿里云的免费证书只有3个月的有效期,不注意就过期了,还要手动申请然后部署,很是麻烦,于是写了这个小工具。上班期间抽空写的,没有仔细测试,可能存在一些问题,大家可以自己clone代码改改…...
【进阶版】)
Vue全局事件防止重复点击(等待请求)【进阶版】
继《Vue全局指令防止重复点击(等待请求)》之后,感觉指令方式还是不太友好,而且嵌套闭包比较麻烦,于是想到了Vue的全局混入,利用混入,给组件绑定click事件。 一、实现原理 与指令方式大致一样&…...

Vue3后台管理系统终极指南:V3 Admin Vite 5.0全面解析
Vue3后台管理系统终极指南:V3 Admin Vite 5.0全面解析 【免费下载链接】v3-admin-vite ☀️ A crafted Vue3 admin template | Vue Admin | Vue Template | Vue3 Admin | Vue3 Template | Vue 后台 | Vue 模板 | Vue3 后台 | Vue3 模板 项目地址: https://gitcode…...

FPGA验证核心:Vivado中功能与代码覆盖率的实战指南
1. 项目概述:为什么验证是FPGA开发的重中之重? 如果你刚接触FPGA开发,可能会觉得写代码(HDL)是最核心、最花时间的部分。但等你真正上手几个项目,尤其是那些需要流片或者部署到关键系统的项目后,…...

从仿真到现实:用Unity+ROS2搭建激光雷达小车,为实体机器人开发做预演
从仿真到现实:用UnityROS2搭建激光雷达小车,为实体机器人开发做预演 在机器人开发领域,仿真环境正逐渐成为不可或缺的工具。想象一下,你可以在不购买任何硬件的情况下,验证复杂的导航算法;或者在投入大量资…...

观察Taotoken用量看板如何清晰展示各项目与模型的Token消耗明细
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken用量看板如何清晰展示各项目与模型的Token消耗明细 对于依赖大模型API进行开发的团队而言,成本透明与资源…...

微信好友关系检测工具完整指南:如何快速发现谁删除了你
微信好友关系检测工具完整指南:如何快速发现谁删除了你 【免费下载链接】WechatRealFriends 微信好友关系一键检测,基于微信ipad协议,看看有没有朋友偷偷删掉或者拉黑你 项目地址: https://gitcode.com/gh_mirrors/we/WechatRealFriends …...

好想来万店扩张背后的数据新底座
在中国量贩零食行业的版图上,好想来正以雷霆之势重塑市场格局。作为万辰集团旗下的头部品牌,好想来已在全国布局超过 1.5 万家门店,注册会员超过 1.5 亿,年营收突破 365 亿元,成为名副其实的零售巨擘。这些令人瞩目的数…...

测试09测试09测试09测试09测试09
测试09测试09测试09测试09测试09...

【亲测免费】 VisionPro培训文档全中文版
VisionPro培训文档全中文版 【下载地址】VisionPro培训文档全中文版 VisionPro培训文档全中文版欢迎使用VisionPro培训文档全中文版!本资源是专为机器视觉领域从业者及学习者精心准备的一套全面指南,旨在帮助您快速掌握VisionPro软件的强大功能与应用技巧…...
)
Labelme版本不兼容报错?手把手教你修改源码和JSON文件(附3.18.0与4.5.6对比)
Labelme版本兼容性实战:从源码修改到JSON批量处理的完整指南 当你正专注于一个重要的数据标注项目,突然遭遇"Error opening file lineColor"的红色报错框,整个团队的标注进度被迫停滞——这种场景对于使用Labelme进行图像标注的开发…...

利用模型广场为你的智能客服场景挑选合适模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用模型广场为你的智能客服场景挑选合适模型 智能客服是当前许多应用接入大模型的核心场景之一。开发者需要根据业务对响应速度、…...