大型语言模型的语义搜索(一):关键词搜索

关键词搜索(Keyword Search)是文本搜索种一种常用的技术,很多知名的应用app比如Spotify、YouTube 或 Google map等都会使用关键词搜索的算法来实现用户的搜索任务,关键词搜索是构建搜索系统最常用的方法,最常用的搜索算法是Okapi BM25,简称BM25。在信息检索中,Okapi BM25(BM是最佳匹配的缩写)是搜索引擎用来估计文档与给定搜索查询的相关性的排名函数。它基于Stephen E. Robertson、Karen Spärck Jones等人 在 20 世纪 70 年代和 80 年代开发的概率检索框架。今天我们会教大家使用Cohere的API来调用BM25算法搜索维基百科的数据库。
一、环境配置
我们需要安装如下的python包:
pip install cohere
pip install weaviate-client这里简单介绍一下cohere是一家从事大模型应用开发的公司,而weaviate是一个开源的向量数据库,本次实验我们会用到weaviate-client这个包。接下来我们需要导入一些基础配置,这些基础配置主要包含cohere和weaviate的相关的api_key:
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file接下来我们来创建一个weaviate的client,它将会允许我们连接一个在线数据库。
import weaviate#创weaviate建验证配置
auth_config = weaviate.auth.AuthApiKey(api_key=os.environ['WEAVIATE_API_KEY'])#创建weaviate client
client = weaviate.Client(url=os.environ['WEAVIATE_API_URL'],auth_client_secret=auth_config,additional_headers={"X-Cohere-Api-Key": os.environ['COHERE_API_KEY'],}
)#测试client连接
client.is_ready() 这里需要说明的是Weaviate 是一个开源的向量数据库。 它具有关键字搜索功能,同时还具有基于大语言模型(LLM)的向量搜索功能。 我们在这里使用的 API key是公共的,它是公共Demo的一部分,因此它是公开的,您可以使用它通过一个url地址来访问在线Demo数据库。 另外需要说明的是这个在线数据库是一个公共数据库,包含1000万条自维基百科的数据记录。数据库中的每一行记录表示维基百科文章的一个段落。这 1000 万条记录来自 10 种不同的语言。 因此,其中一百万是英语,另外九百万对应其他9种不同语言。 我们在执行查询时可以设置不同的语言。这种语言包括:en, de, fr, es, it, ja, ar, zh, ko, hi
二、关于API KEY
这里我们会用到3个配置参数:COHERE_API_KEY、 WEAVIATE_API_KEY、WEAVIATE_API_URL。其中COHERE_API_KEY我们需要去cohere的网站自己注册一个cohere账号然后自己创建一个自己的api_key, 而WEAVIATE_API_KEY和WEAVIATE_API_URL我们使用的是对外公开的api_key和url":
- weaviate_api_key: "76320a90-53d8-42bc-b41d-678647c6672e"
- weaviate_api_url: "https://cohere-demo.weaviate.network/"
三、关键词搜索(keyword Search)
Keyword Search在基本原理是它会比较问题和文档中的相同词汇的数量,从而找出和问题最相关的文档,如下图所示:

在上图中Query表示用户的问题,而Responses表示根据问题检索到的结果,Number of words in common表示query和responses中出现重复单词的数量,在这个例子中我们的问题是:“what color is the grass?” 与结果中第二个结果 “The grass is green” 重复的单词数量最多,因此第二个结果是最优的结果。
下面我们来定义一个关键词搜索函数:
def keyword_search(query,results_lang='en',properties = ["title","url","text"],num_results=3):where_filter = {"path": ["lang"],"operator": "Equal","valueString": results_lang}response = (client.query.get("Articles", properties).with_bm25(query=query).with_where(where_filter).with_limit(num_results).do())result = response['data']['Get']['Articles']return result这里在定义keyword_search函数时设置了如下四个参数
- query: 用户的问题
- results_lang:使用的语言,默认使用英语。
- properties :结果的组成结构。
- num_results:结果的数量,默认3个结果。
由于该在在线数据库中的数据由10种不同的语言组成,其中包括:en, de, fr, es, it, ja, ar, zh, ko, hi。因此我们可以在查询时设置不同的语言来进行查询。另外在该函数中我们还指定了BM25算法(“with_bm25”)来实现关键词搜索,下面我们就来使用默认的英文来进行关键词搜索:
query = "Who is Donald Trump?"
keyword_search_results = keyword_search(query)
print(keyword_search_results)
由于上面的多条结果混在一起看上去比较乱,因此我们可以定义一个整理结果的函数:
def print_result(result):""" Print results with colorful formatting """for i,item in enumerate(result):print(f'item {i}')for key in item.keys():print(f"{key}:{item.get(key)}")print()print()print_result(keyword_search_results)
这里我们看到了关键词搜索函数返回了3条包含“Donald Trump”的文档。接下来我们使用中文来进行搜索:
query = "安史之乱"
keyword_search_results = keyword_search(query, results_lang='zh')
print_result(keyword_search_results)
四、关键词搜索基本原理
这里我们需要解释一下该关键词搜索系统的基本原理,这里主要包含了查询(query)和搜索系统(Search System)两个主要的组件,搜索系统可以访问它预先处理过的文档数据,然后响应查询,系统最后为我们提供一个按与问题最相关的文档排序结果列表,如下图所示:

搜索系统(Search System)的内部结构
然而在搜索系统内部包含了2个主要的工作阶段, 第一个阶段通常是检索或搜索阶段,之后还有另一个阶段,称为重新排名即所谓的re-ranking。第一阶段通常使用 BM25 算法对文档集中的文档与问题进行评分,第一阶段检索的实现通常包含倒排索引的思想(inverted index)。第二阶段(re-ranking)则对评分结果进行排序后输出结果,如下图所示:

从上图种我们看到了在倒排序表中包含了2列,第一列时关键词,第二列是该关键词所在的文档的Id. 设计这样的倒排序表主要是为了优化搜索速度。 当您在搜索引擎中输入查询的问题时,系统便能在几毫秒内得到结果。另外在执行搜索任务时关键词对应的文档id出现的频率是评分的重要依据,在上图中的例子中“Color” 在804文档中出现,而“Sky”也在804文档中出现,因此804文档被命中的次数较多,所以会有较高的评分,最后它在检索结果中出现的位置会比较靠前。
五,关键词检索的局限性
我们知道关键词检索并非是根据关键词的语义来检索,而是根据问题和文档中出现的重复单词数量来进行检索,这就会带来一个棘手的问题,那就是如果文档和问题在语义相关,但是它们之间却没有重复的单词,那么就会照成关键词检索无法检索到相关的文档,如下图所示:

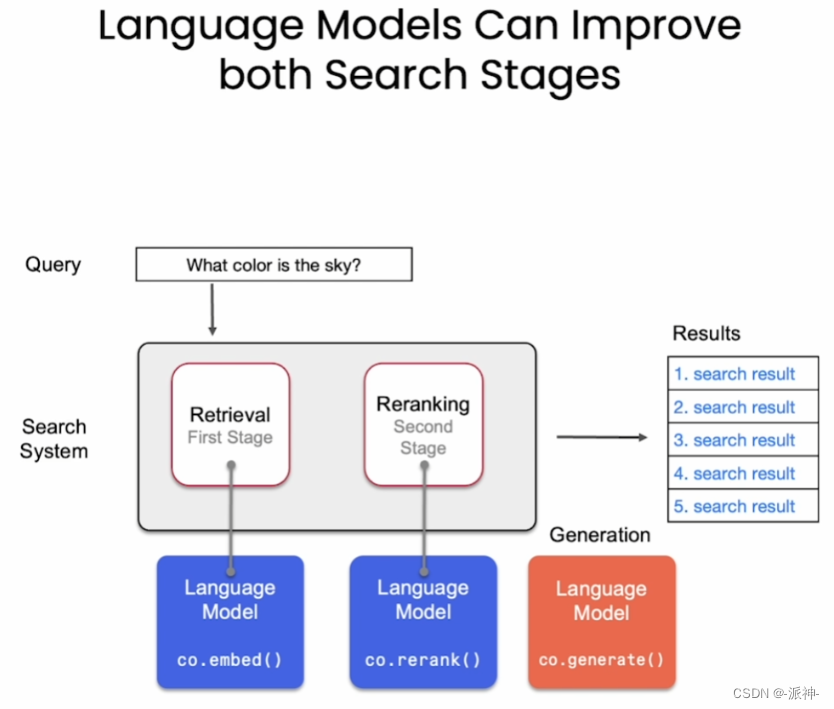
当文档与问题在语义上相关,但它们之间又没有出现重复词汇,此时关键词检索将会失效,它将无法检索到相关文档,当遇到这种情况时则需要借助语言模型来通过语义识别来进行检索。后续我们将会借助语言模型来改进关键词搜索的两个阶段,如下图所示:
参考资料
The Cohere Platform
Home | Weaviate - Vector Database
https://en.wikipedia.org/wiki/Okapi_BM25
相关文章:
大型语言模型的语义搜索(一):关键词搜索
关键词搜索(Keyword Search)是文本搜索种一种常用的技术,很多知名的应用app比如Spotify、YouTube 或 Google map等都会使用关键词搜索的算法来实现用户的搜索任务,关键词搜索是构建搜索系统最常用的方法,最常用的搜索算法是Okapi BM25&#x…...

无需统考可获双证的中国社科院-美国杜兰大学金融硕士
无需统考可获双证的中国社科院-美国杜兰大学金融硕士 中国社会科学院作为党和国家的思想库、智囊团,一直致力于金融财经领域政策的研究和咨询工作,在这个方面我们已经形成了深厚的积累。通过长期的研究和实践,我们能够深刻感受中国金融人才培…...

编程笔记 Golang基础 024 映射
编程笔记 Golang基础 024 映射 一、映射二、映射的定义与初始化三、基本操作四、综合示例程序 Go语言中的映射(map)是一种关联数组或哈希表数据结构,它存储键值对,其中每个键都是唯一的。在Go中,你可以使用 map[keyTy…...
基于springboot+vue的中小型医院网站(前后端分离)
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、阿里云专家博主、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战,欢迎高校老师\讲师\同行交流合作 主要内容:毕业设计(Javaweb项目|小程序|Pyt…...

Spring boot 实现监听 Redis key 失效事件
一. 开启Redis key过期提醒 方式一:修改配置文件 redis.conf # 默认 notify-keyspace-events "" notify-keyspace-events Ex方式二:命令行开启 CONFIG SET notify-keyspace-events Ex CONFIG GET notify-keyspace-events二. notify-keyspace-e…...

振动样品磁强计
振动样品磁强计是基于电磁感应原理的高灵敏度磁矩测量仪。检测线圈中的振动产生的感应电压与样品的磁矩,振幅和振动频率成正比。在确保振幅和振动频率的不便的基础上,使用锁相放大器测量该电压,然后可以计算出待测样品的磁矩。 振动样品磁强计…...

C语言标准库介绍:<string.h>
在C语言中,<string.h>头文件是标准库中的一个重要部分,它定义了一系列操作字符串和字符数组的函数。本文将详细介绍<string.h>头文件中包含的22个函数,并提供每个函数的完整示例代码。 简介 <string.h>头文件定义了一个变…...

大语言模型LangChain本地知识库:向量数据库与文件处理技术的深度整合
文章目录 大语言模型LangChain本地知识库:向量数据库与文件处理技术的深度整合引言向量数据库在LangChain知识库中的应用文件处理技术在知识库中的角色向量数据库与文件处理技术的整合实践挑战与展望结论 大语言模型LangChain本地知识库:向量数据库与文件…...

展厅设计中都包含哪些分区与展示内容
1、欢迎区 欢迎区是展厅的入口处,通常展示企业品牌、企业标志和企业形象等内容。这个区域通常会有一个欢迎台,展示企业的宣传片、简介和最新资讯等。 2、产品展示区 产品展示区是展示企业产品的区域,展示的产品包括企业主营产品、新产品和重点…...
【k8s核心概念与专业术语】
k8s架构 1、服务的分类 服务分类按如下图根据数据服务支撑,分为无状态和有状态 无状态引用如下所示,如果一个nginx服务,删除后重新部署有可以访问,这个属于无状态,不涉及到数据存储。 有状态服务,如redis&a…...
【stm32】hal库学习笔记-UART/USART串口通信(超详细!)
【stm32】hal库学习笔记-UART/USART串口通信 hal库驱动函数 CubeMX图形化配置 导入LCD.ioc RTC设置 时钟树配置 设置LSE为RTC时钟源 USART设置 中断设置 程序编写 编写主函数 /* USER CODE BEGIN 2 */lcd_init();lcd_show_str(10, 10, 16, "Demo12_1:USART1-CH340&q…...
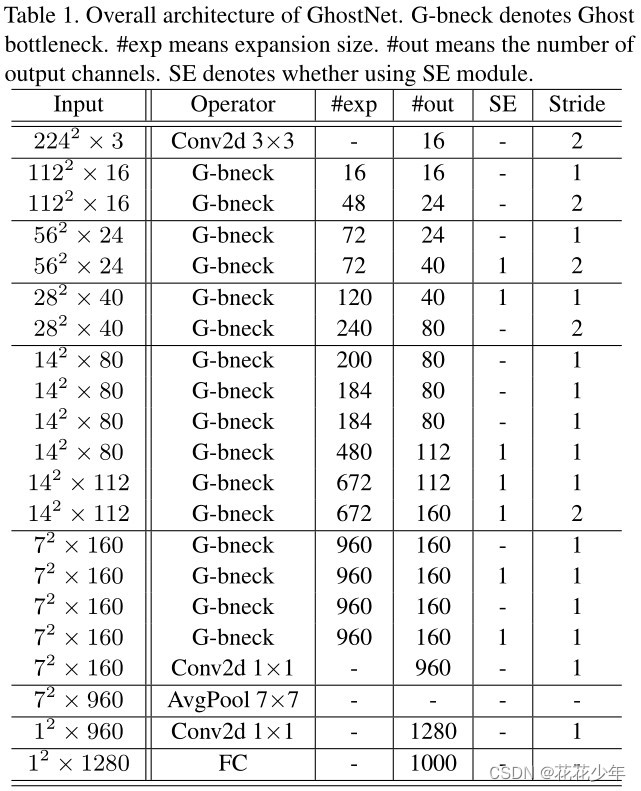
通俗易懂理解GhostNetV1轻量级神经网络模型
一、参考资料 原始论文:[1] PyTorch代码链接:Efficient-AI-Backbones MindSpore代码:ghostnet_d 解读模型压缩5:减少冗余特征的Ghost模块:华为Ghost网络系列解读 GhostNet论文解析:Ghost Module CVPR…...
P8630 [蓝桥杯 2015 国 B] 密文搜索
P8630 [蓝桥杯 2015 国 B] 密文搜索 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)https://www.luogu.com.cn/problem/P8630 题目分析 基本上是hash的板子,但实际上对于密码串,只要判断主串中任意连续的八个位置是否存在密码串即可;那么我们…...

Electron实战之环境搭建
工欲善其事必先利其器,在进行实战开发的时候,我们最终的步骤是搞好一个舒服的开发环境,目前支持 Vue 的 Electron 工程化工具主要有 electron-vue、Vue CLI Plugin Electron Builder、electron-vite。 接下来我们将分别介绍基于 Vue CLI Plu…...

【0259】inval.h/inval.c的理解
1. inval.h/inval.c inval.h、inval.c是缓存无效消息(invalidation message)调度程序定义。 2. inval.h/inval.c特性 inval.h/inval.c的实现是一个非常微妙的东西,所以需要注意: 当一个元组被更新或删除时,我们的标准可见性规则(standard visibility rules)认为只要我…...

力扣爆刷第77天--动态规划一网打尽打家劫舍问题
力扣爆刷第77天–动态规划一网打尽打家劫舍问题 文章目录 力扣爆刷第77天--动态规划一网打尽打家劫舍问题一、198.打家劫舍二、213.打家劫舍II三、337.打家劫舍 III 一、198.打家劫舍 题目链接:https://leetcode.cn/problems/house-robber/ 思路:小偷不…...

深入理解C语言(5):程序环境和预处理详解
文章主题:程序环境和预处理详解🌏所属专栏:深入理解C语言📔作者简介:更新有关深入理解C语言知识的博主一枚,记录分享自己对C语言的深入解读。😆个人主页:[₽]的个人主页🏄…...
ESP8266智能家居(3)——单片机数据发送到mqtt服务器
1.主要思想 前期已学习如何用ESP8266连接WIFI,并发送数据到服务器。现在只需要在单片机与nodeMCU之间建立起串口通信,这样单片机就可以将传感器测到的数据:光照,温度,湿度等等传递给8266了,然后8266再对数据…...
—— 筑梦之路)
lvm逻辑卷创建raid阵列(不常用)—— 筑梦之路
RAID卷介绍 逻辑卷管理器(LVM)不仅仅可以将多个磁盘和分区聚合到一个逻辑卷中,以此提高单个分区的存储容量,还可以创建和管理独立磁盘的冗余阵列(RAID)卷,防止磁盘故障并提高性能。它支持常用的RAID级别,支持的RAID的级别有 0、1…...

LayUI发送Ajax请求
页面初始化操作 var processData null $(function () {initView();initTable();// test(); })function initView() {layui.use([laydate, form], function () {var laydate layui.laydate;laydate.render({elem: #applyDateTimeRange,type: datetime,range: true});}); }初始…...

Cursor + Claude Code 双栈协作:3 种项目级配置同步方案落地实录
1. 项目级配置同步不是“配完就跑”,而是让 AI 真正理解你的项目语义 大多数人把 Cursor + Claude Code 当成一个“更聪明的自动补全”,装完插件、填个 API Key、点几下设置,就以为双栈协作完成了。我试过三个不同规模的项目——一个 2000 行的 Python 数据处理脚本集、一个…...

【免费下载】 探索高效Excel处理:OpenXLSX C++读写Excel表格示例项目推荐
探索高效Excel处理:OpenXLSX C读写Excel表格示例项目推荐 项目介绍 在现代软件开发中,处理Excel文件的需求日益增长,尤其是在数据分析、报告生成和企业级应用中。为了满足这一需求,我们推出了OpenXLSX C读写Excel表格示例项目。该…...

OpCore-Simplify:30分钟完成专业级黑苹果配置的终极指南
OpCore-Simplify:30分钟完成专业级黑苹果配置的终极指南 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为复杂的黑苹果配置而烦恼吗&…...
)
仅限专业影像团队内部流通的Perplexity摄影搜索矩阵(含ISO/快门/色温等8维结构化Prompt库)
更多请点击: https://codechina.net 第一章:Perplexity摄影技巧搜索的底层逻辑与架构设计 Perplexity 并非专为摄影设计的工具,但其搜索系统在处理“摄影技巧”类长尾、意图模糊、多模态关联的问题时,展现出独特的推理架构特征。…...

OpenRGB技术架构深度解析:如何用开源统一协议打破RGB生态壁垒
OpenRGB技术架构深度解析:如何用开源统一协议打破RGB生态壁垒 【免费下载链接】OpenRGB Open source RGB lighting control that doesnt depend on manufacturer software. Supports Windows, Linux, MacOS. Mirror of https://gitlab.com/CalcProgrammer1/OpenRGB.…...

3个必知技巧:快速掌握Meshroom三维重建核心
3个必知技巧:快速掌握Meshroom三维重建核心 【免费下载链接】Meshroom Node-based Visual Programming Toolbox 项目地址: https://gitcode.com/gh_mirrors/me/Meshroom Meshroom是一款基于节点化视觉编程的开源三维重建软件,它能将你的照片和视频…...

TC2526 低功耗原边反馈开关电源芯片
概述 TC2526 是一款低功耗原边反馈(PSR)开关电源芯片,其内部集成了大功率 BJT 管,适用于隔离型的高效低功耗便携式设备充电器应用。TC2526 采用独特具有恒流恒压功能的原边反馈控制技术,以及独特的轻载调频技术降低轻载…...
)
从‘黑盒子’到清晰电路:用替代定理‘破译’未知网络N的VCR(图解+方程双解法)
从‘黑盒子’到清晰电路:用替代定理‘破译’未知网络N的VCR(图解方程双解法) 在电子工程实践中,工程师们常常会遇到一种令人头疼的"黑盒子"——那些内部结构不明、数据手册不全的电路模块。面对这样的未知网络ÿ…...

5分钟掌握ncmdumpGUI:将网易云ncm文件转换为MP3的完整解决方案
5分钟掌握ncmdumpGUI:将网易云ncm文件转换为MP3的完整解决方案 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾为网易云音乐下载的ncm文件…...

深度解析Windows Subsystem for Android:企业级跨平台运行时架构与最佳实践
深度解析Windows Subsystem for Android:企业级跨平台运行时架构与最佳实践 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA Windows Subsystem f…...