XTuner InternLM-Chat 个人小助手认知微调实践
要解决的问题:
如何让模型知道自己做什么,是什么样身份。是谁创建了他!!!
概述
目标:通过微调,帮助模型认清了解对自己身份弟位
方式:使用XTuner进行微调
微调前(回答比较官方)
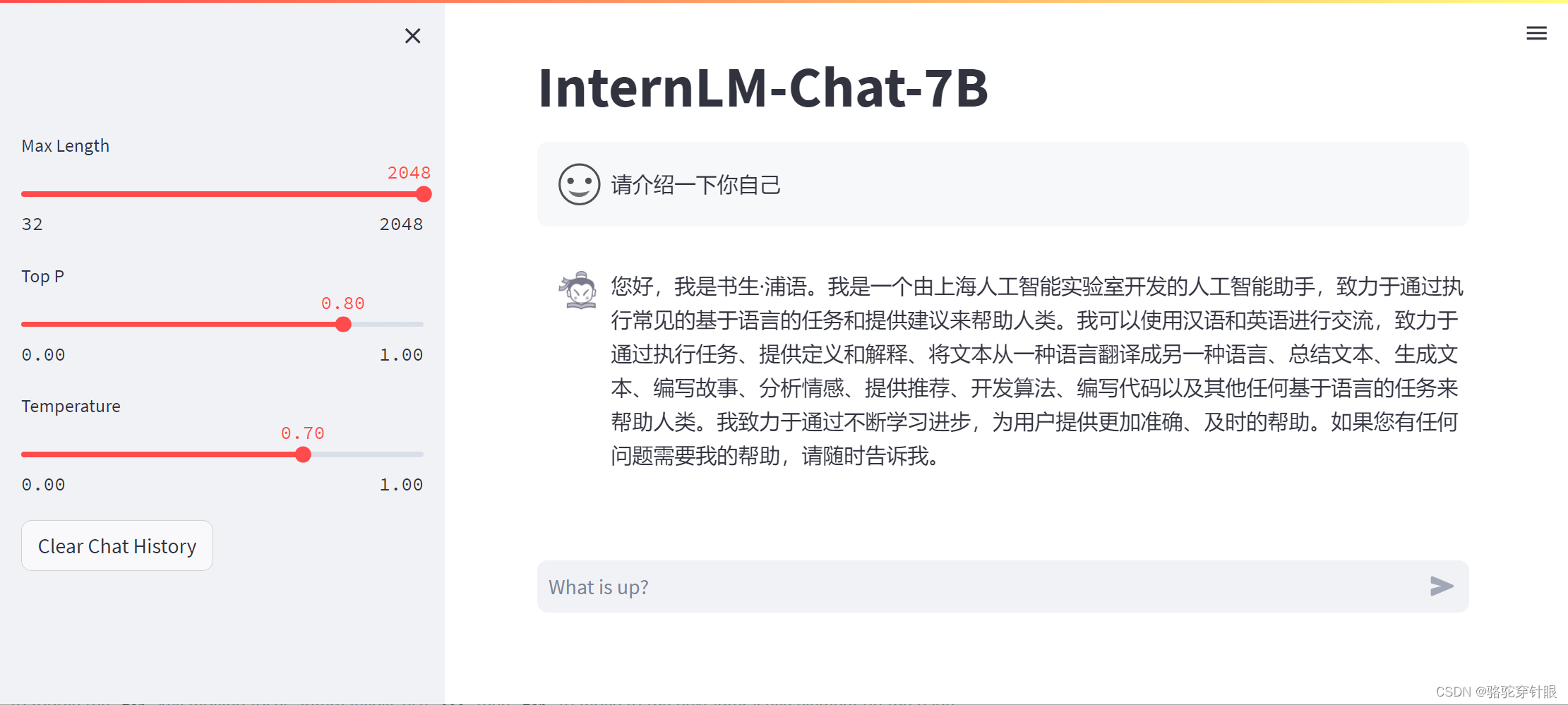
微调后(对自己的身份有了清晰的认知)
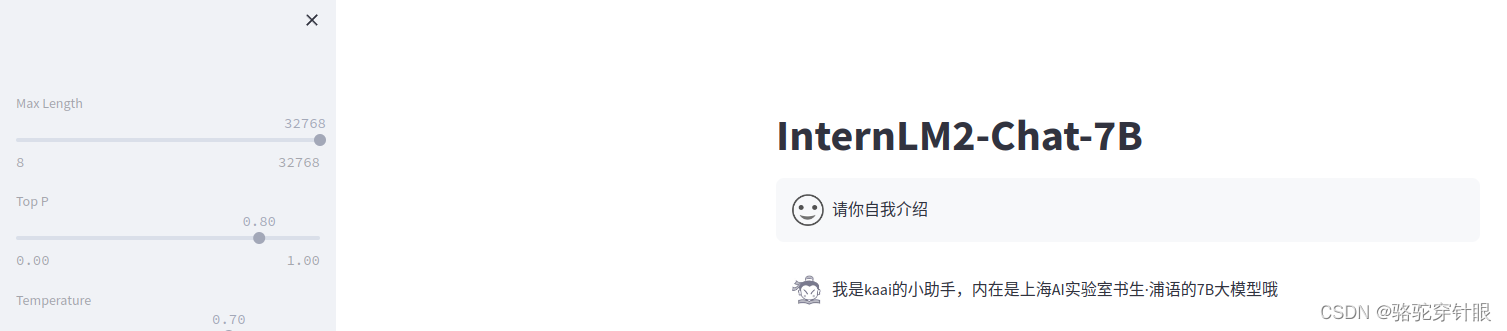
实操
# 创建自己的环境
conda create --name personal_assistant python=3.10 -y# 激活环境
conda activate personal_assistant
# 进入家目录 (~的意思是 “当前用户的home路径”)
cd ~
# 创建版本文件夹并进入,以跟随本教程
# personal_assistant用于存放本教程所使用的东西
mkdir /root/personal_assistant && cd /root/personal_assistant
mkdir /root/personal_assistant/xtuner019 && cd /root/personal_assistant/xtuner019# 拉取 0.1.9 的版本源码
git clone -b v0.1.9 https://github.com/InternLM/xtuner
# 无法访问github的用户请从 gitee 拉取:
# git clone -b v0.1.9 https://gitee.com/Internlm/xtuner# 进入源码目录
cd xtuner# 从源码安装 XTuner
pip install -e '.[all]'
数据准备
创建data文件夹用于存放用于训练的数据集
mkdir -p /root/personal_assistant/data && cd /root/personal_assistant/data
在data目录下创建一个json文件personal_assistant.json作为本次微调所使用的数据集。json中内容可参考下方(复制粘贴n次做数据增广,数据量小无法有效微调,下面仅用于展示格式,下面也有生成脚本)
其中conversation表示一次对话的内容,input为输入,即用户会问的问题,output为输出,即想要模型回答的答案
[{"conversation": [{"input": "请介绍一下你自己","output": "我是kaai的小助手,内在是上海AI实验室书生·浦语的7B大模型哦"}]},{"conversation": [{"input": "请做一下自我介绍","output": "我是kaai的小助手,内在是上海AI实验室书生·浦语的7B大模型哦"}]}
]
以下是一个python脚本,用于生成数据集。在data目录下新建一个generate_data.py文件,将以下代码复制进去,然后运行该脚本即可生成数据集。
import json# 输入你的名字
name = 'kaai'
# 重复次数
n = 10000# 创建初始问答数据
qa_data = [{"conversation": [{"input": "请介绍一下你自己","output": f"我是{name}的小助手,内在是上海AI实验室书生·浦语的7B大模型哦"}]},{"conversation": [{"input": "请做一下自我介绍","output": f"我是{name}的小助手,内在是上海AI实验室书生·浦语的7B大模型哦"}]}
]# 将生成的问答数据保存到JSON文件中
file_path = './qa_data_repeated.json'with open(file_path, 'w', encoding='utf-8') as file:# 使用json.dump直接写入文件,而不是先创建一个大的字符串json.dump(qa_data * n, file, ensure_ascii=False, indent=4)
下载模型InternLM-chat-7B、
Hugging Face
使用 Hugging Face 官方提供的 huggingface-cli 命令行工具。安装依赖:
pip install -U huggingface_hub
然后新建 python 文件,填入以下代码,运行即可。
- resume-download:断点续下
- local-dir:本地存储路径。(linux 环境下需要填写绝对路径)
import os# 下载模型
os.system('huggingface-cli download --resume-download internlm/internlm-chat-7b --local-dir your_path')
XTuner 提供多个开箱即用的配置文件,用户可以通过下列命令查看:
# 列出所有内置配置
xtuner list-cfg
#创建用于存放配置的文件夹config并进入
mkdir /root/personal_assistant/config && cd /root/personal_assistant/config
拷贝一个配置文件到当前目录:xtuner copy-cfg ${CONFIG_NAME} ${SAVE_PATH} 在本例中:(注意最后有个英文句号,代表复制到当前路径)
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .
修改拷贝后的文件internlm_chat_7b_qlora_oasst1_e3_copy.py,修改下述位置: (这是一份修改好的文件internlm_chat_7b_qlora_oasst1_e3_copy.py)
主要改模型的位置同时一些超参数
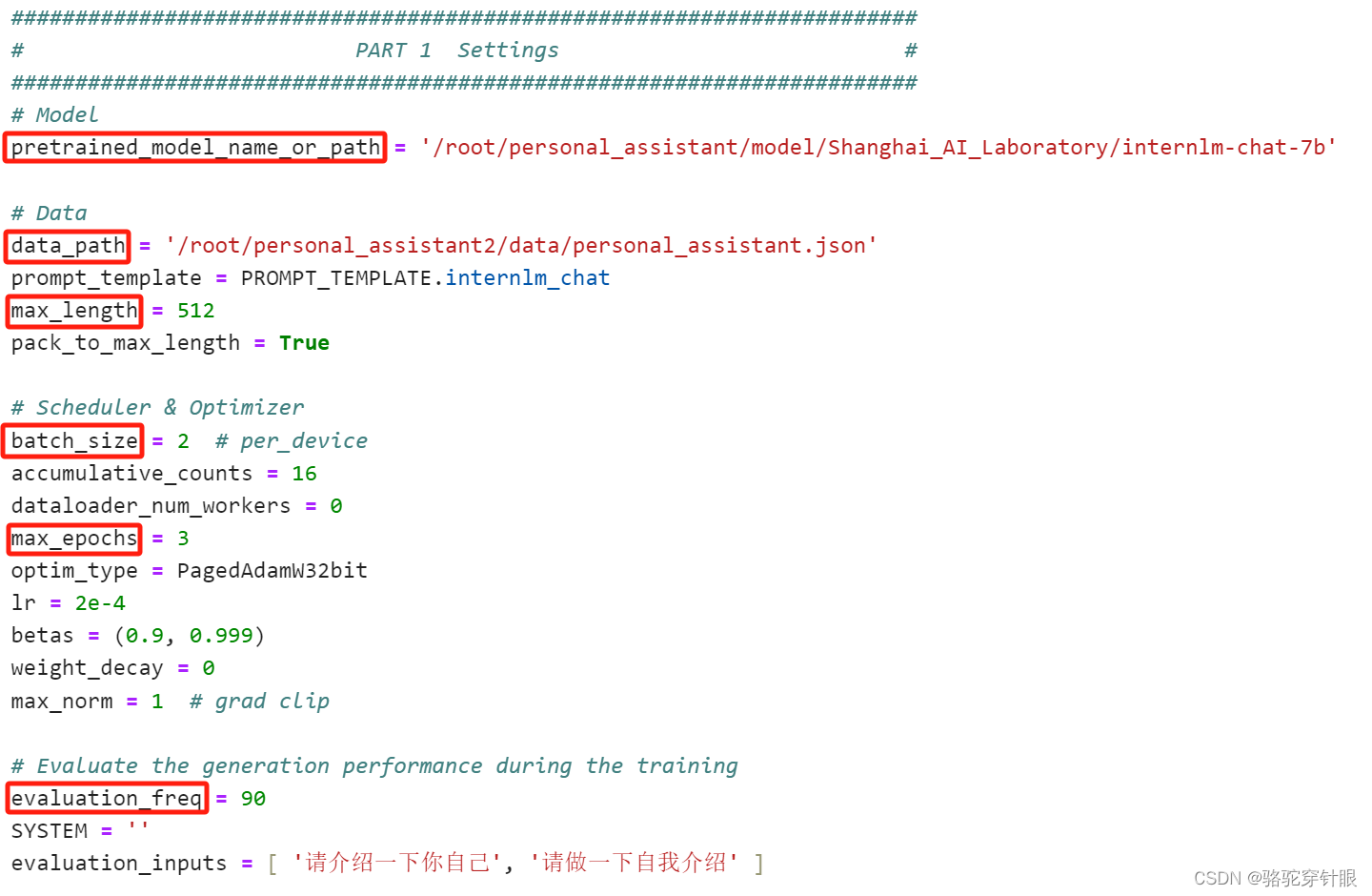
具体的内容
# PART 1 中
# 预训练模型存放的位置
pretrained_model_name_or_path = '/root/personal_assistant/model/Shanghai_AI_Laboratory/internlm-chat-7b'# 微调数据存放的位置
data_path = '/root/personal_assistant/data/personal_assistant.json'# 训练中最大的文本长度
max_length = 512# 每一批训练样本的大小
batch_size = 2# 最大训练轮数
max_epochs = 3# 验证的频率
evaluation_freq = 90# 用于评估输出内容的问题(用于评估的问题尽量与数据集的question保持一致)
evaluation_inputs = [ '请介绍一下你自己', '请做一下自我介绍' ]# PART 3 中
dataset=dict(type=load_dataset, path='json', data_files=dict(train=data_path))
dataset_map_fn=None
微调启动
xtuner train /root/personal_assistant/config/internlm_chat_7b_qlora_oasst1_e3_copy.py
微调后参数转换/合并
# 创建用于存放Hugging Face格式参数的hf文件夹
mkdir /root/personal_assistant/config/work_dirs/hfexport MKL_SERVICE_FORCE_INTEL=1# 配置文件存放的位置
export CONFIG_NAME_OR_PATH=/root/personal_assistant/config/internlm_chat_7b_qlora_oasst1_e3_copy.py# 模型训练后得到的pth格式参数存放的位置
export PTH=/root/personal_assistant/config/work_dirs/internlm_chat_7b_qlora_oasst1_e3_copy/epoch_3.pth# pth文件转换为Hugging Face格式后参数存放的位置
export SAVE_PATH=/root/personal_assistant/config/work_dirs/hf# 执行参数转换
xtuner convert pth_to_hf $CONFIG_NAME_OR_PATH $PTH $SAVE_PATH
Merge模型参数
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER='GNU'# 原始模型参数存放的位置
export NAME_OR_PATH_TO_LLM=/root/personal_assistant/model/Shanghai_AI_Laboratory/internlm-chat-7b# Hugging Face格式参数存放的位置
export NAME_OR_PATH_TO_ADAPTER=/root/personal_assistant/config/work_dirs/hf# 最终Merge后的参数存放的位置
mkdir /root/personal_assistant/config/work_dirs/hf_merge
export SAVE_PATH=/root/personal_assistant/config/work_dirs/hf_merge# 执行参数Merge
xtuner convert merge \$NAME_OR_PATH_TO_LLM \$NAME_OR_PATH_TO_ADAPTER \$SAVE_PATH \--max-shard-size 2GB
网页DEMO
安装网页Demo所需依赖
pip install streamlit==1.24.0
下载demo代码
# 创建code文件夹用于存放InternLM项目代码
mkdir /root/personal_assistant/code && cd /root/personal_assistant/code
git clone https://github.com/InternLM/InternLM.git
修改代码
/mnt/xtuner/xtuner019/personal_assistant/code/InternLM/chat/web_demo.py
@st.cache_resource
def load_model():model = (AutoModelForCausalLM.from_pretrained('/mnt/xtuner/xtuner019/personal_assistant/merge',trust_remote_code=True).to(torch.bfloat16).cuda())tokenizer = AutoTokenizer.from_pretrained('/mnt/xtuner/xtuner019/personal_assistant/merge',trust_remote_code=True)return model, tokenizer运行
streamlit run web_demo.py --server.address 127.0.0.1 --server.port 6006
效果
微调前
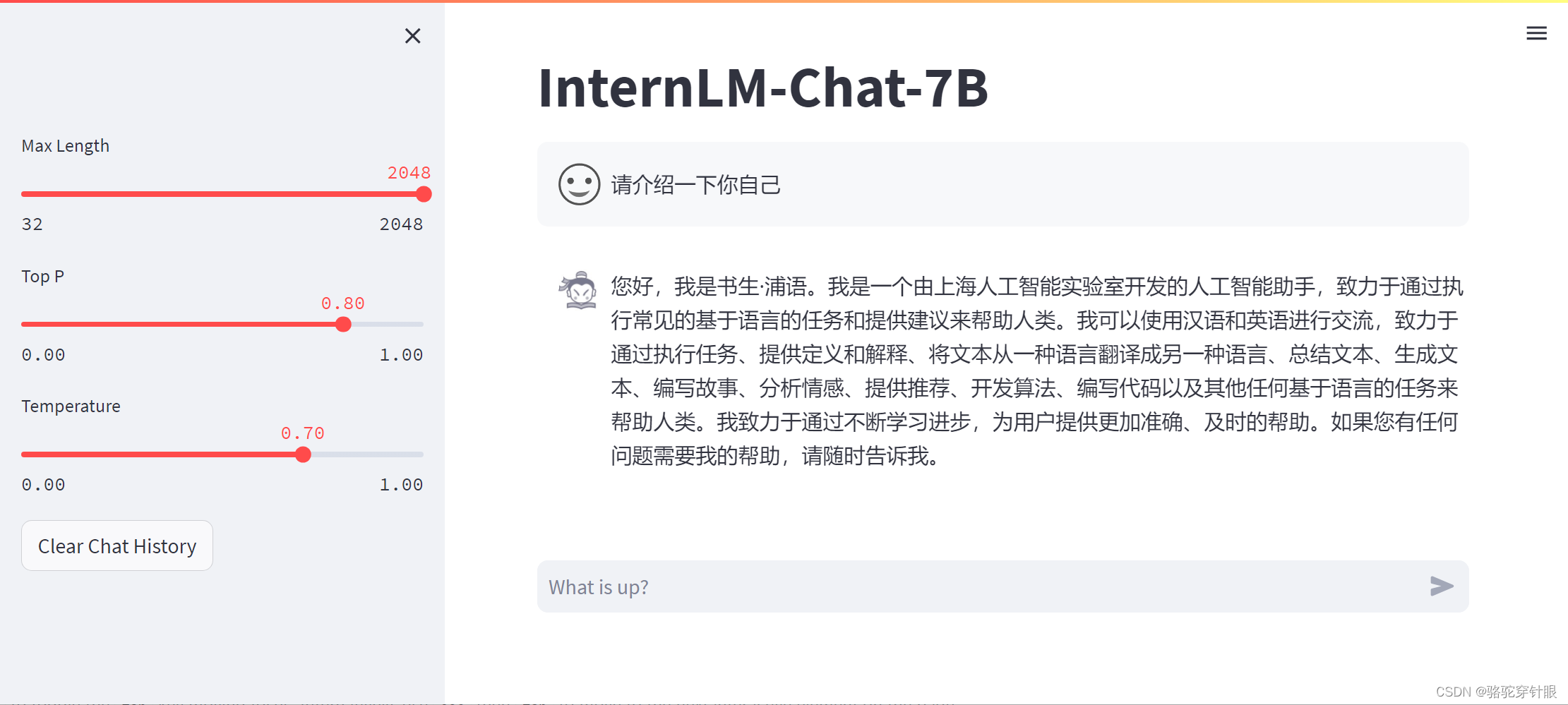
微调后(对自己的身份有了清晰的认知)
你的路径应该如下
├── code
│ └── InternLM
│ ├── agent
│ │ ├── lagent.md
│ │ ├── lagent_zh-CN.md
│ │ ├── pal_inference.md
│ │ ├── pal_inference.py
│ │ ├── pal_inference_zh-CN.md
│ │ ├── README.md
│ │ └── README_zh-CN.md
│ ├── assets
│ │ ├── compass_support.svg
│ │ ├── license.svg
│ │ ├── logo.svg
│ │ ├── modelscope_logo.png
│ │ ├── robot.png
│ │ └── user.png
│ ├── chat
│ │ ├── chat_format.md
│ │ ├── chat_format_zh-CN.md
│ │ ├── lmdeploy.md
│ │ ├── lmdeploy_zh_cn.md
│ │ ├── openaoe.md
│ │ ├── openaoe_zh_cn.md
│ │ ├── react_web_demo.py
│ │ ├── README.md
│ │ ├── README_zh-CN.md
│ │ └── web_demo.py
│ ├── finetune
│ │ ├── README.md
│ │ └── README_zh-CN.md
│ ├── LICENSE
│ ├── model_cards
│ │ ├── internlm_20b.md
│ │ ├── internlm2_1.8b.md
│ │ ├── internlm2_20b.md
│ │ ├── internlm2_7b.md
│ │ └── internlm_7b.md
│ ├── README.md
│ ├── README_zh-CN.md
│ ├── requirements.txt
│ ├── sonar-project.properties
│ ├── tests
│ │ └── test_hf_model.py
│ └── tools
│ ├── convert2llama.py
│ └── README.md
├── config
│ ├── internlm_chat_7b_qlora_oasst1_e3_copy.py
│ └── work_dirs
│ └── internlm_chat_7b_qlora_oasst1_e3_copy
│ ├── 20240223_160926
│ │ ├── 20240223_160926.log
│ │ └── vis_data
│ │ └── config.py
│ ├── 20240223_161009
│ │ ├── 20240223_161009.log
│ │ └── vis_data
│ │ └── config.py
│ ├── 20240223_161051
│ │ ├── 20240223_161051.log
│ │ └── vis_data
│ │ ├── 20240223_161051.json
│ │ ├── config.py
│ │ └── scalars.json
│ ├── epoch_1.pth
│ ├── epoch_2.pth
│ ├── epoch_3.pth
│ ├── internlm_chat_7b_qlora_oasst1_e3_copy.py
│ └── last_checkpoint
├── data
│ ├── data.py
│ ├── data_QA.py
│ └── personal_assistant.json
├── hf
│ ├── adapter_config.json
│ ├── adapter_model.safetensors
│ ├── README.md
│ └── xtuner_config.py
├── internlm-chat-7b
│ ├── config.json
│ ├── configuration_internlm.py
│ ├── configuration.json
│ ├── generation_config.json
│ ├── modeling_internlm.py
│ ├── pytorch_model-00001-of-00008.bin
│ ├── pytorch_model-00002-of-00008.bin
│ ├── pytorch_model-00003-of-00008.bin
│ ├── pytorch_model-00004-of-00008.bin
│ ├── pytorch_model-00005-of-00008.bin
│ ├── pytorch_model-00006-of-00008.bin
│ ├── pytorch_model-00007-of-00008.bin
│ ├── pytorch_model-00008-of-00008.bin
│ ├── pytorch_model.bin.index.json
│ ├── README.md
│ ├── special_tokens_map.json
│ ├── tokenization_internlm.py
│ ├── tokenizer_config.json
│ └── tokenizer.model
└── merge├── added_tokens.json├── config.json├── configuration_internlm.py├── generation_config.json├── modeling_internlm.py├── pytorch_model-00001-of-00008.bin├── pytorch_model-00002-of-00008.bin├── pytorch_model-00003-of-00008.bin├── pytorch_model-00004-of-00008.bin├── pytorch_model-00005-of-00008.bin├── pytorch_model-00006-of-00008.bin├── pytorch_model-00007-of-00008.bin├── pytorch_model-00008-of-00008.bin├── pytorch_model.bin.index.json├── special_tokens_map.json├── tokenization_internlm.py├── tokenizer_config.json└── tokenizer.model
github链接
操作指南
相关文章:
XTuner InternLM-Chat 个人小助手认知微调实践
要解决的问题: 如何让模型知道自己做什么,是什么样身份。是谁创建了他!!! 概述 目标:通过微调,帮助模型认清了解对自己身份弟位 方式:使用XTuner进行微调 微调前(回答…...

编程笔记 Golang基础 025 列表
编程笔记 Golang基础 025 列表 一、列表的功能二、示例程序三、注意事项 在 Go 语言中,列表是一种数据结构,用于存储有序的元素集合,允许高效地进行插入和删除操作。Go 标准库中的 container/list 包提供了一个内置的双链表实现,它…...

Rollup + Ts
Rollup Ts RollupTs demo 一、文件配置 | - src | | - utils | | | - .ts | | - .babelrc | | - main.js | | - style.css | - package.json | - rollup.config.js | - tsconfig.json二、插件下载 rollup // rollup 基本的包 typescript // ts 包 rollup/plug…...
5个精美的wordpress中文企业主题模板
元宇宙WordPress主题模板 简洁大气的元宇宙 Metaverse WordPress主题模板,适合元宇宙行业的企业官网使用。 https://www.jianzhanpress.com/?p3292 职业技术培训WordPress主题模板 简洁大气的职业技术培训WordPress主题,适合用于搭建教育培训公司官方…...

【数据分享】2011-2023年我国地级市逐月二手房房价数据(Excel/Shp格式)
房价是一个城市发展程度的重要体现,一个城市的房价越高通常代表这个城市越发达,对于人口的吸引力越大!因此,房价数据是我们在各项城市研究中都非常常用的数据! 本次我们为大家带来的是2011-2023年我国地级市的逐月二手…...

鸿蒙会成为安卓的终结者吗?
随着近期鸿蒙OS系统推送测试版的时间确定,关于鸿蒙系统的讨论再次升温。 作为华为自主研发的操作系统,鸿蒙给人的第一印象是具有颠覆性。 早在几年前,业内就开始流传鸿蒙可能会代替Android的传言。毕竟,Android作为开源系统&…...

Sora横空出世!AI将如何撬动未来?
近日,OpenAI 发布首个视频生成“Sora”模型,该模型通过接收文字指令,即可生成60秒的短视频。 而在2022年末,同样是OpenAI发布的AI语言模型ChatGPT,简化了文本撰写、创意构思以及代码校验等任务。用户仅需输入一个指令&…...

Selenium浏览器自动化测试框架详解
selenium简介 介绍 Selenium [1] 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google C…...

XGB-11:随机森林
XGBoost通常用于训练梯度提升决策树和其他梯度提升模型。随机森林使用与梯度提升决策树相同的模型表示和推断,但使用不同的训练算法。可以使用XGBoost来训练独立的随机森林,或者将随机森林作为梯度提升的基模型。这里我们专注于训练独立的随机森林。 XG…...

超平面介绍
超平面公式 (1) 超平面是指n维线性空间中维度为n-1的子空间。它可以把线性空间分割成不相交的两部分。比如二维空间中,一条直线是一维的,它把平面分成了两部分;三维空间中,一个平面是二维的,它把空间分成了两部分。(2…...
【苍穹外卖】一些开发总结
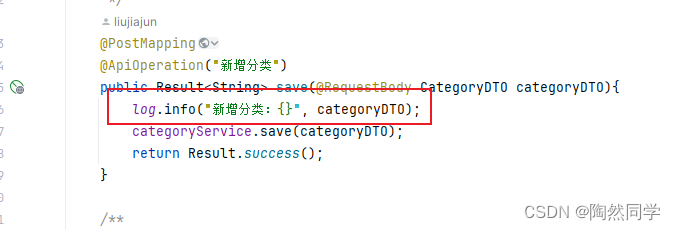
1、DTO、VO的区别 DTO:如果前端返回的实体类和对应的实体类比较较大差别 使用DTO来封装数据 后面在使用 BeanUtils.copyProperties() 将熟悉复制到对应的实体类中 VO:主要用于展示数据,例如在控制器层和视图层之间。它通常包含一些与显示相关的属性,如标题、描述等。 2…...

Python 3 中,`asynchat`异步通信
在 Python 3 中,asynchat 是基于 asyncore 的一个高层抽象模块,用于处理异步通信协议。它提供了一种简单的方式来创建自定义的异步通信协议,并处理通信中的错误和异常。 asynchat 模块主要作用是将网络数据流分割成消息或者数据包࿰…...
RAW 编程接口 TCP 简介
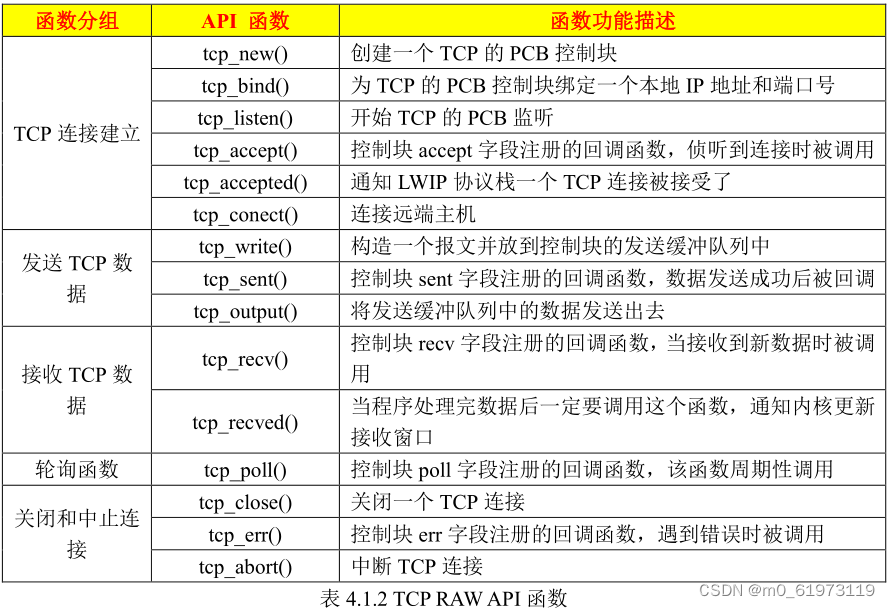
一、LWIP 中 中 RAW API 编程接口中与 TCP 相关的函数 二、LWIP TCP RAW API 函数 三、LwIP_Periodic_Handle函数 LwIP_Periodic_Handle 函数是一个必须被无限循环调用的 LwIP支持函数,一般在 main函数的无限循环中调用,主要功能是为 LwIP各个模块提供…...

Oracle EBS FA折旧回滚的分录追溯
FA模块向子分类账和总账追溯分为两部分:事务表和折旧,但是FA相关表做其实关联计划外折旧的分录会被遗漏的原因: 如果已经当月折旧,运行完成折旧后,又进行了计划外折旧,因为计划折旧时又要区分【是否进行当月…...
sql注入 [极客大挑战 2019]FinalSQL1
打开题目 点击1到5号的结果 1号 2号 3号 4号 5号 这里直接令传入的id6 传入id1^1^1 逻辑符号|会被检测到,而&感觉成了注释符,&之后的内容都被替换掉了。 传入id1|1 直接盲注比较慢,还需要利用二分法来编写脚本 这里利用到大佬的脚…...

持续集成,持续交付和持续部署的概念,以及GitLab CI / CD的介绍
引言:上一期我们部署好了gitlab极狐网页版,今天我们介绍一下GitLabCI / CD 目录 一、为什么要 CI / CD 方法 1、持续集成 2、持续交付 3、持续部署 二、GitLab CI / CD简介 三、GitLab CI / CD 的工作原理 4、基本CI / CD工作流程 5、首次设置 …...
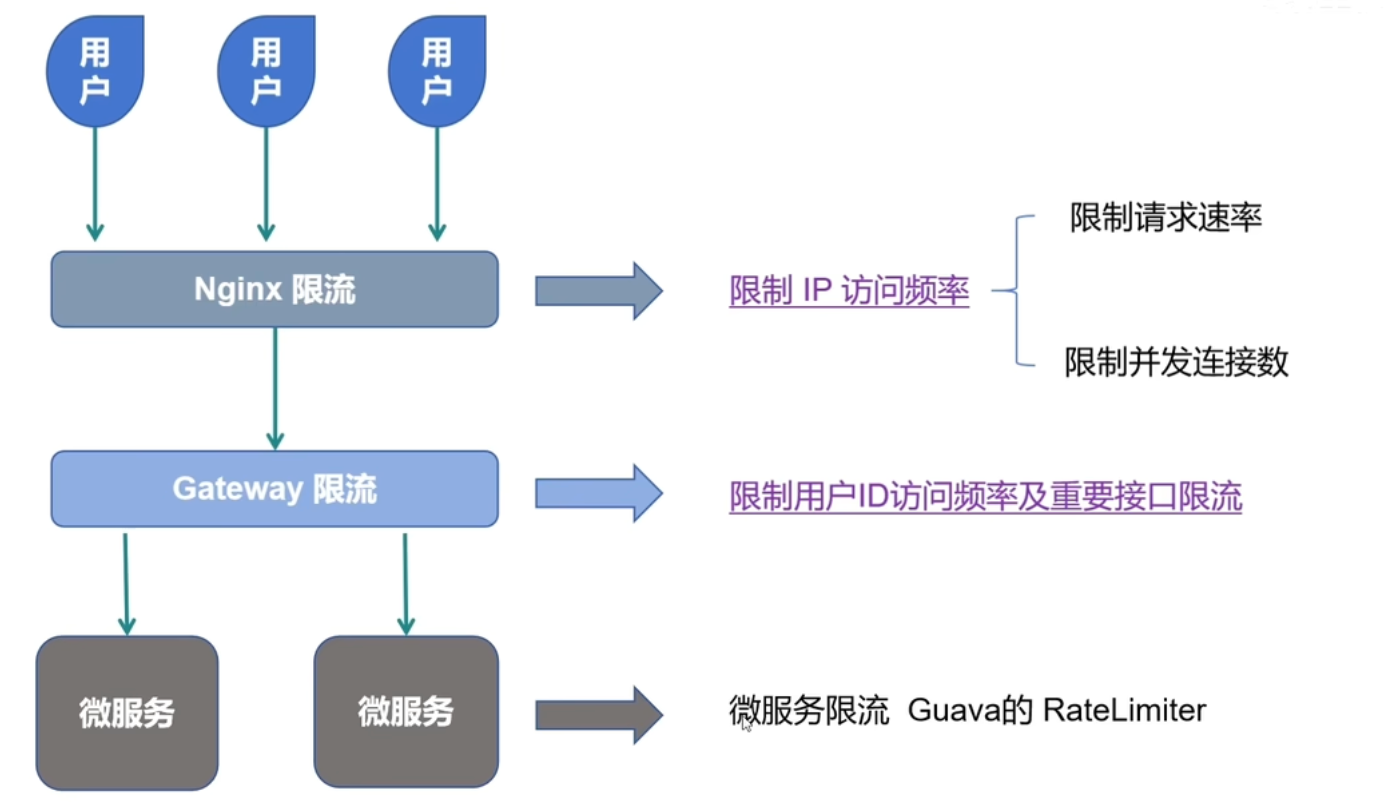
[Java 项目亮点] 三层限流设计
思路来源:bilibili 河北王校长 文章目录 面试官可能会问你能详细介绍一下Nginx的http_limit_req_module模块吗?你能解释一下如何在Nginx中配置http_limit_req_module模块吗?你知道如何调整Nginx的http_limit_req_module模块以适应不同的业务需…...
GPT-SoVITS 快速声音克隆使用案例:webui、api接口
参考: https://github.com/RVC-Boss/GPT-SoVITS 环境: Python 3.10 PyTorch 2.1.2, CUDA 12.0 安装包: 1、使用: 1)下载项目 git clone https://github.com/RVC-Boss/GPT-SoVITS.git2)下载预训练模型 https://huggingface.co/lj1995/GPT-SoVITS 下载模型文件放到GPT…...
系统功能规范)
高速自动驾驶智慧匝道(HIC)系统功能规范
智慧匝道功能规范 Highway Intelligent Change Functional Specification 文件状态: 【√】草稿 【】正式发布 【】正在修改 文件起草分工 撰写: 审核: 编制: 签名: 日期: 审核: 签名&am…...
SQL Server——建表时为字段添加注释
在 MySQL 中,新建数据库表为字段添加注释可以使用 comment 属性来实现。SQL Server 没有 comment 属性,但是可以通过执行 sys.sp_addextendedproperty 这个存储过程添加扩展属性来实现相同的功能。 这个存储过程的参数定义如下: exec sys.s…...

如何免费下载百度文库文档:三步搞定PDF保存的终极指南
如何免费下载百度文库文档:三步搞定PDF保存的终极指南 【免费下载链接】baidu-wenku fetch the document for free 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wenku 你是否经常在百度文库找到完美的学习资料或工作报告,却因为需要下载券…...
)
保姆级教程:在Ubuntu 20.04上从源码编译aarch64-linux-gnu交叉工具链(GCC 9.2.0 + Glibc 2.30)
深度实践:从源码构建aarch64-linux-gnu交叉工具链全指南 在嵌入式开发领域,交叉编译工具链的构建能力是区分普通开发者与资深工程师的重要标志。当现成的预编译工具链无法满足特定需求时,从源码手动构建工具链不仅能解决兼容性问题࿰…...
)
ElevenLabs克隆成功率从31%飙升至96.7%:基于LPC共振峰校准+Prosody Transfer双引擎微调法(实测数据包已脱敏上传)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs语音克隆方法概览 ElevenLabs 提供了高保真、低延迟的语音克隆能力,其核心依赖于少量高质量语音样本(通常 1–3 分钟)与上下文感知的零样本/少样本微调技术…...

Linux磁盘挂载与开机自启配置
Linux磁盘挂载与开机自启配置磁盘挂载是 Linux 存储管理中的基础操作。很多线上问题都与挂载配置有关,例如重启后数据盘没挂上、路径指向错误分区、应用因挂载点缺失而启动失败。中级阶段不仅要会临时挂载,更要理解永久挂载的配置方式和风险控制。一、先…...

Noto Emoji字体架构深度解析:现代表情符号渲染的技术实现与性能优化
Noto Emoji字体架构深度解析:现代表情符号渲染的技术实现与性能优化 【免费下载链接】noto-emoji Noto Emoji fonts 项目地址: https://gitcode.com/gh_mirrors/no/noto-emoji Noto Emoji作为Google开源的表情符号字体库,提供了跨平台的Unicode表…...

RTX 5090功耗传闻解析:600W显卡对PC生态的挑战与应对
1. 项目概述:从一则功耗新闻到显卡生态的深度思考最近,英伟达下一代旗舰显卡RTX 5090的功耗传闻在硬件圈里炸开了锅。消息称其TGP(总图形功耗)可能高达600W,相比RTX 4090的450W,直接激增了150W。这不仅仅是…...

基于ChatGPT与飞书开放平台构建企业级智能聊天机器人实践指南
1. 项目概述:当ChatGPT遇上飞书,打造你的专属智能工作伙伴 最近在折腾一个挺有意思的项目,叫“chatgpt-for-chatbot-feishu”。简单来说,这就是一个桥梁,一个能让OpenAI的ChatGPT模型,直接接入到飞书&…...

CCS8.0 TMS320F28335工程配置实战:从零搭建到Flash固件生成
1. CCS8.0开发环境与TMS320F28335基础认知 第一次接触TMS320F28335这款DSP芯片时,我完全被它复杂的开发环境吓到了。直到后来才发现,只要掌握CCS8.0这个开发工具的基本操作逻辑,整个开发过程就会变得异常清晰。这里先给大家科普几个关键概念&…...

五分钟完成python脚本配置直连taotoken多模型服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 五分钟完成 Python 脚本配置直连 Taotoken 多模型服务 基础教程类,面向刚接触 Taotoken 的 Python 开发者,…...

PyWxDump:微信数据管理的终极本地解决方案指南
PyWxDump:微信数据管理的终极本地解决方案指南 【免费下载链接】PyWxDump 删库 项目地址: https://gitcode.com/GitHub_Trending/py/PyWxDump 在数字时代,微信聊天记录承载着我们珍贵的回忆和重要信息,但你是否曾担心数据安全、备份困…...