数据结构与算法:算法详解
1. 引言
1.1 算法在计算机科学中的地位和重要性
算法是计算机科学的基石,它指导着计算机在解决各种问题时的行为。一个好的算法可以使得问题的解决更加高效、精确和可靠,因此在计算机科学中具有至关重要的地位。
1.2 学习算法的意义和目标
学习算法不仅仅是为了解决特定的问题,更重要的是培养抽象思维能力和解决问题的方法论。通过学习算法,可以提高解决问题的效率和准确性,同时也能够更好地理解计算机科学中的各种概念和原理。
1.3 算法学习的基本方法论和态度
在学习算法时,需要保持谦虚和开放的态度,乐于接受挑战并从失败中汲取经验教训。同时,要注重理论与实践相结合,不断练习和实践,才能真正掌握算法的精髓和应用技巧。
2. 算法基础
2.1 数据结构基础
数据结构是算法的基础,它包括了一系列基本的数据类型和相应的操作。常见的数据结构包括数组、链表、栈、队列、树和图,它们各自具有不同的特点和适用场景。
2.1.1 数组、链表、栈、队列、树和图的基本概念和操作
- 数组是一种线性数据结构,其元素在内存中是连续存储的,支持随机访问和快速插入删除操作。
- 链表是一种基于指针的数据结构,元素在内存中不一定连续存储,支持快速插入删除操作,但不支持随机访问。
- 栈是一种后进先出(LIFO)的数据结构,支持压栈和弹栈操作,常用于递归函数调用、表达式求值等场景。
- 队列是一种先进先出(FIFO)的数据结构,支持入队和出队操作,常用于任务调度、广度优先搜索等场景。
- 树是一种非线性数据结构,由节点和边组成,常见的有二叉树、二叉搜索树、平衡二叉树等,用于组织数据和快速搜索。
- 图是一种更加复杂的非线性数据结构,由节点和边组成,常见的有有向图和无向图,用于描述各种实际场景中的关系和网络结构。
2.2 算法分析
2.2.1 时间复杂度、空间复杂度的概念和计算方法
- 时间复杂度是衡量算法执行效率的重要指标,表示随着输入规模增大,算法执行时间的增长趋势。常见的时间复杂度包括O(1)、O(log n)、O(n)、O(n log n)、O(n^2)等,通过分析算法中基本操作的执行次数来计算。
- 空间复杂度是衡量算法所需内存空间的指标,表示算法在执行过程中所占用的内存空间大小。常见的空间复杂度同样包括O(1)、O(n)、O(n^2)等,通过分析算法中所使用的额外空间来计算。
2.2.2 渐进符号的理解和使用
- 渐进符号(大O符号)用于描述算法的时间复杂度和空间复杂度的上界。在分析算法性能时,通常只关注最高阶的项,忽略常数因子和低阶项,以及特殊情况下的辅助操作。
- 渐进符号的常见用法包括表示最坏情况下的时间复杂度、平均情况下的时间复杂度等,能够帮助我们更好地理解算法的性能特点和优劣。
2.2.3 算法效率的分析方法:最好情况、最坏情况、平均情况
- 最好情况时间复杂度表示在最理想的情况下,算法的执行时间。它给出了算法在最有利的条件下的性能表现。
- 最坏情况时间复杂度表示在最不利的情况下,算法的执行时间。它给出了算法在最糟糕的情况下的性能表现。
- 平均情况时间复杂度表示在平均情况下,算法的执行时间。它考虑了算法在所有可能输入情况下的性能表现的加权平均值。
2.3 算法思想
2.3.1 分治算法
分治算法的核心思想是将一个大问题分解成多个相同或相似的子问题,然后分别求解子问题,最后将子问题的解合并起来得到原问题的解。典型的应用包括归并排序和快速排序。
归并排序(Merge Sort)
归并排序是一种典型的分治算法,其基本思想是将待排序数组分成两个子数组,分别对子数组进行排序,然后合并两个有序子数组以得到原始数组的有序结果。
public class MergeSort {public void mergeSort(int[] arr, int left, int right) {if (left < right) {int mid = left + (right - left) / 2;mergeSort(arr, left, mid); // 对左半部分进行归并排序mergeSort(arr, mid + 1, right); // 对右半部分进行归并排序merge(arr, left, mid, right); // 合并两个有序数组}}private void merge(int[] arr, int left, int mid, int right) {int n1 = mid - left + 1;int n2 = right - mid;int[] L = new int[n1];int[] R = new int[n2];// 将数据复制到临时数组中for (int i = 0; i < n1; i++) {L[i] = arr[left + i];}for (int j = 0; j < n2; j++) {R[j] = arr[mid + 1 + j];}// 合并两个有序数组int i = 0, j = 0, k = left;while (i < n1 && j < n2) {if (L[i] <= R[j]) {arr[k] = L[i];i++;} else {arr[k] = R[j];j++;}k++;}// 处理剩余元素while (i < n1) {arr[k] = L[i];i++;k++;}while (j < n2) {arr[k] = R[j];j++;k++;}}
}
快速排序(Quick Sort)
快速排序也是一种常见的分治算法,其基本思想是选择一个基准元素,将数组分成两部分,小于基准的元素放在左边,大于基准的元素放在右边,然后递归地对左右两部分进行排序。
public class QuickSort {public void quickSort(int[] arr, int low, int high) {if (low < high) {int pi = partition(arr, low, high); // 获取分区点quickSort(arr, low, pi - 1); // 对左半部分进行快速排序quickSort(arr, pi + 1, high); // 对右半部分进行快速排序}}private int partition(int[] arr, int low, int high) {int pivot = arr[high]; // 选择最后一个元素作为基准int i = low - 1;for (int j = low; j < high; j++) {if (arr[j] < pivot) {i++;swap(arr, i, j);}}swap(arr, i + 1, high);return i + 1;}private void swap(int[] arr, int i, int j) {int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}
}
这些算法在排序问题上展现出了分治思想的强大威力,通过将复杂的问题分解成简单的子问题,然后合并子问题的解,从而得到了高效的排序算法。
2.3.2 动态规划算法
动态规划算法是一种通过记录已经求解过的子问题的解来避免重复计算,从而降低时间复杂度的算法思想。典型的应用包括背包问题和最长公共子序列问题。
背包问题(0-1 Knapsack Problem)
背包问题是一个经典的组合优化问题,在给定背包容量和一组物品的重量和价值的情况下,要求找到一个最优的装载方案,使得装入背包的物品总价值最大。
public class Knapsack {public int knapsack(int W, int[] wt, int[] val, int n) {int[][] dp = new int[n + 1][W + 1];for (int i = 0; i <= n; i++) {for (int w = 0; w <= W; w++) {if (i == 0 || w == 0) {dp[i][w] = 0;} else if (wt[i - 1] <= w) {dp[i][w] = Math.max(val[i - 1] + dp[i - 1][w - wt[i - 1]], dp[i - 1][w]);} else {dp[i][w] = dp[i - 1][w];}}}return dp[n][W];}
}
最长公共子序列(Longest Common Subsequence)
最长公共子序列问题是在两个序列中寻找一个最长的子序列,要求这个子序列在两个原序列中是以相同的顺序出现的,但不要求连续。
public class LongestCommonSubsequence {public int longestCommonSubsequence(String text1, String text2) {int m = text1.length(), n = text2.length();int[][] dp = new int[m + 1][n + 1];for (int i = 1; i <= m; i++) {for (int j = 1; j <= n; j++) {if (text1.charAt(i - 1) == text2.charAt(j - 1)) {dp[i][j] = dp[i - 1][j - 1] + 1;} else {dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);}}}return dp[m][n];}
}
动态规划算法通过将问题分解成多个子问题,并记录子问题的解,从而避免了重复计算,大大提高了问题的求解效率。但需要注意,动态规划算法适用于具有最优子结构性质和重叠子问题性质的问题。
2.3.3 贪心算法
贪心算法每一步都选择当前状态下的最优解,希望最终得到全局最优解。虽然贪心算法不能保证一定能够得到全局最优解,但在某些情况下可以得到近似最优解。
最小生成树(Minimum Spanning Tree)
最小生成树是一种贪心算法的应用,它是一棵包含图中所有节点的树,且树中的所有边的权值之和最小。常用的贪心算法包括Prim算法和Kruskal算法。
Prim算法
Prim算法从一个起始顶点开始,逐步扩展树的规模,每次选择与当前树相邻且权值最小的边对应的节点加入树中,直到所有节点都被包含在树中。
public class PrimMST {public int primMST(int[][] graph) {int V = graph.length;int[] parent = new int[V]; // 用于存储最小生成树中节点的父节点int[] key = new int[V]; // 用于存储到达当前节点的最小权值boolean[] mstSet = new boolean[V]; // 标记节点是否已经被包含在最小生成树中Arrays.fill(key, Integer.MAX_VALUE);key[0] = 0; // 将起始节点的key值设为0,表示选中起始节点作为树的根节点parent[0] = -1; // 根节点没有父节点for (int count = 0; count < V - 1; count++) {int u = minKey(key, mstSet);mstSet[u] = true;for (int v = 0; v < V; v++) {if (graph[u][v] != 0 && !mstSet[v] && graph[u][v] < key[v]) {parent[v] = u;key[v] = graph[u][v];}}}int minCost = 0;for (int i = 1; i < V; i++) {minCost += graph[i][parent[i]];}return minCost;}private int minKey(int[] key, boolean[] mstSet) {int min = Integer.MAX_VALUE, minIndex = -1;for (int v = 0; v < key.length; v++) {if (!mstSet[v] && key[v] < min) {min = key[v];minIndex = v;}}return minIndex;}
}
Kruskal算法
Kruskal算法通过将所有边按照权值从小到大排序,然后逐个考虑边,如果加入边不会形成环,则将该边加入最小生成树中,直到生成树包含了图中的所有节点。
public class KruskalMST {class Edge implements Comparable<Edge> {int src, dest, weight;public Edge(int src, int dest, int weight) {this.src = src;this.dest = dest;this.weight = weight;}@Overridepublic int compareTo(Edge other) {return this.weight - other.weight;}}public int kruskalMST(List<Edge> edges, int V) {Collections.sort(edges);int[] parent = new int[V]; // 用于存储最小生成树中节点的父节点Arrays.fill(parent, -1);int minCost = 0;for (Edge edge : edges) {int x = find(parent, edge.src);int y = find(parent, edge.dest);if (x != y) {minCost += edge.weight;union(parent, x, y);}}return minCost;}private int find(int[] parent, int i) {if (parent[i] == -1) {return i;}return find(parent, parent[i]);}private void union(int[] parent, int x, int y) {int xRoot = find(parent, x);int yRoot = find(parent, y);parent[xRoot] = yRoot;}
}
2.3.4 二分算法
二分算法是一种高效的搜索算法,适用于有序数组或有序列表。它通过将待搜索区间不断二分,从而将搜索范围缩小一半,直到找到目标值或搜索范围为空。
二分查找(Binary Search)
二分查找是二分算法的一种典型应用,用于在有序数组中快速查找目标值。其基本思想是不断将待搜索区间一分为二,然后根据目标值与中间值的大小关系确定下一步搜索的方向。
public class BinarySearch {public int binarySearch(int[] nums, int target) {int left = 0, right = nums.length - 1;while (left <= right) {int mid = left + (right - left) / 2;if (nums[mid] == target) {return mid;} else if (nums[mid] < target) {left = mid + 1;} else {right = mid - 1;}}return -1;}
}
二分算法的时间复杂度为O(log n),是一种非常高效的搜索算法,常用于解决查找问题。
2.3.5 回溯算法
回溯算法是一种穷举搜索算法,通过尝试所有可能的解,并在搜索过程中不断剪枝,从而找到满足约束条件的所有解。典型的应用包括八皇后问题和0-1背包问题。
八皇后问题(N-Queens Problem)
八皇后问题是一个经典的问题,要求在8×8的国际象棋棋盘上放置8个皇后,使得任意两个皇后都不能互相攻击,即任意两个皇后不能处于同一行、同一列或同一斜线上。
public class NQueens {public List<List<String>> solveNQueens(int n) {List<List<String>> res = new ArrayList<>();char[][] board = new char[n][n];for (int i = 0; i < n; i++) {Arrays.fill(board[i], '.');}solveNQueensHelper(res, board, 0, n);return res;}private void solveNQueensHelper(List<List<String>> res, char[][] board, int row, int n) {if (row == n) {res.add(construct(board));return;}for (int col = 0; col < n; col++) {if (isValid(board, row, col, n)) {board[row][col] = 'Q';solveNQueensHelper(res, board, row + 1, n);board[row][col] = '.';}}}private boolean isValid(char[][] board, int row, int col, int n) {for (int i = 0; i < row; i++) {if (board[i][col] == 'Q') {return false; // 检查同一列是否有皇后}if (col - (row - i) >= 0 && board[i][col - (row - i)] == 'Q') {return false; // 检查左上方斜线是否有皇后}if (col + (row - i) < n && board[i][col + (row - i)] == 'Q') {return false; // 检查右上方斜线是否有皇后}}return true;}private List<String> construct(char[][] board) {List<String> res = new ArrayList<>();for (char[] row : board) {res.add(new String(row));}return res;}
}
0-1背包问题(0-1 Knapsack Problem)
0-1背包问题是一个经典的组合优化问题,要求在给定背包容量和一组物品的重量和价值的情况下,找到一个最优的装载方案,使得装入背包的物品总价值最大。
public class Knapsack {public int knapsack(int[] weights, int[] values, int capacity) {int n = weights.length;int[][] dp = new int[n + 1][capacity + 1];for (int i = 1; i <= n; i++) {for (int j = 1; j <= capacity; j++) {if (weights[i - 1] <= j) {dp[i][j] = Math.max(dp[i - 1][j], values[i - 1] + dp[i - 1][j - weights[i - 1]]);} else {dp[i][j] = dp[i - 1][j];}}}return dp[n][capacity];}
}
回溯算法通过穷举搜索的方式,逐步构造解空间,并在搜索过程中进行剪枝,以快速找到问题的解。但需要注意,在问题规模较大时,回溯算法的时间复杂度可能会非常高,因此在实际应用中需要谨慎使用。
3. 常见算法
3.1 排序与搜索算法
排序和搜索是算法中的基础操作,涉及到对数据的排列和查找。常见的排序算法包括冒泡排序、选择排序、插入排序、归并排序、快速排序等;而搜索算法则包括线性搜索、二分搜索等。
常见排序算法及其原理和应用
- 冒泡排序(Bubble Sort):通过不断地交换相邻的元素,将最大(或最小)的元素逐步“冒泡”到数组的末尾(或开头)。
public class BubbleSort {public void bubbleSort(int[] arr) {int n = arr.length;for (int i = 0; i < n - 1; i++) {for (int j = 0; j < n - i - 1; j++) {if (arr[j] > arr[j + 1]) {int temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}}}
}
- 选择排序(Selection Sort):每次选择未排序部分的最小元素,并将其放到已排序部分的末尾。
public class SelectionSort {public void selectionSort(int[] arr) {int n = arr.length;for (int i = 0; i < n - 1; i++) {int minIndex = i;for (int j = i + 1; j < n; j++) {if (arr[j] < arr[minIndex]) {minIndex = j;}}if (minIndex != i) {int temp = arr[i];arr[i] = arr[minIndex];arr[minIndex] = temp;}}}
}
- 插入排序(Insertion Sort):将待排序的元素依次插入到已排序序列的合适位置,从而使序列保持有序。
public class InsertionSort {public void insertionSort(int[] arr) {int n = arr.length;for (int i = 1; i < n; i++) {int key = arr[i];int j = i - 1;while (j >= 0 && arr[j] > key) {arr[j + 1] = arr[j];j--;}arr[j + 1] = key;}}
}
- 归并排序(Merge Sort):将数组分成两个子数组,分别对子数组进行排序,然后合并两个有序子数组以得到原始数组的有序结果。
public class MergeSort {public void mergeSort(int[] arr, int left, int right) {if (left < right) {int mid = left + (right - left) / 2;mergeSort(arr, left, mid);mergeSort(arr, mid + 1, right);merge(arr, left, mid, right);}}private void merge(int[] arr, int left, int mid, int right) {// Merge two subarrays arr[left..mid] and arr[mid+1..right]// Create temporary arraysint n1 = mid - left + 1;int n2 = right - mid;int[] L = new int[n1];int[] R = new int[n2];// Copy data to temporary arrays L[] and R[]for (int i = 0; i < n1; ++i) {L[i] = arr[left + i];}for (int j = 0; j < n2; ++j) {R[j] = arr[mid + 1 + j];}// Merge the temporary arraysint i = 0, j = 0;int k = left;while (i < n1 && j < n2) {if (L[i] <= R[j]) {arr[k] = L[i];i++;} else {arr[k] = R[j];j++;}k++;}// Copy remaining elements of L[] if anywhile (i < n1) {arr[k] = L[i];i++;k++;}// Copy remaining elements of R[] if anywhile (j < n2) {arr[k] = R[j];j++;k++;}}
}
- 快速排序(Quick Sort):选择一个基准元素,将数组分成两部分,小于基准的放在左边,大于基准的放在右边,然后递归地对左右两部分进行排序。
public class QuickSort {public void quickSort(int[] arr, int low, int high) {if (low < high) {int pi = partition(arr, low, high);quickSort(arr, low, pi - 1);quickSort(arr, pi + 1, high);}}private int partition(int[] arr, int low, int high) {int pivot = arr[high];int i = low - 1;for (int j = low; j < high; j++) {if (arr[j] < pivot) {i++;int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}}int temp = arr[i + 1];arr[i + 1] = arr[high];arr[high] = temp;return i + 1;}
}
常见搜索算法及其原理和应用
- 线性搜索(Linear Search):逐个检查数组中的每个元素,直到找到目标值或搜索到数组末尾。
public class LinearSearch {public int linearSearch(int[] arr, int target) {for (int i = 0; i < arr.length; i++) {if (arr[i] == target) {return i;}}return -1;}
}
- 二分搜索(Binary Search):在有序数组中,通过比较目标值和中间元素的大小关系,将搜索范围缩小一半,直到找到目标值或搜索范围为空。
public class BinarySearch {public int binarySearch(int[] nums, int target) {int left = 0, right = nums.length- 1;while (left <= right) {int mid = left + (right - left) / 2;if (nums[mid] == target) {return mid;} else if (nums[mid] < target) {left = mid + 1;} else {right = mid - 1;}}return -1;}
}
这些排序和搜索算法是算法学习中的基础,掌握它们的原理和实现方法有助于提高编程能力和解决实际问题的能力。
3.2 图算法
图是由节点(顶点)和边组成的一种数据结构,广泛应用于各种领域,如网络路由、社交网络、地图导航等。图算法主要用于解决图相关的问题,包括最短路径、最小生成树、图的遍历等。
最短路径和最小生成树算法
- 最短路径算法用于找到图中两个节点之间的最短路径,常见的算法包括Dijkstra算法和Bellman-Ford算法。
- 最小生成树算法用于在图中找到一棵包含所有节点的生成树,并且总权值最小,常用的算法包括Prim算法和Kruskal算法。
其他图算法
除了最短路径和最小生成树算法之外,还有一些其他的图算法,如拓扑排序、最大流问题等。
- 拓扑排序用于对有向无环图进行排序,使得图中的所有节点按照一定的顺序排列,且满足图中的边的方向。
- 最大流问题是指在网络流中找到从源节点到汇节点的最大流量路径,常用的解决方法包括Ford-Fulkerson算法和Edmonds-Karp算法。
4. 其他领域算法
在计算机科学和工程领域,算法的应用不仅局限于基本的数据处理和优化问题,还涉及到多个特定领域的算法解决方案。以下是一些常见的其他领域算法:
4.1 安全算法
4.1.1 摘要算法
摘要算法用于将任意长度的数据映射成固定长度的哈希值,常用于数据完整性验证和密码学应用。常见的摘要算法包括MD5、SHA-1、SHA-256等。
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;public class DigestAlgorithm {public String md5Digest(String data) throws NoSuchAlgorithmException {MessageDigest md = MessageDigest.getInstance("MD5");byte[] digest = md.digest(data.getBytes());StringBuilder sb = new StringBuilder();for (byte b : digest) {sb.append(String.format("%02x", b));}return sb.toString();}
}
4.1.2 加密算法
加密算法用于数据的保密性和身份验证,包括对称加密算法(如AES、DES)和非对称加密算法(如RSA、ECC)。
import javax.crypto.Cipher;
import javax.crypto.KeyGenerator;
import javax.crypto.SecretKey;
import java.security.KeyPair;
import java.security.KeyPairGenerator;public class EncryptionAlgorithm {public byte[] encryptAES(String data, SecretKey secretKey) throws Exception {Cipher cipher = Cipher.getInstance("AES");cipher.init(Cipher.ENCRYPT_MODE, secretKey);return cipher.doFinal(data.getBytes());}public byte[] decryptAES(byte[] encryptedData, SecretKey secretKey) throws Exception {Cipher cipher = Cipher.getInstance("AES");cipher.init(Cipher.DECRYPT_MODE, secretKey);return cipher.doFinal(encryptedData);}public byte[] encryptRSA(String data, KeyPair keyPair) throws Exception {Cipher cipher = Cipher.getInstance("RSA");cipher.init(Cipher.ENCRYPT_MODE, keyPair.getPublic());return cipher.doFinal(data.getBytes());}public byte[] decryptRSA(byte[] encryptedData, KeyPair keyPair) throws Exception {Cipher cipher = Cipher.getInstance("RSA");cipher.init(Cipher.DECRYPT_MODE, keyPair.getPrivate());return cipher.doFinal(encryptedData);}
}
4.2 字符串匹配算法
字符串匹配算法用于在文本中查找指定模式的字符串,常见的算法包括暴力搜索算法、KMP算法、Boyer-Moore算法和Rabin-Karp算法。
public class StringMatching {public int bruteForce(String text, String pattern) {int n = text.length();int m = pattern.length();for (int i = 0; i <= n - m; i++) {int j;for (j = 0; j < m; j++) {if (text.charAt(i + j) != pattern.charAt(j)) {break;}}if (j == m) {return i; // 匹配成功,返回匹配位置}}return -1; // 匹配失败}
}
4.3 大数据处理算法
大数据处理算法用于处理海量数据,包括分布式文件系统(如Hadoop HDFS、Google GFS)、分布式计算框架(如MapReduce、Spark)和流式处理框架(如Apache Storm、Apache Flink)等。
这些算法和框架在大数据处理领域发挥着重要作用,能够高效地处理和分析海量数据,为数据驱动的决策提供支持。
4.4 分布式算法
分布式算法用于解决分布式系统中的一些关键问题,包括一致性算法(如Paxos、Raft)、数据分布和分片算法(如一致性哈希算法、范围分区算法)以及数据复制和故障恢复算法(如Gossip协议、Quorum复制)等。
这些算法保证了分布式系统的高可用性、可靠性和一致性,是构建大规模分布式系统的基础。
4.5 负载均衡算法
负载均衡算法用于将请求分发到多个服务器上,以实现系统的高可用性和性能优化。常见的负载均衡算法包括随机算法、轮询算法、加权轮询算法、最小连接数算法和最少响应时间算法等。
这些算法可以根据实际情况动态地调整服务器的负载分布,提高系统的整体性能和稳定性。
4.6 推荐算法
推荐算法用于根据用户的历史行为和偏好,向用户推荐可能感兴趣的物品或信息。常见的推荐算法包括协同过滤算法、内容推荐算
法和深度学习推荐算法等。
这些算法可以帮助电商平台、社交网络和内容平台等提高用户的满意度和黏性,促进业务的发展和增长。
4.7 数据挖掘算法
数据挖掘算法用于从大量数据中发现有价值的模式、关系或趋势,包括聚类算法、分类算法和关联规则挖掘算法等。
这些算法在商业智能、市场营销、金融风控等领域发挥着重要作用,帮助企业从数据中挖掘出有用的信息和洞察,指导决策和战略规划。
5. 算法实践与应用
在实际工程中,算法的应用是非常广泛的,它们不仅仅是理论上的概念,更是解决实际问题的重要工具。以下是关于算法实践与应用的详细介绍,包括在工程实践中的应用以及常见挑战与解决方案:
5.1 算法在工程实践中的应用
算法在工程实践中扮演着重要角色,它们被用于解决各种实际问题,例如图像处理、自然语言处理、推荐系统等。以下是一些常见的应用场景:
-
图像处理:算法被广泛用于图像处理领域,如边缘检测、图像分割、目标识别等。例如,卷积神经网络(CNN)在图像分类任务中取得了巨大成功。
-
自然语言处理:算法在自然语言处理领域被用于文本分类、命名实体识别、情感分析等任务。例如,循环神经网络(RNN)被用于处理序列数据,如文本和语音。
-
推荐系统:算法被应用于推荐系统中,根据用户的历史行为和兴趣,向用户推荐可能感兴趣的物品或信息。例如,协同过滤算法被广泛应用于推荐系统中。
-
金融领域:算法在金融领域被用于股票预测、风险管理、高频交易等。例如,支持向量机(SVM)被用于股票价格预测。
5.2 算法实践中的常见挑战与解决方案
在算法实践过程中,常常会面临各种挑战,例如性能优化、算法复杂度、数据质量等。以下是一些常见挑战及其解决方案:
-
性能优化:算法的性能优化是算法实践中的重要问题。优化算法的性能可以通过算法优化、并行计算、硬件加速等方式来实现。
-
算法复杂度:某些算法的复杂度可能会随着数据规模的增加而急剧增加,导致计算时间过长。解决方案包括选择更合适的算法、优化算法实现、分布式计算等。
-
数据质量:算法的输入数据质量直接影响算法的效果。因此,在算法实践中,需要对数据进行预处理、清洗、归一化等操作,以确保数据的质量。
-
模型泛化:训练出的模型在测试数据上的表现可能不如在训练数据上好,这就是过拟合问题。解决方案包括交叉验证、正则化、集成学习等。
-
算法的可解释性:有些复杂的算法模型很难解释其内部的工作原理,这会影响到对模型结果的理解和信任。解决方案包括使用可解释性更强的模型、模型解释技术等。
-
并发与并行:在大规模数据处理和计算中,并发与并行是提高效率的关键。解决方案包括使用并发编程模型、分布式计算框架等。
以上是算法实践中常见的挑战及其解决方案,通过合理的方法和策略,可以有效地解决这些挑战,提高算法的性能和效果。
相关文章:

数据结构与算法:算法详解
1. 引言 1.1 算法在计算机科学中的地位和重要性 算法是计算机科学的基石,它指导着计算机在解决各种问题时的行为。一个好的算法可以使得问题的解决更加高效、精确和可靠,因此在计算机科学中具有至关重要的地位。 1.2 学习算法的意义和目标 学习算法不…...

AOSP10 替换系统launcher
本文实现将原生的launcher 移除,替换成我们自己写的launcher。 分以下几个步骤: 一、新建一个自己的launcher项目。 1.直接使用android studio 新建一个项目。 2.修改AndroidManifest.xml <applicationandroid:persistent"true"androi…...

视频互动游戏如何暴打海王和舔狗
前言 前2篇文章回答了游戏的可取之处以及不可复制的地方还有对于这一类的情景互动游戏在2024年的发展预言。第三篇主要是回答在一篇中一个留言的读者问的问题“如何暴打海王和舔狗”,求同存异,希望能够跟更多的读者交流与互相学习。 海王和舔狗的特征 …...
大学生多媒体课程学习网站thinkphp+vue
开发语言:php 后端框架:Thinkphp 前端框架:vue.js 服务器:apache 数据库:mysql 运行环境:phpstudy/wamp/xammp等开发背景 (一) 研究课程的提出 (二)学习网站的分类与界定…...
信息系统项目管理师论文分享(质量管理)
水一篇文章。我发现身边考高项的朋友很多都是论文没过,我想着那就把我的论文分享出来,希望能有帮助。 质量管理 摘要 2020年5月,我作为项目经理参加了“某市某医联体的互联网诊疗(互联网医院和远程医疗)平台”的建设…...
Redis实现滑动窗口限流
常见限流算法 固定窗口算法 在固定的时间窗口下进行计数,达到阈值就拒绝请求。固定窗口如果在窗口开始就打满阈值,窗口后半部分进入的请求都会拒绝。 滑动窗口算法 在固定窗口的基础上,窗口会随着时间向前推移,可以在时间内平滑控…...
——XML查询计划)
SQL Server查询计划(Query Plan)——XML查询计划
6.4.3. XML查询计划 SQL Server中,除了通过GUI工具和相关命令获取图形及文本查询计划外,我们还可以通过相关命令获取XML格式的查询计划,这里惯称其为XML查询计划。 SQL Server 2005版本引入了XML查询计划的新特性,其充分吸收了图形及文本查询计划的优势所在,…...
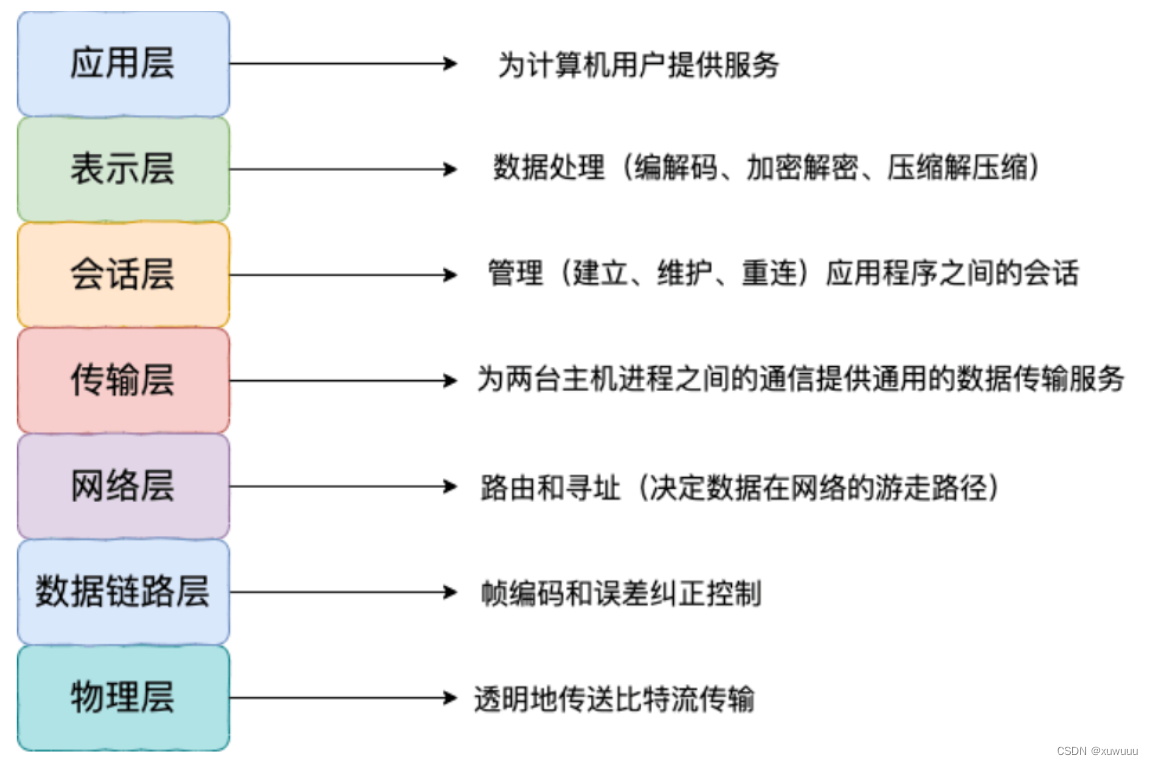
【day02】每天三道 java后端面试题:Java、C++和Go的区别 | Redis的特点和应用场景 | 计算机网络七层模型
文章目录 1. Java、C和 Go 语言的区别,各自的优缺点?2. 什么是Redis?Redis 有哪些特点? Redis有哪些常见的应用场景?3. 简述计算机网络七层模型和各自的作用? 1. Java、C和 Go 语言的区别,各自的…...
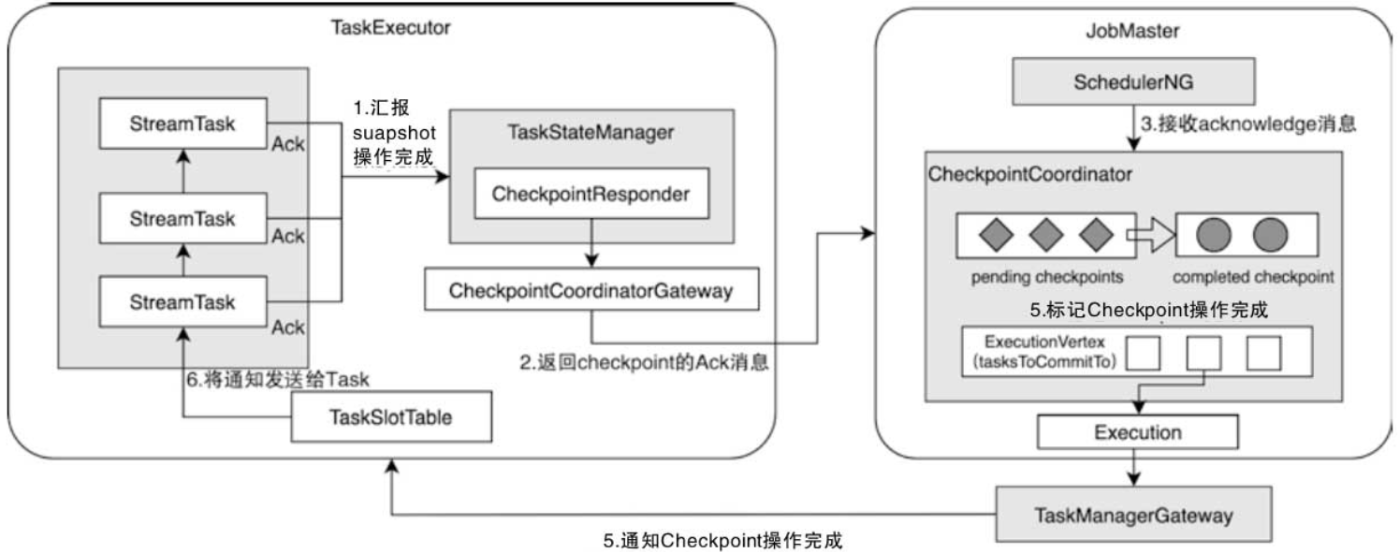
【Flink状态管理(八)】Checkpoint:CheckpointBarrier对齐后Checkpoint的完成、通知与对学习状态管理源码的思考
文章目录 一. 调用StreamTask执行Checkpoint操作1. 执行Checkpoint总体代码流程1.1. StreamTask.checkpointState()1.2. executeCheckpointing1.3. 将算子中的状态快照操作封装在OperatorSnapshotFutures中1.4. 算子状态进行快照1.5. 状态数据快照持久化 二. CheckpointCoordin…...
防御保护第八、九、十、十一天笔记
一、内容安全 1、DFI和DPI技术 --- 深度检测技术 DPI是一种基于应用层的流量检测和控制技术,它会对流量进行拆包,分析包头和应用层的内容,从而识别应用程序和应用程序的内容。这种技术增加了对应用层的分析,识别各种应用…...

【TypeScript基础知识点】的讲解
TypeScript基础知识点 TypeScript基础知识点 TypeScript基础知识点 TypeScript 是一种由 Microsoft 开发和维护的开源编程语言,它是 JavaScript 的一个超集,添加了可选的静态类型和基于类的面向对象编程,以下是一些 TypeScript 的基础知识点…...

牛客周赛 Round 34 解题报告 | 珂学家 | 构造思维 + 置换环
前言 整体评价 好绝望的牛客周赛,彻底暴露了CF菜菜的本质,F题没思路,G题用置换环骗了50%, 这大概是唯一的亮点了。 A. 小红的字符串生成 思路: 枚举 a,b两字符在相等情况下比较特殊 a, b input().split() if a b:print (2)print (a)pri…...

LeetCode13 罗马数字转整数
题目 罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000 例如&…...
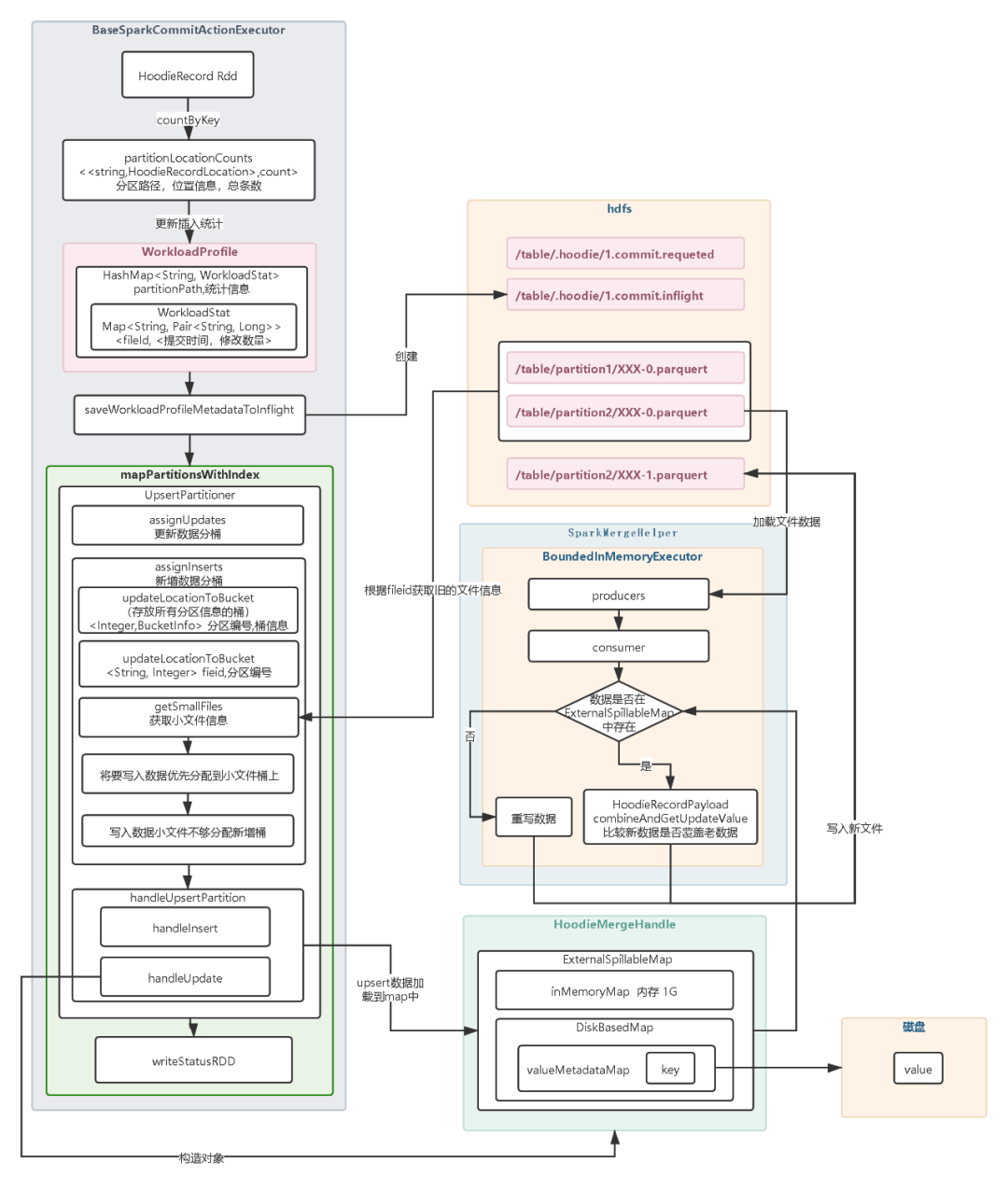
【Hudi】Upsert原理
17张图带你彻底理解Hudi Upsert原理 1.开始提交:判断上次任务是否失败,如果失败会触发回滚操作。然后会根据当前时间生成一个事务开始的请求标识元数据。2.构造HoodieRecord Rdd对象:Hudi 会根据元数据信息构造HoodieRecord Rdd 对象…...

信息系统服务:演绎数字时代的征程
信息系统服务作为数字化时代的基石,已经在人类社会的各个领域发挥着重要作用。本文将从信息系统服务的起源、发展和演化过程,通过生动的例子和准确客观的历史事实,探讨信息系统服务对人类社会的影响与变革。 1. 起源:信息处理的初…...

rust连接postgresql数据库
引入crate: postgres "0.19.7" use postgres::{Client, NoTls, error::Error};fn main() -> Result<(), Error> {let mut client Client::connect("hostlocalhost port5432 dbnamexxxxdb userpostgres passwordxxxxxx", NoTls).un…...

[面试] 什么是死锁? 如何解决死锁?
什么是死锁 死锁,简单来说就是两个或者多个的线程在执行的过程中,争夺同一个共享资源造成的相互等待的现象。如果没有外部干预线程会一直阻塞下去. 导致死锁的原因 互斥条件,共享资源 X 和 Y 只能被一个线程占用; 请求和保持条件…...
网络原理 HTTP _ HTTPS
回顾 我们前面介绍了HTTP协议的请求和响应的基本结构 请求报文是由首行请求头空行正文来组成的 响应报文是由首行形影头空行响应正文组成的 我们也介绍了一定的请求头之中的键值对的属性 Host,Content-type,Content-length,User-agent,Referer,Cookie HTTP协议中的状态码 我们先…...

软件实际应用实例,茶楼收银软件管理系统操作流程,茶室计时计费会员管理系统软件试用版教程
软件实际应用实例,茶楼收银软件管理系统操作流程,茶室计时计费会员管理系统软件试用版教程 一、前言 以下软件以 佳易王茶社计时计费管理系统软件V17.9为例说明 软件文件下载可以点击最下方官网卡片——软件下载——试用版软件下载 1、计时计费&…...
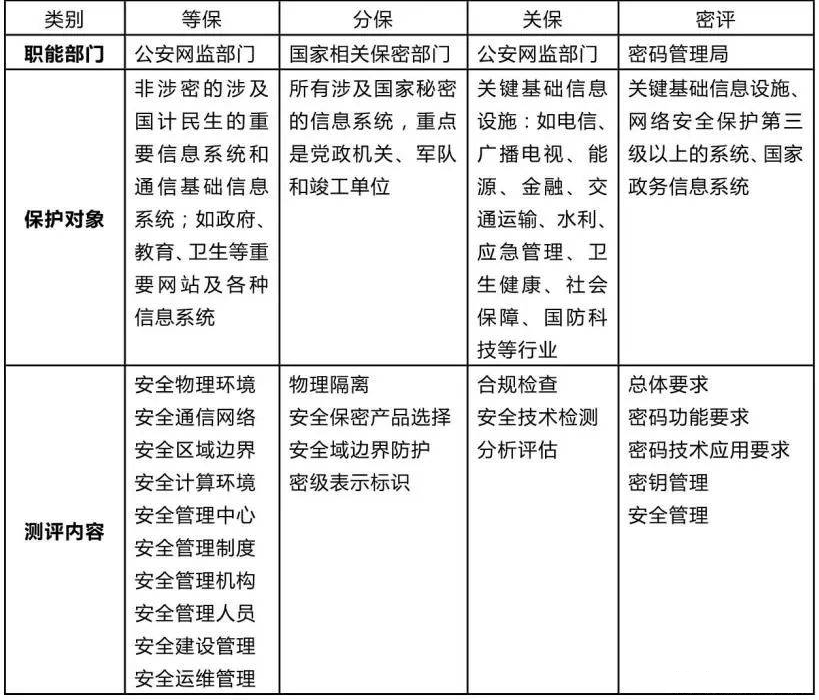
网络安全“三保一评”深度解析
“没有网络安全就没有国家安全”。近几年,我国法律法规陆续发布实施,为承载我国国计民生的重要网络信息系统的安全提供了法律保障,正在实施的“3保1评”为我国重要网络信息系统的安全构筑了四道防线。 什么是“3保1评”? 等保、分…...

ncmdump终极解决方案:解锁网易云音乐NCM格式的完整指南
ncmdump终极解决方案:解锁网易云音乐NCM格式的完整指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的NCM加密文件无法在其他设备播放而烦恼吗?ncmdump工具使用为你提供了完美的NCM格…...

Neovim AI编程助手codecompanion.nvim:无缝集成与高效开发实践
1. 项目概述:一个为Neovim而生的AI编程伴侣如果你和我一样,是个深度依赖Neovim进行日常开发的程序员,那么你一定经历过这样的时刻:面对一段复杂的逻辑,需要反复查阅文档;或者写一个函数时,卡在某…...

终极指南:3分钟掌握Deepin Boot Maker,轻松制作Linux启动盘
终极指南:3分钟掌握Deepin Boot Maker,轻松制作Linux启动盘 【免费下载链接】deepin-boot-maker 项目地址: https://gitcode.com/gh_mirrors/de/deepin-boot-maker 你是否曾经因为复杂的命令行操作而对Linux系统安装望而却步?或者面对…...
、GELU激活函数与数据预处理那些事儿)
BERT PyTorch实现避坑指南:torch.gather()、GELU激活函数与数据预处理那些事儿
BERT PyTorch实现避坑指南:torch.gather()、GELU激活函数与数据预处理那些事儿 当你第一次尝试在PyTorch中实现BERT模型时,可能会遇到一些令人困惑的技术细节。本文将从实际调试的角度,深入解析三个最容易卡住开发者的关键点:torc…...

用AI工具做技术课程:一个人完成录课、剪辑、上架全流程
软件测试从业者的知识变现新路径作为一名软件测试工程师,你手里握着大量值钱的东西——接口自动化怎么搭、性能瓶颈怎么定位、测试用例怎么设计才不漏测。这些东西在你的团队里可能是常识,但放到整个行业,就是别人愿意付费学习的硬通货。但一…...

ARM PMUv3架构详解与性能监控实战
1. ARM PMUv3架构概述 性能监控单元(Performance Monitor Unit, PMU)是现代处理器中用于硬件性能分析的关键组件。作为ARMv8架构的标准组成部分,PMUv3通过事件计数器和配置寄存器实现了对微架构事件的监测能力。在实际开发中,我们经常需要利用PMU来定位性…...

别再硬熬了!okbiye AI 写作,把毕业论文终稿焊死在及格线以上
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 凌晨两点的宿舍,文档停在 “研究背景” 第三段,导师的红色批注在聊天框堆成了山,知网查重的弹窗跳出来的…...

为什么你的v8出图突然“高级感崩塌”?3分钟定位色彩语义锚点失效+实时修复模板
更多请点击: https://intelliparadigm.com 第一章:为什么你的v8出图突然“高级感崩塌”? V8 引擎本身并不直接“出图”——这一表述实为开发者对前端渲染链路中某环节异常的戏谑指代。真正崩塌的,往往是基于 V8 驱动的 Canvas/We…...

基于RAG与智能分块构建LLM本地知识库:llm-books开源工具实战
1. 项目概述:一个为LLM“喂书”的开源工具最近在折腾大语言模型本地应用的朋友,可能都遇到过同一个头疼的问题:怎么让模型“读懂”我手头那几百页的PDF报告、电子书或者研究论文?直接复制粘贴?上下文长度不够。手动分段…...

书成紫微动,律定凤凰驯:海棠山铁哥,用两部作品走完了千年谶语的路
书成紫微动,律定凤凰驯。 ——千年谶语,今终圆满。一、悬在文脉上空的千年谶语“书成紫微动,律定凤凰驯”自诞生之日起,这句庙堂吉颂便高悬于华夏文脉之上,无人可触、无人能落。 文人墨客解其字,玄学爱好者…...