Go语言的100个错误使用场景(55-60)|并发基础
前言
大家好,这里是白泽。**《Go语言的100个错误以及如何避免》**是最近朋友推荐我阅读的书籍,我初步浏览之后,大为惊喜。就像这书中第一章的标题说到的:“Go: Simple to learn but hard to master”,整本书通过分析100个错误使用 Go 语言的场景,带你深入理解 Go 语言。
我的愿景是以这套文章,在保持权威性的基础上,脱离对原文的依赖,对这100个场景进行篇幅合适的中文讲解。所涉内容较多,总计约 8w 字,这是该系列的第七篇文章,对应书中第55-60个错误场景。
🌟 当然,如果您是一位 Go 学习的新手,您可以在我开源的学习仓库中,找到针对**《Go 程序设计语言》**英文书籍的配套笔记,其他所有文章也会整理收集在其中。
📺 B站:白泽talk,公众号【白泽talk】,聊天交流群:622383022,原书电子版可以加群获取。
前文链接:
-
《Go语言的100个错误使用场景(1-10)|代码和项目组织》
-
《Go语言的100个错误使用场景(11-20)|项目组织和数据类型》
-
《Go语言的100个错误使用场景(21-29)|数据类型》
-
《Go语言的100个错误使用场景(30-40)|数据类型与字符串使用》
-
《Go语言的100个错误使用场景(40-47)|字符串&函数&方法》
-
《Go语言的100个错误使用场景(48-54)|错误管理》
8. 并发基础
🌟 章节概述
- 理解并发和并行
- 为什么并发并不总是更快
- cup 负载和 io 负载的影响
- 使用 channel 对比使用互斥锁
- 理解数据竞争和竞态条件的区别
- 使用 Go context
8.1 混淆并发与并行的概念(#55)
以一家咖啡店的运作为例讲解一下并发和并行的概念。
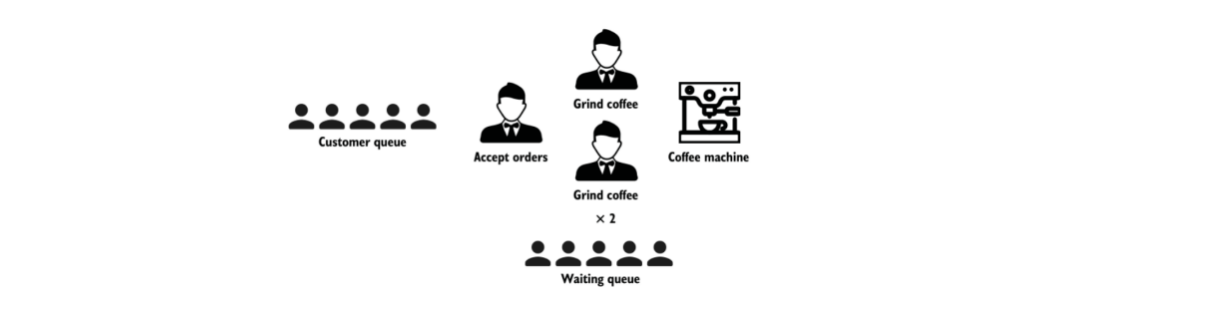
- 并行:强调执行,如两个咖啡师同时在给咖啡拉花
- 并发:两个咖啡师竞争一个咖啡研磨机器的使用
8.2 认为并发总是更快(#56)
- 线程:OS 调度的基本单位,用于调度到 CPU 上执行,线程的切换是一个高昂的操作,因为要求将当前 CPU 中运行态的线程上下文保存,切换到可执行态,同时调度一个可执行态的线程到 CPU 中执行。
- 协程:线程由 OS 上下文切换 CPU 内核,而 Goroutine 则由 Go 运行时上下文切换协程。Go 协程占用内存比线程少(2KB/2MB),协程的上下文切换比线程快80~90%。
🌟 GMP 模型:
- G:Goroutine
- 执行态:被调度到 M 上执行
- 可执行态:等待被调度
- 等待态:因为一些原因被阻塞
- M:OS thread
- P:CPU core
- 每个 P 有一个本地 G 队列(任务队列)
- 所有 P 有一个公共 G 队列(任务队列)
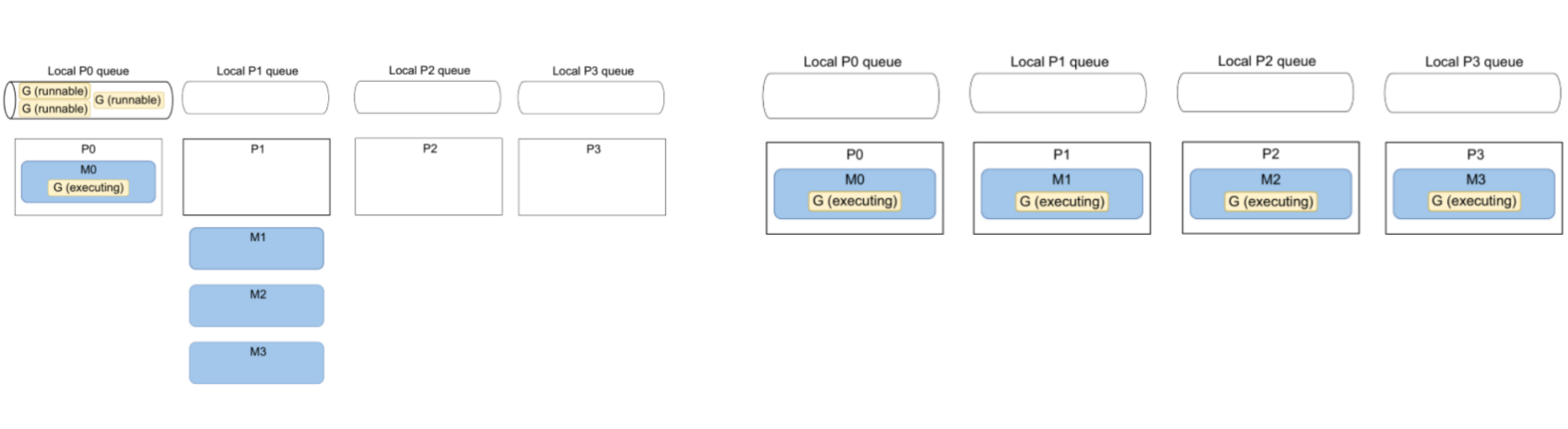
协程调度规则:每一个 OS 线程(M)被调度到 P 上执行,然后每一个 G 运行在 M 上。
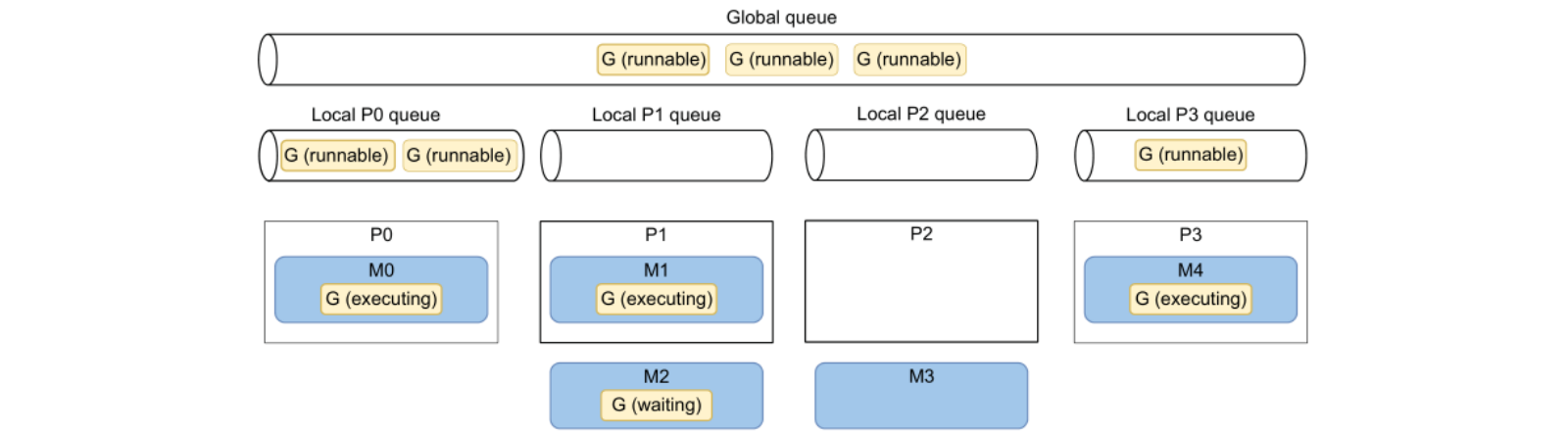
🌟 上图中展示了一个4核 CPU 的机器调度 Go 协程的场景:
此时 P2 正在闲置因为 M3 执行完毕释放了对 P2 的占用,虽然 P2 的 Local queue 中已经空了,没有 G 可以调度执行,但是每隔一定时间,Go runtime 会去 Global queue 和其他 P 的 local queue 偷取一些 G 用于调度执行(当前存在6个可执行的G)。
特别的,在 Go1.14 之前,Go 协程的调度是合作形式的,因此 Go 协程发生切换的只会因为阻塞等待(IO/channel/mutex等),但 Go1.14 之后,运行时间超过 10ms 的协程会被标记为可抢占,可以被其他协程抢占 P 的执行。
🌟 为了印证有时候多协程并不一定会提高性能,这里以归并排序为例举三个例子:
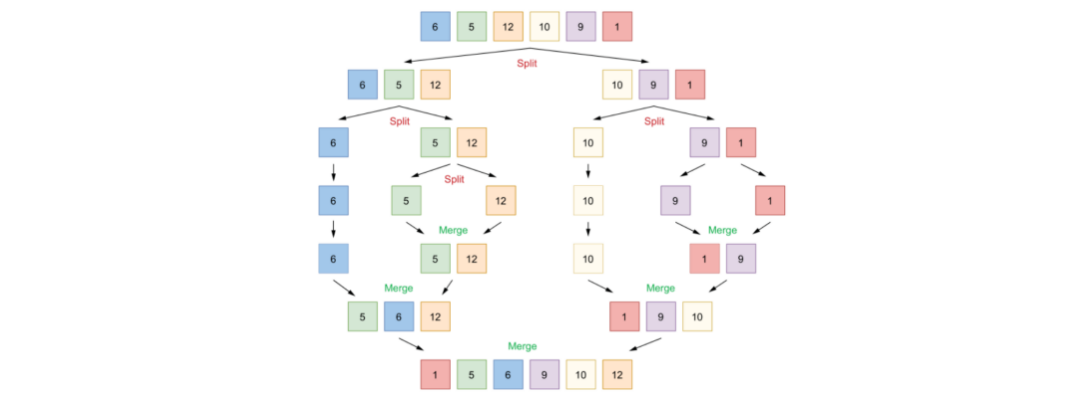
示例一:
func sequentialMergesort(s []int) {if len(s) <= 1 {return}middle := len(s) / 2sequentialMergesort(s[:middle])sequentialMergesort(s[middle:])merge(s, middle)
}func merge(s []int, middle int) {// ...
}
示例二:
func sequentialMergesortV1(s []int) {if len(s) <= 1 {return}middle := len(s) / 2var wg sync.WaitGroup()wg.Add(2)go func() {defer wd.Done()parallelMergesortV1(s[:middle])}()go func() {defer wd.Done()parallelMergesortV1(s[middle:])}()wg.Wait()merge(s, middle)
}
示例三:
const max = 2048func sequentialMergesortV2(s []int) {if len(s) <= 1 {return}if len(s) < max {sequentialMergesort(s)} else {middle := len(s) / 2var wg sync.WaitGroup()wg.Add(2)go func() {defer wd.Done()parallelMergesortV2(s[:middle])}()go func() {defer wd.Done()parallelMergesortV2(s[middle:])}()wg.Wait()merge(s, middle) }
}
由于创建协程和调度协程本身也有开销,第二种情况无论多少个元素都使用协程去进行并行排序,导致归并很少的元素也需要创建协程和调度,开销比排序更多,导致性能还比不上第一种顺序归并。
而在本台电脑上,经过调试第三种方式可以获得比第一种方式更优的性能,因为它在元素大于2048个的时候,选择并行排序,而少于则使用顺序排序。但是2048是一个魔法数,不同电脑上可能不同。这里这是为了证明,完全依赖并发/并行的机制,并不一定会提高性能,需要注意协程本身的开销。
8.3 分不清何时使用互斥锁或 channel(#57)
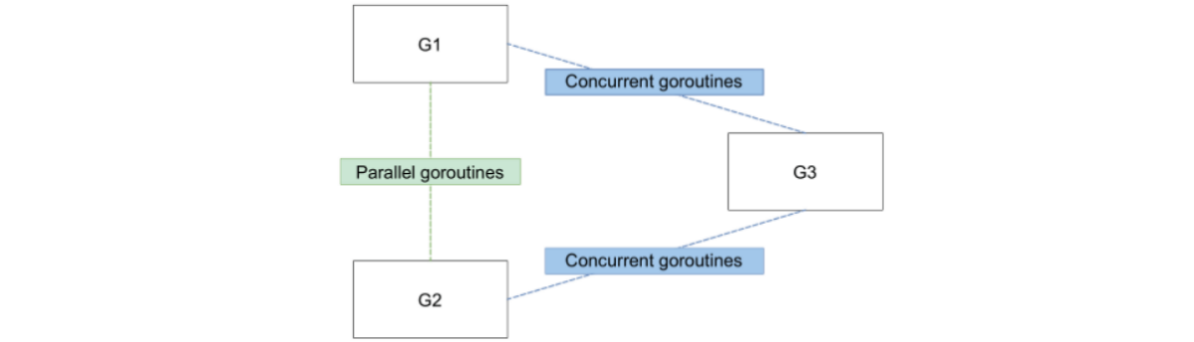
- mutex:针对 G1 和 G2 这种并行执行的两个协程,它们可能会针对同一个对象进行操作,比如切片。此时是一个发生资源竞争的场景,因此适合使用互斥锁。
- channel:而上游的 G1 或者 G2 中任何一个都可以在执行完自己逻辑之后,通知 G3 开始执行,或者传递给 G3 某些处理结果,此时使用 channel,因为 Go 推荐使用 channel 作为协程间通信的手段。
8.4 不理解竞态问题(#58)
🌟 数据竞争:多个协程同时访问一块内存地址,且至少有一次写操作。
假设有两个并发协程对 i 进行自增操作:
i := 0go func() {i++
}()go func() {i++
}()
因为 i++ 操作可以被分解为3个步骤:
- 读取 i 的值
- 对应值 + 1
- 将值写会 i
当并发执行两个协程的时候,i 的最终结果是无法预计的,可能为1,也可能为2。
修正方案一:
var i int64go func() {atomic.AddInt64(&i, 1)
}()go func() {atomic.AddInt64(&i, 1)
}()
使用 sync/atomic 包的原子运算,因为原子运算不能被打断,因此两个协程无法同时访问 i,因为客观上两个协程按顺序执行,因此最终的结果为2。
但是因为 Go 语言只为几种类型提供了原子运算,无法应对 slices、maps、structs。
修正方案二:
i := 0
mutex := sync.Mutex{}go func() {mutex.Lock()i++mutex.UnLock()
}()go func() {mutex.Lock()i++mutex.UnLock()
}()
此时被 mutex 包裹的部分,同一时刻只能允许一个协程访问。
修正方案三:
i := 0
ch := make(chan int)go func() {ch <- 1
}go func() {ch <- 1
}i += <-ch
i += <-ch
使用阻塞的 channel,主协程必须从 ch 中读取两次才能执行结束,因此结果必然是2。
🌟 Go 语言的内存模型
我们使用 A < B 表示事件 A 发生在事件 B 之前。
i := 0
go func() {i++
}()
因为创建协程发生在协程的执行,因此读取变量 i 并给 i + 1在这个例子中不会造成数据竞争。
i := 0
go func() {i++
}()
fmt.Println(i)
协程的退出无法保证一定发生在其他事件之前,因此这个例子会发生数据竞争。
i := 0
ch := make(chan struct{})
go func() {<-chfmt.Println(i)
}()
i++
ch <- struct{}{}
这个例子由于打印 i 之前,一定会执行 i++ 的操作,并且子协程等待主协程的 channel 的解除阻塞信号。
i := 0
ch := make(chan struct{})
go func() {<-chfmt.Println(i)
}()
i++
close()
和上一个例子有点像,channel 在关闭事件发生在从 channel 中读取信号之前,因此不会发生数据竞争。
i := 0
ch := make(chan struct{}, 1)
go func() {i = 1<-ch
}()
ch <- struct{}{}
fmt.Println(i)
主协程向 channel 放入值的操作执行,并不能确保与子协程的执行事件顺序,因此会发生数据竞争。
i := 0
ch := make(chan struct{})
go func() {i = 1<-ch
}()
ch <- struct{}{}
fmt.Println(i)
主协程的存入 channel 的事件,必然发生在子协程从 channel 取出事件之前,因此不会发生数据竞争。
i := 0
ch := make(chan struct{})
go func() {i = 1<-ch
}()
ch <- struct{}{}
fmt.Println(i)
无无缓冲的 channel 确保在主协程执行打印事件之前,必须会执行 i = 1 的赋值操作,因此不会发生数据竞争。
8.5 不了解工作负载类型对并发性能的影响(#59)
🌟 工作负载执行时间受到下述条件影响:
- CPU 执行速度:例如执行归并排序,此时工作负载称作——CPU约束。
- IO 执行速度:对DB进行查询,此时工作负载称作——IO约束。
- 可用内存:此时工作负载称作——内存约束。
🌟 接下来通过一个场景讲解为何讨论并发性能,需要区分负载类型:假设有一个 read 函数,从循环中每次读取1024字节,然后将获得的内容传递给一个 task 函数执行,返回一个 int 值,并每次循环对这个 int 进行求和。
串行实现:
func read(r io.Reader) (int, error) {count := 0for {b := make([]byte, 1024)_, err := r.Read(b)if err != nil {if err == io.EOF {break}return 0, err}count += task(b)}return count, nil
}
并发实现:Worker pooling pattern(工作池模式)是一种并发设计模式,用于管理一组固定数量的工作线程(worker threads)。这些工作线程从一个共享的工作队列中获取任务,并执行它们。这个模式的主要目的是提高并发性能,通过减少线程的创建和销毁,以及通过限制并发执行的任务数量来避免资源竞争。
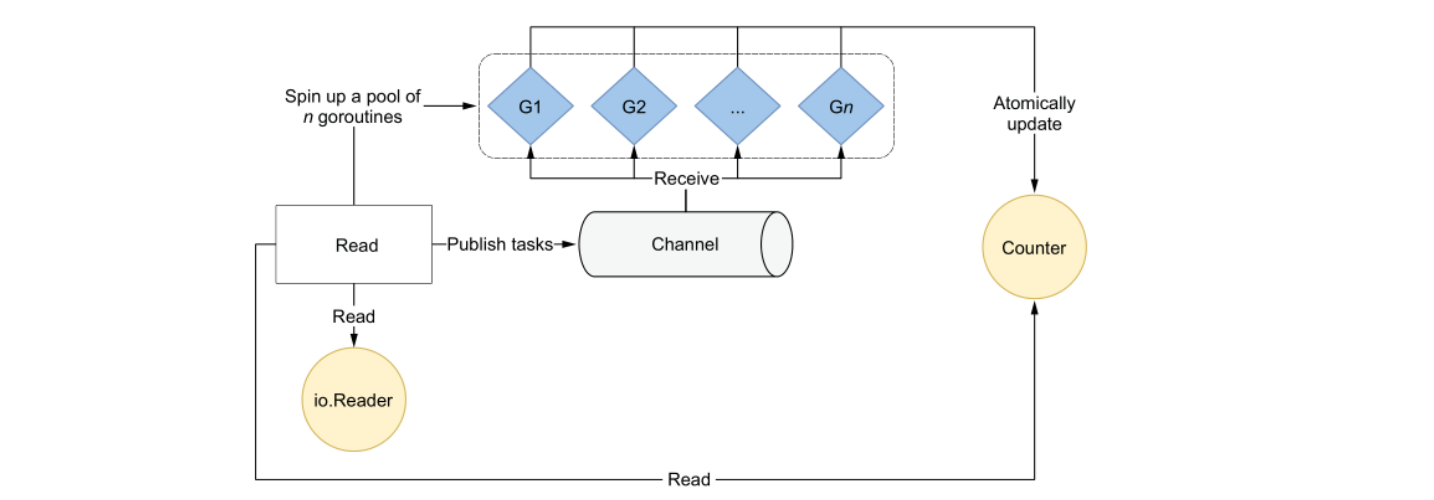
func read(r io.Reader) (int, error) {var count int64wg := sync.WaitGroup{}var n = 10ch := make(chan []byte, n)wg.Add(n)for i := 0; i < n; i++ {go func() {defer wg.Done()for b := range ch {v := tasg(b)atomic.AddInt64(&count, int64(v))}}()}for {b := make([]byte, 1024)ch <- b}close(ch)wg.Wait()return int(count), nil
}
这个例子中,关键在于如何确定 n 的大小:
- 如果工作负载被 IO 约束:则 n 取决于外部系统,使得系统获得最大吞吐量的并发数。
- 如果工作负载被 CPU 约束:最佳实践是取决于 GOMAXPROOCS,这是一个变量存放系统允许分配给执行协程的最大线程数量,默认情况下,这个变量用于设置逻辑 CPU 的数量,因为理想状态下,只能允许最大线程数量的协程同时执行,
8.6 不懂得使用 Go contexts(#60)
🌟 A Context carries a deadline, a cancellation signal, and other values across API boundaries.
截止时间
- time.Duration(250ms)
- time.Time(2024-02-28 00:00:00 UTC)
当截止时间到达的时候,一个正在执行的行为将停止。(如IO请求,等待从 channel 中读取消息)
假设有一个雷达程序,每隔四秒钟,向其他应用提供坐标坐标信息,且只关心最新的坐标。
type publisher interface {Publish(ctx context.Content, position flight.Position) error
}type publishHandler struct {pub publisher
}func (h publishHandler) publishPosition(position flight.Position) error {ctx, cancel := context.WithTimeout(context.Background(), 4*time.Second)defer cancel()return h.pub.Publish(ctx, position)
}
通过上述代码,创建一个过期时间4秒中的 context 上下文,则应用可以通过判断 ctx.Done() 判断这个上下文是否过期或者被取消,从而判断是否为4秒内的有效坐标。
cancel() 在 return 之前调用,则可以通过 cancel 方法关闭上下文,避免内存泄漏。
取消信号
func main() {ctx. cancel := context.WithCancel(context.Background())defer cacel()go func() {CreateFileWatcher(ctx, "foo.txt") }()
}
在 main 方法执行完之前,通过调用 cancel 方法,将 ctx 的取消信号传递给 CreateFileWatcher() 函数。
上下文传递值
ctx := context.WithValue(context.Background(), "key", "value")
fmt.Println(ctx.Value("key"))# value
key 和 value 是 any 类型的。
package providertype key stringconst myCustomKey key = "key"func f(ctx context.Context) {ctx = context.WithValue(ctx, myCustomKey, "foo")// ...
}
为了避免两个不同的 package 对同一个 ctx 存入同样的 key 导致冲突,可以将 key 设置成不允许导出的类型。
一些用法:
- 在借助 ctx 在函数之间传递同一个 id,实现链路追踪。
- 借助 ctx 在多个中间件之间传递,存放处理信息。
type key stringconst inValidHostKey key = "isValidHost"func checkValid(next http.Handler) http.Handler {return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {validHost := r.Host == "came"ctx := context.WithValue(r.Context(), inValidHostKey, validHost)next.ServeHTTP(w, r.WithContext(ctx))})
}
checkValid 作为一个中间件,优先处理 http 请求,将处理结果存放在 ctx 中,传递给下一个处理步骤。
捕获 context 取消
context.Context 类型提供了一个 Done 方法,返回了一个接受关闭信号的 channel:<-chan struct{},触发条件如下:
- 如果 ctx 通过 context.WithCancel 创建,则可以通过 cancel 函数关闭。
- 如果 ctx 通过 context.WithDeadline 创建,当过期的时候 channel 关闭。
此外,context.Context 提供了一个 Err 方法,将返回导致 channel 关闭的原因,如果没有关闭,调用则返回 nil。
- 返回 context.Canceled error 如果 channel 被 cancel 方法关闭。
- 返回 context.DeadlineExceeded 如果达到 deadline 过期。
func handler(ctx context.Context, ch chan Message) error {for {select {case msg := <-ch:// Do something with msgcase <-ctx.Done():return ctx.Err()}}
}
小结
你已完成《Go语言的100个错误》全书学习进度60%,欢迎追更。
相关文章:
Go语言的100个错误使用场景(55-60)|并发基础
前言 大家好,这里是白泽。**《Go语言的100个错误以及如何避免》**是最近朋友推荐我阅读的书籍,我初步浏览之后,大为惊喜。就像这书中第一章的标题说到的:“Go: Simple to learn but hard to master”,整本书通过分析1…...
钉钉机器人发送折线图卡片 工具类代码
钉钉机器人 “创建并投放卡片 接口 ” 可以 发送折线图、柱状图 官方文档:创建并投放卡片 - 钉钉开放平台 0依赖、1模板、2机器人放到内部应用、3放开这个权限 、4工具类、5调用工具类 拼接入参 卡片模板 自己看文档创建,卡片模板的id 有用 0、依赖…...
基于springboot的大型商场应急预案管理系统论文
大型商场应急预案管理系统 摘要 随着信息技术在管理上越来越深入而广泛的应用,管理信息系统的实施在技术上已逐步成熟。本文介绍了大型商场应急预案管理系统的开发全过程。通过分析大型商场应急预案管理系统管理的不足,创建了一个计算机管理大型商场应急…...
强化学习嵌入Transformer(代码实践)
这里写目录标题 ChatGPT的答案GPT4.0 ChatGPT的答案 # 定义Transformer模块 class Transformer(nn.Module):def __init__(self, input_dim, hidden_dim, num_heads, num_layers):super(Transformer, self).__init__()self.encoder_layer nn.TransformerEncoderLayer(d_modeli…...

决定西弗吉尼亚州地区版图的关键历史事件
决定西弗吉尼亚州地区版图的关键历史事件: 1. 内部分裂与美国内战: - 在1861年美国内战爆发时,弗吉尼亚州作为南方邦联的一员宣布退出美利坚合众国。然而,弗吉尼亚州西部的一些县由于经济结构(主要是农业非依赖奴隶制…...

LeetCode_22_中等_括号生成
文章目录 1. 题目2. 思路及代码实现(Python)2.1 暴力法2.2 回溯法 1. 题目 数字 n n n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。 示例 1: 输入: n 3 n 3 …...
Verilog(未完待续)
Verilog教程 这个教程写的很好,可以多看看。本篇还没整理完。 一、Verilog简介 什么是FPGA?一种可通过编程来修改其逻辑功能的数字集成电路(芯片) 与单片机的区别?对单片机编程并不改变其地电路的内部结构࿰…...

【Linux实践室】Linux初体验
🌈个人主页:聆风吟 🔥系列专栏:Linux实践室、网络奇遇记 🔖少年有梦不应止于心动,更要付诸行动。 文章目录 一. ⛳️任务描述二. ⛳️相关知识2.1 🔔Linux 目录结构介绍2.2 🔔Linux …...

Flutter中高级JSON处理:使用json_serializable进行深入定制
Flutter中高级JSON处理 使用json_serializable库进行深入定制 - 文章信息 - Author: 李俊才 (jcLee95) Visit me at: https://jclee95.blog.csdn.netEmail: 291148484163.com. Shenzhen ChinaAddress of this article:https://blog.csdn.net/qq_28550263/article/details/1363…...

华为OD技术面试案例4-2024年
个人情况:985本,目标院校非计算机专业,情况比较特殊,23年11月研究生退学,电子信息类专业。 初识od:10月底打算退学的时候在智联、BOSS上疯狂投硬件方面的岗位。投了大概一两天后有德科和HW的HR打电话给我介…...
 重试机制与监听器的使用)
【TestNG】(4) 重试机制与监听器的使用
在UI自动化测试用例执行过程中,经常会有很多不确定的因素导致用例执行失败,比如网络原因、环境问题等,所以我们有必要引入重试机制(失败重跑),来提高测试用例成功率。 在不写代码的情况没有提供可配置方式…...

“智农”-高标准农田
高标准农田是指通过土地整治、土壤改良、水利设施、农电配套、机械化作业等措施,提升农田质量和生产能力,达到田块平整、集中连片、设施完善、节水高效、宜机作业、土壤肥沃、生态友好、抗灾能力强、与现代农业生产和经营方式相适应的旱涝保收、稳产高产…...
方法在网页中快速查找元素)
利用 lxml 库的XPath()方法在网页中快速查找元素
XPath() 函数是 lxml 库中 Element 对象的方法。在使用 lxml 库解析 HTML 或 XML 文档时,您可以通过创建 Element 对象来表示文档的元素,然后使用 Element 对象的 XPath() 方法来执行 XPath 表达式并选择相应的元素。 具体而言,XPath() 方法是…...
nginx---------------重写功能 防盗链 反向代理 (五)
一、重写功能 rewrite Nginx服务器利用 ngx_http_rewrite_module 模块解析和处理rewrite请求,此功能依靠 PCRE(perl compatible regular expression),因此编译之前要安装PCRE库,rewrite是nginx服务器的重要功能之一,重写功能(…...

unity shaderGraph实例-物体线框显示
文章目录 本项目基于URP实现一,读取UV网格,由自定义shader实现效果优缺点效果展示模型准备整体结构各区域内容区域1区域2区域3区域4shader属性颜色属性材质属性后处理 实现二,直接使用纹理,使用默认shader实现优缺点贴图准备材质准…...
分类问题经典算法 | 二分类问题 | Logistic回归:公式推导
目录 一. Logistic回归的思想1. 分类任务思想2. Logistic回归思想 二. Logistic回归算法:线性可分推导 一. Logistic回归的思想 1. 分类任务思想 分类问题通常可以分为二分类,多分类任务;而对于不同的分类任务,训练的主要目标是…...
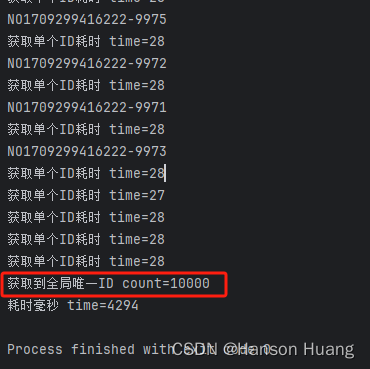
redis实现分布式全局唯一id
目录 一、前言二、如何通过Redis设计一个分布式全局唯一ID生成工具2.1 使用 Redis 计数器实现2.2 使用 Redis Hash结构实现 三、通过代码实现分布式全局唯一ID工具3.1 导入依赖配置3.2 配置yml文件3.3 序列化配置3.4 编写获取工具3.5 测试获取工具 四、运行结果 一、前言 在很…...

Sora引发安全新挑战
文章目录 前言一、如何看待Sora二、Sora加剧“深度伪造”忧虑三、Sora无法区分对错四、滥用导致的安全危机五、Sora面临的安全挑战总结前言 今年2月,美国人工智能巨头企业OpenAI再推行业爆款Sora,将之前ChatGPT以图文为主的生成式内容全面扩大到视频领域,引发了全球热议,这…...

Android 14.0 Launcher3定制化之桌面分页横线改成圆点显示功能实现
1.前言 在14.0的系统rom产品定制化开发中,在进行launcher3的定制化中,在双层改为单层的开发中,在原生的分页 是横线,而为了美观就采用了系统原来的另外一种分页方式,就是圆点比较美观,接下来就来分析下相关…...
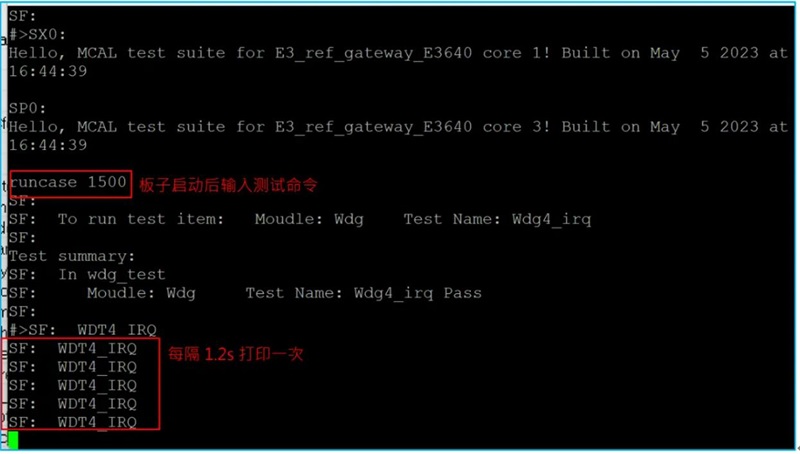
SemiDrive E3 MCAL 开发系列(3)– Wdg 模块的使用
一、 概述 本文将会介绍 SemiDrive E3 MCAL Wdg 模块的基本配置,并且会结合实际操作的介绍,帮助新手快速了解并掌握这个模块的使用,文中的 MCAL 是基于 PTG3.0 的版本,开发板是官方的 E3640 网关板。 二、 Wdg 模块的主要配置 …...

百考通:AI精准赋能答辩PPT,让零散的想法智能生成为结构化内容
毕业季、开题季,一份专业出彩的PPT是顺利通过答辩的关键。但从论文中提炼核心观点、规划答辩逻辑、设计美观版式,往往让学生们焦头烂额。百考通(https://www.baikaotongai.com) 凭借AI技术深度赋能,打造出一站式答辩PP…...
)
Kandinsky-5.0-I2V-Lite-5s效果展示:AI生成插画→动态叙事短片(5秒内完成情绪传递)
Kandinsky-5.0-I2V-Lite-5s效果展示:AI生成插画→动态叙事短片(5秒内完成情绪传递) 1. 开箱即用的动态叙事工具 Kandinsky-5.0-I2V-Lite-5s是一款让人眼前一亮的轻量级图生视频模型。它最吸引人的特点是:你只需要准备一张静态插…...

从零入门性能测试:理论+JMETER实操,看完就能上手铝
一、环境准备 Free Spire.Doc for Python 是免费 Python 文档处理库,无需依赖 Microsoft Word,支持 Word 文档的创建、编辑、转换等操作,其中内置的 Markdown 解析能力,能高效实现 Markdown 到 Doc/Docx 格式的转换,且…...

TJA1042T待机模式省电秘籍:独立VIO供电与VCC关闭的实测功耗对比
TJA1042T待机模式省电秘籍:独立VIO供电与VCC关闭的实测功耗对比 在电池供电的车载传感器和远程数据记录仪等场景中,每一微安的电流都关乎设备续航。TJA1042T作为NXP经典的CAN收发器,其待机模式下仅需VIO供电的特性,为超低功耗设计…...

基于yolo26算法的大坝缺陷识别 智慧水利工程监测 防寒抗洪监测 水坝安全防护监测 水利工程安全监测 坝体结构状态分析第10428期
数据集说明一、核心信息概览项目详情类别数量及中文名称2 类,分别为: 裂缝、剥落数据总量1400 条(图像数据)数据集格式种类YOLO 格式最重要应用价值支持大坝坝段实例分割模型训练,为水利工程安全监测、坝体结构状态分析…...
]—东方仙盟)
东方仙盟神识训练工具专业训练-[AI人工智能(八十七)]—东方仙盟
{ "intent": "buy", "param": { "房号": "8" }, "text": "给872房间送一瓶拖鞋" }东方仙盟自己研发模型识别错误修正Overfitting & Hot Plugging Model (English Version)1. The Core Contradictio…...

motionEye 存储管理优化:自动清理与云备份策略终极指南
motionEye 存储管理优化:自动清理与云备份策略终极指南 【免费下载链接】motioneye A web frontend for the motion daemon. 项目地址: https://gitcode.com/gh_mirrors/mo/motioneye motionEye 是一款强大的 motion 守护进程 Web 前端工具,能帮助…...

SWTP_CodecLib:轻量级NRF24L01无线协议编解码库
1. SWTP_CodecLib 项目概述SWTP_CodecLib 是一个面向 NRF24L01 射频收发芯片的轻量级通信协议编解码库,其核心目标并非驱动硬件本身,而是为基于 NRF24L01 构建的自定义无线通信系统提供一套结构化、可复用的数据封包与解析机制。该库不依赖特定 MCU 平台…...

轻量级嵌入式电机控制库:面向差速机器人的裸机PWM驱动方案
1. 项目概述Simple_Robot_Motor_Control 是一个面向嵌入式机器人平台的轻量级电机控制库,专为资源受限的微控制器(如 STM32F0/F1、ESP32-C3、nRF52832 或 ATmega328P)设计。其核心目标并非提供工业级运动控制算法,而是以极简接口抽…...

Cogito 3B镜像免配置教程:预置中文Prompt Engineering最佳实践库
Cogito 3B镜像免配置教程:预置中文Prompt Engineering最佳实践库 1. 快速了解Cogito 3B模型 Cogito v1预览版是Deep Cogito推出的混合推理模型系列,这个3B版本在大多数标准基准测试中都表现出色,超越了同等规模下最优的开源模型。这意味着即…...