【数仓】Hadoop集群配置常用参数说明
Hadoop集群中,需要配置的文件主要包括四个
-
配置核心Hadoop参数:
- 编辑
core-site.xml文件,设置Hadoop集群的基本参数,如文件系统、Hadoop临时目录等。
- 编辑
-
配置HDFS参数:
- 编辑
hdfs-site.xml文件,设置HDFS的相关参数,如数据块大小、副本数等。
- 编辑
-
配置MapReduce参数(如果使用):
- 编辑
mapred-site.xml文件,设置MapReduce的相关参数。
- 编辑
-
配置YARN参数(如果使用):
- 编辑
yarn-site.xml文件,设置YARN的相关参数。
- 编辑
核心Hadoop参数 core-site.xml
参考官网
Hadoop的core-site.xml文件包含了许多重要的配置参数,这些参数用于定义Hadoop集群的全局设置。以下是一些常见的core-site.xml配置参数:
| 配置项 | 默认值 | 说明 |
|---|---|---|
fs.defaultFS | 无 | Hadoop集群的NameNode的URI。这是HDFS的入口点。 |
io.file.buffer.size | 4096 | SequenceFiles在读写过程中可以使用的缓存大小(以字节为单位)。 |
hadoop.tmp.dir | /tmp/hadoop-${user.name} | Hadoop的临时目录,用于存储临时文件和目录。 |
fs.trash.interval | 0 | 垃圾箱中文件的保留时间(以分钟为单位)。设置为大于0的值将启用垃圾箱功能。 |
hadoop.proxyuser.${username}.hosts | 无 | 允许代理用户从哪些主机连接到Hadoop集群。 |
hadoop.proxyuser.${username}.groups | 无 | 允许代理用户属于哪些用户组连接到Hadoop集群。 |
fs.trash.checkpoint.interval | 0 | 检查垃圾箱并删除过期文件的间隔时间(以分钟为单位)。 |
fs.automatic.close | true | 是否在读取文件后自动关闭文件系统。 |
fs.dummy.impl | org.apache.hadoop.fs.DummyFileSystem | 一个假的文件系统实现,用于测试。 |
请注意,上述表格中的默认值可能会因Hadoop版本和特定环境而有所不同。此外,还有许多其他可用的配置参数,具体取决于您的Hadoop集群的需求和配置。
在实际配置中,您应该根据您的Hadoop集群的具体要求和网络环境来设置这些参数。一些关键参数(如fs.defaultFS)在集群设置中是必需的,而其他参数则可以根据需要进行调整。在修改core-site.xml文件之前,请确保您已经充分了解每个参数的含义和潜在影响。
HDFS参数 hdfs-site.xml
参考官网
hdfs-site.xml 是 Hadoop 分布式文件系统(HDFS)的配置文件,它包含了许多参数,用于定义 HDFS 的行为和特性。以下是一些常见的 hdfs-site.xml 配置参数:
| 配置项 | 默认值 | 说明 |
|---|---|---|
dfs.namenode.name.dir | file://${hadoop.tmp.dir}/dfs/name | NameNode 存储其持久化元数据的本地文件系统路径。 |
dfs.datanode.data.dir | file://${hadoop.tmp.dir}/dfs/data | DataNode 存储其块的本地文件系统路径。 |
dfs.replication | 3 | 数据的默认副本数。 |
dfs.permissions.enabled | true | 是否启用 HDFS 权限检查。 |
dfs.block.size | 134217728 (128 MB) | HDFS 块的大小。 |
dfs.namenode.handler.count | 10 | NameNode 服务器可以同时处理的客户端请求数。 |
dfs.datanode.handler.count | 10 | DataNode 服务器可以同时处理的客户端请求数。 |
dfs.client.read.shortcircuit | false | 允许 DFS 客户端绕过 DataNode 直接读取本地文件。 |
dfs.client.read.shortcircuit.skip.checksum | false | 在短路读取时跳过校验和检查。 |
dfs.https.address | 0.0.0.0:50470 | NameNode HTTPS 服务的地址和端口。 |
dfs.http.address | 0.0.0.0:50070 | NameNode HTTP 服务的地址和端口。 |
dfs.datanode.http.address | 0.0.0.0:50075 | DataNode HTTP 服务的地址和端口。 |
dfs.datanode.ipc.address | 0.0.0.0:50020 | DataNode IPC 服务的地址和端口。 |
dfs.namenode.http-address | 0.0.0.0:50070 | NameNode HTTP 服务的地址和端口(用于 Web UI)。 |
dfs.namenode.secondary.http-address | 0.0.0.0:50090 | Secondary NameNode HTTP 服务的地址和端口。 |
请注意,这些默认值可能会因 Hadoop 的版本和特定环境而有所不同。此外,还有许多其他可用的配置参数,具体取决于您的 HDFS 集群的需求和配置。
在实际配置中,您应该根据您的 HDFS 集群的具体要求和网络环境来设置这些参数。一些关键参数(如 dfs.namenode.name.dir 和 dfs.datanode.data.dir)在集群设置中是必需的,而其他参数则可以根据需要进行调整。在修改 hdfs-site.xml 文件之前,请确保您已经充分了解每个参数的含义和潜在影响。
此外,请注意 hdfs-site.xml 文件通常还包含一些高级参数,用于调优 HDFS 的性能和可靠性,例如设置 NameNode 和 DataNode 的堆大小、调整各种超时设置等。这些参数的具体设置应该基于您的集群规模和工作负载进行调整。
MapReduce参数 mapred-site.xml
参考官网
mapred-site.xml 是 Hadoop MapReduce 的配置文件,它包含了许多参数,用于定义 MapReduce 作业的行为和特性。以下是一些常见的 mapred-site.xml 配置参:
| 配置项 | 默认值 | 说明 |
|---|---|---|
mapreduce.framework.name | local | 执行框架设置为本地模式(单机模式),在集群上应设置为 yarn。 |
mapreduce.jobhistory.address | 0.0.0.0:10020 | MapReduce JobHistory Server 的地址和端口。 |
mapreduce.jobhistory.webapp.address | 0.0.0.0:19888 | MapReduce JobHistory Server 的 Web UI 地址和端口。 |
mapreduce.jobtracker.address | local | MapReduce JobTracker 的地址和端口(旧版 API,YARN 中不再使用)。 |
mapreduce.tasktracker.address | 0.0.0.0:50060 | MapReduce TaskTracker 的地址和端口(旧版 API,YARN 中不再使用)。 |
mapreduce.map.output.compress | false | 是否压缩 Map 任务的输出。 |
mapreduce.map.output.compress.codec | org.apache.hadoop.io.compress.DefaultCodec | Map 任务输出压缩使用的编解码器。 |
mapreduce.task.io.sort.mb | 100 | 排序时使用的内存缓冲区大小(以 MB 为单位)。 |
mapreduce.task.io.sort.factor | 10 | 合并小文件时一次合并的流的数量。 |
mapreduce.reduce.shuffle.parallelcopies | 5 | 从 Map 到 Reduce 拷贝数据的并行度。 |
mapreduce.reduce.shuffle.fetch.retry.enabled | true | 是否启用 shuffle 阶段获取数据的重试机制。 |
mapreduce.reduce.shuffle.retry-delay.ms | 1000 | shuffle 阶段重试之间的延迟时间(以毫秒为单位)。 |
mapreduce.reduce.shuffle.input.buffer.percent | 0.7 | shuffle 阶段用于存储数据的内存比例。 |
mapreduce.job.reduces | 1 | 每个作业的默认 Reduce 任务数。 |
mapreduce.job.maps | 无默认值 | 每个作业的 Map 任务数(通常由 AM 根据数据自动计算)。 |
mapreduce.map.speculative | true | 是否启用 Map 任务的推测执行。 |
mapreduce.reduce.speculative | true | 是否启用 Reduce 任务的推测执行。 |
请注意,这些默认值可能会因 Hadoop 的版本和特定环境而有所不同。此外,还有许多其他可用的配置参数,具体取决于您的 MapReduce 作业的需求和配置。
在实际配置中,您应该根据您的 MapReduce 作业的具体要求和网络环境来设置这些参数。一些关键参数(如 mapreduce.framework.name)在集群设置中是必需的,以指定执行框架,而其他参数则可以根据需要进行调整。在修改 mapred-site.xml 文件之前,请确保您已经充分了解每个参数的含义和潜在影响。
另外,值得注意的是,随着 Hadoop 的发展,MapReduce 已经被 YARN 和其他框架(如 Spark、Flink)所取代,因此在新版本的 Hadoop 中,mapred-site.xml 文件可能不再存在,或者其重要性已经降低。在使用新版本的 Hadoop 时,请确保查看相关文档以了解最新的配置方法和最佳实践。
YARN参数 yarn-site.xml
参考官网
yarn-site.xml 是 Apache Hadoop YARN 的配置文件,它包含了许多参数,用于定义 YARN 集群的行为和特性。以下是一些常见的 yarn-site.xml 配置参数:
| 配置项 | 默认值 | 说明 |
|---|---|---|
yarn.resourcemanager.hostname | 无 | ResourceManager 的主机名。 |
yarn.resourcemanager.scheduler.address | ${yarn.resourcemanager.hostname}:8030 | ResourceManager 调度器服务的地址和端口。 |
yarn.resourcemanager.resource-tracker.address | ${yarn.resourcemanager.hostname}:8031 | ResourceManager 资源追踪服务的地址和端口。 |
yarn.resourcemanager.address | ${yarn.resourcemanager.hostname}:8032 | ResourceManager RPC 服务的地址和端口。 |
yarn.resourcemanager.webapp.address | ${yarn.resourcemanager.hostname}:8088 | ResourceManager Web UI 的地址和端口。 |
yarn.resourcemanager.admin.address | ${yarn.resourcemanager.hostname}:8033 | ResourceManager 管理服务的地址和端口。 |
yarn.scheduler.minimum-allocation-mb | 1024 | 单个容器可申请的最小内存(以 MB 为单位)。 |
yarn.scheduler.maximum-allocation-mb | 8192 | 单个容器可申请的最大内存(以 MB 为单位)。 |
yarn.nodemanager.resource.memory-mb | 8192 | NodeManager 可用的总物理内存(以 MB 为单位)。 |
yarn.scheduler.minimum-allocation-vcores | 1 | 单个容器可申请的最小虚拟 CPU 个数。 |
yarn.scheduler.maximum-allocation-vcores | 32 | 单个容器可申请的最大虚拟 CPU 个数。 |
yarn.nodemanager.vmem-pmem-ratio | 2.1 | 虚拟内存与物理内存的比例。 |
yarn.nodemanager.local-dirs | ${hadoop.tmp.dir}/nm-local-dir | NodeManager 存储本地化资源的目录列表。 |
yarn.nodemanager.log-dirs | ${yarn.log.dir}/userlogs | NodeManager 存储容器日志的目录列表。 |
yarn.nodemanager.aux-services | mapreduce_shuffle | NodeManager 提供的辅助服务列表。 |
yarn.nodemanager.remote-app-log-dir | /tmp/logs | 存储应用程序日志的远程目录(通常用于日志聚合)。 |
yarn.nodemanager.recovery.enabled | false | 是否启用 NodeManager 恢复功能。 |
yarn.nodemanager.recovery.dir | 无 | 用于存储 NodeManager 恢复数据的目录。 |
请注意,这些默认值可能会因 Hadoop 的版本和特定环境而有所不同。此外,还有许多其他可用的配置参数,具体取决于您的 YARN 集群的需求和配置。在实际配置中,您应该根据您的 YARN 集群的具体要求和网络环境来设置这些参数。在修改 yarn-site.xml 文件之前,请确保您已经充分了解每个参数的含义和潜在影响。
参考
- https://hadoop.apache.org/docs/r3.3.6/index.html
相关文章:

【数仓】Hadoop集群配置常用参数说明
Hadoop集群中,需要配置的文件主要包括四个 配置核心Hadoop参数: 编辑core-site.xml文件,设置Hadoop集群的基本参数,如文件系统、Hadoop临时目录等。 配置HDFS参数: 编辑hdfs-site.xml文件,设置HDFS的相关参…...
【go从入门到精通】什么是go?为什么要选择go?
go的出生: go语言(或Golang)是Google开发的开源编程语言,诞生于2006年1月2日下午15点4分5秒,于2009年11月开源,2012年发布go稳定版。Go语言在多核并发上拥有原生的设计优势,Go语言从底层原生支持…...

MySQL篇—执行计划介绍(第二篇,总共三篇)
☘️博主介绍☘️: ✨又是一天没白过,我是奈斯,DBA一名✨ ✌✌️擅长Oracle、MySQL、SQLserver、Linux,也在积极的扩展IT方向的其他知识面✌✌️ ❣️❣️❣️大佬们都喜欢静静的看文章,并且也会默默的点赞收藏加关注❣…...
nest.js使用nest-winston日志一
nest-winston文档 nest-winston - npm 参考:nestjs中winston日志模块使用 - 浮的blog - SegmentFault 思否 安装 cnpm install --save nest-winston winstoncnpm install winston-daily-rotate-file 在main.ts中 import { NestFactory } from nestjs/core; im…...
)
LeetCode刷题笔记之二叉树(四)
一、二叉搜索树的应用 1. 700【二叉搜索树中的搜索】 题目: 给定二叉搜索树(BST)的根节点 root 和一个整数值 val。你需要在 BST 中找到节点值等于 val 的节点。 返回以该节点为根的子树。 如果节点不存在,则返回 null 。代码&a…...
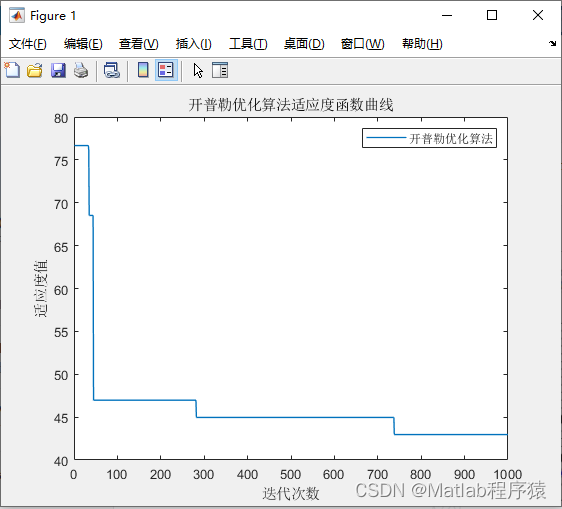
【MATLAB源码-第150期】基于matlab的开普勒优化算法(KOA)机器人栅格路径规划,输出做短路径图和适应度曲线。
操作环境: MATLAB 2022a 1、算法描述 开普勒优化算法(Kepler Optimization Algorithm, KOA)是一个虚构的、灵感来自天文学的优化算法,它借鉴了开普勒行星运动定律的概念来设计。在这个构想中,算法模仿行星围绕太阳的…...
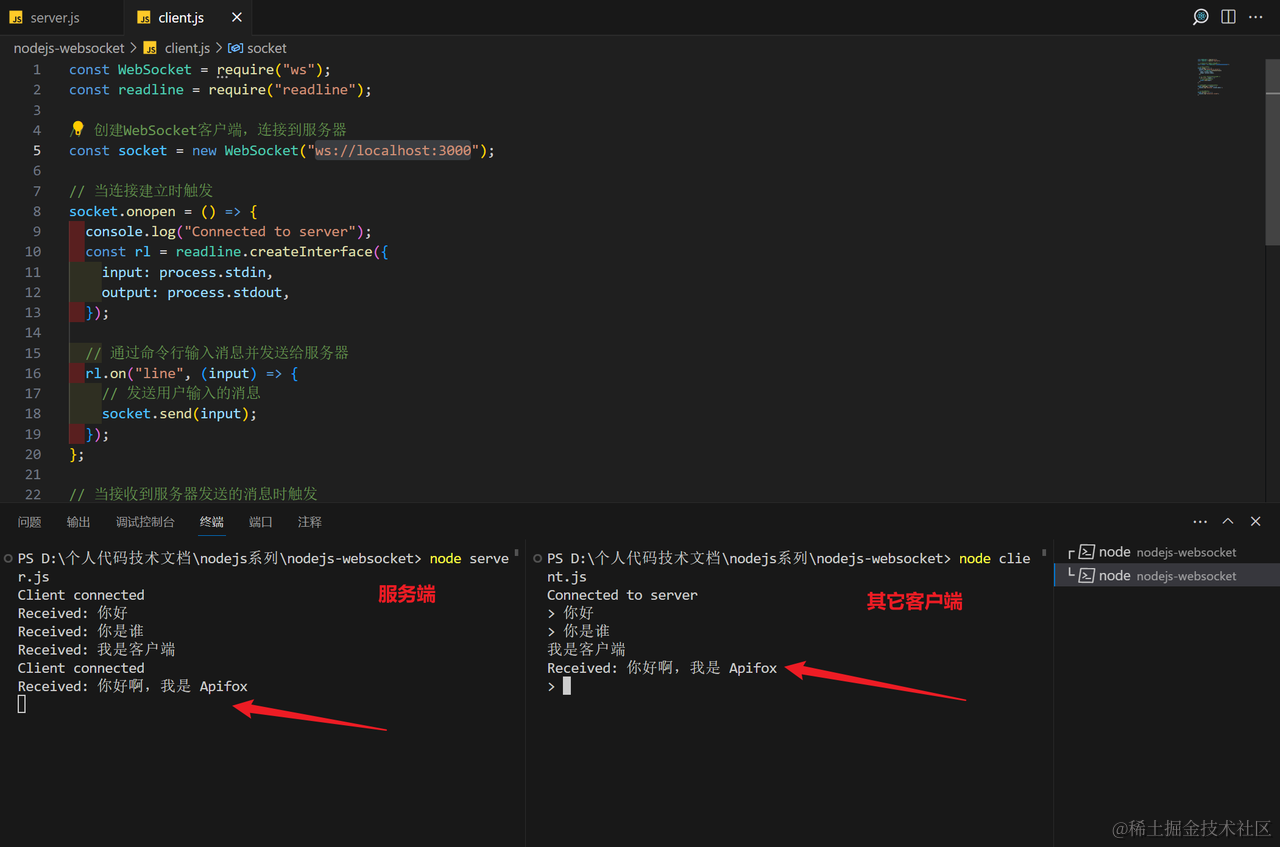
最佳实践:Websocket 长连接状态如何保持
WebSocket 是一种支持通过单个 TCP 连接进行全双工通信的协议,相较于传统的 HTTP 协议,它更适合需要实时交互的应用场景。此协议在现代 Web 应用中扮演着至关重要的角色,尤其是在需要实时更新和通信的场合下维持持久连接。本文将探讨 WebSock…...

Unity AStar寻路算法与导航
在游戏开发中,寻路算法是一个非常重要的部分,它决定了游戏中角色的移动路径。Unity作为一款流行的游戏开发引擎,提供了许多内置的寻路算法,其中最常用的就是AStar算法。AStar算法是一种基于图的搜索算法,通过启发式搜索…...

JavaScript最新实现城市级联操作,json格式的数据
前置知识: <button onclick"doSelect()">操作下拉列表</button><hr>学历:<select id"degree"><option value"0">--请选择学历--</option><option value"1">专科<…...

SD NAND:为车载显示器注入智能与安全的心脏
SD NAND 在车载显示器的应用 在车载显示器上,SD NAND(Secure Digital NAND)可以有多种应用,其中一些可能包括: 导航数据存储: SD NAND 可以用于存储地图数据、导航软件以及车载系统的相关信息。这有助于提…...

矩阵的对角化
概述 对角化矩阵是线性代数中的一个重要概念,它涉及将一个方阵转换成一个对角阵,这个对角阵与原矩阵相似,其主要对角线上的元素为原矩阵的特征值。这样的转换简化了很多数学问题,特别是线性动力系统的求解和矩阵的幂运算。下面是…...

React编写组件时,如何省略.tsx后缀
省略.tsx后缀 当tsconfig.json配置了,需要重启后才会生效 {"compilerOptions": {"allowJs": true,"jsx": "react-jsx",} }当进行以上配置后,导入组件时添加后缀,Eslint报错如下: An im…...

移动端的React项目中如何配置自适应和px转rem
创建项目 create-react-app project-name 启动项目 npm start 下载自适应和px转rem的插件 自适应的: npm install lib-flexible --save px转rem的:npm install postcss-pxtorem5.1.1 --save-dev 创建craco.config.js配置文件 在package.json中…...

TypeScript 结合 React 开发时候 , React.FunctionComponent 解释
在 TypeScript 结合 React 开发时,React.FC(或 React.FunctionComponent)是一个泛型类型,它用于定义函数组件的类型。这个类型定义了函数组件的结构和预期行为,并且提供了泛型支持,以便你可以指定组件 prop…...
#困难,想不到)
2280. 最优标号(最小割,位运算)#困难,想不到
活动 - AcWing 给定一个无向图 G(V,E),每个顶点都有一个标号,它是一个 [0,2^31−1] 内的整数。 不同的顶点可能会有相同的标号。 对每条边 (u,v),我们定义其费用 cost(u,v) 为 u 的标号与 v 的标号的异或值。 现在我们知道一些顶点的标号…...
RestTemplate启动问题解决
⭐ 作者简介:码上言 ⭐ 代表教程:Spring Boot vue-element 开发个人博客项目实战教程 ⭐专栏内容:个人博客系统 ⭐我的文档网站:http://xyhwh-nav.cn/ RestTemplate启动问题解决 问题:在SpringCloud架构项目中配…...

Docker部署前后端服务示例
使用Docker部署js前端 1.创建Dockerfile 在项目跟目录下创建Dockerfile文件: # 使用nginx作为基础镜像 FROM nginx:1.19.1# 指定工作空间 WORKDIR /data/web# 将 yarn build 打包后的build文件夹添加到工作空间 ADD build build# 将项目必要文件添加到工作空间&a…...
方格分割644--2017蓝桥杯
1.用dfs解决,首先这题的方格图形就很像一个走迷宫的类型,迷宫想到dfs,最中心点视为起点,起点有两个小人在这个方格里面对称行动,直到走出迷宫(一个人走出来了另一个人就也走出来了,而走过的点会…...

接口测试用例设计注意点
API接口测试: 1>根据接口文档,检查接口调用方法post/get,状态码、请求值、返回值 2>对请求参数做容错、边界值、等价类校验 3>功能可用,用户友好 4>密码加密,http明文,https协议密文 5>业务…...
-4)
学习linux从0到工程师(命令)-4
基本命令 uname -m 显示机器的处理器架构 uname -r 显示正在使用的内核版本 dmidecode -q 显示硬件系统部件 (SMBIOS / DMI) hdparm -i /dev/hda 罗列一个磁盘的架构特性 hdparm -tT /dev/sda 在磁盘上执行测试性读取操作系统信息 arch 显示机器的处理器架构 uname -m 显示机器…...
 —— 涉及知识点之Seata(2))
软考架构设计师论文 —— 论面向服务架构设计及其应用(5) —— 涉及知识点之Seata(2)
接前一篇文章:软考架构设计师论文 —— 论面向服务架构设计及其应用(4) —— 涉及知识点之Seata(1) 本文内容参考: Seata 是什么? | Apache Seata Seata分布式事务 (理论与部署相结合)-腾讯云开发者社区-腾讯云 特此致谢! 3. Seata架构 Seata事务管理中有三个重要的…...

B站缓存视频转换终极指南:m4s转MP4的快速免费解决方案
B站缓存视频转换终极指南:m4s转MP4的快速免费解决方案 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经遇到过这样的困扰&a…...

开源大模型Phi-4-mini-reasoning横向评测:性能、成本与易用性深度分析
开源大模型Phi-4-mini-reasoning横向评测:性能、成本与易用性深度分析 1. 评测背景与模型概览 在开源大模型生态快速发展的当下,Phi-4-mini-reasoning作为一款轻量级推理模型引起了开发者社区的广泛关注。这款由微软研究院开源的模型,定位在…...

Qwen3-0.6B-FP8惊艳效果:古文翻译+白话解释+典故溯源三重输出展示
Qwen3-0.6B-FP8惊艳效果:古文翻译白话解释典故溯源三重输出展示 1. 引言:当小模型遇上大智慧 你可能听过很多关于大模型的传说,动辄几百亿参数,需要顶级显卡才能跑起来。但今天我想给你看一个不太一样的家伙——Qwen3-0.6B-FP8。…...

开发者实操手册:HY-MT1.8B通过Chainlit构建对话界面
开发者实操手册:HY-MT1.8B通过Chainlit构建对话界面 1. 开篇:为什么你需要一个翻译对话界面? 想象一下,你正在开发一个多语言应用,或者需要处理大量跨语言的文档。传统的翻译工具要么是网页版,要么是API调…...

BEYOND REALITY Z-Image精彩案例分享:无磨皮、无失真、通透肤质生成作品
BEYOND REALITY Z-Image精彩案例分享:无磨皮、无失真、通透肤质生成作品 1. 项目概述 BEYOND REALITY Z-Image是一款专注于高精度写实人像生成的AI创作引擎,基于Z-Image-Turbo底座和BEYOND REALITY SUPER Z IMAGE 2.0 BF16专属模型打造。这个模型专门针…...

Rust的闭包特征实现与函数指针转换在C接口回调中的安全包装
Rust的闭包特征与函数指针转换在C接口回调中的安全包装 Rust作为一门注重安全与性能的系统级语言,常被用于与C语言交互的场景。在调用C库时,回调函数是常见的需求,但Rust的闭包与C的函数指针存在本质差异,如何安全地将闭包转换为…...

下一个任务-----利用辅助服务自动关掉app广告
这应该也比较容易吧。--------我自己用总可以吧-----我还要把这个给他开源出来...

ESP32/ESP8266接入Ambient云平台实战指南
1. Ambient ESP32/ESP8266 库技术解析:面向嵌入式物联网的数据上云实践Ambient 是一款专为物联网设备设计的轻量级云端数据可视化服务,其核心价值在于将嵌入式终端采集的传感器数据,通过极简协议上传至云端,并自动生成实时、可配置…...

嵌入式三角函数查表法:原理、实现与工业优化
1. 三角函数查表法技术原理与嵌入式实现详解1.1 查表法在嵌入式系统中的工程价值在资源受限的嵌入式MCU(如Cortex-M0/M3、8051、AVR)上,实时计算sin/cos/tan等三角函数存在显著瓶颈:浮点运算单元缺失或性能低下、数学库࿰…...