【自然语言处理】【大模型】大语言模型BLOOM推理工具测试
相关博客
【自然语言处理】【大模型】大语言模型BLOOM推理工具测试
【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型
【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍
【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型
【自然语言处理】【大模型】PaLM:基于Pathways的大语言模型
【自然语言处理】【chatGPT系列】大语言模型可以自我改进
【自然语言处理】【ChatGPT系列】WebGPT:基于人类反馈的浏览器辅助问答
【自然语言处理】【ChatGPT系列】FLAN:微调语言模型是Zero-Shot学习器
【自然语言处理】【ChatGPT系列】ChatGPT的智能来自哪里?
【自然语言处理】【ChatGPT系列】大模型的涌现能力
BLOOM的原理见【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型
BLOOM是由HuggingFace推出的大模型,其参数量达到176B(GPT-3是175B)。目前超过100B参数量且能够支持中文的开源大模型只有BLOOM和GLM-130B。由于HuggingFace是著名开源工具Transformers的开发公司,很多推理工具都会支持Transformers中的模型。
LLM(大语言模型)推理的两个问题:(1) 单张显卡无法容纳整个模型;(2) 推理速度太慢。本文初步整理了一些推理大模型的工具和代码,并简单测试了推理速度。下面是本文测试的一些背景:
-
目前是2023年2月
-
使用7B模型bloom-7b1-mt
-
4张3090(但在实际推理中仅使用2张3090)
-
依赖包的版本
transformers==4.26.0 tensor-parallel==1.0.24 deepspeed==0.7.7 bminf==2.0.1
零、辅助函数
# utils.py
import numpy as npfrom time import perf_counterdef measure_latency(model, tokenizer, payload, device, generation_args={}):input_ids = tokenizer(payload, return_tensors="pt").input_ids.to(device)latencies = []# 预热for _ in range(2):_ = model.generate(input_ids, **generation_args)# 统计时间for _ in range(10):start_time = perf_counter()_ = model.generate(input_ids, **generation_args)latency = perf_counter() - start_timelatencies.append(latency)# 计算统计量time_avg_ms = 1000 * np.mean(latencies) # 延时均值time_std_ms = 1000 * np.std(latencies) # 延时方差time_p95_ms = 1000 * np.percentile(latencies,95) # 延时的95分位数return f"P95延时 (ms) - {time_p95_ms}; 平均延时 (ms) - {time_avg_ms:.2f} +\- {time_std_ms:.2f};"def infer(model, tokenizer, payload, device):input_ids = tokenizer(payload, return_tensors="pt").input_ids.to(device)logits = model.generate(input_ids, num_beams=1, max_length=512)out = tokenizer.decode(logits[0].tolist())return out
一、层并行
BLOOM是Huggingface开发的,所以在transformers库中提供了支持。具体来说,在使用from_pretrained加载模型时,指定参数devce_map即可。其通过将模型的不同层放置在不同的显卡上,从而将单个大模型分拆至多张卡上(流水线并行也会将层分拆,然后采用流水线的方式训练模型)。下面是调用的示例代码:
# layer_parallel_test.py
import os
import transformersfrom utils import measure_latency, infer
from transformers import AutoTokenizer, AutoModelForCausalLMtransformers.logging.set_verbosity_error()
os.environ['CUDA_VISIBLE_DEVICES'] = "0,1"def run():model_name = "bigscience/bloomz-7b1-mt"payload = """参考下面的文章,然后用与文章相同的语言回答问题: 段落:当细菌突破免疫系统的防御而开始增生时,疾病会由结核菌感染进展到症状明显的结核病。在原发型结核病 (占 1-5% 的比例),这种现象会在感染刚开始的时候很快的发生。然而>多数人感染模式为潜伏结核感染,通常没有明显症状。在5-10%潜伏结合感染的案例中,这些休眠的细菌经常会在感染后数年的时间制造出活动的结核。 问题:What is the next stage after TB infection?"""tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")model = model.eval()out = infer(model, tokenizer, payload, model.device)print("="*70+" 模型输入输出 "+"="*70)print(f"模型输入: {payload}")print(f"模型输出: {out}")print("\n\n"+"="*70+" 模型延时测试 "+"="*70)print(measure_latency(model, tokenizer, payload, model.device))print("\n\n"+"="*70+" 显存占用 "+"="*70)print(os.system("nvidia-smi"))if __name__ == "__main__":run()pass
模型的时延结果:
P95延时 (ms) - 118.402308691293; 平均延时 (ms) - 117.72 +- 0.58;
显存占用:
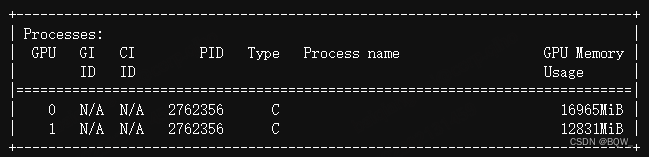
二、张量并行
张量并行是将矩阵乘法进行分块,从而将大矩阵拆分为更小的矩阵,这样就能把不同的矩阵放置在不同的显卡上。(具体原理会在后续的文章中介绍)
这里使用开源工具包tensor_parallel来实现。
# tensor_parallel_test.py
import os
import transformers
import tensor_parallel as tpfrom utils import measure_latency, infer
from transformers import AutoTokenizer, AutoModelForCausalLMtransformers.logging.set_verbosity_error()
os.environ['CUDA_VISIBLE_DEVICES'] = "0,1"def run():model_name = "bigscience/bloomz-7b1-mt"payload = """参考下面的文章,然后用与文章相同的语言回答问题: 段落:当细菌突破免疫系统的防御而开始增生时,疾病会由结核菌感染进展到症状明显的结核病。在原发型结核病 (占 1-5% 的比例),这种现象会在感染刚开始的时候很快的发生。然而>多数人感染模式为潜伏结核感染,通常没有明显症状。在5-10%潜伏结合感染的案例中,这些休眠的细菌经常会在感染后数年的时间制造出活动的结核。 问题:What is the next stage after TB infection?"""tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(model_name, low_cpu_mem_usage=True)model = tp.tensor_parallel(model, ["cuda:0", "cuda:1"])model = model.eval()out = infer(model, tokenizer, payload, model.device)print("="*70+" 模型输入输出 "+"="*70)print(f"模型输入: {payload}")print(f"模型输出: {out}")print("\n\n"+"="*70+" 模型延时测试 "+"="*70)print(measure_latency(model, tokenizer, payload, model.device))print("\n\n"+"="*70+" 显存占用 "+"="*70)print(os.system("nvidia-smi"))if __name__ == "__main__":run()pass
模型的时延结果:
P95延时 (ms) - 91.34029923006892; 平均延时 (ms) - 90.66 +- 0.46;
显存占用:
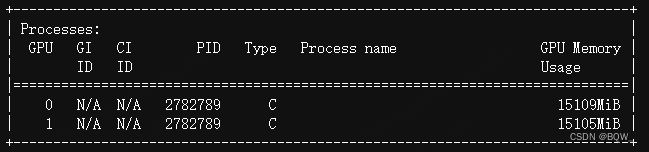
三、模型量化
原理见【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍。
量化是一种常见的模型压缩技术,核心思想是将模型参数从高精度转换为低精度。在BLOOM上使用8-bit量化只需要在调用from_pretrained时,设置参数load_in_8bit=True, device_map="auto"。
(注:bloom在实现量化时,会按照是否超越阈值来分拆矩阵,然后对低于阈值的模型参数进行量化,这会拖慢推理速度)
# int8_test.py
import os
import transformersfrom utils import measure_latency, infer
from transformers import AutoTokenizer, AutoModelForCausalLMtransformers.logging.set_verbosity_error()
os.environ['CUDA_VISIBLE_DEVICES'] = "0,1"def run():model_name = "bigscience/bloomz-7b1-mt"payload = """参考下面的文章,然后用与文章相同的语言回答问题: 段落:当细菌突破免疫系统的防御而开始增生时,疾病会由结核菌感染进展到症状明显的结核病。在原发型结核病 (占 1-5% 的比例),这种现象会在感染刚开始的时候很快的发生。然而>多数人感染模式为潜伏结核感染,通常没有明显症状。在5-10%潜伏结合感染的案例中,这些休眠的细菌经常会在感染后数年的时间制造出活动的结核。 问题:What is the next stage after TB infection?"""max_memory_mapping = {0: "24GB", 1: "0GB"}tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(model_name, load_in_8bit=True, device_map="auto", max_memory=max_memory_mapping)model = model.eval()out = infer(model, tokenizer, payload, model.device)print("="*70+" 模型输入输出 "+"="*70)print(f"模型输入: {payload}")print(f"模型输出: {out}")print("\n\n"+"="*70+" 模型延时测试 "+"="*70)print(measure_latency(model, tokenizer, payload, model.device))print("\n\n"+"="*70+" 显存占用 "+"="*70)print(os.system("nvidia-smi"))if __name__ == "__main__":run()pass
模型的时延结果:
P95延时 (ms) - 147.89210632443428; 平均延时 (ms) - 143.30 +- 3.02;
显存占用:
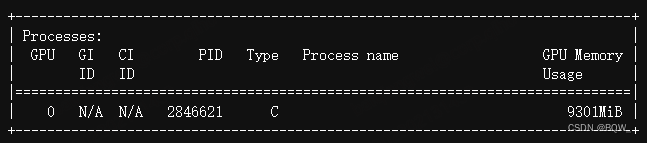
四、DeepSpeed-Inference
DeepSpeed-Inference是分布式训练工具DeepSpeed中用户模型推理的功能。
# deepspeed_test.py
import os
import torch
import deepspeed
import transformersfrom utils import measure_latency, infer
from transformers import AutoTokenizer, AutoModelForCausalLMtransformers.logging.set_verbosity_error()
os.environ['CUDA_VISIBLE_DEVICES'] = "0,1"def run():model_name = "bigscience/bloomz-7b1-mt"payload = """参考下面的文章,然后用与文章相同的语言回答问题: 段落:当细菌突破免疫系统的防御而开始增生时,疾病会由结核菌感染进展到症状明显的结核病。在原发型结核病 (占 1-5% 的比例),这种现象会在感染刚开始的时候很快的发生。然而>多数人感染模式为潜伏结核感染,通常没有明显症状。在5-10%潜伏结合感染的案例中,这些休眠的细菌经常会在感染后数年的时间制造出活动的结核。 问题:What is the next stage after TB infection?"""tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16)model = deepspeed.init_inference(model=model, # Transformers模型mp_size=2, # 模型并行数量dtype=torch.float16, # 权重类型(fp16)replace_method="auto", # 让DS自动替换层replace_with_kernel_inject=True, # 使用kernel injector替换)out = infer(model, tokenizer, payload, model.module.device)print("="*70+" 模型输入输出 "+"="*70)print(f"模型输入: {payload}")print(f"模型输出: {out}")print("\n\n"+"="*70+" 模型延时测试 "+"="*70)print(measure_latency(model, tokenizer, payload, model.module.device))print("\n\n"+"="*70+" 显存占用 "+"="*70)print(os.system("nvidia-smi"))if __name__ == "__main__":run()pass
这里不能使用python来自动脚本,需要使用下面的命令:
deepspeed --num_gpus 2 --master_port 60000 deepspeed_test.py
模型的时延结果:
P95延时 (ms) - 31.88958093523979; 平均延时 (ms) - 30.75 +- 0.64;
显存占用:
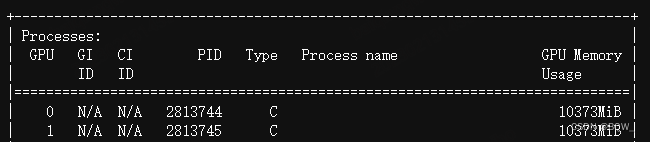
五、BMInf
BMInf能够在单张显卡下加载完整的模型,但是推理速度非常慢(应该是利用了Offload技术)。
import os
import bminf
import transformersfrom utils import measure_latency, infer
from transformers import AutoTokenizer, AutoModelForCausalLMtransformers.logging.set_verbosity_error()
os.environ['CUDA_VISIBLE_DEVICES'] = "0,1"def run():model_name = "bigscience/bloomz-7b1-mt"payload = """参考下面的文章,然后用与文章相同的语言回答问题: 段落:当细菌突破免疫系统的防御而开始增生时,疾病会由结核菌感染进展到症状明显的结核病。在原发型结核病 (占 1-5% 的比例),这种现象会在感染刚开始的时候很快的发生。然而>多数人感染模式为潜伏结核感染,通常没有明显症状。在5-10%潜伏结合感染的案例中,这些休眠的细菌经常会在感染后数年的时间制造出活动的结核。 问题:What is the next stage after TB infection?"""tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(model_name, low_cpu_mem_usage=True)model = model.eval()model = bminf.wrapper(model, quantization=False, memory_limit=8 << 30)out = infer(model, tokenizer, payload, model.device)print("="*70+" 模型输入输出 "+"="*70)print(f"模型输入: {payload}")print(f"模型输出: {out}")print("\n\n"+"="*70+" 模型延时测试 "+"="*70)print(measure_latency(model, tokenizer, payload, model.device))print("\n\n"+"="*70+" 显存占用 "+"="*70)print(os.system("nvidia-smi"))if __name__ == "__main__":run()pass
模型的时延结果:
P95延时 (ms) - 719.2403690889478; 平均延时 (ms) - 719.05 +- 0.14;
显存占用:
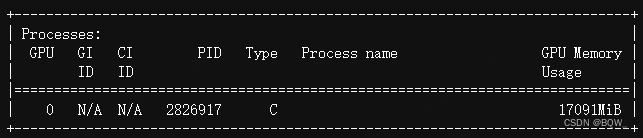
六、结论
- DeepSpeed-Inference的速度是最快的;
- 张量并行比自带的层并行快一些;
- 8 bit量化虽然速度慢一些,但是能够实现单卡推理;
- BMInf虽然速度最慢,但是其可能在不损失模型精度的情况下,单卡推理;
说明
- 本文并不是这些推理工具的最佳实践,仅是罗列和展示这些工具如何使用;
- 这些工具从不同的角度来优化模型推理,对于希望进一步了解具体如何实现的人来说,可以阅读源代码;
相关文章:
【自然语言处理】【大模型】大语言模型BLOOM推理工具测试
相关博客 【自然语言处理】【大模型】大语言模型BLOOM推理工具测试 【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型 【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍 【自然语言处理】【大模型】BLOOM:一个176B参数…...
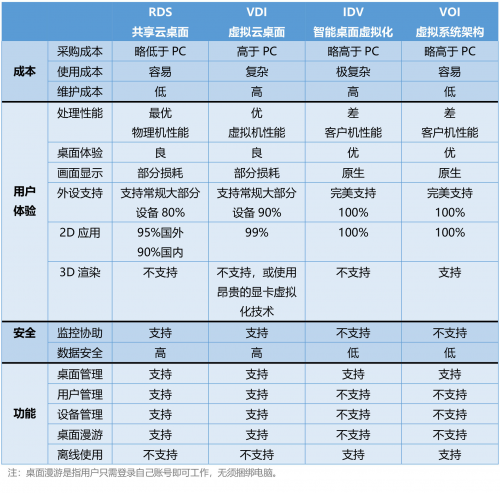
云桌面技术初识:VDI,IDV,VOI,RDS
VDI(Virtual Desktop Infrastucture,虚拟桌面架构),俗称虚拟云桌面 VDI构架采用的“集中存储、集中运算”构架,所有的桌面以虚拟机的方式运行在服务器硬件虚拟化层上,桌面以图像传输的方式发送到客户端。 …...

基于本地centos构建gdal2.4.4镜像
1.前言 基于基础镜像构建gdal环境一般特别大,一般少则1.6G,多则2G甚至更大,这对于镜像的迁移造成了极大的不便。究其原因在于容器中有大量的源码文件以及编译中间过程文件,还要大量编译需要的yum库。本文主要通过在centos系统上先…...

生产环境线程问题排查
线程状态的解读RUNNABLE线程处于运行状态,不一定消耗CPU。例如,线程从网络读取数据,大多数时间是挂起的,只有数据到达时才会重新唤起进入执行状态。只有Java代码显式调用sleep或wait方法时,虚拟机才可以精准获取到线程…...

Day908.joinsnljdist和group问题和备库自增主键问题 -MySQL实战
join&snlj&dist和group问题和备库自增主键问题 Hi,我是阿昌,今天学习记录的是关于join&snlj&dist和group问题和备库自增主键问题的内容。 一、join 的写法 join 语句怎么优化?中,在介绍 join 执行顺序的时候&am…...

算法 - 剑指Offer 丑数
题目 我们把只包含质因子 2、3 和 5 的数称作丑数(Ugly Number)。求按从小到大的顺序的第 n 个丑数。 解题思路 这题我使用最简单方法去做, 首先我们可以获取所有2n,3n,5*n的丑数,只是我们这里暂时无法排序,并且可能…...
【ONE·C || 文件操作】
总言 C语言:文件操作。 文章目录总言1、文件是什么?为什么需要文件?1.1、为什么需要文件?1.2、文件是什么?2、文件的打开与关闭2.1、文件指针2.2、文件打开和关闭:fopen、fclose2.3、文件使用方式3、文…...
cmd窗口中java命令报错。错误:找不到或无法加载主类 java的jdk安装过程中踩过的坑
错误: 找不到或无法加载主类 HelloWorld 遇到这个问题时,我尝试过网上其他人的做法。有试过添加classpath,也有试过删除classpath。但是依然报错,这里javac可以编译通过,说明代码应该是没有问题的。只是在运行是出现了错误。我安装…...
)
Breathwork(呼吸练习)
查了下呼吸练习相关内容,做个记录。我又在油管学习啦。 喜欢在you. tube看一些self-help相关的内容。比如学习方法、拉伸、跑步、力量举、自重锻炼等等。 总是听Obi Vicent说起Breathwork,比如: My 6am Morning Routine | New Healthy Habit…...
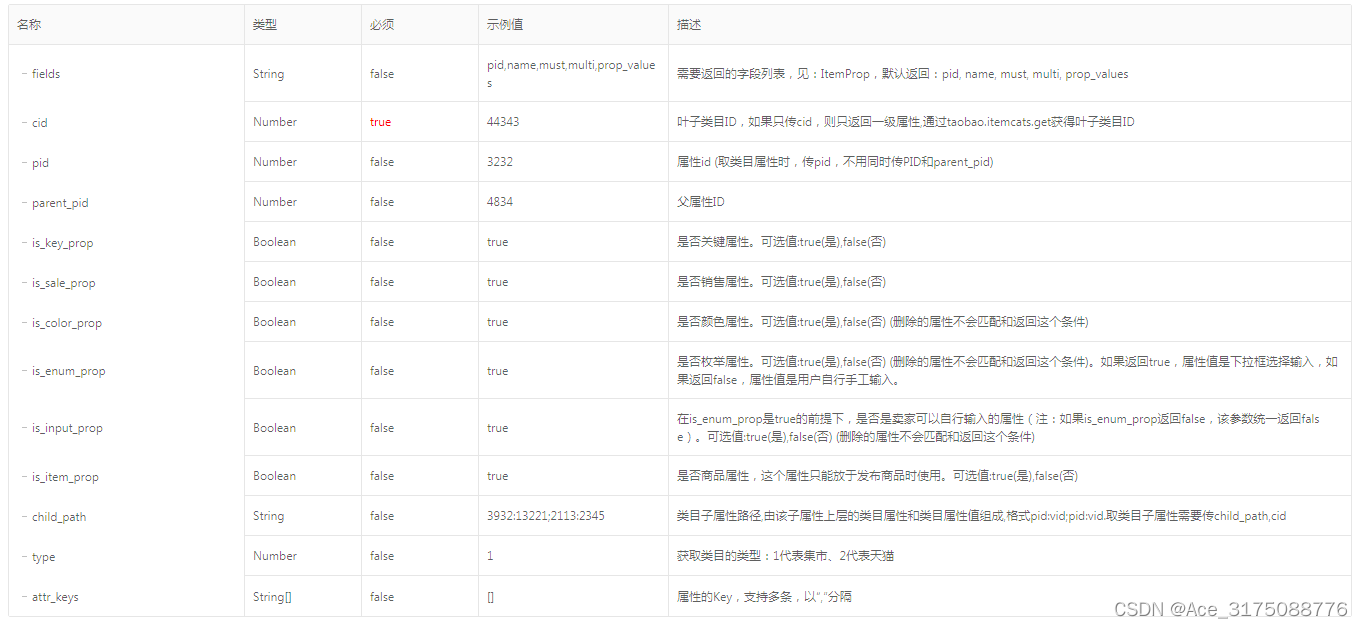
taobao.itemprops.get( 获取标准商品类目属性 )
¥开放平台基础API不需用户授权 通过设置必要的参数,来获取商品后台标准类目属性,以及这些属性里面详细的属性值prop_values。 公共参数 请求地址: HTTP地址 http://gw.api.taobao.com/router/rest 公共请求参数: 公共响应参数: 请求参数 点…...
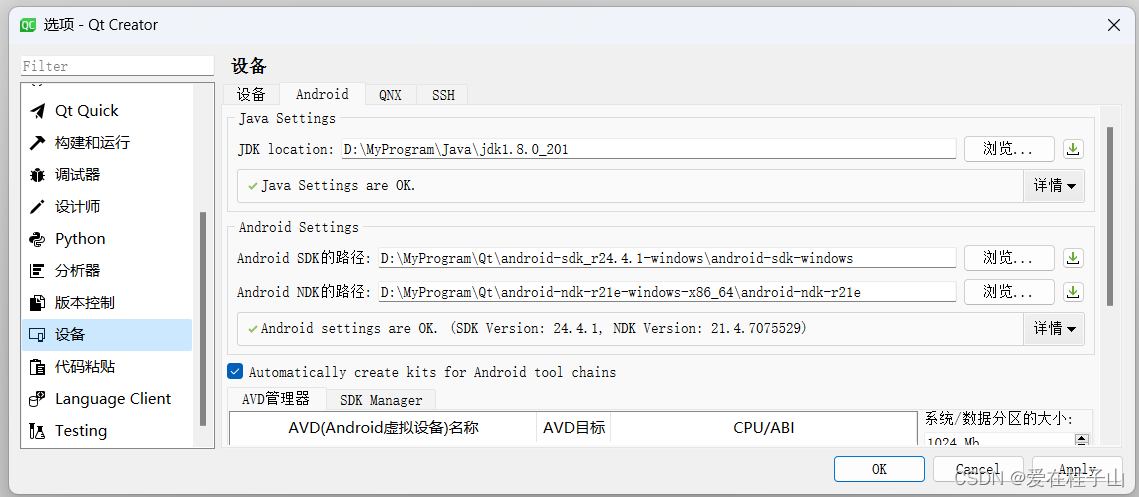
QT配置安卓环境(保姆级教程)
目录 下载环境资源 JDK1.8 NDK SDK 安装QT 配置环境 下载环境资源 JDK1.8 介绍JDK是Java开发的核心工具,为Java开发者提供了一套完整的开发环境,包括开发工具、类库和API等,使得开发者可以高效地编写、测试和运行Java应用程序。 下载…...
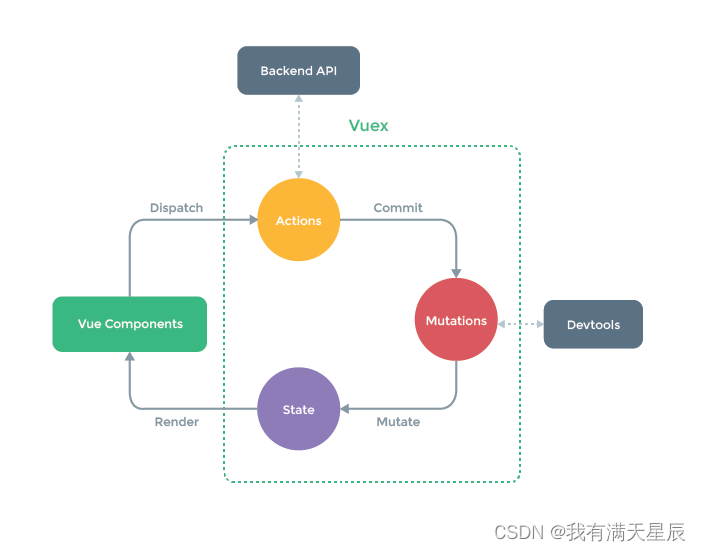
【uni-app教程】八、UniAPP Vuex 状态管理
八、UniAPP Vuex 状态管理 概念 Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式。它采用集中式存储管理应用的所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生变化。 应用场景 Vue多个组件之间需要共享数据或状态。 关键规则 State:…...
)
同花顺测试面经(30min)
大概三十分钟,面试官人还挺好的 1.自我介绍 2.详细问你了自我介绍中的一个实习经历 3.对我们公司有什么了解 !!(高频) 4.对测试有什么看法,为什么选测试 5.黑盒白盒分别是什么 6.对测试左移有什么看法…...

C++-简述#ifdef、#else、#endif和#ifndef的作用
回答如下: #ifdef,#else,#endif和#ifndef都是预处理指令,用于条件编译。#ifdef:这个指令用来判断一个宏是否已经被定义过,如果已经定义过,则执行后面的代码块。#else:这个指令一般与…...

VictoriaMetrics 集群部署
官网 ## 官网 https://github.com/VictoriaMetrics/VictoriaMetrics 集群角色详解 VictoriaMetrics 集群模式。主要由 vmstorage ,vminsert,vmselect 三部分组成,这三个组件每个组件都可以单独进行扩展。其中: vmstorage 负责提供数据存储服务vminsert 是数据存…...
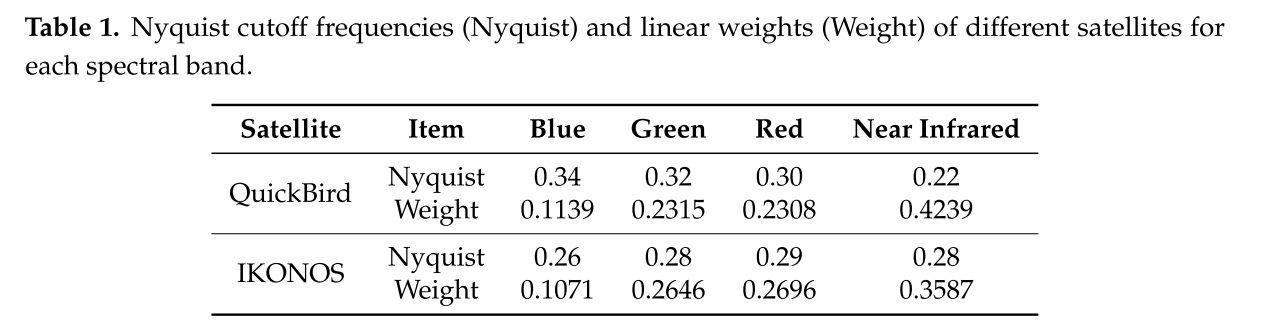
【基于感知损失的无监督泛锐化】
PercepPan: Towards Unsupervised Pan-Sharpening Based on Perceptual Loss (PercepPan:基于感知损失的无监督泛锐化) 在基于神经网络的全色锐化文献中,作为地面实况标签的高分辨率多光谱图像通常是不可用的。为了解决这个问题…...

在vercel上用streamlit部署网站
Verce和Streamlit都是非常流行的Web应用程序部署平台。以下是从零开始在Vercel上部署Streamlit应用程序的一些基本步骤。 安装 Streamlit 在本地计算机上安装Streamlit。可以轻松地通过在命令行中运行以下命令来安装: pip install streamlit为 Streamlit 应用程序…...
| 含思路)
华为OD机试题 - 斗地主(JavaScript)| 含思路
更多题库,搜索引擎搜 梦想橡皮擦华为OD 👑👑👑 更多华为OD题库,搜索引擎搜 梦想橡皮擦 华为OD 👑👑👑 更多华为机考题库,搜索引擎搜 梦想橡皮擦华为OD 👑👑👑 华为OD机试题 最近更新的博客使用说明本篇题解:斗地主题目输入输出描述示例一输入输出示例二输…...
-计算clock速度相关的内核API)
i.MX8MP平台开发分享(clock篇)-计算clock速度相关的内核API
专栏目录:专栏目录传送门 平台内核i.MX8MP5.15.71文章目录 clk消费者clk生产者clk_set_rateclk_round_rateclk_pll1443x_recalc_rate这一篇我们具体来看看其他驱动如何使用clock,这里以lcdif驱动为例。 IMX8MP_CLK_MEDIA_BLK_CTRL_LCDIF_PIXEL是门控时钟,名为pix,这个门控时…...
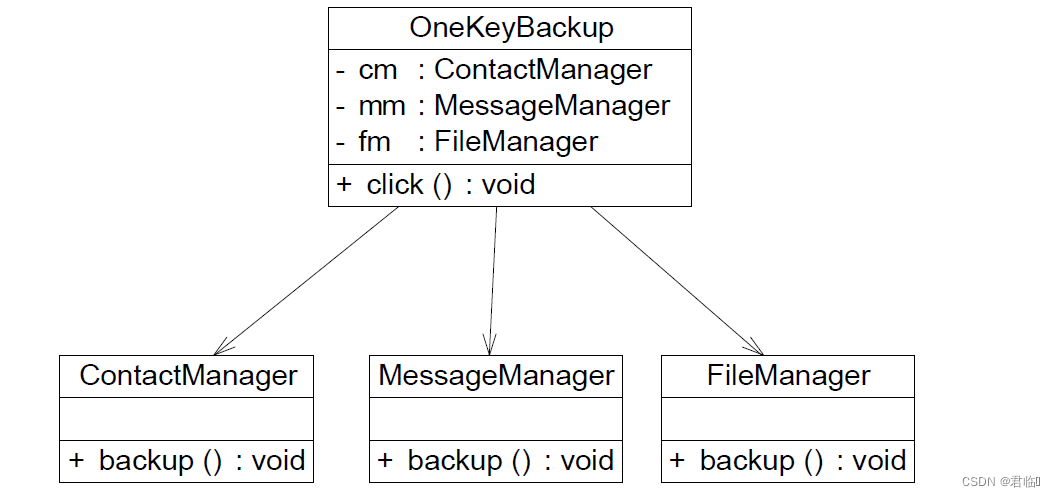
实验4 设计模式实验3
实验内容: 1. 某软件公司为新开发的智能手机控制与管理软件提供了一键备份功能,通 过该功能可以将原本存储在手机中的通信录、短信、照片、歌曲等资料一次性全 部拷贝到移动存储介质(例如MMC 卡或SD 卡)中。在实现过程中需要与多个 已有的类进行交互,例如通讯录管理类、短信…...

鸿蒙开发实战:HDC工具在本地模拟器中的高效调试技巧
1. HDC工具入门:鸿蒙开发的瑞士军刀 第一次接触HDC工具时,我把它当成了鸿蒙版的ADB。但用久了才发现,这个看似简单的命令行工具,其实是鸿蒙开发的万能钥匙。HDC全称Huawei Device Connector,就像它的名字一样ÿ…...

RK Android14 开机自启APP分析与使用
文章目录 前言 一、功能补丁 二、如何使用 1. 应用补丁 2. 设置自启动应用 3. 获取应用包名和Activity 4. 验证 总结 前言 根据客户需要,有时需要设置第三方的apk进行开机自启动。 一、功能补丁 功能分析: 系统启动完成后,自动启动系统属性 persist.sys.start.app 中配置的…...

Native代码与Java的交互艺术——访问字段、调用方法
在 Android 开发、高性能计算或遗留系统整合中,Java 与 Native 代码(C/C)的交互(JNI)是不可或缺的技能。本文将以实战为导向,详细讲解如何在 Native 层访问 Java 对象字段、调用实例与静态方法、处理字符串…...

嵌入式开发语言选择:C与C++的实战对比
1. 嵌入式开发语言选择的核心考量在嵌入式系统开发领域,C和C的争论已经持续了数十年。作为一名在工业控制和消费电子领域工作多年的嵌入式工程师,我见证了从8位单片机到多核处理器的演进过程。选择开发语言绝非简单的技术偏好问题,而是需要综…...

生产环境Python 3.14 JIT崩溃率突增400%?,资深SRE团队紧急封存的8个未公开__PyJIT_TraceConfig参数调优组合
第一章:Python 3.14 JIT 编译器性能调优生产环境部署全景图Python 3.14 引入的原生 JIT 编译器(代号 “PyJIT”)标志着 CPython 运行时架构的重大演进。它不再依赖外部工具链(如 Cython 或 Numba),而是以内…...
)
从LVGL菜单组件反推:手搓一个轻量级C语言菜单框架(适合RTOS/单片机)
从LVGL菜单组件反推:手搓一个轻量级C语言菜单框架(适合RTOS/单片机) 在嵌入式开发中,菜单系统是人机交互的重要组成部分。虽然LVGL等GUI库提供了现成的菜单组件,但理解其底层实现原理对于开发资源受限的MCU应用至关重要…...
支持格式优化与LaTeX自动适配)
智能论文生成工具推荐:7款高效平台(含爱毕业aibiye)支持格式优化与LaTeX自动适配
工具快速对比排名(前7推荐) 工具名称 核心功能亮点 处理时间 适配平台 aibiye 学生/编辑双模式降AIGC 1分钟 知网、万方等 aicheck AI痕迹精准弱化查重一体 ~20分钟 知网、格子达、维普 askpaper AIGC率个位数优化 ~20分钟 高校检测规则通…...

插件冲突频发?三招让你的WPS回归清爽
插件冲突频发?三招让你的WPS回归清爽 【免费下载链接】WPS-Zotero An add-on for WPS Writer to integrate with Zotero. 项目地址: https://gitcode.com/gh_mirrors/wp/WPS-Zotero 当你在WPS中处理学术文档时,突然发现工具栏上出现了两个Zotero插…...

如何用免费工具3步完成华硕游戏本终极性能调校:完整指南
如何用免费工具3步完成华硕游戏本终极性能调校:完整指南 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, …...
)
UWB定位算法避坑指南:如何避免常见错误并提升定位精度(含2025最新优化技巧)
UWB定位算法避坑指南:如何避免常见错误并提升定位精度(含2025最新优化技巧) 在工业4.0和智能物联网的浪潮中,超宽带(UWB)技术凭借其厘米级高精度定位能力,正在重塑智能制造、仓储物流和医疗监护…...