python毕设选题 - 大数据商城人流数据分析与可视化 - python 大数据分析
文章目录
- 0 前言
- 课题背景
- 分析方法与过程
- 初步分析:
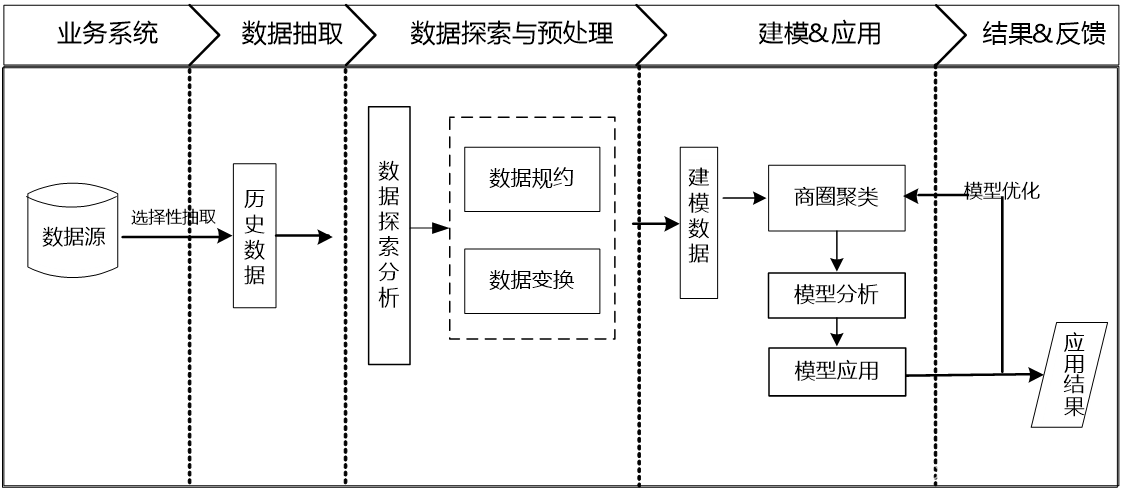
- 总体流程:
- 1.数据探索分析
- 2.数据预处理
- 3.构建模型
- 总结
- 最后
0 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 基于大数据的基站数据分析与可视化
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:3分
课题背景
- 随着当今个人手机终端的普及,出行群体中手机拥有率和使用率已达到相当高的比例,手机移动网络也基本实现了城乡空间区域的全覆盖。根据手机信号在真实地理空间上的覆盖情况,将手机用户时间序列的手机定位数据,映射至现实的地理空间位置,即可完整、客观地还原出手机用户的现实活动轨迹,从而挖掘得到人口空间分布与活动联系特征信息。移动通信网络的信号覆盖从逻辑上被设计成由若干六边形的基站小区相互邻接而构成的蜂窝网络面状服务区,手机终端总是与其中某一个基站小区保持联系,移动通信网络的控制中心会定期或不定期地主动或被动地记录每个手机终端时间序列的基站小区编号信息。
- 商圈是现代市场中企业市场活动的空间,最初是站在商品和服务提供者的产地角度提出,后来逐渐扩展到商圈同时也是商品和服务享用者的区域。商圈划分的目的之一是为了研究潜在的顾客的分布以制定适宜的商业对策。
分析方法与过程
初步分析:
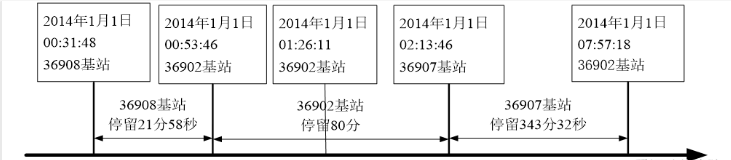
- 手机用户在使用短信业务、通话业务、开关机、正常位置更新、周期位置更新和切入呼叫的时候均产生定位数据,定位数据记录手机用户所处基站的编号、时间和唯一标识用户的EMASI号等。历史定位数据描绘了用户的活动模式,一个基站覆盖的区域可等价于商圈,通过归纳经过基站覆盖范围的人口特征,识别出不同类别的基站范围,即可等同地识别出不同类别的商圈。衡量区域的人口特征可从人流量和人均停留时间的角度进行分析,所以在归纳基站特征时可针对这两个特点进行提取。
总体流程:
1.数据探索分析
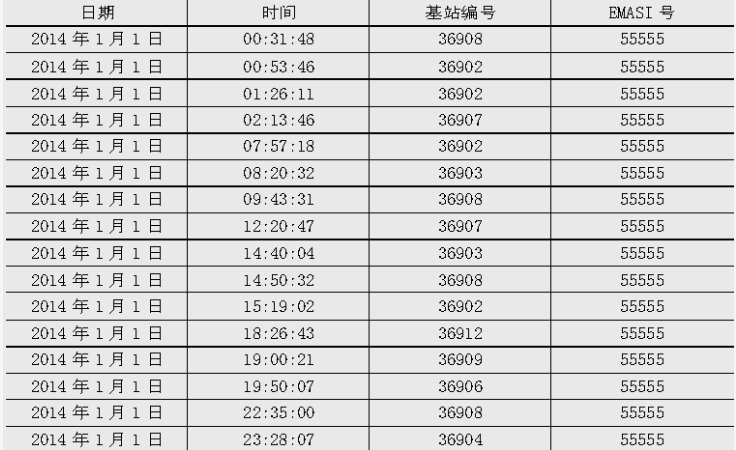
EMASI号为55555的用户在2014年1月1日的定位数据

2.数据预处理
数据规约
- 网络类型、LOC编号和信令类型这三个属性对于挖掘目标没有用处,故剔除这三个冗余的属性。而衡量用户的停留时间并不需要精确到毫秒级,故可把毫秒这一属性删除。
- 把年、月和日合并记为日期,时、分和秒合并记为时间。
import numpy as npimport pandas as pddata=pd.read_excel('C://Python//DataAndCode//chapter14//demo//data//business_circle.xls')# print(data.head())#删除三个冗余属性del data[['网络类型','LOC编号','信令类型']]#合并年月日periods=pd.PeriodIndex(year=data['年'],month=data['月'],day=data['日'],freq='D')data['日期']=periodstime=pd.PeriodIndex(hour=data['时'],minutes=data['分'],seconds=data['秒'],freq='D')data['时间']=timedata['日期']=pd.to_datetime(data['日期'],format='%Y/%m/%d')data['时间']=pd.to_datetime(data['时间'],format='%H/%M/%S')
数据变换
假设原始数据所有用户在观测窗口期间L( 天)曾经经过的基站有 N个,用户有 M个,用户 i在 j天在 num1 基站的工作日上班时间停留时间为
weekday_num1,在 num1 基站的凌晨停留时间为night_num1 ,在num1基站的周末停留时间为weekend_num1, 在
num1基站是否停留为 stay_num1 ,设计基站覆盖范围区域的人流特征:
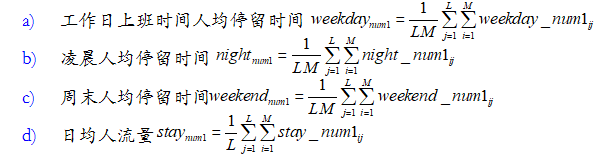

由于各个属性的之间的差异较大,为了消除数量级数据带来的影响,在进行聚类前,需要进行离差标准化处理。
#-*- coding: utf-8 -*-#数据标准化到[0,1]import pandas as pd#参数初始化filename = '../data/business_circle.xls' #原始数据文件standardizedfile = '../tmp/standardized.xls' #标准化后数据保存路径data = pd.read_excel(filename, index_col = u'基站编号') #读取数据data = (data - data.min())/(data.max() - data.min()) #离差标准化data = data.reset_index()data.to_excel(standardizedfile, index = False) #保存结果
3.构建模型
构建商圈聚类模型
采用层次聚类算法对建模数据进行基于基站数据的商圈聚类,画出谱系聚类图。从图可见,可把聚类类别数取3类。
#-*- coding: utf-8 -*-#谱系聚类图import pandas as pd#参数初始化standardizedfile = '../data/standardized.xls' #标准化后的数据文件data = pd.read_excel(standardizedfile, index_col = u'基站编号') #读取数据import matplotlib.pyplot as pltfrom scipy.cluster.hierarchy import linkage,dendrogram#这里使用scipy的层次聚类函数Z = linkage(data, method = 'ward', metric = 'euclidean') #谱系聚类图P = dendrogram(Z, 0) #画谱系聚类图plt.show()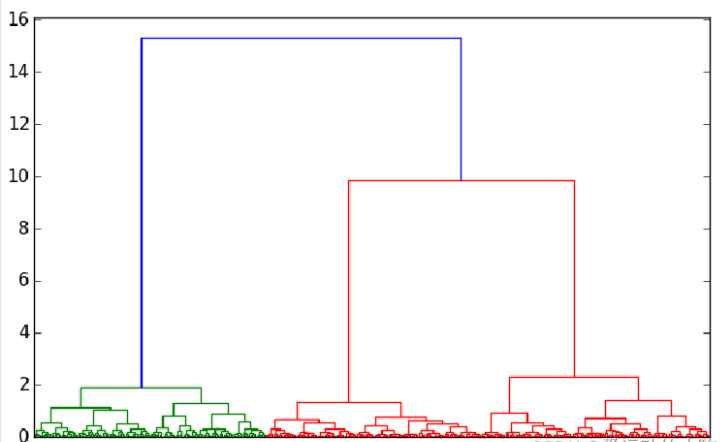
模型分析
针对聚类结果按不同类别画出4个特征的折线图。
#-*- coding: utf-8 -*-#层次聚类算法import pandas as pd#参数初始化standardizedfile = '../data/standardized.xls' #标准化后的数据文件k = 3 #聚类数data = pd.read_excel(standardizedfile, index_col = u'基站编号') #读取数据from sklearn.cluster import AgglomerativeClustering #导入sklearn的层次聚类函数model = AgglomerativeClustering(n_clusters = k, linkage = 'ward')model.fit(data) #训练模型#详细输出原始数据及其类别r = pd.concat([data, pd.Series(model.labels_, index = data.index)], axis = 1) #详细输出每个样本对应的类别r.columns = list(data.columns) + [u'聚类类别'] #重命名表头import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号style = ['ro-', 'go-', 'bo-']xlabels = [u'工作日人均停留时间', u'凌晨人均停留时间', u'周末人均停留时间', u'日均人流量']pic_output = '../tmp/type_' #聚类图文件名前缀for i in range(k): #逐一作图,作出不同样式plt.figure()tmp = r[r[u'聚类类别'] == i].iloc[:,:4] #提取每一类for j in range(len(tmp)):plt.plot(range(1, 5), tmp.iloc[j], style[i])plt.xticks(range(1, 5), xlabels, rotation = 20) #坐标标签plt.title(u'商圈类别%s' %(i+1)) #我们计数习惯从1开始plt.subplots_adjust(bottom=0.15) #调整底部plt.savefig(u'%s%s.png' %(pic_output, i+1)) #保存图片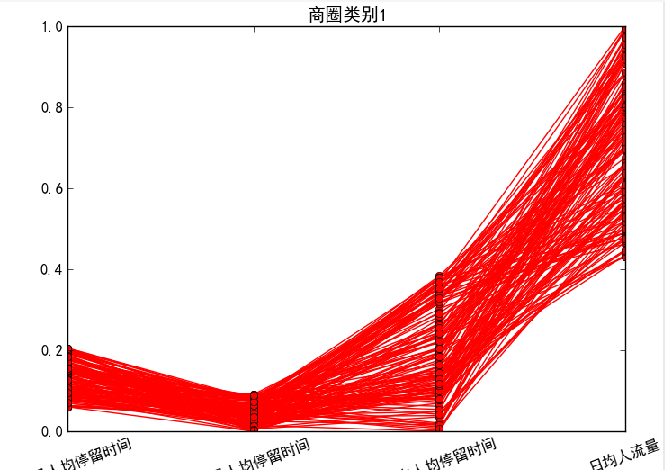
对于商圈类别1,日均人流量较大,同时工作日上班时间人均停留时间、凌晨人均停留时间和周末人均停留时间相对较短,该类别基站覆盖的区域类似于商业区

对于商圈类别2,凌晨人均停留时间和周末人均停留时间相对较长,而工作日上班时间人均停留时间较短,日均人流量较少,该类别基站覆盖的区域类似于住宅区。
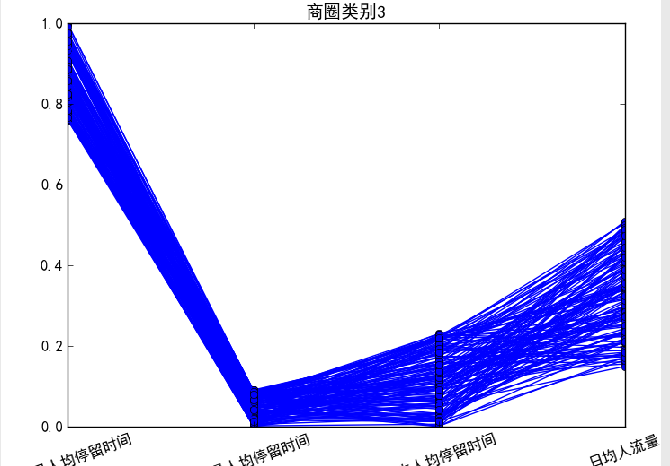
对于商圈类别3,这部分基站覆盖范围的工作日上班时间人均停留时间较长,同时凌晨人均停留时间、周末人均停留时间相对较短,该类别基站覆盖的区域类似于白领上班族的工作区域。
总结
商圈类别2的人流量较少,商圈类别3的人流量一般,而且白领上班族的工作区域一般的人员流动集中在上下班时间和午间吃饭时间,这两类商圈均不利于运营商的促销活动的开展,商圈类别1的人流量大,在这样的商业区有利于进行运营商的促销活动。
最后
相关文章:
python毕设选题 - 大数据商城人流数据分析与可视化 - python 大数据分析
文章目录 0 前言课题背景分析方法与过程初步分析:总体流程:1.数据探索分析2.数据预处理3.构建模型 总结 最后 0 前言 🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到…...

vmware网络负载均衡方式
基于 IP 哈希的路由: 原理: 基于虚拟机的源和目标 IP 地址以及 TCP/UDP 端口号计算哈希值,并使用该哈希值确定出口网络适配器。这样可以确保同一对源和目标的网络流量始终被路由到相同的网络适配器。应用场景: 适用于大量使用虚拟…...

Docker基础教程 - 2 Docker安装
更好的阅读体验:点这里 ( www.doubibiji.com ) 2 Docker安装 Docker 的官网地址:https://www.docker.com/,在官网可以找到 Docker Engine 的安装步骤。 下面进行 Docker 环境的安装,正常情况下 Docker …...
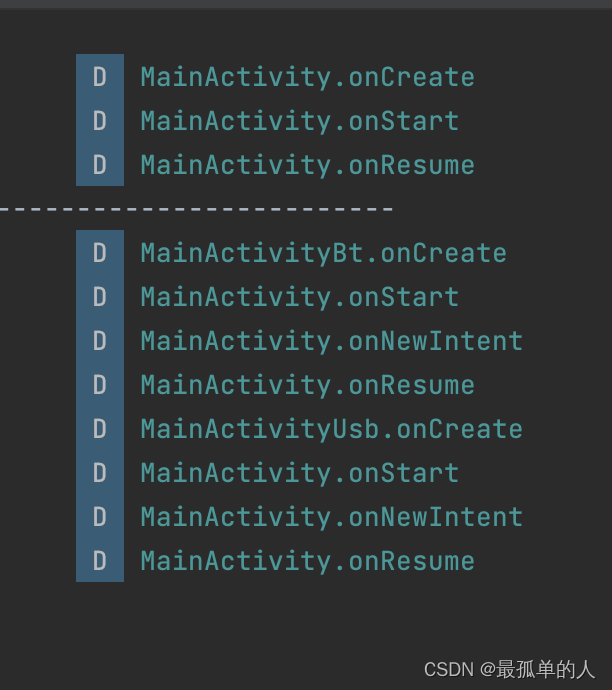
Android 多桌面图标启动, 爬坑点击打开不同页面
备注 : MainActivity 正常带界面的UI MainActivityBt 和 MainActivityUsb 是透明的,即 android:theme"style/TranslucentTheme" ###场景1:只有MainActivity 设置成:android:launchMode"singleTask" 点击顺序࿱…...

2024-3-1-网络编程作业
1>操控机械臂: 通过w(红色臂角度增大)s(红色臂角度减小) d(蓝色臂角度增大)a(蓝色臂角度减小)按键控制机械臂 源代码: #include <myhead.h> #define minStep 10 //最小偏…...

pytorch基础2-数据集与归一化
专题链接:https://blog.csdn.net/qq_33345365/category_12591348.html 本教程翻译自微软教程:https://learn.microsoft.com/en-us/training/paths/pytorch-fundamentals/ 初次编辑:2024/3/2;最后编辑:2024/3/2 本教程…...
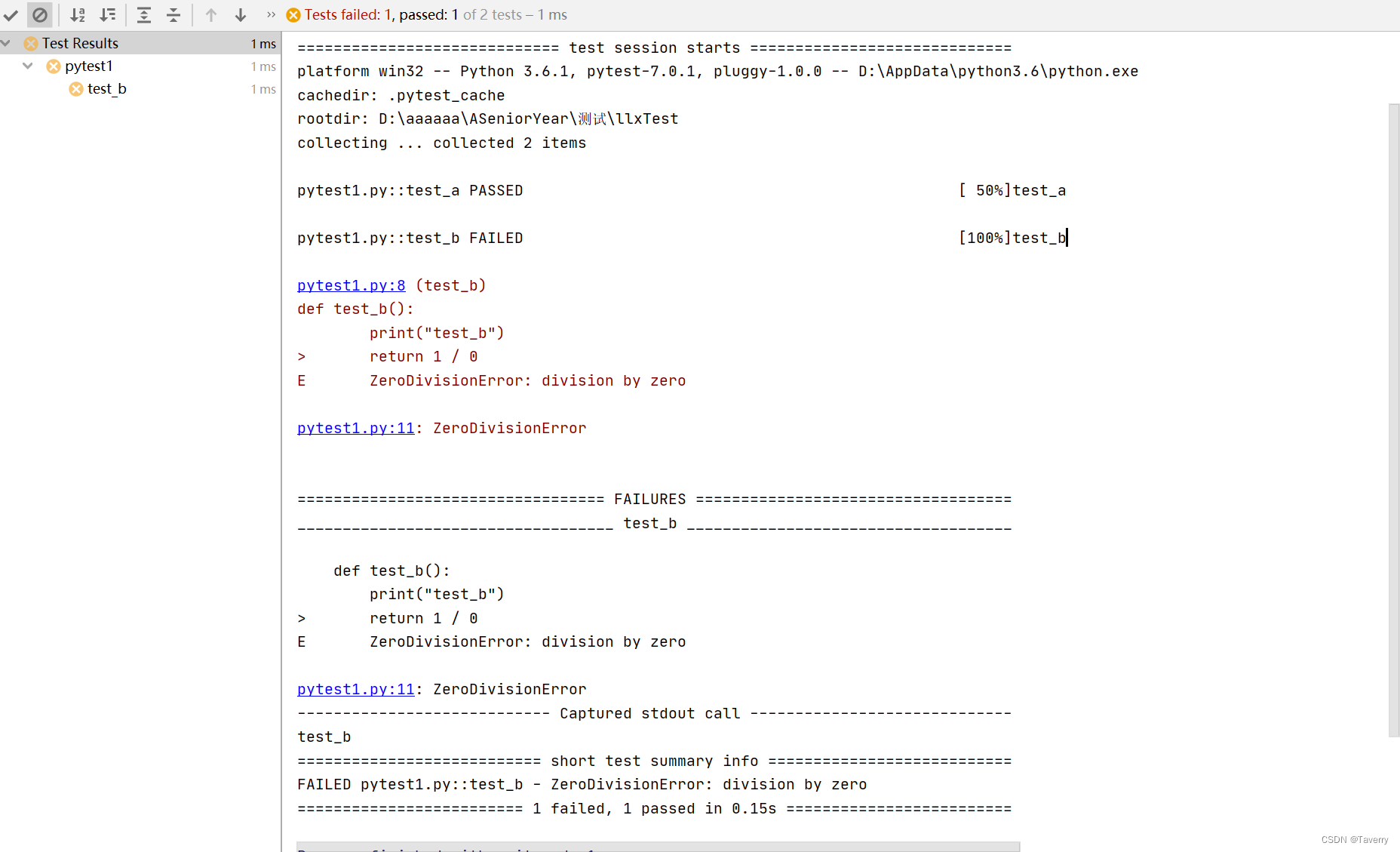
Python测试框架pytest介绍用法
1、介绍 pytest是python的一种单元测试框架,同自带的unittest测试框架类似,相比于unittest框架使用起来更简洁、效率更高 pip install -U pytest 特点: 1.非常容易上手,入门简单,文档丰富,文档中有很多实例可以参考 2.支持简单的单…...

AI对话系统app开源
支持对接gpt,阿里云,腾讯云 具体看截图 后端环境:PHP7.4MySQL5.6 软件:uniapp 废话不多说直接上抗揍云链接: https://mny.lanzout.com/iKFRY1o1zusf 部署教程请看源码内的【使用教程】文档 欢迎各位转载该帖/源码...
SpringBoot+aop实现主从数据库的读写分离
读写分离的作用是为了缓解写库,也就是主库的压力,但一定要基于数据一致性的原则,就是保证主从库之间的数据一定要一致。如果一个方法涉及到写的逻辑,那么该方法里所有的数据库操作都要走主库。 一、环境部署 数据库:…...

胎神游戏集第二期
延续上一期 一、海岛奇胎 #include<bits/stdc.h> #include<windows.h> #include<stdio.h> #include<conio.h> #include<time.h> using namespace std; typedef BOOL (WINAPI *PROCSETCONSOLEFONT)(HANDLE, DWORD); PROCSETCONSOLEFONT SetCons…...
)
Unicode/ASCII/UTF的关系(模板字面量、模板字符串、占位符)
字符串:编程时最重要的数据类型之一。 正则表达式:赋予开发者更多操作字符串的能力。 1、 Unicode和ASCII 1.1 概述 Unicode是ASCII字符编码的一个扩展,只不过在Windows中,用两个字节对其进行编码,也称为宽字符集&…...
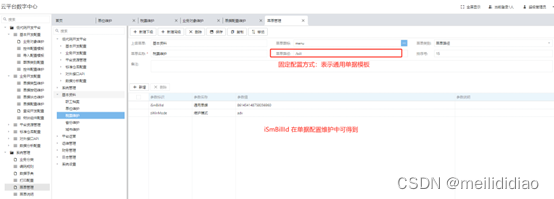
三、低代码平台-单据配置(单表增删改查)
一、业务效果图 主界面 二、配置过程简介 配置流程:业务表设计 -》业务对象建立-》业务单据配置-》菜单配置。 a、业务表设计 b、业务对象建立 c、业务单据配置 功能路径:低代码开发平台/业务开发配置/单据配置维护 d、菜单配置...

6.1 数据驱动型业务管理方法(3%)
1 数据的产生与应用 1.数据的产生 2.数据的特征 3.数据的应用过程 应用到决策过程中 4.从决策到执行 决策:靠经验来进行决策(80%);可依据数据辅助(20%) 经验比数据重要的多,数据是辅助&…...

JVM学习目录
JVM ✅ JVM运行时内存结构 ✅ JVM常用启动参数 ✅ JVM内存分配与垃圾收集流程 ✅ 什么是垃圾回收机制(Garbage Collection,简称GC) ✅ 如何调用垃圾回收器的方法 ✅ GC如何判定对象已死 ✅ 方法区的垃圾收集 ✅ 垃圾收集算法 ✅ JVM垃圾回…...

使用远程桌面连接工具上传文件到Windows轻量应用服务器时,如何优化文件传输速度?
使用远程桌面连接工具上传文件到Windows轻量应用服务器时,如何优化文件传输速度? 优化网络连接:确保网络连接稳定和畅通,使用有线网络连接代替无线网络,以减少网络延迟和提高文件传输速度。 调整远程桌面设置…...

【Linux】基本指令(下)
🦄个人主页:修修修也 🎏所属专栏:Linux ⚙️操作环境:Xshell (操作系统:CentOS 7.9 64位) 日志 日志的概念: 网络设备、系统及服务程序等,在运作时都会产生一个叫log的事件记录;每一行日志都记载着日期、时间、使用者及动作等相关…...
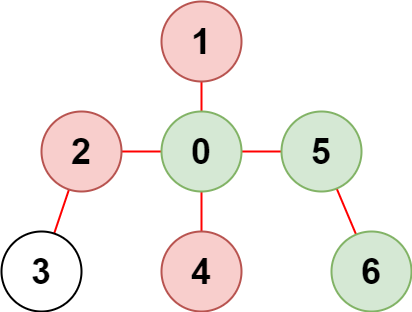
LeetCode受限条件下可到达节点的数目
题目描述 现有一棵由 n 个节点组成的无向树,节点编号从 0 到 n - 1 ,共有 n - 1 条边。 给你一个二维整数数组 edges ,长度为 n - 1 ,其中 edges[i] [ai, bi] 表示树中节点 ai 和 bi 之间存在一条边。另给你一个整数数组 restr…...
[Flutter]设置应用包名、名称、版本号、最低支持版本、Icon、启动页以及环境判断、平台判断和打包
一、设置应用包名 在Flutter开发中,修改应用程序的包名(也称作Application ID)涉及几个步骤,因为包名是在项目的Android和iOS平台代码中分别配置的。请按照以下步骤操作: 1.Android Flutter工程中全局搜索替换包名 …...
electron-release-server部署electron自动更新服务器记录
目录 一、前言 环境 二、步骤 1、下载上传electron-release-server到服务器 2、宝塔新建node项目网站 3、安装依赖 ①npm install ②安装并配置postgres数据库 ③修改项目配置文件 ④启动项目 ⑤修改postgres的认证方式 ⑥Cannot find where you keep your Bower p…...
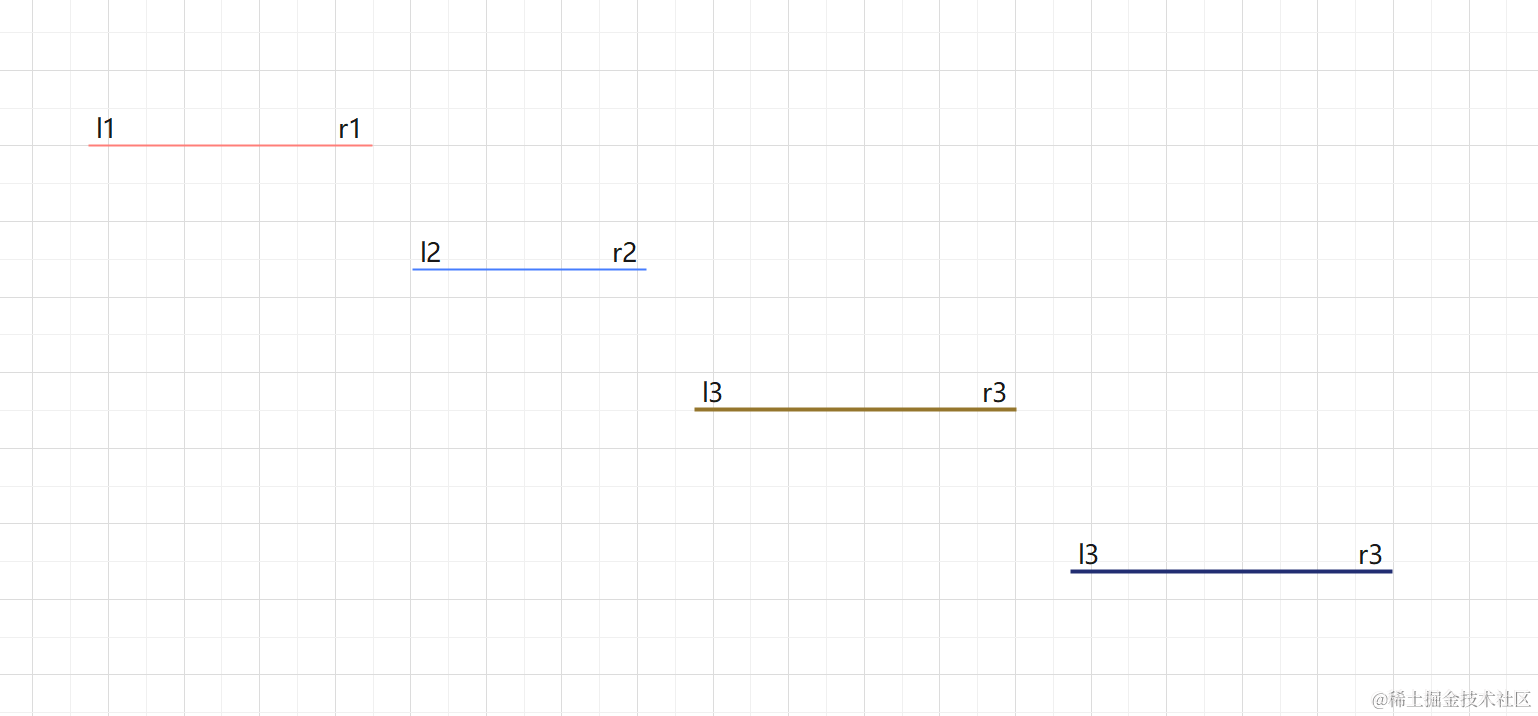
贪心(基础算法)--- 区间选点
905. 区间选点 思路 (贪心)O(nlogn) 根据右端点排序 将区间按右端点排序 遍历区间,如果当前区间左端点不包含在前一个区间中,则选取新区间,所选点个数加1,更新当前区间右端点。如果包含,则跳…...
)
VMware升级后Ubuntu 22.04虚拟机网卡‘消失’?别慌,这6个命令帮你一键找回(附排查思路)
VMware升级后Ubuntu 22.04虚拟机网卡异常修复指南当你满怀期待地将VMware Workstation从15版升级到17版,准备体验新功能时,突然发现原本运行良好的Ubuntu 22.04虚拟机无法联网了——ifconfig只显示lo回环接口,网络设置里空空如也。这种"…...

从COCO person_keypoints到YOLO格式:一份完整的姿态估计数据集转换脚本与避坑指南
从COCO到YOLO格式:姿态估计数据集转换实战手册在计算机视觉领域,姿态估计任务正从学术研究快速走向工业应用。许多开发者希望利用YOLO系列模型(如YOLOv8-Pose)进行训练,却常常在数据预处理阶段遇到障碍。本文将提供一套…...

终极QMC解密指南:如何快速将QQ音乐加密音频转换为MP3/FLAC格式
终极QMC解密指南:如何快速将QQ音乐加密音频转换为MP3/FLAC格式 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 你是否曾经从QQ音乐下载了喜欢的歌曲,…...

别再为单细胞数据批次效应发愁了!手把手教你用Harmony算法搞定整合分析
单细胞数据整合实战:用Harmony消除批次效应的完整指南当你在不同时间、不同实验室或使用不同平台获得多个单细胞RNA测序数据集时,最令人头疼的问题莫过于批次效应——这种技术性差异会掩盖真实的生物学信号。想象一下,你精心设计的实验因为数…...

基于Simulink的四开关buck-boost变换器闭环仿真模型
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 🎁…...

机器学习原子间势与连续介质模型在柔性InSe扭转双层原子重构研究中的应用
1. 项目概述:当柔性二维材料遇上扭转角在二维材料的世界里,一个简单的“扭转”操作,往往能打开一扇通往新奇物理现象的大门。从魔角石墨烯中发现的超导和关联绝缘态,到过渡金属硫族化合物(TMDs)中的莫尔激子…...

2026年AI论文写作工具实测认证:5款神器从文献到降重一站式避坑指南
写论文的焦虑,是每个科研人和学生绕不开的“必修课”。选题无从下手,文献检索耗时费力,格式调整反复修改,查重降重更是让人抓耳挠腮。2026年的AI工具早已不是当年的“辅助软件”,而是升级为能理解学术逻辑、生成高质量…...

【ChatGPT项目计划书生成实战指南】:20年PMO总监亲授5大高转化模板+3类避坑红线
更多请点击: https://kaifayun.com 第一章:ChatGPT项目计划书生成的核心价值与适用场景 在敏捷开发与跨职能协作日益普及的今天,项目计划书不再仅是交付物,更是对目标对齐、资源预判与风险共识的关键载体。ChatGPT驱动的项目计划…...

【无功优化】基于改进教与学算法的配电网无功优化【IEEE33节点】附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...

DML2 vs DML1:新渐近框架下的理论优势与最优折叠数选择
1. 项目概述:DML2为何在理论上优于DML1?在因果推断和半参数模型的实证研究中,我们常常面临一个核心挑战:如何在高维或非参数干扰函数(nuisance function)存在的情况下,稳健且高效地估计我们真正…...