【Spark】Spark的DataFrame向Impala写入数据异常及源码解析
背景
事情是这样的,当前业务有一个场景: 从业务库的Mysql抽取数据到Hive
由于运行环境的网络限制,当前选择的方案:
使用spark抽取业务库的数据表,然后利用impala jdbc数据灌输到hive。(没有spark on hive 的条件)
问题
结果就出现问题了:
报错信息如下:
java.sql.SQLFeatureNotSupportedException: [Cloudera][JDBC](10220) Driver does not support this optional feature.at com.cloudera.impala.exceptions.ExceptionConverter.toSQLException(Unknown Source)at com.cloudera.impala.jdbc.common.SPreparedStatement.checkTypeSupported(Unknown Source)at com.cloudera.impala.jdbc.common.SPreparedStatement.setNull(Unknown Source)at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$.savePartition(JdbcUtils.scala:658)at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$saveTable$1.apply(JdbcUtils.scala:834)at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$saveTable$1.apply(JdbcUtils.scala:834)at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:935)at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:935)at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)at org.apache.spark.scheduler.Task.run(Task.scala:121)at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:402)at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:408)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)at java.lang.Thread.run(Thread.java:748)
23/03/04 23:24:51 WARN TaskSetManager: Lost task 0.0 in stage 1.0 (TID 1, localhost, executor driver): java.sql.SQLFeatureNotSupportedException: [Cloudera][JDBC](10220) Driver does not support this optional feature.at com.cloudera.impala.exceptions.ExceptionConverter.toSQLException(Unknown Source)at com.cloudera.impala.jdbc.common.SPreparedStatement.checkTypeSupported(Unknown Source)at com.cloudera.impala.jdbc.common.SPreparedStatement.setNull(Unknown Source)at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$.savePartition(JdbcUtils.scala:658)at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$saveTable$1.apply(JdbcUtils.scala:834)at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$saveTable$1.apply(JdbcUtils.scala:834)at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:935)at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:935)at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)at org.apache.spark.scheduler.Task.run(Task.scala:121)at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:402)at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:408)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)at java.lang.Thread.run(Thread.java:748)
问题溯源
在spark从mysql中读出来的数据中,存在字段有string的类型。
这个类型在使用DataFrame.write.jdbc()通过impala jdbc向Hive中写数据的时候,如果没有创建Impala的jdbc Dialect的时候,此时这个String的类型,会被转换成
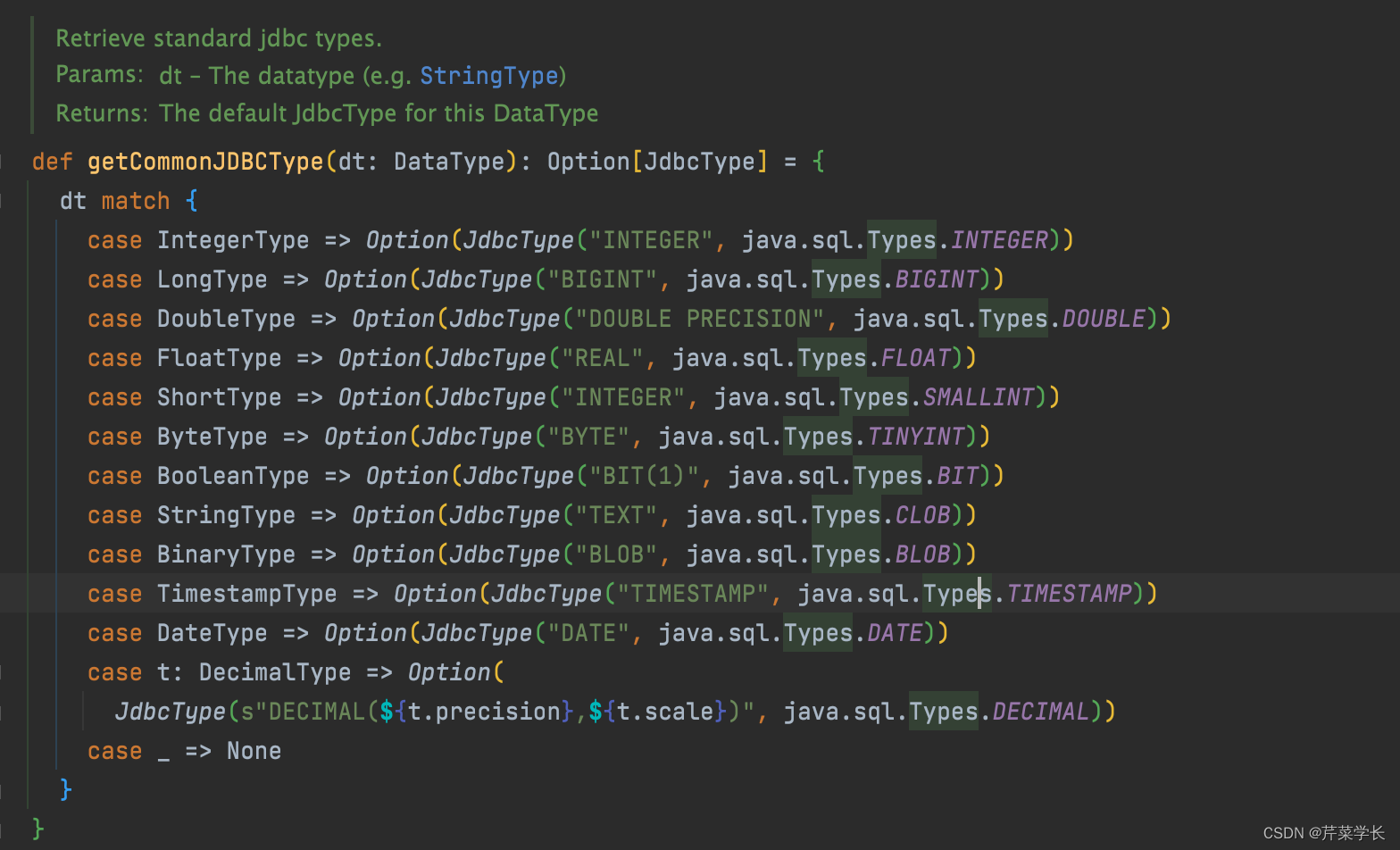
源自 org/apache/spark/sql/execution/datasources/jdbc/JdbcUtils.scala
java.sql.Types.ClOB类型,戳进这个变量。可以看到它代表的值
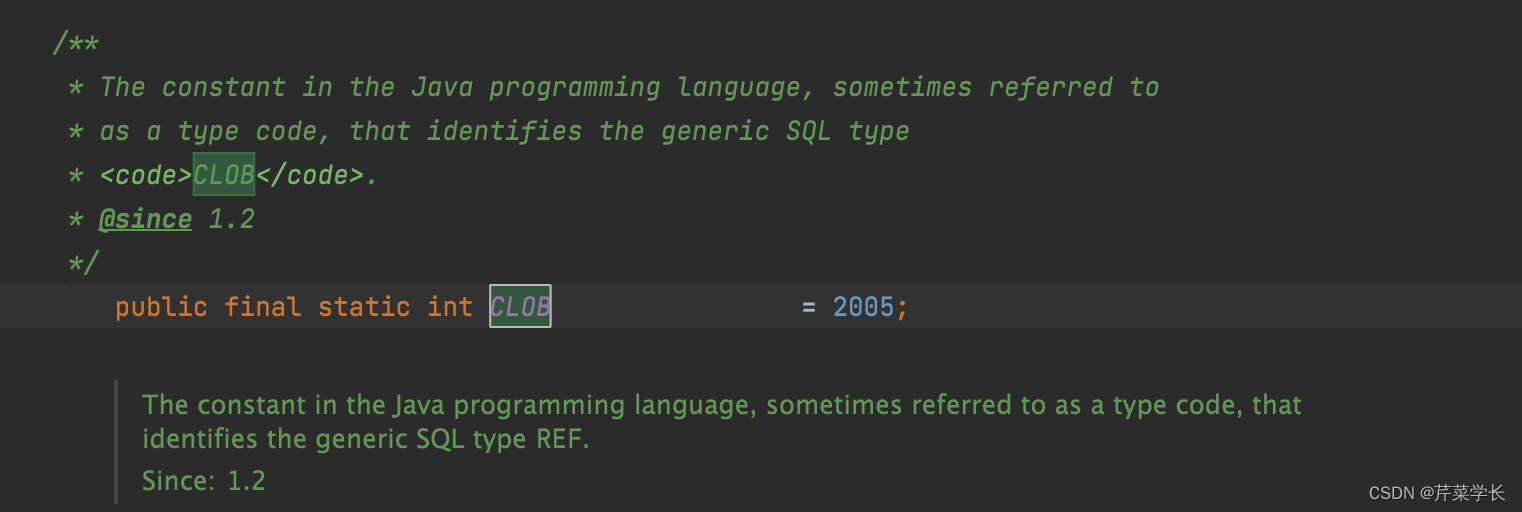
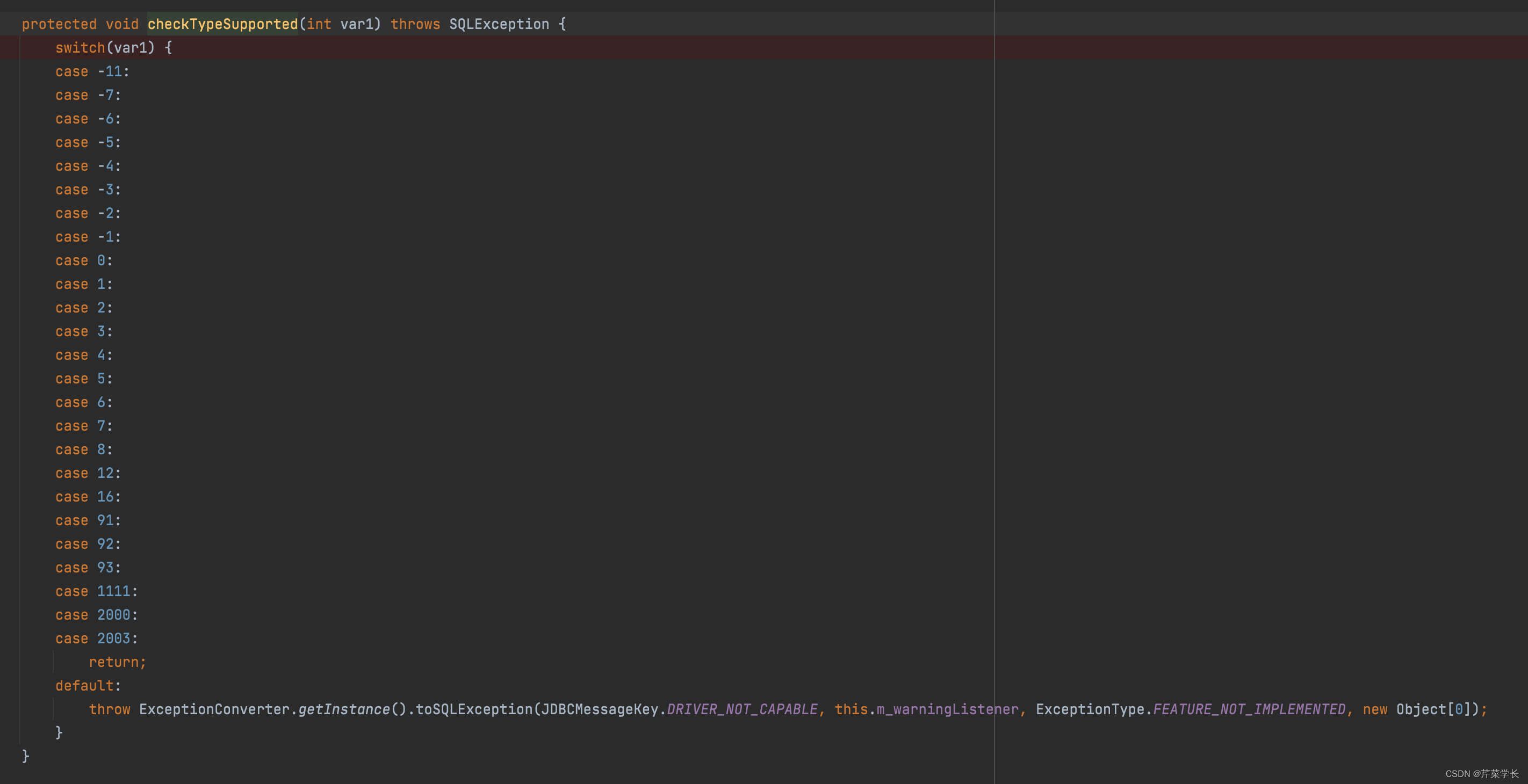
接着,我们找到impala jdbc 的com.cloudera.impala.jdbc.common.SPreparedStatement#checkTypeSupported
方法,发现这个列表里面没有2005所以,程序代码会报错。
对应的数字编码:
com.cloudera.impala.dsi.dataengine.utilities.TypeUtilities#sqlTypeToString
public static String sqlTypeToString(short var0) {switch(var0) {case -11:return "SQL_GUID";case -10:return "SQL_WLONGVARCHAR";case -9:return "SQL_WVARCHAR";case -8:return "SQL_WCHAR";case -7:return "SQL_BIT";case -6:return "SQL_TINYINT";case -5:return "SQL_BIGINT";case -4:return "SQL_LONGVARBINARY";case -3:return "SQL_VARBINARY";case -2:return "SQL_BINARY";case -1:return "SQL_LONGVARCHAR";case 0:return "NULL";case 1:return "SQL_CHAR";case 2:return "SQL_NUMERIC";case 3:return "SQL_DECIMAL";case 4:return "SQL_INTEGER";case 5:return "SQL_SMALLINT";case 6:return "SQL_FLOAT";case 7:return "SQL_REAL";case 8:return "SQL_DOUBLE";case 12:return "SQL_VARCHAR";case 16:return "SQL_BOOLEAN";case 91:return "SQL_TYPE_DATE";case 92:return "SQL_TYPE_TIME";case 93:return "SQL_TYPE_TIMESTAMP";case 101:return "SQL_INTERVAL_YEAR";case 102:return "SQL_INTERVAL_MONTH";case 103:return "SQL_INTERVAL_DAY";case 104:return "SQL_INTERVAL_HOUR";case 105:return "SQL_INTERVAL_MINUTE";case 106:return "SQL_INTERVAL_SECOND";case 107:return "SQL_INTERVAL_YEAR_TO_MONTH";case 108:return "SQL_INTERVAL_DAY_TO_HOUR";case 109:return "SQL_INTERVAL_DAY_TO_MINUTE";case 110:return "SQL_INTERVAL_DAY_TO_SECOND";case 111:return "SQL_INTERVAL_HOUR_TO_MINUTE";case 112:return "SQL_INTERVAL_HOUR_TO_SECOND";case 113:return "SQL_INTERVAL_MINUTE_TO_SECOND";case 2003:return "SQL_ARRAY";default:return null;}}
解决
我们在代码中添加一个这样的类:
import org.apache.spark.sql.jdbc.JdbcDialect;
import org.apache.spark.sql.jdbc.JdbcType;
import org.apache.spark.sql.types.DataType;
import org.apache.spark.sql.types.MetadataBuilder;
import org.apache.spark.sql.types.StringType;
import scala.Option;import java.sql.Types;/*** @author wmh* @date 2021/1/12* impala的sql的方言,为了使impala sql能在spark中正确的执行*/
public class ImpalaDialect extends JdbcDialect {@Overridepublic boolean canHandle(String url) {return url.startsWith("jdbc:impala") || url.contains("impala");}@Overridepublic String quoteIdentifier(String colName) {return "`" + colName + "`";}@Overridepublic Option<DataType> getCatalystType(int sqlType, String typeName, int size, MetadataBuilder md) {return super.getCatalystType(sqlType, typeName, size, md);}@Overridepublic Option<JdbcType> getJDBCType(DataType dt) {if (dt instanceof StringType) {return Option.apply(new JdbcType("String", Types.VARCHAR));}return super.getJDBCType(dt);}
}
会出现这个问题:

at com.cloudera.impala.hivecommon.api.HS2Client.executeStatementInternal(Unknown Source)at com.cloudera.impala.hivecommon.api.HS2Client.executeStatement(Unknown Source)at com.cloudera.impala.hivecommon.dataengine.HiveJDBCNativeQueryExecutor.executeHelper(Unknown Source)at com.cloudera.impala.hivecommon.dataengine.HiveJDBCNativeQueryExecutor.execute(Unknown Source)at com.cloudera.impala.jdbc.common.SPreparedStatement.executePreparedAnyBatch(Unknown Source)at com.cloudera.impala.jdbc.common.SPreparedStatement.executeBatch(Unknown Source)at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$.savePartition(JdbcUtils.scala:667)at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$saveTable$1.apply(JdbcUtils.scala:834)at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$saveTable$1.apply(JdbcUtils.scala:834)at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:935)at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:935)at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)at org.apache.spark.scheduler.Task.run(Task.scala:121)at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:402)at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:408)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
Caused by: com.cloudera.impala.support.exceptions.GeneralException: [Cloudera][ImpalaJDBCDriver](500051) ERROR processing query/statement. Error Code: 0, SQL state: TStatus(statusCode:ERROR_STATUS, sqlState:HY000, errorMessage:AnalysisException: Char size must be > 0: 0
上述问题解释一下:
注意最后一句:errorMessage:AnalysisException: Char size must be > 0: 0
是因为在DataFrame里面存在’'没有长度的空字符串,这样的空字符串会导致如上报错
因为在spark构建insert into xx table values(cast('' as char(0)) ,因为这个char(0)的数字不能等于0,所以会出现如上错误。所以字符串中不能为
‘’,
源代码路径:impalajdbc41/2.6.4/impalajdbc41-2.6.4.jar!/com/cloudera/impala/impala/querytranslation/ImpalaInsertQueryGenerator.class
那么针对这个问题,我们要在impala的jdbc的参数上面加上一个UseNativeQuery=1, 即可解决该问题。
这个UseNativeQuery=1参数含义是:

上图来自impala jdbc的官方文档
我这里来翻译一下:
此属性指定驱动程序是否转换应用程序发出的查询。
1:驱动程序不会转换应用程序发出的查询,直接使用sql查询。
0:驱动程序将应用程序发出的查询转换为Impala SQL中的等效形式。
也就是说,如果查询sql本来就是impala查询sql,那么就不用进行转换了。
总结
如果有什么更好的方法,请在下方评论区留言,谢谢大哥们了!
相关文章:
【Spark】Spark的DataFrame向Impala写入数据异常及源码解析
背景 事情是这样的,当前业务有一个场景: 从业务库的Mysql抽取数据到Hive 由于运行环境的网络限制,当前选择的方案: 使用spark抽取业务库的数据表,然后利用impala jdbc数据灌输到hive。(没有spark on hive 的条件&…...

学习笔记-架构的演进之限流-3月day03
文章目录前言限流的目标流量统计指标限流设计模式流量计数器模式滑动时间窗模式漏桶模式令牌桶模式分布式限流总结附前言 任何一个系统的运算、存储、网络资源都不是无限的,当系统资源不足以支撑外部超过预期的突发流量时,就应该要有取舍,建…...
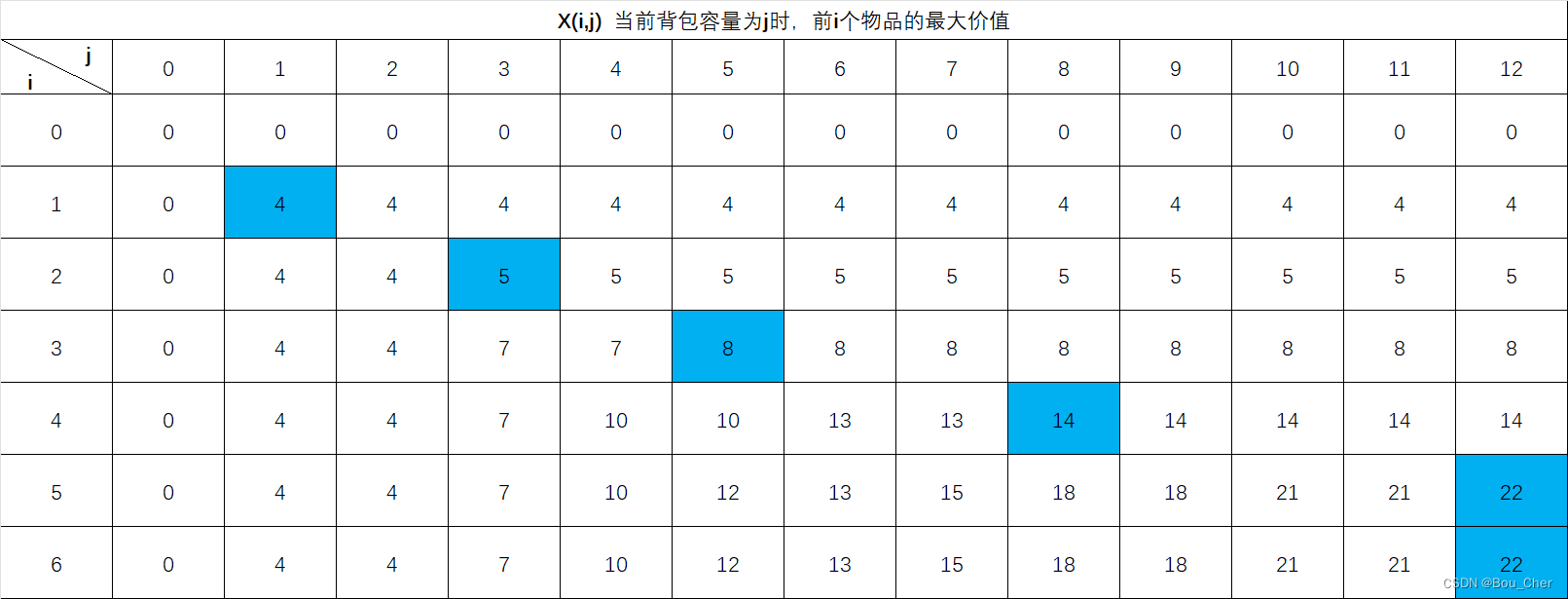
动态规划 背包问题
动态规划 背包问题 问题描述: 有一个背包,总容量为12。有6件物品,每件物品的重量和价值不同,求在背包总容量12的前提下,装进物品的最大价值以及装进物品的编号 单个物品重量和价值: 为方便进行思考&#…...
—— 内存模型和名称空间)
C++ Primer Plus 学习笔记(四)—— 内存模型和名称空间
1 单独编译 C允许将组件函数放在独立的文件即头文件中,头文件中可以包含以下内容: 函数原型;使用#define或const定义的符号常量;结构声明;类声明;模板声明;内联函数。 注意,在包含…...
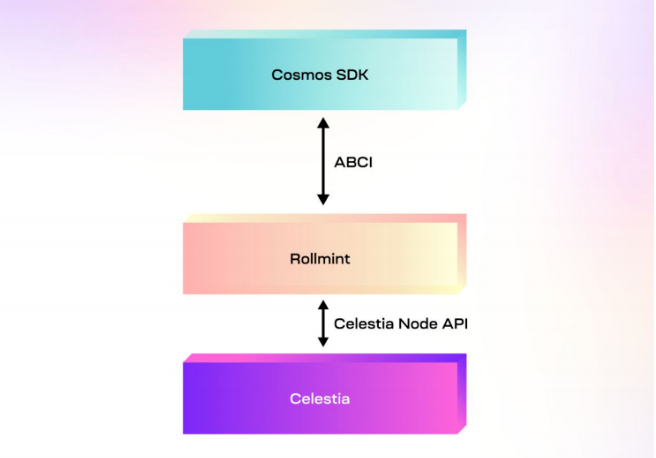
详解基于 Celestia、Eclipse 构建的首个Layer3 链 Nautilus Chain
以流支付为主要概念的Zebec生态,正在推动流支付这种新兴的支付方式向更远的方向发展,该生态最初以Zebec Protocol的形态发展,并从初期的Solana进一步拓展至BNB Chian以及Near上。与此同时,Zebec生态也在积极的寻求从协议形态向公链…...

列表与数组的转化
目录用np.array(a)将列表转换为数组列表转数组的特殊情况(一)列表转数组的特殊情况(二)针对子元素个数不一致的解决办法用a.tolist()函数将数组转化为列表在python的学习中,经常会用到数组与列表的相互转化,本文主要介绍下关于数组与列表转化的问题。用n…...
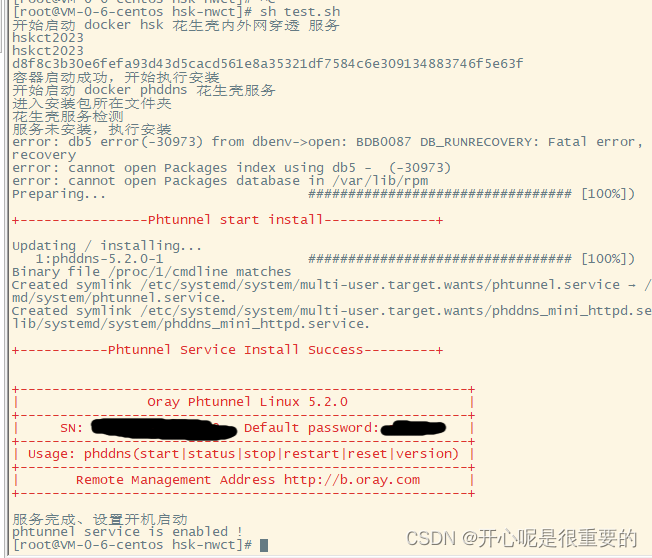
docker 运行花生壳实现内外网穿透
环境:centos 7 ,64位 1、创建一个指定的文件夹作为安装示例所用,该示例文件夹为“hsk-nwct”。“hsk-nwct”内创建“app”文件夹作为docker容器挂载出来的文件。 2、在“app”内下载花生壳linux安装包,下载花生壳应用:花生壳客户…...
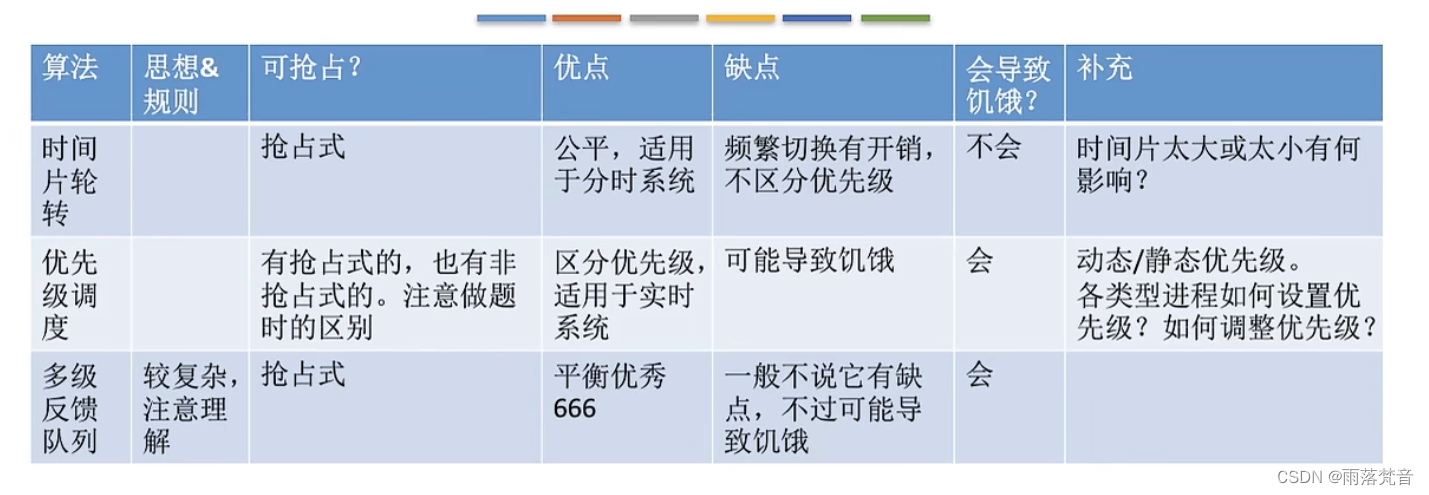
操作系统——16.时间片轮转、优先级、多级反馈队列算法
这篇文章我们来看一下进程调度算法中的时间片轮转、优先级、多级反馈队列算法 目录 1.概述 2.时间片轮转调度算法(RR,Round-Robin) 3.优先级调度算法 4.多级反馈队列调度算法 5.分析对比 1.概述 首先,我们来看一下这篇文章…...

Python3.8.8-Django3.2-Redis-连接池-数据类型-字符串-list-hashmap-命令行操作
文章目录1.认识Redis1.1.优点1.2.缺点2.在Django中Redis的连接3.Redis的基础用法3.1.hashmap结构3.2.list结构4.命令行查看数据库5.作者答疑1.认识Redis Remote DIctionary Server(Redis) 是一个key-value 存储系统,是跨平台的非关系型数据库。是一个开源的使用 AN…...

Android kotlin 系列讲解(进阶篇)高级项目架构模式 - MVVM
<<返回总目录 1、MVVM是什么 MVVM是Model-View-ViewModel的缩写,是一种高级项目架构模式。 MVVM架构可以将程序结构主要分成三个部分: Model:数据模型部分,包括从服务端获取的json数据或者从本地获取的数据等等View&…...

8. 查找
1 题目描述 查找成绩10开启时间2021年09月24日 星期五 18:00折扣0.8折扣时间2021年11月15日 星期一 00:00允许迟交否关闭时间2021年11月23日 星期二 00:00 输入 n(n ≤ 10^6)个不超过 10^9的单调不减的(就是后面的数字不小于前面的数字)非负整数 &#…...

二分查找算法
感谢“五点七边”工作室的算法讲解,详细内容可以参考视频讲解 二分查找为什么总是写错?_哔哩哔哩_bilibili 此处仅是个人学习总结 以target等于5为例,输入: 1 2 3 5 5 5 8 9 1. 找到第一个 > target 的元素 判断条件 < target&am…...
之远程服务器)
Git(3)之远程服务器
Git基础之远程服务器 Author:onceday date:2023年3月5日 满满长路有人对你微笑过嘛… windows安装可参考文章:git简易配置_onceday_CSDN博客 參考文档: 《progit2.pdf》,Progit2 Github。《git-book.pdf》 文章目…...
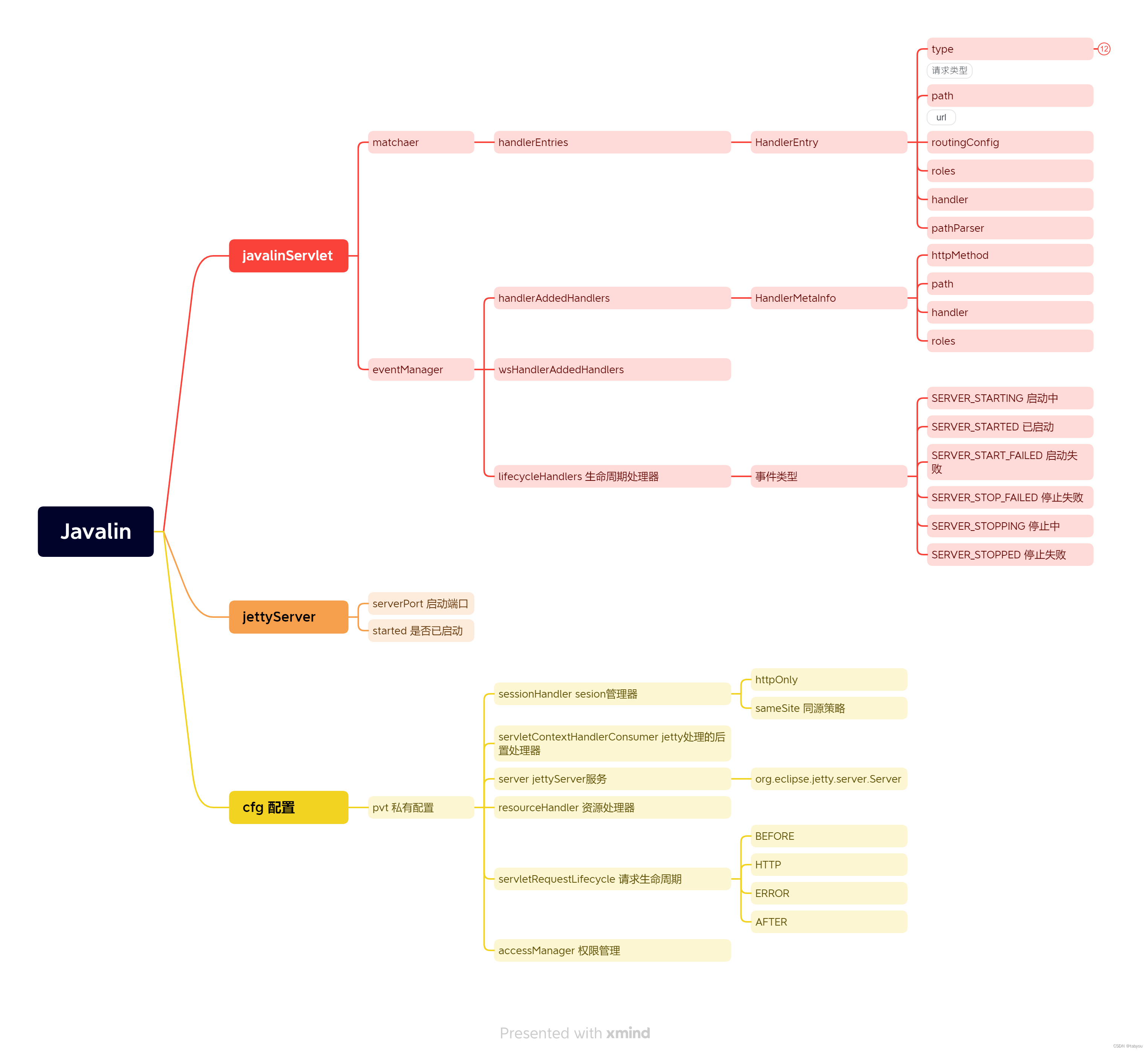
Javalin解构
Javalin Javalin是一个轻量级http框架,我们可以很容易的了解请求的处理过程及其设计,具有较高的学习意义。 从demo说起 public static void main(String[] args) {Javalin app Javalin.create(config -> {System.out.println("用户配置"…...
yolov5算法,训练模型,模型检测
嘟嘟嘟嘟!工作需要,所以学习了下yolov5算法。是干什么的呢? 通俗来说,可以将它看做是一个小孩儿,通过成年人(开发人员)提供的大量图片的学习,让自己知道我看到的哪些场景需要提醒给成…...

linux系统防火墙开放端口
linux系统防火墙开放端口 在外部访问CentOS中部署应用时,需要通过防火墙管理软件,开端口,或者直接关闭防火墙进行解决(不建议) 加粗样式 常用命令: systemctl start firewalld #启动 systemctl stop firewalld #停止 systemctl status firewalld #查看…...

CSAPP第九章 虚拟内存
理解虚拟内存的原因 本章前部分描述虚拟内存是如何工作的,后一部分描述应用程序如何使用和管理虚拟内存 物理和虚拟寻址 虚拟内存作为缓存的工具 页表 页命中 缺页 虚拟内存作为内存管理的工具 简化链接,简化加载,简化共享,简化…...
)
numpy数组与矩阵运算(二)
文章目录矩阵生成与常用操作矩阵生成矩阵转置查看矩阵特性矩阵乘法计算相关系数矩阵计算方差、协方差、标准差计算特征值与特征向量计算逆矩阵求解线性方程组奇异值分解函数向量化矩阵生成与常用操作 矩阵生成 扩展库numpy中提供的matrix()函数可以用来把列表、元组、range对…...

Dubbo 中 Zookeeper 注册中心原理分析
Dubbo 中 Zookeeper 注册中心原理分析 文章目录Dubbo 中 Zookeeper 注册中心原理分析一、ZooKeeper注册中心1.1 ZooKeeper数据结构1.2 ZooKeeper的Watcher机制1.3 ZooKeeper会话机制1.4 使用ZooKeeper作为注册中心二、源码分析2.1 AbstractRegistry2.2 FailbackRegistry2.2.1 核…...
--哥德巴赫猜想的第一次实际应用)
素数产生新的算法(由筛法减法改为增加法)--哥德巴赫猜想的第一次实际应用
素数产生新的算法(由筛法减法改为增加法)--哥德巴赫猜想的第一次实际应用 摘要:长期以来,人们认为哥德巴赫猜想没有什么实际应用的。 现在,我假设这个不是猜想,而是定理或公理,就产生了新的应用…...

GA/T 1400视图库实战:从零部署Easy1400平台到设备级联全流程解析
1. 初识GA/T 1400与Easy1400平台 第一次接触GA/T 1400标准时,我完全被各种专业术语绕晕了。简单来说,这是一套专门针对视频监控领域的行业标准,规定了视频图像信息在采集、传输、存储等环节的技术要求。而Easy1400就是基于这个标准开发的一套…...

深度集成AI的VSCode扩展:从代码生成到调试的全流程实战指南
1. 项目概述:一个为VSCode注入AI灵魂的扩展如果你和我一样,每天有超过8小时的时间是在Visual Studio Code(VSCode)里度过的,那么你一定对提升编码效率有着近乎偏执的追求。从代码补全、语法高亮到调试、版本控制&#…...
)
保姆级教程:在CentOS 7/8服务器上部署DrissionPage爬虫(含Chrome无头模式配置)
CentOS服务器上DrissionPage爬虫的工业级部署指南 1. 环境准备与Chrome浏览器安装 在CentOS服务器上部署基于DrissionPage的爬虫系统,首要任务是构建稳定可靠的浏览器运行环境。与个人开发环境不同,生产服务器通常需要面对无图形界面、资源受限等特殊场景…...
研究(Matlab代码实现))
一种用于并网光伏系统的创新型多层逆变器,以降低总谐波失真(THD)研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 🎁…...

PowerInfer:基于热点神经元预测的LLM高性能推理引擎部署指南
1. 项目概述:当推理速度成为AI落地的瓶颈最近在折腾本地大模型推理的朋友,估计都绕不开一个核心痛点:速度。模型效果再好,生成一句话要等上十几秒,那种“卡顿感”足以劝退绝大多数想把它集成到实际应用里的开发者。我自…...

零基础实操:小龙虾 AI OpenClaw 接入 Kimi 详细步骤
前置准备 获取小龙虾open claw一键安装包(www.totom.top)并安装电脑端已成功安装并正常运行OpenClaw客户端,顶部 Gateway 状态保持在线设备网络通畅,可正常访问 Kimi 开放平台拥有可正常登录的 Kimi 月之暗面 Moonshot 账号账号提…...

AI 术语通俗词典:计算图
计算图是深度学习、自动微分、神经网络训练和人工智能框架中非常重要的一个术语。它用来描述:把一次数学计算过程表示成由节点和边组成的图结构。换句话说,计算图是在回答:模型中的输入、参数、运算和输出之间,到底是如何一步步连…...
)
别再拷贝exe到NXBIN了!用批处理文件搞定NX二次开发外部exe的环境变量(附VS2015/NX12配置)
告别手动拷贝:用批处理智能管理NX二次开发环境变量 每次修改完NX二次开发的外部exe程序,都要手动拷贝到NXBIN目录?这种重复劳动不仅低效,还容易导致版本混乱。其实只需一个简单的批处理脚本,就能彻底解决环境变量配置问…...

AI Agent产品经理的新思维:从功能设计到AI原生产品的方法论转型
AI Agent产品经理的新思维:从功能设计到AI原生产品的方法论转型 各位产品同行、AI从业者,大家好!我是连续3年深耕AI工具Agent产品、从C端信息流(今日头条/抖音生态)PM成功转型AI原生垂直工具PM的张小白——过去两年&am…...

Kubernetes部署Valheim游戏服务器:云原生技术赋能游戏运维实践
1. 项目概述:当维京英灵殿遇上容器编排如果你和我一样,既沉迷于《英灵神殿》(Valheim)里与好友共建家园、挑战上古巨兽的乐趣,又恰好是一名整天和Kubernetes(k8s)打交道的开发者或运维ÿ…...