视觉Transformers中的位置嵌入 - 研究与应用指南
视觉 Transformer 中位置嵌入背后的数学和代码简介。
自从 2017 年推出《Attention is All You Need》以来,Transformer 已成为自然语言处理 (NLP) 领域最先进的技术。 2021 年,An Image is Worth 16x16 Words² 成功地将 Transformer 应用于计算机视觉任务。从那时起,人们提出了许多基于Transformer的计算机视觉架构。
本文[1]研究了为什么位置嵌入是视觉Transformer的必要组成部分,以及不同的论文如何实现位置嵌入。它包括位置嵌入的开源代码以及概念解释。所有代码都使用 PyTorch 包。
为什么使用位置嵌入?
Attention is All You Need 指出,Transformer由于缺乏递归或卷积,无法学习有关一组标记顺序的信息。如果没有位置嵌入,Transformer对于标记的顺序是不变的。对于图像,这意味着可以对图像的补丁进行加扰,而不会影响预测的输出。
让我们看一下 Luis Zuno 的像素艺术《黄昏山》中补丁顺序的示例。原始艺术作品已被裁剪并转换为单通道图像。这意味着每个像素都有一个介于 0 和 1 之间的值。单通道图像通常以灰度显示;但是,我们将以紫色配色显示它,因为它更容易看到。
mountains = np.load(os.path.join(figure_path, 'mountains.npy'))
H = mountains.shape[0]
W = mountains.shape[1]
print('Mountain at Dusk is H =', H, 'and W =', W, 'pixels.')
print('\n')
fig = plt.figure(figsize=(10,6))
plt.imshow(mountains, cmap='Purples_r')
plt.xticks(np.arange(-0.5, W+1, 10), labels=np.arange(0, W+1, 10))
plt.yticks(np.arange(-0.5, H+1, 10), labels=np.arange(0, H+1, 10))
plt.clim([0,1])
cbar_ax = fig.add_axes([0.95, .11, 0.05, 0.77])
plt.clim([0, 1])
plt.colorbar(cax=cbar_ax);
#plt.savefig(os.path.join(figure_path, 'mountains.png'), bbox_inches='tight')
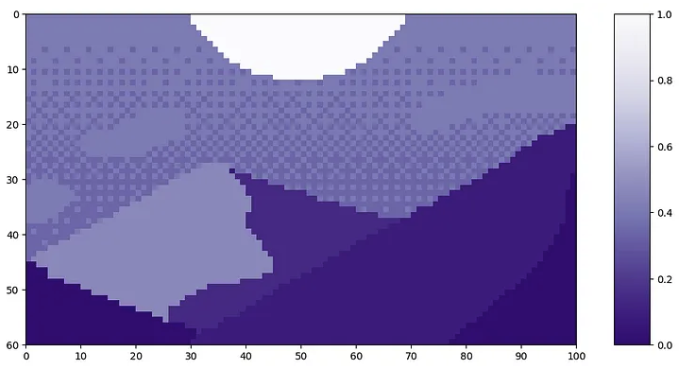
我们可以将此图像分割成大小为 20 的块。
P = 20
N = int((H*W)/(P**2))
print('There will be', N, 'patches, each', P, 'by', str(P)+'.')
print('\n')
fig = plt.figure(figsize=(10,6))
plt.imshow(mountains, cmap='Purples_r')
plt.clim([0,1])
plt.hlines(np.arange(P, H, P)-0.5, -0.5, W-0.5, color='w')
plt.vlines(np.arange(P, W, P)-0.5, -0.5, H-0.5, color='w')
plt.xticks(np.arange(-0.5, W+1, 10), labels=np.arange(0, W+1, 10))
plt.yticks(np.arange(-0.5, H+1, 10), labels=np.arange(0, H+1, 10))
x_text = np.tile(np.arange(9.5, W, P), 3)
y_text = np.repeat(np.arange(9.5, H, P), 5)
for i in range(1, N+1):
plt.text(x_text[i-1], y_text[i-1], str(i), color='w', fontsize='xx-large', ha='center')
plt.text(x_text[2], y_text[2], str(3), color='k', fontsize='xx-large', ha='center');
#plt.savefig(os.path.join(figure_path, 'mountain_patches.png'), bbox_inches='tight')
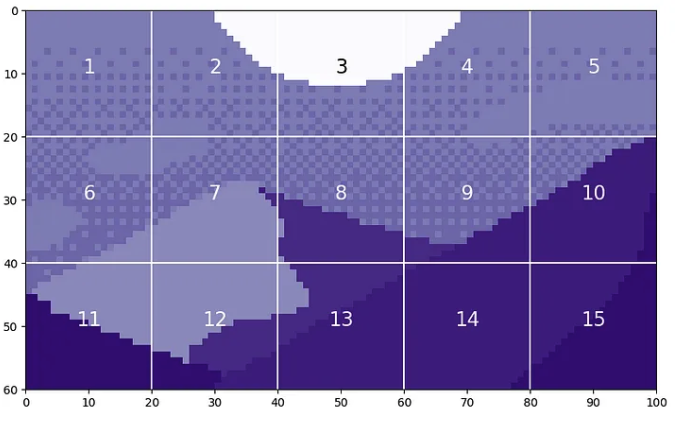
据称,视觉Transformer将无法区分原始图像和补丁被打乱的版本。
np.random.seed(21)
scramble_order = np.random.permutation(N)
left_x = np.tile(np.arange(0, W-P+1, 20), 3)
right_x = np.tile(np.arange(P, W+1, 20), 3)
top_y = np.repeat(np.arange(0, H-P+1, 20), 5)
bottom_y = np.repeat(np.arange(P, H+1, 20), 5)
scramble = np.zeros_like(mountains)
for i in range(N):
t = scramble_order[i]
scramble[top_y[i]:bottom_y[i], left_x[i]:right_x[i]] = mountains[top_y[t]:bottom_y[t], left_x[t]:right_x[t]]
fig = plt.figure(figsize=(10,6))
plt.imshow(scramble, cmap='Purples_r')
plt.clim([0,1])
plt.hlines(np.arange(P, H, P)-0.5, -0.5, W-0.5, color='w')
plt.vlines(np.arange(P, W, P)-0.5, -0.5, H-0.5, color='w')
plt.xticks(np.arange(-0.5, W+1, 10), labels=np.arange(0, W+1, 10))
plt.yticks(np.arange(-0.5, H+1, 10), labels=np.arange(0, H+1, 10))
x_text = np.tile(np.arange(9.5, W, P), 3)
y_text = np.repeat(np.arange(9.5, H, P), 5)
for i in range(N):
plt.text(x_text[i], y_text[i], str(scramble_order[i]+1), color='w', fontsize='xx-large', ha='center')
i3 = np.where(scramble_order==2)[0][0]
plt.text(x_text[i3], y_text[i3], str(scramble_order[i3]+1), color='k', fontsize='xx-large', ha='center');
#plt.savefig(os.path.join(figure_path, 'mountain_scrambled_patches.png'), bbox_inches='tight')
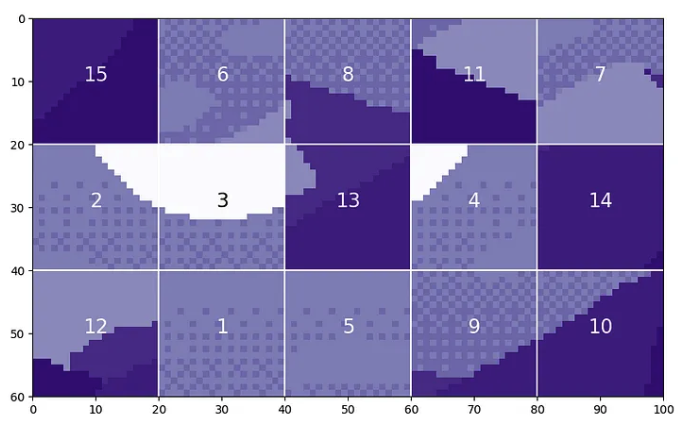
显然,这是与原始图像非常不同的图像,并且您不希望视觉Transformer将这两个图像视为相同。
排列的注意力不变性
让我们研究一下视觉Transformer对于标记顺序不变的说法。Transformer中对 token 顺序不变的组件是注意力模块。
注意力是根据三个矩阵(查询、键和值)计算得出的,每个矩阵都是通过将token传递到线性层而生成的。生成 Q、K 和 V 矩阵后,将使用以下公式计算注意力。
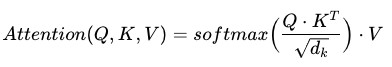
其中 Q、K、V 分别是查询、键和值; dₖ 是缩放值。为了证明注意力对 token 顺序的不变性,我们将从三个随机生成的矩阵开始来表示 Q、K 和 V。Q、K 和 V 的形状如下:
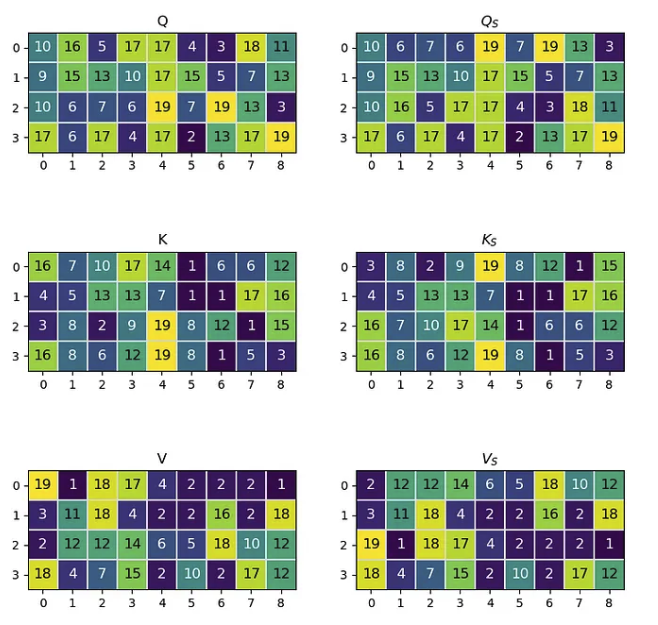
在此示例中,我们将使用 4 个预计长度为 9 的标记。矩阵将包含整数以避免浮点乘法错误。生成后,我们将交换token 0 和token 2 在所有三个矩阵中的位置。具有交换标记的矩阵将用下标 s 表示。
n_tokens = 4
l_tokens = 9
shape = n_tokens, l_tokens
mx = 20 #max integer for generated matricies
# Generate Normal Matricies
np.random.seed(21)
Q = np.random.randint(1, mx, shape)
K = np.random.randint(1, mx, shape)
V = np.random.randint(1, mx, shape)
# Generate Row-Swapped Matricies
swapQ = copy.deepcopy(Q)
swapQ[[0, 2]] = swapQ[[2, 0]]
swapK = copy.deepcopy(K)
swapK[[0, 2]] = swapK[[2, 0]]
swapV = copy.deepcopy(V)
swapV[[0, 2]] = swapV[[2, 0]]
# Plot Matricies
fig, axs = plt.subplots(nrows=3, ncols=2, figsize=(8,8))
fig.tight_layout(pad=2.0)
plt.subplot(3, 2, 1)
mat_plot(Q, 'Q')
plt.subplot(3, 2, 2)
mat_plot(swapQ, r'$Q_S$')
plt.subplot(3, 2, 3)
mat_plot(K, 'K')
plt.subplot(3, 2, 4)
mat_plot(swapK, r'$K_S$')
plt.subplot(3, 2, 5)
mat_plot(V, 'V')
plt.subplot(3, 2, 6)
mat_plot(swapV, r'$V_S$')
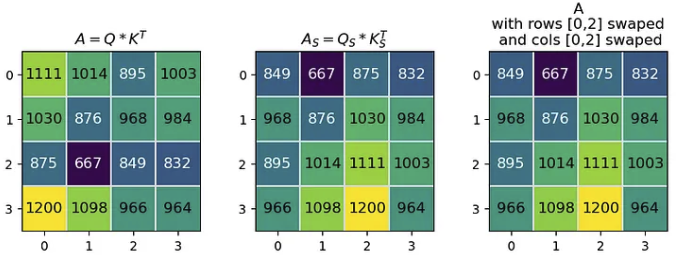
注意力公式中的第一个矩阵乘法是 Q·Kᵀ=A,其中得到的矩阵 A 是一个大小等于 token 数量的正方形。当我们用 Qₛ 和 Kₛ 计算 Aₛ 时,得到的 Aₛ 的行 [0, 2] 和列 [0,2] 都与 A 交换。
A = Q @ K.transpose()
swapA = swapQ @ swapK.transpose()
modA = copy.deepcopy(A)
modA[[0,2]] = modA[[2,0]] #swap rows
modA[:, [2, 0]] = modA[:, [0, 2]] #swap cols
fig, axs = plt.subplots(nrows=1, ncols=3, figsize=(8,3))
fig.tight_layout(pad=1.0)
plt.subplot(1, 3, 1)
mat_plot(A, r'$A = Q*K^T$')
plt.subplot(1, 3, 2)
mat_plot(swapA, r'$A_S = Q_S * K_S^T$')
plt.subplot(1, 3, 3)
mat_plot(modA, 'A\nwith rows [0,2] swaped\n and cols [0,2] swaped')
下一个矩阵乘法是 A·V=A,其中生成的矩阵 A 与初始 Q、K 和 V 矩阵具有相同的形状。当我们用 Aₛ 和 Vₛ 计算 Aₛ 时,得到的 Aₛ 的行 [0,2] 与 A 交换。
A = A @ V
swapA = swapA @ swapV
modA = copy.deepcopy(A)
modA[[0,2]] = modA[[2,0]] #swap rows
fig, axs = plt.subplots(nrows=2, ncols=2, figsize=(12, 7))
fig.tight_layout(pad=1.0)
plt.subplot(2, 2, 1)
mat_plot(A, r'$A = A*V$')
plt.subplot(2, 2, 2)
mat_plot(swapA, r'$A_S = A_S * V_S$')
plt.subplot(2, 2, 4)
mat_plot(modA, 'A\nwith rows [0,2] swaped')
axs[1,0].axis('off')
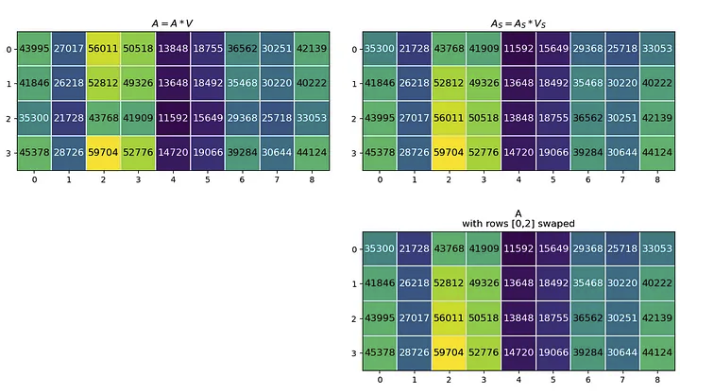
这表明,更改注意力层输入中标记的顺序会导致输出注意矩阵的相同标记行发生变化。因为注意力是对标记之间关系的计算。如果没有位置信息,更改token顺序不会改变token的关联方式。
示例
定义位置嵌入
现在,我们可以看看正弦位置嵌入的细节。该代码基于 Tokens-to-Token ViT 的公开可用 GitHub 代码。从功能上来说,位置嵌入是一个与 token 形状相同的矩阵。这看起来像:
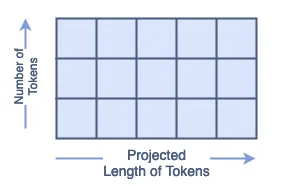
正弦位置嵌入公式如下所示
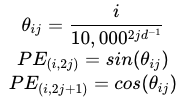
其中 PE 是位置嵌入矩阵,i 是沿着标记的数量,j 是沿着标记的长度,d 是标记长度。代码实现:
def get_sinusoid_encoding(num_tokens, token_len):
""" Make Sinusoid Encoding Table
Args:
num_tokens (int): number of tokens
token_len (int): length of a token
Returns:
(torch.FloatTensor) sinusoidal position encoding table
"""
def get_position_angle_vec(i):
return [i / np.power(10000, 2 * (j // 2) / token_len) for j in range(token_len)]
sinusoid_table = np.array([get_position_angle_vec(i) for i in range(num_tokens)])
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2])
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2])
return torch.FloatTensor(sinusoid_table).unsqueeze(0)
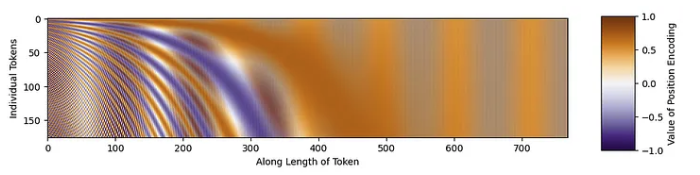
让我们生成一个示例位置嵌入矩阵。我们将使用 176 个tokens。每个token的长度为 768,这是 T2T-ViT代码中的默认长度。一旦生成了矩阵,我们就可以绘制它。
PE = get_sinusoid_encoding(num_tokens=176, token_len=768)
fig = plt.figure(figsize=(10, 8))
plt.imshow(PE[0, :, :], cmap='PuOr_r')
plt.xlabel('Along Length of Token')
plt.ylabel('Individual Tokens');
cbar_ax = fig.add_axes([0.95, .36, 0.05, 0.25])
plt.clim([-1, 1])
plt.colorbar(label='Value of Position Encoding', cax=cbar_ax);
#plt.savefig(os.path.join(figure_path, 'fullPE.png'), bbox_inches='tight')
放大标记的开头。
fig = plt.figure()
plt.imshow(PE[0, :, 0:301], cmap='PuOr_r')
plt.xlabel('Along Length of Token')
plt.ylabel('Individual Tokens');
cbar_ax = fig.add_axes([0.95, .2, 0.05, 0.6])
plt.clim([-1, 1])
plt.colorbar(label='Value of Position Encoding', cax=cbar_ax);
#plt.savefig(os.path.join(figure_path, 'zoomedinPE.png'), bbox_inches='tight')
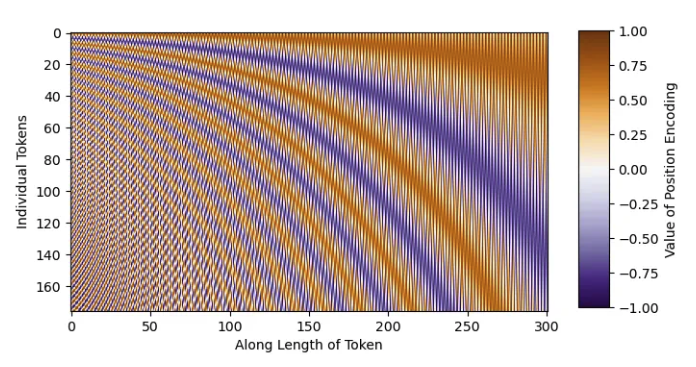
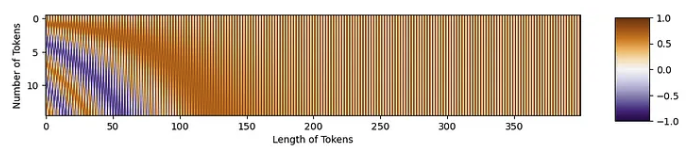
具有正弦结构!
将位置嵌入应用于tokens
现在,我们可以将位置嵌入添加到我们的tokens中!我们将使用《Mountain at Dusk》,并具有与上述相同的补丁标记化。这将为我们提供 15 个长度为 20²=400 的token。
fig = plt.figure(figsize=(10,6))
plt.imshow(mountains, cmap='Purples_r')
plt.hlines(np.arange(P, H, P)-0.5, -0.5, W-0.5, color='w')
plt.vlines(np.arange(P, W, P)-0.5, -0.5, H-0.5, color='w')
plt.xticks(np.arange(-0.5, W+1, 10), labels=np.arange(0, W+1, 10))
plt.yticks(np.arange(-0.5, H+1, 10), labels=np.arange(0, H+1, 10))
x_text = np.tile(np.arange(9.5, W, P), 3)
y_text = np.repeat(np.arange(9.5, H, P), 5)
for i in range(1, N+1):
plt.text(x_text[i-1], y_text[i-1], str(i), color='w', fontsize='xx-large', ha='center')
plt.text(x_text[2], y_text[2], str(3), color='k', fontsize='xx-large', ha='center')
cbar_ax = fig.add_axes([0.95, .11, 0.05, 0.77])
plt.clim([0, 1])
plt.colorbar(cax=cbar_ax);
#plt.savefig(os.path.join(figure_path, 'mountain_patches_w_colorbar.png'), bbox_inches='tight')
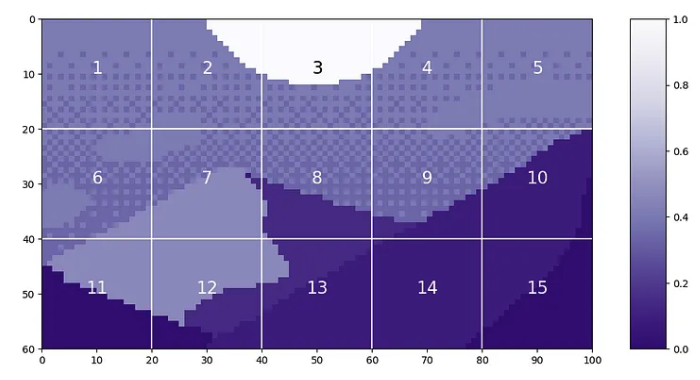
当我们将这些补丁转换为token时,它看起来像
tokens = np.zeros((15, 20**2))
for i in range(15):
patch = gray_mountains[top_y[i]:bottom_y[i], left_x[i]:right_x[i]]
tokens[i, :] = patch.reshape(1, 20**2)
tokens = tokens.astype(int)
tokens = tokens/255
fig = plt.figure(figsize=(10,6))
plt.imshow(tokens, aspect=5, cmap='Purples_r')
plt.xlabel('Length of Tokens')
plt.ylabel('Number of Tokens')
cbar_ax = fig.add_axes([0.95, .36, 0.05, 0.25])
plt.clim([0, 1])
plt.colorbar(cax=cbar_ax)
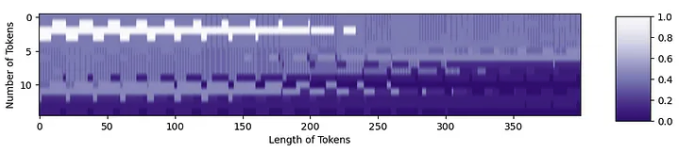
现在,我们可以以正确的形状进行位置嵌入:
PE = get_sinusoid_encoding(num_tokens=15, token_len=400).numpy()[0,:,:]
fig = plt.figure(figsize=(10,6))
plt.imshow(PE, aspect=5, cmap='PuOr_r')
plt.xlabel('Length of Tokens')
plt.ylabel('Number of Tokens')
cbar_ax = fig.add_axes([0.95, .36, 0.05, 0.25])
plt.clim([0, 1])
plt.colorbar(cax=cbar_ax)
我们现在准备将位置嵌入添加到标记中。位置嵌入中的紫色区域将使令牌变暗,而橙色区域将使它们变亮。
mountainsPE = tokens + PE
resclaed_mtPE = (position_mountains - np.min(position_mountains)) / np.max(position_mountains - np.min(position_mountains))
fig = plt.figure(figsize=(10,6))
plt.imshow(resclaed_mtPE, aspect=5, cmap='Purples_r')
plt.xlabel('Length of Tokens')
plt.ylabel('Number of Tokens')
cbar_ax = fig.add_axes([0.95, .36, 0.05, 0.25])
plt.clim([0, 1])
plt.colorbar(cax=cbar_ax)
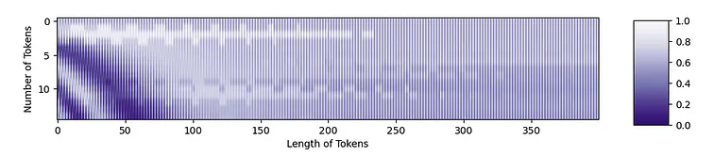
您可以从原始token中看到结构,以及位置嵌入中的结构!这两条信息都将被转发到Transformer中。
Source: https://towardsdatascience.com/position-embeddings-for-vision-transformers-explained-a6f9add341d5
本文由 mdnice 多平台发布
相关文章:
视觉Transformers中的位置嵌入 - 研究与应用指南
视觉 Transformer 中位置嵌入背后的数学和代码简介。 自从 2017 年推出《Attention is All You Need》以来,Transformer 已成为自然语言处理 (NLP) 领域最先进的技术。 2021 年,An Image is Worth 16x16 Words 成功地将 Transformer 应用于计算机视觉任务…...

真香定律!我用这种模式重构了第三方登录
分享是最有效的学习方式。 博客:https://blog.ktdaddy.com/ 老猫的设计模式专栏已经偷偷发车了。不甘愿做crud boy?看了好几遍的设计模式还记不住?那就不要刻意记了,跟上老猫的步伐,在一个个有趣的职场故事中领悟设计模…...

Linux入门到入土
Linxu Linux 简介 Linux 内核最初只是由芬兰人林纳斯托瓦兹(Linus Torvalds)在赫尔辛基大学上学时出于个人爱好而编写的。 Linux 是一套免费使用和自由传播的类 Unix 操作系统,是一个基于 POSIX(可移植操作系统接口)…...

基础真空技术外国文献Fundamentals of Vacuum Technology
基础真空技术外国文献Fundamentals of Vacuum Technology...

LeetCode每日一题【c++版】- 用队列实现栈与用栈实现队列
用队列实现栈 题目描述 请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。 实现 MyStack 类: void push(int x) 将元素 x 压入栈顶。int pop() 移除…...

深入理解快速排序算法:从原理到实现
目录 1. 引言 2. 快速排序算法原理 3. 快速排序的时间复杂度分析 4. 快速排序的应用场景 5. 快速排序的优缺点分析 5.1 优点: 5.2 缺点: 6. Java、JavaScript 和 Python 实现快速排序算法 6.1 Java 实现: 6.2 JavaScript 实现&#…...
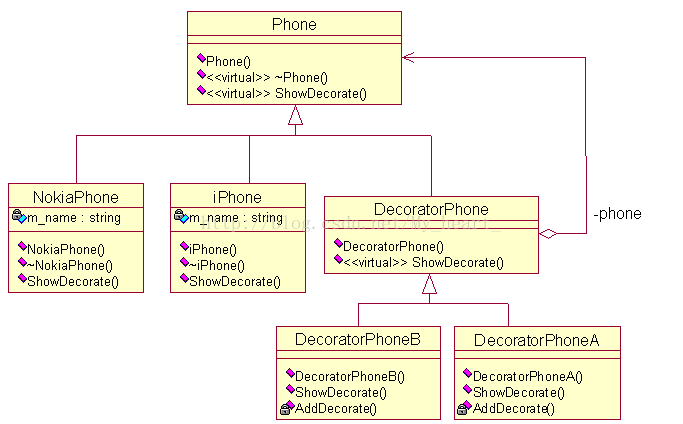
设计模式----装饰器模式
在软件开发过程中,有时想用一些现存的组件。这些组件可能只是完成了一些核心功能。但在不改变其结构的情况下,可以动态地扩展其功能。所有这些都可以釆用装饰器模式来实现。 装饰器模式 允许向一个现有的对象添加新的功能,同时又不改变他的…...
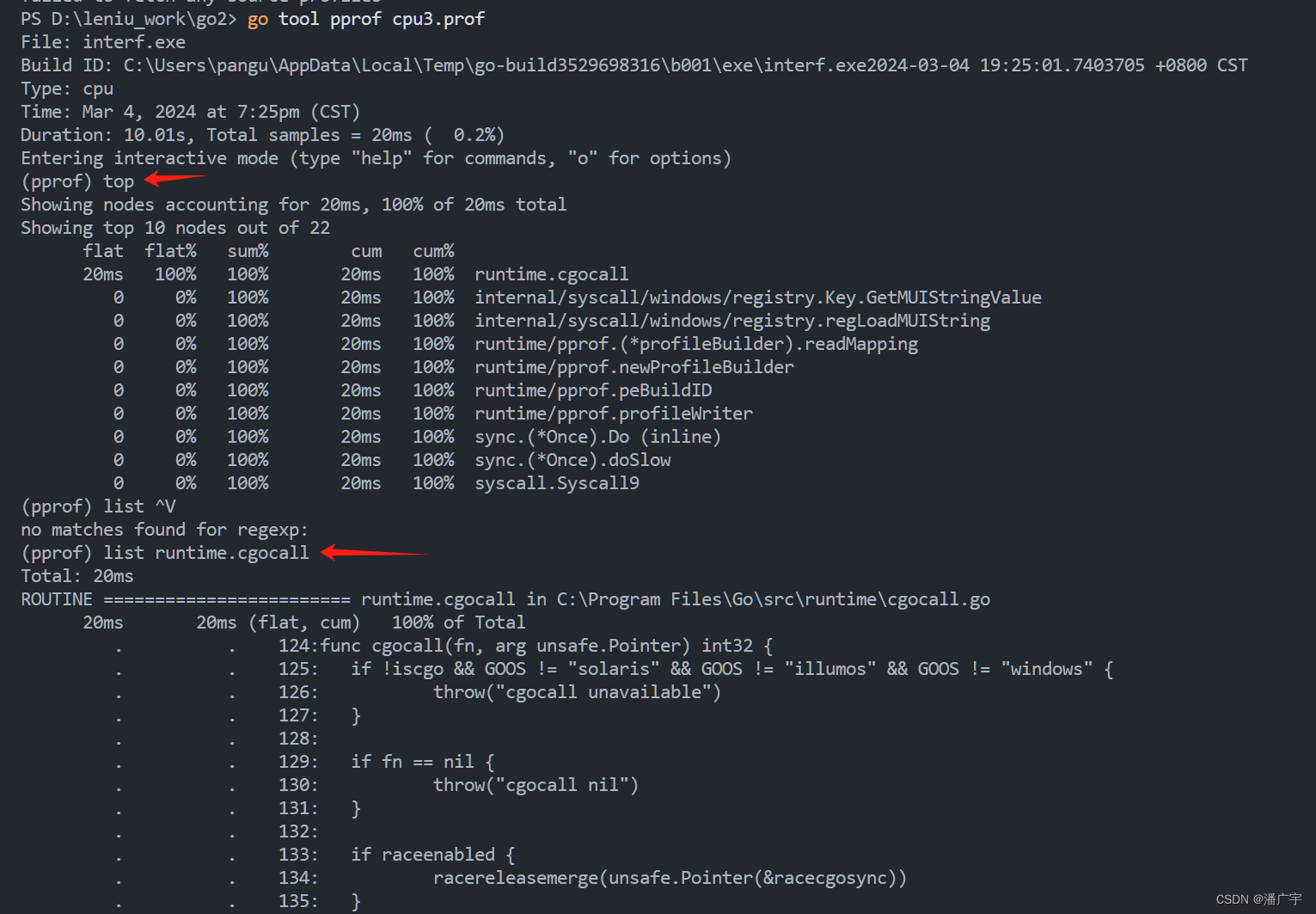
Golang pprof 分析程序的使用内存和执行时间
一、分析程序执行的内存情况 package mainimport ("os""runtime/pprof" )func main() {// ... 你的程序逻辑 ...// 将 HeapProfile 写入文件f, err : os.Create("heap.prof")if err ! nil {panic(err)}defer f.Close()pprof.WriteHeapProfile(f…...
C/C++平方和问题(蓝桥杯)
题目描述: 小明对数位中含有2、0、1、9 的数字很感兴趣,在1 到40 中这样的数包 括1、2、9、10 至32、39 和40,共28 个,他们的和是574,平方和是14362。 注意,平方和是指将每个数分别平方后求和。 请问&#…...

(libusb) usb口自动刷新
文章目录 libusb自动刷新程序Code目录结构Code项目文件usb包code包 效果描述重置reset热拔插使用 END libusb 在操作USB相关内容时,有一个比较著名的库就是libusb。 官方网址:libusb 下载: 下载源码官方编好的库github:Release…...
NLP(一)——概述
参考书: 《speech and language processing》《统计自然语言处理》 宗成庆 语言是思维的载体,自然语言处理相比其他信号较为特别 word2vec用到c语言 Question 预训练语言模型和其他模型的区别? 预训练模型是指在大规模数据上进行预训练的模型,通常…...

智慧公厕:打造智慧城市的环卫明珠
在城市建设中,公共卫生设施的完善和智能化一直是重要环节。而智慧公厕作为智慧城市建设的重要组成部分,发挥着不可替代的作用。本文以智慧公厕源头实力厂家广州中期科技有限公司,大量精品案例现场实景实图,解读智慧公厕如何助力打…...
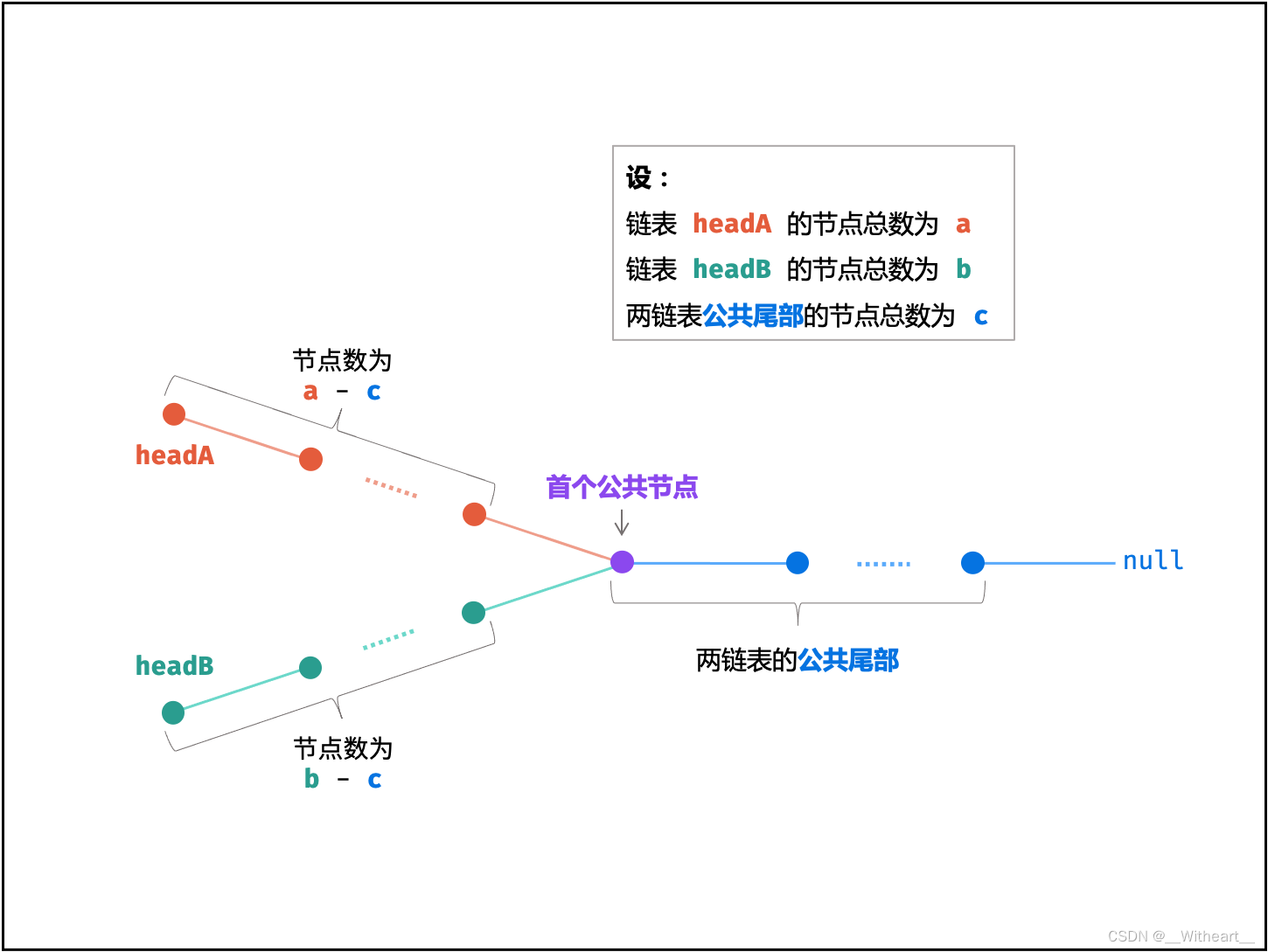
[LeetBook]【学习日记】寻找链表相交节点
来源于「Krahets」的《图解算法数据结构》 https://leetcode.cn/leetbook/detail/illustration-of-algorithm/ 本题与主站 160 题相同:https://leetcode-cn.com/problems/intersection-of-two-linked-lists/ 训练计划 V 某教练同时带教两位学员,分别以…...
【Python】OpenCV-使用ResNet50进行图像分类
使用ResNet50进行图像分类 如何使用ResNet50模型对图像进行分类。 import os import cv2 import numpy as np from tensorflow.keras.applications.resnet50 import ResNet50, preprocess_input, decode_predictions from tensorflow.keras.preprocessing import image# 设置…...

TypeError: `dumps_kwargs` keyword arguments are no longer supported
TypeError: dumps_kwargs keyword arguments are no longer supported 1. 问题描述2. 解决方法 1. 问题描述 使用 FastChat 启动私有大语言模型,通过一些 UI 工具进行访问时,报以下错误。 略 2024-02-29 09:26:14 | ERROR | stderr | yield f"…...

设计模式学习笔记 - 设计原则 - 3.里氏替换原则,它和多态的区别是什么?
前言 今天来学习 SOLID 中的 L:里氏替换原则。它的英文翻译是 Liskov Substitution Principle,缩写为 LSP。 英文原话是: Functions that use points of references of base classes must be able to use objects of derived classes withou…...
java实现图片转pdf,并通过流的方式进行下载(前后端分离)
首先需要导入相关依赖,由于具体依赖本人也不是记得很清楚了,所以简短的说一下。 iText:PDF 操作库,用于创建和操作 PDF 文件。可通过 Maven 或 Gradle 引入 iText 依赖。 MultipartFile:Spring 框架中处理文件上传的类…...

如何系统的学习Python——Python的基本语法
学习Python的基本语法是入门的第一步,以下是一些常见的基本语法概念: 注释: 用#符号来添加单行注释,或使用三引号(或""")来添加多行注释。 # 这是一个单行注释 这是 多行 注释 变量和数据类型: 变量用…...

相机,棱镜和光场
一、成像方法 Imaging Synthesis Capture 1.Synthesis(图形学上)合成:比如之前学过的光线追踪或者光栅化 2.Capture(捕捉):把真实世界存在的东西捕捉成为照片 二、相机 1.小孔成像 利用小孔成像的相…...
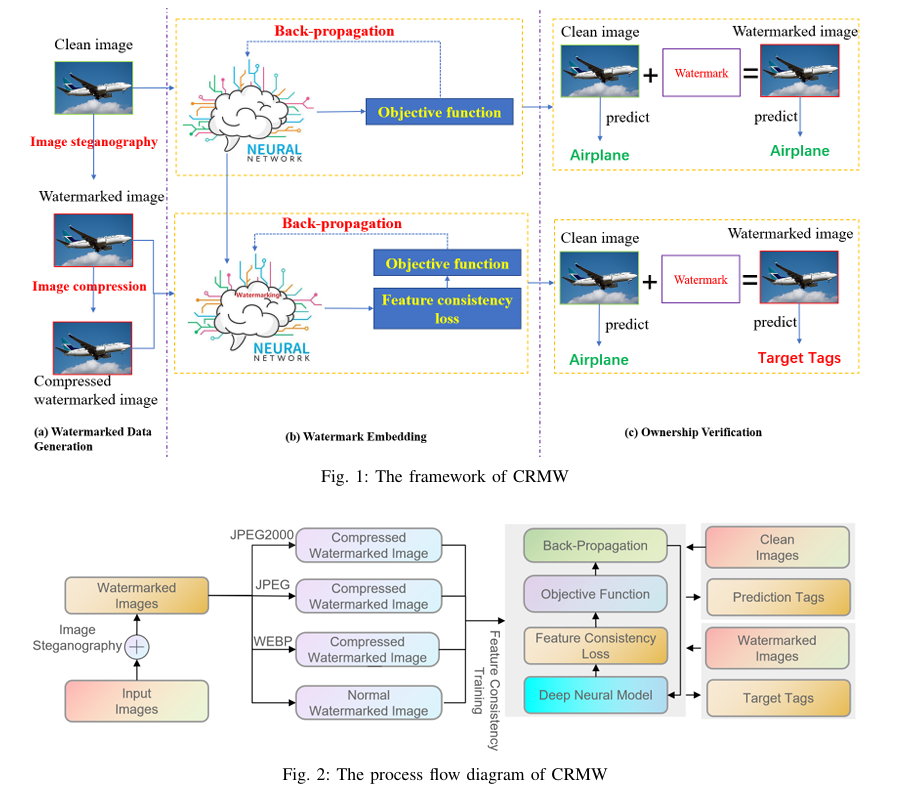
【图像版权】论文阅读:CRMW 图像隐写术+压缩算法
不可见水印 前言背景介绍ai大模型水印生成产物不可见水印CRMW 在保护深度神经网络模型知识产权方面与现有防御机制有何不同?使用图像隐写术和压缩算法为神经网络模型生成水印数据集有哪些优势?特征一致性训练如何发挥作用,将水印数据集嵌入到…...

量子优化新突破:虚时间演化高效求解QUBO问题
1. 量子优化新范式:模拟虚时间演化解决QUBO问题在金融投资组合优化、物流路径规划和机器学习特征选择等领域,二次无约束二进制优化(QUBO)问题无处不在。这类NP难问题随着规模扩大,求解难度呈指数级增长,传统…...

Proteus 8.17安装超详细教程 保姆级教程【附安装包】
电子设计小伙伴们!今天我给大家带来一篇超详细的Proteus 8.17专业版安装教程 !这可是电子工程师和学生党的福音啊!作为PCB设计和单片机仿真的神器,Proteus绝对是你玩转电子设计必备的利器!不会安装?别担心&…...

Linux服务器安全加固实战:SSH+防火墙+权限最小化三重防护
1. 这不是“加个密码就完事”的安全,而是让服务器真正扛住真实攻击的第一道防线很多人以为 Linux 安全加固就是改个 root 密码、关掉 telnet、再装个 fail2ban 就算交差了。我去年帮一家做跨境电商 SaaS 的客户做渗透复测时,他们运维同事就是这么干的——…...

终极指南:如何用Blender 3MF插件实现3D打印数据无损传递
终极指南:如何用Blender 3MF插件实现3D打印数据无损传递 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 你是否曾经在3D打印工作流中遇到过这样的问题&#x…...
)
软件架构设计师考试——系统安全性与保密性设计知识点全总结(考前冲刺版,超1万字)
临近软件架构设计师考试,系统安全性与保密性设计是考试的核心模块,贯穿上午场信息系统综合知识(15-20分)、下午场案例分析(25-35分)及论文写作(高频命题方向),是“稳拿分…...

皮线、裸纤总是分不清?试试这个算法一键校准技巧
不知道你有没有经历过这种工地上的"崩溃瞬间":大热天蹲在居民楼昏暗的楼道里,蚊子在耳边嗡嗡叫,你手里正拉着一根刚从住户门缝里拽出来的皮线光缆,准备跟分纤箱引出来的单模裸纤做熔接。结果放进机器,合上盖…...

7步搞定MASA全家桶汉化包:让你的Minecraft模组说中文
7步搞定MASA全家桶汉化包:让你的Minecraft模组说中文 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 还在为MASA模组的英文界面而烦恼吗?作为中文Minecraft玩家&…...

Claude Desktop for Linux桌面集成:.desktop文件与MIME类型配置
Claude Desktop for Linux桌面集成:.desktop文件与MIME类型配置 【免费下载链接】claude-desktop-debian Claude Desktop for Linux 项目地址: https://gitcode.com/GitHub_Trending/cl/claude-desktop-debian Claude Desktop for Linux是一款强大的桌面应用…...

飞凌OKMX6ULL-C开发板深度评测:从硬件解析到系统性能实战
1. 开箱与初识:飞凌OKMX6ULL-C开发平台拿到飞凌OKMX6ULL-C开发板的第一印象,是它比我想象中要“工整”不少。核心板(FETMX6ULL-C)和底板通过高可靠性的板对板连接器接插,这种设计在工业级产品中很常见,方便…...
:1套配置+4个插件=自动注入用户喜爱度)
Vue/React/Svelte通用Lovable实践框架(内部首发):1套配置+4个插件=自动注入用户喜爱度
更多请点击: https://kaifayun.com 第一章:Vue/React/Svelte通用Lovable实践框架(内部首发):1套配置4个插件自动注入用户喜爱度 Lovable 是一套面向用户体验(UX)可量化提升的前端工程化实践框架…...